

Разрыв между быстродействием процессоров в общем смысле и быстродействием основной памяти DRAM, также в общем смысле, был проблемой в последние 30 лет – в этот период разрыв начал по-настоящему расти. И стоит честно сказать, что инженеры, разрабатывавшие как оборудование, так и программы, создавшие иерархию кэшей и ПО, способное воспользоваться её преимуществами, поступили просто гениально. Это одна из труднейших в реализации архитектур, когда-либо задуманных человеком.
Однако теперь, когда мы находимся на пороге появления постоянно расширяющейся иерархии памяти, когда начинает появляться энергонезависимая память типа Optane 3D XPoint (вариант памяти с изменением фазового состояния) в формате DIMM и SSD, а также новые протоколы (CXL, OpenCAPI, CCIX, NVLink и Gen-Z), возникает вопрос: не пора ли добавить серверам кэш четвёртого уровня? Поскольку от комплекса CPU зависит работа такого количества устройств – некоторые из которых расположены ближе, другие же дальше – логично задуматься над тем, не нужен ли нам ещё один уровень кэша, маскирующий задержки этих других видов памяти и увеличивающий пропускную способность всей системы.
Чтобы представить открывающиеся возможности, мы покопались в своей собственной памяти, а заодно пообщались с разработчиками архитектуры чипов из IBM, Intel, AMD и Marvell, чтобы понять, что они думают об использовании кэша L4 в серверах. Кэш L4, конечно, не новое слово в быстродействии, однако он и не так уж часто встречается в системных архитектурах.
Однако прежде нам стоит пробежаться по истории вопроса.
Добавление кэша первого уровня к процессорам, у которых в то время было всего одно ядро, в 1980-х стало компромиссом, добавляющим задержки в подсистемы памяти, одновременно снижающим среднюю задержку запросов данных и инструкций процессорами. Кэши L1 изначально находились во внешней SRAM, находившейся на материнских платах и подключавшейся к комплексу CPU-память. Такой кэш L1 находился очень близко к процессору, как в смысле тактовой частоты, так и в смысле физического пространства на плате, и давал возможность повысить загрузку CPU. Потом эти кэши разделили, чтобы в одном блоке можно было хранить часто используемые данные, а во втором – популярные инструкции, и это немного увеличило быстродействие. В какой-то момент увеличения тактовой частоты процессоров и соответствующего разрыва в быстродействии CPU и DRAM, были добавлены более жирные, но и более медленные кэши L2 (зато более дешёвые в пересчёте на пропускную способность), опять-таки сначала находившиеся вне корпуса CPU, а потом интегрированные в него. А когда в CPU начали добавлять всё больше и больше ядер, а также всё больше контроллеров DRAM для их загрузки, к иерархии добавили ещё более крупные блоки кэшей L3.
По большей части такая система работала достаточно хорошо. В некоторых схемах CPU мы даже видим определённые практические правила, отражающие уровни иерархии кэшей, которые позволят нам прикинуть возможности, связанные с четвёртым уровнем.
Крис Джианос, инженер чипов и архитектор из Intel, руководившей разработкой многих прошлых поколений процессоров Xeon, объясняет это так: «С каждым уровнем кэша нам обычно нужно, чтобы они выросли достаточно сильно по сравнению с предыдущим уровнем, чтобы всё это имело смысл, поскольку чтобы достичь заметного прироста быстродействия системы, нужно достичь достаточно интересной частоты успешных обращений. Если вы „попадаете“ в кэшированные данные всего в нескольких процентах случаев, это будет сложно заметить. Всё остальное затормаживает ваше быстродействие, и этот прирост будет незаметным. Поэтому требуются относительно большие кэши, и когда речь идёт о более высоких уровнях, нужны реально огромные кэши. Сегодня L2 измеряются мегабайтами, L3 измеряются десятками или сотнями мегабайт. Так что понятно, что если вы начинаете думать о кэше L4, то речь пойдёт уже о сотнях мегабайт, если не о гигабайтах. А такой размер определённо приведёт к их высокой стоимости. Нужно, чтобы сложились определённые условия, чтобы этот вариант стал интересным, и дешёвым он определённо не будет».
Инженеры из компании AMD, с которыми мы беседовали, пожелали остаться неизвестными потому, что они не хотели создать впечатление, что компания собирается добавить кэш L4 в линейку процессоров Epyc – и, если быть точным, AMD ничего такого и не обещала. Однако компания всё же признаёт, что это следующий очевидный шаг для рассмотрения, и, точно так же, как Intel, считает, что все инженеры размышляют о реализации кэша L4. По сути, AMD говорит, что компромиссы, связанные с уровнями кэшей и задержками подробно изучены как в промышленности, так и в научных кругах, и что с каждым новым уровнем, который оказывается больше и медленнее предыдущего, возникает компромисс увеличения общего пути к DRAM. Об этом говорит и Джианос из Intel, рассказывая о необходимости поиска баланса между успешными запросами к КЭШу и его объёмом.
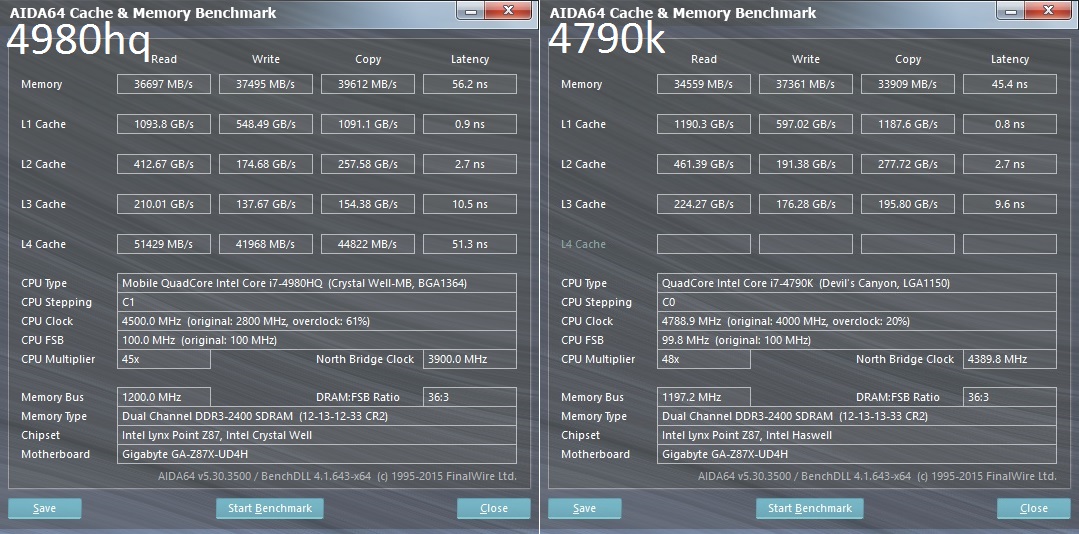
IBM, конечно, добавляла кэш L4 к некоторым своим чипсетам X86 в 2000-х, а в 2010-х добавила L4 к чипсетам NUMA (неравномерный доступ к памяти) на мейнфреймах System z11. У процессора z11 четыре ядра, 64 КБ L1 кэш для инструкций и 128 КБ L1 кэш для данных, плюс 1,5 МБ L2 кэш для каждого из ядер и 24 МБ L3 кэш общего доступа для всех ядер. У чипсета NUMA для z10 было два банка по 96 МБ L4 кэша, то есть, 192 МБ в сумме. Выпустив z12, IBM урезала размер кэша L1 до 98 КБ на ядро, однако увеличила L2 кэш до 2 МБ на ядро, разделив его при этом на две части, для инструкций и для данных, как в случае с L1. Также она удвоила размер кэша L3 до 48 МБ для шести ядер, а размер кэша L4 был увеличен до 384 МБ для пары чипов в чипсете. При смене поколений процессоров System z объёмы кэшей росли, и у процессоров z15, анонсированных в сентябре, пара кэшей L1 будет весить по 128 КБ, пара кэшей L2 – по 4 МБ, а общий кэш L3 будет для 12 ядер иметь объём 256 МБ. Объём кэша L4 в каждом отсеке мейнфрейма составляет 960 МБ, а его общий объём для всей системы, состоящей из пяти отсеков, равняется 4,68 ГБ.
Как мы уже указывали ранее, у процессоров Power8 и Power9 память буферизована, а IBM добавила 16 МБ L4 кэша к каждому буферу Centaur, что составляет 128 МБ L4 кэша на сокет для 32-х планок памяти. У самых дешёвых машин с Power9 нет буфера памяти, а, следовательно, и кэша L4. Архитекторы, разрабатывавшие схему Power10, были заняты разработкой схемы для Power11, и потому не смогли ответить на наши вопросы, но Уильям Старк, управлявший разработкой Power10, нашёл для нас немного времени, и заметил следующее:
«В целом мы пришли к выводу, что кэши последнего уровня большого размера полезны для увеличения быстродействия промышленных систем, — пояснил нам Старк по емейл. – Высокие задержки, связанные с энергонезависимой памятью, в частности, с памятью с изменением фазового состояния, порождают запрос на кэширование – возможно, на кэш типа L4 – в иерархии накопительной памяти».
Именно так мы и думали. И, кстати, мы не утверждаем, что кэш L4 обязательно будет находиться в непосредственной близости от буферизированной памяти будущего DDR5 DIMM. Возможно, его лучше расположить между PCI-Express и кэшем процессора L3, а ещё лучше, в буферах памяти и между PCI-Express и кэшем процессора L3. Возможно, его для этого придётся поместить наверху контроллера I/O и памяти в будущей серверной архитектуре, что немного напоминает технологию Foveros от Intel.
На это возможно взглянуть и с другой точки зрения – допустим, у IBM была возможность менять размеры кристалла, и инженеры решили добавить кэш L4 к шине System z NUMA или к чипу буферизации памяти Power8 и Power9 не ради его самого, а просто потому, что у них оставалась ещё возможность добавить транзисторов после того, как все необходимые функции были реализованы. Иногда нам кажется, что количество ядер в процессорах Intel X86 зависит от размера кэша L3, который они могут себе позволить. Иногда кажется, что Intel назначает максимальный размер кэша L3 на один кристалл, и после этого кристаллы Xeon трёх разных размеров просто изготавливают по этим спецификациям – в последних поколениях у них по 10, 18 или 28 ядер на техпроцессе в 14 нм.
Всё это, конечно, чисто академические вопросы, однако они дают нам возможную мотивацию для IBM и других производителей чипсетов на добавление кэша L4. Это не просто может помочь в каких-то случаях, это просто довольно очевидная вещь. Думаем, что на таком монстре I/O, как мейнфрейм System z, кэш L4 без вопросов находится на своём месте и приносит пользу всем клиентам, увеличивая пропускную способность этих машин и позволяя им работать на 98-99% загрузке процессора, поскольку как количество ядер, так и масштабы NUMA в мейнфреймах в последнее время сильно подросли.
Нет причин для того, чтобы делать кэш L4 исключительно на встроенной DRAM (как делает IBM со своими чипами) или на базе куда как более дорогой SRAM – об этом нам напоминает Рабин Сугумар, архитектор чипов из компаний Cray Research, Sun Microsystems, Oracle, Broadcom, Cavium и Marvell:
«Наши кэши L3 уже достаточно большие, — говорит Сугумар. – Так что L4 в интересующем вас случае нужно делать по другой технологии. Возможно, eDRAM или даже HBM или DRAM. В данном контексте интересным вариантом выглядит реализация кэша L4 на основе HBM, и этот кэш решает не столько проблему задержки, сколько пропускной способности. Поскольку ёмкость HBM ограничена, а пропускная способность велика, мы можем получить определённую прибавку к скорости – и в некоторых специальных случаях мы действительно видим значительное увеличение пропускной способности». Сугумар добавляет, что для довольно большого количества применений наблюдается относительно большое количество «промахов» кэша. Однако нужно подсчитать – будет ли добавление очередного уровня кэша стоить того.
Ещё один возможный вариант использования чего-то наподобие кэша L4, говорит Сугумар, это использовать локальную DRAM в качестве кэша. «У нас не ведётся никаких подобных исследований в лаборатории, но допустим, у нас на чипе есть интерфейс с высокой пропускной способностью, соединенный с общей распределённой памятью где-то на другом конце шлейфа, на расстоянии от 500 нс до 1 мкc. Тогда один из вариантов использования будет создать кэш, перемещающий эти данные из общей распределённой памяти в локальную DRAM. Можно представить работу конечного автомата, управляющего этой памятью, поэтому большую часть времени обращения будут идти к локальной DRAM, и вы сможете минимизировать количество обращений к общей распределённой DRAM».
Нам этот вариант кажется очень интересной разновидностью NUMA. Кстати, Сугумар работал над распределённой памятью для высокоскоростных параллельных систем в Sun Microsystems ещё до того, как появилась энергонезависимая память. И одна из проблем с этими различными вариантами иерархии памяти заключалась в том, что если одна из них потеряется из-за отказа сети или шины, то вся машина упадёт. «В системах с распределённой памятью приходится обрабатывать отказы сети более элегантно, и это порождает множество сложностей при проектировании».
Ещё один момент в том, что нам хочется, чтобы любой кэш высокого уровня, даже не L4, был реализован по максимуму при помощи железа и по минимуму при помощи софта. Ядрам операционок и другому ПО всегда нужно некоторое время, чтобы догнать железо, будь то добавление новых ядер, или кэшей L3 или L4, или адресуемой энергонезависимой памяти.
«В какой-то момент дополнительный уровень кэша станет неизбежностью, — говорит Джианос. – У нас появился первый уровень кэша, и в какой-то момент появился и второй. А потом мы, в конце концов, добавили третий. И когда-то у нас будет четвёртый. Вопрос только – когда и зачем. И мне кажется, что ваши наблюдения, касающиеся возможностей этого кэша, достаточно интересные. Но в Intel пока не решили, когда или зачем будут обнародовать такие вещи. Другие компании тоже изучают этот вопрос; было бы глупо не исследовать его. Рано или поздно это произойдёт, однако скоро это будет, или не очень – пока неясно».










{kind=link}
{kind=link}
Methos
бла бла бла
вся статья о том, что кеш нам нужен, или не нужен, так нужен или нет, нет или да, да или нет, нужен или не нужен?
Arris
Это просто еще один гуглоперевод ради гуглоперевода. Не ищите в нём смысл. Не найдете.