

Скачать ее можно перейдя по ссылке, данная база является открытой и содержит все адреса объектов по России (адресный реестр). Интерес к этой базе вызван тем, что файлы, которые в ней содержатся достаточно объемны. Так, например, самый маленький составляет 2,9 Гб. Предлагается остановиться на нем и посмотреть, справится ли с ним pandas, если работать на машине, располагая только 8 Гб оперативной памяти. А если не справится, какие есть опции, для того, чтобы скормить pandas данный файл.
Положа руку на сердце, не разу не сталкивался с данной базой и это дополнительное препятствие, т.к. абсолютно не ясен формат данных, представленных в ней.
Скачав архив fias_xml.rar с базой, достанем из него файл — AS_ADDROBJ_20190915_9b13b2a6-b3bd-4866-bd1c-7ab966fafcf0.XML. Файл имеем формат xml.
Для более удобной работы в pandas рекомендуется конвертировать xml в csv или json.
Однако все попытки конвертации сторонними программами и самим python приводят к ошибке «MemoryError» либо зависанию.
Хм. Что, если разрезать файл и частями конвертировать? Хорошая идея, но все «резчики» также пытаются считать файл в память целиком и виснут, не режет его и сам python, идущий по пути «резчиков». 8 Гб явно маловато? Что ж, посмотрим.
Программа Vedit
Придется воспользоваться сторонней программой vedit.
Данная программа позволяет считать файл xml размером 2,9 Гб и поработать с ним.
Также она позволяет его разделить. Но тут есть небольшая хитрость.
Как видно при считывании файла, в нем, помимо прочего, есть открывающий тег AddressObjects:

Значит, создавая части данного большого файла, надо не забывать его(тег) закрывать.
То есть начало каждого xml файла будет таким:
<?xml version="1.0" encoding="utf-8"?><AddressObjects>
а окончание:
</AddressObjects>
Теперь отрежем первую часть файла (для остальных частей шаги те же).
В программе vedit:
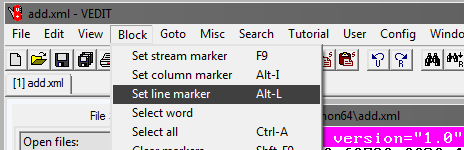
Далее выбираем Goto и Line#. В открывшемся окне пишем номер строки, например 1000000:

Далее надо подкорректировать выделенный блок, чтобы он захватил до конца объект в базе до закрывающего тега:
Ничего страшного, если будет небольшой нахлест на последующий объект.
Далее в программе vedit сохраняем выделенный фрагмент — File, Save as.
Таким же способом создаем остальные части файла, помечая начало блока выделения и окончание с шагом 1млн строк.
В итоге должно получиться 4-е xml файла размером примерно по 610 Мб.
Доработаем xml-части
Теперь надо во вновь созданных файлах xml добавить теги, чтобы они читались как xml.
Откроем поочередно файлы в vedit и добавим в начале каждого файла:
<?xml version="1.0" encoding="utf-8"?><AddressObjects>
и в конце:
</AddressObjects>
Таким образом, теперь у нас 4 xml части разделенного первоначального файла.
Xml-to-csv
Теперь переведем xml в csv, написав программу на python.
Код программы
# -*- coding: utf-8 -*-
from __future__ import unicode_literals
import codecs,os
import xml.etree.ElementTree as ET
import csv
from datetime import datetime
parser = ET.XMLParser(encoding="utf-8")
tree = ET.parse("add-30-40.xml",parser=parser)
root = tree.getroot()
Resident_data = open('fias-30-40.csv', 'w',encoding='UTF8')
csvwriter = csv.writer(Resident_data)
start = datetime.now()
for member in root.findall('Object'):
object = []
object.append(member.attrib['AOID'])
object.append(member.attrib['AOGUID'])
try:
object.append(member.attrib['PARENTGUID'])
except:
object.append(None)
try:
object.append(member.attrib['PREVID'])
except:
object.append(None)
#try:
# object.append(member.attrib['NEXTID'])
#except:
# object.append(None)
object.append(member.attrib['FORMALNAME'])
object.append(member.attrib['OFFNAME'])
object.append(member.attrib['SHORTNAME'])
object.append(member.attrib['AOLEVEL'])
object.append(member.attrib['REGIONCODE'])
object.append(member.attrib['AREACODE'])
object.append(member.attrib['AUTOCODE'])
object.append(member.attrib['CITYCODE'])
object.append(member.attrib['CTARCODE'])
object.append(member.attrib['PLACECODE'])
object.append(member.attrib['STREETCODE'])
object.append(member.attrib['EXTRCODE'])
object.append(member.attrib['SEXTCODE'])
try:
object.append(member.attrib['PLAINCODE'])
except:
object.append(None)
try:
object.append(member.attrib['CODE'])
except:
object.append(None)
object.append(member.attrib['CURRSTATUS'])
object.append(member.attrib['ACTSTATUS'])
object.append(member.attrib['LIVESTATUS'])
object.append(member.attrib['CENTSTATUS'])
object.append(member.attrib['OPERSTATUS'])
try:
object.append(member.attrib['IFNSFL'])
except:
object.append(None)
try:
object.append(member.attrib['IFNSUL'])
except:
object.append(None)
try:
object.append(member.attrib['OKATO'])
except:
object.append(None)
try:
object.append(member.attrib['OKTMO'])
except:
object.append(None)
try:
object.append(member.attrib['POSTALCODE'])
except:
object.append(None)
#print(len(object))
csvwriter.writerow(object)
Resident_data.close()
print(datetime.now()- start)
#0:00:21.122437С помощью программы надо конвертировать все 4-е файла в csv.
Размер файлов уменьшится, каждый будет по 236 Мб (сравните с 610 Мб в xml).
В принципе, теперь с ними уже можно работать, через excel или notepad++.
Однако файлов пока 4-е вместо одного, и мы не добрались до цели — обработка файла в pandas.
Склеим файлы в один
В Windows это может оказаться непростым занятием, поэтому воспользуемся консольной утилитой на python, которая называется csvkit. Устанавливается как модуль python:
pip install csvkit*На самом деле это целый набор утилит, но оттуда потребуется одна.
Зайдя в папку с файлами для склейки в консоли, выполним склейку в один файл. Так как все файлы без заголовков, то назначим при склейке стандартные названия столбцов: a,b,c и т.д.:
csvstack -H fias-0-10.csv fias-10-20.csv fias-20-30.csv fias-30-40.csv > joined2.csvНа выходе получаем готовый csv файл.
Поработаем в pandas над оптимизацией использования памяти
Если сразу загрузить в pandas файл
import pandas as pd
import numpy as np
gl = pd.read_csv('joined2.csv',encoding='ANSI',index_col='a')
print (gl.info(memory_usage='deep')) # использование памяти
def mem_usage(pandas_obj):
if isinstance(pandas_obj,pd.DataFrame):
usage_b = pandas_obj.memory_usage(deep=True).sum()
else: # предположим, что если это не датафрейм, то серия
usage_b = pandas_obj.memory_usage(deep=True)
usage_mb = usage_b / 1024 ** 2 # преобразуем байты в мегабайты
return "{:03.2f} МВ" .format(usage_mb)
и проверить сколько он займет памяти, результат может неприятно удивить:

3 Гб! И это при том, что при считывании данных первый столбец «пошел» в качестве индекс-столбца*, а так объем был бы еще больше.
*По умолчанию pandas задает свой индекс-столбец.
Проведем оптимизацию, используя методы из предыдущего поста и статьи:
— object в category;
— int64 в uint8;
— float64 в float32.
Для этого при считывании файла добавим dtypes и считывание столбцов в коде будет выглядеть так:
gl = pd.read_csv('joined2.csv',encoding='ANSI',index_col='a', dtype ={
'b':'category', 'c':'category','d':'category','e':'category',
'f':'category','g':'category',
'h':'uint8','i':'uint8','j':'uint8',
'k':'uint8','l':'uint8','m':'uint8','n':'uint16',
'o':'uint8','p':'uint8','q':'uint8','t':'uint8',
'u':'uint8','v':'uint8','w':'uint8','x':'uint8',
'r':'float32','s':'float32',
'y':'float32','z':'float32','aa':'float32','bb':'float32',
'cc':'float32'
})
Теперь, открыв файл pandas использование памяти будет разумным:

Осталось добавить в csv файл, при желании, строку-фактические названия столбцов, чтобы данные обрели смысл:
AOID,AOGUID,PARENTGUID,PREVID,FORMALNAME,OFFNAME,SHORTNAME,AOLEVEL,REGIONCODE,AREACODE,AUTOCODE,CITYCODE,CTARCODE,PLACECODE,STREETCODE,EXTRCODE,SEXTCODE,PLAINCODE,CODE,CURRSTATUS,ACTSTATUS,LIVESTATUS,CENTSTATUS,OPERSTATUS,IFNSFL,IFNSUL,OKATO,OKTMO,POSTALCODE*Этой строкой можно заменить названия столбцов, но тогда придется поменять код.
Сохраним первые строки файла из pandas
gl.head().to_csv('out.csv', encoding='ANSI',index_label='a')
и посмотрим, что получилось в excel:

Код программы для оптимизированного открытия csv файла с базой:
import os
import time
import pandas as pd
import numpy as np
#используем оптимизацию памяти при считывании датафрейма: для object-category,для float64-float32,для int64-int
gl = pd.read_csv('joined2.csv',encoding='ANSI',index_col='a', dtype ={
'b':'category', 'c':'category','d':'category','e':'category',
'f':'category','g':'category',
'h':'uint8','i':'uint8','j':'uint8',
'k':'uint8','l':'uint8','m':'uint8','n':'uint16',
'o':'uint8','p':'uint8','q':'uint8','t':'uint8',
'u':'uint8','v':'uint8','w':'uint8','x':'uint8',
'r':'float32','s':'float32',
'y':'float32','z':'float32','aa':'float32','bb':'float32',
'cc':'float32'
})
pd.set_option('display.notebook_repr_html', False)
pd.set_option('display.max_columns', 8)
pd.set_option('display.max_rows', 10)
pd.set_option('display.width', 80)
#print (gl.head())
print (gl.info(memory_usage='deep')) # использование памяти
def mem_usage(pandas_obj):
if isinstance(pandas_obj,pd.DataFrame):
usage_b = pandas_obj.memory_usage(deep=True).sum()
else: # предположим, что если это не датафрейм, то серия
usage_b = pandas_obj.memory_usage(deep=True)
usage_mb = usage_b / 1024 ** 2 # преобразуем байты в мегабайты
return "{:03.2f} МВ" .format(usage_mb)В завершение посмотрим размер датасета:
gl.shape(3348644, 28)3,3 млн строк, 28 столбцов.
Итог: при первоначальном объеме файла csv 890 Мб, «оптимизированный» для целей работы с pandas он занимает в памяти 1,2 Гб.
Таким образом, при грубом расчете можно предположить что файл размером 7,69 Гб можно будет открыть в pandas, предварительно его «оптимизировав».
Комментарии (30)

semindm
24.09.2019 14:40+1чтобы обработать xml большого размера, совсем необязательно загружать его в память или пользоваться сторонними приложениями. мне тоже довелось работать с ФИАС, и я читал данные из файла XmlReader'ом (.net).
Примерно так:
var reader = XmlReader.Create(xml); while (!reader.EOF) { reader.Read(); ... }
В Python нет чего-то похожего?vpiskunov
24.09.2019 14:48Когда читаешь подобный заголовок, надеешься, что будет что-то типа lxml.de/parsing.html#iterparse-and-iterwalk а тут XML2CSV и нет ответа как работать с большими XML при маленьком количестве оперативки. Это что, сезон курсовых на хабре опять? до нового года еще далеко.
Извините за снобизм
zoldaten Автор
24.09.2019 15:15Так файл не парсится целиком. Поэтому путь через разбиение и конвертацию.
Кроме того, после нее размеры файлов уменьшаются в разы.TheGodfather
24.09.2019 15:25Ну так вам и говорят, что это ручное разбиение и конвертация — это костыль, а не нормальное взрослое решение :) Вот для файла в всего 3 Гб работает, а что вы будете делать с файлом в 30 Гб? Файл и не надо парсить целиком, вон же ссылка выше про парсинг по частям (если структура позволяет).
zoldaten Автор
24.09.2019 15:30Тогда тем более не ясна ваша ссылка на итераторы.

trapwalker
24.09.2019 16:43Для этого много лет назад придумали SAX-парсеры.
Можно читать XML не превращая его в объектную модель в памяти, а держать лишь маленький контекст, соответствующий максимум одной записи.
SAX-парсер устроен так, что в нём описывается код реакции на каждый элемент XML. Причем отдельно описывается реакция на открытие и закрытие каждого тега. Так на закрытие тега поля можно сохранять значение поля в буфферный словарик под соответствующим ключем, а на закрытие тега записи сохранять накопившийся словарик в CSV-файл в потоковом режиме дописывая в него строчку.
Так и террабайтные xml можно без мороки обрабатывать, лишь бы одна максимальная его запись в память помещалась. Думаю на гитхабе готовых SAX XML to CSV конвертеров валом. Ну или стоит сделать, если нет (хотя я сильно удивлюсь). Думаю код поместится на полтора экрана со всеми обработками ошибок и CLI.sshikov
24.09.2019 19:35Ну, ради объективности, это ФИАС такой простой, что у него одна запись. У меня были случаи, когда нужно было парсить 8 гигабайт, при этом данные размазаны по иерархии XML. Так что я вынужден был держать верхние уровни в памяти тоже, да и конкретно SAX при этом большого удовольствия не доставляет.
P.S. Отдельный вопрос — почему бы не прочитать ФИАС в формате .dbf, где такой проблемы вообще не существует как класса.trapwalker
24.09.2019 22:15На счёт дбф я даже не стал упоминать ввиду очевидности. А где 8 гигов, там и 28. Никакой памяти не напасешься, так что конвертить тем же саксом во что-то удобоваримое типа набора быстрых key-value коллекций на диске или реляционной бд или той же монги и работать уже с этим. Да, метод "сакс", но как иначе построить масштабируемое решение?
sshikov
24.09.2019 22:27Очевидно что принципиально больше никак. И против решения ничего не имею, это было лишь небольшое уточнение. Впрочем, как вариант могу предложить что-то вроде этого:
jawher.wordpress.com/2011/02/28/introducing-immanix-java-library-process-xml-using-parser-combinators
Я пользовался, в том числе для разбора 8 гиговых xml. По сравнению с голым SAX — чуть удобнее, примерно при тех же ресурсах.
А упоминание про .dbf… ну не знаю, я как-то запросил у смежной команды периодически импортировать к нам OpenStreetMap. При этом явно написал — берите pbf. Потому что содержимое идентично, а размеры в разы меньше. И что бы вы думали — в итоге реализовали импорт из xml. Считайте, что это была агитация за то, чтобы рассмотреть все варианты :)
MonkAlex
24.09.2019 16:00Аналогично, парсил ФИАС используя простую конструкцию
Почти не требует памяти (Мне хватало 128мб, с учетом того что в памяти хранились все нужные объекты, но я только до городов сверху вниз парсил), работает довольно шустро.using (var xmlReader = new XmlTextReader(file)) { while (xmlReader.Read()) { if (xmlReader.Name != "Object") continue; var address = XElement.Load(xmlReader.ReadSubtree()); ... } }
vvm13
24.09.2019 14:41Неохота читать Python-код (не мой язык), но у SAX-парсера (в отличие от DOM-парсера) не должно быть таких проблем с памятью, чтобы XML-файл предварительно приходилось бы делить.
remzalp
24.09.2019 15:10+1Ага…
героически игнорируем гениальный по экономичности подход SAX парсеров
сохраняем руками в четыре файла (open, seek, read/write уж на крайний случай)
используем замечательный инструмент (спасибо за явную конверсию типов, раньше не обращал внимание),
но для чего? Переименовать столбцы и сохранить в итоговый файл?zoldaten Автор
24.09.2019 15:25-1Изложите ваш подход? Опыт бесценен.
remzalp
24.09.2019 15:30habr.com/ru/post/171447
уже есть вполне готовый пример. Или интересует именно ФИАС, питоном и пачкой зараз?
Но смысл? В чем сверхзадача?
Получить данные — это один промежуточный процесс, потом с ними надо что-то сделать полезное.zoldaten Автор
24.09.2019 15:37Сверхзадача — выяснить как чувствует себя pandas при малых объемах памяти и большим датасетом, если ли предел модуля. Какова скорость работы на сверхбольших данных.
Странно, что все смотрят только в сторону конвертации xml-csv.remzalp
24.09.2019 15:46Учитывая, что внутри прячется numpy, то ответ довольно предсказуемый.
Немного лучше, чем нативный код на питоне.
www.draketo.de/english/python-memory-numpy-list-array
В любом случае Pandas пока что хранит данные в оперативной памяти, так что всё плохо и будет потихоньку выпадать в своп при превышении
RatWar
24.09.2019 15:18В Винде со времен XP есть xmllite.dll это SAX-парсер, помню как-то давно на Дельфи с ее помощью ФИАС в свою базу заливал.
Delphi 7 (1 ГБ ОЗУ) в MSSQL 2005

BEERsk
24.09.2019 17:52Делал похожую задачу, тоже связанную с ФНС (данные о среднесписочном составе — представляют собой огромное кол-во XML — файлов. Требовалось привести их к виду, привычному для юристов — электронной таблице Excel, т.е. много мелких XML файлов объединить в одну или несколько таблиц Excel) с помощью XSLT -преобразования. Реализовал с помощью программы xsltproc пакета libxslt (в archlinux, в других дистрах может по другому). Самым сложным было сочинить XSL-фильтр, через который прогонялся XML-файл, т.к. довольно редко приходится работать с данными в XML, но хотелось сделать красиво.
sshikov
24.09.2019 19:37Много мелких файлов и один большой файл — это две совершенно непохожие задачи. Особенно в свете xslt, которому нужна вся модель документа в памяти.
BEERsk
25.09.2019 09:06Наверное, всё-таки похожие, поскольку я не думаю что XSLT-фильтр сначала целиком прочитывает весь файл в память, а потом разбирает его. Я склонен к тому что он делает это порциями, по мере чтения файла. Но на 100% пока не уверен, т.к. сам лично не проверял.
sshikov
25.09.2019 20:33>Наверное, всё-таки похожие, поскольку я не думаю что XSLT-фильтр сначала целиком прочитывает весь файл в память, а потом разбирает его.
Ага, ага. Только если у вас XSLT 3.0, в чем я сильно сомневаюсь.
dem0n3d
25.09.2019 17:38Специальная утилита для склеивания CSV-файлов. Серьёзно?
zoldaten Автор
25.09.2019 17:49Если вы это в сети нашли:
copy *.csv big.csv, то там названия столбцов не задаются при склейке.
knagaev
25.09.2019 17:58Вы можете сделать первый файл с названиями столбцов
copy header.csv + 1.csv + 2.csv +… big.csv
dem0n3d
25.09.2019 18:04Это вы про a,b,c т.д.? Да, это большая потеря.
А имя файла в tree = ET.parse("add-30-40.xml",parser=parser) вы вручную каждый раз подставляли? Нельзя было просто циклом пройтись сразу по всем XML-файлам и записать разом в один CSV файл?
Кстати, заголовок в CSV вообще не обязателен (в т.ч. для pandas).zoldaten Автор
25.09.2019 18:14Нельзя было просто циклом пройтись сразу по всем XML-файлам и записать разом в один CSV файл?
С адресным реестром (база из статьи) это возможно. А вот с «домами» — база из архива на 29 Гб уже нет, так как база битая — некоторые теги не закрыты, поэтому парсер вылетает.
*Из 119 чанок по 220 Мб, только половина парсится без проблем.
Кроме того, не ясна структура, а большой файл после создания не открыть для уточнения.
Кстати, заголовок в CSV вообще не обязателен (в т.ч. для pandas).
Все верно. Эти названия необходимы для ориентации в датасете.
trolley813
python xml splitterвыдает вот это. Если почитать код, понятно, что считывается в память и парсится оно чанками, а не все сразу. (Понятно, что наверняка есть еще куча других "резчиков", которые делают то же самое.)zoldaten Автор
1. Очень помогло. Доработал код по вашей ссылке под python 3 и русские символы, которые он не читал — код.
Синтаксис сохранен:
2.Да, это вынужденная мера, чтобы освободить память. По значениям, которые встречаются в столбцах, это допустимо.
ps. vedit -30 дней бесплатно.
trolley813
Спасибо! Если не сложно, выложите на Github, пожалуйста (как-то не очень комильфо хранить исходники на Яндекс.Диске, плюс вдруг кто-нибудь еще захочет доработать).
zoldaten Автор
Не пользуюсь гитхабом, несмотря на всю его привлекательность.