
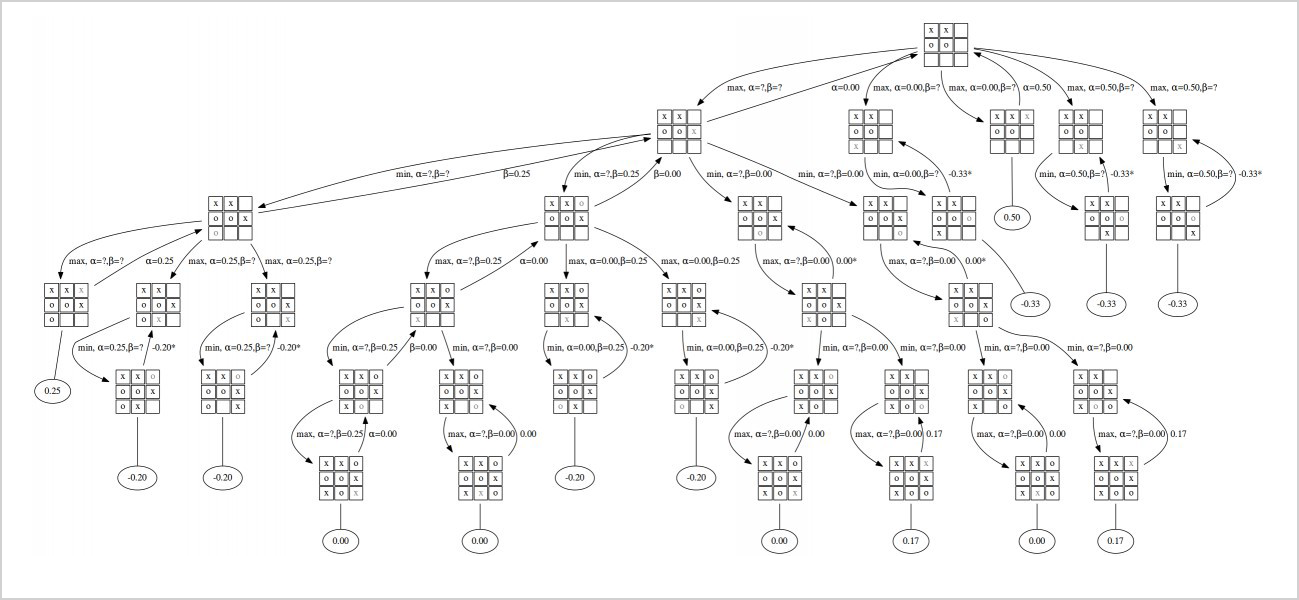
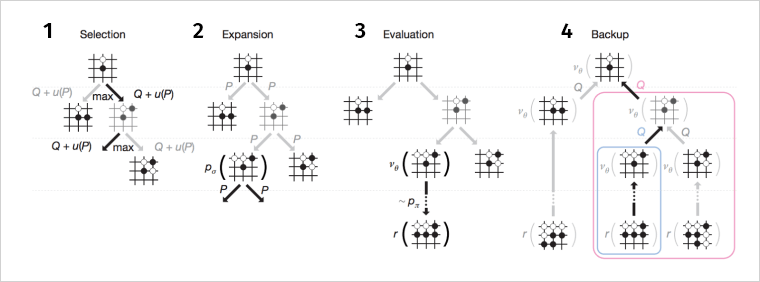
- Выбор (Selection). Симулирует обход дерева, выбирая дуги с максимальным весом Q (насколько хорош шаг).
- Раскрытие вершины (Expansion). Если вершина выбрана при обходе, она скармливается supervised learning (SL) policy network для получения априорных вероятностей возможных шагов.
- Оценка (Evaluation). Включается Reinforcement Learning стратегия, которая играет множество игр и оценивает, насколько текущая позиция хороша (условно, если белые выиграли у черных 8 из 10 раз начиная с данной расстановки, то вес позиции — 0,8).
- Backup. Приписываем вес всему дереву и продолжаем поиски.
- Команда активации — Alexa;
- Команда выбора модуля — музыкальный модуль Spotify;
- Spotify query template matching <album> by <artist> — тут подсистема поняла, что у нас запрос вида <music> by <performer> и что в данной ситуации <music> является альбомом, а <performer> — группой.


- Выбор (Selection). Симулирует обход дерева, выбирая дуги с максимальным весом Q (насколько хорош шаг).
- Раскрытие вершины (Expansion). Если вершина выбрана при обходе, она скармливается supervised learning (SL) policy network для получения априорных вероятностей возможных шагов.
- Оценка (Evaluation). Включается Reinforcement Learning стратегия, которая играет множество игр и оценивает, насколько текущая позиция хороша (условно, если белые выиграли у черных 8 из 10 раз начиная с данной расстановки, то вес позиции — 0,8).
- Backup. Приписываем вес всему дереву и продолжаем поиски.


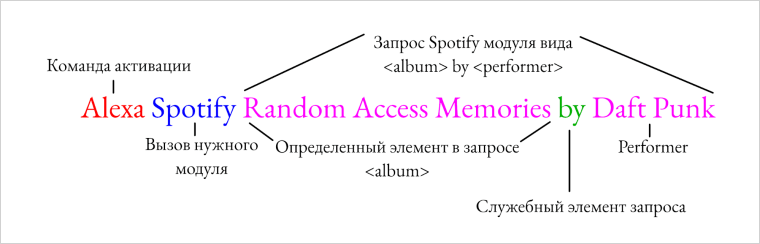
- Команда активации — Alexa;
- Команда выбора модуля — музыкальный модуль Spotify;
- Spotify query template matching <album> by <artist> — тут подсистема поняла, что у нас запрос вида <music> by <performer> и что в данной ситуации <music> является альбомом, а <performer> — группой.





Комментарии (33)

Antizavr
13.12.2019 18:27+3Грубо говоря, здесь речь идет об экспертных системах, искусственный интеллект на текущем уровне техники — это фантастика.

QDeathNick
18.12.2019 00:43-3А говоря менее грубо, здесь речь идёт об интеллектуальной системе, способой успешно выявить смысловые и фактические ошибки в академическом эссе на уровне специалиста в условиях ограниченного времени.
Как мне кажется, за это сойдёт даже набор regexp, сгенерённый на основе генетического алгоритма. Главное генерить в районе SK Сколково и тогда приз ваш.

dougrinch
15.12.2019 12:48+4> Интересный инсайт: в такой игре, как StarCraft, обладая возможностью быстро и безошибочно контролировать и координировать действия, простые линейные юниты побеждают даже самые сложные комбинации созданий и существ.
Только вот работает это только в ситуациях, подобных тем, на которых AI учился. А в любой новой нестандартной он начинает тупить и делать вещи, абсурдность которых человеку очевидна. www.youtube.com/watch?v=mpAUufSzaUo
Treviz
18.12.2019 00:16+3В Старкрафте ДипМайнд стал резко проигрывать середнячкам (даймонд лига) после лишения только половины читерских возможностей.

Kilorad
16.12.2019 12:52+1Reinforcement Learning пока ещё работает довольно плохо.
habr.com/ru/post/437020
Есть отдельные впечатляющие достижения, но обычно это результат очень ручного серьёзного дотачивания системы под задачу.
Чего-то надёжного, типа XGBoost, но для RL пока не сделали, к сожалению
allbom
19.12.2019 10:36+3В шахматах выбор не такой уж и большой, 20 — это максимально возможное число на первом ходу, а осмысленных из них не больше 12 и число их не растет, а уменьшается. Но шахматы — игра счетная и делать это надо постоянно, человек проигрывает когда устает и пропускает удар. В Го же большее значение имеет интуиция и если компьютер начал выигрывать в Го — пора звать семейку Конноров.

dom1n1k
23.12.2019 01:30+1Почему число ходов уменьшается? Фигур становится меньше, но за счет опустения доски у них становится больше вариантов движения. Условно говоря, в исходной позиции у коня всего 2 варианта хода, а в эндшпиле в центре почти пустой доски — 8. Ладья, слон, ферзь в эндшпиле легко могут иметь больше десятка возможных ходов на одну фигуру.
allbom
23.12.2019 04:27+1Возможных ходов — больше, осмысленных — меньше. Stockfish оценивает 70 миллионов позиций в секунду, разорвавший его AlphaZero от DeepMind — 80,000/сек., на 99.89 процентов позиций меньше.
(https://www.chess.com/ru/article/view/kak-ustroen-shakhmatnyi-mozg-alphazero):
… проблемой шахмат является взрывное ветвление вариантов. Расчет на два хода вперед из дебютной позиции требует оценки 150,000 позиций и с увеличением глубины это количество растет экспоненциально. AlphaZero сокращает количество вариантов, рассматривая только ходы, рекомендованные ее стратегической сетью. Она также использует оценочную сеть, чтобы прекратить изучение вариантов с ясной оценкой (победа/поражение).
Допустим, что стратегическая сеть предлагает в среднем по три заслуживающих внимания хода в каждой позиции. При скорости 80,000 позиций в секунду, которую использует AlphaZero, за минуту она заглянет на семь полных ходов вперед...dom1n1k
23.12.2019 11:08+1Главная проблема не ветвление вариантов, а функция оценки позиции. Чтобы как раз отличать возможные ходы от осмысленных. Это самое сложное и именно в этой части прорыв у Альфы.

Akon32
31.01.2020 18:36свой тупой язык достаточно умным людям
И эти "достаточно умные люди" изъясняются неоднозначными фразами ("Ты где?" — "Я щас буду"), сами не понимают друг друга, а потом жалуются, что это ИИ тупой.
попытки создать новый мировой язык
Увы, это никому не нужно. Есть английский, мировой дефакто. В принципе, вместо него мировым может быть любой другой язык, как только получит распространение. Очередной новый язык обычно не вносит ничего нового, не имеет "киллер-фич", не имеет того, что нельзя выразить более стандартным языком.
вследствие распостранения голосового ввода из английского стремительно уходят знаки препинания
Да? Я помню, в английском было куда меньше запятых, чем в русском, даже до голосового ввода.


anonymous
00.00.0000 00:00Akon32
28.01.2020 04:56+1Так значит, стройность и однозначность бинарного лингва технис вы не одобряете?
Между тем, хорошие приказы, как и хорошие отчёты, должны интерпретироваться правильно, полно и однозначно. Языки программирования тому пример. А SQL — ещё и пример попытки создания человекочитаемого языка программирования.
Не вижу ничего плохого в том, чтобы вместе с естественным языком учить некий универсальный язык запросов для плотного взаимодействия с любой техникой. Сейчас тыкать пальцем в планшет, вроде бы, учатся раньше, чем говорить, но этого, наверно, недостаточно для чёткого изложения любых мыслей.
Akon32
03.02.2020 16:02[саркастически] ну ага.
При создании языка можно предусмотреть теги эмоций)Но зачем это всё (эмоции) при общении с роботом? У вас есть сообщение роботу, вы преобразовываете своё сообщение в несколько бит данных, чтобы робот корректно понял сообщение и сделал именно то, что вам нужно. Вы не хотите, чтобы робот понял вас неправильно. Логично предусмотреть надёжную и однозначную систему сообщений. Глупо кодировать сообщения кодом без спецификации (эмоциями). У некоторых предрасположенных людей, я слышал, подобные неоднозначности могут даже спровоцировать шизофрению. После команды "АЛИСАААА !!!" робот же с некоторой вероятностью сделает не то, что вам нужно. Человек, кстати, тоже.
Akon32
06.02.2020 11:32Уровень срочности / важности.
Для этого придумали
числазапись приоритета числами. Опять же, каждую фразу несложно тегировать.Да не в этом суть. Команды должны быть однозначны, тогда как эти ваши "характеры звукоизвлечения" у животных неоднозначны и имеют неписаные правила. Если какой-то пользователь привык орать и слюной брызгать, отдавая приказы, это не значит, что приказ другого пользователя, сказанный монотонно, можно не выполнять.

PavelMSTU
23.12.2019 18:07-1А игры — это интересная абстракция части существующего мира
Нет, автор. Игры — это игры.Но как система идет от набора звуков к буквам и смыслам, которые за ним стоят?
Никак, читаем Джона Сёрля.Продолжать тему можно бесконечно, но, наверное, актуальный путь ее развития — это движение в сторону плотного взаимодействия человека и ИИ.
Нет. Путь — дальнейшая автоматизация под «хайп» и соус Data Science.

Dabbuger
25.12.2019 16:20+1я не знаю, правильно ли возмущаюсь, но всё же не машина нас учит, а программист (создатель железки, программы и т.д.), посредством машины, учит нас как ей пользоваться.
Не книга же нас учит, а её автор.Akon32
28.01.2020 04:34+1По поводу формализованных подмножеств языка вы, наверно, правы — структура фраз задаётся создателями этих языков. С другой стороны, типичные сценарии взаимодействия с компьютером, например раскладка клавиатуры, использование мыши, концепция ctrl-c ctrl-v, за много лет наверно настолько "выжигаются" в нейронной сети мозга, что их можно считать отдельным языком, и уже не разобраться, кто научил этому языку.
Гораздо интереснее случаи с "чистыми" реализациями ИИ в том же го (alpha zero и подобные). Тут программируются лишь правила игры, а не умение играть. Умение играть вычисляется машиной. И потом живые игроки 9 дана учатся именно у машины, а не программистов, её создавших, т.к. те программисты не понимают игру настолько хорошо, чтобы учить топовых игроков.

Nashev
29.01.2020 08:00Автор задаёт чему можно научиться, а учит нас то, что проверяет ответы и даёт на них обратную связь. Таки машина. Ей приходится говорить так, чтоб она отреагировала желаемым поведением

MaxLevs
30.12.2019 09:10+1Я так и не понял, чем так прославились 37 и 78 ходы? (слишком много энтимемов)
Посмотрел представленные кусочки документалки, но "ответов системы" не заметил. (мой англлийский)
Подскажите, пожалуйста, почему 37 ход так шокировал людей, а 78 стали звать "прикосновением бога"?Akon32
28.01.2020 04:11+1Про 37й ход 2й игры — машина сделала хороший ход "креативно", не по канонам, которых известно достаточно для начального этапа игры, чем всех удивила.
78й ход Ли Седоля в 4й игре оказался неожиданным для машины. После этого оценка позиции машины упала, машина начала делать плохие ходы и через несколько десятков ходов сдалась. Это было последним случаем, когда человек победил машину. Следующие версии машины, основные не на человеческом опыте, а на чистых правилах игры (zero), уверенно побеждали всегда, и человек вряд ли когда-нибудь ещё победит. (я имею в виду конфигурации alpha go и alpha go zero, играющие на полной мощности, в отличие от их свободных клонов типа leela zero, которые каждый волен запускать хоть на чайнике, и тогда их легко победить).
MaxLevs
02.03.2021 15:11А можно по-конкретнее, какие каноны обошла альфа на 37-м ходу? Я не искушён игрой Го, и для меня это просто "поставь камень рядом с камнем противника", но в документалке диктор на этом моменте начинает с восхищением рассказывать про связанность всех позиций в игре.
Akon32
03.03.2021 07:19Судя по фильму, все комментаторы сошлись во мнении, что этот диагональный ход по 5й линии — это слишком далеко от края доски, они говорят "так не играют". У противника камень на 4й линии создаёт возможность взять слишком много пунктов территории на правой стороне, и надавливание по 5й линии не ведёт к существенному уменьшению территории тут.
С другой стороны, это надавливание блокирует выход белых в центр и неплохо уменьшает влияние белых по правой стороне на центр… Такое "надавливание сверху" (вроде бы) часто применяется, по крайней мере по 4й линии и в эпоху после-AlphaGo.
Но, конечно, профессионалам и сильным программам виднее, их так просто не понять.

agmt
30.12.2019 09:12+2И тут случается что-то невероятное. Сначала мы учим помощника понимать человеческую речь, общаясь с ним так, как с обычным человеком, но потом незаметно для себя мы переходим на искусственный язык запросов.
Человек-человек системы тоже приходят к искусственному языку, если требуется точность передачи запроса и жесткое временнОе ограничение: общение с авиадиспетчером, отправка торговых заявок, отправка сообщений на пейджер (пытался отправить в детстве сообщение: операторши скидывали звонок несколько раз — видимо, не по шаблону и медленно говорил).

YernarShambayev
08.01.2020 09:24+1Вообще, честно говоря, сложилось впечатление, что автор поверхностно разбирается в теме программирования логических настольных игр (или, по крайней мере, неглубоко в ней).
«Магнус Карлсен утверждает, что видит в среднем на 15, а иногда на 20 ходов вперед (не endspiel) — современные компьютеры могут обсчитать на порядок большее число шагов.»
«На порядок больше» — это, как минимум, в 10 раз. Считать на 150-200 ходов современные машины не в состоянии и вряд ли будут в обозримом будущем. Считать на 150 ходов — это значит из начальной позиции увидеть, чем закончится партия, и фактически закрыть тему шахмат.
Лучшие современные движки считают в середине партии в среднем на 50-60 полуходов (!!), то есть на 25-30 ходов. Причем ветки в переборе разной глубины (где-то сокращаются всякими prunings и reductions, где-то продлеваются, например, quiescence search) Это много, это далеко, но это еще не закрывает тему шахмат. Компьютеры могущественны, но и с человеком на данном этапе развития нужно считаться (поэтому матчи «человек + машина» против «машины» заканчиваются в пользу адванса). Не удивлюсь, если выяснится, что и Leela Zero играет далеко не идеально.
Проблема подобного рода статей — в том, что их, к сожалению, пишут не спецы, а люди, просто интересующиеся темой. А так хотелось бы почитать взгляд на данную проблему от русскоязычных разработчиков Белки/Стрелки, Greko, Gull, WildCat и проч.
Извините, если излишне критичен.

kalisto74
23.01.2020 07:13+1Спасибо Вам за то, что поделились видением.
Согласна как с одним из вариантов будущего — вначале человек учит машину, но потом машина учит человека. И это взаимообратимо бесконечно.
Правда многообразие жизни предполагает и другие варианты и их много.
Да наступило время взаимосотрудничества с алгоритмами по всем областям. Я осознаю, что как вариант человек не станет особо необходим в экономической сфере по многим профессиям. И с другой стороны острая нехватка квалифицированных людей. Не только в плане интеллекта а в плане расширения сознания. Я смотрю на себя, на меняющийся мир и делаю выводы — видеть алгоритмы в своих мыслях, поступках, различать эмоциональную составляющую и логическую в себе. Раскрывать в себе скрытый потенциал — прислушиваясь и присматриваясь глубже. Я вижу как на работе я концентрируюсь на том, что делаю. Я словно машина, которая сама приняла в действие ряд этапов по решению задачи. Я вижу когда еду или отдыхаю — как хочется впитать все, что удивляет меня и наполняет. Я вижу как летит время — перемены ускоряются. И конечно мне любопытно очень интегрироваться с алгоритмами — интересно. Как ребенок жизни я фантазирую где и как автоматизировать что либо. А где раскрыть свой потенциал человеческий — интуицию, чтение мыслей, гипноз и другое.

me21
30.01.2020 08:13"Главное здесь — помнить, что человек решает, что, как и зачем происходит."
Это пока :-)
h3j3j
>Рассмотрим, например, голосовой помощник «Аэрофлота»
Ненавижу чатботов и голосовых помошников. Если я звоню в банк и мне отвечает машина я чувствую что на мне сэкономили и впарили ширпортреб. Это как баланда в дешевой столовке.
Кроме того, я человек в достаточной степени сообразительный чтобы простую информацию найти самому и если я звоню в поддержку — значит у меня достаточно сложный вопрос, на который и поддержка не всегда сразу ответит. И вместо того чтобы этот вопрос решать, я должен биться головой в голосового помощника. Это жесть и фрустрация.