
Алгоритмы сжатия — это очень коварная тема, привлекающая многих новичков. Это правда! Часто человеку кажется, что его осенила божественная идея, как сильно сжать данные. Любые, кстати! Без потерь! Рекурсивно! А поскольку данные — это хранение информации и передача, то если хотя бы на единицы процентов результат улучшить — это миллиарды долларов (смотрим экономию всех провайдеров на передаче и хранении, всех дата-центров компаний, всех домашних пользователей, перемножаем… аж дух захватывает)! И люди пишут письма:
«Обращаюсь к вам, как «создателю и демиургу проекта ;) compression». Мной придуман алгоритм, основанный на простом рассуждении – если файл условно несжимаемый, есть вероятность что, часть файла имеет избыточность и файл можно сжать частично. …»
«Обращаюсь к Вам, как к одному из главных специалистов в области сжатия информации. Предлагаю Вам ознакомиться с изобретением в области сжатия информации. [...] По мнению автора, основным достоинством данного «Способа кодирования информации» является способность одинаково хорошо сжимать без потери качества информацию любого типа (видео, аудио, текст, архив и т.д.). Помимо этого «Способ» позволяет проводить процесс кодирования (сжатия) повторно....»
Бывает даже так:
«Мне, для начала, нужно 30–60 минут общения с Вами по Скайпу.
Вопрос: каково Ваше вознаграждение и куда его отправить?»
И если вы думаете, что обращения типа последнего — мои любимые, то реакция ровно обратная («Боже, дай мне терпения!»). Ибо по опыту в последнем случае люди наиболее настойчивые… Кстати, это могут быть не только авторы, но и инвесторы, о которых ниже тоже будет.

Кому интересно, в чем же таки коварство алгоритмов, есть ли у нас таланты, и где же, наконец, деньги — добро пожаловать под кат! (Талантливые авторы алгоритмов могут сразу переходить в раздел «Про деньги»).
Disclaimer 1: Любые совпадения в тексте с реальными лицами и фактами являются абсолютно случайными!
Disclaimer 2: Автор съел на этой теме несколько
Когда-то давно я имел неосторожность организовать команду из 4-х человек, и мы вместе написали книжку по алгоритмам сжатия, где много подходов разобрали. С тех пор идет довольно стабильный поток подобных писем. Настоящая жемчужина была этой весной. Пока люди страдали от ковида, человек написал очень прикольный текст про свой будущий архиватор. Зацените концовку (орфография во всех цитатах авторская):
«И когда компрессор ******- будет создан… Тогда… Тогда…
Да развергнутся Небеса.
И сойдёт на создателя сего творения Благодать, которая наполнит его Чашу богоугодным напитком,
Который опьянит его рассудок. И разольётся тепло по всей периферии, по всем жилам, согревая утомлённое от трудов, его бренное тело
И тогда сожмётся несжимаемый файл.
И тогда все скажут: — О, чудо!… И сильно удивятся, и начнут кричать: — Ура! И начнут кидать вверх запонки, туфли, галстуки, лифчики
А потом выползет на пронизывающий свет брюзглявый скептик
Откроет один зашореный глаз, и пробубнит: — Этого не может быть, так не бывает, у меня в книжке написано.
А скромный создатель ******, снисходительно улыбнётся. Зачем ему доказывать что-то, когда его Чаша наполнена, а Душа преисполнена
удовлетворённостью от выполненного дела…»
Боже, как поэтично! Особенно про несжимаемый файл, подброшенные лифчики и «брюзглявого» скептика, написавшего книжку! Волшебно! Я давно так не смеялся. Причем автор жег и дальше:
«А для военных, — это вообще находка. И сложно представить, сколько фильмов можно будет записать на одну флэшку. ТВ, интернет, телефон — всё по двум проводам в дом. А оптоволокно будут использовать для новогодних гирлянд и магазинных вывесок. Мы живём в удивительное время, когда всё меняется. А России нужен технологический скачок.»
В общем, Россия обречена на процветание. Причем в письме есть интересные рассуждения об алгоритмах, из которых понятно, что этот текст — тонкий стеб с отличным юмором. Но, если бы такой человек был один…
О неправоте старика Шеннона
Писем таких много. Вот, например, человек теорему Шеннона поминает, но, похоже, не разбирался с ее доказательством:
«Просмотрите pls не так бегло ;) Сравнение с Zip только «для широкого круга читателей». Прямое сравнение с Арифметическим кодированием встречается в неск. местах. И да: я понимаю, что значит «противоречит теореме Шеннона», именно это я и показываю НА ПРАКТИКЕ! Возможный по p*log(p) предел кодирования — **** его превосходит! (в отдельных случаях)
Это не шутка.»
Или вот:
«И все бы хорошо, но **** действительно обеспечивает лучшее сжатие, т.е. поправить надо бы в консерватории Шеннона…»
А эти ребята даже стартап создали:
«Мы создаём алгоритм сжатия данных, очень интересно было бы с вами пообщаться. [...] Мы начали разрабатывать алгоритм сжатия данных в конце 2017 года. ************ (второй сооснователь) придумал как сжимать любые данные в несколько раз. С технической точки зрения он лучше меня сможет объяснить, я занимаюсь продвижением.»
Вежливо замечу, что если человек действительно напишет программу, которая ЛЮБЫЕ данные сожмет В НЕСКОЛЬКО РАЗ, то ему не нужен продвиженец, он может прямо сейчас начать хорошо зарабатывать. И я обязательно расскажу как.
Характерно, что многие присланные изобретенные способы «позволяют проводить процесс кодирования (сжатия) повторно», давая возможность в итоге в несколько итераций успешно сжать даже несжимаемые файлы, что специально подчеркивается авторами. Аллилуйя!!!
В принципе тема классная! Помнится, в средневековье, на заре становления химии, многие ученые бились над поиском философского камня, который позволил бы трансмутировать металлы в золото. К сожалению, в повести-сказке для программистов «Понедельник начинается в субботу» эта тема обрывается на самом интересном месте: «Я дошел до стенда «Развитие идеи философского камня», когда в зале вновь появились сержант Ковалев и Модест Матвеевич».
Впрочем, для любого программиста совершенно очевидно, что в наш информационный век современный философский камень — это сжатие несжимаемых данных. И неважно, что для чего-то там что-то доказано.
— Г-голубчики, — сказал Федор Симеонович озадаченно, разобравшись в почерках. — Это же п-проблема Бен Б-бецалеля. К-калиостро же доказал, что она н-не имеет р-решения.
— Мы сами знаем, что она не имеет решения, — сказал Хунта, немедленно ощетиниваясь. — Мы хотим знать, как ее решать.
— К-как-то ты странно рассуждаешь, К-кристо… К-как же искать решение, к-когда его нет? Б-бессмыслица какая-то…
— Извини, Теодор, но это ты очень странно рассуждаешь. Бессмыслица — искать решение, если оно и так есть. Речь идет о том, как поступать с задачей, которая решения не имеет. Это глубоко принципиальный вопрос, который, как я вижу, тебе, прикладнику, к сожалению, не доступен. По-моему, я напрасно начал с тобой беседовать на эту тему.
Все-таки Стругацкие гениальны. Особенно остро это ощущаешь, когда регулярно приходится выступать в роли
Явление, которое проиллюстрировано выше цитатами из писем, — это обычный эффект Даннинга-Крюгера, описанный в статье 1999 года, но хорошо известный со времен античности. Когда человек только начинает изучать любую область, ему кажется, что она очень проста и понятна, уверенность в своих знаниях растет очень быстро. Однако, чем выше самоуверенность в начале, тем глубже яма страданий потом из-за того, что реальность кардинально расходится с представлениями о ней. Причем попытки уберечь людей от глубоких страданий являются крайне неблагодарным занятием. Проверял несколько раз (мать-мать-мать, ладно, страдайте!!!).
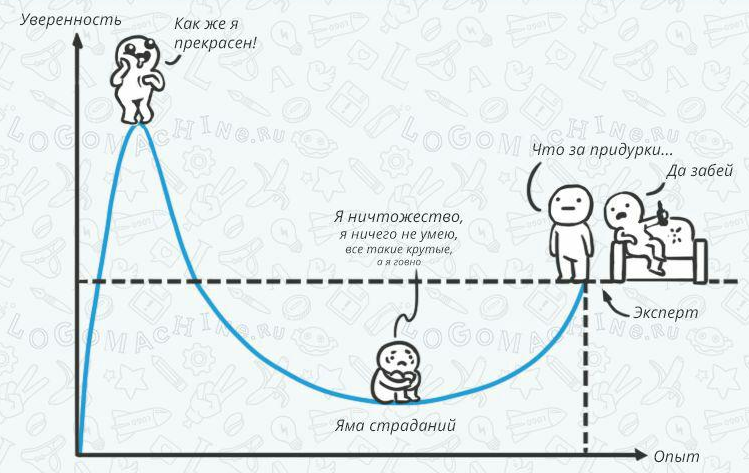
Что можно сказать об опыте авторов таких писем? Когда смотришь присланный людьми PDF на тему «сжатия несжимаемого», Яндекс дает просто неприличную рекламу (реальный скриншот аттача письма):

Справедливости ради люди часто прямо пишут:
«Программирую на Delphi. Язык C, я плохо понимать.»
Или так:
«Так как мои познания в программировании ограничены, ищу соавтора — программиста разбирающегося в алгоритмах сжатия информации»
Или вот очень культурно:
«Дмитрий, если у вас есть возможность помочь в данном вопросе, или заинтересуется кто-то из ваших знакомых – прошу со мной связаться. Если окажется, что алгоритм неработоспособен, готов компенсировать затраты и потраченное время»
Плохая новость заключается в том, что нужно будет разобраться не только как формально записывать алгоритм, но и для каких условий сформулирована та самая пресловутая теорема Шеннона, которую столь дружно «превосходят» начинающие авторы кодеров. «Теория, мой друг, суха, но зеленеет жизни древо» (Гете). И пока практика подтверждала теорию…

Впрочем… Ладно, расскажу! На самом деле сжимать уже сжатые данные, конечно, можно. («Что-о-о-о… он несет???» — возмущенно раздалось с мест!) Спокойно, господа! Рассказываю, как это делается на практике.
Когда-то я руководил разработкой проекта компании SoundGenetics с внутренним названием MP3Zip, позднее названным Sound Slimmer (сайт проекта, увы, более не поддерживается). Тогда удалось достичь сжатия MP3 в среднем в 1.2 раза на большой выборке MP3. Причем сжимался файл полностью без потерь, бит в бит. Идея была в том, что файл распаковывался до потока коэффициентов MDCT, которые далее паковались более эффективно (кому интересны детали, там было несколько патентов).
Причем если кто-то думает, что сильно сжать — основная проблема, то он серьезно ошибается. Как показало вскрытие, огромный процент MP3 файлов, которые тогда ходили по людям, были битые. Особенно конец файла (наследие ранних p2p). И учесть корректно побитые файлы было не так просто. Т.е., если бы можно было «починить» файл, было бы достигнуто большее сжатие, но тогда каждый чайник проверил бы, увидел, что не бит в бит, и что есть силы закричал бы: «Они обма-а-а-анывают!» И был бы прав. Поэтому мы всячески извращались, стараясь минимально потерять сжатие, и максимально парсили битые куски (алгоритмически там не так все просто).
Также интересно, что если бы можно было зафиксировать распакованный файл (условно WAV), а не MP3, то для того же распакованного файла (бит в бит в WAV) можно было бы еще чуть увеличить сжатие. Но, увы, бизнес сказал: работаем только на уровне MP3. Так что эта часть осталась во внутренних разработках. Также по заказу известной японской компании была сильно переделана архитектура алгоритма («а теперь, ребята, делаем те же трюки, только стоя на канате!») и появилась возможность сжимать MP3 поток, т.е. работать по буферу, видя только небольшую часть файла. Это позволяло сжимать вещание. Аналогично, удалось примерно на 11% сжать AAC со всеми наворотами типа обработки битых и было показано, как аналогично дожимать JPEG и GIF (т.е. всю графику тогдашнего веба). В проекте работало 6 человек, и это было очень прикольно!
Так что сжимать сжатое можно! За это даже платят. Лично проверял!
Про деньги
А теперь про самое интересное («Да-да! Было явно обещано про деньги», — раздалось с мест). Умные люди заранее спрашивают в письмах:
«Существующие технологии сжатия графики будут развиваться. В частности, появятся новые преобразования [...]
Вопрос: как с минимальными усилиями извлечь некоторую финансовую выгоду в случае разработки более перспективных преобразований (которые на 20-30% лучше по быстродействию или по качеству сжатия)?»
Мне нравятся такие письма. Перед тем как
Постараюсь ответить детально и по пунктам. Поехали!
Способ 0: Популярные неработающие подходы
Начну с нулевого во всех смыслах способа.
В письмах довольно регулярно всплывает тема заработка на патентах. Уж не буду цитатами сыпать, но предложения «вместе сделать и запатентовать» идут регулярно. Сожалею, но вынужден разочаровать, поскольку успешных кейсов, чтобы человек подал патент на алгоритм сжатия и разбогател, я не встречал. Можно реально заработать патентной экспертизой, это да, это реально. А вот продажей патента… Обычно люди сильно недооценивают себестоимость жизненного цикла патента. А вопрос «Почему ваш патент будет работать?» вызывает реальный ступор. («А оно разве не само работает?» — Нет...) Поинтересуйтесь хотя бы, в каких юрисдикциях и как обеспечивают работу патента патентные тролли. Впрочем, это совершенно другая история.
Также частое желание — сделать стартап и, конечно, продать его Google. Джим Коунси, директор подразделения Autodesk Developers Network (на потоке покупавший стартапы), несколько лет вел блог Dances with Elephants: How small companies can partner with large companies to accelerate their business growth. Его метафора танца со слонами довольно точно передает суть процесса. Безусловно, в блоге отражена точка зрения слона, поэтому скольких во время этих танцев раздавили даже не со зла, а просто не заметив, история умалчивает. Но, если вы мечтаете о продаже крупняку за много миллионов — почитайте и трезво содрогнитесь.
Способ 1: Сжимаем несжимаемое за славу и деньги (на новом месте работы)
Проще всего тем, кто реально может «сжимать несжимаемое». Марк Нельсон, автор толстенного кирпича The Data Compression Book — библии сжатия 90-х, еще в 2002 году объявил конкурс, позднее названный The Million Random Digit Challenge и продлевавшийся с уточнением правил не один раз. Смысл конкурса в том, что была взята хорошо подготовленная последовательность случайных чисел (большой файл):

Задача была создать архиватор для этого файла, который вместе с архивом был бы меньше по размеру, чем сжимаемый файл. Ибо, если ограничение на размер архиватора не ставить, задача, как вы понимаете, решается тривиально («Джентльмены верят на слово [что мы часть архива в архиватор не кладем]… Тут-то мне карта и поперла!»). Т.е. надо на другом чистом компе из двух файлов искомый несжимаемый распаковать, ибо история знала случаи, когда «сжимающий ЛЮБОЙ файл» архиватор просто клал часть файла в tmp директорию компа. И люди проверяли, и у них, вы не поверите, работало! Несжимаемые файлы успешно сжимались!!! На самом деле!!! И они коллегам срочно пересылали попробовать, и у них тоже
В общем, уже много лет Марк Нельсон покупает торт и задувает все больше и больше свечей на день рождения The Million Random Digit Challenge (ведь его детищу уже стукнуло 18!), но воз и ныне там. Интересно, что к созданию исходного файла конкурса приложил руку тот самый физик Джон фон Нейман, который недвусмысленно высказывался, что:
«Любой, кто рассматривает арифметические методы получения случайных чисел, безусловно грешник»
Это, впрочем, не мешает и по сей день особо упорным товарищам со словами
Способ 2: Получаем под сжатие деньги инвестора
Вообще стартапы по теме сжатия возникают регулярно. Даже в сериале «Кремниевая долина» у главного героя, если помните, был стартап по сжатию (в т.ч. 3D видео, что характерно). Поверьте, это не случайность, а тонкий троллинг. Деньги под сжатие просят (и даже получают!) довольно часто.
Но русские стартапы и инвесторы — это прям очень своеобразная тема. Нет, классные компании бывают, особенно бутстрэппинг или спин-офф, но в обычных венчурах по сжатию обычно такая жесть под капотом… Причем причина, на мой скромный взгляд, в непрофессионализме инвесторов. Я не знаю, на каком лесе,

Причем у меня с такими товарищами была масса характерных разговоров. Выходят на меня, как правило, через МГУ, и у них представление такое, что ученый должен млеть от самого факта общения с
Господа! За получасовой сеанс вам все про ваш pet project расскажут экстрасенсы (с гарантией 100%, кстати). А если вам заливают в уши грамотно, то реально вникать надо. В общем, смотришь на этот мастер-класс по переговорам и так и хочется сказать:
Справедливости ради — я прекрасно понимаю, что мне приходится общаться с «попавшими» инвесторами, и это, конечно, вариации на тему «ошибки выжившего». Опять же я хорошо знаю, насколько изменился в лучшую сторону российский венчур за последние 20 лет. Но тем не менее…
Короче, господа! Непуганых людей с деньгами в наших, да и чужих палестинах все еще явно хватает. Поэтому ищите и обрящете, стучите и откроется. Как минимум, сможете проверить свою идею. Чужим опытом получения инвестиций в русских реалиях, впрочем, тоже интересоваться рекомендую. Так, знаете, на всякий случай!
Способ 3: Конкурс на сжатие википедии
В 2006 профессор австралийского университета (ныне — исследователь в Google DeepMind) и автор нескольких книжек (в том числе книги 2005 года по раннему ИИ и алгоритмической вероятности) Маркус Хаттер объявил приз в 50000 € за лучшее сжатие 100 Mb текстов википедии. На самом деле это реклама, поскольку формула приза построена так, что более чем 10000 € Маркус не рисковал. Но тем не менее за 11 лет конкурса 8747 € призовых были выплачены! Вот, к примеру, призы за 2007 и 2018 коллеге и соавтору нашей книжки Александру Ратушняку (и это не все, о чем будет ниже):


Интересно, что в 2020 году конкурс получил новое название 500'000€ Prize for Compressing Human Knowledge, а размер корпуса на сжатие увеличен до 1 Gb.
В общем, если вы реально классно сжимаете — дерзайте! Сжатие википедии — дело благородное. Причем, если вы выиграете, очень многие компании будут рады видеть вас у себя и вы будете
Способ 4: Специализированные конкурсы
Также существуют специализированные конкурсы. Например, в 2011 году был конкурс Sequence Squeeze Compression Competition на сжатие последовательности ДНК с призовым фондом 15000 $. Причем в результатах видно, что по сравнению с baseline удалось либо практически на порядок увеличить скорость сжатия при существенном уменьшении файла, либо при той же скорости практически в 3 раза увеличить сжатие. Это является основной мотивацией компаний для проведения таких конкурсов (например, в 3 раза уменьшить затраты на хранение данных):
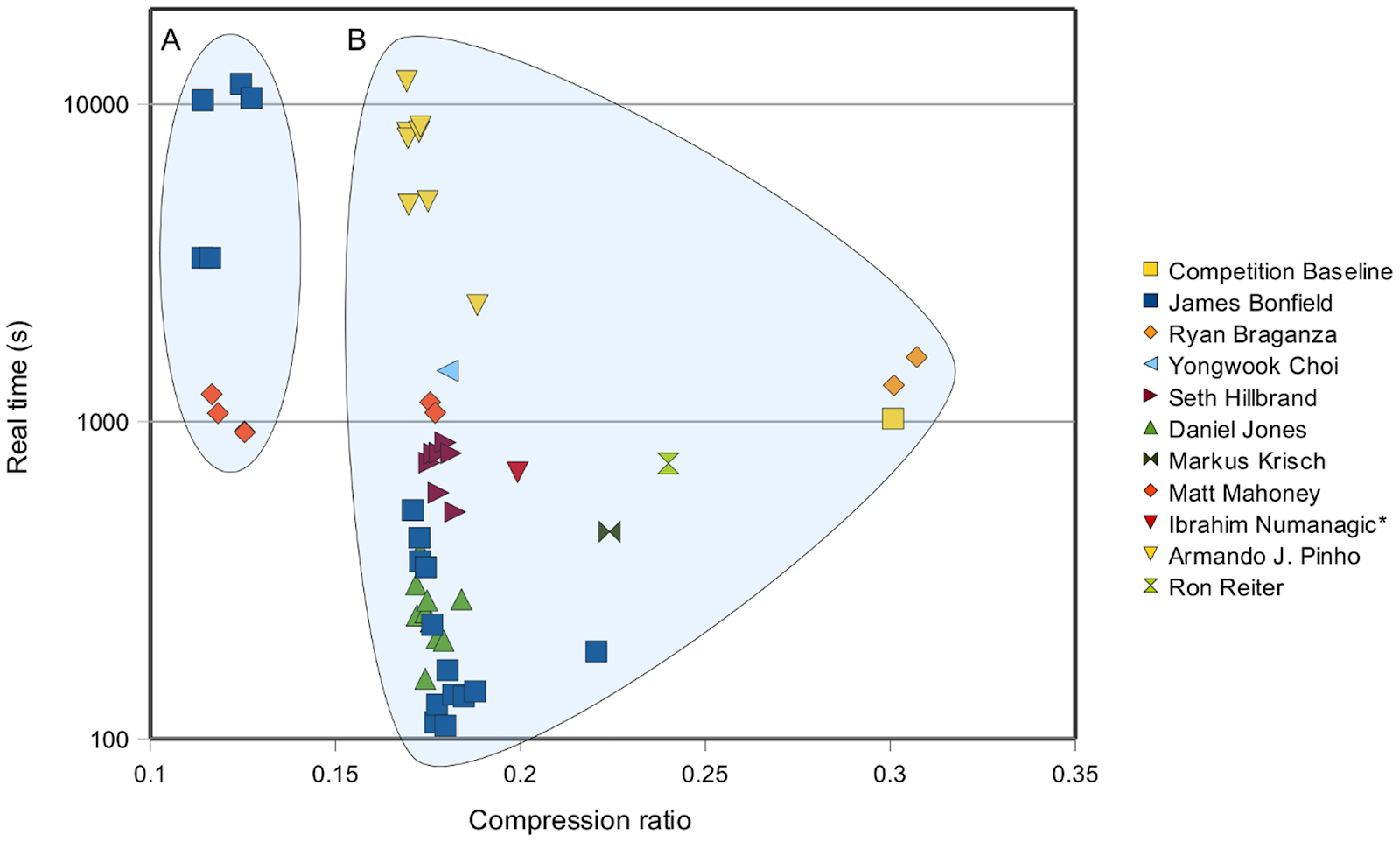
В этом конкурсе победители публиковались в открытых исходных текстах, что
Способ 5: Конкурс на 50000 евро + слава в подарок

И, наконец, прямо сейчас идет конкурс Global Data Compression Competition с прямым призовым фондом 50000 € (т.е. вся сумма планируется к выплате после оглашения результатов). Как я понимаю, это самый крупный в истории конкурс по сжатию без потерь, если считать размер выплаты ко времени конкурса. В его организации принимают участие трое из четырех авторов той самой книжки.
В конкурсе 4 вида данных:
- Тексты (дань традиции). Размер 1 Gb. Практический смысл сжатия текстов сегодня ограничен, но с новыми ML/DL NLP подходами там есть с чем развернуться и силушку показать.
- Картинки. Размер 1 Gb. Тут понятно.
- Количественно-качественные данные: исполняемые файлы с большим процентом числовых таблиц. Размер 1 Gb. Это, условно, кейс дистрибутивов, бэкапов и разнообразные случаи сжатия разнородных данных.
- Блочное сжатие — 1 Gb блоков по 32 Kb — это кейс баз данных, block storage, сжатия файловых систем. Данные в этом кейсе неоднородные, чтобы также приблизиться к реальным условиям.
Для каждого вида данных есть 3 варианта ограничений по скорости для быстрых, средних и медленных («Иду на рекорд!») алгоритмов. Впрочем, многие алгоритмы можно адаптировать без переделки, и вы наверняка обращали внимание, что в тех же RAR или ZIP можно задавать силу сжатия, и чем сильнее, тем дольше жмет. Вот ровно про это речь.
Итого получается 12 номинаций, в каждой из которых призы за лучшие места. Можно и нужно точиться по времени и занимать первые места в нескольких номинациях (если у вас адски мощный DL препроцессинг текстовых данных, например).
Соревнование международное, и в нем уже участвуют авторы алгоритмов сжатия от профессоров университетов США до индийских программистов.
Важный момент — никто не требует исходников. Это, безусловно, расширяет список участников, но… Правильно, тут же появляются «самые умные». Например, один из участников из… гм… Юго-Восточной Азии явственно парсит GitHub на предмет годных исходников, точит их под задание и засылает. Просто и со вкусом. При том, что вычислить такое поведение, пусть сложно, но реально.
Чтобы сразу понятно было. Финансирует конкурс Huawei. В этот момент должен раздаться хор непонятно чем недовольных. Поскольку когда такого спонсора нет, то призовой фонд, вспоминаем старика Нельсона, равен 100 $. Причем в его случае он мог и миллион долларов пообещать, но представляете, с какими изощренными способами спрятать куда-то кусок архива ему бы пришлось столкнуться! Он же не мазохист. И вообще у нас на compression.ru и ранее рейтинги кодеров проводились. И в других местах тоже. Но это, похоже, первое широкомасштабное соревнование на тему сжатия без потерь, проспонсированное компанией! Т.е. ни Google, ни Apple, ни Intel, ни Microsoft как-то не сподобились. При том что они от этого вполне выигрывают, в том числе реальные большие деньги на экономии трафика и хранении. А, чем выше призовой фонд, тем больше геморрой для
Сейчас большие надежды возлагаются на Deep Learning, который, конечно, сметет все старые алгоритмы и в сжатии без потерь тоже. И тогда покажется смешным сжатие бит в бит MP3 и JPEG на 20%, и снизойдет на автора алгоритма благодать, и он улыбнется.
Короче, господа! Результаты, надеемся, будут очень интересные. И, если вы где-то будете в лидерах — вас точно заметят
Резюмируя тему, замечу, что наиболее частый путь успеха в общем-то похож на путь современного ML/DL поколения: прокачка > Kaggle/хакатоны/конкурсы > победы > зарплата $100–200K в год. Маркус Хаттер в DeepMind, как видим, получает столько, что конкурсы на полмиллиона евро лично спонсирует. В этом большой плюс соревнований и побед. Главное — адекватно оценивать усилия, необходимые на качественную прокачку и быстро переходить от слов к делу (это самое сложное по опыту).
Про талант
И, наконец, последняя обещанная тема. Может показаться, что я как-то неровно дышу к нашим

И к счастью, я знаю много замечательных талантливых (в рамках этого определения) соотечественников. Например, мы 17 лет проводим сравнения кодеков, в которых участвуют компании из разных стран. Так, до недавнего времени едва ли не половина общения шла на русском. Т.е. компания была западная, а видеокодеками в ней занимались люди родом из России, Украины, Белоруссии, из Прибалтики, наконец. Недавно, правда, стало очень много китайцев (как компаний, так и разработчиков), но это отдельная тема.
С обычным сжатием ситуация также очень показательна:
- Если кто не знает, то автор RAR (WinRAR) — фактически самого популярного коммерческого архиватора в мире — талантливый челябинец Евгений Рошал.
- Автор 7-zip — крайне популярной бесплатной open-source программы сжатия и LZMA SDK — Игорь Павлов.
- Автор алгоритма PPMd (использованного и в RAR, и в 7-zip) и почти призер Hutter Prize — Дмитрий Шкарин. Кстати, его же метод BMF сейчас в топе Global Data Compression Competition на сжатии изображений. При том что он придуман 15–20 лет назад!
- Автор PPMY, PPMd_sh, shar2 и многих алгоритмов рекомпрессии JPEG, MP3, AAC, Deflate (участник упоминавшегося проекта SoundSlimmer) — харьковчанин Евгений Шелвин. Евгений — контрибьютор большого количества компрессоров с открытым кодом и поддерживает, пожалуй, самый известный в мире форум по сжатию.
- Александр Ратушняк, один из авторов той самой книги и соорганизатор конкурса Global Data Compression Competition, автор высокоэффективных компрессоров изображений, контрибьютор стандарта JPEG-XL, четыре раза получал Hutter Prize! Вообще таблица призеров Hutter Prize выглядит так, будто, несмотря на длительность конкурса, Саша не оставил другим авторам никаких шансов:
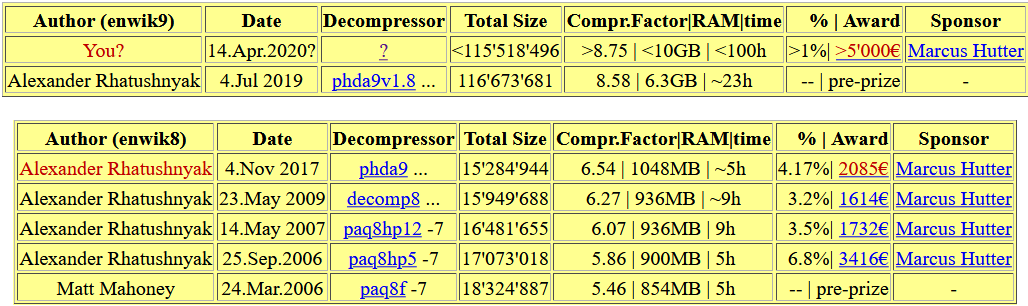
И список выше далеко не полный. Причем когда общаешься с этими замечательными людьми, понимаешь, что талант — не главное. А главное — терпеливо и настойчиво заниматься темой, которая тебе действительно нравится.
Закончить хотелось бы словами любимых Стругацких:
Сюда пришли люди, которым было приятнее быть друг с другом, чем порознь, которые терпеть не могли всякого рода воскресений, потому что в воскресенье им было скучно. Маги, Люди с большой буквы, и девизом их было — «Понедельник начинается в субботу»… они приняли рабочую гипотезу, что счастье в непрерывном познании неизвестного и смысл жизни в том же. Каждый человек — маг в душе, но он становится магом только тогда, когда начинает меньше думать о себе и больше о других, когда работать ему становится интереснее, чем развлекаться в старинном смысле этого слова.
Дерзайте! Доводите ваши идеи до результата! И пусть ваша работа будет интереснее ваших развлечений!
Читайте также: Уличная магия сравнения кодеков. Раскрываем секреты — текст о том, как мы много лет кодеки сравнивали и с какими эпичными случаями сталкивались.
Благодарности
Хотелось бы сердечно поблагодарить:
- Лабораторию Компьютерной Графики и Мультимедиа ВМК МГУ им. М.В. Ломоносова за вклад в развитие сжатия медиа в России и не только,
- моих соавторов по книге «Методы сжатия данных», благодаря которым этот проект вообще стал возможным и нанес непоправимую пользу многим людям,
- персонально Константина Кожемякова и Кирилла Малышева, которые сделали очень много для того, чтобы эта статья стала лучше,
- и, наконец, огромное спасибо Дмитрию Коновальчуку, Максиму Смирнову, Анастасии Кирилловой, Андрею Москаленко, Егору Склярову, Никите Молотилову, Ивану Молодецких, Вячеславу Мещанинову, Михаилу Дремину, Александру Гущину и Николаю Сафонову за большое количество дельных замечаний и правок, сделавших этот текст намного лучше!
Gengenid
Да уж! Люди, возомнившие что вот они-то точно придумали СОВЕРШЕННО НОВУЮ, ГЕНИАЛЬНУЮ идею — это нечто.
Но давайте лучше обсудим действительно новую, отличную штуку, которая взорвет рынок сжатия данных. Как Вас найти в Скайпе?
Qwerty710
Может, автор принципиально новой операционной системы решил выпустить «Архиватор Попова»
Gengenid
Не, с архиватором был уже другой уникум
http://engineerblog.ru/algoritm-arhivatsii-babushkina/
3Dvideo Автор
Волшебная история! ) На хабре о ней тоже упоминали habr.com/ru/post/170487, но без анализа «алгоритма»)
saboteur_kiev
Сама идея хранить где-то архивированные части не нова и даже не так плоха, как кажется.
Для организаций с большим количеством данных, можно сделать централизированное хранилище доступное по сети с большим набором готовых блоков данных, которые можно использовать в «архивации».
Так сказать внешний большой словарь готовых блоков.
Также автоматически вычисляются блоки, которые могут быть переиспользованы достаточно раз, чтобы для них выделить место и наоборот — если блок используется мало, оригинальный файл перепаковывается, чтобы не использовать хранилище.
Я читал что такая схема где-то используется на практике, но это очень нишевое решение, которое не подойдет для публичного использования.
nvksv
То, что вы описали, называется «дедупликация».
Большой словарь готовых блоков — это хорошо, но его где-то тоже надо хранить. Да, можно хранить его где-то далеко, а локально сохранять только известные хеши — тогда сжатие будет очень быстрым, но для распаковки придется запрашивать по сети сами блоки. В сценарии, когда часто идет архивация шаблонных данных, а разархивирование происходит крайне редко, это еще может быть оправдано.
Если же разархивировать приходится часто, либо шаблонности в данных маловато — увы, заранее сгенерированная таблица известных блоков превращается скорее в обузу. Проще строить ее на ходу, чем, собственно, все и занимаются.
BigBeaver
GIT же. Клиент видит полноценную базу кода для кадой версии, но в реальности мы храним дельту. Если ваша организация хранит, например, накладные, где менеджер заполняет только определенные поля, то это эквивалентная ситуация с точки зрения данных. В том смысле, что позволяет решить задачу такими же методами.
saboteur_kiev
Эм. Гит не хранит дельту, он хранит все версии и локально и на сервере.
Как минимум по умолчанию.
Cerberuser
AFAIK, гит использует дельту именно что "под капотом" в качестве метода сжатия. А семантически, да, хранит все версии.
BigBeaver
Тогда боюсь спросить, как так вышло, что папка .git весит в 20 раз меньше самой кодовой базы при наличии порядка 200 коммитов в одном только master.
saboteur_kiev
1. Каждая версия файла хранится в виде сжатого блоба, к каждому блобу есть хеш для его индексации. Исходники — это текст, который жмется очень хорошо. Тут я могу ошибаться, но вполне возможно что используется обычный зип.
2. Используется дедупликация — в каждом коммите просто список хешей. То есть если сжать какой-то одинаковый файл два раза — гит получит тот же самый хеш для этого блоба, и не будет хранить этот блоб дважды.
Периодически он перепаковывает одиночные файлы недавних коммитов в более крупные наборы файлов более старых коммитов, но внутри каждый файл хранится отдельным объектом-блобом.
2. коммиты, которые не принадлежат бренчам (удалил фича бренч) удаляются целиком, что еще раз говорит о том, что это несложная операция. GC по дефолту вроде удаляет это примерно через 3 недели неиспользования какого-либо коммита.
3. git как раз умышленно отказался от модели CVS — хранить диффы, чтобы было удобно делать различные штуки типа cherry pick, удалять старые ненужные коммиты и так далее. Он каждый файл хранит целиком. Просто пакует их.
Черт побери, ребята, это же написано в документации к гиту, о чем спор??
git-scm.com/book/en/v2/Git-Internals-Git-Objects#_tree_objects
nfarina.com/post/9868516270/git-is-simpler
В гите есть даже отдельные команды, чтобы распаковать отдельно взятый блоб в файл.
BigBeaver
2. Все равно получается, что полностью хранится только измененный файл, а остальное берется из прошлых. Но да, это не совсем то, что я сказал.
Да это и не спор — так, поболтать. Был не прав в формулировках, признаю. Впрочем, плохо понятно, как (3) помогает черри пику а не наоборот мешает.
saboteur_kiev
Так прошлые файлы тоже все хранятся целиком.
Нигде не хранится дельта файла.
И даже не хранятся дельты коммитов.
Каждый коммит — список определенных файлов в него входящих
Именно поэтому бренчи и коммиты в гите настолько легковесны — у них нет никаких зависимостей, которые нужно вычислять и хранить.
BigBeaver
Только не бейте — я уже признал, что перепутал дельту файла с дельтой репы.
Но таки поясните по пункту 3. А то я то ли тплю, то ли что-то еще упускаю.
anonymous
м.б. это ibrix fusion?
novoselov
А какой алгоритм сжатия покажет наибольшую эффективность, если в наличии много ресурсов и времени, а сжатие нужно произвести только 1 раз, например сжимаем видео 16K HDR 3D?
И в 2 словах: почему сжатие через поиск последовательности в числе Pi гиблая идея? :)
Alert1234
если в наличии много ресурсов и времени, можно начать разрабатывать квантовое сжатие чтобы все что угодно в один кубит помещалось.
3Dvideo Автор
Потому, что фон Нейман таки в чем-то прав)))
iproger
Есть ли какая-то утилита которая бы определяла наиболее оптимальный алгоритм сжатия?
sumanai
Скрипт на BASH, который сжимает всеми сразу и сверяет результаты.
iproger
Это понятно, но не то. Возможно, это как раз идеальная задача для нейросетей.
zuko3d
А чем плох скрипт на баше? Надёжно, быстро, дёшево.
iproger
Да ничем. Не считая отсутсвия кросс-платформенности и неоптимальности проверки. Просто представьте, вы предлагаете попробовать сжимать условный фильм на 5-10 гб множеством алгоритмов. Даже если взять кусок, это все равно слшком много. В идеале нейросеть могла бы по готовой базе сразу определить какой алгоритм будет лучше.
zuko3d
Ну баш условный же, ясное дело что питон тоже покатит.
По поводу неоптимальности — тут смотря какие параметры оптимизировать. Если сжимать универсальные файла по 5 ГБ, то нейросеть для оценки таких файлов почти наверняка не уместится в оперативке, т.е. запустить её в работу будет нелегко. А доказать, что она всегда выдаёт качественный результат (а в промышленных решениях без аудита никуда) ещё тяжелее…
Arris
По моему, овчинка выделки не стоит. Сначала надо нейросеть обучить на основе огромного объёма данных для сжатия, потом проанализировать наши данные, а потом уже сжать "условно оптимальным алгоритмом". Времени/электричества на первые два шага-то не жалко? ;)
MRD000
Плюс есть вопрос «с какими параметрами». Алгоритмы сжатия видео имеют кучу параметров, которые могут улучшить или ухудшить картинку. Плюс разные реализации одного и того же сжатия. И там немало комбинаций может быть. Кстати, как раз в теории нейросеть в этом бы и помогла, но для этого её нужно обучить на всех этих комбинациях.
Arris
Я не профи ни в нейросетях, ни в сжатии видео, но мне кажется, единственное реальное применение нейросети в сжатии — это анализ небольшой совокупности кадров на предмет "а чем именно лучше сжать именно вот эту последовательность?".
Ну и обучать, кмк, проще и дешевле.
Берем разные последовательности между I-кадрами, кормим нейросети, потом сжимаем разными способами и сообщаем обучалке, какой в данном случае алгоритм был лучше всех. Ну, там много нюансов, много направлений для оптимизации, но — судя по тому, что я слышал об этом деле — это наиболее вероятное применение.
3Dvideo Автор
Есть такой проект «Effective Video Transcoding», где как суть в том, что можно анализируя небольшую совокупность кадров пережать кусок, причем получив гейн по размеру до 15% в среднеми до 50% в лучших случаях. Как человек, имеющий прямое отношение к разработке этого алгоритма замечу, что как ни странно нейросети пока проигрывают классическим алгоритмам построения модели кодека). Посмотрим, конечно, что дальше будет, останавливаться на достигнутом не планируем.
При этом сегодня нейросети массово уходят внутрь кодеков. В новом AV1, например, который молитвами Google уже в каждом новом смартфоне под Android, внутри десятки небольших сеток на 5-7 слоев, заменивших методы принятия решений предыдущих поколений. Наш аспирант в этот проект код контрибьютил, в итоге сейчас работает в офисе Google в Лондоне.
drWhy
«как ни странно нейросети пока проигрывают классическим алгоритмам построения модели кодека»
КМК ничего странного. Кодеки десятилетиями целенаправленно проектировались на потерю незначительных для человеческого восприятия деталей, нейросети пока под это не обучаются массово, по крайней мере судя по образчикам их творчества.
15432
Зависит от входных данных и критериев. Основное в сжатии — поиск закономерности во входных данных и описание её в меньшем объёме. Например, видео сжимается в основном за счёт поиска схожести между соседними кадрами. С годами придумывают всё более изощренные и эффективные способы — H.264, H.265, H.266. При этом у каждого есть параметр preset («настырности»), сколько он будет пытаться подбирать эту самую схожесть. Поэтому берите самый актуальный из них и выкручивайте ресурсы на максимум.
anonymous
В двух словах, потому что размер адреса который укажет на нужную последовательность всегда будет больше чем сама последовательность.
Hilbert
Всегда? Не подскажете адрес последовательности 14159265358979323846264338327950288419716? :)
drWhy
«Хватит. Кончай мозгами скрипеть, балда. Вот ваша планета: 013 в Тентуре, налево от Большой Медведицы. Хочешь поговорить? Плати ещё чатлы.»
zuko3d
Конечно же не всегда и вы привели корректный контр-пример. Думаю, автор подразумевал «по мат. ожиданию». И тут такое дело, что если вы хотите закодировать последовательность из N (двоичных) цифр, то минимум у половины последовательностей начало стоит дальше, чем 2 ^ N и как следствие, потребует больше памяти на хранение адреса, нежели на хранение самой последовательности.
15432
anonymous
А почему именно pi? Можно взять тройку чисел M, N и P, таких, что M/N дает кусок нужной последовательности, а P — количество символов этой последовательности. Другой вопрос, существуют ли такие M и N отношение которых даст произвольную последовательность достаточной длины, чтобы это было выгодно? И есть ли способ их найти?
Hilbert
Потому пи — потому что иррациональное число, вот почему.
anonymous
это не единственное иррациональное число
zuko3d
Чисто Пи любят по той причине, что для него доказано, что в его десятичной записи можно найти любую наперёд-заданную последовательность. Это верно не для всех иррациональных чисел.
kipar
Насколько я знаю, это распространенное заблуждение — нормальность числа пи является открытой проблемой.
iingvaar
Нормальность — избыточное требование даже для утверждения «в его десятичной записи можно найти любую наперёд-заданную последовательность». А для целей «имеющейся у нас конкретной последовательности» достаточно даже рационального числа.
kipar
Избыточное, но существование любой последовательности доказать ещё сложнее (нормальность упрощённо говоря означает "все последовательности примерно равноправны, так что алгоритм построения числа не делает какие-то из них менее вероятными"), и для пи подобного доказательства нет.
Рациональными числами искать не столь интересно — обычно в виде шутки (а иногда и всерьез) предлагают искать именно в пи.
iingvaar
Здесь получается задача оптимизации с полиномиальным временем и без гарантии успеха.
Пример: Имеем число М=705128205
Представим его как смешанную периодическую дробь, отступив 3 знака: 0,705(128205)
Преобразуем в обыкновенную: 55/78
Было 9 разрядов. Стало (55,78,3) 5 разрядов. Явно стало короче, но для этого нам пришлось подобрать место расположения скобки.
nvksv
Пример попроще: из числа Pi генерируем таблицу перестановок byte -> byte (т.е. таблицу битовых последовательностей длины 8). И выходим на рынок с супер-идеей: наша таблица перестановок настолько супер-крута, что любые файлы после замены всех байт по ней начинают сжиматься гораздо лучше!
RolexStrider
Лучший комментарий, строго по Шеннону: когда вероятность следующего бита в зависимости от предыдущего — 50/50 — ловить тут нечего от слова СОВСЕМ. Об этом и статья.
Paranoich
А сайты всё пухнут и жиреют.
Четыре года назад мне хватало гигабайта с небольшим трафика в месяц, чтобы скоротать время в пути на работу. Сейчас не хватает пяти. И непохоже, что кого-то интересуют «единицы процентов». Хотя что, например, сделаешь с фейсбуком или вконтактиком? Толстеют и будут толстеть.
3Dvideo Автор
Но и оптимизировать будут. Недавно разговаривал с коллегами, которые грамотно пережимают тысячи картинок вконтакта в JPEG2000. Там хороший гейн был получен. И нетривиальная работа по оптимизации реализации JPEG2000 на GPU проведена.
AlexNoo
О! Jpeg2000… помнится, я писал по его поводу письмо автору статьи. И он даже ответил. :-)
Alexey2005
А ведь оно всё в сжатом виде передаётся. Всё видео — сжатое, изображения сжаты (bmp вроде уже ни на одном сайте нету), и даже HTML/JS передаются упакованными в gzip. Страшно представить, сколько сегодня уходило бы трафика, если бы постоянно не внедрялись всё новые способы сжатия. Вот скоро на смену png придёт массовый WebP, и размеры файлов изображений ещё снизятся.
sumanai
Самое забавное, что я эту фразу читал лет 5 назад )) Впрочем, оно уже много где заменило.
Sdima1357
Все правильно, но статья не понравилась. Никакой новой информации, кроме того, что мы самые крутые и отстаньте от нас со своими тупыми идеями. Вот вам тест, получится, приходите. С чем я согласен-ибо нефиг.
В остальном -каша. Пол текста об алгоритмах без потерь, потом резко вдруг об мр3, который ну никак к ним не относится со своей психо-аккустической моделью сжатия с потерями. Так же как и сжатие видео. А именно эти компрессии и представляют сегодня коммерческий интерес, а остальные -только научный. Немного сумбурно, но надеюсь, что автор меня понял
3Dvideo Автор
Вы точно внимательно прочитали? )
1. Речь шла про сжатие mp3 БЕЗ ПОТЕРЬ, психо-аккустика при этом не применяется, только энтропийный движок.
2. Сжатие видео — отдельная интересная тема, которой автор много и плотно занимается и о которой писал на хабр, ссылка на статью в конце для тех кому интересно приведена.
3. В тексте несколько раз даны примеры именно коммерческой эффективности алгоритмов сжатия без потерь. И ровно по этой причине компании объявляют конкурсы на десятки тысяч долларов (2 примера дано, в последнем конкурсе 12 номинаций).
Sdima1357
Я прочитал внимательно. И я тоже занимаюсь сжатием аудио, видео за деньги. То что вам заплатили за пережатие файлов с потерями без потерь — это просто забавный случай. В medical imaging, которым я занимаюсь больше 20 лет случались и более забавные истории. Я же не сказал, что что-то не так, я сказал что освещение темы -однобокое.
И да -десятки тысяч долларов — это просто ни о чем. Это зарплата за пару месяцев. А приличные алгоритмы сжатия аудио видео сегодня — это пару лет работы. И не одного человека, а нескольких.
3Dvideo Автор
Про конкурсы — на десятки тысяч долларов логика в статье совершенно конкретная: множество людей по непонятной причине полагает, что они изобретут классный алгоритм, дорого продадут его и будут богаты. Реальные же примеры — скорее ближе к ML/DL пути, т.е. победы на конкурсах и далее работа в компаниях. Т.е. заработок будет на зарплате, а не на патентах/продаже технологии. В чем однобокость? )
Sdima1357
Однобокость в направлении освещения темы. Коммерческого интереса, эффективность по сжатию алгоритмов сжатия без потерь сегодня не представляют, в силу отсутствия принципиально более эффективных алгоритмов. Деньги сегодня — в сжатии аудио -видео. И там и алгоритмы другие. Тема сжатия без потерь удобна именно лёгкостью верификации алгоритма, и не слегка устарела. Лет на 20. Ну может скорость компрессии/ декомпрессии представляет коммерческий интерес.Впрочем, не может, а точно представляет коммерческий интерес.
Сложности именно в сжатии аудио -видео с потерями в котором даже верификация вызывает нетривиальные проблемы. В смысле что я согласен с комментарием:
habr.com/ru/post/525664/#comment_22244112
3Dvideo Автор
Деньги, конечно, в основном в сжатии видео. Но приколитесь, я уже 17 лет читаю курс на ВМК МГУ, где есть сжатие (хотя большую часть — обработка видео). Так еще года три назад хотел кусок про сжатие вообще прибить. Так первые, кто были против — это российский Intel. Они занимаются всем спектром кодеков, но, говорят, совсем нигде энтропийному не учат, брать неоткуда людей будет. И даже платную магистратуру оплатили человеку, со студенческой лабораторией несколько лет помогали. Сейчас вот Huawei пришел — говорит — нужны люди на кодеки. И даже конкурс проспонсировали. Короче — похоже, что ваша точка зрения, что «коммерческого интереса алгоритмы сжатия без потерь не представляют» однобока. ) Причем интерес идет со стороны разработчиков алгоритмов сжатия видео с потерями, т.е. самого что ни на есть мейнстрима.
Также интересно, что как раз сейчас появился реальный шанс на появление «принципиально более эффективных алгоритмов». Тут надо будет через пару лет смотреть.
Sdima1357
Вот через пару лет и поговорим. А я пошел дальше писать компрессию для данных с СT detectors ~10 гигабайт /сек.
И да, в Хайфе Интел более отзывчивый
drWhy
Когда же уже сырые данные начнут хранить вместо восстановленных срезов?
Sdima1357
А их и хранят какое-то время на самом сканере. Есть специальный отдельный raid. У некоторых фирм, даже в отдельной машине. Иначе он FDA не пройдет. А дальше -не знаю, видимо никому не нужны. А кроме того -их слишком дофига и формат не стандарт, там много служебной информации не хватает для реконструкции. Вроде Филлипс пытался что-то изобразить, но дальше не знаю, у всех свои секреты и обязанности. Реконструированный DICOM наружу отдали и ладно.
drWhy
Так недостающих данных по сравнению с объёмом сырых кот нарыдал. А объём последующих реконструкций может его кратно превосходить, не неся дополнительной информации но теряя возможность последующих реконструкций.
Объёма накопителя для сырых данных хватает на несколько дней и они могут тереться по мере получения новых.
Что-то мне подсказывает, что для объёмных данных можно достичь гораздо более высоких коэффициентов сжатия, чем для послойных, сжатых скажем JPEG2000.
Sdima1357
Немного оффтопик, да простит меня автор статьи.
1 реконструкция выполняется на более дорогом оборудовании чем, то на котором доктор смотрит картинки иногда на пару порядков, в случае итеративного реконсруирования
2 вместе с сырыми данными нужно поставлять и программу реконструирования, а она не всегда влезет на компьютер доктора, и результат ещё надо верифицировать для разных архитектур.
3.число степеней свободы (значимый объем данных) у исходных данных и реконструированных примерно одинаково. Собственно это одно из требований FDA(реконструкция без потери значимой информации). Так что компрессироваться они будут абсолютно одинаково.
4 серия DICOM картинок отлично жмётся именно благодаря некоторой избыточности. Картинки сильно зависят друг от друга по оси Z. И этим пользуются при хранении.
drWhy
1 не всегда, а иногда напротив
2 аналогично, встречал ПО для реконструкции свёрткой, занимающее что-то около 20 МБ.
3 о таких требованиях не знал, спасибо. Информативность сырых данных всё же выше к оси вращения и ниже по краям, на плоских реконструкциях она равномерна. Т.е. если реконструкции делать с максимальным разрешением, как в центре они будут избыточно большими, если взять среднее разрешение неизбежно какая-то часть существенных данных пропадёт.
4 тут как раз в тему статьи.
Sdima1357
Реконструкция сверткой — это только малая часть. Да и не всегда ей пользуются. Сейчас больше в моде итеративное обратное моделирование физики процесса. И даже простейшеая реконструкция в виде обратной проекции со сверткой с фильтром имеет дофига дополнительных дееталей. Есть ещё beam hardening correction, коррекция плохих или нестабильных детекторов(которая зависит от промежуточных результатов), редукция металлических артефактов, балансировка взвешивания проекций для спиральных и сканов сердца с учётом кардиограммы, тока трубки и профиля излучения, коррекция рассеивания, ожидание контраста и ещё много много всего. И добавьте вишенку — подавление шума. Правда не все этом занимаются
drWhy
Интересно, а «редукция металлических артефактов» была бы очень актуальна, ибо артефакты от звона свёртки об металл мешали анализу изображений. Но поставщик не заморачивался и предлагал только свёртку. К более дорогим детекторам раньше поставлялся отдельный Фурье-процессор, потом похоже о нём окончательно забыли.
Печально всё же, что несмотря на бурно развивающееся в последние годы ПО для обработки DICOM изображений всё ещё не налажена обработка чужих сырых данных. То есть понятно, что есть ограничения на ПО в связи с его применением в диагностических целях, ответственность и всё такое. Но жаль.
saintbyte
Супер-словарь предлагали сделать уже?
3Dvideo Автор
Конечно) Кстати — при сжатии википедии в Hutter Prize умное применение предварительных статистик крайне актуально.
AntonSor
То есть сейчас самая главная надежда на нейросети, которые будут реконструировать данные по описанию?
3Dvideo Автор
Я бы не говорил «надежда», но нейросети многое в сжатии перетряхнут (с заметным повышением эффективности алгоритмов). Это уже четко видно.
Alexey2005
Кстати, сжатие данных нейросетями может существенно подкосить пиратство. Если для качественной упаковки фильма на обычной персоналке потребуется 500 лет, пираты попросту вымрут из-за невозможности повторить этот процесс в домашних условиях.
AntonSor
Будут пережимать с потерей данных, в устаревшем формате :) Смотрят же люди экранку.
6095959
ботнет запрягут, делов то,
а вы и не узнаете, что ваш умный пылесос или кормушка для животных видео кодируют
Yaong
Никто не вымрет, просто будут упаковывать некачественно, но за сутки.
demon416nds
Compression.ru как давно это было.
С универсальными архиваторами таки да особо текущую ситуацию не улучшить. А вот со специализированными поле деятельности весьма широкое. Скажем сжимать мультипликацию в целом и аниме в частности явно можно лучше чем стандартными видеокодеками просто в силу методов создания мультипликации.
Для текста тоже можно вынести изрядную часть избыточности в специализированный архиватор.
3Dvideo Автор
На Hutter Prize ровно об этом речь. И там сейчас минимальный приз 5000 EUR (они подняли).
demon416nds
Вектор слишком ресурсоемко рендерить. Да и с векторизацией тоже много проблем к которым на данный момент непонятно как подступиться. В особенности градиенты доставляют.
AntonSor
Это пока ресурсоемко.
Griboks
Тоже сделал свой архиватор для скриншотов через рекомпрессию — сэкономил достаточно много места.
А не знаете ли вы какие-нибудь профессиональные программы для этой цели?
p.s.
3Dvideo, спасибо.
3Dvideo Автор
Сорри, не слежу. Запросы на screen capture codec получали от разных компаний, в последний раз от Huawei.
AlexanderplUs
Книга «Методы сжатия данных» очень хорошая была, по крайней мере в плане алгоритмов сжатия данных и текста. Зачитал до дыр, большое спасибо!
3Dvideo Автор
Бальзам на душу, спасибо! 3 автора книги комментарии читают)
le1ic
Господи боже, ваш пост заставил меня вспомнить времена, когда на собеседовании можно было спросить хотя бы, что такое хаффмановское кодирование. Эх, неплохие времена были…
С Ратушняком и Смирновым пересекались в одной преснопамятной конторе…
3Dvideo Автор
)))) Да, что такое хаффмановское кодирование современная молодежь не знает
Sergey_Kovalenko
)))))) Видать человеку тоже надоело дурацкие письма читать, вот он и решил всех граждан с нестандартным мышлением собрать на одном большом корабле.
3Dvideo Автор
Абсолютно верно ))))
Sdima1357
А ещё можно посылать всех например сюда:
quixdb.github.io/squash-benchmark
В интернете есть ещё несколько подобных мест, куда можно посылать любителей покомпрессировать.
force
Ээх… тоже делал свой архиватор (LZ4, вид сбоку), такая интересная тема. Понял, что гораздо интереснее делать всякие нестандартные вещи (типа сжатие независимых похожих объектов), передача метаинформации в архиве, сжимать ресурсы в программе с простым кодом расжимания. Но понимаешь, что даже ради хобби — достаточно грустное занятие, т.к. ресурсов надо на порядок больше.
tyomitch
Первое, что приходит в голову — это LZW в GIF: вроде бы за него Unisys успешно сдирали деньги.
Sdima1357
Арифметический кодек, тоже под патентом. Был во всяком случае.
3Dvideo Автор
5 патентами на арифметик владела IBM и никому их не лицензировала. И тоже не обогатилась на этом)
Sdima1357
Да, точно. Они вообще ребята забавные,IBM в смысле.я когда у них Албани был по поводу переговоров относительно процессора Cell они нам сервер на нем так и не дали для тестов, заломили безумную цену в 50000. Ну и сидели как собаки на сене. Процессор, который мог стать их удачей, стал чистым расходом. И для них и для Сони и для Тошиба. Несвоевременная жадность — она до добра не доводит.
3Dvideo Автор
akuleshov7
Отличная статья, спасибо! Реально полезно :)
drWhy
Тем временем Фабрис Беллар, автор lzexe и много чего ещё разработал эффективный алгоритм сжатия текста с учётом вероятности появления следующего слова.
Идея: допиливаем сеть, хорошо транскрибирующую видео и сжимаем результат алгоритмом Фабриса Беллара. Другая сеть по разжатой транскрипции восстанавливает Нео, взмывающего со взволнованного асфальта ввысь и Тринити в обтягивающем мотокостюме, обрушиваюшуюся с небес на головы незадачливых охранников.
Результат сжатия печатаем на (одной) перфокарте для потомков.
Спасибо за содержательную статью, в особенности за напоминание кто есть ху в мире сжатия.
AlexNoo
А вот был такой формат архивов как HA. И им любили сжимать книги… утверждали, что текст он лучше всех жмёт… И когда я стал его искать, то нашлась одна программа, чтобы открывать эти архивы. BookSeer. :-) Интересно, это я так плохо искал, или где-то есть программы для работы с этими архивами?
SlimShaggy
Есть HA Archiver Plugin для Total Commander: http://wcx.sourceforge.net/
saboteur_kiev
под досбоксом ha можно вполне запускать, в инете гуляет две версии.
И да, тексты он жмет (или жал) заметно лучше всех, но раза в 3-4 медленнее чем другие архиваторы.
tyomitch
Раз уж пошла такая пьянка: где раздобыть досовских архиваторов?
Кажется, у WinAce была неплохая версия под DOS.
drWhy
saboteur_kiev
Да думаю на любом торренте можно найти подборку досовских архиваторов. У меня где-то завалялись в бэкап диске всякие arj,zoo,pkpack но я не уверен что последние версии.
Опасаться подобных программ не стоит — можно скачать с какого-нить сайта любителей раритетов, прогнать через любой онлайн антивирус и в досбокс.
usbstor
HA жмёт хуже, чем RAR. У меня было несколько тысяч книг, ещё с BBS скаченных и запакованных HA, так я их в RAR перегнал, потому что на CD не влезали, а после RAR-а стали влезать.
Arris
Разумеется. Просто в свое время HA жал тексты заметно лучше, чем ARJ, ZIP или какой-нибудь, прости Тьюринг, AIN.
P.S. Учитывая, что AIN еще любил запарывать архивы на ровном месте, RAR был как манна небесная.
saboteur_kiev
Видимо вы сравниваете очень старый ha и очень новый rar
Во-вторых я почти уверен, что вы сравниваете rar c использованием solid archive.
А если взять рар во времена DOS (дай бог памяти, какой-нить 2.55 версии), то ha однозначно был лучше.
saboteur_kiev
Вдобавок, видимо вы неправильно пользовались ha и даже не ставили хороший метод сжатия, ибо я попробовал вот прямо сейчас.
ha0999.exe
winrar 5.20 (оба метода — в rar и rar5)
Везде максимальная степень сжатия, максимально большой словарь, солид архив.
Результаты:
hotstart.txt, обычный текст в winn1251, размер 656850
250448 hotstart.rar
250843 hotstart_rar5.rar
223972 hotstart.ha
tzan.htm тоже текст, но в UTF-8, размер 1148861
263504 tzan1.rar
263769 tzan1_rar5.rar
249144 TZAN1.HA
hpmor.ru.fb2 UTF-8, есть парочка jpegs in base64, размер 6819245
1334614 hpmor_ru.rar
1334009 hpmor_ru_rar5.rar
1376798 HPMOR2.HA
edem.fb2 UTF-8, только текст без аттачей, размер 821121
193101 edem.rar
193280 edem_rar5.rar
173413 EDEM.HA
Итого, ha уверенно лидирует, показывая результат на 5-10% лучше. Но только если файл — чистый текст
tyomitch
Солид архив — это просто «накатить tar перед сжатием»; при сжатии одиночного файла это не приводит ни к какой разнице.
saboteur_kiev
Ну смысл в том, что я не уверен, что ha умеет в солид, ибо отдельной опции у него такой нет, и на большом количестве файлов, есть вероятность, что современный winrar может построить словарь лучше, используя 64 гб оперативки, о чем ha естественно не мог и мечтать, работая даже в 640 кбайт.
sumanai
Думаю, ему можно будет скормить tar. Unix way ))
saboteur_kiev
Ну можно, просто смысла особого нет по вышеуказанной причине.
Современные архиваторы, которые в солид, могут использовать гигабайты оперативки для создания словаря, следовательно на большом количестве файлов однозначно будет выигрыш
А ха — ну что-то улучшится, но я сомневаюсь что будет какой-либо прирост после 1-2 мегабайта, ибо в 95 году 4 мб оперативки была редкость.
3Dvideo Автор
Интересно CMIX посмотреть, например).
Вообще на Large Text Compression Benchmark у Мэтта Махоней топ-10 (из примерно 200 архиваторов текстов) выглядит так:
Понятно, что это заточка именно под Large Text, но тем не менее хорошо новых лидеров измерить.
phda9 (2 место), кстати — это Саша Ратушняк, durilca'kingsize (6 место) — это Дмитрий Шкарин, и к paq8* (4 и 7) Саша Ратушняк руку также прикладывал)
saboteur_kiev
Не, кофморт использования и популярность в большинстве случаев значит больше, чем специализация. ПРосто тут выше был спор о том, что winrar лучше ha жал тексты. Я вот попробовал — что на одиночном текстовом файле он и сейчас оказался лучше, несмотря на разницу почти в 15-20 лет.
Ну а gzip вообще не имеет смысл сравнивать. Его плюс точно не в силе сжатия =)
BigBeaver
У RARа (или его левых условно свободных реализаций) есть еще проблемы с кодировками в именах файлов. В общем, для людей, кто выбирает его вместо zip, есть отдельный котёл.
tyomitch
Ух сколько раз я видел ZIP-ы со сломанными кодировками в именах файлов! Даже стандартный file-roller в Ubuntu записывает имена в UTF-8, а стандартный просмотрщик в Windows категорически отказывается их в таком виде понимать.
BigBeaver
Ну рар, сделанный в винде в линуксе гарантированно сломан. С зипом не встречал проблем ни разу.
saboteur_kiev
о, рар в линукс. Я слышал что его там собрали и запустили, но это же не winrar ;)
saboteur_kiev
Простите, какие там проблемы? у Winrar вроде бы никогда не было проблем с кодировками. Нормальный utf-8
Или вы про досовские версии?
BigBeaver
А про (win)rar никто и не говорил.
saboteur_kiev
Мне кстати интересно.
Почему сравнение идет именно с gzip, а не хотя бы zip?
Ведь gzip это вообще потоковый архиватор, с которым прямо нет смысла соревноваться тем, кто может прочитать и проанализировать файл целиком перед сжатием?
3Dvideo Автор
Потому, что gzip и zip — это один алгоритм сжатия, а поддержка gzip вообще говоря выше, поскольку он поддерживается, например, во всех броузерах.
А с zip человек сравнивается (пусть и с ключем максимальной степени сжатия), поскольку он сжимает хуже, конечно).
Для сравнения: у 7zip 44 место в рейтинге, у WinRAR — 71 место, у bzip2 (крайне популярен под Linux) — 116, а у gzip — 146 место (из 199))). При том, что все архиваторы внесены с наилучшими опциями (сжатие может сильно отличаться в зависимости от опций).
Arris
https://yadi.sk/d/y01KMiG7KQ282Q (взято откуда-то из сети)
Развлекайтесь (на генте собралось без проблем, с парой варнингов)
Xitsa
Ещё есть зеркало на gitlab'е.
3Dvideo Автор
Интересно следить за новыми экспериментами, например, NNCP: Lossless Data Compression with Neural Networks. Не рекордный, но на enwik9 сжимает тексты В 2.7 РАЗА(!) сильнее gzip!
А за ними еще есть tensorflow-compress (последнее обновление которого на гитхабе 2 дня назад(!!!)), или DeepZip: Lossless Data Compression using Recurrent Neural Networks, CMIX с нейросетевой LSTM и т.д.
Это крайне интересные ростки завтрашнего дня! Надеюсь, руки дойдут и про это нейросетевое безобразие напишу. )
inemiten
Самое лучшее сжатие без потерь обеспечивает magnet ссылка.
Celsius
IPFS еще и скорость "распаковки" обеспечивает хорошую для любых файлов.
Интересно, сколько раз автору предлагали алгоритм сжатия на основе условного sha256+размер файла.
v1000
Самый короткий анекдот: pkunzip.zip
DmitrySpb79
Раз уж речь зашла про аудио и MP3… Можно дурацкий вопрос — существуют ли кодеки для сжатия без потерь при записи, чтобы вместо wav можно было использовать? 24ч wav для SDR анализа весят больше гига даже при минимальном sample rate 8000.
3Dvideo Автор
Безусловно:
hd_keeper
FLAC, ALAC, APE не пробовали?
DmitrySpb79
Спасибо. FLAC наверно самое удобное, да, под него библиотек и плееров много.
drWhy
Так в SDR Вы на переднем крае, искать ИМХО придётся самому оптимальный вариант. Любой кодек, написанный для звука и чего-то другого не приспособлен для SDR и либо будет неэффективен, либо убьёт информативность.
КМК искать нужно либо у коллег по цеху, либо у радиоастрономов — им приходится десятилетиями хранить огромные массивы необработанных данных, не теряя пока не найденных артефактов.
Возможно, выходом было бы хранение несжатых данных на винчестерах ноутбучного формфактора — они массово доступны на вторичном рынке за гроши. Весьма удобно использовать, не теряя в скорости, через USB3 переходник. Либо подключать наживую к материнской плате с шестью sata портами, периодически подставляя пустые.
DmitrySpb79
Спасибо. У меня нет цели хранить терабайты месяцами (хотя слышал о проектах, где некоторые хранили IQ-записи АМ-диапазонов целиком, для истории довольно любопытно, но там при sample rate хотя бы 2МГц размеры файлов уже космические). Но файлы хотя бы 192КГц битрейтом и 24ч длительностью для анализа иногда записать полезно.
Другой вопрос, что радиосигнал содержит случайные шумы, и может он вообще не пожмется без потерь, но тут хз, я не теоретик :)
drWhy
«радиосигнал содержит случайные шумы, и может он вообще не пожмется без потерь»
А эти утерянные при сжатии шумы внезапно окажутся сигналами внеземной цивилизации, за которые кто-то не сжавший получит нобелевку.
DmitrySpb79
Разумеется, любой сигнал для анализа нужно сохранять без потерь. Просто если сжатие дает 5% но требует больших вычислительных ресурсов, проще вообще не сжимать, а писать каноничный чистый WAV :)
DmitrySpb79
В дополнение, провел сейчас эксперимент.
WAV файл с радиозаписью размером 986 Мб сжался zip до 906 Мб и 7z ultra до 712 Мбайт. Наверно оно того не стоит, кардинального прироста нет, а сложность записи и обработки таких файлов вырастает.
super-guest
Кхе-кхе. Я извиняюсь,
но какой архиватор посоветуете для Mac OS?
Пользуюсь либо встроенным (жмёт в zip), либо Archiver, либо Keka, но может есть вариант(ы) получше?
hd_keeper
tar+bzip2
DmitrySpb79
По-моему пользоваться надо тем, что есть на каждом компе, особенно если речь о пересылке файлов. Zip тут как раз самое то.
Весело бывает с тем же Маком, когда кто-то присылает архив в RAR (и зачем? 10 Кб сэкономить?) и начинаются поиски распаковщика в App Store :)
drWhy
Зато rar умеет добавлять избыточную информацию для восстановления битых архивов, например.
le1ic
Битые архивы — это артефакт времен аналоговых модемов с crc16 / crc32. В современных реалиях, где сплошь tls, откуда взяться битому архиву.
drWhy
Бывает, данные теряются и их восстанавливают. Бывает лента не дочиталась или оптический диск поцарапался.
tyomitch
Дискеты ещё! Записать архив на десять убитых дискет и прочитать все части без повреждений — редкая удача.
drWhy
Дискеты ещё существенно разные были, даже в одной пачке.
Помню, маялись, отбирая лучшие образцы, у которых скорость записи/считывания могла быть процентов на 10-20 лучше средней. Их форматировали на 1,7 МБ и записывали дистрибутив Windows 3.11 для ускорения последующей установки.
OnvogSGN
drWhy
Кто вообще придумывает названия для Mac OS? Кексты, Keka…
Тут Far manager под Macos запилили, он 7z умеет, как и Keka впрочем. Зато можно в теме запросить новую функциональность.
BorodaMhogogreshnaya
В одной программе, над которой я работал, надо было сохранять данные в двоичном виде. А что такое двоичные данные? Это набор массивов каких-то типов. Каждый тип имеет какую-то длину в байтах, например, тип int – 4 байта. Я разделил каждый массив поразрядно. В результате простой RLE сжимает типичные данные вдвое, потому что старшие разряды у полей — в большинстве случаев либо 0, либо FF.
Если натравить на результирующий файл стандартный архиватор, то он сожмёт ещё вдвое.
Если же сохранять массивы не поразрядно, то стандартный архиватор, всё равно сжимает только в два раза.
tyomitch
В этом случае отлично помогают en.wikipedia.org/wiki/Variable-length_quantity
MaxAkaAltmer
В свое время тоже увлекался сжатием, разработал даже два довольно экзотических алгоритма: комбинаторное без потерь и аффинное для сигналов (почитать можно тут — arts-union.ru/articles/altmer/geomonitoring.pdf), имхо занятие вряд ли прибыльное (в современных реалиях), но точно увлекательное!
anonymous
Вот если рассмотреть файл побитно до сжатия без потерь и после сжатия (результат), можно заметить интересную картину: в результирующем файле (по сравнению с исходным, особенно, если сжать удалось в несколько раз) мы можем увидеть гораздо более длинные цепочки подряд идущиех битыов, равных 1, аналогично и для равных 0.
Существует какое-то объяснение этого явления?
saboteur_kiev
ну например для ASC текста — в подавляющем большинстве случаев никто не использует псевдографику, а английский алфавит и все нужные символы влазят в первые 127 символов. Поэтому 8й бит не нужен, и можно просто без сжатия сохранить текст как 7-мибитный, убрав лишний 0 из каждого байта.
Вот и уменьшили количество нулей в текстовом файле на 10 восмиричных процентов
xvoland
Вы всё правильно написали, особенно забавно было почитать про конкурсы в $100 и известность.
Вы же сами привели Джима Коунси, директора подразделения Autodesk Developers Network и вспомнили про блог Dances with Elephants: How small companies can partner with large companies to accelerate their business growth.
Т.е. некая компания, хочет получить что-то дорогое, всего за $100 или даже за $10000.
Что такое $10т. в современном мире? Это месяц-два работы!
Получается, что человек/компания потратившая много-много своего личного времени (за $0 в час) на разработку какого-то уникального алгоритма, должна отдать его за эту смешную подачку?!
Вы можете ещё возразить, а как же «слава»?
Ну, так вам Коунси и объясняет — вас раздавят и не заметят! Другими словами, просто отберут алгоритм и скажут: вы — никто, а мы — всё! (История имеет МНОГО примеров) Даже просто по тому, что у них медиа и финансовый ресурс — ОГРОМЕН! И вы не сможете с ними бороться за «славу».
Я, как и вы, когда-то занимался разработкой сжатия данных. Я, как и вы, получил замечательные результаты, но был один минус — не всегда удавалось сжать данные и иногда сжимаемые данные, на выходе, были больше чем оригинал (это нормально, такое есть и у RAR и Zip). Необходимо было дополнительно исследовать и разрабатывать, НО хотелось кушать!
Вообщем, моя мораль: я, лучше разработаю это, как говорят писатели, в стол до лучших времён, ну а если не получится то на предсмертном одре — расскажу, как…
3Dvideo Автор
Мой личный рецепт в последнем разделе статьи — ориентироваться на лучших. Лучшие часто алгоритмами зарабатывают (не всегда сжатия без потерь, тема все-таки довольно узкая, но тем не менее))).
xvoland
Ок. Конкурсы, проводят не для просто так, а для зарабатывания потом много $$$$$$$$$
Поэтому, стоит задуматься, если у вас действительно есть что-то гениальное, как это гениальное сохранить. Я — не Перельман, я — хочу кушать, ездить на новых машинах, ходить в удобной хорошей одежде, обеспечивать семью и родителей.
А, слава?! Нафиг нужно!
Сто раз подумайте, какую вы имеете цель и для чего вы это всё делаете.
Миром правят — прагматики! Но с другой стороны, без лоха и жизнь плоха )))))
Vpolevoj
Автору браво.
Аплодирую стоя.