
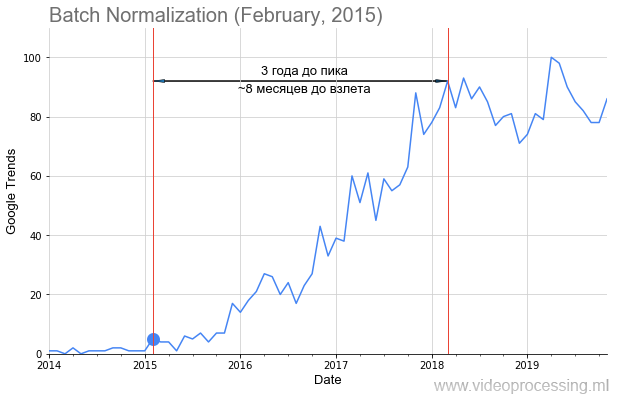
Новый год все ближе, скоро закончатся 2010-е годы, подарившие миру нашумевший ренессанс нейросетей. Мне не давала покоя

Понятно, что можно примерно посчитать количество статей по разным областям. Метод не идеальный, нужно учитывать подобласти, но в целом можно пробовать. Дарю идею, по Google Scholar (BatchNorm) это вполне реально! Можно считать новые датасеты, можно новые курсы. Ваш же покорный слуга, перебрав несколько вариантов, остановился на Google Trends (BatchNorm).
Мы с коллегами взяли запросы основных технологий ML/DL, например, Batch Normalization, как на картинке выше, точкой добавили дату публикации статьи и получили вполне себе график взлета популярности темы. Но не у всех тем
Кому интересно, что получилось — добро пожаловать под кат!
Вместо введения или про распознавание картинок
Итак! Исходные данные были довольно сильно зашумлены, иногда были резкие пики.

Источник: твиттер Андрея Карпаты — студенты стоят в проходах огромной аудитории, чтобы послушать лекцию по сверточным нейросетям
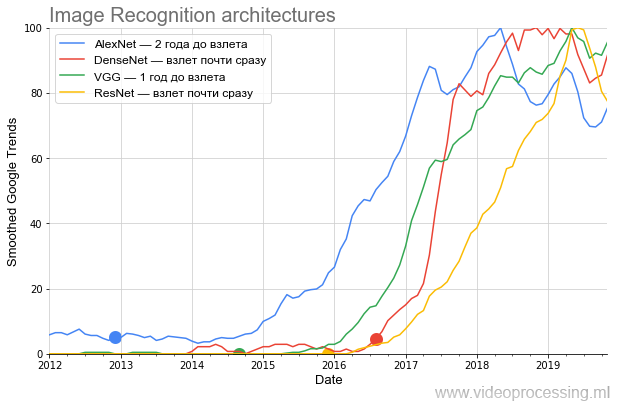
Условно, достаточно было Андрею Карпаты прочитать лекцию легендарного CS231n: Convolutional Neural Networks for Visual Recognition на 750 человек с популяризацией понятия, как идет резкий пик. Поэтому данные сглаживались простым box-фильтром (все сглаженные помечены как Smoothed на оси). Поскольку нас интересовало сравнение скорости роста популярности — после сглаживания все данные были нормализованы. Получилось довольно забавно. Вот график основных архитектур, соревновавшихся на ImageNet:
Источник: Здесь и далее — расчеты автора по данным Google Trends
На графике очень хорошо видно, что после нашумевшей публикации AlexNet, заварившей кашу текущего хайпа нейросетей в конце 2012, еще в течении практически двух лет бурлил
Дальше, во второй половине 2014, появился VGG. К слову, придумал VGG в соавторстве с научным руководителем мой бывший студент Карен Симонян, ныне работающий в Google DeepMind (AlphaGo, AlphaZero и т.д.). Учась в МГУ на 3-м курсе, Карен реализовал неплохой алгоритм Motion Estimation, который уже 12 лет служит референсом 2-курсникам. Причем задачи там в чем-то неуловимо похожи. Сравните:
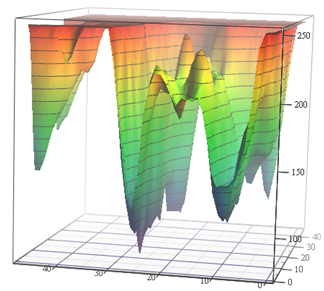
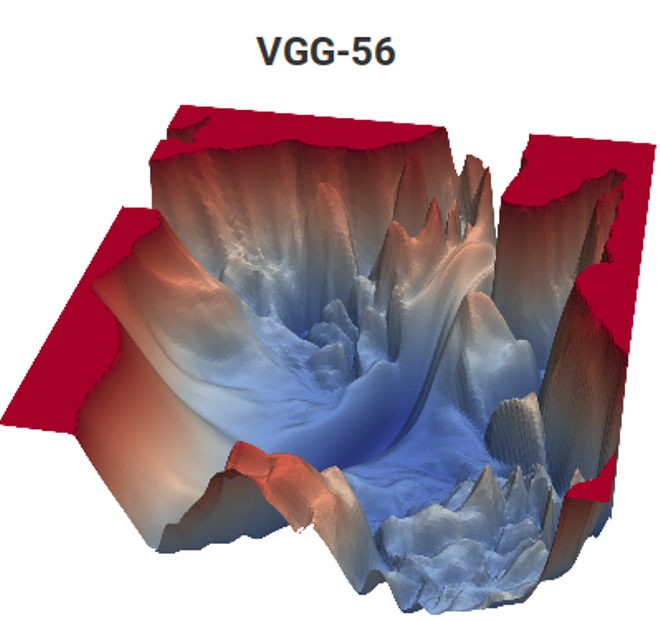
Источник: Функция потерь для задач Motion Estimation (материалы автора) и VGG-56
Слева нужно за минимальное число измерений найти самую глубокую точку в нетривиальной поверхности, зависящей от входных данных (при этом возможно много локальных минимумов), и справа нужно с минимальными вычислениями найти точку пониже (и тоже куча локальных минимумов, и тоже поверхность зависит от данных). Слева получим предсказанный motion vector, а справа — обученную сеть. А разница в том, что слева есть только неявное измерение цветового пространства, а справа это пара измерений из сотни миллионов. Ну и вычислительная сложность справа примерно на 12 порядков (!) выше. Чуть-чуть так… Но второй курс даже с простенькой задачкой колтыхаются как… [вырезано цензурой]. И уровень программирования вчерашних школьников по непонятным причинам за последние 15 лет заметно упал. Приходится им говорить: «Вот будете хорошо ME делать, вас возьмут в DeepMind!». Можно было бы говорить «изобретете VGG», но «возьмут в DeepMind» почему-то мотивирует лучше. Это, очевидно, современный продвинутый аналог классического «Будешь есть манную кашу, станешь космонавтом!». Впрочем, в нашем случае, если посчитать число детей в стране и размер отряда космонавтов, шансы в миллионы раз выше, ибо из нашей лаборатории уже двое работают в DeepMind.
Дальше был ResNet, пробивший планку количества слоев и начавший взлетать через полгода. И, наконец, пришедшийся на начало хайпа DenseNet пошел на взлет почти сразу, даже круче ResNet.
Если мы говорим про популярность, хотелось бы пару слов вставить про характеристики сети и эффективность работы, от которых популярность тоже зависит. Если посмотреть, как на ImageNet предсказывают класс в зависимости от количества операций в сети, расклад будет такой (выше и левее — лучше):
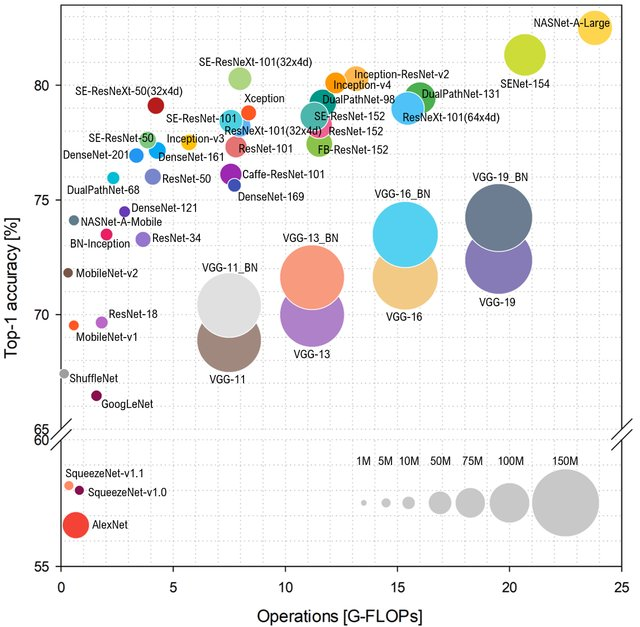
Источник: Benchmark Analysis of Representative Deep Neural Network Architectures
Типа AlexNet уже совсем не торт, и рулят сети на основе ResNet. Однако если посмотреть на более близкую моему сердцу практическую оценку FPS, то хорошо видно, что VGG тут поближе к оптимуму, и вообще, расклад заметно меняется. В том числе AlexNet неожиданно на Парето-оптимальной огибающей (горизонтальная шкала логарифмическая, лучше выше и правее):
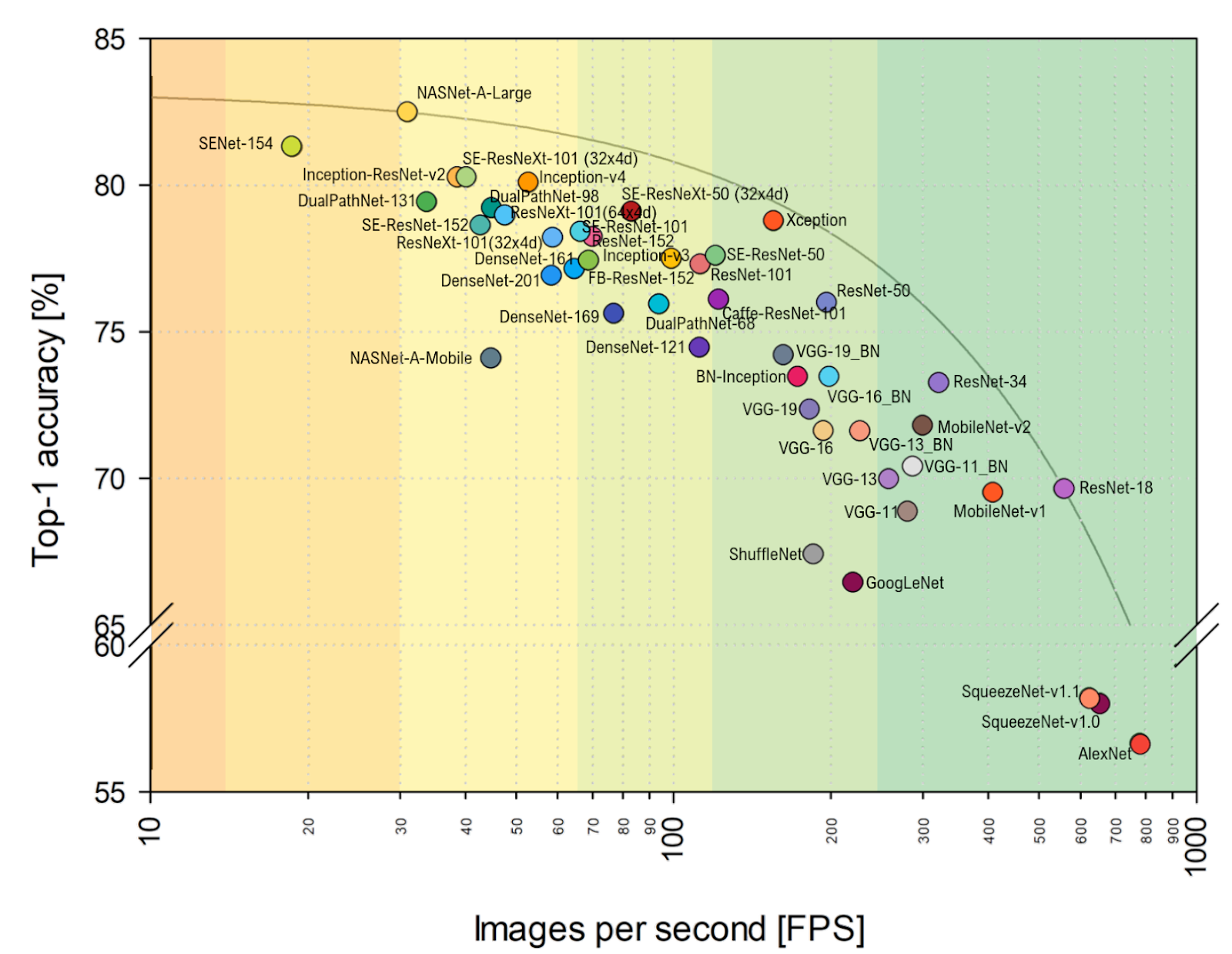
Источник: Benchmark Analysis of Representative Deep Neural Network Architectures
Итого:
- В ближайшие годы расклад архитектур с большой вероятностью очень существенно поменяется из-за прогресса акселераторов нейросетей, когда какие-то архитектуры уйдут в корзины, а какие-то внезапно взлетят, просто потому что лучше лягут на новое железо. Например, в упомянутой статье сделано сравнение на NVIDIA Titan X Pascal и NVIDIA Jetson TX1 board, и расклад заметно меняется. При этом прогресс TPU, NPU и прочих только начался.
- Как практик, не могу не обратить внимание, что сравнение на ImageNet делается по умолчанию на ImageNet-1k, а не на ImageNet-22k, уже просто потому, что большинство тренирует свои сети на ImageNet-1k, где в 22 раза меньше классов (это и проще, и быстрее). Переход на ImageNet-22k, более актуальный для многих практических применений, также поменяет расклад (для тех, кто заточился на 1k — сильно).
Глубже в технологии и архитектуры
Впрочем, вернемся к технологиям. Термин Dropout как поисковое слово достаточно зашумлен, однако 5-кратный рост явно связан с нейросетями. А спад интереса к нему — скорее всего с патентом Google и появлением новых методов. Обратите внимание, что от публикации исходной статьи до всплеска интереса к методу прошло около полутора лет:
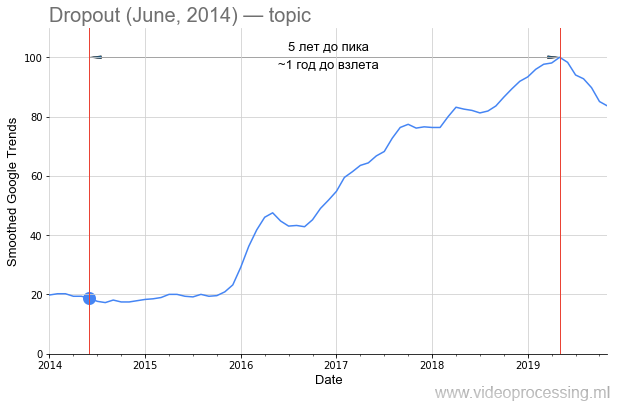
Впрочем, если говорить о сроке до взлета популярности, то в DL одно из первых мест явно занимают рекуррентные сети и LSTM:
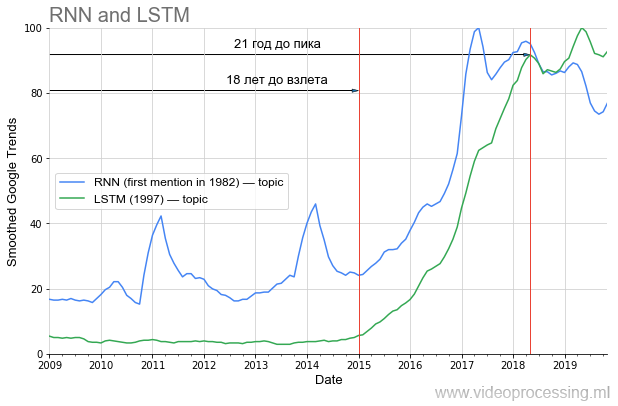
Долгие 20 лет до текущего пика популярности, и теперь с их использованием кардинально улучшен машинный перевод, анализ генома, а в ближайшее время (если из моей области брать) благодаря им вдвое упадет трафик YouTube, Netflix при том же визуальном качестве. Если правильно учить уроки истории, то очевидно, что часть идей из текущего вала статей «взлетит» только через 20 лет. Ведите здоровый образ жизни, берегите себя, и вы увидите это лично!
Теперь ближе к обещанному хайпу. GAN-ы взлетали так:
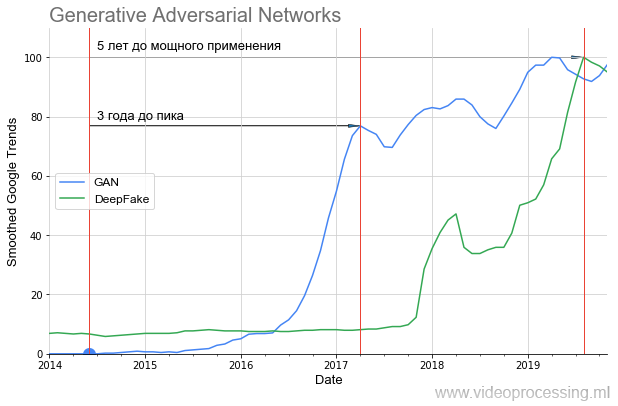
Хорошо видно, что почти год была вообще тишина и только в 2016, через 2 года, пошел резкий взлет (результаты удалось заметно улучшить). Этот взлет еще через год дал нашумевший DeepFake, тоже, впрочем, взлетавший 1,5 года. То есть даже очень многообещающим технологиям требуется заметное время, чтобы от идеи дойти до приложений, которые может использовать каждый.
Если посмотреть, какие картинки генерировал GAN в исходной статье и что можно построить со StyleGAN, то становится совершенно очевидно, почему была такая тишина. В 2014 только специалисты могли оценить, как это круто — сделать, по сути, функцией потерь другую сеть и обучать их вместе. А в 2019 оценить, как это круто, мог уже каждый школьник (совершенно не понимая, как это сделано):

Разных проблем, успешно решаемых нейросетями, сегодня очень много, можно брать лучшие сети и строить графики популярности для каждого направления, разбираться с шумами и пиками поисковых запросов и т.д. Чтобы не растекаться мыслью по древу, завершим эту подборку темой алгоритмов сегментации, где идеи atrous/dilated convolution и ASPP в последние полтора года вполне себе выстрелили в бенчмарке алгоритмов:
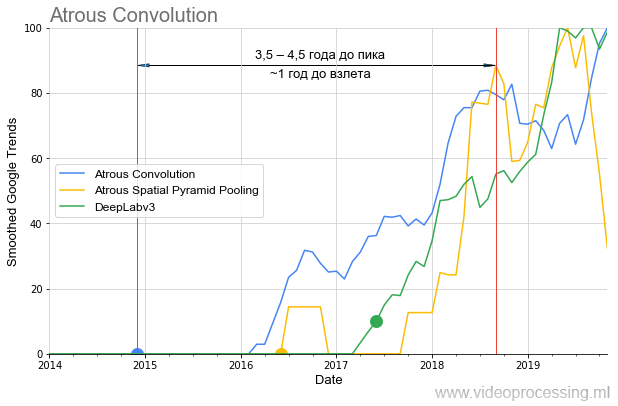
Также следует отметить, что если DeepLabv1 год с лишним «ждал» взлета популярности, то DeepLabv2 взлетел через год, а DeepLabv3 вообще практически сразу. Т.е. в целом можно говорить об ускорении роста интереса со временем (ну или ускорение роста интереса к технологиям зарекомендовавших себя авторов).
Все это вместе привело к созданию следующей глобальной проблемы — взрывному росту количества публикаций по теме:
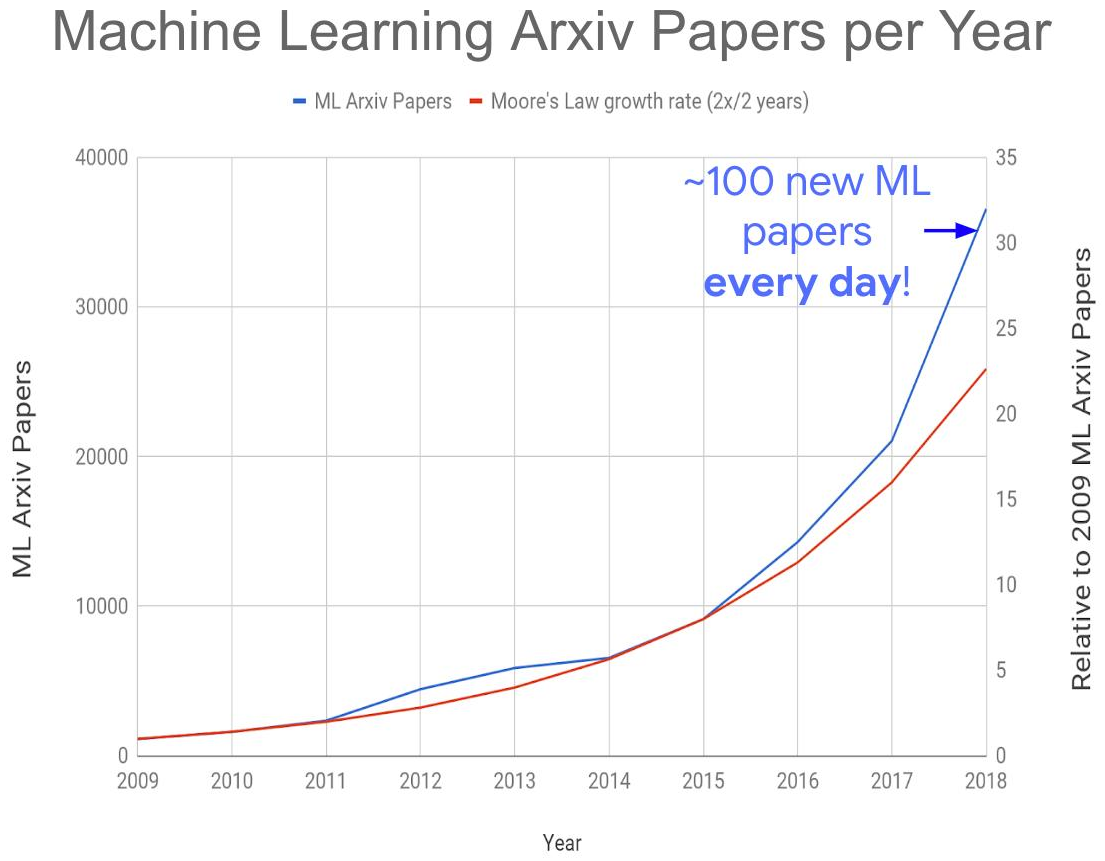
Источник: Too many machine learning papers?
На этот год получается порядка 150–200 статей в день, учитывая, что на arXiv-e публикуются не все. Прочитывать статьи даже в своей подобласти сегодня становится совершенно невозможно. Как следствие, многие интересные идеи заведомо окажутся погребенными под завалами новых публикаций, что скажется на сроках их «взлета». Впрочем, также взрывное увеличение числа грамотных специалистов, занятых в области, дает
Итого:
- Помимо ImageNet и оставшейся за кадром истории с игровыми успехами DeepMind, GAN-ы дали начало новой волне популяризации нейросетей. С ними реально стала возможна «съемка» актеров без применения камеры. И то ли еще будет! Под этот информационный шум будут финансироваться и менее звучные, но вполне рабочие технологии обработки и распознавания.
- Поскольку публикаций становится слишком много, с нетерпением ждем появления новых нейросетевых методов быстрого анализа статей, ибо только они нас спасут (шутка с долей шутки!).
Вкалывают роботы, счастлив человек
Уже 2 года
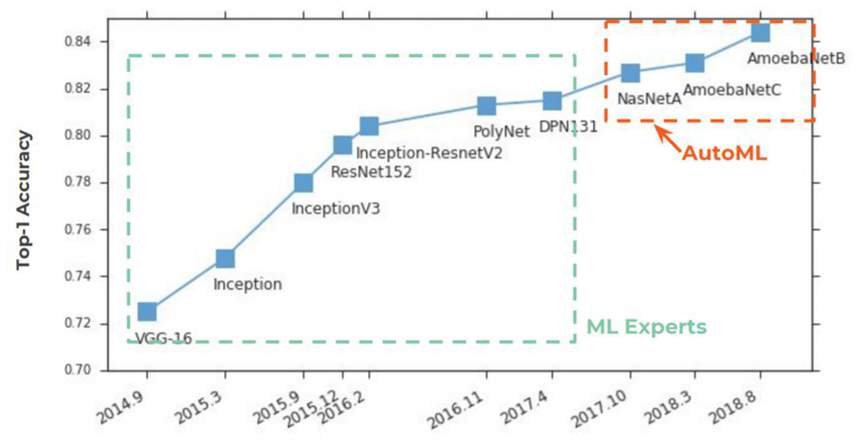
Суть AutoML очень проста, в нем сбылась вековая мечта data scientist-ов — чтобы гиперпараметры подбирала нейросеть. Идея была встречена на ура:

Ниже на графике мы видим довольно редкую ситуацию, когда после публикации исходных статей по NASNet и AmoebaNet, они начинают набирать популярность по меркам предыдущих идей практически мгновенно (сказывается огромный интерес к теме):
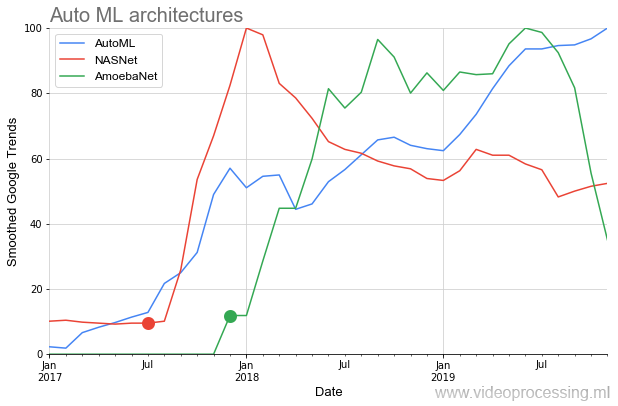
Идиллическую картину несколько портят два момента. Во-первых, любой разговор про AutoML начинается с фразы: «Если у вас есть дофигалион GPU...». И это проблема. Google, конечно, утверждает, что с их Cloud AutoML это легко решаемо,
В любом случае, основной взлет AutoML начнется со следующим поколением аппаратных акселераторов нейросетей и, собственно, с улучшением алгоритмов.

Источник: Картинка Дмитрия Коновальчука, материалы автора
Итого: На самом деле вечного праздника у data scientist-ов не наступит, конечно, ибо еще очень надолго останется большая головная боль с данными. Но перед Новым Годом и началом 2020-х почему бы не помечтать?
Пара слов про инструменты
Эффективность исследований очень сильно зависит от инструментов. Если для того, чтобы запрограммировать AlexNet, нужно было нетривиальное программирование, то сегодня подобную сеть можно в несколько строк собрать в свежих фреймворках.
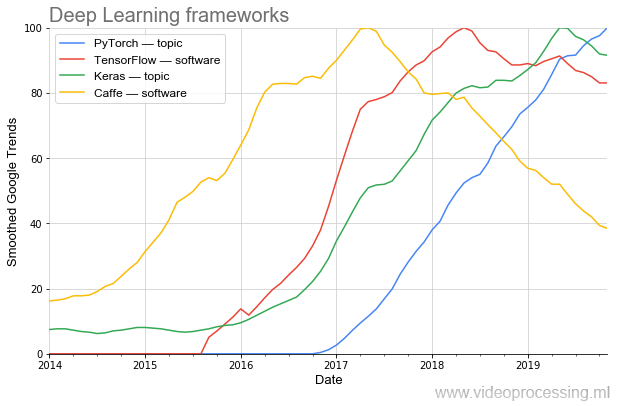
Хорошо видно, как волнами меняется популярность. На сегодня наиболее популярным (в том числе по данным PapersWithCode) является PyTorch. А когда-то популярный Caffe красиво очень плавно уходит. (Примечание: topic и software означает, что при построении графика использовалась фильтрация по теме от Google.)
Ну и раз мы затронули инструменты разработки, стоит упомянуть библиотеки ускорения исполнения сетей:
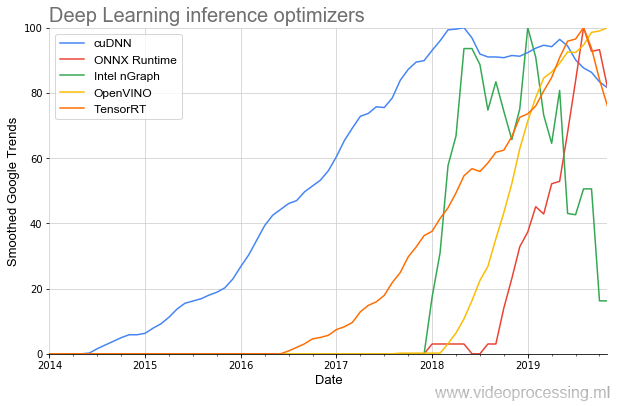
Старейшей в теме является (респект NVIDIA) cuDNN, и, к счастью для разработчиков, за последние пару лет количество библиотек кратно возросло, а старт их популярности стал ощутимо круче. И, похоже, все это — еще только начало.
Итого: Даже за последние 3 года инструменты серьезно изменились к лучшему. А 3 года назад их по нынешним меркам не было совсем. Прогресс очень хороший!
Обещанные перспективы нейросетей
Но самое интересное начнется позднее. Этим летом в отдельной большой статье я подробно описал, почему CPU и даже GPU — недостаточно эффективны для работы с нейросетями, почему миллиарды долларов вливаются в разработку новых чипов, и какие там перспективы. Не буду повторяться. Ниже обобщение и дополнение предыдущего текста.
Начнем с того, что надо понимать отличия вычислений нейросетей от вычислений в привычной фон Неймановской архитектуре (в которой их вычислять, конечно, можно, но менее эффективно):
Источник: Картинка Дмитрия Коновальчука, материалы автора
| Архитектура фон Неймана |
Нейросети |
| Большинство вычислений — последовательное выполнение операций |
Массивно-параллельные вычисления (нужна архитектура с большим количеством вычислительных модулей и акселерацией тензорных вычислений) |
| Ход вычислений меняется в зависимости от условий (нужна суперскалярность) |
Структура вычислений почти всегда фиксирована и заранее известна (суперскалярность неэффективна) |
| Есть локальность по данным (хорошо работает кэш) |
Нет локальности по данным (кэш греет воздух) |
| Вычисления точные |
Вычисления могут быть неточными |
| Данные изменяются по-разному для разных алгоритмов |
Десятки мегабайт коэффициентов сети неизменны при многократном прогоне данных через нейросеть |
В предыдущий раз основное обсуждение пошло вокруг FPGA/ASIC, а неточные вычисления остались практически незамеченными, поэтому остановимся на них поподробнее. Огромные перспективы уменьшения чипов следующих поколений именно в возможности считать неточно (и хранить локально данные коэффициентов). Огрубление, собственно, используется и в точной арифметике, когда веса сети переводятся в целые числа и квантуются, но на новом уровне. В качестве примера рассмотрим однобитный сумматор (пример достаточно абстрактный):
Источник: A High Speed and Low Power 8 Bit x 8 Bit Multiplier Design using Novel Two Transistor (2T) XOR Gates
Ему требуется 6 транзисторов (существуют разные подходы, число требуемых транзисторов может быть больше и меньше, но в целом примерно так). Для 8 бит требуется примерно 48 транзисторов. При этом аналоговому сумматору требуется всего 2 (два!) транзистора, т.е. в 24 раза меньше:
Источник: Analog Multipliers (Analysis and Design of Analog Integrated Circuits)
Если точность будет более высокой (например, эквивалентной цифровым 10 или 16 битам), разница будет еще больше. Еще интереснее ситуация с умножением! Если цифровому 8-битному мультиплексору требуется около 400 транзисторов, то аналоговому 6, т.е. в 67 раз (!) меньше. Безусловно, «аналоговые» и «цифровые» транзисторы с точки зрения схемотехники существенно отличаются, однако идея понятна — если нам удается повысить точность аналоговых вычислений, то мы на умножениях легко достигаем ситуации, когда нам требуется на два порядка меньше транзисторов. И дело даже не столько в сокращении размера (что важно в связи с «замедлением закона Мура»), сколько в сокращении потребления электричества, что критично для мобильных платформ. Да и для дата-центров лишним не будет.
Источник: IBM thinks analog chips to accelerate machine learning
Ключевым для успеха тут будет сокращение точности, и опять тут IBM в первых рядах:
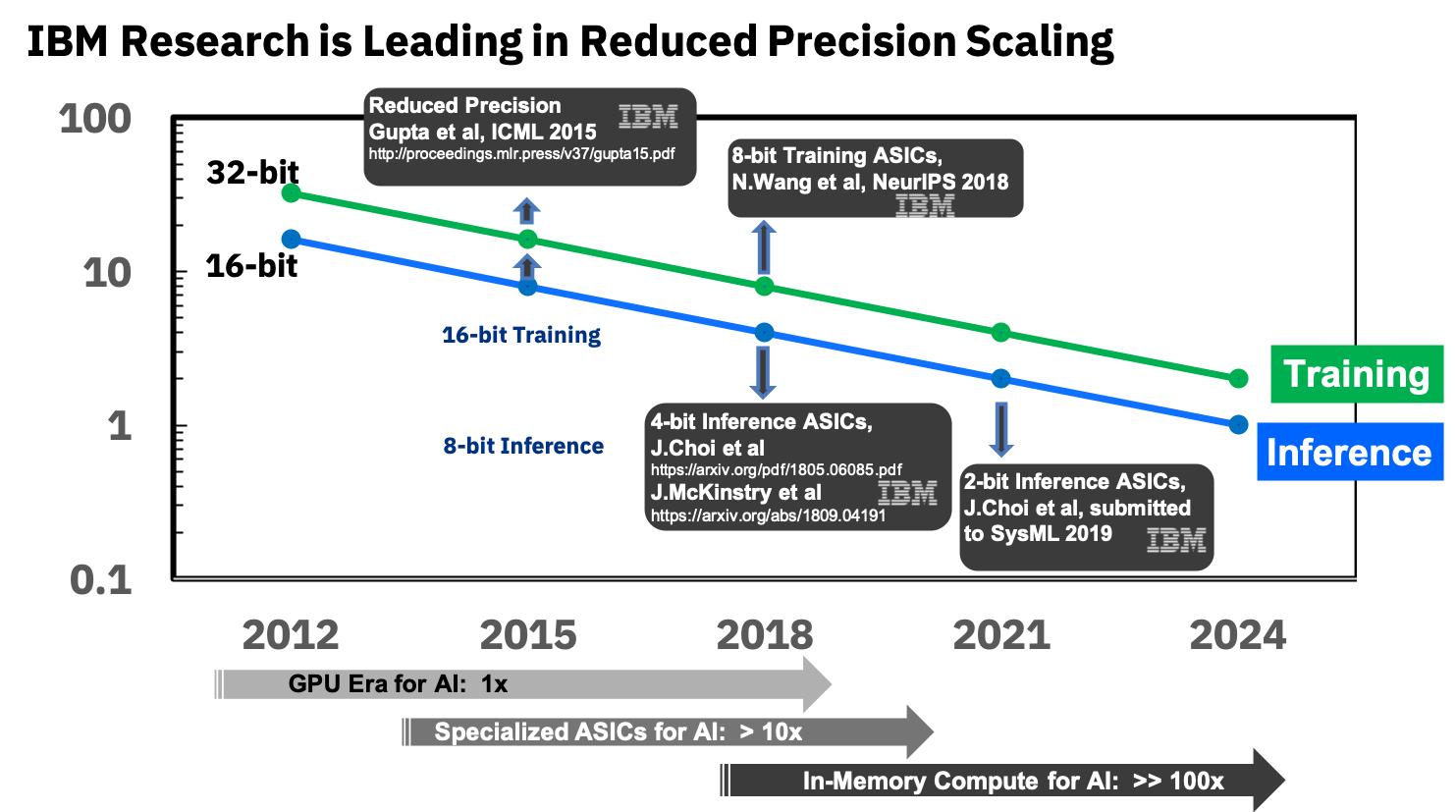
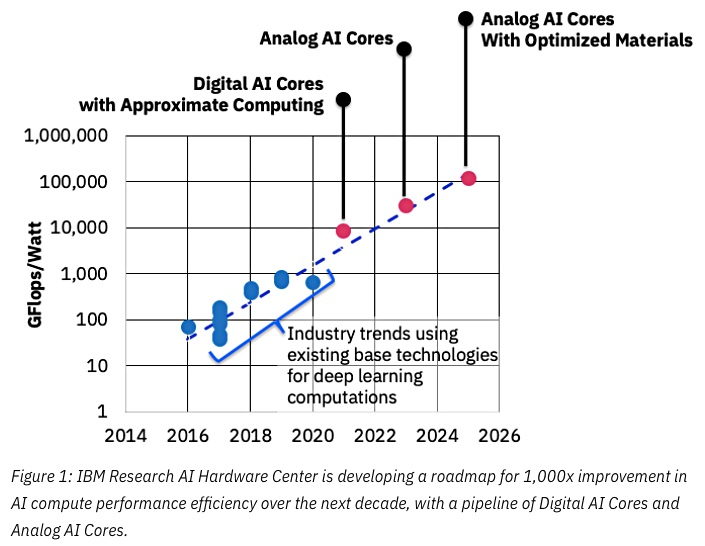
Источник: IBM Research Blog: 8-Bit Precision for Training Deep Learning Systems
Они уже занимаются специализированными ASIC для нейросетей, которые показывают более чем 10-кратное превосходство над GPU, и планируют в ближайшие годы достичь 100-кратного превосходства. Выглядит предельно обнадеживающе, очень ждем, поскольку, повторюсь, для мобильных устройств это будет прорыв.
Пока же ситуация не так волшебна, хотя есть серьезные успехи. Вот интересный тест текущих мобильных аппаратных акселераторов нейросетей (картинка кликабельна, и, что опять греет душу автора, тоже в картинках в секунду):

Источник: Performance evolution of mobile AI accelerators: image throughput for the float Inception-V3 model (FP16 model using TensorFlow Lite and NNAPI)
Зеленым обозначены мобильные чипы, синим — CPU, оранжевым — GPU. Хорошо видно, что текущие мобильные чипы и в первую очередь топовый чип от Huawei уже обгоняют по производительности CPU в десятки раз большего размера (и энергопотребления). И это сильно! С GPU пока все не так волшебно, но то ли еще будет. Подробнее результаты можно посмотреть на отдельном сайте http://ai-benchmark.com/, обратите там внимание на секцию тестов, они выбрали хороший набор алгоритмов для сравнения.
Итого: Прогресс аналоговых акселераторов сегодня довольно сложно оценивать. Идет гонка. Но изделия пока не вышли, поэтому публикаций относительно мало. Можно мониторить появляющиеся с задержкой патенты (например, плотный поток от IBM) или выуживать редкие патенты других производителей. Похоже, это будет очень серьезная революция, в первую очередь в смартфонах и серверных TPU.
Вместо заключения
ML/DL сегодня называют новой технологией программирования, когда мы не пишем программу, а вставляем блок и обучаем его. Т.е. типа сначала был ассемблер, потом С, потом С++, и вот теперь, после долгих 30 лет ожидания, следующая ступенька — ML/DL:
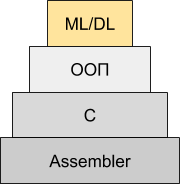
В этом есть свой смысл. В продвинутых компаниях с недавних пор места принятия решений в программах заменяют нейросетями. Т.е. если вчера там были решения «на IF-ах» или на милых сердцу программиста эвристиках или даже использовались уравнения Лагранжа (вау!) и прочие более сложные достижения десятилетий развития теории управления, то сегодня там ставят простенькую нейросеть на 3-5 слоев с несколькими входами и несколькими десятками коэффициентов. Она мгновенно обучается, ощутимо эффективнее работает, и разрабатывать код становится быстрее. Если раньше надо было сидеть, шаманить
Естественно, отладка теперь отличается. Если раньше, когда что-то не работало, шел запрос: «Пришлите пример, на котором не работает!» И дальше серьезный опытный
Впрочем, как математический инструмент ML/DL вообще и нейросети в частности — это явно нечто большее, чем следующая технология программирования. Те же нейросети теперь встречаются просто на каждом шагу:
- Смартфон фотографирует текст и распознает его — это нейросети,
- Смартфон неплохо переводит на лету с языка на язык и проговаривает перевод — нейросети и еще раз нейросети,
- Навигатор и умная колонка вполне сносно распознают речь — снова нейросети,
- Телевизор показывает яркую контрастную картинку 8K из входного 2K видео — также нейросети,
- Роботы на производстве стали точнее, начали лучше видеть и распознавать нештатные ситуации — опять нейросети,
- Школьник в 10 классе скачивает из интернета сканы школьных сочинений, размечает их на буквы и пишет
на коленкена удивление неплохо работающую программу распознавания рукописного текста, неподъемную задачу для мега-профессионалов 90-х — и тут нейросети,
- В автосервисе записывают звук двигателя и тут же получают список потенциальных проблем — и это нейросети,
- И даже так — команда вместо непростого и до сих пор медленного решения дифференциальных уравнений инверсной кинематики обучает что-то волшебное и получает быстрые и довольно точные решения — конечно же это нейросети,
- В общем — нейросети теперь абсолютно везде! )

С момента, когда люди научились обучать действительно глубокие нейросети во многом благодаря BatchNorm (2015) и skip connections (2015), прошло всего 4 года, а с момента, как они «взлетели», — 3 года, и результаты их работы мы пока толком не видели. И сейчас они будут доходить до продуктов. Что-то подсказывает, что в ближайшие годы нас ждет много интересного. Особенно когда «взлетят» акселераторы…

Когда-то давно, если кто помнит, Прометей похитил с Олимпа огонь и передал его людям. Рассердившийся Зевс с другими богами создали первую красавицу женщину-человека по имени Пандора, которую наделили многими замечательными женскими качествами

Источник: Художник Фредерик Стюарт Чёрч, «Открытый ящик Пандоры»
С тех времен пошло выражение «открыть ящик Пандоры», то есть совершить
Знаете, чем глубже у меня погружение в нейросети, тем явственнее ощущение, что это очередной ящик Пандоры. Впрочем, у человечества богатейший опыт открытия подобных ящиков! Из свежего недавнего — это ядерная энергетика и интернет. Так что, думаю, совместными усилиями справимся. Не зря же куча суровых
Итого:
- В статью не вошло много интересных тем, например, классические ML алгоритмы, transfer learning, reinforcement learning, популярность датасетов и т.д. (Господа, вы можете продолжить тему!)
- К вопросу о ларце: я лично считаю, что программисты Google, которые добились того, что Google отказалась от контракта с Пентагоном на 10 миллиардов, — молодцы и красавцы. Им респект и уважуха. Впрочем, заметим, кто-то этот крупный тендер выиграл.
Читайте также:
- Аппаратное ускорение глубоких нейросетей: GPU, FPGA, ASIC, TPU, VPU, IPU, DPU, NPU, RPU, NNP и другие буквы — текст автора про текущее состояние и перспективы аппаратного ускорения нейросетей в сравнении с текущими подходами.
- Deep Fake Science, кризис воспроизводимости и откуда берутся пустые репозитории — про проблемы в науке, порождаемые ML/DL.
- Уличная магия сравнения кодеков. Раскрываем секреты — пример фейка на основе нейросетей.
Всем большого количества новых интересных открытий в 2020-х вообще и в Новом году, в частности!
Благодарности
Хотелось бы сердечно поблагодарить:
- Лабораторию Компьютерной Графики и Мультимедиа ВМК МГУ им. М.В. Ломоносова за вклад в развитие глубокого обучения в России и не только,
- персонально Константина Кожемякова и Дмитрия Коновальчука, которые сделали очень много для того, чтобы эта статья стала лучше и нагляднее,
- и, наконец, огромное спасибо Кириллу Малышеву, Егору Склярову, Николаю Оплачко, Андрею Москаленко, Ивану Молодецких, Евгению Ляпустину, Роману Казанцеву, Александру Яковенко и Дмитрию Клепикову за большое количество дельных замечаний и правок, сделавших этот текст намного лучше!
Комментарии (42)

da0c
25.12.2019 12:27+1Статья отличная, спасибо!
Однако Deep Learning слишком долго на пике хайпа на кривой Гартнера (вот, например, 2018 год), и ожидаемо должен был свалиться. Тем более разговоры о том, что Free lunch is over для классических сверточных сетей ведуться достаточно массированно. Вот статья, в которой есть основные тезисы таких разговоров, ее уже упоминали здесь в комментариях.
Если же посмотреть на Гартнера 2019 года, то можно увидить интересный эффект — DL не свалился с пика, а просто исчез… развалившись на составные части — AutoML, GAN сети, Transfer Learning. Но ни в "пропасть разочарования", ни на "плато продуктивности" ни одна из этих частей (пока) не попала.
Что это означает доподлинно судить не берусь, но мне кажется, что DL как цельное понятие с пика хайпа уходит.
3Dvideo Автор
25.12.2019 12:53Статья отличная, спасибо!
Спасибо!)
Однако Deep Learning слишком долго на пике хайпа на кривой Гартнера
Я бы различал подобные взлеты в науке, у стартапов, и у продуктов.
Гартнер — это для стартапов и я с перегретостью темы для них я согласен, о чем писал.
С наукой — сложнее, поскольку там волны возникают либо когда тема расширяется, либо при открытии нового метода, который дает хотя бы локальный прорыв.
Ну и сложнее всего (и интереснее) с продуктами. Я про это писал недавно в большой статье — про экспоненциальный рост рынков. Там были хорошие графики, как выглядит взлет продуктов.
Возвращаясь к нейросетям — на мой взгляд взлет действительно глубоких сетей (100+ слоев) только начинается. И все очень зависит от акселераторов. У них рост точно будет, но если будет прорыв (в 100 раз быстрее GPU хотя бы в узких областях) — это будет мощнейший толчок. Основания для оптимизма есть.
DL не свалился с пика, а просто исчез… развалившись на составные части — AutoML, GAN сети, Transfer Learning
Да-да-да! Именно так. Происходит явное расширение темы. При том, что соседние области явно усиливают друг-друга просто за счет использования одних инструментов, одного железа и т.д.
DL как цельное понятие с пика хайпа уходит.
Если DL уйдет с пика хайпа для стартапов — это будет большое благо (сейчас масса случаев, когда деньги дали явным проходимцам). Печально будет, если история повторится с завернутыми в другие обертки теми же ушами. Пока, к тому идет.

beduin01
25.12.2019 13:59Такими темпами к 2025 году мы и сильный ИИ увидим.
3Dvideo Автор
25.12.2019 16:38+2Маловероятно) А вот что тема второе дыхание получит — крайне вероятно.

Ermit
25.12.2019 18:15Согласен с Вами. Второе, третье и четвертое дыхание. На фоне этого понимания очень странно слышать прогнозы о «новой зиме ИИ»…
Что касается СИИ, здесь ключевую роль сыграет «генеральная идея», которая объединит существующие методы ML/DL вокруг новой архитектуры.3Dvideo Автор
25.12.2019 19:31На фоне этого понимания очень странно слышать прогнозы о «новой зиме ИИ»…
Негативные новости просто лучше кликаются.) Всегда! Это вечная тема, примерно как статьи о крахе доллара)
Что касается СИИ, здесь ключевую роль сыграет «генеральная идея», которая объединит существующие методы ML/DL вокруг новой архитектуры.
Возможно. По крайней мере нет ощущения, что с архитектурами все резервы выбраны, скорее наоборот. В любом случае плавное развитие благодаря ускорению обучения заведомо будет происходить.
ua30
25.12.2019 18:57+2Нейросети, безусловно, новая веха в IT. Но нейросети !== ИИ. В текущей реализации им не хватает целого ряда ключевых свойств. Сколько данных не было бы в распоряжении сети.
3Dvideo Автор
25.12.2019 19:33+1Согласен. Именно поэтому не использую термин ИИ, кроме как когда собеседник в такую терминологию переходит. Уже просто потому, что ИИ все определяют по разному, причем со временем (по десятилетиям) определения заметно меняются.

ZlodeiBaal
25.12.2019 21:47+3Вторая крутая статья за две недели! Как у вас сил хватает!:)
Главное что в текущем прогрессе смущает — что почти нет кардинально новых идей. По сути все новые алгоритмы/идей/результаты — это обсасывание идей и подходов 4-5 летней давности. Те же GAN — это 14 год.
С другой стороны наука так и должна работать. Нужно сначала сформулировать почему то что получилось не является ИИ. А когда задача будет сформулирована и понятна — тогда уже можно будет попробовать её решить.
Пока что-то всё упирается в «нужно больше хороших датасетов»/«как нам организовать разметку»:)red75prim
25.12.2019 22:56+2Главное что в текущем прогрессе смущает — что почти нет кардинально новых идей.
Идей много. Мало идей, которые получается заставить работать. Скажем, model-based reinforcement learning заставили работать лучше других подходов совсем недавно в MuZero. А древнюю идею объединения коннекционизма с манипуляциями символами пока заставить работать не получается. И когда/если получится, то это тоже не будет новой идеей.
3Dvideo Автор
26.12.2019 00:12В том числе! Это правда, что не всякую красивую идею удается быстро успешно применить так, чтобы большой прирост получился.
3Dvideo Автор
26.12.2019 00:10+1Вторая крутая статья за две недели! Как у вас сил хватает!:)
Антон, спасибо! Очень приятно! Писал урывками 2 месяца, положил разом просто) Хотелось до конца года успеть.
Главное что в текущем прогрессе смущает — что почти нет кардинально новых идей. По сути все новые алгоритмы/идей/результаты — это обсасывание идей и подходов 4-5 летней давности. Те же GAN — это 14 год.
В каком-то смысле это так кажется. Я как раз пытался донести мысль, что сейчас есть разные интересные идеи, но пока они так же уродливы, как и GAN в 2014, поэтому их крутизну мало кто заметил. И это нормально. С остальными идеями было то же самое, как правило, условное «признание» и «известность» приходили к ним через год-два после публикации. В худшем случае — через 20 лет. Это нормально! ) И хорошо видно по графикам.
Ну и в целом — исходя из того же Томаса Куна — после прорыва (в том числе микропрорыва типа GAN) — идет плато и оно тоже крайне для этого развития важно. У тех же GAN плато иллюстрируется великолепно. И это тоже очень важно.
Пока что-то всё упирается в «нужно больше хороших датасетов»/«как нам организовать разметку»:)
Это правда. Идет революция. Новое поколение алгоритмов работает на данных и текущих данныхкатегорическикатастрофически не хватает. И это объективно снижает эффективность науки, когда господа ученые начинаю клепать фигню, просто потому, что это дает +0,0001% на мелком датасете. Реально оно не работает. А на хорошие датасеты нужно время, делать их реально сложно. Это нормально! )Druu
26.12.2019 10:15Новое поколение алгоритмов работает на данных и текущих данных категорически катастрофически не хватает.
Ну, собственно, 50 лет назад у нейросетей была та же самая проблема :)
Данные появились — в результате задачи, поставленные для сетей 70-х годов, мы теперь решать худо-бедно умеем. Ждем еще 50 лет.3Dvideo Автор
26.12.2019 12:39Данные появились — в результате задачи, поставленные для сетей 70-х годов, мы теперь решать худо-бедно умеем. Ждем еще 50 лет.
Походу быстрее). А так — да, типичная спираль развития)

AlexanderS
25.12.2019 22:57Я, читая, хотел задать вопрос: про плюсы-то всё ясно, а какие же минусы? Но окончание статьи дало своеобразный ответ)
3Dvideo Автор
26.12.2019 00:17Спасибо. Там есть над чем подумать.
И это не только Пентагон. Например, анализ движений глаз. Вы себе не представляете, как много можно оттуда извлечь данных о человеке. Характер, привычки, склонности, падкость на рекламу и т.п. Больше, чем человек о себе знает. С условными Google Glass 3.0 люди не представляют, сколько информации о себе сольют. Куда там броузерам. И все будет добровольно, как со смартфонами, только на новом уровне.
epishman
26.12.2019 00:42В зависимости от разрешения — по глазам хорошо диагностируется здоровье, по движениям — нейростатус, похоже гугл будет скоро знать обо мне больше чем мой личный терапевт с психоаналитиком. Пусть знает, лишь бы потом лечил :)
3Dvideo Автор
26.12.2019 12:30Представил такое будущее и вздрогнул! ) Ой, если Google (Яндекс, Байду) будут еще и лечить, совсем весело может получиться) Орруэлу и не снилось)
epishman
26.12.2019 15:57+1Почти уверен, что так и будет, если им законодательно не запретят, консультации по ЗОЖ сейчас по моему не лицензируются, реклама лекарств тоже. А так вылезет какая-нибудь Алиса и пропоет — у вас спазм глазных артерий, мышечный тремор, потемнение коньюнквы, пульс с третичным ритмом, вероятность атеросклероза 70%, съешьте импазу, заказать, скажите окей? :)))
AlexanderS
26.12.2019 10:54Да я немного не про то. Есть интуитивное неприятие того, что мы вступаем в эру «нечёткого» программирования.
Ассемблер/С/С++ — это всё же код. Это всякие if-else. Я могу взять другой код и разобраться в нём. Да, с позиций двух десятилеток 21 века это сложно, т.к. конечный код это порой нагромождение фреймворков и библиотек. Но я могу провести аудит кода. Могу точно объяснить почему код себя ведёт так, а не иначе и как это исправить так.
А нейросети? Как мне проводить аудит безопасности кода для шифрования данных? Если зафиксирован сбой программы, то насколько успешно я это исправлю? И таких вопросов — уйма. Сейчас-то ПО страшновато использовать, а что будет в будущем? )3Dvideo Автор
26.12.2019 12:34Есть интуитивное неприятие того, что мы вступаем в эру «нечёткого» программирования.
Более того. Это неприятие еще толком не началось, поскольку ML/DL программирование еще в стадии начального становления. В стеках разработки оно нигде толком не прокинуто, существует на своих фреймворках, которые также еще пока стремительно меняются. Дальше будет интереснее)
Сейчас-то ПО страшновато использовать, а что будет в будущем? )
Жизнь станет еще лучше и еще интереснее, без вариантов))) Роль интуиции в отладке точно вырастет ))) Как минимум!
red75prim
26.12.2019 15:11Я встречал описание такого реально используемого подхода: тренируется сетка, на её основе делается PID(?) контроллер с доказуемыми свойствами.
По-моему, в идеале должно быть такое: нейросетка на основе описания задачи интуичит какие известные алгоритмические решения к каким частям задачи можно применить, дообучается работать с частями, для которых ещё нет явного решения, пытается дистиллировать дообученную часть в набор явных правил и добавляет эти правила к известным способам решения.
AlexanderS
26.12.2019 15:32В идеале-то может и так. Но не будет такого. Уже сейчас все обленились, код пухнет и пухнет. Виджет погоды за 4 года распух с 400кБ до 12МБ) И дальше лучше не будет. Если условный «модуль» будет давать нужный результат — будут его использовать и всё. Никто не будет заморачиваться на допконтроль.
Цепи обратной связи с «железно-алгоритмическими» решениями концепции ПИД — это хорошо, но не везде же это применимо. Это АСУТП всякие, в эту степь. Сдаётся мне в «обычном» программировании никого так сильно это не озаботит.3Dvideo Автор
26.12.2019 15:36+2Виджет погоды за 4 года распух с 400кБ до 12МБ)
У бесплатного виджета погоды нужно смотреть, чем он реально занят. А то как в анекдоте: «приложению „Фонарик“ требуется доступ к вашим контактам, звонкам и диску»)))
red75prim
26.12.2019 15:56Работодателей заботит. Такая система, накапливая готовые решения и строя интуицию, где их стоит применять, может дорасти до уровня кодера. Результатом дистилляции может быть не только контроллер, но и алгоритм (не обязательно оптимальный).
Впрочем, это — дальняя перспектива.
JayS
25.12.2019 23:48Так вроде же PPL скоро заменит DL. Вон Gen со всех углов лезет. DL уже на покой идет
salkat
26.12.2019 02:41Про Google и Пентагон, тут вот какой фокус…
Если вводить запрет, любой, то слушаться этого запрета будут только законопослушные люди. А незаконопослушным на запрет наплевать. Это как бы очевидно.
Поэтому когда кто-то продвигает что-то вроде «давайте запретим оружие», я слышу «давайте запретим оружие нормальным людям. А у преступников пусть остаётся»
Когда сотрудники Гугла продавили отказ от сотрудничества с Пентагоном, это же не означало, что никто больше в мире не будет разрабатывать никакого военного ИИ. По сути, они заявили «пусть у Штатов не будет военного ИИ, а у остальных пусть будет».
Так что, с точки зрения противников США, они молодцы и герои, а с точки зрения американцев они то ли придурки, то ли предатели.3Dvideo Автор
26.12.2019 10:04Когда сотрудники Гугла продавили отказ от сотрудничества с Пентагоном, это же не означало, что никто больше в мире не будет разрабатывать никакого военного ИИ. По сути, они заявили «пусть у Штатов не будет военного ИИ, а у остальных пусть будет».
Это не так, увы. 10 миллиардный тендер Пентагона 100% выиграла американская компания.

decomeron
26.12.2019 03:37Это, очевидно, современный продвинутый аналог классического «Будешь есть манную кашу, станешь космонавтом!». Впрочем, в нашем случае, если посчитать число детей в стране и размер отряда космонавтов, шансы в миллионы раз выше, ибо из нашей лаборатории уже двое работают в DeepMind.…
Как бы 2 человека это верно, ровно столько из миллионов детей сейчас хотят стать космонавтами… еслиб это было году этак в 1961 или, хотя бы 1970гг, а сейчас все больше моделями или певцами или банкирами…
А за статью огромное спасибо3Dvideo Автор
26.12.2019 10:08а сейчас все больше моделями или певцами или банкирами…
Увы… Нам осталась только классическая фраза.
А за статью огромное спасибо
Спасибо)

perfect_genius
26.12.2019 12:36Про нейросети в медицине не упомянули, а это очень важное применение ведь.
Так традиционным программистам надо бояться или нет?3Dvideo Автор
26.12.2019 12:42Про нейросети в медицине не упомянули
Про это в прошлой статье хорошо было.
Так традиционным программистам надо бояться или нет?
Ага! Страдающим неофобией уже можно начинать бояться! ) Остальным — можно начинать учиться! Как-то так)
Rebelqwe
26.12.2019 13:46Очень настораживает такая любовь и пропаганда неточных вычислений, и вообще тенденция к ним стремится, особенно с учетом того, что допуски, по размерам для реальных изделий, наоборот, сокращаются колоссальными темпами. Особенно в нанотехнологиях, реальные изделия размером нанометры, допуски — сотые доли нанометров, и, если вычисления будут неточными, все чипы станут резко непригодными к расчету чего-то реального. А точные чипы разрушатся от старости и мы потеряем вообще возможность хоть что-то посчитать и смоделировать с таких областях. Очень страшная перспектива.
3Dvideo Автор
26.12.2019 13:58настораживает такая любовь и пропаганда неточных вычислений,
Ну у вас и терминология)
Это не любовь и не пропаганда, а констатация факта, что для акселерации нейросетей уже сегодня наиболее распространенный прием — это перевод весов в целые числа и их квантование. И потенциально используя это свойство нейросетей можно еще довольно значительно ускорить вычисления.
А точные чипы разрушатся от старости и мы потеряем вообще возможность хоть что-то посчитать и смоделировать с таких областях. Очень страшная перспектива.
))) «С приходом GPU 25 лет назад все CPU разрушились от старости и мы вообще потеряли возможность что-то выполнить не параллельно»))). К счастью NPU и TPU не отменяют CPU и даже GPU. Можно с облегчением выдохнуть!

epishman
Хорошая статья. Был бы я трейдером, сказал бы что мы находимся в конце волны 3 (по эллиоту), и далее нас ожидает трехволновая коррекция вниз, процентов на 20.
3Dvideo Автор
“Пузырь лопнул? Хайп перегрет? Они умерли как блокчейн?”
А то ж! Завтра в вашем телефоне перестанет работать Сири, а послезавтра Тесла не отличит поворот от кенгуру.
Это цитата из «Лопнул ли пузырь машинного обучения, или начало новой зари», там про это хорошо было )))
А коррекция (ожиданий) для инвесторов крайне нужна, я про это писал по ссылкам внизу статьи.
epishman
Статья хорошая, спасибо. А по графикам мы скорее всего увидим клин с последующим пробивом наверх — когда будут какие-то теоретические прорывы с объясняющим AI.
3Dvideo Автор
Это еще не скоро.
Пока идет ускоряющееся расширение областей применения нейросетей (как в науке, так и в продуктах), которое активно поддерживают новые акселераторы. Раньше всего как оно работает увидим в телефонах, где нейроакселераторы были опробованы год назад Apple & Huawei (и это было рисковано и чипы часто просто занимали место в телефоне), но оно прошло успешно и сейчас идет расширение линейки (и акселераторов, и продуктов с ними). Т.е. относительно банальный рост)