
— How big a cluster do I need?
— Well, it depends… (злобное хихиканье)
Elasticsearch — сердце Elastic Stack, в котором происходит вся магия с документами: выдача, приём, обработка и хранение. От правильного количества нод и архитектуры решения зависит его производительность. И цена, кстати, тоже, если ваша подписка Gold или Platinum.
Основные характеристики аппаратного обеспечения — это диск (storage), память (memory), процессоры (compute) и сеть (network). Каждый из этих компонентов в ответе за действие, которое Elasticsearch выполняет над документами, это, соответственно, хранение, чтение, вычисления и приём/передача. Поговорим об общих принципах сайзинга и раскроем то самое «it depends». А в конце статьи ссылки на вебинары и статьи по теме. Поехали!
Эта статья основана на материалах вебинара Дэвида Мура «Sizing and Capacity Planning». Его рассуждения мы дополнили ссылками и комментариями, чтобы было чуть понятнее. В конце статьи бонус-трек — ссылки на материалы Elastic для тех, кто хочет лучше погрузиться в тему. Если у вас хороший опыт работы с Elasticsearch, пожалуйста, поделитесь в комментариях как проектируете кластер. Нам и всем коллегам было бы интересно узнать ваше мнение.
Архитектура Elasticsearch и выполняемые операции
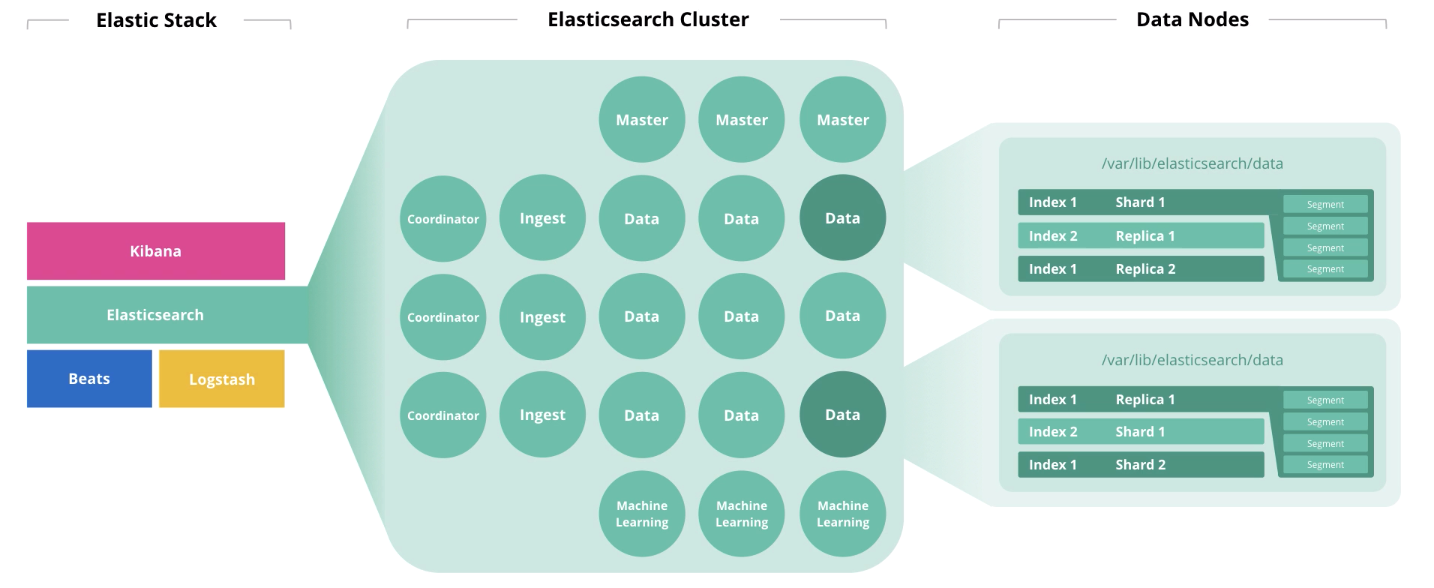
В начале статьи мы говорили про 4 компонента, формирующие аппаратное обеспечение: диск, память, процессоры и сеть. На утилизацию каждого из этих компонентов влияет роль ноды. Одна нода может выполнять сразу несколько ролей, но с ростом кластера, эти роли должны быть распределены по разным нодам.
Master-ноды выполняют контроль за работоспособностью кластера в целом. В работе master-нод должен соблюдаться кворум, т.е. их количество должно быть нечётным (может быть 1, но лучше 3).
Data-ноды выполняют функции хранения. Для повышение производительности кластера, ноды нужно разделить на «горячие» (hot), «тёплые» (warm) и «холодные» (frozen). Первые предназначены для оперативного доступа, вторые для хранения, а третьи для архива. Соответственно, для «горячих» разумно использование локальных SSD-дисков, а для «тёплых» и «холодных» подойдёт массив HDD локально или в SAN.
Для определения объёма памяти нод для хранения, Elastic рекомендует пользоваться следующей логикой: «горячие» > 1:30 (30Гб дискового пространства на каждый гигабайт памяти), «тёплые» > 1:100, «холодные» > 1:500). Под JVM Heap не более 50% общего объёма памяти и не более 30Гб во избежание набега garbage collector. Оставшаяся память будет использована как кэш операционной системы.
На утилизацию ядер процессоров в большей степени влияют такие показатели производительности инстанса Elastisearch как thread pools и thread queues. Первые формируются на основе тех действий, которые выполняет нода: search, analyze, write и другие. Вторые являются очередью из соответствующих запросов различных типов. Количество доступных для использования процессоров Elasticsearch определяет автоматически, но в настройках можно указать это значение вручную (может быть полезно когда у вас на одном хосте запущено 2 и более инстанса Elasticsearch). Максимальное количество thread pools и thread queues каждого типа можно задать в настройках. Показатель thread pools — это основной показатель производительности Elasticsearch.
Ingest-ноды принимают на вход данные от сборщиков (Logstash, Beats и т.д.), выполняют преобразования над ними и записывают в целевой индекс.
Ноды Machine learning предназначены для анализа данных. Как мы писали в статье о машинном обучении в Elastic Stack, механизм написан на С++ и работает за пределами JVM, в которой крутится сам Elasticsearch, поэтому разумно выполнять такую аналитику на отдельной ноде.
Coordinator-ноды принимают поисковый запрос и маршрутизируют его. Наличие такого типа нод ускоряет обработку поисковых запросов.
Если рассматривать нагрузку на ноды в разрезе инфраструктурных мощностей, распределение будет примерно таким:
| Нода | Диск | Память | Процессор | Сеть |
| Master | v | v | v | v |
| Data | ^^ | ^ | ^ | > |
| Ingest | v | > | ^ | > |
| Machine Learning | v | ^^ | ^^ | > |
| Coordinator | v | > | > | > |
| ^^ — очень высокая, ^ — высокая, > — средняя, v — низкая | ||||
Дальше мы приведём 4 основных типа операций в Elasticsearch, каждая из которых требует определённого типа ресурсов.
Index — обработка и сохранение документа в индексе. На схеме ниже представлены ресурсы, используемые на каждом из этапов.
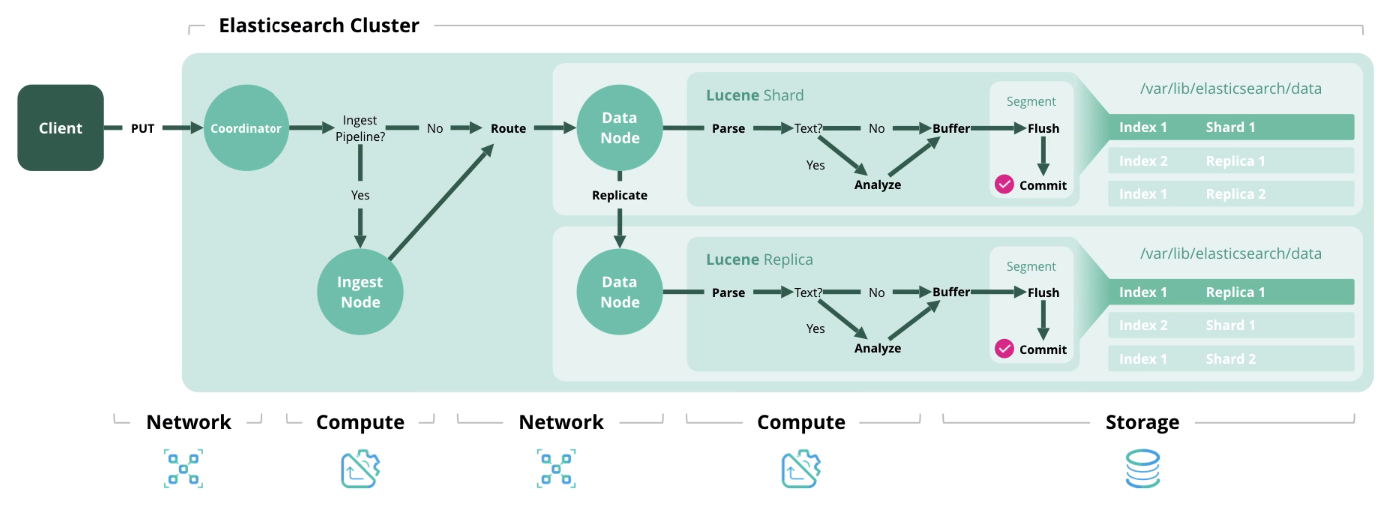
Delete — удаление документа из индекса.
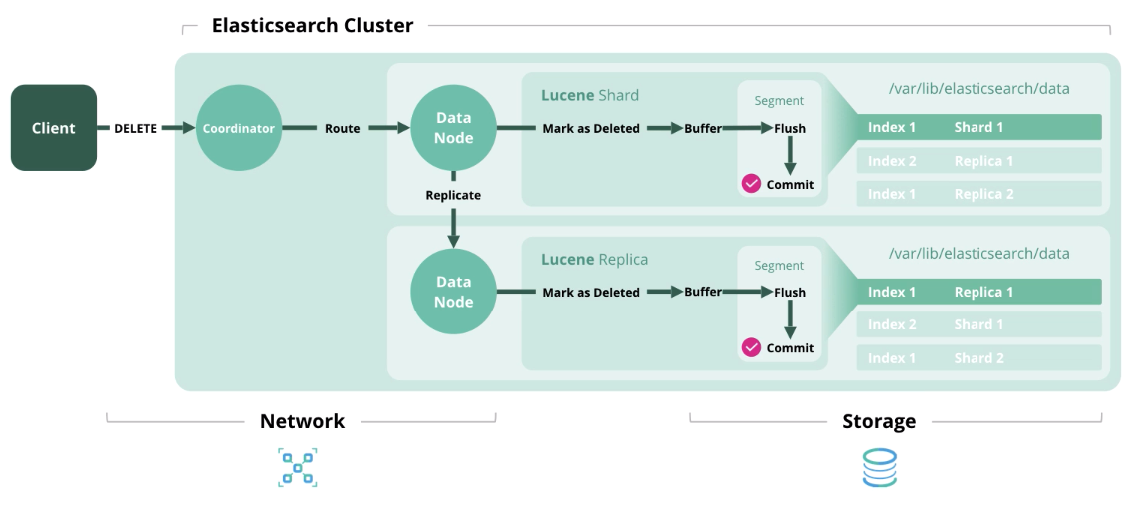
Update — работает как Index и Delete, потому что документы в Elasticsearch неизменны.
Search — получение одного или более документов или их агрегация из одного или более индексов.
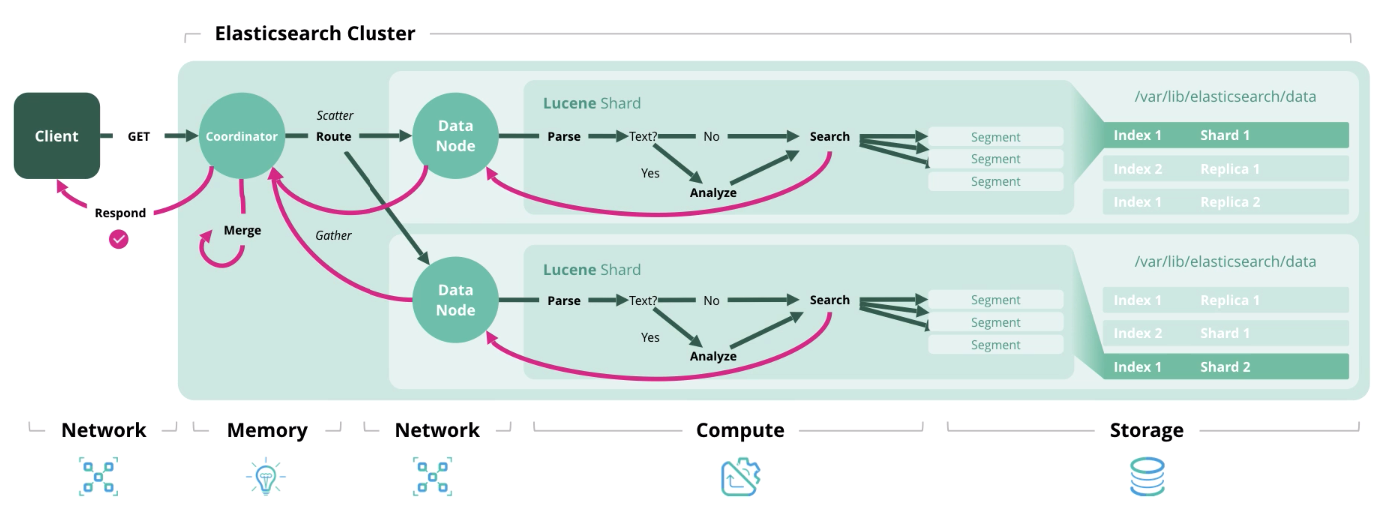
С архитектурой и типами нагрузки разобрались, теперь перейдём к формированию модели сайзинга.
Сайзинг Elasticsearch и вопросы перед его формированием
Elastic рекомендует использовать две стратегии сайзинга: ориентированную на объём хранения и на пропускную способность. В первом случае первостепенное значение приобретают дисковые ресурсы и память, а во втором память, процессорная мощность и сеть.
Сайзинг архитектуры Elasticsearch в зависимости от объема хранения
Перед проведением расчётов получим исходные данные. Нужно:
- Объём сырых данных в день;
- Период хранения данных в днях;
- Фактор трансформации данных (json factor + indexing factor + compression factor);
- Количество шард репликации;
- Объём памяти дата-ноды;
- Соотношение памяти к данным (1:30, 1: 100 и т.д.).
К сожалению, фактор трансформации данных вычисляется только опытным путём и зависит от разных вещей: формата сырых данных, количества полей в документах и т.д. Чтобы это выяснить, нужно загрузить в индекс порцию тестовых данных. На тему таких тестов есть интересное видео с конференции и дискуссия в коммьюнити Elastic. В общем случае можно оставлять его равным 1.
По умолчанию, Elasticsearch сжимает данные по алгоритму LZ4, но есть и DEFLATE, который жмёт на 15% сильнее. В общем можно добиться сжатия 20-30%, но это тоже вычисляется опытным путём. При переключении на алгоритм DEFLATE возрастает нагрузка на вычислительные мощности.
Ещё есть дополнительные рекомендации:
- Заложить 15%, чтобы был запас по дисковому пространству;
- Заложить 5% на дополнительные нужды;
- Заложить 1 эквивалент ноды с данными для обеспечения быстрой миграции.
А теперь переходим к формулам. Ничего сложного тут нет, и, думаем, вам будет интересно проверить ваш кластер на соответствие этим рекомендациям.
Общее количество данных (Гб) = Сырые данные в день * Количество дней хранения * фактор трансформации данных * (количество реплик — 1)
Общее хранилище данных (Гб) = Общее количество данных (Гб) *(1 + 0,15 запаса + 0,05 дополнительные нужды)
Общее количество нод = ОКРВВЕРХ (Общее хранилище данных (Гб) / Объём памяти на ноду / соотношение памяти к данных + 1 эквивалент ноды данных)
Сайзинг архитектуры Elasticsearch для определения количества шард и нод данных в зависимости от объёма хранения
Перед проведением расчётов получим исходные данные. Нужно:
- Количество index patterns вы создадите;
- Количество основных шард и реплик;
- Через сколько дней будет выполняться ротация индексов, если вообще будет;
- Количество дней хранения индексов;
- Объём памяти на каждую ноду.
Ещё есть дополнительные рекомендации:
- Не превышайте 20 шард на 1 Гб JVM Heap на каждой ноде;
- Не превышайте объема дискового пространства шарды в 40 Гб.
Формулы выглядят следующим образом:
Количество шард = Количество index patterns * Количество основных шард * (Количество реплицированных шард + 1)* количество дней хранения
Количество нод данных = ОКРВВЕРХ ( Количество шард / (20 * Память на каждую ноду))
Сайзинг архитектуры Elasticsearch в зависимости от пропускной способности
Самый частый случай, когда нужна высокая пропускная способность —это частые и в большом количестве поисковые запросы.
Необходимые исходные данные для расчёта:
- Пиковое количество поисковых запросов в секунду;
- Среднее допустимое время ответа в миллисекундах;
- Количество ядер и threads на процессорное ядро на нодах с данными.
Пиковое значение тредов = ОКРВВЕРХ (пиковое количество поисковых запросов в секунду * среднее количество время ответа на поисковый запрос в миллисекундах / 1000 миллисекунд)
Объём thread pool = ОКРВВЕРХ (( количество физических ядер на ноду * количество threads на ядро * 3 / 2) +1)
Количество нод данных = ОКРВВЕРХ ( Пиковое значение тредов / Объём thread pool )
Возможно, не все исходные данные будут у вас на руках при проектировании архитектуры, но посмотрев вебинар или прочитав эту статью появится понимание, что в принципе влияет на количество аппаратных ресурсов.
Обращаем ваше внимание, что не обязательно придерживаться приведённой архитектуры (например, создавать ноды-координаторы и ноды-обработчики). Достаточно знать, что такая эталонная архитектура существует и она может дать прирост производительности, которого вы не могли добиться другими средствами.
В одной из следующих статей мы опубликуем полный список вопросов, на которые нужно получить ответы для определения размера кластера.
Для связи с нами можно использовать личные сообщения на Хабре или форму обратной связи на сайте.
Дополнительные материалы
Вебинар «Elasticsearch sizing and capacity planning»
Вебинар о планировании мощностей Elasticsearch
Выступление на ElasticON с темой «Quantitative Cluster Sizing»
Вебинар про утилиту Rally для определения показателей производительности кластера
Статья о сайзинге Elasticsearch
Вебинар об архитектуре Elastic stack
Комментарии (14)


iwram
09.10.2019 07:32Тоже используем elastic. Но пока не в таких больших объемах, в среднем по 30-40гб в сутки. Тема с горячими и холодными нодами- все про нее говорят, но как реализовать правильнее нигде не указано. Поэтому самым простым выходом из ситуации-это иметь кластер elasticsearch, который пишет боевые данные, например в течение месяца или двух- в зависимости от требований и наличия объема. А все остальные данные бэкапить используя snapshot на nfs диск. А потом в случае разбора каких то старых логов, восстановить на отдельный dev elasticsearch.
Еще не проверял, как можно сэкономить место на архивах snabpshot используя дедупликацию.

ghostinushanka
Я этого места ждал и, что неудивительно, дождался. Откровенно удивляет, что это можно увидеть в документации к версии 7.4, в то время как оно тянется ещё со времён эластика 2.5.
Мы переехали на Java11, используем 64-бит поинтеры и новый сборщик мусора, ограничиваем память JVM с помощью cgroup и хипе выдаём столько, сколько влезает оперативки с учётом ограничений, потому что запуск нескольких инстансов эластика на одной ноде (как написано в одном из документов с ответами на «а что делать, ведь сейчас сотни гигов оперативки не редкость») это добровольное поедание кактуса. «Been there, done that» как говорится.
Собираем и индексируем по 5+ ТБ данных в день, больше тысячи проиндексированных полей, до вышеописанного решения пришли опытным путём при переезде с 5-й на 6-ю версии. Написали себе свой сборщик бэкапов (на Go, выхлоп в json) потому что снэпшоты это всё тот же кактус.
Однажды, в далёкой, далёкой… параллельной реальности руки дойдут и время будет про всё это написать :)
therb1
Если это все еще есть в документации, то это значит что этот кейс работает для количества случаев приближенных к 100%.
Ваша же версия настройки эластика говорит о том что в вашем кейсе данная предосторожность не нужна.
Я сомневаюсь что такая большая компания как эластик забыла поправить документацию.
Мы тоже используем больше 32 GB heap, но тут четко нужно понимать для чего ты это делаешь и что поимеешь в каких случаях.
cv28
ghostinushanka чем ищете в бэкапах, если не секрет? Скриптами? Или это вообще никогда не бывает надо? Нам тут как-то понадобилось пойти на полгода назад, посмотреть каких кастомеров потенциально могло зацепить одной редкой проблемой…
ghostinushanka
зависит от кол-ва искомых данных и точности задачи
если вопрос уровня «в день Д, час Ч в интервале между 10й и 20й минутой надо вот этот сквозной идентификатор», то просто парсится json, на то он и json
если что-то типа «такого-то числа, примерно, клиент делал Х на платформе, а ща говорит что этого не было, и он вообще делал У», то берётся набор бэкапов и проигрывается (replay) в эластик для дальнейшего разбора
храним мы 14 месяцев, при дневном обьёме не сложно посчитать сколько это и во что бы обошелся «отмороженный» индекс
cv28
Спасибо. При этом под «бэкапом» понимается зип, в котором лежит текстовый файл с экспортированными в json всеми документами за определенный период времени или что-то другое?
Вопрос не праздный, я поясню. Была сереьезная разборка, когда внешний компонент одной уважаемой компании, при определенных обстоятельствах, мог отдать респонс не на твой запрос, а на совсем другой запрос, сделанный параллельно. Мы конечно сами виноваты что недостаточно изолировали, но как говорится «кто без греха...». Такое случалось очень редко, но могло сильно навредить. После закрытия дыры, надо было посмотреть «кого за это время могло задеть». Для этого, надо было в логах за полгода 1) найти все «плохие сессии» по признаку повышенного количества в них определенных ошибок 2) для каждой такой сессии найти соседние сессии, которые происходили на этом же хосте в это же время. 3) для 1) и 2) вынуть идентификаторы клиентов из определнных эвентов в сессии. Мы сделали это скриптами по архиву текстовых логов.
Сейчас у девопсов появился Эластик, в него влезает 4 недели и делаются ежедневные снапшоты штатными средствами. Теперь вопрос: может ли Эластик + снапшоты эффективно решить проблему выше? Или нам все же нужно параллельно держать текстовый архив, чтобы иметь возможность искать там скриптами или, в простом случае, логпадом. Нам кажется, что это имеет смысл, ищем подтверждения.
Я правильно, что в Вашем случае, как раз у Вас организован похожий архив?
dzsysop
Мне кажется вы задаете несколько вопросов в одном.
Это не совсем релевантно к дискуссии.
Все это же с помощью эластика и Кибаны или без нее вы можете сделать в десятки а порой и в сотни раз быстрее при наличии определенного опыта и навыков.
Это же отдельный вопрос связанный скорее всего с бюджетированием и планированием. Ведь понятно что если вам надо посмотреть данные за полгода (26 недель), а в наличии места только на 4, то при ваших специфических ограничениях задача явно если и будет иметь решение то кривоватое.
Но если убрать это в сторону и рассматривать чисто технологически. То можно поднять эластик который либо будет держать бОльший объем данных постоянно. Либо поднимаем временный кластер в облаке заливаем в него данные за полгода, проводим анализ и убиваем кластер. Слава богу облака сегодня позволяют это делать быстро и недорого.
cv28
Спасибо за ответ.
Этот вариант не рассматривается по причинам высокой стоимости. 4 недели и так уже серьезная стоимость, тем более что их несколько, один на каждый регион.
Этот вариант интересный, спасибо. надо будет оценить размер и стоимость такого кластера в облаке. Я правильно понимаю, что Эластик сможет как-то автоматически смерджить данные из этих 26 снапшотов, без дупликатов?
cv28
Или Вы как раз имели в виду, что чтобы «залить данные за полгода», нужно их иметь в исходном виде json, а не в снапшотах? Если это так, то это имхо, подтверждает необходимость файлового архива.
ghostinushanka
экспортированный в json индекс. Индексы автоматически обрабатывается через curator и rollover api. rollover по времени и достижению кол-ва документов (что первым происходит, наш трафик — волна). За счёт этого отдельные куски достаточно маленькие получаются. curator закладывает время «перемотки» для последующего упрощения поиска.
Архивируем, в два этапа — более свежие с меньшим сжатием, после трёх месяцев пережимаем ещё сильнее.
Для мелких запросов поиск по тексту быстрее чем проигрывание с восстановлением в эластик и переиндексацией.
Для больших же, с анализом, как я уже писал, и как вам советует dzsysop — заливайте в эластик. Однако стоимость кластера в облаке это в первую очередь стоимость передачи всего массива данных и для обьёмов о которых мы говорим, это, я уверен, будет стоить больше, чем сами вычислительные мощности.
Если нет своей инфраструктуры, берите в аренду managed сервера на короткий промежуток времени.
У того же hetzner, например, вы заплатите за модель с 10-ю дисками по 10ТБ каждый — 170 евро в месяц. Но у большенства моделей они берут ещё одну месячную плату за установку.
Альтернативно можно посмотреть в сторону провайдеров с почасовой оплатой (месяц выйдет понятно дороже, но в вашем случае может быть выгоднее), например packet
Если стоимость (при необходимом обьёме данных) приемлема для бизнеса — это вполне рабочий вариант.
cv28
ghostinushanka, спасибо за детальный ответ. Обьемы, конечно, смущают. У нас, конечно, не 5TB в день, но все же… Если взять Ваши цифры на секунду…
То есть я правильно Вас понял, что если бы Вам потребовалось провести сложное расследование на всех 14 месяцах, то специалисту по Эластику, при наличии бюджета и за разумный срок (скажем неделя) не составило бы проблемы поднять в облаке Эластик-кластер на 2 петабайта логов?..