
В прошлой статье мы выяснили, что кэш — это безусловно полезная штука, но применительно к контроллерной логике он иногда создаёт трудности. В частности, он вносит непредсказуемость длительности импульсов либо иных задержек при программном формировании временных диаграмм. Ну, и в «общепрограммистском» плане, неудачное расположение функции может свести выигрыш от кэша на нет, постоянно провоцируя его перезагрузку из медленной памяти. Я упоминал, что 15 лет назад мы вынуждены были делать специальный препроцессор, который устранял возникающие проблемы для процессора SPARC-8, и обещал, что расскажу, как легко устранить подобные трудности при разработке для синтезированного процессора Nios II, рекомендуемого для использования в комплексе Redd. Пришла пора выполнить обещание.

Сегодня нашей настольной книгой будет документ Embedded Design Handbook, а точнее — его раздел 7.5. Using Tightly Coupled Memory with the Nios II Processor Tutorial. Раздел сам по себе колоритный. Сегодня мы проектируем процессорные системы для ПЛИС Intel в программе Platform Designer. Во времена Altera, она называлась QSys (отсюда расширение .qsys у файла проекта). Но до появления QSsys, все пользовались её предком, SOPC Builder (в память о котором осталось расширение файла .sopcinfo). Так вот, хоть документ и отмаркирован логотипом Intel, но рисунки в нём являются скриншотами из этого SOPC Builder. Он явно написан более десяти лет назад, и с тех пор в нём правились только термины. Правда, тексты вполне современные, поэтому в качестве методички этот документ вполне пригодится.
Итак. Мы хотим добавить в нашу спартанскую процессорную систему память, которая никогда не кэшируется и при этом работает на максимально возможной скорости. Разумеется, это будет встроенная память ПЛИС. Мы добавим память как для кода, так и для данных, но это будут разные блоки. Начнём с памяти для данных, как наиболее простой. Добавляем уже известную нам OnChip Memory в систему.
Ну, скажем, пусть её объём будет 2 килобайта (главная проблема встроенной памяти ПЛИС в том, что её мало, так что приходится экономить). В остальном — обычная память, какую мы уже добавляли.

Но подключать мы её будем не к шине данных, а к особой шине. Чтобы она появилась, входим в свойства процессора, идём на вкладку Caches and Memory Interfaces и в списке выбора Number of tightly coulped data master ports выбираем значение 1.
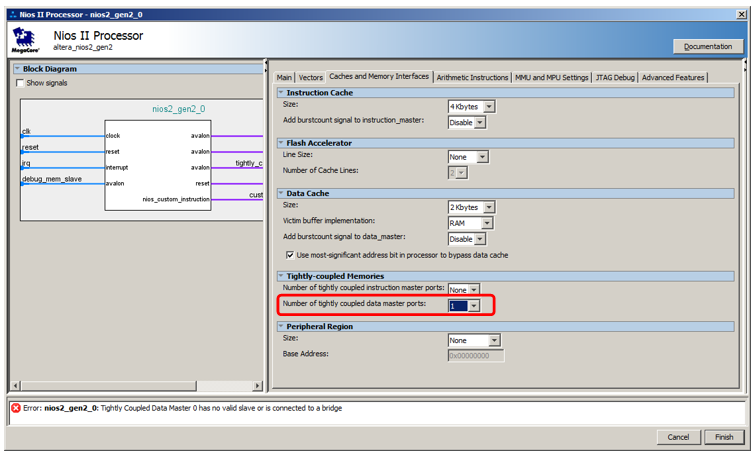
Вот такой новый порт появился у процессора:

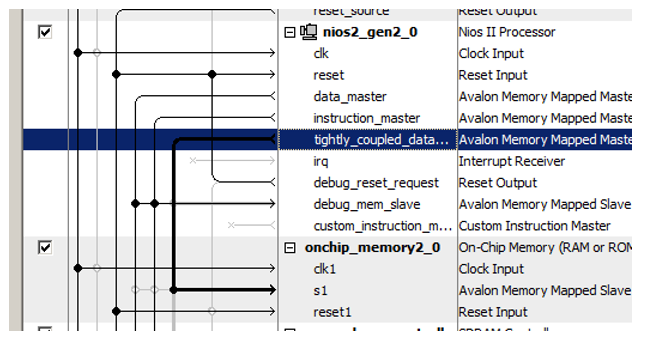
Недавно добавленный блок памяти подключаем именно к нему!
Ещё одна хитрость — в назначении адресов этой новой памяти. В документе есть длинная цепочка рассуждений про оптимальность декодирования адреса. Там утверждается, что некэшируемая память должна отличаться от всех остальных видов памяти чётко выраженным одним битом адреса. Поэтому в документе вся некэшируемая память относится к диапазону 0x2XXXXXXX. Так что впишем вручную адрес 0x2000000 и запрём его на замок, чтобы при следующих автоматических назначениях он не изменялся.

Ну, и чисто для эстетики, переименуем блок… Назовём его, скажем, NonCachedData.

С аппаратурой для некэшируемой памяти данных всё. Переходим к памяти для хранения кода. Здесь всё почти так же, но чуть-чуть сложнее. На самом деле, всё можно сделать полностью идентично, только ведущий порт шины открывается в списке Number of tightly coulped instruction master ports, однако отлаживать такую систему будет невозможно. При заливке программы средствами отладчика, она вливается туда через шину данных. При остановке, дизассемблируемый код считывается отладчиком также через шину данных. И даже если программа загружается из внешнего загрузчика (мы такой метод ещё не рассматривали, тем более, что в бесплатной версии среды разработки мы обязаны работать только при подключённом JTAG отладчике, но в целом, никто так делать не запрещает), заливка также идёт через шину данных. Поэтому память придётся делать двухпортовой. К одному порту подключать некэшируемый мастер инструкций, который работает в основное время, а к другому — вспомогательную штатную шину данных. Она будет использоваться для загрузки программы извне, а также для получения содержимого ОЗУ отладчиком. В остальное время эта шина будет простаивать. Вот так всё это выглядит в теоретической части документа:

Процессору добавим некэшируемый порт инструкций:

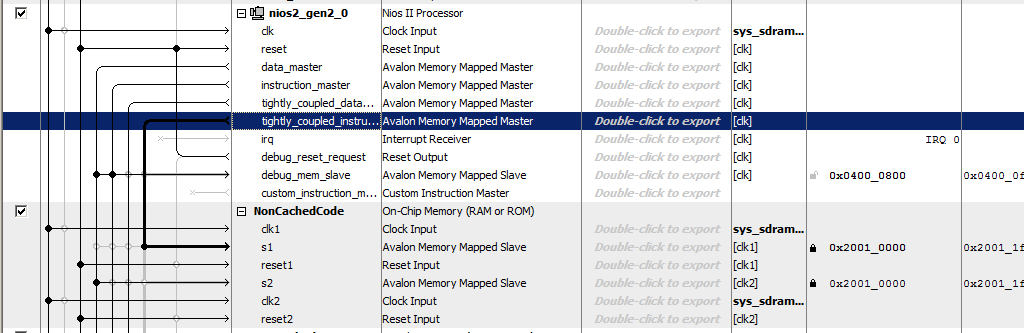
Память назовём NonCachedCode, подключим память к шинам, назначим ей адрес 0x20010000 и запрём его на замок (для обоих портов). Итого, у нас получается как-то так:
Всё. Сохраняем и генерим систему, собираем проект. Аппаратура готова. Переходим к программной части.
Обычно после изменения процессорной системы достаточно просто выбрать пункт меню Generate BSP, но сегодня нам придётся открыть BSP Editor. Так как мы это делаем редко, напомню, где расположен соответствующий пункт меню:
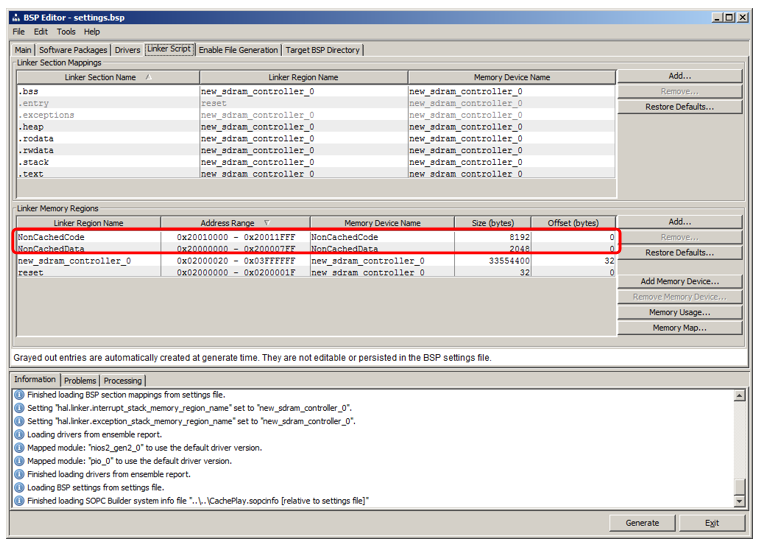
Там мы идём на вкладку Linker Script. Мы видим, что у нас добавились регионы, унаследовавшие имена от блоков ОЗУ:
Я покажу, как добавить секцию, в которую будет помещаться код. В разделе секций нажимаем Add:
В появившемся окне даём имя секции (чтобы исключить путаницу в статье, я назову её очень не похоже на имя региона, а именно — nccode) и связываем её с регионом (я выбрал NonCachedCode из списка):

Всё, генерим BSP и закрываем редактор.
Напомню, что у нас в программе, доставшейся в наследство от прошлой статьи, имеется две функции: MagicFunction1() и MаgicFunction2(). При первом проходе обе они подгружали своё тело в кэш, что было видно на осциллографе. Дальше – в зависимости от ситуации в окружении, работали либо на максимальной скорости, либо постоянно затирали друг друга своими телами, провоцируя постоянные подгрузки из SDRAM.
Давайте перенесём первую функцию в новый некэшируемый сегмент, а вторую оставим на месте, после чего выполним пару прогонов.
Выполняем первый прогон одной итерации цикла (я поставил точку останова на строчку while):
Видим следующий результат:
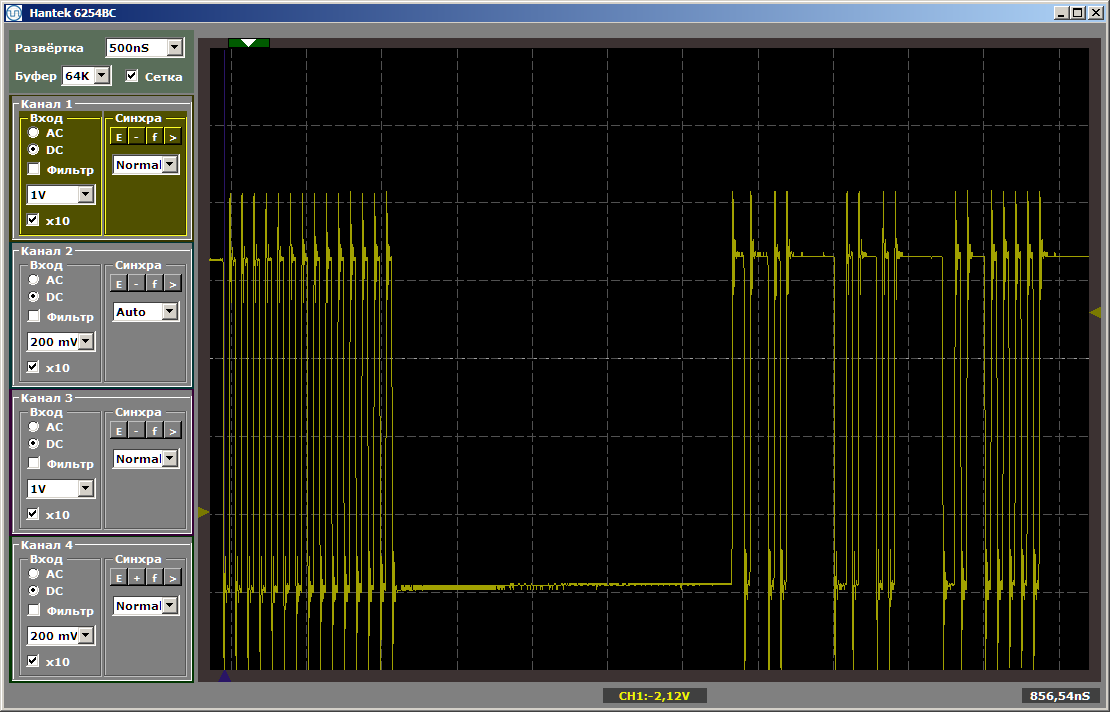
Как видим, первая функция действительно выполняется на максимальной скорости, вторая подгружается из SDRAM. Выполняем второй прогон:
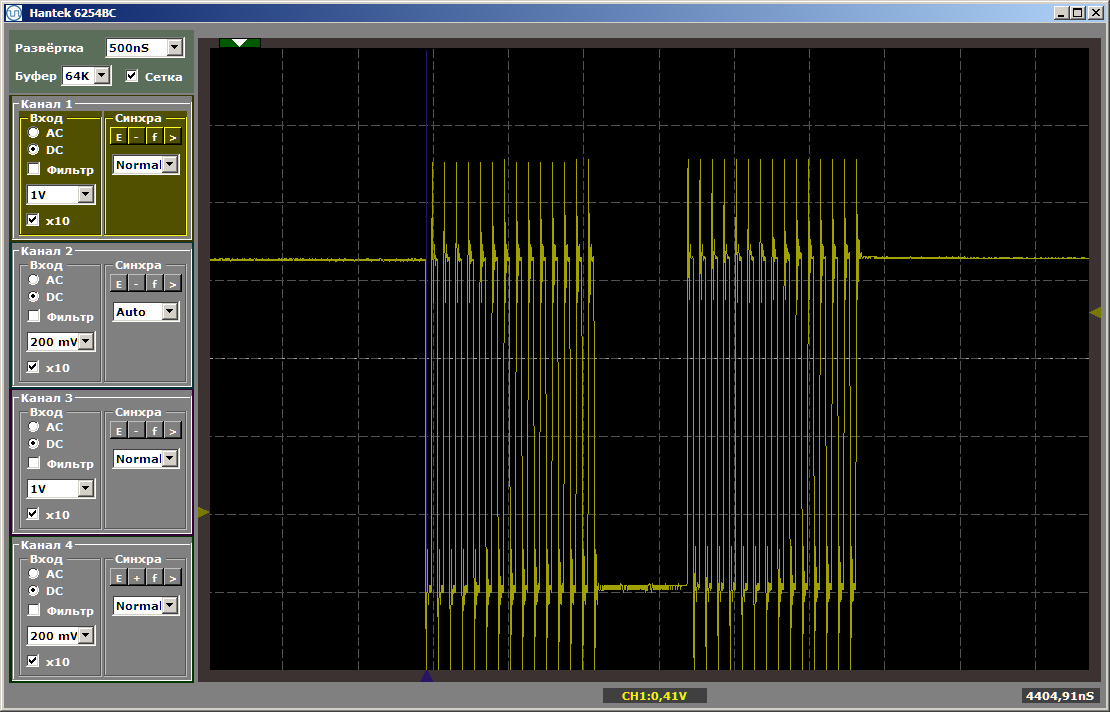
Обе функции работают на максимальной скорости. И первая функция не выгружает вторую из кэша, несмотря на то, что между ними стоит та вставка, которую я оставил после написания прошлой статьи:
Эта вставка больше не влияет на взаимное положение двух функций, так как первая из них уехала совсем в другую область памяти.
Аналогично можно создать секцию некэшируемых данных и размещать туда глобальные переменные, присваивая им такой же атрибут, но для экономии места, я не буду приводить подобных примеров.
Регион для такой памяти у нас создан, сопоставление с секцией можно сделать тем же путём, что и для секции кода. Осталось только понять, как присвоить переменной соответствующий атрибут. Вот первый попавшийся пример объявления таких данных, найденный в недрах автоматически созданного кода:
Ну, собственно, из очевидных вещей: теперь мы можем разместить в SDRAM основную часть кода, а в некэшируемый участок вынести те функции, которые формируют временные диаграммы программным путём, либо быстродействие которых должно быть максимальным, а значит они не должны замедляться из-за того, что какая-то другая функция постоянно выгружает соответствующий код из кэша.
А теперь внимательно посмотрим на шины в получившейся процессорной системе. У нас их получилось почти четыре. Красным я обвёл основную шину (являющуюся объединением из двух, именно поэтому я и написал «почти»: физически — шин две, но логически — одна). Зелёным я выделил шину, ведущую к некэшируемой памяти инструкций, синим — к некэшируемой памяти данных. Эти три шины работают параллельно и независимо друг от друга!

Помните, в статье про DMA я рассуждал о том, что одним из ограничивающих производительность фактором является то, что данные передаются по одной и той же шине? Блок DMA читает данные из шины, пишет данные в неё же, да ещё в это же время той же шиной пользуется процессорное ядро. Как видим, этот недостаток закрытых систем полностью устранён в ПЛИС. В готовых контроллерах производители при прокладке связей вынуждены разрываться между потребностями и возможностями. Программисту может понадобиться такой вариант. И такой. И такой. И такой… Много чего может понадобиться. Но ресурсы стоят денег, да и не всегда на выбранном кристалле хватит места под них. Всё не разместишь. Приходится выбирать, что реально нужно всем, а что понадобится в единичных случаях. И какие единичные случаи следует внедрить, а про какие — забыть. И дальше появляются компромиссные решения, все тонкости которых, если есть желание их использовать, программисту приходится держать в уме. В нашем же случае, мы можем действовать без затей. Что нам нужно сегодня, то сегодня и проложили. У нас ресурс гибкий. Мы тратим его так, чтобы аппаратура была оптимальна под нашу сегодняшнюю задачу. Под завтрашнюю и вчерашнюю задачи, ресурсы резервировать не нужно. Но зато под сегодняшнюю мы проложим всё так, чтобы программа работала максимально эффективно, не требуя для того особых программистских изысков.
Давным-давно, в университете на курсе по сигнальным процессорам нас учили искусству параллельного использования двух шин одной командой. Насколько я знаю, в современных ARM контроллерах также детальное знание матрицы шин позволяет производить оптимизацию. Но всё это хорошо, когда разработчик годами работает с одной и той же системой. Если от проекта к проекту приходится скакать на совершенно разные железки, всё заучить не удаётся. В случае же с ПЛИС, мы не изучаем особенности среды, мы вольны подгонять среду под себя.
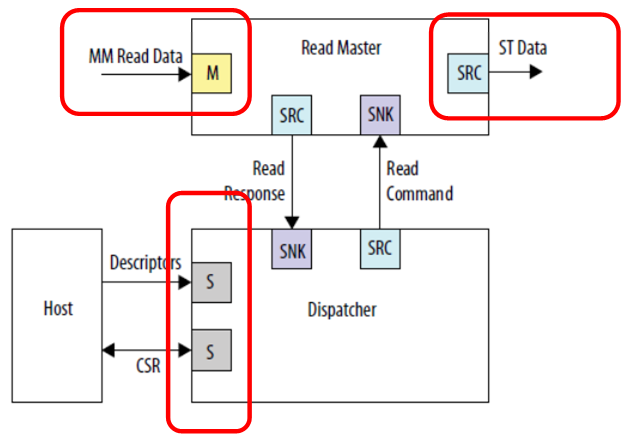
Мы видим три независимых подключения. Входные данные (на данном рисунке это шина, проецируемая на память), выходные данные (на данном рисунке это совсем другой тип шины – потоковый интерфейс) и связь с управляющим процессором. Никто не мешает подключить это всё к разным шинам, тогда работа будет идти в параллель. Входные данные (например, от SDRAM) будут идти одним потоком, которому никто не мешает; выходные данные будут уходить другим потоком, скажем, в канал FT245-FIFO, который мы уже рассматривали; а работа центрального процессора не будет отъедать от этих шин тактов, так как основная шина изолирована. Хотя в этом случае, разумеется, память в SDRAM, будучи на отдельной шине, окажется программно недоступна. Но никто не помешает её также считывать средствами DMA. Если цель — достичь высокой производительности работы с буфером, то её надо достигать любой ценой. Разве что всю программу придётся уместить в памяти, встроенной в ПЛИС, так как иных блоков хранения в аппаратуре Redd не предусмотрено.
Для распараллеливания шин также можно использовать некэшируемые шины, ведь мы видели, что их может быть и несколько. На подчинённые устройства, подключаемые к этим шинам накладывается ряд ограничений:
Если эти условия выполняются, такое подчинённое устройство может быть подключено к некэшируемой шине. Разумеется, скорее всего, это будет шина данных.
В общем, зная эти базовые принципы, вы наверняка сможете использовать их в реальных задачах. Но, в целом, именно можете. Можно обойтись и без этого, если результат достигается и обычными средствами. Но держать в уме это стоит. Иногда оптимизация системы через эти механизмы происходит проще, чем тонкая подгонка программы.
Мы рассмотрели методику выноса участков кода, критичных к производительности либо к предсказуемости растактовки исполнения, в некэшируемую память. Попутно мы рассмотрели возможности оптимизации производительности за счёт использования нескольких шин, работающих параллельно и независимо друг от друга.
Чтобы закончить тему, мы должны ещё научиться поднимать тактовую частоту системы (сейчас она ограничена компонентом, вырабатывающим тактовые импульсы для микросхемы SDRAM). Но так как статьи идут по принципу «одна вещь — одна статья», сделаем мы это уже в следующий раз.
Предыдущие статьи цикла:
- Разработка простейшей «прошивки» для ПЛИС, установленной в Redd, и отладка на примере теста памяти.
- Разработка простейшей «прошивки» для ПЛИС, установленной в Redd. Часть 2. Программный код.
- Разработка собственного ядра для встраивания в процессорную систему на базе ПЛИС.
- Разработка программ для центрального процессора Redd на примере доступа к ПЛИС.
- Первые опыты использования потокового протокола на примере связи ЦП и процессора в ПЛИС комплекса Redd.
- Веселая Квартусель, или как процессор докатился до такой жизни.
- Методы оптимизации кода для Redd. Часть 1: влияние кэша.
Сегодня нашей настольной книгой будет документ Embedded Design Handbook, а точнее — его раздел 7.5. Using Tightly Coupled Memory with the Nios II Processor Tutorial. Раздел сам по себе колоритный. Сегодня мы проектируем процессорные системы для ПЛИС Intel в программе Platform Designer. Во времена Altera, она называлась QSys (отсюда расширение .qsys у файла проекта). Но до появления QSsys, все пользовались её предком, SOPC Builder (в память о котором осталось расширение файла .sopcinfo). Так вот, хоть документ и отмаркирован логотипом Intel, но рисунки в нём являются скриншотами из этого SOPC Builder. Он явно написан более десяти лет назад, и с тех пор в нём правились только термины. Правда, тексты вполне современные, поэтому в качестве методички этот документ вполне пригодится.
Подготовка аппаратуры
Итак. Мы хотим добавить в нашу спартанскую процессорную систему память, которая никогда не кэшируется и при этом работает на максимально возможной скорости. Разумеется, это будет встроенная память ПЛИС. Мы добавим память как для кода, так и для данных, но это будут разные блоки. Начнём с памяти для данных, как наиболее простой. Добавляем уже известную нам OnChip Memory в систему.
Ну, скажем, пусть её объём будет 2 килобайта (главная проблема встроенной памяти ПЛИС в том, что её мало, так что приходится экономить). В остальном — обычная память, какую мы уже добавляли.
Но подключать мы её будем не к шине данных, а к особой шине. Чтобы она появилась, входим в свойства процессора, идём на вкладку Caches and Memory Interfaces и в списке выбора Number of tightly coulped data master ports выбираем значение 1.
Вот такой новый порт появился у процессора:
Недавно добавленный блок памяти подключаем именно к нему!
Ещё одна хитрость — в назначении адресов этой новой памяти. В документе есть длинная цепочка рассуждений про оптимальность декодирования адреса. Там утверждается, что некэшируемая память должна отличаться от всех остальных видов памяти чётко выраженным одним битом адреса. Поэтому в документе вся некэшируемая память относится к диапазону 0x2XXXXXXX. Так что впишем вручную адрес 0x2000000 и запрём его на замок, чтобы при следующих автоматических назначениях он не изменялся.
Ну, и чисто для эстетики, переименуем блок… Назовём его, скажем, NonCachedData.
С аппаратурой для некэшируемой памяти данных всё. Переходим к памяти для хранения кода. Здесь всё почти так же, но чуть-чуть сложнее. На самом деле, всё можно сделать полностью идентично, только ведущий порт шины открывается в списке Number of tightly coulped instruction master ports, однако отлаживать такую систему будет невозможно. При заливке программы средствами отладчика, она вливается туда через шину данных. При остановке, дизассемблируемый код считывается отладчиком также через шину данных. И даже если программа загружается из внешнего загрузчика (мы такой метод ещё не рассматривали, тем более, что в бесплатной версии среды разработки мы обязаны работать только при подключённом JTAG отладчике, но в целом, никто так делать не запрещает), заливка также идёт через шину данных. Поэтому память придётся делать двухпортовой. К одному порту подключать некэшируемый мастер инструкций, который работает в основное время, а к другому — вспомогательную штатную шину данных. Она будет использоваться для загрузки программы извне, а также для получения содержимого ОЗУ отладчиком. В остальное время эта шина будет простаивать. Вот так всё это выглядит в теоретической части документа:
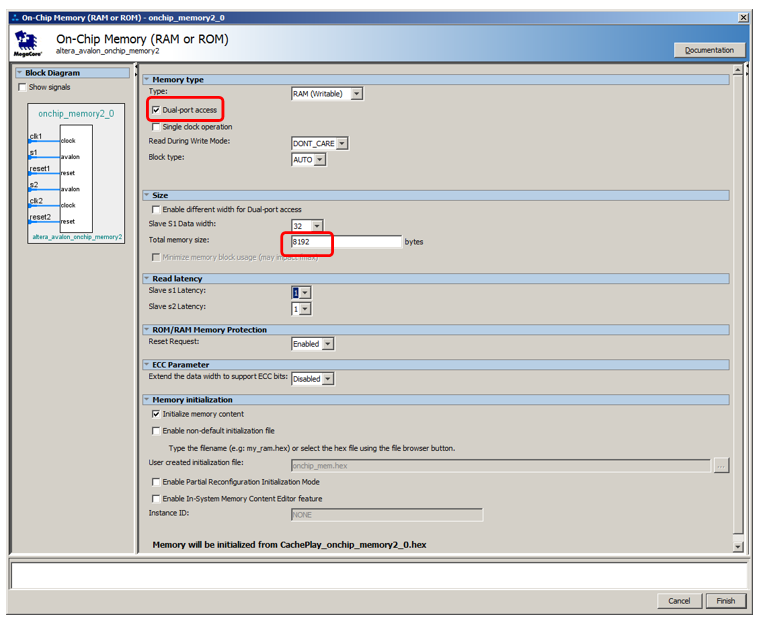
Обратите внимание, что в документе не объясняется почему, но отмечается, что даже у двухпортовой памяти только один порт может быть подключён к некэшируемому мастеру. Второй должен быть подключён к обычному.Давайте добавим 8 килобайт памяти, сделаем её двухпортовой, остальное оставим по умолчанию:
Процессору добавим некэшируемый порт инструкций:
Память назовём NonCachedCode, подключим память к шинам, назначим ей адрес 0x20010000 и запрём его на замок (для обоих портов). Итого, у нас получается как-то так:
Всё. Сохраняем и генерим систему, собираем проект. Аппаратура готова. Переходим к программной части.
Подготовка BSP в программной части
Обычно после изменения процессорной системы достаточно просто выбрать пункт меню Generate BSP, но сегодня нам придётся открыть BSP Editor. Так как мы это делаем редко, напомню, где расположен соответствующий пункт меню:
Там мы идём на вкладку Linker Script. Мы видим, что у нас добавились регионы, унаследовавшие имена от блоков ОЗУ:
Я покажу, как добавить секцию, в которую будет помещаться код. В разделе секций нажимаем Add:
В появившемся окне даём имя секции (чтобы исключить путаницу в статье, я назову её очень не похоже на имя региона, а именно — nccode) и связываем её с регионом (я выбрал NonCachedCode из списка):
Всё, генерим BSP и закрываем редактор.
Размещение кода в новой секции памяти
Напомню, что у нас в программе, доставшейся в наследство от прошлой статьи, имеется две функции: MagicFunction1() и MаgicFunction2(). При первом проходе обе они подгружали своё тело в кэш, что было видно на осциллографе. Дальше – в зависимости от ситуации в окружении, работали либо на максимальной скорости, либо постоянно затирали друг друга своими телами, провоцируя постоянные подгрузки из SDRAM.
Давайте перенесём первую функцию в новый некэшируемый сегмент, а вторую оставим на месте, после чего выполним пару прогонов.
Чтобы поместить функцию в новую секцию, следует добавить ей атрибут section.Перед определением функции MagicFunction1() поместим ещё и её объявление с этим атрибутом:
void MagicFunction1()__attribute__ ((section("nccode")));
void MagicFunction1()
{
IOWR (PIO_0_BASE,0,1);
IOWR (PIO_0_BASE,0,0);
...
Выполняем первый прогон одной итерации цикла (я поставил точку останова на строчку while):
while (1)
{
MagicFunction1();
MagicFunction2();
}
Видим следующий результат:
Как видим, первая функция действительно выполняется на максимальной скорости, вторая подгружается из SDRAM. Выполняем второй прогон:
Обе функции работают на максимальной скорости. И первая функция не выгружает вторую из кэша, несмотря на то, что между ними стоит та вставка, которую я оставил после написания прошлой статьи:
volatile void FuncBetween()
{
Nops256 Nops256 Nops256
Nops64 Nops64 Nops64
Nops16 Nops16
}
Эта вставка больше не влияет на взаимное положение двух функций, так как первая из них уехала совсем в другую область памяти.
Пара слов о данных
Аналогично можно создать секцию некэшируемых данных и размещать туда глобальные переменные, присваивая им такой же атрибут, но для экономии места, я не буду приводить подобных примеров.
Регион для такой памяти у нас создан, сопоставление с секцией можно сделать тем же путём, что и для секции кода. Осталось только понять, как присвоить переменной соответствующий атрибут. Вот первый попавшийся пример объявления таких данных, найденный в недрах автоматически созданного кода:
volatile alt_u32 alt_log_boot_on_flag __attribute__ ((section (".sdata"))) = ALT_LOG_BOOT_ON_FLAG_SETTING;
Что это нам даёт
Ну, собственно, из очевидных вещей: теперь мы можем разместить в SDRAM основную часть кода, а в некэшируемый участок вынести те функции, которые формируют временные диаграммы программным путём, либо быстродействие которых должно быть максимальным, а значит они не должны замедляться из-за того, что какая-то другая функция постоянно выгружает соответствующий код из кэша.
Внимательно посмотрим на шины
А теперь внимательно посмотрим на шины в получившейся процессорной системе. У нас их получилось почти четыре. Красным я обвёл основную шину (являющуюся объединением из двух, именно поэтому я и написал «почти»: физически — шин две, но логически — одна). Зелёным я выделил шину, ведущую к некэшируемой памяти инструкций, синим — к некэшируемой памяти данных. Эти три шины работают параллельно и независимо друг от друга!
Помните, в статье про DMA я рассуждал о том, что одним из ограничивающих производительность фактором является то, что данные передаются по одной и той же шине? Блок DMA читает данные из шины, пишет данные в неё же, да ещё в это же время той же шиной пользуется процессорное ядро. Как видим, этот недостаток закрытых систем полностью устранён в ПЛИС. В готовых контроллерах производители при прокладке связей вынуждены разрываться между потребностями и возможностями. Программисту может понадобиться такой вариант. И такой. И такой. И такой… Много чего может понадобиться. Но ресурсы стоят денег, да и не всегда на выбранном кристалле хватит места под них. Всё не разместишь. Приходится выбирать, что реально нужно всем, а что понадобится в единичных случаях. И какие единичные случаи следует внедрить, а про какие — забыть. И дальше появляются компромиссные решения, все тонкости которых, если есть желание их использовать, программисту приходится держать в уме. В нашем же случае, мы можем действовать без затей. Что нам нужно сегодня, то сегодня и проложили. У нас ресурс гибкий. Мы тратим его так, чтобы аппаратура была оптимальна под нашу сегодняшнюю задачу. Под завтрашнюю и вчерашнюю задачи, ресурсы резервировать не нужно. Но зато под сегодняшнюю мы проложим всё так, чтобы программа работала максимально эффективно, не требуя для того особых программистских изысков.
Давным-давно, в университете на курсе по сигнальным процессорам нас учили искусству параллельного использования двух шин одной командой. Насколько я знаю, в современных ARM контроллерах также детальное знание матрицы шин позволяет производить оптимизацию. Но всё это хорошо, когда разработчик годами работает с одной и той же системой. Если от проекта к проекту приходится скакать на совершенно разные железки, всё заучить не удаётся. В случае же с ПЛИС, мы не изучаем особенности среды, мы вольны подгонять среду под себя.
Применительно к подходу «мы не тратим много времени на разработку», это звучит так:Давайте для закрепления материала взглянем на пример включения блока DMA из документа Embedded Peripherals IP User Guide.
Нам не надо прилагать усилия по оптимальному использованию готовых типовых шин, мы можем быстро проложить их наиболее оптимальным для решаемой задачи способом, быстро закончить эту вспомогательную разработку и быстро обеспечить процесс отладки либо тестирования основного проекта.
Мы видим три независимых подключения. Входные данные (на данном рисунке это шина, проецируемая на память), выходные данные (на данном рисунке это совсем другой тип шины – потоковый интерфейс) и связь с управляющим процессором. Никто не мешает подключить это всё к разным шинам, тогда работа будет идти в параллель. Входные данные (например, от SDRAM) будут идти одним потоком, которому никто не мешает; выходные данные будут уходить другим потоком, скажем, в канал FT245-FIFO, который мы уже рассматривали; а работа центрального процессора не будет отъедать от этих шин тактов, так как основная шина изолирована. Хотя в этом случае, разумеется, память в SDRAM, будучи на отдельной шине, окажется программно недоступна. Но никто не помешает её также считывать средствами DMA. Если цель — достичь высокой производительности работы с буфером, то её надо достигать любой ценой. Разве что всю программу придётся уместить в памяти, встроенной в ПЛИС, так как иных блоков хранения в аппаратуре Redd не предусмотрено.
Для распараллеливания шин также можно использовать некэшируемые шины, ведь мы видели, что их может быть и несколько. На подчинённые устройства, подключаемые к этим шинам накладывается ряд ограничений:
- подчинённое устройство всегда одно на шине;
- подчинённое устройство не использует механизм задержки шины;
- латентность записи всегда равна нулю, латентность чтения всегда равна единице.
Если эти условия выполняются, такое подчинённое устройство может быть подключено к некэшируемой шине. Разумеется, скорее всего, это будет шина данных.
В общем, зная эти базовые принципы, вы наверняка сможете использовать их в реальных задачах. Но, в целом, именно можете. Можно обойтись и без этого, если результат достигается и обычными средствами. Но держать в уме это стоит. Иногда оптимизация системы через эти механизмы происходит проще, чем тонкая подгонка программы.
Заключение
Мы рассмотрели методику выноса участков кода, критичных к производительности либо к предсказуемости растактовки исполнения, в некэшируемую память. Попутно мы рассмотрели возможности оптимизации производительности за счёт использования нескольких шин, работающих параллельно и независимо друг от друга.
Чтобы закончить тему, мы должны ещё научиться поднимать тактовую частоту системы (сейчас она ограничена компонентом, вырабатывающим тактовые импульсы для микросхемы SDRAM). Но так как статьи идут по принципу «одна вещь — одна статья», сделаем мы это уже в следующий раз.
VBKesha
Отлично, очень хорошо описываете, подробно и понятно.
Спасибо.