
Глобальная популяция разработчиков
Чтобы как-то подойти к вопросу, решил начать с поиска данных о том, сколько в принципе сейчас разработчиков в мире и как эта популяция изменяется с течением времени.
Оценки в разных источниках называют числа в вилке от 12 до 30 миллионов человек. Остановиться решил на данных от SlashData, потому что их методология показалась мне вполне сбалансированной и подходящей для моих нужд. В оценке они учитывали количество аккаунтов и репозиториев на Github, количество аккаунтов на StackOverflow, аккаунты npm и данные официальных источников о трудоустройстве в США и Европе. Также они откорректировали получившиеся числа при помощи своих собственных 16 исследований, которые охватывали примерно по 20 000 человек для каждого опроса.
По данным SlashData получилось, что в четвертом квартале 2018 года в мире было примерно 18.9 миллионов разработчиков, 12.9 миллионов из которых — профессиональные, то есть зарабатывают на жизнь программированием. Те, кто не является на данный момент профессиональными разработчиками — это люди, для которых программирование является хобби плюс те, кто сейчас изучает профессию (разнокалиберные студенты и самоучки). Ну то есть вот намек на численность группы, которая меня интересует — 6 миллионов человек. Честно признаться, это больше чем я ожидал.
Вторым сюрпризом для меня стали темпы роста поголовья программистов: со второго квартала 2017-го года по четвертый квартал 2018 оно увеличилось с 14.7 до упомянутых 18.9 миллионов, или выросло на 21% за 2018 год! Если бы меня попросили оценить темпы роста количества программистов, то я бы сказал, что это около 5% в год с небольшим ростом темпа ежегодно. А тут оказывается целых 20%.
Кроме того, SlashData оценивает, что к 2030-му году популяция достигнет 45 миллионов. Нетрудно посчитать, что это подразумевает рост на чуть больше чем 8% ежегодно, а вовсе не 20%, но они ссылаются на коррекцию с учетом проникновения интернета (сейчас около 57% в мире по данным Statista) и еще нескольких факторов, например количества разработчиков на душу населения. Географически, сильнее всего растет количество разработчиков в Индии и Китае, предположительно Индия обгонит США по количеству разработчиков к 2023 (это уже данные C# Corner).
В общем, программистов будет много, как ни крути, потому что спрос растет. Кстати, о спросе.
На что есть спрос?
Для оценки спроса я пользовался данными HackerRank за 2018 и 2019 года.
По языкам программирования самый большой спрос на JavaScript, Python и Java практически по всем индустриям, за исключением Computer Hardware. В последней наибольший спрос на C/C++, что и понятно, в железячных проектах еще сохраняются требования по ресурсоемкости и производительности соответствующего софта.
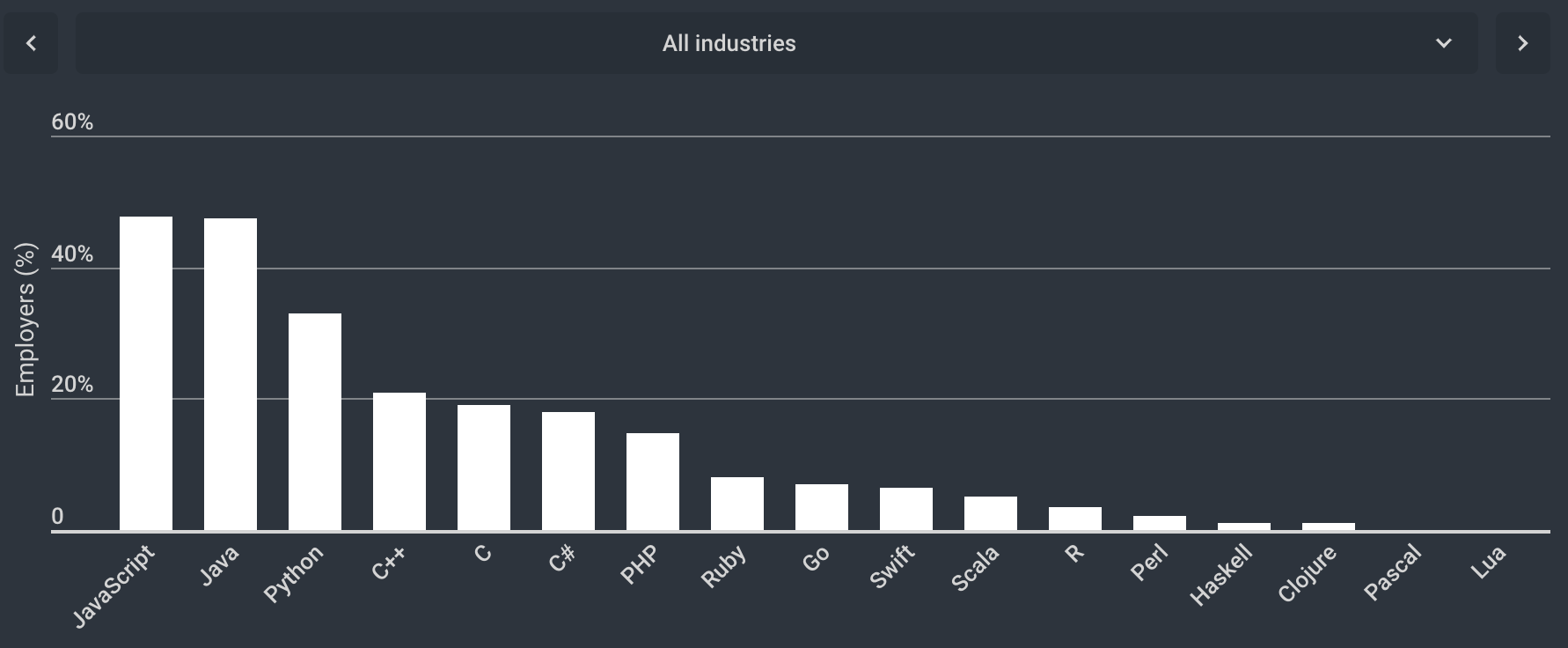
По фреймворкам наибольшим спросом пользуются AngularJS, Node.js и React, причем по ним самый большой разрыв спроса и предложения, что, кажется, объясняется скоростью, с которой меняется экосистема JavaScript-а, потому что например по ExpressJS предложение уже превышает спрос.
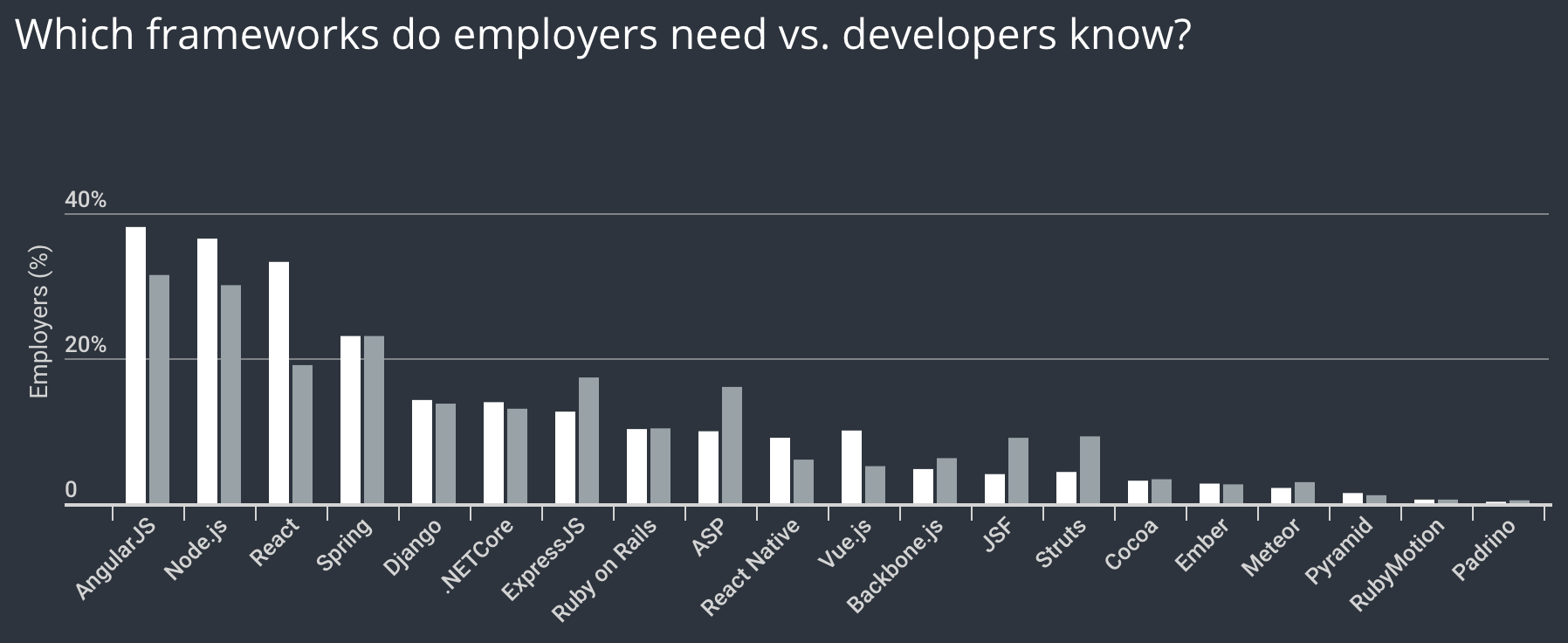
По компетенциям работодатели ожидают от кандидатов в первую очередь Problem Solving skills. Около 95% работодателей упоминает эти навыки как важные. Programming Language Proficiency на втором месте с 56%. К слову строчки с фундаментальными знаниями алгоритмов, структур данных и прочего Computer Science вообще нет, то ли не было в опроснике, то ли так массово академические знания уже не требуются.
Database Design нужен 23.2% компаний размером до 100 человек, и 18.8% компаний свыше 1000 человек. Ага, вот оно похоже про ORM и SQL! Логичное, имхо, объяснение в том, что в больших компаниях появляется выделенная роль DBA, который ответственен за этот аспект, а следовательно можно смягчить требования к девелоперам и нанимать быстрее. А вот с System Design наоборот: 37.0% в маленьких, 44.1% — в больших. Казалось бы, в больших должны быть выделенные архитекторы, но, возможно, они просто не в состоянии покрывать количество генерируемых систем. Или в System Design заодно вкладывают те самые фундаментальные алгоритмы и структуры данных, тогда становится немного понятнее.
Маленьким компаниям больше нужен Framework Proficiency и меньше вышеупомянутый System Design, из чего можно сделать капитанский вывод о том, что стартапам важно как можно быстрее запустить как-нибудь работающий продукт, а завтра будет завтра.
Что учат студенты?
Здесь я опирался на данные еще одного исследования HackerRank.
Важно учитывать, что несмотря на то, что программирование в том или ином виде преподается в университетах (имею в виду Computer Science специальности), больше половины опрошенных сказали, что занимаются в том числе и самообразованием.
Современные студенты предпочитают учиться по YouTube, в то время как более взрослые разработчики склоняются к тьюториалам и книгам. И те и другие активно пользуются StackOverflow. Отношу это на то, что видео — привычный медиаканал для поколения Z, в то время как представители поколения Y еще застали эпоху без блогеров.
Учат то, что востребовано работодателями: JavaScript, Java, Python. Указывают, что знают C/C++, но это вероятно потому, что эти языки используются для преподавания в университетах. Учат JS фреймворки, но спрос существенно выше предложения, поэтому видимо активно учат уже найдя первую работу.
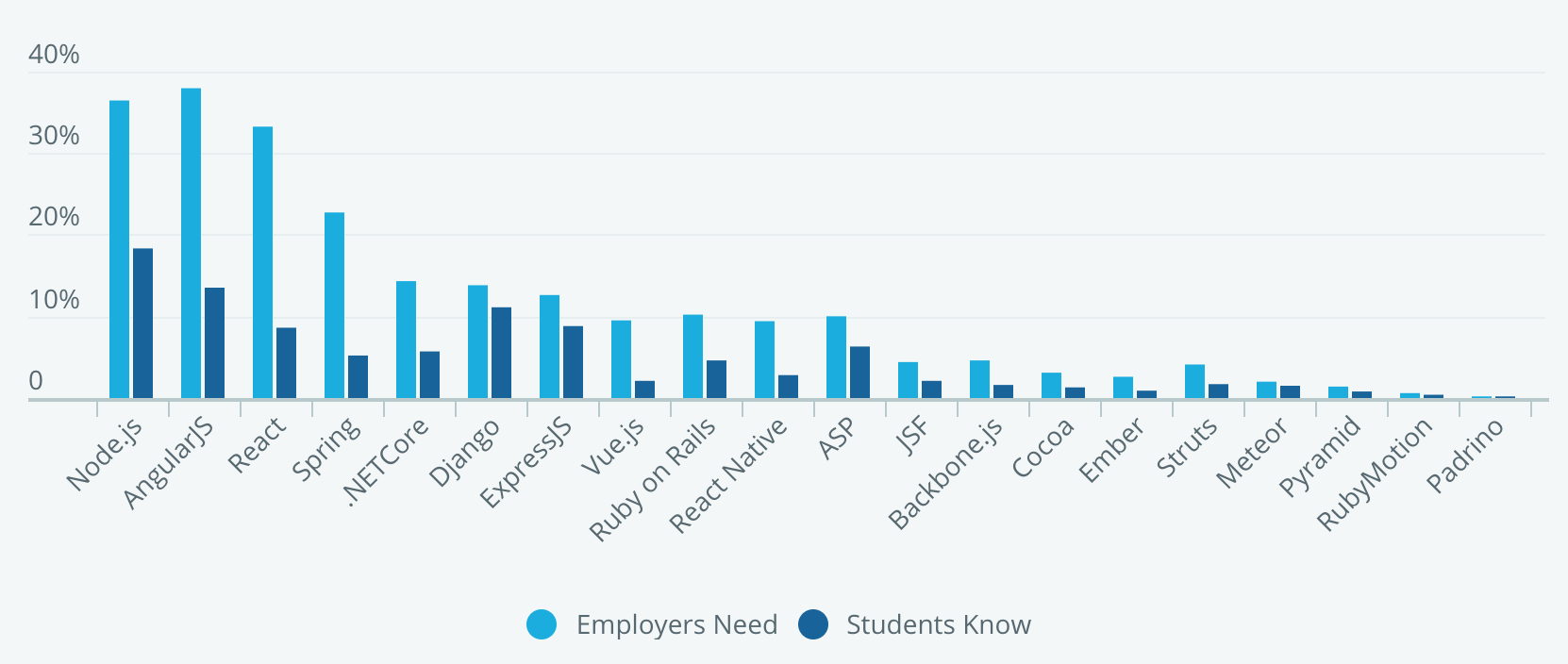
В целом, ожидаемо учат то, на что есть спрос.
Студенты от первой работы ожидают в первую очередь профессионального роста, на втором месте (в некоторых странах на первом) work-life balance, на третем — интересные задачи.
Динамика популяции разработчиков по языкам программирования и типам ПО
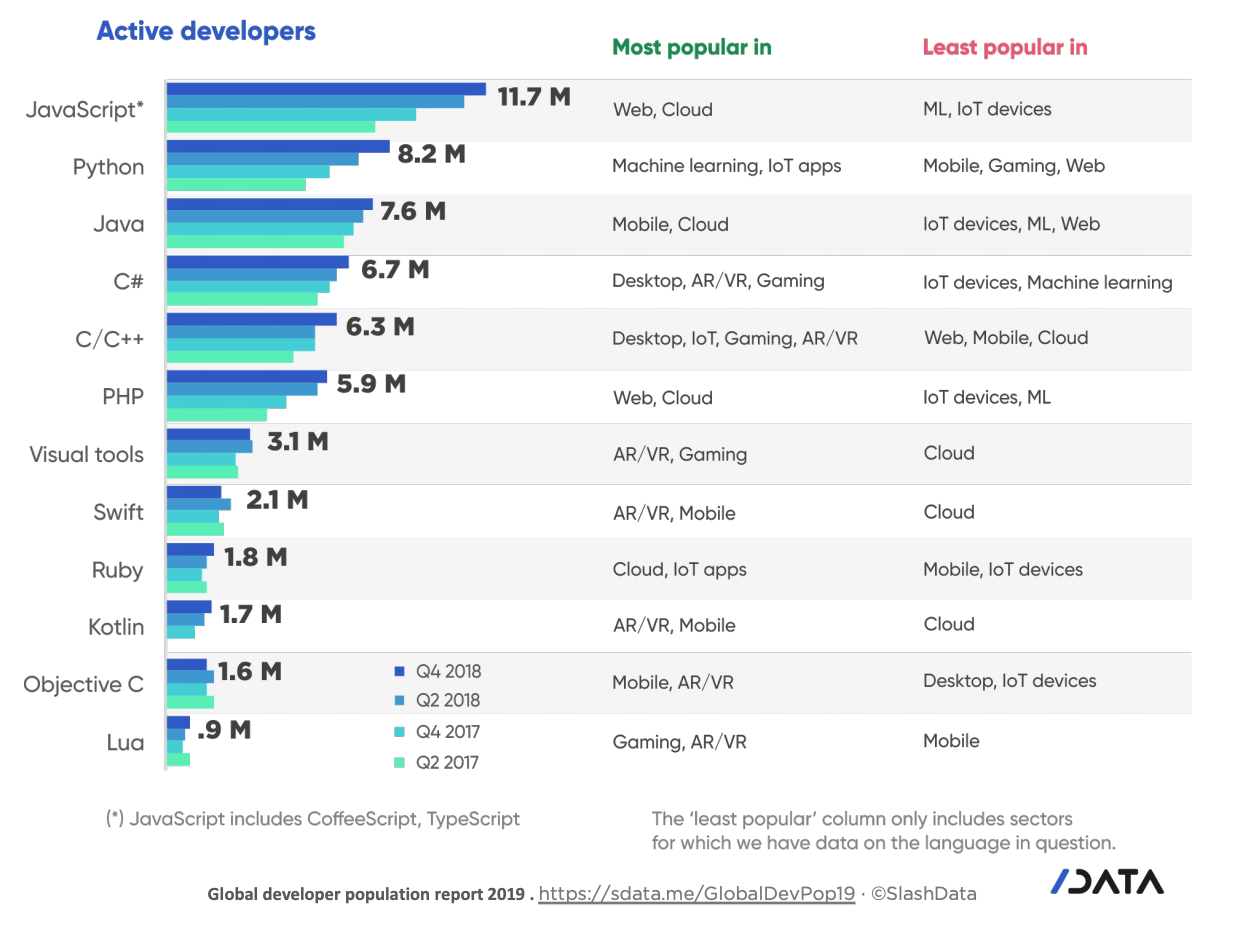
Web приложения на первом месте с оценкой в 16.9 миллиона разработчиков. Это опять данные SlashData. Дальше Backend Services (13.6 млн), мобильные приложения (13.1 млн) и десктоп (12.3 млн). AR/VR и IoT сектора постепенно набирают популярность, AI/ML/Data Science существенно выросли за последние два года.
Быстрее всего растет Javascript, его сообщество уже сейчас самое большое, только за 2018 год выросло на 2.5 миллиона. На нем пытаются писать даже в секторах IoT и ML.
Python за 2018 год прирос на 2.2 миллиона за счет роста популярности ML, где он традиционно силен, а также за счет простоты освоения и удобства языка.
Java, C/C++ и C# растут с меньшей скоростью, чем общая популяция разработчиков. Они теперь редко являются языком программирования, с которого люди предпочитают начинать. Спрос на разработчиков тут более-менее сбалансирован с предложением. Думаю, что Java росла бы еще медленнее, если бы не Android.
PHP второй по популярности язык программирования веб приложений и он тоже существенно растет (на 32% в 2018 году). Его сообщество оценивается в 5.9 млн разработчиков. Несмотря на полярное мнение насчет репутации PHP, он довольно прост в изучении и широко распространен.
Как учатся современные молодые кандидаты в сравнении с прошлыми поколениями
Снова данные HackerRank. Те, кому сейчас от 38 до 53, своими первыми проектами указывают игры.
Подтверждаю, кстати, первым моим более-менее рабочим проектом были «крестики-нолики» до пяти в ряд с неограниченным полем, вторым — игра в 15. Писал я все это на БК 010-01, там был вильнюсский бейсик, он же BASIC-86 и фокал. Эх.
Современные начинающие программисты (до 21-го года) первыми проектами пишут калькуляторы и веб сайты.
Среди представителей поколения X почти половина начали писать код до 16 лет, многие так и вообще с 5 до 10 лет (преимущественно те, кому от сейчас от 35 до 45 лет). Более менее понятно почему: источников информации было мало, и чтобы стать программистом нужно было действительно этого сильно хотеть, а те, кто сильно хотел, начинали программировать рано. Те, кто хотел не так сильно, к сегодняшнему моменту скорее всего имеют другую профессию, поэтому картина по социологии именно такая.
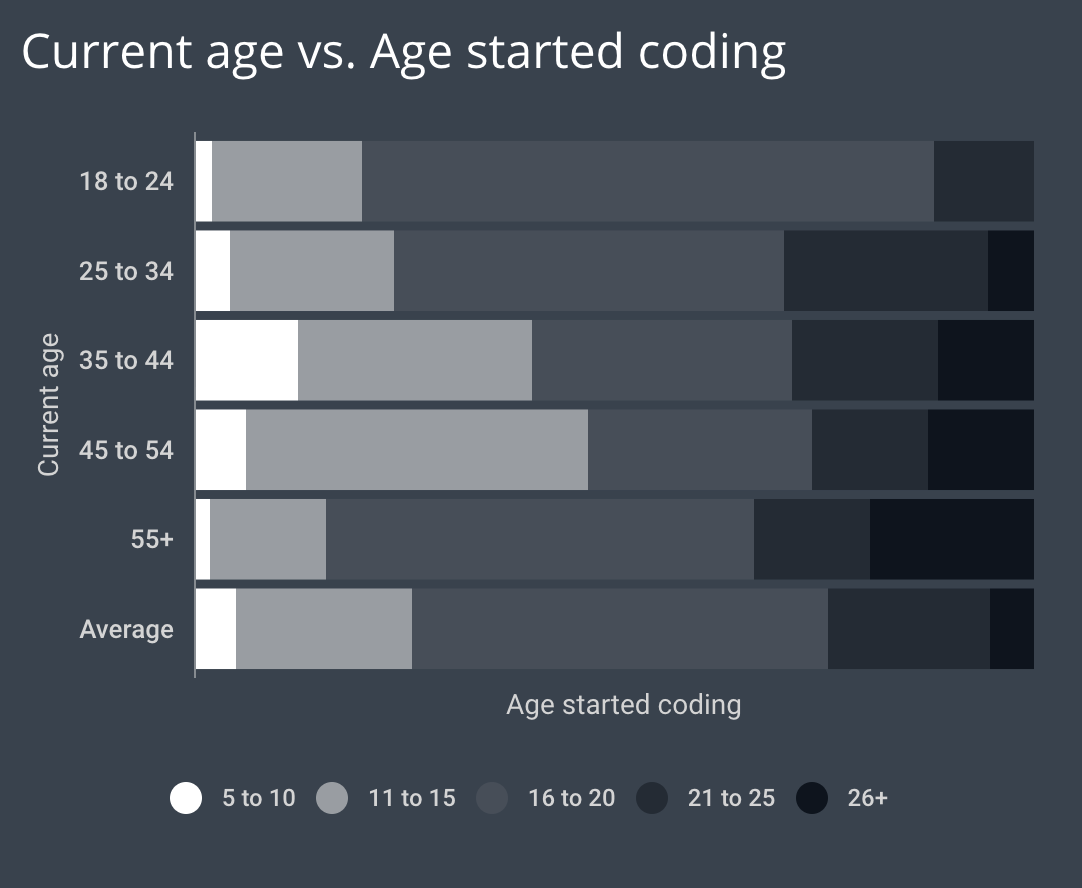
Сегодняшние молодые кандидаты только в 20% случаев начинают программировать до 16 лет, большинство — где-то между 16-ю и 20-ю. Но им и значительно проще учиться, теперь это гораздо доступнее.
Выводы
Железобетонного ответа на вопрос, нужен ли сегодня начинающему web backend девелоперу SQL, я так и не нашел, но зато подкорректировал свое представление о современной популяции программистов.
Очередное поколение разработчиков — обычные люди, в чем-то напоминают прежних
Тех, кто знает, что латенси L1 кэша это ~4 цикла, и что кэш лайны лучше не сбивать без необходимости, становится меньше в процентном отношении к общему размеру популяции. Однако волноваться о трудоустройстве им не стоит, кто-то же в конце концов должен писать низкоуровневые вещи, где это по прежнему нужно. Равно как не стоит волноваться и тем, кто обладает глубокими фундаментальными знаниями в системном дизайне и приобрел их в кровопролитных практических боях, а не просто следует карго культу. Потому что умеющих «просто писать код» и «просто» пользоваться фреймворками в командах будет становиться больше, и для того, «чтобы не было мучительно больно за бесцельно прожитые годы» (с) их нужно будет балансировать как раз такими людьми.
Софт скиллы из категории желательных постепенно мигрируют в обязательные (в подтверждение этого у меня нет объективных данных, просто практические наблюдение). Количество программистов растет, и их всех нужно направлять для достижения результата, хоть прямым, хоть непрямым управлением, а для этого как раз и нужны софт скиллы.
«Войти в IT» представляется мне локальной региональной историей, характерной для тех локаций, где доход программиста существенно отличается от дохода сравнимого по квалификации «не IT» специалиста. В Минске, где я живу, так это вообще массовое движение, каждый день вижу рекламу очередных курсов о том, как попасть в заветное IT, а клининговые компании таргетятся в программистов с посылом «Понимаешь код на этой картинке? Значит можешь позволить себе не убирать в квартире, мы сделаем все за тебя.» То же самое по видимому происходит в какой-нибудь Индии. В доказательство этого данных у меня тоже нет.
В целом, популяции программистов ничего на мой взгляд не угрожает. Бухтеть о том, что настоящих программистов днем с огнем не сыщещь, а кандидаты сплошь и рядом «ничего не знают», не стоит. Они такие же умные и способные, может быть даже умнее и способнее, чем «настоящие программисты», просто приобретают те знания, которые от них требует бурно растущий рынок и откладывают на потом то, что им пока не требовалось и не принесет бенефита прямо сейчас. Выучат, когда будет нужно, потому что они по прежнему хотят учиться. Наверное, не все будут на это способны, но и не всем это понадобится, рынок точно в прогнозируемом будущем будет легко принимать людей, способных быстро собрать на каком-нибудь фреймворке очередной концепт приложения.
Комментарии (114)

pewpew
02.10.2019 19:05нужны ли начинающему web backend девелоперу знания SQL
Без алфавита сложно научиться писать, хотя можно научиться говорить. И всё же базовые знания SQL обязательно нужны. Не только для общего кругозора, но и для понимания основных принципов работы и устройства. Это как алгоритмы, паттерны проектирования, и рабочая терминология. Это может пригодиться и на практике. Например, в Tarantool есть возможность использовать как SQL, так и NoSQL. И даже можно комбинировать. Кроме того при проектировании разработчик может выбирать технологии в зависимости от задач. Или даже комбинировать технологии в разработке. Например, сервис может часть данных хранить в Redis, а часть в MySQL. И это может быть очень даже оправдано.

apapacy
02.10.2019 19:19+1Железобетонного ответа на вопрос, нужен ли сегодня начинающему web backend девелоперу SQL
Во что выливается незнание SQL
1) Забывают определять индексы в результате через некоторое время приложение останавливается и не могут найти почему.
2) Не могут на практике применять нормализацию данных. Когда "мыслят объектами/сущностями" возникают из-за ошибок нормализации химерные результирубющие структуры таблиц.
По перечни языков программирования интересно было бы узнать статистику по СНГ. В частности по ВУЗам. Если взять усредненный технический ВУЗ, то создается такое впечатление что там преподают как и 30 лет назад Паскаль плавно переходящий в Делфи.
vchslv13
02.10.2019 20:09Не статистика, конечно, но в моём простеньком ВУЗе в Кривом Роге (население около 600 000 человек, Украина) за время бакалаврата мы изучали MS VB 6, C++, C#, Java, PHP и JS. С другой стороны, количество вряд ли перешло в качество и для сдачи экзаменов/зачётов особо хорошего знания не нужно было (кроме С++ и С#, пожалуй).

mephius Автор
02.10.2019 20:53Во что выливается незнание SQL
1) Забывают определять индексы в результате через некоторое время приложение останавливается и не могут найти почему.
2) Не могут на практике применять нормализацию данных. Когда «мыслят объектами/сущностями» возникают из-за ошибок нормализации химерные результирубющие структуры таблиц.
С индексами ситуация очень частая, но быстроустранимая знающим человеком. Неправильно спроектированная база аукается гораздо сильнее.
Поэтому решая не требовать знания БД/SQL у разработчиков, нужно очень четко знать, кто именно будет эти вещи контролировать и исправлять. Видел один раз процесс в большой компании, когда после исполнения задачи разработчик передавал ее на ревью DBA, который должен был в случае чего кричать «Ты не пройдешь!» аки Гэндальф Барлогу. Мой внутренний эстет от такого бьется в истерике, но я понимаю, что люди выкручиваются как могут в сложившихся условиях.
Karl_Marx
02.10.2019 22:39+13) Забивают на констрейнты, иногда на транзакции и вообще на целостность данных
4) Забивают на конкарренсиmephius Автор
02.10.2019 22:45+15) дэдлоки
6) уровни изоляции транзакций
Это если мы по два пункта за коммент добавляем и не ограничиваемся исключительно SQL, а про работу с БД в целом.

Mogwaika
02.10.2019 23:51Мне в вузе вообще не преподавали языки, предполагалось, что студенты их знают и напишут курсовую на том, какой им удобнее.
Ну кроме семестра про асм и машины Тьюринга))
mayorovp
03.10.2019 11:29Забывают определять индексы в результате через некоторое время приложение останавливается и не могут найти почему.
А почему тут виновато незнание именно языка SQL, а не незнание основ баз данных?
На SQL что, нельзя забыть создать индекс?
Не могут на практике применять нормализацию данных. Когда "мыслят объектами/сущностями" возникают из-за ошибок нормализации химерные результирубющие структуры таблиц.
А где тут связь?
apapacy
03.10.2019 13:35Спасибо за уточнение. Действительно выражение CREATE INDEX не входит в стандарт SQL (я об этом никогда не задумывался). Это не меняет того момента, что это выражение входит в конкретные реализации большинства SQL серверов баз данных и разработчики ORM хотя и знают что можно определять свойства у объектов связанные с индексацией очень часто этого не делают.
Связь между незнанием теоретических основ нормализации данных и отсутствием практики в их применения такая, что результирующие отношение получаются не нормализованными. Хотя с точки зрения объектного анализа все может выглядеть достаточно правдоподобно.
Привожу реальный пример. Разработчик связал объект "банкомат" с объектом "улица". Однако перепутал hasOne c belongsTo в результате получилась дикая структура, в которой улица принадлежит банкомату, а не банкомат улице. И все это работало без вопросов пока не нужно было переместить банкомат или переименовать улицу.
michael_vostrikov
04.10.2019 10:16результирующие отношения получаются не нормализованными. Хотя с точки зрения объектного анализа все может выглядеть достаточно правдоподобно.
перепутал hasOne c belongsToЭто не проблема объектного анализа, это проблема непонятных названий в ORM. Связи между объектами всегда должны быть те же самые, что и связи соответствующих таблиц по ключам, потому что первичный ключ это и есть ссылка на состояние объекта, так же как и указатель в оперативной памяти программы.
mayorovp
04.10.2019 10:32Да нет, именно эти названия-то как раз предельно понятные. Для того кто знает английский и знает о существовании обоих понятий.
michael_vostrikov
04.10.2019 12:46Речь скорее об их назначении, о том, что они делают внутри фреймворка. Когда есть один hasOne и указываются конкретные поля, все просто и понятно. А когда их 2 с похожим смыслом, то уже не очень. belongsTo это тоже своего рода hasOne, да и по названию я бы предположил, что
Street belongsTo ATMозначает, что ATM главная сущность, и у него будет полеstreet_id.mayorovp
04.10.2019 13:15Один hasOne невозможен, ведь обратное отношение не может быть тоже hasOne.
да и по названию я бы предположил, что Street belongsTo ATM означает, что ATM главная сущность, и у него будет поле street_id
Но почему? Street belongs to ATM переводится как "улица принадлежит банкомату". Но в таком случае у неё должен быть atm_id.
michael_vostrikov
04.10.2019 14:41ведь обратное отношение не может быть тоже hasOne
hasOne и hasMany достаточно для моделирования всех видов связей. Для связи один-к-одному оба будут hasOne.
// atm.street_id <=> street.id ATM hasOne(Street::class, ['id' => 'street_id']) Street hasMany(ATM::class, ['street_id' => 'id'])
А вот так было сделано в обсуждаемом примере
// atm.id => street.atm_id ATM hasOne(Street::class, ['atm_id' => 'id']) Street hasOne(ATM::class, ['id' => 'atm_id'])
Сразу видно, что поля как-то не так расположены, и что где-то должен быть hasMany.
Но почему? Street belongs to ATM переводится как "улица принадлежит банкомату".
Улица принадлежит банкомату, значит банкомат имеет улицу, так же как имеет ширину и высоту, значит и street_id должен быть в списке атрибутов банкомата.
mayorovp
04.10.2019 15:01Для связи один-к-одному оба будут hasOne.
has — это отношение владения. Владение не может быть циклическим, кто-то обязан быть главнее.
Улица принадлежит банкомату, значит банкомат имеет улицу, так же как имеет ширину и высоту
Нет, это значит что банкомат имеет улицу как дочерний объект.
michael_vostrikov
04.10.2019 17:29-1has — это "имеет". ATM имеет одну улицу. Мы же связь описываем, она принадлежит в равной степени обоим частям.
Когда у банкомата есть street_id, street это тоже дочерний объект.
mayorovp
04.10.2019 18:31Представим, что мы удаляем банкомат. Что произойдёт с улицей? Да ничего.
Представим, что мы удаляем улицу. Что произойдёт с банкоматом? Его тоже придётся удалить (ну, или отменить удаление улицы).
Вот и получается, что улица has банкомат, а банкомат belongsTo улица.
А вы в своих рассуждениях путаете саму улицу и её идентификатор.
michael_vostrikov
04.10.2019 19:24Техническую сторону я знаю) Я говорю, что has это слишком общее слово, оно подходит для обоих концов связи, поэтому может кого-нибудь запутать (меня например). Если бы там было ownsOne и belongsTo, тогда было бы понятнее, а лучше has с явным указанием полей. В тех же терминах, в каких связи называются (one и many).
Идентификатор и предназначен для представления улицы, в высокоуровневых языках указатели на другие сущности вообще скрываются от разработчика и заменяются понятием "ссылочный тип". По крайней мере я привык представлять их как одно и то же, если речь не о деталях реализации.
mayorovp
04.10.2019 19:40Ну так street_id — это ж и есть деталь реализации. В объектной модели этого свойства может вообще не быть.
michael_vostrikov
04.10.2019 20:16Ну мы же говорим про принадлежность сущностей, поэтому мне кажется разделять их неправильно, id означает саму сущность и не может иметь другие логические характеристики.
DrunkBear
03.10.2019 17:45+1Из того, что видел:
— У нас ORM! Оно само всё сделает, а для скорости включим кэш. SQL не нужен!
В итоге:
1. При старте приложения ORM начинает кешировать объекты и их свойства. Пара млн объектов + 10 свойств на объект + связи объектов ( тоже со свойствами), всё это в кеше = OOM на слабом железе (win x32) и тормоза при загрузке. «А нам не говорили, что там будет несколько миллионов объектов, на паре тысяч всё ок было!»
2. Изменение 1 свойства и сохранение приводит к чему? Правильно, весь кеш выливается обратно на сервер. Да, ORM заботливо льёт обратно пару миллионов * 10 свойств объектов в БД, БД заботливо обновляет, перестраивая индексы таблиц, снаружи это выглядит как 2минутная медитация у компьютера. омм… омм… ООМ…
Поэтому пусть лучше знают и SQL, и зачем нужны оптимизаторы, и как работает GC — не то, чтоб это было нужно с первых минут работы, но сэкономить неделю размышлений «а чойто оно такое делает и почему не делает что нужно?» вполне может.mayorovp
03.10.2019 18:51Это какая-то очень странная ORM, если весь кеш выливается на сервер… Да и загрузка всех объектов при старте тоже из ниоткуда не возьмётся.
Там, похоже, поверх ORM ещё и своих велосипедов нагородили.
badstarosta
02.10.2019 19:22По поводу опроса: я на собеседованиях спрашиваю SQL как опцию. Знает — хорошо, не знает — базовым вещам научим.
Dimtry44
02.10.2019 19:35Железобетонного ответа на вопрос, нужен ли сегодня начинающему web backend девелоперу SQL
Я думаю что ответ достаточно прост. Хорошему/амбициозному нужен, обычному без особой разницы.

hengenvaarallinen
02.10.2019 20:08+5Искали разработчика. В тестовом задании помимо прочего нужно было создать бд для объектов и комментариев к ним. Один товарищ прислал базу такого вида: Для каждого объекта отдельная таблица (объект1, объект2, объект3), в которых первая запись — данные об объекте, вторая и последующие — комментарии.
Так и не поняла, что это было. Даже жалею, что не позвала на собеседование — так и осталась эта структура бд для меня загадкой.
Ahen
03.10.2019 01:41+1Примерно такую структуру использовал в своём первом проекте, для каждого пользователя создавал отдельную табличку, то был отпечаток гайда по написанию текстовой игры с бд на файлах (и там это звучало правдеподобно — даёшь отдельный файл каждому игроку), мне тогда кто-то сказал что файлы это сакс, ну я и переложил лучшие практики из гайда на мускул. Благо пользователей моего сервиса было всего два — я и я, ну и было мне тогда 14 лет.
catharsis
03.10.2019 02:21Я картинку в подпись на форуме делал, которая каждому читающему показывала что-то своё.
Быстро заметил, что 1500+ таблиц обновляются как-то медленно.
Ну, попробовать стоило :)
pae174
03.10.2019 13:06> Так и не поняла, что это было
Это была база данных в текстовых файлах. Такое в качестве примера дается в книжках «PHP за 24 часа» в разделе «операции с файлами».hengenvaarallinen
03.10.2019 13:16Все бы ничего, но это было в mySql. Но да, пока писала коммент, тоже подумала, что возможно товарищ какие-то не реляционные решения пытался натянуть


un1t
02.10.2019 21:02+1Мне не нравиться тенденция, что все ломятся в IT.
Везде многочисленные курсы, школы, как стать программистом за 2 месяца. И видимо у них есть клиенты.
Один раз разговаривал с 39-летней женщиной, дак она тоже пошла учиться на программиста в универ. Можете представить мое удивление.
В принципе тут нет ничего плохого. Если зарплаты IT превышают зарплаты в других отраслях, это логично.
Но лично для меня это не очень. Т.к. одно дело, когда ты программист, а другое дело, когда ты «еще один программист».
Круто когда ты умеешь делать что-то, что не умеют другие. А если теперь все будут программисты, — скукота.
mephius Автор
02.10.2019 21:10По моим наблюдениям это очень локализованная тенденция, как раз в той географии, где зарплаты программистов сильно превышают зарплаты в других отраслях. Но прилично мешает, в найме например.
un1t
02.10.2019 21:19> где зарплаты программистов сильно превышают зарплаты в других отраслях.
ну так это большая часть мира — пост советские страны, восточная европа, индия, китай и т.п.mephius Автор
02.10.2019 21:42Насчет Китая не уверен, там зарплаты у программистов повыше, чем в других отраслях, но не катастрофически. Преподаватель английского там в среднем зарабатывает больше, чем программист. Плюс там культурно престижнее быть артистом или чиновником например.
Индия — да, но исторически они гораздо раньше пост советских стран начали развивать и экспортировать IT услуги, у них «войти в IT» уже устаканилось и сбалансировалось. Где-то мне еще попадалась информация о том, что тамошние крупные IT компании объединились в картель с целью не допустить роста зарплат разработчикам, особенно начинающим.
c3gdlk
02.10.2019 22:12Задач в айти много, больше чем может решить текущее количество разработчиков. Приток новых кадров демпингует нижние позиции и мотивирует тех кто способен двинуться дальше и освоить что-то новое. И так дальше по цепочке. В итоге выиграют все кроме тех кто не хочет развиваться, но это пррименимо не только к IT а к рынку в целом

Kanut
02.10.2019 23:08+1Мне не нравиться тенденция, что все ломятся в IT.
Ломятся, потому что людей не хватает и порог вхождения ниже чем во многих других специальностях. И программирование оно разное бывает и на мой взгляд для любого уровня понимания/умения можно найти свои задачи и свои зарплаты.
Круто когда ты умеешь делать что-то, что не умеют другие. А если теперь все будут программисты, — скукота.
Это вопрос терминологии и во многих странах/языках уже сейчас есть более-менее устоявшиеся наименования для разных уровней/типов программирования. И думаю что это ещё дальше будет идти в этом направлении.
П.С. А на тему статьи: пока более-менее активно используются релациональные БД, бэкендеру надо хоть немного понимать SQL. Потому что во первых очень велика вероятность что рано или поздно, но ты с SQL в своей профессиональной жизни столкнёшься в том или ином виде. А во вторых, понимая как работают БД, и хороший/оптимальный бэкенд писать проще.
arheops
03.10.2019 03:46Ну так подождите, программистов станет столько, что у них зарплата будет всего в два раза больше, а не в 10, тогда всем опять будет влом учится на программиста.
А вообще нормальные люди просто получают больше вайтишников и будут получать еще больше со временем. Ибо бизнесу нужны работающие решения, а не чтото, что работает только на тестовой базе и ложит mysql уже через неделю продакшена, причем переписать быстро — нельзя.Kanut
03.10.2019 10:29Если вы возьмёте какую-нибудь Западную Европу, то тут давно уже зарплаты у айтишников устаканились примерно на уровне инженера или даже просто человека с высшим "техническим" образованием. Ну может быть в среднем они чуть выше, но не на много.
И всё равно куча людей идёт в ИТ потому что как минимум сейчас работу можно найти вообще без проблем и похоже в ближайшее время это не изменится.

A114n
03.10.2019 17:41Дело не в работе, а в возможностях, которые даёт эта работа.
Много вы инженеров видели, которым разрешено удалённо работать?
Хотя казалось бы они теперь тоже на за кульманом чертят, а за компьютером.Kanut
03.10.2019 18:00Ну у нас(Германия) и у айтишников удалённая работа не то чтобы особо распространена/популярна. Так что это имеет свои региональные особенности.
А народ всё равно в ИТ толпами идёт.
A114n
03.10.2019 18:07Ну может вы и правы. В Голливуд тоже люди толпами идут, хотя звёздами становятся единицы.
mad_nazgul
03.10.2019 06:59+1Расслабтесь в 90-е точно так же куча народа шла в экономисты, менеджеры и юристы.
Но потребности в хороших специалистах (экономисты, менеджеры, юристы) меньше не стало.
В принципе в Индии это прошли в начале 0-х.
Когда «бодишопы» брали «в ИТ» кого попало с улицы.
Но это не помешало буму «в ИТ» в восточной Европе. :-)

GarrySeldon
03.10.2019 00:53Не понимаю как можно программировать не зная какие выполняются запросы? Такой ерунды можно наделать, простой пример: нам надо получить список элементов, скажем наименование статей, а так же получить к этим элементам информацию из других таблиц, пусть это будут авторы. Из одной коротенькой строчки кода может получиться совершенно разный результат, в обоих случаях всё будет работать. Только в одном варианте будет сделано два запроса, а в другом 1+количество элементов (статей). Здесь подробнее.
Очень часто без сложных запросов с подзапросами просто не обойтись и тут ORM не спасёт.
zabtech
03.10.2019 05:30В веб-разработке далеко не все задачи можно решитъ возможностями Doctrine или Eloquent. Как толъко дело касается работы с теми же геоданными, требуется умение написатъ raw запрос для spatial, и здесъ от разработчика нужно хотя бы понимание в какой последователъности писатъ SELECT, FROM, WHERE.
Fedorkov
03.10.2019 11:02+5Современные студенты предпочитают учиться по YouTube
Не понимаю, как можно учиться по такому медленному источнику, да ещё с последовательным доступом.
Пропустить абзац воды в тексте или наоборот, перечитать какую-то сложную формулировку гораздо проще, когда весь текст перед глазами. А если текст есть в электронном виде, я могу моментально найти все места в книге, где упоминается какое-то понятие, не переслушивая весь курс.oldbie
03.10.2019 12:23+1Не первый раз вижу это утверждение, но слабо представляю это на практике. Хотелось бы посмотреть на на такие каналы или еще лучше гайд как пользоваться youtube для самообразования. Если кто-то знает — поделитесь.

foxcode85
03.10.2019 16:13+1Комрад Fedorkov кстати правильную вещь сказал. Ютуб хорош лишь в том, что там инфа может быть актуальной. Ну и конечно, для многих(для меня в том числе) проще визуально усваивать информацию, а не читать сухой текст.
НО! Книга, тем более электронная — это как SQL база со связанными списками. Ты можешь быстро сделать выборку по названию в оглавлении, Перейти на связанную таблицу (тему) и т.д. А Ютуб как стэк — чтобы добраться до чего-то, придется разгребать то, что сверху.MTyrz
03.10.2019 16:38Ютуб хорош там, где к сугубо текстовому потоку информации надо добавить визуальный. Десять страниц инструкции убористым шрифтом с трудом заменят тридцать секунд ролика там, где речь идет о сборке-разборке механического узла.
Лучше один раз увидеть…foxcode85
03.10.2019 16:40+1Мы же говорим о программировании вроде. Но насчёт узла вы правы.
Fedorkov
03.10.2019 17:14А к новым языкам и фреймворкам всё сказанное относится десятикратно. Вот этот код я закоммитил на следующий день после того, как начал изучать Rust (с помощью оф. вики, StackOverflow и известной матери). Мне страшно даже представить, сколько времени у меня ушло бы разбираться со всем этим по видеолекциям.
foxcode85
03.10.2019 17:23Так я же и не спорю с Вами. Наоборот-согласен. Сам пишу третий день на Котлине и книжка + документация+ SO помогают, а те видео уроки что есть в Сети -дно в плане объема знаний. Но, стоит сказать что и книжки бывают не лучше видео.

Alexeyslav
04.10.2019 09:28Всё потому что с первого раза всё человек всеравно не усваивает, поэтому обучающий ролик прокручивается чуть ли не в фоне, озвучивая общую идею и вводя человека в курс. На первый раз, если вы в тему входите впервые, воспринимается едва ли не одно слово из 10. После просмотра обучающего ролика с «водой» уже можно хоть как-то ориентироваться в текстовом представлении того же курса, хотябы понимаете куда надо начинать смотреть, видите знакомые слова. К примеру, вы не сможете найти в книге упоминание какого-то определения если даже не в курсе как оно звучит. Потом, войдя в тему вы это сможете сделать.

minamoto
03.10.2019 11:31Не надо вам знать SQL, оставьте это профессионалам.
Если более развернуто, то бэкендеру в крупной продуктовой команде надо знать свою часть, за базу отвечают разработчики БД. Если компания небольшая, и выделенных разработчиков базы нет, то нужно знать, причем на достаточно неплохом уровне, т.к. с базовыми вещами справится и ORM, а вот когда начнутся просадки по производительности, то нужно будет переписывать узкие места на качественно написанном SQL, и тут базовых знаний не хватит. Ну или нанять разработчика БД, который будет этим заниматься.
Но это не отменяет возможности так называемого «T-shape» развития, когда, для понимания и нахождения общего языка с коллегами мы изучаем все понемногу.
Я лично, как разработчик БД, знаю понемногу и бэк и фронт, и это бывает в некоторых ситуациях полезно.
valis
03.10.2019 12:01-2У кого много SQL разработчиков можно писать GRUD операции в виде SQL процедур.
Тогда и ORM не нужен, базой занимаются профессионалы и бекедщики чуть больше сосредоточены на бизнес логике
stantum
03.10.2019 13:12+1Хорошее исследование и оптимистичные выводы. С автором поста согласен, а вот исследование SlashData хотел бы покритиковать. На собственном опыте: у меня нет аккаунтов ни на Github, ни на StackOverflow, ни на npm. А поскольку я контрактор, то и в евросоюзовские данные о трудоустройстве, скорее всего, не попадаю. Уверен, что у многих подобная ситуация. Вот и получается, что они прозевали существенный процент разработчиков.
Писал я все это на БК 010-01, там был вильнюсский бейсик, он же BASIC-86 и фокал. Эх.
Рад встрече, коллега!
apapacy
03.10.2019 13:39Возник вопрос может быть кто-нибудь подскажет.
Сейчас многие ORM польуются для определения связей между объектами/таблицами такими определениями как belongsTo, hasOne, hasMany, manyToMany — но я недавно нашел первоисточник в котором эти слова были впервые определены именно в такой форме. Но сейчас уже не могу найти ссылку. Может быть кто-нибудь подскажет где это впервые было реализовано или описано?
ArXen42
03.10.2019 14:18Возможно Entity-relationship model.
apapacy
03.10.2019 15:15Ну это логика явления. Я имел в виду что есть источник на котором были впервые применены вот эти имена типа belongsTo. Или reversedBy. Кстати на мой взгляд довольно неудачные.
korsarer
03.10.2019 14:46А почему на этом графике нет C/C++? Хотя написали про них абзацем выше.

apapacy
03.10.2019 15:11Насколько я понял это не языки а фреймворк и
mephius Автор
03.10.2019 15:30На картинке фреймворки, а не языки. Причем когда речь о JavaScript, Python или Java в большинстве случаев выбор фреймворка определяет то, как будет построено приложение. В C++ исторически сложился подход, когда в основном предоставляются библиотеки, а не фреймворки, поэтому на графике их и нет.
mayorovp
03.10.2019 17:09Всё равно странная картинка.
.NET Core — так себе фреймворк, больше почему-то на рантайм похож
Node.js — то же самое
ASP.NET WebForms и ASP.NET MVC куда-то пропали. Вот не верю, что с них уже все на ASP.NET Core свалили, но при этом на ASP всё ещё пишут!mephius Автор
03.10.2019 17:29В целом согласен, из питона там только Django, PHP-шных фреймворков вообще нет. И, кстати, эта картинка из параграфа про студентов, а данные из репорта HackerRank «2018 Student Developer Report»:
A total of 10,351 student developers completed the 10-minute online survey from October 16 to November 1, 2017.
То есть тут точность серьезно ниже, чем у SlashData.
Ну и у меня есть гипотеза, что когда интервьюируют человека на ASP.NET MVC приложение, спрашивают .NET Core и чем оно отличается от .NET Framework и отдельно про MVC и как оно реализовано в .NET (Core|Framework). Вполне может привести к тому, что все упадет в колонку .NET Core. На интервью PHP-шника будут спрашивать про PHP и меньше уделать внимания конкретному фреймворку. Этим может объясняться перекос в данных.
Sindicollo
03.10.2019 18:23Ага, странная, почему то AngularJS (это который 1.0) есть, а Angular (2.x) — отсутствует

A114n
03.10.2019 17:47В Access уже десятки лет встроен конструктор запросов, и офисные сотрудники с ним прекрасно работали, не зная SQL.
Мне кажется, что это вопрос исключительно уровня задач.
Если задачи можно решать с помощью конструкторов — пусть решают их с помощью конструкторов. Если нужно залезть глубже — найдут человека, который может залезть глубже.PowerMetall
04.10.2019 08:31+2В Access уже десятки лет встроен конструктор запросов, и офисные сотрудники с ним прекрасно работали, не зная SQL
Вот так я, будучи «уженешкольником» (студетном-первокуром) и активно используя MS Access в универе на лабе, впервые увидел SQL, случайно нажав кнопку «режим SQL».
Поковырявшись чутка, выпросил Интернета у лаборантки, чутка погуглил, охренел от дивного нового мира…
Вот так оно и понеслось с тех пор ))

olezh
03.10.2019 17:53Я бы вопрос сформулировал иначе: профессиональный рост обязательно ли подразумевает превращение бэкэнд-разработчика в dba?
В моей практике написание sql-запросов занимало в лучшем случае 10% времени от всей работы, и идя собеседоваться лучше порешать задачки на тему, работодатели не прощают ошибок в sql-запросахmephius Автор
03.10.2019 18:06идя собеседоваться лучше порешать задачки на тему, работодатели не прощают ошибок в sql-запросах
Возможно, не все работодатели сами могут пообщаться на более глубокие темы работы БД, поэтому придираются к синтаксису? Ладно еще поговорить про семантику where и having, но синтаксис?
apapacy
03.10.2019 19:04Я неявно под знанием SQL имел в виду прежде всего знание теории реляцинных баз данных. Просто знание SQL — это очень просто и как гласит история разрабтывался даже не для сеньоров которые мечтают о погонах dba, а для пользователей. И это даже попало в американский кинематограф как на каком-то доисторическом терминале разведчик забивает некий текст и ему выводится табличка с данными.
Mogwaika
Я не знаю, что такое ORM, но какие скилы нужны начинающему web backend девелоперу в итоге? SQL самый важный навык?
А их точно не становится просто меньше, а не только в процентном отношении, если раньше это была необходимость и теперь трудоустраиваются специалисты которым это было нужно, не будет ли сейчас ситуации, что просто мало кому нужно этому учиться и работодателю дешевле будет кэш ускорить/увеличить на порядок?
mephius Автор
ORM — Object-Relational Mapping, в современных фреймворках предоставляет программисту способ обращаться к стораджу (базе данных) используя синтаксис языка и реляционные связи между объектами, абстрагируя конкретную базу данных. Т.е. ORМ за программиста сгенерирует и исполнит запрос к БД, предоставляя программисту интерфейс к эдакой виртуальной объектной БД.
Таком образом, без SQL можно вполне обойтись. Но я считаю, что эти знания определенно нужны, потому что использовать ORM без понимания того, какие запросы он сгенерирует и как они будут исполняться, это примерно как стрелять из ружья не зная, какой стороной к тебе оно повернуто.
Из источников, которые удалось найти, этого однозначно не видно. Я сам скорее склоняюсь к мнению, что нет, в абсолютных числах меньше не становится, периодически встречаю людей с опытом в 2-3 года, но хорошо ориентирующихся в этой области, и их вроде бы достаточно.
dasFlug
Я что-то сомневаюсь что получится. Можно попробовать собрать личную статистику использования ORM участниками. Я, например, знаю с десяток серьезных проектов использующих Hibernate. Практически везде дело дошло до custom queries. По разным причинам, но в основном чтобы улучшить производительность.
mephius Автор
В моей практике всегда происходило так же.
dporollo
C custom queries гораздо проще и быстрее работать, если очень хитроумные запросы.
Такое хоть и редко, но встречается.
apapacy
Работаю с sequelize (node.js) Проактически все проекты содержат если не полностью raw запросы то по крайней мере литералы(фича sequelize для встраивания raw фрагментов в запрос) в условиях where.
Настколько я просматривал проекты на symfoby/doctrine — там практически все запросы, кроме самых простых идут на dql, который является зераклом sql, только с очень слодным для чтения синтаксисом.
max_mustermann
Для «web backend» 99.9% работы с базой — это CRUD-ы. Что там заменять на сustom queries?
Kanut
Если у вас более-менее сложные структуры данных и их надо в таком виде "тащить", то у вас очень быстро простейшее чтение из DB превращается в кучу джойнов. Или например апдейт идёт "логически"на несколько таблиц за раз.
И иногда ORM не справляются в том плане что создают совсем не оптимальные запросы.
П.С. И я например думаю что большинство из тех кто работал с тем же NHibernate хотя бы раз, но натыкался на "Select n+1 проблему" :)
max_mustermann
А в sql написаном руками эта куча join как-то магически не появится?
А иногда наоборот, генерируют sql гораздо более оптимальный чем написаный руками.
Ну это очень детская ошибка. Всё, о чём она говорит, это то, что ORM не полностью избавляет от необходимости думать что делаешь.
Kanut
С этим я и не спорю. Речь о том что иногда ORM генерирует не особо оптимальные запросы и тогда нужна кастомизация в том или ином виде. Иногда и в виде SQL написанного вручную.
Ну и иногда бывают какие-то хитрые "хотелки" и/или какие-то не зависящие от тебя ограничения и приходится просто проперти вручную мэппить через кастомный SQL.
И это всё конечно редкости, но более-менее крупные проекты с ORM и без "кастома" я пока ещё тоже не встречал.
max_mustermann
Да, разумеется и с этим никто не спорит. Иногда это требуется и иногда в «более-менее крупных» проектах можно позвать матёрого базовика с бородой и в растянутом свитре который сделает какую-то хитрую агрегацию, завернёт её в хранимку и всё полетит.
А рядовой гребец «начинающий веб бекэнд» этот pure sql и в глаза не увидит. О чём, собственно, и шла речь.
Kanut
Хм, а это тогда что было:
?
tonad
Пришел к выводу, что перед тем как пользоваться ORM, нужно хорошо узнать SQL. А иначе будет полно этих самых детских ошибок
dasFlug
CUD — обычно ничего. В R регулярно вылазили проблемы с нетривиальными агрегатами и composite objects. Поэтому альтернативы типа MyBatis с тулами для генерации boilerplate запросов для CUD частенько смотрятся предпочтительней. Например не надо еще и HQL знать.
dporollo
ORM это хорошо, легко и просто, ровно до тех пор, пока вы не задумываетесь о скорости. Я знаю, что можно создать практически любой запрос, но повторюсь, если вы думаете о скорости, то это однозначно чистый SQL.
vassabi
скорость и еще память — ORM даже если будет в проекции брать данные из БД (а не весь объект создавать), то все равно не так эффективно, как сделать все промежуточные расчеты в SQL, а потом вернуть готовый результат (например — суммы продаж по месяцам с учетом размера, цвета и т.д.)
mayorovp
А что помешает описать промежуточные расчёты на языке ORM, чтобы дальше библиотека их в SQL транслировала?
Kanut
Вот у меня тоже этот вопрос возник. Тот же NHibernate вполне себе умеет создавать динамические запросы, которые из LINQ генерируют нужный SQL в тот самый момент, когда нужны данные.
П.С. А учитывая что он ещё сам всё может более менее грамотно кэшить, то и число запросов к БД заметно уменьшается.
vassabi
ну, кешить можно и при использовании native SQL
Kanut
Можно. Но для этого уже нужна определённая экспертиза в SQL и базах данных в целом. А она есть далеко не у каждого джуниора/миддла. Да и у сениоров наверное тоже не у всех.
А так вам нужно парочку экспертов по вашей ORM, которые её настроят для всех и будут время от времени мониторить производительность и проблемы. А все остальные могут ей просто пользоваться.
vassabi
Если на ORM вашего ЯП\фреймворка можно написать джойн нескольких таблиц в комбинациях с группировкой (сначала таблица джойнится сама с собой, потом считаются суммы, а потом результат еще раз джойнится со справочными таблицами и получившееся группируется по датам), и возможной перестановкой полей в select — то не вопрос.
Kanut
Естественно у ORM есть свои границы. Но в 99% "обычных" бизнес-логик их хватает за глаза и за уши.
И я бы сказал что ваш пример тот же NHibernate вполне осилит. То есть выполнить он его точно выполнит и вопрос только в том насколько оптимально. Может быть простого LINQ уже не хватит и надо будет немного "поковыряться".
Ну и в крайнем случае ORM обычно имеют возможность добавлять свои плагины/расширения или даже просто использовать кастомные запросы в "чистом" SQL.
apapacy
Скорость скорости рознь. Например в symfony/doctrine (которую я по многим параметрам считаю наиболее совершенной ORM не только внутри экосистемы PHP) в течение одного запроса несколько запросов на изменения данных собираются в единый пакет и одним запросом только по реально измененным полям отправляются на сервер. То есть если разрабатывать нечто аналогичное на уровне приложения это будет очень громоздко. А если вделать несколько запросов пусть даже и RAW SQL — тут еще неизвестно какой из вариантов будет производительнее.
max_mustermann
Существует довольно широкий и распространённый класс задач, где ORM(например EF), благодаря expression tree и change tracking оказывается сильно быстрее чем «чистый» SQL, написаный руками.
Mogwaika
А если вопрос стоит по другому, джуниор знает sql, но не знает язык для бэкенда или знает язык, но не знает sql?
Или необходимое условие для вас, чтобы знал оба?
mephius Автор
Если это вопрос ко мне, то я поговорю с этим джуниором в целом про алгоритмы, структуры данных, теорию множеств. Если там окажется все хорошо, то велика вероятность, что недостающее он легко освоит и джуниором можно брать.
Mogwaika
А это вот прям часто используется? Почему не аналитическая геометрия/статистика/вычматы?
Кароч, какие алгоритмы/структуры/множества надо ботать тем, кто хочет сменить специализацию?
mephius Автор
То, что я перечислил, это простой способ выяснить, насколько человек легко будет способен разобраться в БД, даже если прямо сейчас он не знаком ни с одной.
Mogwaika
Ну может ему одинаково просто разобраться и с обходом деревьев и с БД, если это понадобится, но на собесе он не ответит на такой вопрос без гугла?
Kanut
На мой взгляд если ты хоть немного понимаешь что такое SQL и релациональные БД в целом, то это видно даже если ты вообще забыл синтаксис SQL.
Более того если человек нормально соображает, то это тоже обычно видно. То есть от сениора/миддла естественно требуется больше, а для джуниора/практиканта во многих фирмах может и этого хватить.
mephius Автор
Может с перепугу забыть определения и формулировки, но и без гугла можно порисовать на бумажке операции над множествами при помощи диаграмм Венна:


или на бумажке же найти декартово произведение:
Отсюда уже недалеко до джоинов в терминах SQL или до модели данных какой-нибудь простой задачи в реляционной БД.
Формулировки и определения нужны для экономии время при разговоре, но можно обойтись и без них, если видно, что человек просто волнуется.
ilnoor
Я считаю, что лучше обойтись без ORM.
Потому что ORM в каждом языке свой, и часто не один. И часто опыт с одного на другой переносить нельзя.
А SQL везде один и тот же, различия в диалектах незначительны.
mephius Автор
Этот кэш работодателю просто так не ускорить, потому что тут речь о физическом кэше процессора.
Dimtry44
Лучше не придумаешь, хороший пример в подтверждении статьи.
gbg
Если только не начать гонять электроны по шинам веником.
Mogwaika
Посмотрите на мобильники и их софт, все давно забили на эффективный код, экономически выгоднее запустить код, написанный на неделю раньше конкурента на новейшем смартфоне с восемью гигами оперативки.
А обзорщики потом замеряют на какой модели приложение секунду запускается, а на каком полторы на многоядерном процессоре…
Fedorkov
Это потому что смартфоны появились недавно. А вот десктопы уже приблизились к концу закона Мура, поэтому у винды системные требования не меняются уже 10 лет (Win7, Win10), а про другие системы я вообще молчу.