
TL; DR: JSONB может значительно упростить разработку схемы БД без ущерба производительности в запросах.
Введение
Приведем классический пример, наверное, одного из старейших вариантов использования в мире реляционных БД (база данных): у нас есть сущность, и необходимо сохранить определенные свойства (атрибуты) этой сущности. Но не все экземпляры могут имеют одинаковый набор свойств, к тому же в будущем, возможное добавление ещё свойств.
Самый простой путь решения этой проблемы – это создание столбца в таблице БД для каждого значение свойства, и просто заполнять те, которые нужны для определенного экземпляра сущности. Отлично! Проблема решена… до того момента, пока ваша таблица не содержит миллионы записей и у вас не возникнет необходимость добавить новую запись.
Рассмотрим паттерн EAV (Entity-Attribute-Value), он встречается достаточно часто. Одна таблица содержит сущности (записи), другая таблица содержит имена свойств (атрибутов), а третья таблица связывает сущности с их атрибутами и содержит значение этих атрибутов для текущей сущности. Это дает вам возможность иметь разные наборы свойств для разных объектов, а также добавлять свойства “на лету”, не изменяя структуры БД.
Тем не менее, я бы не писал эту заметку, если бы не было недостатков в подходе с использованием EVA. Так, например, для получения одной или нескольких сущностей, которые имеют по 1 атрибуту требуется 2 join'а (объединения) в запросе: первый – объединение с таблицей атрибутов, второй – объединение с таблицей значений. Если сущность имеют 2 атрибуты, то нужно уже 4 join'а! Кроме того, все атрибуты обычно хранятся в виде строк, что приводит к приведению типов, как для результата, так и для условия WHERE. Если вы пишете много запросов, то это достаточно расточительно, с точки зрения использования ресурсов.
Несмотря на эти очевидные недостатки, EAV уже давно используется для решения такого рода проблем. Это были неизбежное недостатки, и лучшей альтернативы просто не было.
Но затем в PostgreSQL появилась новая “технология”…
Начиная с PostgreSQL 9.4, был добавлен тип данных JSONB для хранения двоичных данных JSON. Хотя хранение JSON в этом формате обычно занимает немного больше места и времени, чем простой текстовый JSON, выполнение операций с ним происходит намного быстрее. Также JSONB поддерживает индексирование, что делает запросы к ним еще быстрее.
Тип данных JSONB позволяет нам заменить громоздкий паттерн EAV путем добавления всего лишь одного столбца JSONB в нашу таблицу сущностей, что значительно упрощает проектирование базы данных. Но многие утверждают, что это должно сопровождаться снижением производительности… Вот по этой причине я и появилась эта статья.
Настройка тестовой базы данных
Для этого сравнения я создал базу данных на новой установке PostgreSQL 9.5 на 80-долларовой сборке DigitalOcean Ubuntu 14.04. После настройки некоторых параметров в postgresql.conf я запустил этот скрипт с помощью psql. Для представления данных в виде EAV были созданы следующие таблицы:
CREATE TABLE entity (
id SERIAL PRIMARY KEY,
name TEXT,
description TEXT
);
CREATE TABLE entity_attribute (
id SERIAL PRIMARY KEY,
name TEXT
);
CREATE TABLE entity_attribute_value (
id SERIAL PRIMARY KEY,
entity_id INT REFERENCES entity(id),
entity_attribute_id INT REFERENCES entity_attribute(id),
value TEXT
);
Ниже представлена таблица где будут хранится те же данные, но с атрибутами в столбце типа JSONB – properties.
CREATE TABLE entity_jsonb (
id SERIAL PRIMARY KEY,
name TEXT,
description TEXT,
properties JSONB
);
Выглядит намного проще, не так ли? Затем было добавлено в таблицы сущностей (entity & entity_jsonb) 10 миллионов записей, и соответственно, было заполнено одинаковыми данными таблицы где используется EAV паттерн и подход с JSONB столбцом – entity_jsonb.properties. Таким образом, мы получили несколько разных типов данных среди всего набора свойств. Пример данных:
{
id: 1
name: "Entity1"
description: "Test entity no. 1"
properties: {
color: "red"
lenght: 120
width: 3.1882420
hassomething: true
country: "Belgium"
}
}Итак, теперь у нас есть одинаковые данные, для двух вариантов. Давайте начнем сравнивать реализации в работе!
Упрощение дизайна
Ранее уже было сказано, что дизайн БД был значительно упрощен: одна таблица, за счет использования столбца JSONB для свойств, вместо использования трех таблиц для EAV. Но как же это отражается в запросах? Обновление одного свойства сущности выглядит следующим образом:
-- EAV
UPDATE entity_attribute_value
SET value = 'blue'
WHERE entity_attribute_id = 1
AND entity_id = 120;
-- JSONB
UPDATE entity_jsonb
SET properties = jsonb_set(properties, '{"color"}', '"blue"')
WHERE id = 120;
Как видим, последний запрос не выглядит проще. Чтобы обновить значение свойства в объекте JSONB, мы должны использовать функцию jsonb_set(), и должны передать наше новое значение как объект JSONB. Тем не менее, нам не нужно знать какой-либо идентификатор заранее. Посмотрев на пример с EAV, нам нужно знать и entity_id, и entity_attribute_id, чтобы выполнить обновление. Если вы хотите обновить свойство в столбце JSONB на основе имени объекта, – то это все делается одной простой строкой.
Теперь давайте выберем ту сущность, которую мы только что обновили, по условию ее нового цвета:
-- EAV
SELECT e.name
FROM entity e
INNER JOIN entity_attribute_value eav ON e.id = eav.entity_id
INNER JOIN entity_attribute ea ON eav.entity_attribute_id = ea.id
WHERE ea.name = 'color' AND eav.value = 'blue';
-- JSONB
SELECT name
FROM entity_jsonb
WHERE properties ->> 'color' = 'blue';
Я думаю, что мы можем согласиться с тем, что второе является более коротким (без join!), и соответственно более читабельным. Здесь победа JSONB! Мы используем оператор JSON ->>, чтобы получить цвет как текстовое значение из объекта JSONB. Существует также второй способ достижения того же результата в модели JSONB с использованием оператора @>:
-- JSONB
SELECT name
FROM entity_jsonb
WHERE properties @> '{"color": "blue"}';
Это немного сложнее: мы проверяем, содержит ли объект JSON в столбце свойств объект который находится справа от оператора @>. Менее читаемый, более производительный (см. далее).
Упростим использования JSONB еще сильнее, когда вам нужно выбрать несколько свойств одновременно. Вот где действительно подходит JSONB-подход: мы просто выбираем свойства в качестве дополнительных столбцов в нашем наборе результатов без необходимости объединений:
-- JSONB
SELECT name
, properties ->> 'color'
, properties ->> 'country'
FROM entity_jsonb
WHERE id = 120;
С EAV вам понадобится 2 объединения для каждого свойства, которое вы хотите запросить. На мой взгляд, приведенные выше запросы показывают большое упрощение в дизайне базы данных. Посмотреть больше примеров того, как писать запросы к JSONB, возможно также в этом посте.
Теперь пришло время поговорить о производительности.
Производительность
Чтобы сравнить производительность, я использовал EXPLAIN ANALYZE в запросах, для подсчета времени выполнения. Каждый запрос выполнялся как минимум три раза, потому что в первый раз планировщику запросов требуется больше времени. Сначала я выполнил запросы без каких-либо индексов. Очевидно, это служило преимуществом JSONB, так как join, необходимые для EAV, не могли использовать индексы (поля внешнего ключа не индексировались). После этого я создал индекс для 2-х столбцов внешних ключей таблице значений EAV, а также индекс GIN для столбца JSONB.
Обновления данных показало следующие результаты по времени (в мс). Обратите внимание, что масштаб является логарифмическим:

Видим что JSONB намного (> 50000-x) быстрее, чем EAV, если не использовать индексы, по причине, указанной выше. Когда мы индексируем столбцы c первичными ключами, разница почти пропадает, но JSONB все еще в 1,3 раза быстрее, чем EAV. Обратите внимание, что индекс в столбце JSONB здесь не оказывает никакого влияния, так как мы не используем столбец свойств в критериях оценки.
Для выбора данных на основе значения свойства мы получаем следующие результаты (обычный масштаб):
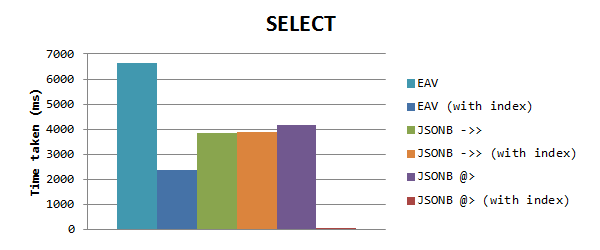
Можно заметить, что JSONB снова работает быстрее, чем EAV без индексов, но когда EAV с индексами – он все таки работает быстрее чем JSONB. Но потом я увидел, что время для JSONB-запросов было одинаковым, это подтолкнуло меня на тот факт, что GIN-индекс не срабатывают. Видимо, когда вы используете индекс GIN для столбца с заполненными свойствами, он действует только при использовании оператора включения @>. Я использовал это в новом тесте, что оказало огромное влияние на время: всего 0,153 мс! Это в 15000 раз быстрее, чем EAV, и в 25000 раз быстрее, чем оператор ->>.
Думаю, это было достаточно быстро!
Размер таблиц БД
Давайте сравним размеры таблиц при обоих подходов. В psql мы можем показать размер всех таблиц и индексов с помощью команды \dti+
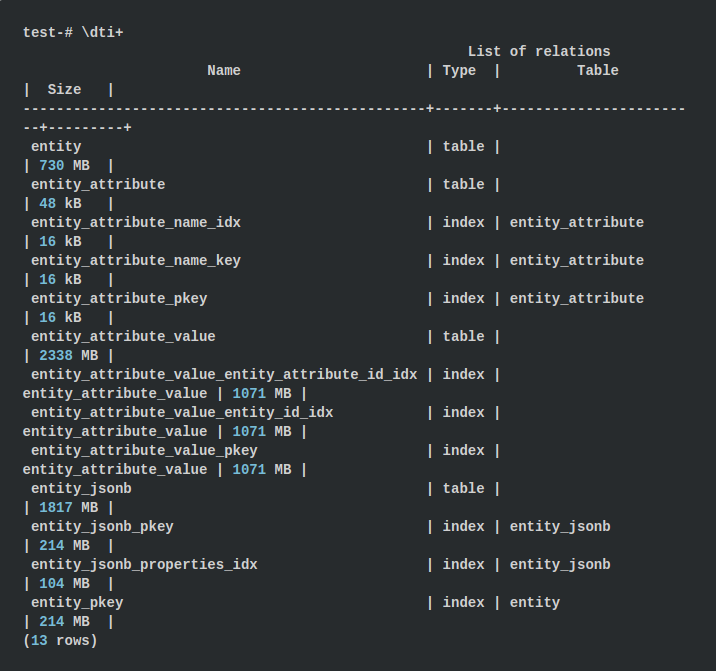
Для подхода EAV размеры таблиц составляют около 3068 МБ, а индексы – до 3427 МБ, что в сумме дает 6,43 ГБ. При использовании подхода с JSONB используется 1817 МБ для таблицы и 318 МБ для индексов, что составляет 2,08 ГБ. Получается в 3 раза меньше! Этот факт немного удивил меня, потому что мы храним имена свойств в каждом объекте JSONB.
Но все таки цифры говорят сами за себя: в EAV мы храним 2 целочисленных внешних ключа на значение атрибута, в результате чего получаем 8 байт дополнительных данных. Кроме того, в EAV все значения свойств хранятся в виде текста, в то время как JSONB будет использовать числовые и логические значения внутри, где это возможно, в результате чего получается меньший объем.
Итоги
В целом, я думаю, что сохранение свойств сущностей в формате JSONB может значительно упростить проектирование и обслуживание вашей базы данных. Если вы выполняете много запросов, то все, что хранится в одной таблице с сущностью, действительно будет работать эффективнее. И тот факт, что это упрощает взаимодействие между данными, уже является плюсом, но и результирующая БД в 3 раза меньше по объему.
Также, по сделанным тестом, можно сделать итог, что потери производительности очень незначительные. В некоторых случаях JSONB даже работает быстрее, чем EAV, что делает его еще лучше. Однако этот эталонный тест, конечно, не охватывает все аспекты (например, сущности с очень большим количеством свойств, значительным увеличением числа свойств существующих данных,…), поэтому, если у вас есть какие-либо предложения о том, как их улучшить, пожалуйста, не стесняйтесь оставлять в комментариях!
Комментарии (33)

StrangerInTheKy
10.11.2019 03:33Если сущность имеют 2 атрибуты, то нужно уже 4 join-на!
Не нужно миллион джойнов, нужен один PIVOT (он в постгресе называется «crosstab» и работает вполне шустро).
И еще...«join-на» — это пять! Почти как «2ва» и «3ри». Пишите хотя бы «join'а», если использовать слово «джойна» так уж не хочется.poxvuibr
10.11.2019 18:51Не нужно миллион джойнов, нужен один PIVOT
Я всегда думал, что нужен один select, в котором в условии where будет id сущности. А джойнов надо всегда два, просто чтобы присоединить к таблице с сущностями таблицы с ключами и значениями. Хотя, честно говоря я не совсем понимаю, почему нельзя это всё сложить в одну таблицу.
adictive_max
10.11.2019 03:39Может JSONB — это и круто, но это вообще никаким местом не полноценная замена EAV.
EAV, в отличие от JSON, это не полный schem-less, это sheme-as-data. Там можно иметь дополнительные метаданные у полей, проводить некоторые манипуляции со структурой Entity, не перетряхивая все значения и иметь где-то фиксированную доступную для просмотра структуру записей. Еще можно делать множественные привязки, но это штука уже довольно сомнительная.

evkochurov
10.11.2019 11:22-- JSONB
UPDATE entity_jsonb
SET properties = jsonb_set(properties, '{"color"}', '"blue"')
WHERE id = 120;
Надо иметь ввиду, что значение в колонке properties заменяется целиком. Теперь представим, что JSON-ы, которые мы храним, достаточно большие. И если типичная нагрузка — это частые обновления отдельно взятых полей JSON-а, то EAV может оказаться и на голову эффективнее.
В общем, в статье незаслуженно обойден вопрос о производительности записи и влиянии на WAL.
EvgeniiR
10.11.2019 11:49+1Надо иметь ввиду, что значение в колонке properties заменяется целиком. Теперь представим, что JSON-ы, которые мы храним, достаточно большие. И если типичная нагрузка — это частые обновления отдельно взятых полей JSON-а, то EAV может оказаться и на голову эффективнее.
Если мы говорим о PostgreSQL, тип jsonb там хранится в бинарном виде, не парсится каждый раз и позволяет без проблем и быстро выбирать/заменять любое свойство внутри json( www.postgresql.org/docs/9.4/datatype-json.html ) не заменяя его полностью.evkochurov
10.11.2019 15:36+1Да, это быстро, но на физическом уровне создается новая версия строки а не перезаписывается существующая, т.е. мы получаем полную копию всего jsonb (с заменой одного поля), в то время, как в EAV — только копию строки, содержащей измененное значение. Как интенсивные обновления больших jsonb повлияют на размер WAL и TOAST-таблиц, на поведение VACUUM — вопрос, который я бы игнорировать поостерегся.
Хотя с основным посылом я согласен — jsonb во многих случаях выглядит предпочтительнее, чем EAV. Указываю только на то, что в общем случае нагрузка на БД не сводится к одним только select-ам.
alexfilus
10.11.2019 11:26А какой именно GIN индекс строился? В этой статье рассматриваются разные варианты. Например с параметром jsonb_path_ops. Не пробовали такие варианты?
DmitriyTitov
10.11.2019 13:45+1Рассмотрим паттерн EAV (Entity-Attribute-Value), он встречается достаточно часто. Одна таблица содержит сущности (записи), другая таблица содержит имена свойств (атрибутов), а третья таблица связывает сущности с их атрибутами и содержит значение этих атрибутов для текущей сущности.
Небольшое замечание: это не структура данных EAV, а скорее реализация связи «многие-ко-многим». Для EAV достаточно одной таблицы с тремя столбцами: собственно сущность, атрибут сущности, значение атрибута. Может быть ещё справочник атрибутов, но не обязательно.
maxxannik
10.11.2019 16:01Не очень понятно зачем для EAV делать 2 таблицы помимо основной таблицы сущностей?
Я работал так:
1. таблица сущностей: entity
2. таблица атрибутов: attributes
у таблицы атрибутов поля:
— id
— entity_id
— key
— value
Все. Это работает. Храним любые атрибуты и их значения.
По любой сущности можно получить все атрибуты и значения 1 запросом с 1 join. Атрибутов моджет быть хоть 1000 штук. Доходило до 20 000 штук.
Хранить такое в JSONB — мб плачевно.
С другой сторону конечно же EAV это не серебрянная пуля. У нее есть как плюсы так и минусы.
Например чаще всего индекс есть только у ключей, а value хранятся без индекса. У этого тоже есть плюсы, но и весомый минус — при больших данных поиск значений в value становится долгим.
Есть много решений. Что то можно выдернуть в отдельные таблицы. Иногда подключается внешний индекс типа Эластика или Алголии. Например для создания поисковых индексов.
JSONB крутая штука. Где то она будет показывать себя лучше. Но не везде )zoryamba
11.11.2019 10:50+1Если я не ошибаюсь, вынесения атрибутов в отдельную таблицу требует 3-я нормальная форма. И правильнее задаваться вопросом, что нам даст подобная денормализация.
mayorovp
11.11.2019 14:47Нет, 3НФ этого не требует. Вообще, ни одна из НФ не требует создавать отдельные суррогатные ключи для кодирования строк.
zoryamba
11.11.2019 21:26Нет, ну конечно, от части Вы правы. Все зависит от того, как эти атрибуты трактует бизнес логика. Если это просто строки, которые не несут особой смысловой нагрузки — тут согласен. Но если это, например, характеристики товара в магазине(как чаще всего бывает и именно этот кейс я имел в виду), по которым нужно организовывать фильтр, или если, не дай бог, от выбора характеристик зависит цена товара, то тут характеристика — это отдельное отношение и хранение ее в таком виде — очевидная денормализация.
Исправьте, если я неправ.
nun-buoy
10.11.2019 16:35Проблема решена… до того момента, пока ваша таблица не содержит миллионы записей и у вас не возникнет необходимость добавить новую запись.
Я не понимаю, в чём проблема добавить новую запись к миллионам других. Или это опечатка, и автор имел в виду «добавить новую колонку»? Но здесь тоже нет никакой проблемы, потому что в современных движках БД строки не фиксированной длины.apapacy
11.11.2019 23:38Если записей миллионы — добавление колонки очень затратная операция в большинстве sql баз. Я бы даже скорее вынес новую колонку в отдельную таблицу 1х1 чем положил базу на пару часов добавлением новой колонки.
x67
10.11.2019 16:43Немного узковатое понимание jsonb. Да, он неплохо подходит для хранения атрибутов, но это не та причина, по которой его создавали — до него в постгресе с этим успешно справлялся hstore. Собственно для хранения атрибутов kv хранилища как правило хватает за глаза.
jsonb же выделяется тем, что быстрее json — об этом написано в статье, а также тем, что это все тот же json, в котором можно хранить не просто атрибуты, а целые структуры с вложениями, kv и списками. Быстрый доступ к таким структурам и возможность работать с такими структурами без костылей и является киллер фичей jsonb в сравнении с hstore.
Но это все историческая ремарка, jsonb сейчас ничуть не медленнее hstore и имеет неплохие преимущества перед ним, потому вопрос о том, что использовать в новом продукте уже и не стоит. Буду рад услышать преимущества hstore, если не прав.
Единственное, чего хотелось бы — типизация на уровне бд, а не на логическом уровне, но это уже капризы)eumorozov
10.11.2019 17:35Я так понял, что hstore — это чисто PostgreSQL изобретение. А jsonb — стандарт. Hstore появился до JSON или до популярности JSON, видимо, jsonb призван со временем его заменить.
iz_amal
10.11.2019 21:14А если свойство может иметь несколько вариантов? {"Ram":[{"ddr3","sdram"}]}. Как проапдейтить или удалить определённое? Если на сотнях, тысячах записей?
REDkiy
10.11.2019 21:16В моём пет-проекте используется EAV. Наелся этого по самое нихочу.
Автор ничтоже сумняше не раскрыл один момент. Трёхтабличный EAV это не более чем пример практики, в реальности что-то адекватное можно построить не менее чем на 7. В моём проекте эта схема реализована на 9 и планирую расширить до 12 в ближайшей перспективе.
Благодаря этому я сохранил преимущества EAV плюс добился того что атрибуты хранятся в БД в своём типе, а не в строке. Недостатки остались конечно.
Вопрос производительности остаётся открытым и стоит остро. Метрики этого пока не собираю.

nitrosbase
11.11.2019 00:32Статья от января 2016 года… У нас в проектах, тянущихся с тех времен, похожие решения используются. Но все-таки уже почти три года прошло с тех пор.
Заголовок спойлераХочется EAV — попробуй RDF-хранилище.
Тормозят JOIN'ы — используй графовую СУБД.
Любишь JSON — есть документные СУБД.EvgeniiR
11.11.2019 00:56Не, ну… Я конечно за то чтобы подбирать инструменты под задачу, но в данном случае это зоопарк технологий непонятно для чего.
Хочется EAV — попробуй RDF-хранилище.
Зачем? Ну если только в пет-проекте попробовать…
Тормозят JOIN'ы — используй графовую СУБД.
Может лучше разобраться чего они тормозят?
Любишь JSON — есть документные СУБД.
Ну пусть дальше будут. Если основная СУБД у меня PostgreSQL я знаю что он вполне себе уже лет 10 как «Not Only SQL», и в текущем состоянии вряд-ли чем-то уступает какой-нибудь Монге( www.youtube.com/watch?v=SNzOZKvFZ68 )
Ну и да — Документо-ориентированные СУБД подразумевают немного другие подходы к декомпозиции в принципе, потому для стандартной модели с реляциями не подходят.
apapacy
11.11.2019 14:42+1По документо-ориентированным DB — много вопросов возникает сейчас. Когда-то на волне хайпа я юзал монгу с nodejs. На тот момент сравнение производительности с теми же postgres+nodejs и mysql+nodejs выглядело сильно в пользу mongo+nodejs. Сейчас выигрыш по insert уже не наблюдается. (Причина неясна, скорее всего драйверы для nodejs были не очень производительные). Плюс у postgresql появился bson. Что имеем в итоге. Постгрес с bson перегрывает весь функционал mongodb и не уступает в производительности. Плюс дает возможность без проблем делать выборки с join, sum, like — чего не очень удобно делать в mongodb
catsmeatman
11.11.2019 10:51+1Если взять интернет-магазин, то таблицу entity_attribute при использовании jsonb все таки заводить придется, т.к. нужно будет учесть, что значения в entity_attribute:
— могут выбираться из списка (цвет товара, класс пожарной опасности).
— могут быть произвольным текстовым полем (название материала подошвы кроссовок)
— могут быть числом с заранее заданным диапазоном (размер шкафа, положительное целое число со значениями от и до)
— хранимое значение и вывод этого значения могут отличаться (водостойкость/морозостойкость в БД хранится, как true/false, а на выходе должно быть отсутствует/присутствует или да/нет или 0/1 или еще как-нибудь)
— может быть обязательным к заполнению или нет
— возможно значение по умолчанию
— единица измерения значения (ширира обоев в см, длина обоев в метрах)
Подскажите, а есть ли какие-нибудь цифры по построению фасетных фильтров при использовании EAV и JSONB?
densol92
11.11.2019 10:51Это всё конечно хорошо, но одним sql сыт не будешь, а orm поддерживают jsonb плохо. Пытался мигрировать с eav на jsonb, но бросил т. к. каждый раз извлекаешь json целиком и парсишь его, чтобы извлечь/изменить нужный атрибут.
Хотя по месту выигрыш был сладкий — 10+ 2Gb индексов превратились в 2.5 +0.6 Gb.alexfilus
11.11.2019 13:59Так есть же операторы позволяющие извлекать конкретные значения из JSON документа, и менять. А с 12 версии в Постгре вообще полноценная поддержка JSONPath.
apapacy
11.11.2019 15:27В принципе статья хорошая в плане направления исследования. Я сам был уверен что индекс по bson работает дольше чем обычный.
Но.
Автор забыл определить индекс для поля value, чем сделал результаты просто неверными.
Я решил перепроверить — уж очень большая была разница и добавил индекс на поле value
Разница была и не очень существенная. Первый запрос по GIN было более продолжительое планирование. При повторных запросах планирование существенно (в 100 раз) сократилось и запрос по GIN был быстрее ( 1,2 мс против 1,3 мс). Но все же это не так у автора 1000-х разница

piton_nsk
11.11.2019 18:19Автор забыл определить индекс для поля value, чем сделал результаты просто неверными.
Ха, я и смотрю, какие-то фантастические результаты у автора получились.
akhkmed
12.11.2019 20:14Ведь стоило добавить к таблице entity_attribute_value многоколоночный btree-индекс (value, entity_attribute_id, entity_id),
как снова производительность возрастает в несколько раз, но теперь уже не в пользу jsonb и gin-индекса.apapacy
12.11.2019 20:36Я не добавлял многоколоночный (добавил одноколоночный), скорость практически одинаковая. Но все же немного ниже на 0,1 мс. Возможно на моем конкретном комьютере и с моими конкретными данными.
Скорее всего скорость может немного просесть если будет большой json объект с большим количеством свойств.
Впрочем это (то есть равноценность) вполне ожидаема, т.к. для чего иначе это было разрабатывать.
akhkmed
13.11.2019 11:53На счёт равноценности Вы в целом правы, но после многих update производительность выборки из gin либо деградирует (при включенном fastupdate), либо сами update сильно замедляются (при выключенном fastupdate). Этого недостатка нет у btree.
Vinchi
explain analize наверно не лучший вариант для теста, надо проверять генегируя таблицу и делая множество разных запросов.
Magikan
Как точка отсчета explain очень даже хорош. Да, можно нагрузочные придумать и посмотреть на систему в динамике, а еще никадать не 10 параметров, а 100500 с неравномерным заполнением дабы было максимально близко с реальности (интернет-магазин всего и вся например).
Вот только есть одно НО: факт в том, что 99.9% проектов ни когда в жизни не достигнут таких объемов данных как в выборке у автора (смешные 10млн) и им куда важнее не скорость выолнения запроса, а скорость разработки этого самого проекта. И по классике жанра, все что тормозит — кладется в кэш и спят спокойно)