

На форуме RAIF 2019, который состоялся в Сколково в рамках «Открытых Инноваций», я рассказывал о том, как происходит внедрение моделей машинного обучения. В связи с особенностями профессии я каждую неделю несколько дней провожу на производствах, занимаясь внедрением моделей машинного обучения, а остальное время – разработкой этих моделей. Этот пост — запись доклада, в котором я постарался обобщить свой опыт.
Начнем с описания процесса крупными мазками, постепенно вдаваясь в детали каждого этапа.
Рассчитываем ли мы на оптимизацию производства по результатам полноценного обследования (в идеале), или происходит просто сбор идей, «лоскутная оптимизация», — результатом так или иначе становится формирование списка инициатив. Необходимо понять, какие области производства мы будем оптимизировать. Этот процесс обычно занимает около двух месяцев.
Потом приступаем к этапу пилотирования, он займет три-четыре месяца – мы должны построить базовую модель и понять, применимо ли к ней машинной обучение, и какие выгоды для бизнеса она может принести.
Следующий этап, гораздо более протяженный во времени, на нем машинного обучения не очень много – это внедрение, когда нужно произвести интеграцию, строить текущие системы и начать получать ту самую прибыль, которую мы спрогнозировали на втором этапе. Внедрение обычно занимает от полугода до девяти месяцев.
Завершает процесс этап контроля. Одно дело: сделать модель и показать, а другое – поддерживать модель в течении некоторого времени. Производство меняется, заменяются станки. В этих условиях и модель приходится постоянно «докручивать» и искать новые возможности для оптимизации.
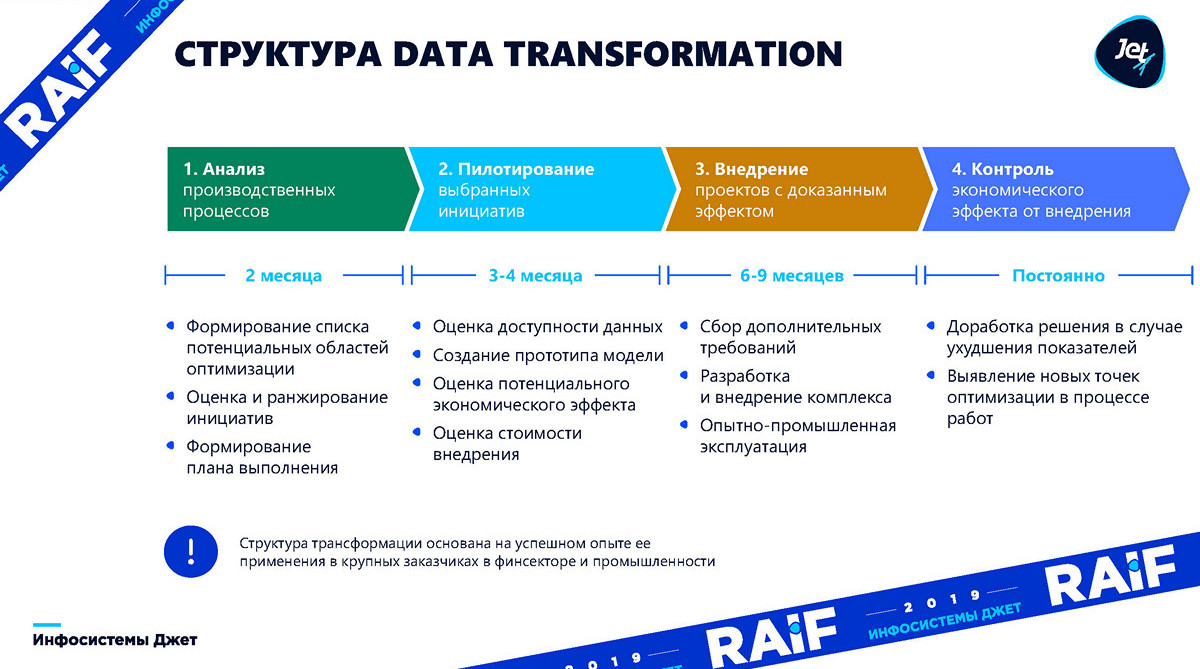
Теперь более подробно по порядку:
Ищем гипотезу
Откуда берется гипотеза? Кто ее выдвинет?
Обычно за гипотезами принято ходить в ИТ-отдел, но там работают люди, которые умеют настраивать системы, знают про интеграцию и ничего не знают про машинное обучение. Кроме того, они не так хорошо представляют себе производство. У них нет компетенции понять на практике, как работает машинное обучение.
Попытка номер два – отправиться за гипотезой на производство. Действительно, близкие к производству специалисты знают технические особенности процесса, но… не знают машинное обучение. Поэтому не могут сказать, где оно применимо, а где нет.
В таком случае, откуда можно взять гипотезу? Для этого придумали специальную должность – Chief Digital Transformation Officer. Это человек, который занимается цифровыми преобразованиями. Или Chief Datа Officer – человек, которые знает данные и как их можно применить. Если этих двух людей в компании нет, то гипотезы должны приходить от топ-менеджмента. То есть специалистов, которые вполне понимают бизнес и занимаются современными технологиями.
Если же на предприятии нет ни Chief Digital Transformation Officer, ни Chief Datа Officer, а топ-менеджмент не способен родить гипотезу, то на помощь придут… конкуренты. Если они что-то внедрили, у них этого не отнять. Но, компания-интегратор, подключенная к проекту, может подсказать, что и как можно оптимизировать.

Как выбрать идею?
Тут важны четыре фактора:
- Оборот оптимизируемого процесса.
- Существенные отклонения в процессе. Есть методология «шесть сигм», которая говорит о том, что все процессы должны отклоняться не более, чем на шесть стандартных отклонений от их результатов. Если у вас эти отклонения больше, то их нужно разобрать, и в этом поможет машинное обучение.
- Доступность и наличие данных. Если, например, вы получаете данные с датчиков по работе оборудования через 12 месяцев, то машинное обучение вы не внедрите.
- Сложность внедрения цифровизации в процесс. Стоимость внедрения вашей модели, в сравнении с стоимостью того, чего она может сэкономить.
Какие бывают данные?
По структуре данные бывают:
Структурированные: какие-нибудь таблицы, показания – все просто. Когда же мы хотим использовать данные из социальных сетей, или наборы фотографий, придется иметь дело с неструктурированными данными. Необходимо закладывать, что такие данные необходимо еще структурировать, превратив в числа, которые машинное обучение сможет воспринять. Третий тип данных – поточные. Если мы работаем с данными, которые меняются каждую миллисекунду, то нужно сразу подумать про балансировку нагрузки: сможет ли наша система выдержать скорость их получения?

По происхождению данные делятся на:
Автоматизированные – датчики генерируют какие-то цифры, мы им доверяем или нет. Но они примерно одинаковые. Введённые вручную – тут нужно понимать, что возможна ошибка, связанная с человеческим фактором. И модель должна быть устойчива к этому. Внешние данные – возможно, нас будут интересовать курсы валют, если внедрение связано с финансовыми операциями, или прогноз погоды, если мы прогнозируем температурные теплообмены. Статические данные – это всё то, что можно снова использовать.

Проблемы с данными
- Полнота – момент, когда некоторые данные/месяцы могут быть пропущены.
- Погрешность изменения – если, например, у вашего датчика погрешность 5 миллисекунд, то модель с точностью две миллисекунды – вы не сможете, так как входные данные начинают расходиться.
- Доступность в режиме онлайн – если вы хотите делать прогноз «прямо сейчас», данные должны быть готовы.
- Время хранения – если вы хотите использовать годовые тенденции, и вам нужно прогнозировать спрос, а данные хранятся только полгода – модель вы не построите.
Работа с данными
Слушать профессионалов, но верить только данным. Нужно ездить в цех, говорить с профессионалами, бывать на заводе, говорить с операторами, понимать их бизнес. Но верить только данным. Было очень много примеров, когда операторы говорят, что такого быть не может – мы показываем данные – оказывается, это действительно происходит. Интересный пример: как-то модель показала, что день недели влияет на производство. По понедельникам – один коэффициент, по пятницам – другой.
Эффект понятен только в бою – очень важно быстрое прототипирование. Самое главное – быстрее посмотреть, как модель работает в быту. В презентациях и на локальных ноутбуках проект может выглядеть совсем не так, как на самом деле: как правило, по факту совсем другие проблемы выходят на первое место.
Только интерпретируемая модель имеет шанс на улучшение. Всегда нужно четко понимать, почему модель решила так, а не иначе.
Работа с метрикой
Реально зависимость точности от прибыли может быть любой. Пока мы не поймем, как эта точность влияет на эффект – вопрос о точности абсолютно бессмысленный. Всегда нужно переводить в прибыль. На графиках ниже видно, что прибыль может по разному зависеть от точности модели. Первый график иллюстрирует, как сложно определить заранее в какой именно момент точности модели хватит для роста прибыли:
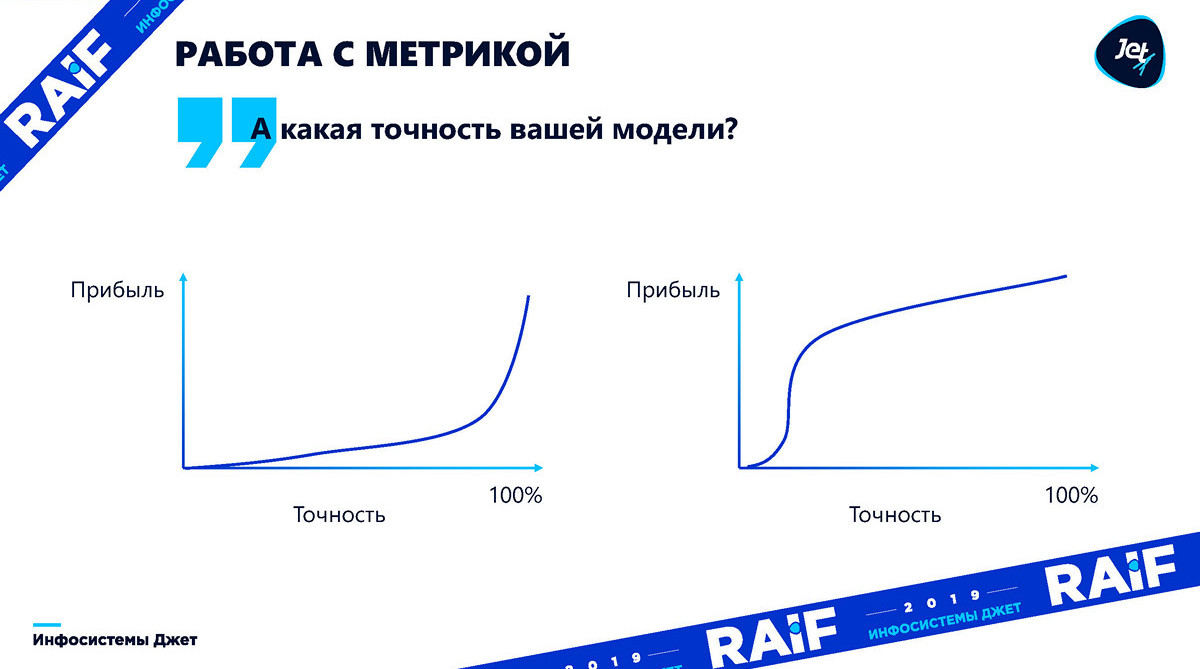
Более того, для некоторых случаев при недостаточной точности модели она будет просто приносить убыток:

Основные моменты про интеграцию:
- Интеграция занимает времени больше, чем разработка модели.
- Новые идеи. Иногда оказывается, что проект приносит пользу, там, где не ожидалось.
- Обучение. Люди адаптируются быстрее железа.
Еще один момент, о котором часто забывают датасайнтисты, это цель внедрения модели: прогноз или рекомендация. Обычно рекомендации основываются на прогнозной модели, но в этом случае прогнозную модель стоит строить особо, ведь искать минимум черного ящика довольно сложно с внезапными неприятными эффектами. Если говорить о метриках эффективности, то в зависимости от цели внедрения:
- Выдавать прогноз, — оценивать результат применения знаний;
- Выдавать рекомендации, — оценивать сравнение со старым процессом.
Важные нюансы этапа внедрения:
Внедрение/Обучение
- Статистическая грамотность, — внедрение проходит гораздо более успешно, когда сотрудники на местах начинают оперировать корректными статистическими терминами.
- Мотивация различных структурных подразделений, — все должны понимать, зачем это происходит, и не бояться перемен.
- Организационные изменения — как минимум один сотрудник посмотрит результат выдачи модели, а значит изменит свой подход к процессу. Очень часто оказывается, что люди к этому не готовы.
Поддержка
Не забываем, что условия меняются и модель приходится постоянно «докручивать» и искать новые возможности для оптимизации. Тут важны:
- Стратегии управления моделями и реакции на прогнозы — немного саморекламы: мы в «Инфосистемы Джет» как раз много думали об этом и разработали свою систему JET GALATEA.
- Человеческий фактор — основные проблемы модели часто связаны с ее использованием, или вмешательством человека, которое модель не могла предусмотреть.
- Регулярный разбор работы с профессионалами из области — вряд ли удастся все свести к одному числу, которое будет указывать, что нужно дорабатывать, нужно будет разбирать каждый сомнительный прогноз или рекомендацию. Будьте готовы освоить еще одну профессию, чтобы говорить на одном языке с технологами и операторами устройств на производстве.

Автор: Николай Князев, руководитель группы машинного обучения «Инфосистемы Джет»
Комментарии (3)

Tyiler
20.11.2019 21:49Спасибо, интересно.
Не первую статью уже вижу, что ML стремится в производство.
Пару мыслей своих выскажу об этом, потому что работал на производстве.
Помню еще, что есть на производстве такая вещь как «АСУТП». У нее задача обеспечивать тех процесс: опрос датчиков, управление эл приводами, регуляторы температуры, давления и тд. Все работает правильно, как написано производителем оборудования, с учетом тех требований и тд.
Теперь появляется ML, она тоже собирает показания с датчиков пусть, но не знает что это за датчики, зачем они вообще нужны, физику процесса не понимает, потому что естественно (неожиданно для Chief Digital Transformation Officer, Chief Datа Officer и прочего пром топ-менеджмента) интеллекта там никакого нет.
Просто ищет корреляции между данными, и на основе выборки (и искусственных эвристик, которые натолкали чтобы хоть как то на правду похоже было)), статистики по сути, выдает суждение (но решение сама естественно не принимает), правильно?
А технологи чем занимаются на производстве, неужели технологи, с многолетним опытом, хуже сделают предложение, чем на коленке написанный питоновский скрипт?
В общем, может я неправ конечно, но пока видится как — на волне хайпа прокатится по ушам, продать слона и тд.
nitrosbase
Не очень понял, как последующее содержание статьи бьётся с перечнем этапов в начале, но да ладно.
Расскажите, пожалуйста, пару случаев, когда ответ был отрицательным. Или про это рассказывают куски о проблемах с качеством данных?
iRumata Автор
Случаи были такие
— Данные есть в исторической выборке, но в момент принятия решения они еще не готовы в системах, и в бою модель не работает
-Модель должна эмулировать действия человека, а он порой противоречит сам себе, и нельзя формализовать ожидания от модели
-Планируемый эффект от модели за годы, ниже затрат на внедренение (тут нужно еще смотреть на косвенные эффекты, вроде автоматизации и понимания того, что происходит, однако если есть выбор, выбирают более прибыльные инциативы)