
Машинное обучение довольно сильно проникло в нашу обыденную жизнь. Некоторые уже не удивляются, когда им рассказывают про нейронные сети в их смартфонах. Одной из больших областей в этой науке являются рекомендательные системы. Они есть везде: когда вы слушаете музыку, читаете книги, смотрите сериалы или видео. Развитие этой науки происходит в компаниях гигантах, таких как YouTube, Spotify и Netfilx. Конечно же, все научные достижения в этой области публикуются как на известных конференциях NeurIPS или ICML, так и на чуть менее известной RecSys, заточенной на эту тематику. И в этой статье мы поговорим, как развивалась эта наука, какие методы применяются в рекомендациях тогда и сейчас и какая математика за всем этим стоит.

На написание данной статьи меня вдохновила работа в лаборатории StatML в Skoltech, связанная с рекомендательными системами.
Зачем и для кого эта статья
Почему это может быть важно для каждого из нас? Посмотрите на представленный список:
- Рекомендации видео: YouTube, Netlix, HBO, Amazon Prime, Disney+, Hulu, Окко
- Рекомендации аудио: Spotify, Яндекс.Музыка, Яндекс.Радио, Apple Music
- Рекомендации товаров: Amazon, Avito, LitRes, MyBook
- Рекомендации в поиске: Google, Yandex, Bing, Yahoo, Mail
- Остальные рекомендации: Booking, Twitter, Instagram, Яндекс.Дзен, Вконтакте, GitHub
Наверняка вы нашли один из сервисов, которым активно пользуетесь. Для меня важно всегда заглядывать под капот машины и узнавать, как она устроена. Поэтому мне интересно знать, что происходит, когда мне рекомендуют новое видео в YouTube.
В интернете можно встретить хорошие статьи на эту тему (например от компании Яндекс), но порой люди говорят об одном и том же разными словами и возникает много путаницы. Кроме этого, существует очень мало мест, где можно найти весь зверинец моделей сразу. Поэтому я разобрался со всеми алгоритмами, и расскажу вам про них простыми словами (или не очень). Во-первых, фокус здесь будет направлен на математическую составляющую рекомендательных систем. И, во-вторых, эта статья будет нацелена в большой степени на людей, которые имеют какое-то представление о машинном обучении. Но я надеюсь, что она будет полезна и новичкам. И конечно же, данный материал будет содержать формулы, поэтому я предполагаю, что у читателя есть некоторое представление о линейной алгебре, математическом анализе и теории оптимизации.
В реальности, конечно, все модели, о которых мы поговорим, являются лишь частью чего-то большего. Обычно используют огромные сборные модели со своей логикой, которая очень зависит от типов данных (кино, музыка, еда, одежда и т.д.). Например, есть интересная статья про такую систему.
Постановка задачи
Как и в любой другой задаче машинного обучения, задаче рекомендательной системы нужны обучающие данные. Для этого введем два множества: и — множества пользователей и товаров. А целевой переменной будем считать результат взаимодействия пользователя и товара . К примеру, это может быть рейтинг фильма, который поставил пользователь, или же покупка товара, или добавление его в избранное. В итоге обучающей выборкой будет являться такое множество:
А нашей задачей будет являться восстановить зависимость и найти такую функцию :
Чтобы было ясно, может быть целом числом от 1 до 5 (оценка от пользователя) или бинарной величиной: 1 или -1 (понравилось / не понравилось)
Виды рекомендательных систем
В литературе условно все методы делят на 3 типа:
- Content-based (CB)
- Collaborative filtering (CF)
- Hybrid recommendations
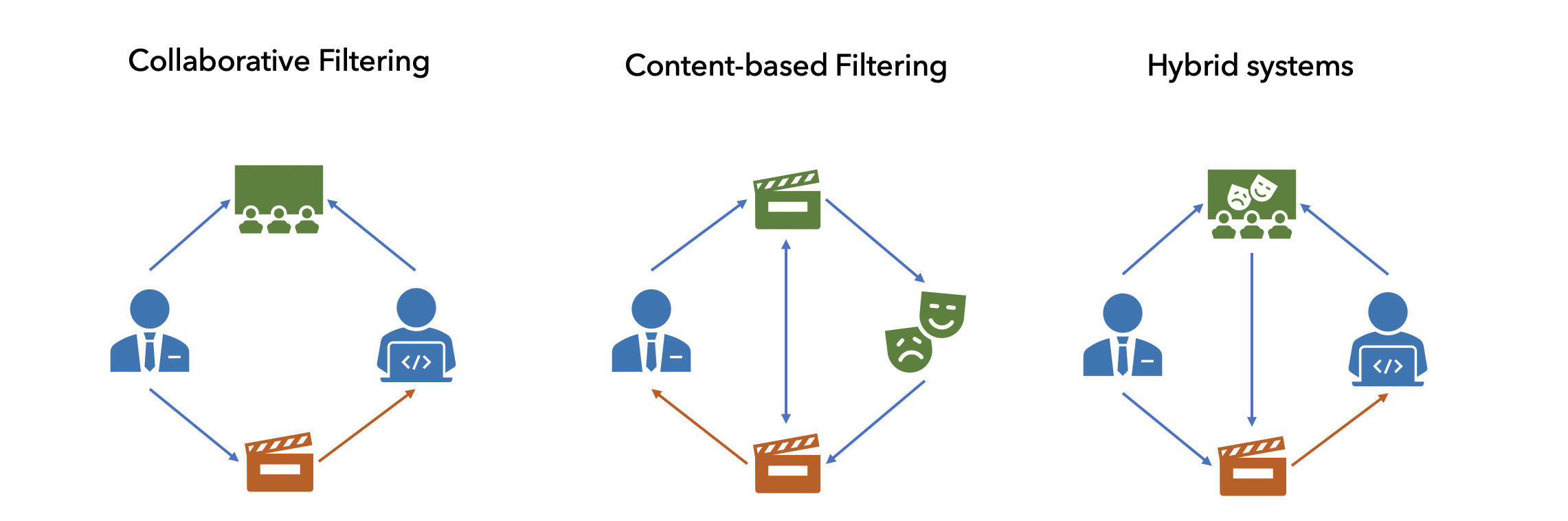
Контентные рекомендации берут всю информацию о товаре и пытаются найти похожий. Простой пример — мне понравилась комедия с Джимом Кери, поэтому мне порекомендовали другую комедию с этим актером. Признаки товаром могут быть разнообразны: для песни — сама его музыкальная дорожка, для товара в магазине — его фотография, параметры и характеристики. Чаще всего такие рекомендации тривиальны и их сможет повторить любой из нас. В таких моделях, мы так же можем использовать информацию о пользователе: пол, возраст и т.д.
Коллаборативная фильтрация не использует никакую информацию о товаре или пользователе, а строит свои рекомендации лишь на истории оценок. Ее главная задача найти какие-то скрытые связи там, где их нельзя найти обычному человеку.
А гибридные рекомендательные системы объединяют эти два подхода в себе. Практически все модели, которые используются в реальном мире, включают в себе помимо историй рекомендаций, еще и дополнительное знание о товарах и пользователях.
Поскольку материала оказалось очень много, я условно разделили все методы на Факторизационные, Графовые и Нейросетевые. В этой статье мы поговорим про первые из них. Отмечу, что в основном речь пойдет именно о коллаборативной фильтрации, но попутно я буду рассказывать про улучшение рассматриваемых моделей до гибридных. А в конце вас будет ждать приятный бонус.
Matrix Factorization

У нас был план, и мы ему следовали. Вот наш план: мы начнем с классических подходов. А далее добавив немного магии мы поговорим про их улучшения.
- Классические подходы:
- Singular Value Decomposition (SVD)
- Singular Value Decomposition with implicit feedback (SVD++)
- Collaborative Filtering with Temporal Dynamics (TimeSVD++)
- Weighted Matrix Factorization (WMF or ALS)
- Sparse Linear Methods (SLIM)
- Factorization Machines (FM)
- Вероятностные подходы:
- Probabilistic Matrix Factorization (PMF)
- Bayesian Probabilistic Matrix Factorization (BPMF)
- Bayesian Factorization Machines (BFM)
- Gaussian Process Factorization Machines (GPFM)
Singular Value Decomposition (SVD)
Начнем с самого простого и понятного метода — SVD. Мы можем записать все наши данные в матрицу размером , где , а . Для известных пар из мы запишем элемент матрицы , а все остальные приравняем к нулю. Используя SVD разложение, можно представить матрицу в виде произведения трех других: . Оставив самых больших по модулю сингулярных значений, можно сделать малораноговую аппроксимацию нашей матрицы .
Обозначим матрицу и следующим образом. Тогда матрица представляется в виде такого произведения:
Или поэлементно это можно записать:
Получается, что и — это латентные представления пользователя и товара в каких-то пространствах размерности . На самом деле мы можем представить нашу модель в конечном виде и сразу искать латентные представления товаров и пользователей. Для этого просто поговорим немного об оптимизации. В данной задаче параметрами выступают латентные вектора:
И в этом случае они будут находиться при минимизации квадратичной ошибки c учетом регуляризации:
Стоит отметить, что большинство методов, о которых пойдет речь дальше, будут минимизировать функционал, записанный в левой части. Меняться будет лишь значение . А оптимизация будет происходить известными градиентным спуском (GD) или же чередованием наименьших квадратов (ALS). Что это и о чем это хорошо рассказано в этой Habr-статье или здесь, и я не вижу смысла тут повторяться. Хотелось бы лишь отметить тот факт, что градиентный спуск работает не только дольше, но и хуже.
Сразу поговорим про улучшение этого метода (иногда вместо обычного SVD, его называют SVD). В реальности бывает так, что некоторые люди склонны завышать оценки товаров, а другие наоборот занижать. Так же и сами товары могут быть довольно популярны и менее популярны. Поэтому обычная модель SVD работает не так хорошо. Для решения этой проблемы нужно просто использовать обычное смещение (bias):
где — смещение для конкретного пользователя, — для товара, а — глобальное смещение. При этом количество параметров немного вырастет:
SVD++
В работе Factorization Meets the Neighborhood описывается новая модификация SVD модели. Но для начала поговорим про явный и неявный отклик от пользователя (explicit and implicit user feedback). Если по итогу взаимодействия между пользователем и товаром мы знаем оценку , то это считается явным откликом. В противном случае мы знаем лишь об их взаимодействии и это неявный. Авторы статьи ассоциируют каждого пользователя с двумя группами товаров: — множество товаров с явным откликом (рейтинги которых мы знаем) и — множество товаров с неявным откликом (знаем лишь о наличии взаимодействия).
Метод SVD++ использует неявный отклик и в результате модель выглядит следующим образом:
В этом случае количество параметров увеличивается:
Поскольку неявный отклик иногда бывает недоступным, множество можно заменить на , т.к. всегда выполняется . А добавку данного метода можно расценивать как рекомендации товара к товару (item-item recommendation).
Asymmetric-SVD
Вместе с SVD++ авторы статьи предлагают другую модель. Идея этого метода так же заключается в использовании неявного отклика. В результате они получают:
где
TimeSVD++
Одним из широко известных гибридных моделей является TimeSVD++. В часто используемых данных (MovieLens, Netflix) помимо историй рейтингов фильмов от пользователей существует информация о времени, когда этот рейтинг был поставлен. Отсюда возникает законный вопрос, как это использовать. В статье Collaborative Filtering with Temporal Dynamics авторы предлагают в модель SVD++ добавить зависимость от времени:
Давайте разбираться, как именно влияет время на каждое слагаемое:
Item bias: Если разделить интервал времени, когда были проставлены рейтинги на отрезки (в работе предлагают 30 частей) и добавить свои собственные параметры для каждого товара, которые выбираются в зависимости от того, в какой промежуток попала переменная :
User bias: Анализируя данные Neflix, заметили, что для каждого пользователя в среднем есть лишь 40 дней, в которые он расставлял рейтинги. Поэтому поступим как с товарами и добавим свои собственные параметры для каждого пользователя. Добавим линейную зависимость от времени — введем дополнительное слагаемое с амортизационным коэффициентом:
.
Есть и другие варианты, как добавить зависимость от времени для пользователей: Более подробно расписано в статье
User embeddings: похожий трюк мы добавим для каждой компоненты нашего латентного представления :
Weighted Matrix Factorization (WMF) & Alternating Least Squares (ALS)
Одной из главных проблем, которая есть в SVD, использование лишь явного отклика от пользователя. Это проблему частично решили в SVD++. Но есть и другой путь — Weighted Matrix Factorization (WMF). В это статье предложили почти не менять модель (), а поменять процесс обучения. Присвоим для рейтингов , которые мы не знаем (т.е. для пар ) значение равное 0. А дальше для каждой пары введем параметр , который будет отвечать за важность рейтинга . Главный посыл в том, что нельзя полностью доверять явным признакам. Ведь пользователь мог купить какой-то товар как подарок для друга. Или просмотреть следующее видео в YouTube только потому, что отошел от компьютера. Плюс ко всему, мы хотим использовать не только рейтинги, которые знаем, но и не знаем. Именно поэтому мы изменим функционал, который будем минимизировать, таким образом, чтобы учесть все что можно:
Авторы статьи предлагают такой выбор параметров: . Такой выбор отвечает главной особенности: большое значение для тех и маленькое для . Параметр константный и в этой работе при модель дала хорошие результаты.
Так же стоит отметить тот факт, что в той же работе авторы используют (ALS) для обновления параметров. И в литературе можно встретить как метод WMF, так и ALS, но это одно и то же.
Fast Alternating Least Squares
Говоря про ALS метод, нельзя не рассказать про метод eALS описанный в этой статье. Метод не меняется, а меняется лишь способ обновления параметров. За счет более умной оптимизации с использованием кеша, параметры модели можно обновлять на лету. За счет этого метод хорошо зарекомендовал себя в онлайн рекомендациях.
Кроме этого, авторы предлагают новый вид для параметров вместо предложенных в ALS методе:
с двумя новыми гиперпараметрами и , которые можно настроить на каждом наборе данных.
Sparse Linear Methods (SLIM)
В работе Sparse Linear Methods (SLIM) авторы статьи предлагают новый метод. Главной мотивацией послужило то, что SVD работает довольно долго. Поэтому они предложили простую модель основанную на идее ближайших соседей в пространстве товаров. Модель SLIM выглядит следующим образом:
Тогда параметрами в этой задаче являются только веса . Причем на эту матрицу весов мы накладываем некоторые ограничения: и . И эти веса подбираются в процессе минимизации следующего функционала:
Матрицу можно рассматривать как матрицу похожести или важности между всеми товарами.
Factorization Machines (FM)
Другой мощной моделью являются факторизационная машина, которая была предложена в работе Factorization Machines (FM). Допустим что целевая переменная зависит не только от самих признаков, но и еще от их попарного взаимодействия (полиномиальная регрессия 2-ого порядка). Тогда модель будет выглядеть следующим образом:
Оптимизация параметров происходит с помощью стохастического градиентного спуска (SGD) (более подробно можно прочитать в работе). Но до сих пор не до конца понятно, что такое и как оно связано с нашей парой . Более наглядно это будет видно на рисунке снизу. Первая часть вектора кодирует пользователя, вторая — товар. После можно добавить дополнительные признаки — историю просмотров пользователя (третья часть). Другие дополнительные признаки зависят лишь от данных и вашей креативности (жирный намек на гибридные методы).
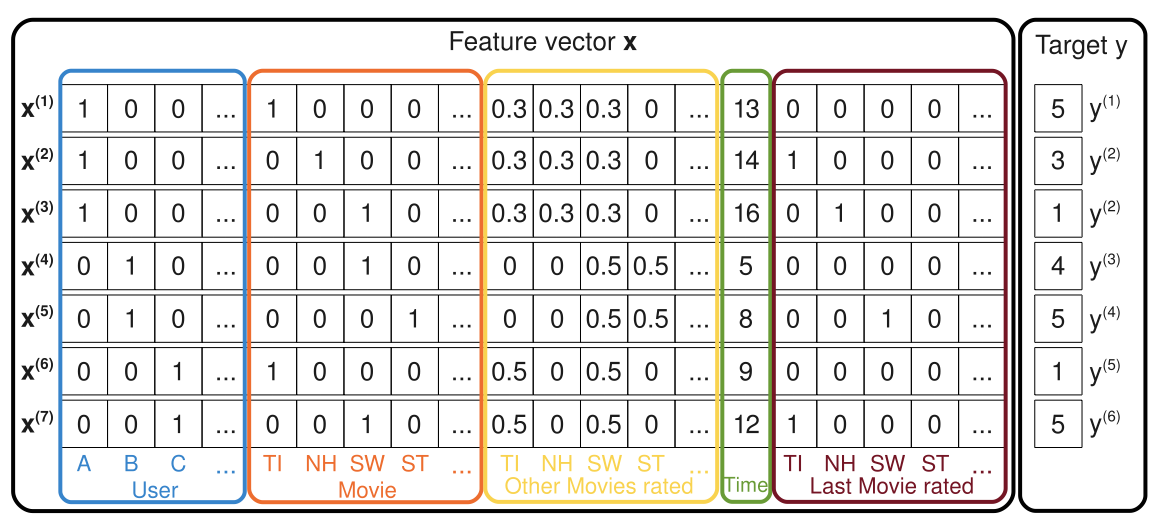
Так же авторы в этой статье показывают, что SVD, SVD++ — это лишь частные случаи FM. Например для SVD это можно получить, если обозначить:
где — символ Кронекера. Т.е. вектор состоит из нулей и двух единиц в индексах кодирующих и . Тогда в выражение для FM представится в виде:
Продолжим рассматривать картинку и увидим, что мы можем добавить абсолютно любые дополнительные признаки в переменную : время, последнюю рекомендацию. Например, у каждого фильма есть жанр, год выпуска, страна, режиссёр, сценарист, оператор и актерский состав. Все это можно добавить как признаки и использовать их в предсказании.
Probabilistic Matrix Factorization (PMF)
Дорогой читатель, хочу поздравить тебя, что ты дошел до этого момента, вот сейчас начнется самое сложное.
Другой мощной моделью считается вероятностная матричная факторизация (PMF), предложенная в этой статье. Главная идея, взять самый простой SVD: и — латентные вектора пользователей и товаров. Но в отличие от обычной модели, зададим вероятностную:
где — нормальное распределение, a — логистическая функция (сигмойда). Сделаем довольно сильное предположение, что наши пользователи и товары независимы, тогда латентные признаки будут распределены по Гауссу с нулевым средним и диагональной матрицей ковариации:
И если воспользоваться методом максимального правдоподобия (подробнее в статье) мы можем записать функционал, который будет минимизировать:
где и — регуляризационные множители. Стоит отметить, что если в обычном SVD они были гиперпараметрами, то здесь они могут подбираться автоматически.
Constrained PMF
В этой же работе последним улучшением обычного PMF является Constrained PMF. Мотивация почти та же самая, что при улучшении SVD до SVD++. Модель не меняется, за исключением того, что вместо мы используем:
где — все то же множество товаров, рейтинги которых есть у пользователя .
Bayesian Probabilistic Matrix Factorization (BPMF)
И сразу же поговорим про улучшение PMF до BPMF. Существенным недостатком PMF модели является тот факт, что мы считаем, что пользователи и товары независимые. Мы можем это исправить поменяв вероятностное распределение:
Параметры и в свою очередь берутся из распределения Гаусса-Вишарта для которых мы зададим свои гиперпараметры . Стоит сказать, что предсказание этой модели не совсем тривиальное и для более детального погружения стоит обратиться к первоисточнику.
Bayesian Factorization Machines (BFM)
Ну и конечно, один из лучших методов не может не получить приставку Bayesian, вот доказательства. Если вспомнить на секундочку обычную модель факторизационной машины, то нашими параметрами будет являться множество Ключевая идея состоит в предположении, что каждый параметр принадлежит какому-то распределению. Для этого введем дополнительное множество гиперпараметров: . После чего мы можем построить апостериорное распределение на наши параметры и с помощью некоторых хитрых техник сэмплировать из него.
Gaussian Process Factorization Machines (GPFM)
В статье про GPFM авторы решили к факторизационным машинам прикрутить гаусовские процессы. Ключевой идеей является введение специальной функции с параметрами . Причем для каждого пользователя параметры будут уникальными и для того, чтобы получить результат, нам необходимо будет лишь посчитать:
У внимательного читателя возникнет вопрос, а причем тут гаусовские процессы. Дело в том, что сама функция как раз и берется из гаусовского процесса, с некоторым ядром. И примечательнее всего, что в этот момент мы можем добавить нелинейность при использовании, к примеру, экспоненциального ядра.
Так же в работе не уходят от возможности гибридного подхода и используют дополнительные латентные вектора для контентных признаков.
На десерт: Bayesian Personalized Ranking (BPR)
В конце хотелось бы рассказать про BPR модель, которая хорошо зарекомендовала себя в "продакшене". На самом деле, BPR — это не модель, а способ оптимизации, подробнее можно прочитать в работе Bayesian Personalized Ranking. Ну а мы начнем разбираться в ней. Начнем с того, что здесь мы будем решать задачу ранжирования, когда для двух товаров и мы хотим выбрать наиболее релевантный для пользователя . Поэтому вместо пары и его рейтинга будем рассматривать тройку и результат сравнения товара с товаром ((+) если нравится больше, чем и (-) наоборот). Множество таких троек назовем . Так же введем вероятность для сравнения двух товаров. Причем результат сравнения зависит от пользователя (поэтому и есть приставка personalized в статье):
где — сигмойда, a — задается моделью. Если воспользоваться методом максимального правдоподобия (MLE), мы можем записать функционал, который будем максимизировать:
А оптимизация происходит с помощью стохастического градиентного спуска (SGD):
До сих пор мы не говорили, какую модель мы берем. И на самом деле, мы можем воспользоваться любой классической моделью, о которых мы поговорили ранее. Выберем модель SVD:
И тогда для такой модели можно вычислить частные производные по параметрам:
У BPR подхода (как и у всех методов ранжирования) есть ряд преимуществ, по сравнению с обычными методами. Последние пытаются ввести меру на товар и пользователя, что не всегда получается сделать хорошо. Методы ранжирования лишены этой проблемы в некотором роде. При этом, попарная задача (pairwise approach) обобщает задачу предсказывания рейтинга (pointwise approach). И такую задачу мы можем решать на разнообразных откликах. К примеру, мы показываем 5 товаров человеку, а он выбирает один. Тогда мы знаем, что выбранный товар ему нравится больше, чем любой из оставшихся. И последние преимущество — BPR не привязано к какой-то модели, а это лишь способ оптимизации. Поэтому, мы можем выбрать удобный нам метод или даже придумать свой.
Show must go on
В этот раз мы обсудили много Факторизационных методов в рекомендательных системах, но еще остались нетронутыми Графовые и Нейросетевые, в которых есть тоже очень много интересного.