

Сначала пара слов о том, что мы вообще разработали, на каких технологиях и архитектуре всё базируется, откуда берётся высокая нагрузка. А далее – про 5 основных решений, которые мы применяем чтобы с этой нагрузкой справиться.
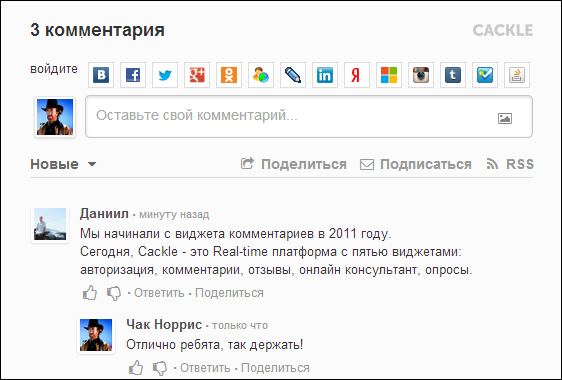
Система комментариев
Cackle Comments – наш первый продукт, анонсированный в 2011 году.
Упрощает процесс комментирования за счёт удобной авторизации – анонимной, социальной или единой с вашим сайтом. Помогает привлечь больше трафика благодаря индексации в поисковиках, трансляции комментариев на стены социальных сетей (ВК, Мой Мир, Facebook, Twitter), подписке на новые комментарии и ответы. Снижает нагрузку за счёт независимости от вашего сайта.
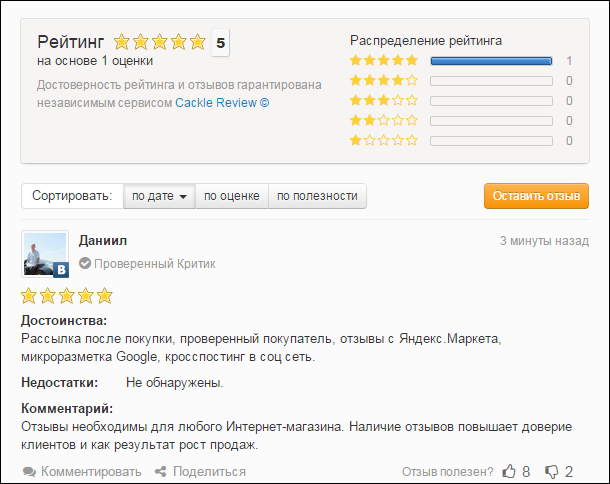
Система отзывов для интернет-магазинов
Cackle Reviews – система отзывов, релиз которой состоялся в 2013 году. Используется в основном интернет-магазинами, но без проблем работает на любом сайте.
Основные возможности:
- Загрузка отзывов с Яндекс.Маркета;
- Индексация в Google с микроразметкой «из коробки» (рейтинг в результатах поиска);
- Follow-up рассылка писем с приглашением оставить отзыв после покупки;
- Удобная анонимная, социальная, единая авторизация;
- Трансляция отзывов в социальные сети: ВК, Мой Мир, Facebook, Twitter;
- Модерация отзывов в режиме реального времени;
- Комментарии к отзывам;
- СПАМ-защита;
- CMS плагины: 1С-Битрикс, Joomla (K2, Virtuemart, Zoo), OpenCart, PrestaShop.
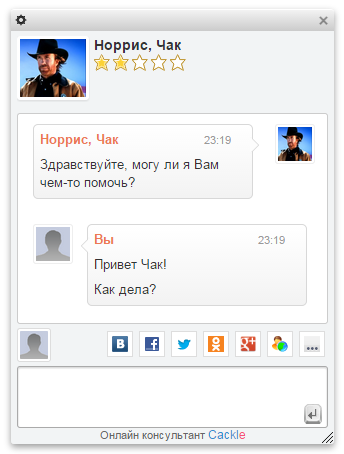
Online-консультант
Cackle Live Chat – онлайн-чат для посетителей сайта, релиз в 2013 году.
Из особенностей: быстрая установка, панель оператора реализована в браузере, не нужно тратить время на инсталляцию desktop-клиента. Социальная авторизация пользователей, при этом оператор получает информацию о клиенте (имя, фото, email, ссылку на профиль).
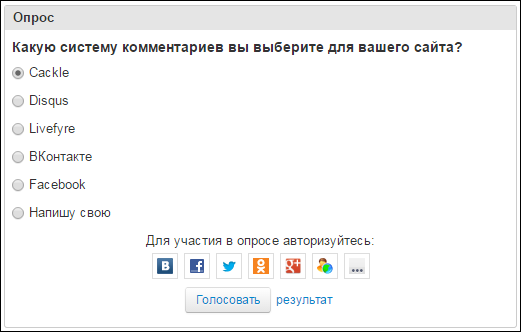
Виджет опросов
Cackle Polls – опросы с возможностью голосования через социальные сети, IP или Cookie, релиз также в 2013 году.
Опросы автоматически индексируются в Google, привлекая дополнительный трафик. Можно загружать изображения, есть распознавание видео YouTube и Vimeo.
Технологии
Фронтенд в понимании Cackle – это JavaScript. Бекенд – сервера данных и логики.
Фронтенд
Фронтенд состоит из виджетов. Виджет – это исполняемая JavaScript-библиотека, базирующаяся на других, общих, JavaScript-библиотеках. Примеры общих библиотек:
- Библиотека для работы с DOM: jQuery сильно тормозил и не работал на нескольких мобильных платформах, поэтому написали свое решение на Vanilla JS. В итоге по некоторым операциям скорость работы выросла в 600 раз + наше решение работает на всех версиях Android и iOS;
- Библиотека единой авторизации (анонимная, социальная, SSO);
- Библиотека поддержки Real-time режима с умным выбором протокола взаимодействия (WebSocket, EventSource, Long-Polling);
- Библиотека кроссдоменных GET/POST запросов;
- И другие: работа с датой, БД браузера (cookie, localstorage), json, загрузка изображений, распознавание видео (YouTube, Vimeo), tray нотификации, пагинация и др.
Все виджеты работают без iframe, за счёт чего возможна модификация css под стиль вашего сайта.
Есть общий загрузчик виджетов (widget.js), что-то на подобии RequireJS, только более простой. У загрузчика два режима работы – devel и prod. Первый применяется при разработке, загружает библиотеки в цикле. Второй на продакшене, грузит собранный бандл (bundle). В prod режиме загрузка виджетов происходит с разных серверов выбранных случайным образом, в итоге получается балансинг (подробнее об этом дальше).
Cackle.Bootstrap = Cackle.Bootstrap || {
appendToRoot: function(child) {
(document.getElementsByTagName('head')[0] || document.getElementsByTagName('body')[0]).appendChild(child);
},
//загружает js
loadJs: function(src, callback) {
var script = document.createElement('script');
script.type = 'text/javascript';
script.src = src;
script.async = true;
if (callback) {
if (typeof script.onload != 'undefined') {
script.onload = callback;
} else if (typeof script.onreadystatechange != 'undefined') {
script.onreadystatechange = function () {
if (this.readyState == 'complete' || this.readyState == 'loaded') {
callback();
}
};
} else {
script.onreadystatechange = script.onload = function() {
var state = script.readyState;
if (!state || /loaded|complete/.test(state)) {
callback();
}
};
}
}
this.appendToRoot(script);
},
//загружает css
loadCss: function(href) {
var style = document.createElement('link');
style.rel = 'stylesheet';
style.type = 'text/css';
style.href = href;
this.appendToRoot(style);
},
//загружает несколько css
loadCsss: function(url, css) {
for (var i = 0; i < css.length; i++) {
Cackle.Bootstrap.loadCss(url + css[i] + Cackle.ver);
}
},
//загружает несколько js
loadJss: function(url, js, i) {
var handler = this;
if (js.length > i) {
Cackle.Bootstrap.loadJs(url + js[i] + Cackle.ver, function() {
handler.loadJss(url, js, i + 1);
});
}
},
//общий загрузчик ресурсов
load: function(host, js, css) {
var url = host + '/widget/';
this.loadJss(url + 'js/', js, 0);
if (css) this.loadCsss(url + 'css/', css);
},
/**
* Далее идут виджеты, например, комментариев
*/
Comment: {
isLoaded: false,
load: function(host) {
this.isLoaded = true;
if (Cackle.env == 'prod') {
//В продакшене загружаем бандл
Cackle.Bootstrap.load(host, ['comment.js'], ['comment.css']);
} else {
//При разработке синхронно загружаем библиотеки и сам виджет для модификации/дебага
Cackle.Bootstrap.load(host, ['fastjs.js',
'json2.js',
'rt.js',
'xpost.js',
'storage.js',
'login.js',
'comment.js'],
['comment.css']);
}
}
},
...
};
//Загружаем виджет комментариев (widget == 'Comment')
//host - случайный сервер из кластера (об этом дальше)
if (!Cackle.Bootstrap[widget].isLoaded) {
Cackle.Bootstrap[widget].load(host);
}
Бекенд
Это кластер Apache Tomcat контейнеров, снаружи обернутых Nginx-серверами. Nginx в данном случае выступает не только как прокси, но и как «поглотитель» нагрузки. База данных PostgreSQL с потоковой репликацией на несколько слейвов.
Все бекенды распределены по нескольким дата-центрам (ЦОДам) России и Европы. Наш опыт показал, что хостить все сервера в одном дата-центре слишком рискованно, поэтому сейчас мы подключены к трём разным ЦОДам.
Real-time
Поддержка обновлений в режиме реального времени (комментарии, лайки, редактирование, модерация, личные сообщения, чат) на стороне браузера, происходит через любую из поддерживаемых технологий: WebSocket, EventSource, Long-Polling. То есть, сначала мы проверяем есть ли WebSocket, далее EventSource, Long-Polling. При дисконнектах (ошибках) связь автоматически восстанавливается функцией, которая в setTimeout мониторит состояние подключения.
На сервере мы используем кластер Nginx + модуль Push Stream. Всего 3 сервера: 2 общих и 1 для онлайн-консультанта. Real-time сообщения из бекендов (Tomcat-ов) отправляются на все сервера. А в браузере, при подключении из виджета, выбирается любой сервер (случайным образом). В итоге получается, что-то на подобии балансинга (к сожалению, Push Stream балансинг «из коробки» не поддерживает).
Кроме этого есть:
- Сервер загрузки, обработки и хранения изображений;
- SMTP сервер.
Архитектура
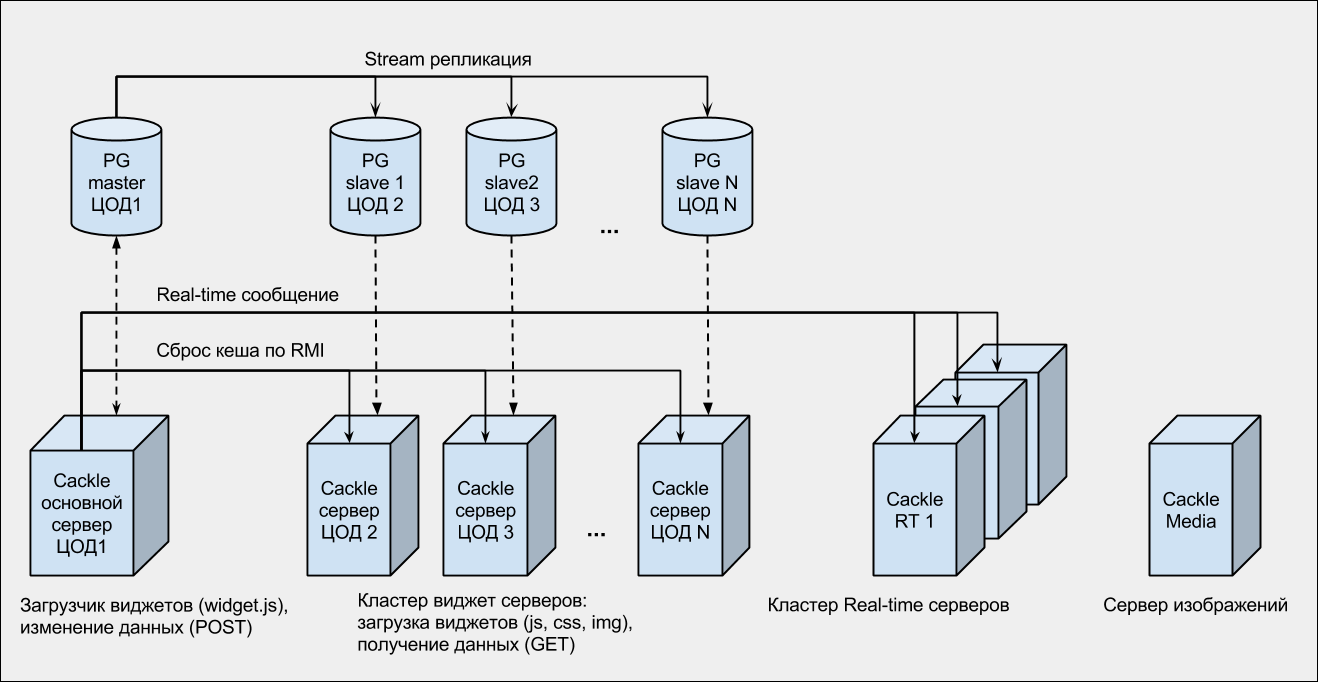
PG — PostgreSQL.
RT — Real-time.
ЦОД (1,2,..., N) — различные дата-центры.
RMI — Java технология удаленного вызова методов (wikipedia).
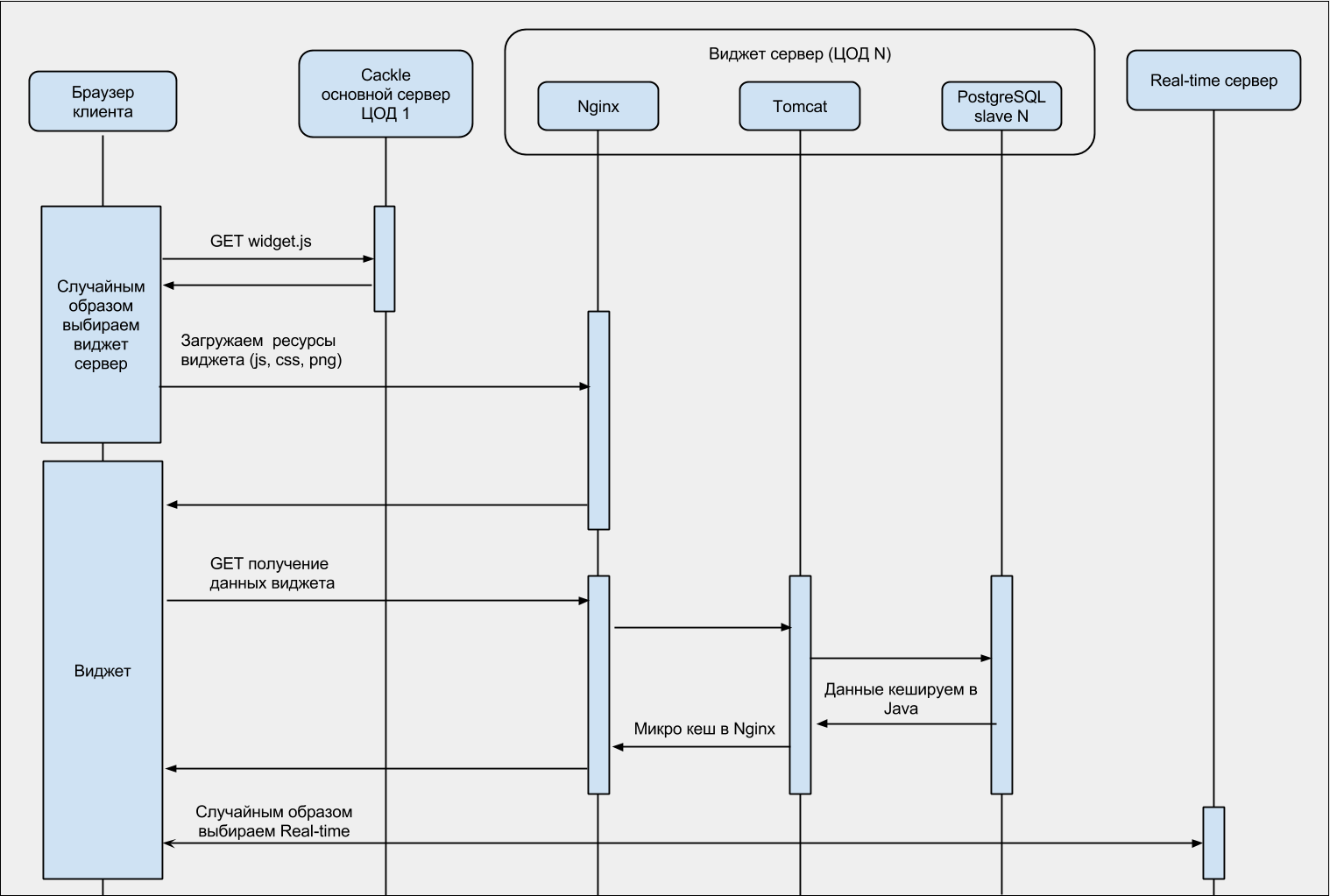
Для лучшего понимания, диаграмма последовательности загрузки виджета:
Нагрузка
Ниже суммарная статистика по виджетам и обращениям к API.
Уникальных хитов в сутки: 60 — 70 миллионов
Пик запросов в секунду: 2700
Пик одновременных real-time сессий: 300 000
Пиковая пропускная способность: 780 мбит/с
Трафик в сутки: 1.6 Тбайт
Ежедневный суммарный лог Nginx: 102 Гбайт
Запросов к БД на чтение (в сутки): 80 — 120 миллионов
Запросов к БД на запись (в сутки): 300 000
Количество зарегистрированных сайтов: 32 558
Количество зарегистрированных пользователей: 8 220 681
Комментариев опубликовано: 23 840 847
Ежедневный средний прирост комментариев: 50 000
Ежедневный средний прирост пользователей: 15 000
Проблемы
Высокая нагрузка порождает две проблемы:
Во-первых, практически у всех хостеров по умолчанию пропускная способность (bandwidth) сервера 100 мбит/с. Все что выше режется или в лучшем случае вас просят докупить дополнительную полосу (а цены там в разы выше стоимости самих серверов).
Вторая проблема – это и есть сама нагрузка. Физику не обманешь, каким бы ни был крутым ваш сервер, у него есть свой предел.
» Решение 1: балансинг в JavaScript
Стандартные методы распределения нагрузки говорят о балансинге входного запроса на сервере. Это решит вторую проблему, но не первую (bandwidth), так как исходящий трафик все равно пойдет через тот же сервер.
Чтоб решить две проблемы одновременно, мы делаем балансинг в JavaScript, в самом загрузчике (widget.js), выбирая бекенд случайным образом. В итоге, трафик перенаправляем на сервера из кластера виджет серверов разделяя между ними bandwidth и распределяя нагрузку.
Дополнительный огромный плюс этого метода, в кешировании JavaScript. Все библиотеки (включая загрузчик widget.js), при обновлении страницы, будут получены из кеша браузера, а наши сервера продолжат спокойно обрабатывать новые запросы.
Продолжение кода загрузчика (widget.js часть 2):
var Cackle = Cackle || {};
Cackle.protocol = ('https:' == window.location.protocol) ? 'https:' : 'http:';
Cackle.host = Cackle.host || 'cackle.me';
Cackle.origin = Cackle.protocol + '//' + Cackle.host;
//Кластер виджет серверов (a.cackle.me, b.cackle.me, c.cackle.me):
Cackle.cluster = ['a.' + Cackle.host, 'b.' + Cackle.host, 'c.' + Cackle.host];
//Тут код загрузчика, см. выше widget.js часть 1
Cackle.getRandInt = function(min, max) {
return Math.floor(Math.random() * (max - min + 1)) + min;
}
Cackle.getRandHost = function() {
return Cackle.cluster[Cackle.getRandInt(0, Cackle.cluster.length - 1)];
};
Cackle.initHosts = function() {
//getRandHost собственно и есть балансинг
var host = Cackle.getRandHost();
for (var i = 0; i < cackle_widget.length; i++) {
cackle_widget[i].host = Cackle.protocol + '//' + host;
}
};
//cackle_widget - служебный массив содержищай виджеты для загрузки,
//он заполняется в коде самого виджета (на сайте клиента).
//Например: cackle_widget.push({widget: 'Comment', id: 1});
Cackle.main = function() {
Cackle.initHosts();
for (var i = 0; i < cackle_widget.length; i++) {
var widget = cackle_widget[i].widget;
if (!Cackle.Bootstrap[widget].isLoaded) {
Cackle.Bootstrap[widget].load(cackle_widget[i].host);
}
}
};
Cackle.main();
А как на счет профессионального CDN?
Это здорово! Проблема только в том, что при наших объемах и нагрузках для того, чтобы использовать CDN необходимо поднять цены минимум в 3 раза, сохранив при этом текущий оборот.
» Решение 2: микрокеш Nginx
Микрокеш это кеш с очень коротким сроком жизни, например 3 секунды. Он очень полезен при пиковых нагрузках, когда в секунду идут тысячи одинаковых GET запросов. Для нас это данные виджетов в JSON формате. Микрокеш имеет смысл делать в proxy серверах, например Nginx для защиты основного бекенда (Tomcat).
Часть конфига Nginx с микрокешем:
...
location /bootstrap {
try_files $uri @proxy;
}
...
location @proxy {
#Бекенд (Tomcat)
proxy_pass http://localhost:8888;
proxy_redirect off;
#В интернете много постов про настройку Nginx кеша,
#но почему-то нигде не сказано, что без этого ничего работать не будет
proxy_ignore_headers X-Accel-Expires Expires Cache-Control;
set $no_cache "";
#Кешируем только GET|HEAD
if ($request_method !~ ^(GET|HEAD)$) {
set $no_cache "1";
}
if ($no_cache = "1") {
add_header Set-Cookie "_mcnc=1; Max-Age=2; Path=/";
add_header X-Microcachable "0";
}
if ($http_cookie ~* "_mcnc") {
set $no_cache "1";
}
proxy_cache microcache;
proxy_no_cache $no_cache;
proxy_cache_bypass $no_cache;
proxy_cache_key $scheme$host$request_method$request_uri;
#Кешируем на 3 секунды
proxy_cache_valid 200 301 302 3s;
proxy_cache_use_stale error timeout http_500 http_502 http_503 http_504 http_403 http_404 updating;
default_type application/json;
}
...
Если есть проблемы с пониманием данного конфига, то обязательно для чтения ngx_http_proxy_module.
» Решение 3: тюнинг Tomcat, Java кеш
Tomcat
Особо протюнинговать Tomcat не получится. Из практического опыта:
- Не морочьте голову с выбором коннектора (Http11Protocol, Nio, Apr). При больших нагрузках это не играет роли.
- Сделайте connectionTimeout минимальным, какой только возможно, желательно не больше 5 секунд.
- Не делайте слишком большой maxThreads, он не поможем, а в некоторых ситуация только навредит. Стандарт для нагруженного проекта 300-350. Если этого мало, добавьте новый Tomcat сервер.
- А вот acceptCount можно сделать несколько тысяч (2000-4000). При маленьких значениях подключения отрубаются (connection refused), а так будут складываться в очередь. При этом не забудьте в ОС выставить такой же или больше backlog.
Java кеш
Принято считать БД, в высоконагруженных проектах, слабым местом. Это действительно так. Например, сервер принимает запрос, отправляет его в сервисный уровень, там сервис обращается к БД и возвращает результат. Связка «сервис — БД (реляционная)» в этом случае работает медленнее всех, поэтому принято оборачивать сервисы кешем. Соответственно результат из БД, кладется в кеш сервиса, и при следующем обращении берется уже из него.
Для кеширования сервисов мы разработали свой кеш, так как стандартные (например Ehcache) работают медленнее и не всегда хорошо решают специфические задачи. Из специфических задач у нас – кеширование с поддержкой нескольких ключей для одного значения. Мы используем org.apache.commons.collections.map.MultiKeyMap.
Нужно это вот для каких задач. Например пользователь заходит на страницу с комментариями. Допустим комментариев много, 300 штук. Они разбиты на три страницы (пагинация) соответственно по 100 каждая. При первом обращении, будет закеширована первая страница (100 комментариев), если пользователь листает вниз, то по очереди закешируется 2 и 3 страницы. Теперь пользователь публикует комментарий на этой странице и тут надо сбросить все три кеша. Используя MultiKeyMap это выглядит примерно так:
MultiKeyMap cache = MultiKeyMap.decorate(new LRUMap(capacity));
cache.put(chanId, "page1", commentSerivce.list(chanId, 1)); //chanId - id страницы с комментариями
cache.put(chanId, "page2", commentSerivce.list(chanId, 2)); //commentSerivce.list - получаем комментарии на странице (chanId) с пагинацией (2)
cache.put(chanId, "page3", commentSerivce.list(chanId, 3));
cache.removeAll(chanId); //Удаляем все 3 кеша на странице для всех пагинаций
Ниже код ядра кеша отлично работающий на highload.
public class CackleCache {
private final MultiKeyMap CACHE = MultiKeyMap.decorate(new LRUMap(capacity));
public static class SoftValue<K, V> extends SoftReference<V> {
final K key;
final long expired;
public SoftValue(V ref, ReferenceQueue<V> q, K key, long timelife) {
super(ref, q);
this.key = key;
this.expired = System.currentTimeMillis() + timelife;
}
}
public synchronized Future<Object> get(final MultiKey key, final long timelife, final MethodInvocation invocation) {
Future<Object> ret;
@SuppressWarnings("unchecked")
SoftValue<MultiKey, Future<Object>> sr = (SoftValue<MultiKey, Future<Object>>) CACHE.get(key);
if (sr != null) {
ret = sr.get();
if (ret != null) {
if (sr.expired > System.currentTimeMillis()) {
return ret;
} else {
sr.clear();
}
}
}
ret = executor.submit(new Callable<Object>() {
@Override
public Object call() throws Exception {
try {
return invocation.proceed();
} catch (Throwable t) {
throw new Exception(t);
}
}
});
SoftValue<MultiKey, Future<Object>> value = new SoftValue<MultiKey, Future<Object>>(ret, referenceQueue, key, timelife);
CACHE.put(key, value);
return ret;
}
public synchronized void evict(Object key) {
try {
CACHE.removeAll(key);
} catch (Throwable t) {}
}
}
» Решение 4: PostgreSQL с потоковой репликацией в разные дата-центры
На наш взгляд PostgreSQL лучшее решение для высоконагруженных проектов. Сейчас модно применять NoSQL, но в большинстве случаев, при правильном подходе и верной архитектуре, PostgreSQL лучше.
В PostgreSQL отлично работает потоковая репликация, причем не важно в одной подсети или в разных сетях, разных дата-центрах. У нас, например, сервера БД расположены в нескольких странах и серьезных проблем замечено не было. Единственный нюанс — это большие модификации базы (ALTER TABLE) при релизах. Делать их надо кусками, стараясь не выполнять за раз весь UPDATE.
По настройке репликации есть много ресурсов, это избитая тема, так что добавить особо нечего, кроме:
- Обязательно сделайте план (конфиг) на случай failover (падение мастера) и реально протестируйте это;
- Поймите принцип работы WAL, чтоб в случае рассинхронизации слейва и мастера знать зачем вам архивы и куда их надо положить;
- Следите за местом на HDD мастера, если вдруг его не станет, то PostgreSQL может упасть, а при репликации это чревато большими неприятностями.
» Решение 5: тюнинг ОС
Не забывайте тюнить параметры ядра ОС, так как без этого некоторые настройки Nginx или Tomcat просто не будут работать.
У нас, например, везде Debian. В настройках ядра ОС (/etc/sysctl.conf) особое внимание нужно обратить на:
kernel.shmmax = 8000234752 // Это для PostgreSQL, чтоб можно было выставлять большой shared_buffers (6 - 8GB)
fs.file-max = 99999999 // Это для Nginx, без него можно получить "Too many open files"
net.ipv4.tcp_max_syn_backlog=524288 // Максимальное число запоминаемых запросов на соединение
net.ipv4.tcp_max_orphans=262144 // Максимальное число допустимых в системе сокетов TCP
net.core.somaxconn=65535 // Максимальное число открытых сокетов
net.ipv4.tcp_mem=1572864 1835008 2097152 // Потребление памяти для протокола TCP
net.ipv4.tcp_rmem=4096 16384 16777216 // Размер приемного буфера сокетов TCP
net.ipv4.tcp_wmem=4096 32768 16777216 // Количество памяти, резервируемой для буферов передачи сокета TCPПроблемы, которые пока решить не удалось
Вернее одна проблема – размер БД. Есть, конечно, шардинг, но стандартного решения для PostgreSQL без падения производительности пока не нашли. Если кто-то может поделиться практическим опытом – welcome!
Спасибо за внимание. Вопросы и пожелания по нашей системе приветствуются!
Комментарии (80)

dark_ruby
08.04.2015 16:58+6оффтоп: почему на заглавной картинке Шварц не обхватывает штангу большими пальцами?

TimReset
08.04.2015 17:36+4Это «открытый хват». Очень опасный, т.к. гриф может соскользнуть, но часто видел что его используют опытные спортсмены. Вот тут не знаю почему — особых преимуществ и отличий от «закрытого хвата» он не даёт (по крайней мере, так пишут). Может потому что могу? :)
P.S. Не обновил комментарии.
priv8v
08.04.2015 18:46+2Открытый хват используется лишь в тренировочных подходах (на соревнованиях он запрещен) для большего включения всех пучков трицепса, ну и кому-то, он может быть более удобен для кистей/предплечий, но это индивидуально: например, французский жим кому-то убивает локти, а кому-то вполне себе удобное упражнение.

{kind=link}

le0pard
08.04.2015 17:18+2Вернее одна проблема – размер БД. Есть, конечно, шардинг, но стандартного решения для PostgreSQL без падения производительности пока не нашли. Если кто-то может поделиться практическим опытом – welcome!
Pl/Proxy, Postgres-XC (3x при 5 нодах), Postgres-XL, Pg_shard? Понятное дело, что при 2-3 нодах шардинг система не имеет особого смылса.

ilyaplot
08.04.2015 17:31+3Как клиент, готов подтвердить, что api работает мгновенно, так же как и виджеты. И радует то, что мы даже не подозреваем о каких-либо проблемах с базой на вашей стороне. Случай редкий и очень радует. Спасибо.

cackle Автор
08.04.2015 17:39+2Спасибо!
Ну это проблема на скорости ни как не сказывается, просто размер растет, соответственно дешевле будет разбить на несколько кусков, чем хранить все в одном месте.

Demetros
08.04.2015 19:24У вас видимо nginx староват, по вашей же ссылке в прокси-модуле можно обнаружить вкусности типа директив proxy_cache_lock*, которые могут заметно сгладить всплески просачивающихся на бэкенд запросов при устаревании кеша.
А почему вы не хотите сделать шардинг сами, на уровне приложения?cackle Автор
08.04.2015 19:27+1>А почему вы не хотите сделать шардинг сами, на уровне приложения?
Все идет именно к этому =)
PS: спасибо за proxy_cache_lock, посмотрю!
cackle Автор
08.04.2015 19:37+1Посмотрел proxy_cache_lock, это не много не то, вернее вообще не то =)
Как я понимаю, данная опция просто блокирует остальных, кто ждет кеша, пока первый кто-то его не заполнит.
Думаю в нашем случае это ухудшит производительность сделав заметным небольшие «замирания» системы, а так все асинхронно, никто ни от кого не зависит.Demetros
08.04.2015 20:36Во-первых, замирание будет равно времени ответа бэкенда.
Во-вторых, вы говорите про 2700 запросов в секунду в пике. Предположим, кеш протух и его обновление занимает 100мс (т.е. бэкенд на этот запрос отвечает за 100мс). Соответственно, в момент протухания кеша на ваш бэкенд пойдет примерно 270 одинаковых запросов практически одновременно! И все эти клиенты получат ответ не ранее чем через 100мс, а скорее даже позже, т.к. ваш бэкенд в любом случае будет работать медленнее при множестве одновременных запросов.
В случае использования proxy_cache_lock на ваш бэкенд уйдет всего один запрос, который обновит кеш за 100мс и все клиенты, ждущие этот кеш (грубо говоря 269 клиентов) получат ответ за те же 100мс, но при этом бэкенд обработал один запрос вместо 270.Demetros
09.04.2015 08:42+1Прошу прощения, я и сам заблуждался, и вас пытался ввести в заблуждение.
В действительности, proxy_cache_lock работает только при создании нового элемента кеша, а при обновлении кеша работает ?proxy_cache_use_stale updating.

el777
08.04.2015 19:27в самом загрузчике (widget.js), выбирая бекенд случайным образом.
Зачем? Чтобы браузеры каждый раз перезагружали ваш виджет снова и снова? Считая, что они грузят их с разных сайтов.
Сделайте DNS round-robin, укажите 20 серверов — тогда можно будет закешировать после 1 обращения.cackle Автор
08.04.2015 19:30+1Спасибо!
DNS round-robin — рассматривали, но он в разы менее гибок (если надо что-то срочно менять), чем round-robin на JS.el777
08.04.2015 19:43Понимаю, но как мне видится, у вас должно быть сейчас очень много трафика лишнего за счет того, что клиент не может закешировать надолго загружаемые файлы. И что хуже — решение не масштабируется.
Если пока не готовы делать как я описал ниже — то попробуйте вынести всю статику на вообще отдельные хосты и поставить их на хорошие каналы.

sunnybear
08.04.2015 21:10BGP должно вас спасти. Но для этого нужны свои IP адреса. Время простоя при BGP-балансировке на 2 порядка меньше, чем при DNS/JS балансировке
sunnybear
08.04.2015 21:12Какой размер данных (количество / размер) у вас в микрокэшах? При большой частоте перезаписи дисковая подсистема становится узким местом.
cackle Автор
09.04.2015 23:04+1Размер ограничен (proxy_cache_path /var/cache/nginx levels=1:2 keys_zone=microcache:50m max_size=100m;)
Вот на одни из серверов:
malta2020:/var/cache/nginx# du. -h
…
122M.
malta2020:/var/cache/nginx# find. -type f | wc -l
17223
То есть 122мб кеш и всего 17223 файла.
sunnybear
09.04.2015 23:05вам повезло, у нас на сервер на 2 порядка больше данных. На таких объемах proxy_cache перестает эффективно работать
el777
08.04.2015 19:40+3Вообще у вас очень странно устроена сетевая часть.
С одной стороны — приличный трафик, сервера стоят в разных странах, а с другой — рандомные хосты в урлах.
При таком трафике лучше сделать свою автономную систему и провайдеро-незаввисимую сеть адресов.
Далее: анонсируете сетку из каждой точки присутствия. И каждый пользователь автоматически пойдет на ближайшее к себе зеркало и заберет оттуда статику. Кроме того: микрокеши нгинкса вы сможете размещать максимально близко к пользователю. Если вдруг пошла мощная нагрузка, то она пошла на одно зеркало и там и осталась.
Плюсы:
+ ускорение загрузки — всегда берется с ближайшего зеркала
+ повышение отказоустойчивости — если одно зеркало упало, нагрузка сама перетечет на другие
+ улучшение кеширования статики — вы можете сильно увеличить DNS TTL и Expires — хоть на год — т.к. и домен и адреса ваши
+ легкость масштабирования — ставите в нужный ДЦ поближе к юзерам, включаете — все работает
+ сокращение расходов на трафик — да, вы получите качество намного выше за заметно меньшие деньги
Минусы:
— вам нужен грамотный сетевой администраторcackle Автор
08.04.2015 19:44+1Если я правильно вас понимаю, то речь о своем CDN?
Alaniyatm
08.04.2015 23:39+1Скорее о anycast. посмотрите как устроен root dns.
в сетевом мире есть такая штука, называется она hot potato routing.
el777
09.04.2015 12:25+1По сути да.
Причем вас никто не обязывает сразу строить огромную сеть — можно начать всего с 2 узлов и вы уже почувствуете экономию. А дальше просто добавляете по мере необходимости. Масштабирование практически линейное. Вся система даже с учетом зарплаты хорошего админа быстро отбивает свои вложения. Когда построите, поймете сколько шкур дерут провайдеры с CDN :)

Draug
09.04.2015 12:34При таком трафике лучше сделать свою автономную систему и провайдеро-незаввисимую сеть адресов.
Насколько сложно сейчас получить PI адреса и свою AS? Хотя бы /24?el777
09.04.2015 12:37Я в свое время становился партнером RIPE, получал статус LIR и с ним сетку /21.
Далее стали выдавать /22 новым лирам.
Сейчас с этим сложнее.
В крайнем случае можно арендовать /24 на рынке. Выйдет подороже, но если проект крупный и много трафика, то это имеет смысл.

amarao
08.04.2015 22:02+3А, давайте, я вам задам вопрос: почему «какл»? Уж очень неблагозвучно.

PHmaster
09.04.2015 01:19+2Хм, странно. Мне казалось, что такой вопрос уже был, но оказывается, это был не вопрос.
IlyaEvseev
09.04.2015 00:29В качестве CDN для статических данных рассматривались варианты с CloudFlare и Яндекс.Диском?
cackle Автор
09.04.2015 23:09+1Про Яндекс ничего не слышали, а вот CloudFlare конечно, но там такие цены… уже лучше свой сделать.
IlyaEvseev
10.04.2015 01:111) У Cloudflare первые три тарифа стоят 0, 20 и 200 долларов за сайт, т.е. более чем умеренно.
Кэширование статики доступно даже на бесплатном.
2) «Про Яндекс ничего не слышали» — это Вы про Яндекс вообще, или только про Яндекс.Диск???
Слышать тут нечего — заходите на disk.yandex.ru, размещаете на нём статический контент, веб-ссылки на него вставляете в динамический, который раздаёте сами. Дальше забота Яндекса, чтобы доставить клиенту статику с максимальной надёжностью за минимальное время.cackle Автор
10.04.2015 01:38+1Конечно, про Диск =)
ИМХО, но думаю у Яндекс.Диска есть лимиты по скорости (они вообще-то везде есть) так как bandwidth везде платный. Думаю для продакшена это плохое решение )
cackle Автор
10.04.2015 01:51+11) У нас был опыт переговоров с компаниями предоставляющими CDN, их тарифы только для самих сайтов, не предоставляющих внешние (embedded) решения для других порталов.
Например вот это $200 per month for each website, означает, что статика будет доступна только для запросов с referer-ом самого сайта, а если вы виджет используете, то это уже 2й сайт, а у нас 34 000 сайтов =))
IlyaEvseev
10.04.2015 01:17Кстати, это случайно не то, что вам нужно?
habrahabr.ru/company/yandex/blog/255357

biomancer
09.04.2015 01:18+1Хотел написать про директиву proxy_cache_methods, которую можно использовать вместо условия с проверкой методов, но потом понял идею с кукой и сбросом кеша для тех, кто что-то запостил, красивое решение.
bRUtality
09.04.2015 08:57Вы пишите о нерешенной проблеме с размером БД. Можно поинтересоваться, о каких объемах речь и что было сделано в плане тюнинга?
cackle Автор
09.04.2015 23:12+1Сейчас поводов для беспокойства пока нет, база растет примерно на 2-3Гб в месяц, так что пока только выбираем правильное решение. Склоняемся к разработке своего функционала.

afiskon
09.04.2015 11:42+2Большое спасибо за интересную статью!
Касательно ручного шардинга PostgreSQL. Судя по отзывам, неплохо работает схема вроде следующей.
Определяете, по какому ключу шардите. Например, это id пользователя. Заводите множество небольших БД, каждая, например, ровно на 1000 пользователей. База 1 держит пользователей 1-1000, база 2 — пользователей 1001-2000 и так далее. Если в БД уже есть 1000 пользователей, заводите новую. Один сервер PostgreSQL держит несколько баз, в зависимости от крутости железа и числа запросов к этим БД. Если нагрузку сервер больше не держит, заводите новый сервер. При обновлении сервера в поднятый на нем PostgreSQL можно перенести бОльшее число баз. Для определения какая БД на каком сервере лежит используется «словарь» который можно держать, скажем, в Redis.
Остается проблема распределенных транзакций, если приложению нужно передавать что-то между пользователями живущими в разных БД. Почти рабочее решение описано в этой статье (в описанном там чтении нет изолированности, решается выполнением транзакции на запись тех же значений, что считали). Альтернативный вариант, более колхозный, описан здесь. Кто-то предпочитает 2PC, но он его сложно реализовать, чтобы он работал при падении узлов или клиента, выполняющего транзакцию, нужно какой-то Raft/Paxos еще прикручивать.
С удовольствием прочитал бы другие заметки о том, как у вас все устроено. Интересуют вопросы из этого списка, например, вы совсем не рассказали про ваши метрики, мониторинг и агрегацию логов.cackle Автор
09.04.2015 23:17+1Спасибо!
>метрики, мониторинг и агрегацию логов
Это все делаем вручную, к сожалению, то есть надо что-то проанализировать, лог например, пишем свой парсер, мониторинг примерно так же устроен.
Проблема в том, что стандартные решения, при наших нагрузках, например мониторинг Tomcat-а, уронят нам всю систему =)
stardust_kid
09.04.2015 15:34-3Несколько раз хотел ваши комменты использовать, но меня останавливал мерзкий дизайн. Неужели трудно сделать как у Disqus или Hypercomments?
cackle Автор
09.04.2015 23:26+1Не знаю, чем вам так дизайн Cackle не угодил.
Сверху Cackle, снизу Hypercomments — найдите хотя бы 1 преимущество последних ;)

Hacker13ua
09.04.2015 15:58+2Единственный нюанс — это большие модификации базы (ALTER TABLE) при релизах. Делать их надо кусками, стараясь не выполнять за раз весь UPDATE.
А не пробовали использовать replication slot?
vilgelm-hero
10.04.2015 00:52Меня как потенциального пользователя продуктов отталкивает две вещи:
1. Убогий дизайн продуктов. Даже если вдруг у вас есть возможность сверстать свой дизайн я хотел бы видеть «все красиво» из коробки, тот же Jivosite гораздо лучше в этом плане (хотя раньше он здорово отставал в этом вопросе). Siteheart тоже ничего.
Сюда же можно включить откровенно слабый дизайн офсайта (привет, бутстрап) и жуткий лого.
2. Название компании. В качестве примера — некоторые компании со звучными названиями типа «хуньсуй» в Россию приходят с адаптированным потребителю названием. Как и наоборот Mail.ru на американском рынке My.com. У вас же компания, насколько показало 20-секундное изучение вашего сайта — русская и выходить с названием «какл» на мой взгляд не очень удачно. Даже несмотря на то, что я какое-то время пользовался потребпродукцией Хуавей (пользовательский опыт, в общем-то, совпадает с названием).
Итого: возможно, хорошие продукты, интересный рассказ по серверной части, но пока все будет оставаться так, как есть сейчас — попыток пользоваться вашей продукцией я предпринимать не буду.
На мой вкус, тут требуется вмешательство маркетологов и ребрендинг. Надеюсь, мой комментарий поможет вам стать лучше.vilgelm-hero
10.04.2015 00:57Ну и еще мелочи —

Каким образом стало возможно проставлять количество в нулях, а главное — зачем?
Минимальный объем заказываемой услуги никак не может быть меньше 1.
cackle Автор
10.04.2015 02:01+2Спасибо за объемный комментарий. От части вы правы, НО…
Название, дизайн сайта, маркетинг — это не сделает наших клиентов счастливыми. А вот подъем конверсии их сайта, за счет наших сервисов, вполне себе осчастливит любого. Это мы и делаем, мы создаем системы, чтобы помогать людям!
Например, сравните хотя бы нашу систему сбора отзывов Cackle Reviews с подобными, разрекламированными, из рунета, и вы поймете о чем я ;)TimReset
10.04.2015 11:05оффтоп: В комментариях уже несколько раз упоминалось неблагозвучное название. А как вообще правильно произносить название Вашей компании? Не могли бы Вы по русски его написать?
vilgelm-hero
10.04.2015 11:57Вы игнорируете написанное мной?
Я написал, что мне, как клиенту — не нравится дизайн в первую очередь продукта (онлайн-консультант), а не сайта.
С системой отзывов все то же — у нее проблемы с юзабилити, в отличие от того же Hypercomments.cackle Автор
10.04.2015 13:43Будут очень благодарен, если услышу от вас хотя бы 3-4 проблемы юзабилити системы комментариев (в отличие от того же Hypercomments). Можете кстати их написать на support@cackle.me.
vilgelm-hero
10.04.2015 21:03Вы все время уходите от вопроса дизайна основных продуктов, например, того же виджета Онлайн-консультанта.
А скриншот сравнения Hypercomments и вашего виджета консультирования приведен выше, любой юзабилист скажет что в нем можно изменить, дабы он не смотрелся как поделка 2005х годов.
Для начала обратите внимание на обводку иконок, их количество и шрифты.alexeydenisov
11.04.2015 09:16+1>Для начала обратите внимание на обводку иконок, их количество и шрифты.
1) Кол-во провайдеров(если вы про них) клиент выбирает в настройках
2) Дизайн любого элемента виджета (в том числе шрифты, обводка) может быть определен через Редактор стиля(выбрать элемент, а затем свойства).

Также дизайн может быть переопределен через стили на сайте путём прописывания более глубоких селекторов и директивы !important.
3) Если этого недостаточно, то через api есть возможность определить html шаблонvilgelm-hero
11.04.2015 12:08-1А еще можно купить Жигули, поставить двигатель от Мерседеса…
Я, как среднестатистический клиент, хочу видеть «красиво» из коробки, а не менять дизайн и подключать по API. Обратите внимание, я уже указывал это в комментарии выше.
Если конкуренты уже предоставляют мне консультанта в симпатичной обертке, зачем мне Какл?
Но, я так чувствую — тут бесполезно что-то доказывать, поскольку мое мнение никого не интересует.alexeydenisov
11.04.2015 14:01+3На вкус и цвет, как говорится…
Именно поэтому у нас сотни различных настроек и возможностей API, которые кстати и появились именно из потребностей наших клиентов — максимально подогнать наши решения под свой сайт. Темы постоянно обновляются, и мы внимательно слушаем различные предложения и вас услышали и подумаем, что можно улучшить.
Не нравится дизайн Cackle и не хотите ничего подстраивать под свой сайт, и знаете что есть подходящие решения — так и используйте их. Или с этим какие-то проблемы?

dougrinch
12.04.2015 03:41+5Вынужден признать, что название выбрано действительно удачно. Посту уже 5 дней, а я все никак не могу выкинуть из головы этот какл.

r0zh0k
14.04.2015 11:03Почему какл если кейкл?:)
TimReset
14.04.2015 11:29Не факт — вот на мой комментарий о правильном произношении ( habrahabr.ru/company/cackle/blog/255013/#comment_8370875 ) представители компании не ответили :)

iZENfire
14.04.2015 18:04Почему используется Debian, а не FreeBSD?

xorax
15.04.2015 00:57потому что KDE пропачить не смогли?
cackle Автор
15.04.2015 01:23+1KDE? На сервере??
Хороший троллинг! =)xorax
15.04.2015 01:28+2Я страшно извиняюсь, если неправильно понял, но мне показалось, что вы не в курсе…
DjOnline
16.04.2015 15:26+1В те года идея таких стартапов витала в воздухе, появились, вы, Disqus, hypercomments.
Но многих останавливали правовые вопросы.
Представьте, что прошёлся бот по всем сайтам и оставил разные запрещённые комментарии, которые так не любит роскомнадзор. Или банально ссылка на бесплатную mp3. Обязательную модерацию не все осилят, вовремя удалить комментарий — тоже. В этом случае есть опасность блокировки и ресурса, где размещен комментарий, и вашего ресурса как технологической платформы?
Прост я с таким сталкивался, видел предписание прокуратуры, и блокировку сервера датацентром, даже за простую ссылку на mp3 (то что можно яндексу/гуглу, нельзя простым людям).cackle Автор
16.04.2015 16:01+1Хороший вопрос!
Мы на практике с этим начали сталкиваться примерно года 2 назад. В каждом случае, Роскомнадзор сначала оповещает сайт, что вот на этой странице есть у вас вот такой комментарий, надо его убрать. Блокировок пока ни разу не видели, но если бы они и были, то естественно затронули бы сам сайт клиента, а не нашу систему.
Кстати мы даже добавили причину бана (удаления) — «Не соответствует требованию Роскомнадзора» :)

yetanothercoder
21.04.2015 11:36+1почему tomcat а не netty если у вас такие высокие нагрузки?
cackle Автор
21.04.2015 14:02+1В интернете очень много статей на счет сравнения производительности Tomcat и Netty, дак вот на больших нагрузках последний начинает вести себя гораздо хуже. Tomcat проверенное «production-ready» решение, советую именно его.
yetanothercoder
21.04.2015 16:25впервый раз слышу, можно какое нибудь такое сравнение где на больших нагрузках томкат уделыват нетти?
также очевидно что в нетте доступны для тюнинга многие низкоуровневые tcp/http вещи, в томкате кроме пула потоков и таймаутов что тюнить можно?cackle Автор
21.04.2015 18:54Если я не ошибаюсь, эти низкоуровневые фичи в основном нужны для быстрой отдачи статики, а у нас для этого Nginx, Tomcat используется только для бизнес уровня.
TimReset
21.04.2015 11:42+1В статье написано, что используется WebSocket, как один из возможных средств доставки сообщений клиенту, Tomcat, как servlet контейнер. А как Вы web socket в Tomcat реализовывали? С помощью Tomcat-зависимых «штук»? А то, насколько я знаю, в Java пока ещё нет стандарта на WebSocket.
cackle Автор
21.04.2015 14:12+1Конечно нет, при таких нагрузка Tomcat ну никак нельзя соединять с Real-time.
Мы используем github.com/wandenberg/nginx-push-stream-module, если интересно, то вот об этом подробнее habrahabr.ru/company/cackle/blog/167895. Tomcat просто оповещает сервер Nginx с данным модулем асинхронным POST сообщением о новом событии (публикация комментария, отзыва, сообщение, редактирование, голосование и т.д.).
PS: И вообще-то в Tomcat-е есть WebSocket на 7ке с подключенным jdk7, мы используем 6 и при старте каждый раз вот такое сообщение получаем:
INFO: JSR 356 WebSocket (Java WebSocket 1.0) support is not available when running on Java 6. To suppress this message, run Tomcat on Java 7, remove the WebSocket JARs from $CATALINA_HOME/lib or add the WebSocketJARs to the tomcat.util.scan.DefaultJarScanner.jarsToSkip property in $CATALINA_BASE/conf/catalina.properties. Note that the deprecated Tomcat 7 WebSocket API will be available.
Finom
*шутка о названии*