
Заканчивался 2018-й год…
Однажды, ясным декабрьским днём, решила наша Компания приобрести новое «железо». Нет, конечно, это не случилось в одночасье. Решение было принято раньше. Намного раньше. Но, как водится, не всегда наши желания совпадают с возможностями акционеров. И денег не было, и мы держались. Но наконец-то наступил тот радостный момент, когда приобретение было одобрено на всех уровнях. Всё было хорошо, «белые воротнички» радостно аплодировали, надоело им на серверах 7-ми летней давности ежемесячно обрабатывать документы по 25 часов и они очень настойчиво просили Департамент ИТ придумать что-нибудь, чтобы подарить им больше времени для других, не менее важных дел.
Мы пообещали сокращение времени обработки документов в 3 раза, до 8 часов. Для этого выстрелили из пушки по воробьям. Этот вариант казался единственным, поскольку в нашей команде нет, и никогда не было, администратора баз данных для применения всевозможных оптимизаций запросов (DBA).
Конфигурация выбранного оборудования была, конечно, заоблачной. Это были три сервера от компании HPE — DL560 Gen10. Каждый из них мог похвастаться 4-я процессорами Intel Xeon Platinum 8164 2.0Ghz по 26 ядер, 256 DDR4 ОЗУ, а также 8 SSD 800Gb SAS (SSD 800Gb WD Ultrastar DC SS530 WUSTR6480ASS204) + 8 SSD 1,92Tb (Western Digital Ultrastar DC SS530).
Эти «железки» предназначались для кластера VMware (HA+DRS+vSAN). Который уже работал у нас почти 3 года на аналогичных серверах 7-го и 8-го поколений, тоже от компании HPE. К слову, никаких проблем не было до тех пор, пока компания HPE не отказалась от их поддержки и обновить ESXi с версии 6.0, хотя бы до 6.5, без бубна не получилось. Ну да ладно, обновить в итоге удалось. Путем изменения установочного образа, удаления из установочного образа несовместимых проблемных модулей и т.д. Это тоже подлило масла в огонь нашего желания соответствовать всему новому. Конечно, если бы не новые «фишки» vSAN, в гробу мы видели обновление всей системы с версии 6.0 до более новой, и статью писать было бы незачем, но мы легких путей не ищем же…
Значит, приобрели мы данное оборудование и решили заменить давно устаревшее. Применили последний SPP к каждому новому серверу, установили в каждый из них по две сетевые карты Ethernet 10G (одну для пользовательских сетей, а вторую — для SAN, 656596-B21 HP Ethernet 10Gb 2-port 530T). Да, в комплекте с каждым новым сервером шла сетевая карта SFP+ без модулей, но у нас сетевая инфраструктура подразумевала Ethernet (два стэка коммутаторов DELL 4032N для сетей LAN и SAN), а модулей HPE 813874-B21 у дистрибьютора HP в Москве не оказалось и мы их так и не дождались.
Когда наступила пора установки ESXi и включения новых узлов в общий датацентр VMware, случилось «чудо». Как оказалось, HPE ESXi Custom ISO версии 6.5 и ниже не предназначен для установки на новые серверы Gen10. Только «хардкор», только 6.7. И пришлось нам невольно следовать заветам «виртуальной компании».
Был создан новый кластер HA+DRS, создан кластер vSAN, всё в непреклонном соответствии с VMware HCL и данным документом. Все было настроено по «феншую» и вызывали подозрение лишь периодические «тревоги» в мониторинге vSAN о ненулевых значениях параметров в данном разделе:
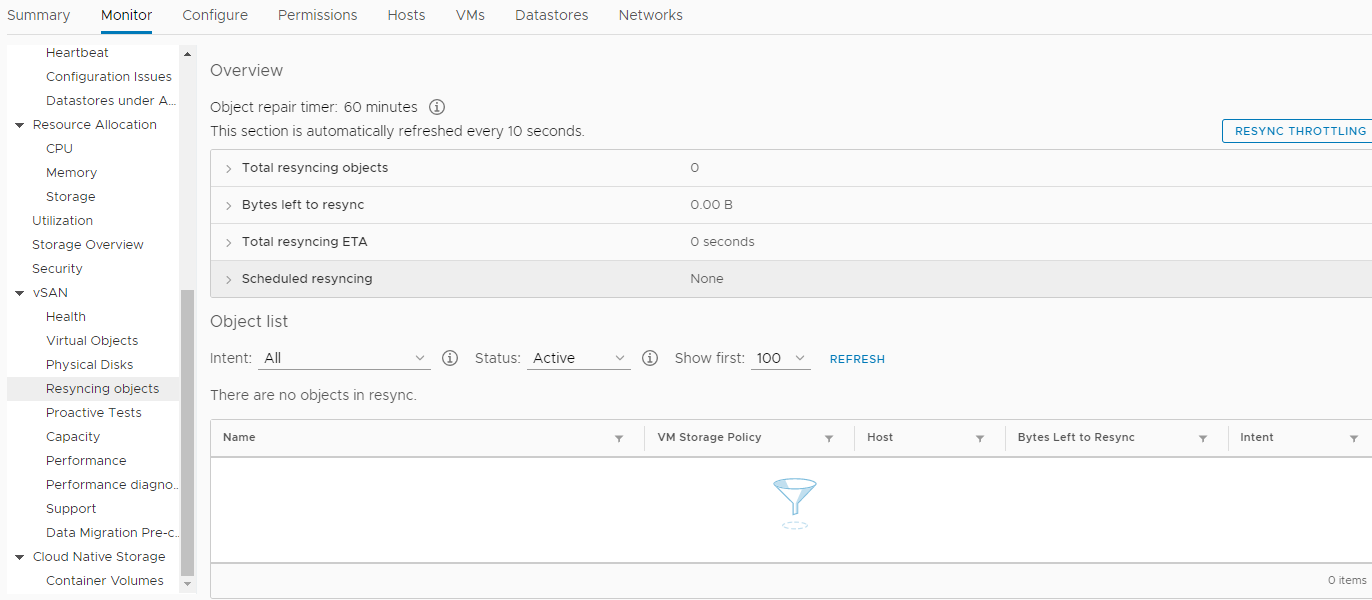
Мы, со спокойной душой, переместили все виртуальные машины (около 50 штук) на новые серверы и в новое хранилище vSAN, построенное уже на SSD дисках, проверили производительность обработки документов в новой среде (к слову, получилось сэкономить намного больше времени, чем планировали). Пока не перенесли самую тяжелую базу в новый кластер, операция, о которой упоминалось в начале статьи, заняла примерно 4 часа вместо 25-и! Это был весомый вклад в предновогоднее настроение всех участников процесса. Некоторые, наверное, начали мечтать о премии. Потом все радостно ушли на новогодние праздники.
Когда начались будни нового, 2019 года, ничто не предвещало катастрофы. Все сервисы, перенесенные на новые мощности, без преувеличения, взлетели! Только событий в разделе повторной синхронизации объектов стало намного больше. А через пару недель произошла беда. Ранним утром, практически все ключевые сервисы Компании (1с, MSSQL, SMB, Exchange и т.д.) перестали отвечать, либо начали отвечать с большой задержкой. Вся инфраструктура погрузилась в полный хаос, и никто не знал что произошло и что делать. Все виртуальные машины в vCenter выглядели «зелеными», никаких ошибок в их мониторинге не было. Перезагрузка не помогала. Более того, после перезагрузки, некоторые машины даже не смогли загрузиться, выдавая различные ошибки процесса в консоли. Казалось, Ад пришел к нам и дьявол потирал руки в предвкушении.
Находясь под давлением серьезного стресса, удалось определить источник беды. Этой проблемой оказалось распределенное хранилище vSAN. Случилось неконтролируемое повреждение данных на дисках виртуальных машин, на первый взгляд — безо всяких на то причин. На тот момент единственным решением, которое казалось рациональным, было обратиться в техническую поддержку VMware с криками: SOS, спасите-помогите!
И это решение, в последствии, и спасло Компанию от потери актуальных данных, включая почтовые ящики сотрудников, базы данных и общие файлы. В совокупности, речь идет о 30+ терабайтах информации.
Обязан отдать должное сотрудникам поддержки VMware, которые не стали «футболить» обладателя базовой подписки на техническую поддержку, а включили данный кейс в Enterpise сегмент, и процесс закрутился в круглосуточном режиме.
Что произошло дальше:
Как эта проблема проявлялась (помимо наглухо упавших сервисов организации).
Экспоненциальный рост ошибок контрольной суммы (CRC) «на ровном месте» в процессе обмена данными с дисками в режиме HBA. Как это можно проверить — в консоли каждого узла ESXi ввести следующую команду:
В результате выполнения, вы сможете увидеть ошибки CRC по каждому диску в vSAN кластере данного узла (нулевые значения не будут отображаться). Если у вас имеются положительные значения, и более того, они постоянно растут, значит появилась причина постоянно возникающих задач в разделе Monitor -> vSAN -> Resincing objects, в кластере.
Как восстанавливать диски виртуальных машин, которые никак не клонируются и не мигрируют стандартными средствами?
Кто бы мог подумать, с помощью мощной команды «cat»:
Как узнать naa.хххх… дисков в дисковых группах:
Как узнать UUIDы vSAN по каждому naa....:
И самое главное.
Проблема оказалась в некорректной работе прошивки RAID контроллера и драйвера HPE с vSAN.
Ранее, в VMware 6.7 U1, совместимая прошивка для контроллера HPE Smart Array P816i-a SR Gen10 в vSAN HCL значилась версии 1.98 (которая оказалась фатальной для нашей организации), а теперь там указана 1.65.
Более того, версия 1.99, которая решала проблему на тот момент (31 января 2019 года) уже была в закромах HPE, но они ее не передавали ни VMware ни нам, ссылаясь на отсутствие сертификации, несмотря на наши увещевания об отказе от ответственности и всё такое, мол нам главное решить проблему с хранилищем и всё.
В итоге, проблему удалось окончательно решить лишь через три месяца, когда вышла версия прошивки 1.99 для контроллера дисков!
Какие выводы я сделал?
Как говорится, обжегся на молоке, дуй на воду.
Вот и всё, ребята. Желаю вам никогда не попадать в такие жуткие ситуации.
Как вспомню, аж вздрогну!
Однажды, ясным декабрьским днём, решила наша Компания приобрести новое «железо». Нет, конечно, это не случилось в одночасье. Решение было принято раньше. Намного раньше. Но, как водится, не всегда наши желания совпадают с возможностями акционеров. И денег не было, и мы держались. Но наконец-то наступил тот радостный момент, когда приобретение было одобрено на всех уровнях. Всё было хорошо, «белые воротнички» радостно аплодировали, надоело им на серверах 7-ми летней давности ежемесячно обрабатывать документы по 25 часов и они очень настойчиво просили Департамент ИТ придумать что-нибудь, чтобы подарить им больше времени для других, не менее важных дел.
Мы пообещали сокращение времени обработки документов в 3 раза, до 8 часов. Для этого выстрелили из пушки по воробьям. Этот вариант казался единственным, поскольку в нашей команде нет, и никогда не было, администратора баз данных для применения всевозможных оптимизаций запросов (DBA).
Конфигурация выбранного оборудования была, конечно, заоблачной. Это были три сервера от компании HPE — DL560 Gen10. Каждый из них мог похвастаться 4-я процессорами Intel Xeon Platinum 8164 2.0Ghz по 26 ядер, 256 DDR4 ОЗУ, а также 8 SSD 800Gb SAS (SSD 800Gb WD Ultrastar DC SS530 WUSTR6480ASS204) + 8 SSD 1,92Tb (Western Digital Ultrastar DC SS530).
Эти «железки» предназначались для кластера VMware (HA+DRS+vSAN). Который уже работал у нас почти 3 года на аналогичных серверах 7-го и 8-го поколений, тоже от компании HPE. К слову, никаких проблем не было до тех пор, пока компания HPE не отказалась от их поддержки и обновить ESXi с версии 6.0, хотя бы до 6.5, без бубна не получилось. Ну да ладно, обновить в итоге удалось. Путем изменения установочного образа, удаления из установочного образа несовместимых проблемных модулей и т.д. Это тоже подлило масла в огонь нашего желания соответствовать всему новому. Конечно, если бы не новые «фишки» vSAN, в гробу мы видели обновление всей системы с версии 6.0 до более новой, и статью писать было бы незачем, но мы легких путей не ищем же…
Значит, приобрели мы данное оборудование и решили заменить давно устаревшее. Применили последний SPP к каждому новому серверу, установили в каждый из них по две сетевые карты Ethernet 10G (одну для пользовательских сетей, а вторую — для SAN, 656596-B21 HP Ethernet 10Gb 2-port 530T). Да, в комплекте с каждым новым сервером шла сетевая карта SFP+ без модулей, но у нас сетевая инфраструктура подразумевала Ethernet (два стэка коммутаторов DELL 4032N для сетей LAN и SAN), а модулей HPE 813874-B21 у дистрибьютора HP в Москве не оказалось и мы их так и не дождались.
Когда наступила пора установки ESXi и включения новых узлов в общий датацентр VMware, случилось «чудо». Как оказалось, HPE ESXi Custom ISO версии 6.5 и ниже не предназначен для установки на новые серверы Gen10. Только «хардкор», только 6.7. И пришлось нам невольно следовать заветам «виртуальной компании».
Был создан новый кластер HA+DRS, создан кластер vSAN, всё в непреклонном соответствии с VMware HCL и данным документом. Все было настроено по «феншую» и вызывали подозрение лишь периодические «тревоги» в мониторинге vSAN о ненулевых значениях параметров в данном разделе:
Мы, со спокойной душой, переместили все виртуальные машины (около 50 штук) на новые серверы и в новое хранилище vSAN, построенное уже на SSD дисках, проверили производительность обработки документов в новой среде (к слову, получилось сэкономить намного больше времени, чем планировали). Пока не перенесли самую тяжелую базу в новый кластер, операция, о которой упоминалось в начале статьи, заняла примерно 4 часа вместо 25-и! Это был весомый вклад в предновогоднее настроение всех участников процесса. Некоторые, наверное, начали мечтать о премии. Потом все радостно ушли на новогодние праздники.
Когда начались будни нового, 2019 года, ничто не предвещало катастрофы. Все сервисы, перенесенные на новые мощности, без преувеличения, взлетели! Только событий в разделе повторной синхронизации объектов стало намного больше. А через пару недель произошла беда. Ранним утром, практически все ключевые сервисы Компании (1с, MSSQL, SMB, Exchange и т.д.) перестали отвечать, либо начали отвечать с большой задержкой. Вся инфраструктура погрузилась в полный хаос, и никто не знал что произошло и что делать. Все виртуальные машины в vCenter выглядели «зелеными», никаких ошибок в их мониторинге не было. Перезагрузка не помогала. Более того, после перезагрузки, некоторые машины даже не смогли загрузиться, выдавая различные ошибки процесса в консоли. Казалось, Ад пришел к нам и дьявол потирал руки в предвкушении.
Находясь под давлением серьезного стресса, удалось определить источник беды. Этой проблемой оказалось распределенное хранилище vSAN. Случилось неконтролируемое повреждение данных на дисках виртуальных машин, на первый взгляд — безо всяких на то причин. На тот момент единственным решением, которое казалось рациональным, было обратиться в техническую поддержку VMware с криками: SOS, спасите-помогите!
И это решение, в последствии, и спасло Компанию от потери актуальных данных, включая почтовые ящики сотрудников, базы данных и общие файлы. В совокупности, речь идет о 30+ терабайтах информации.
Обязан отдать должное сотрудникам поддержки VMware, которые не стали «футболить» обладателя базовой подписки на техническую поддержку, а включили данный кейс в Enterpise сегмент, и процесс закрутился в круглосуточном режиме.
Что произошло дальше:
- Технической поддержке VMware были поставлены два главных вопроса: как восстановить данные и как решить проблему «фантомного» повреждения данных в дисках виртуальных машин в «боевом» кластере vSAN. Кстати, данные некуда было восстанавливать, поскольку дополнительное хранилище было занято резервными копиями и разворачивать «боевые» службы было просто некуда.
- Пока я, совместными усилиями с VMware, пытался собрать воедино «поврежденные» объекты в кластере vSAN, мои коллеги в срочном порядке добывали новое хранилище, способное вместить все 30+ терабайт данных Компании.
- Меня ждали пять, почти бессонных ночей, когда сотрудники круглосуточной поддержки VMware из трех часовых поясов спрашивали меня, почему их встречаю лишь я и беспокоились насчет эффективности такого подхода, мол можно еще больше «накосячить» и совершить много лишних ошибок из-за сверх-сверх нормативного рабочего дня. Но ведь наши реалии вряд ли соответствуют западному пониманию, да?
- Я обзавелся готовыми инструкциями в случае повторения данной ситуации.
- Пришло понимание, где «собака зарыта» в данной проблеме.
- Были восстановлены все виртуальные машины на появившееся благодаря подвигу коллег хранилище, кроме пары несущественных, которые были «воскрешены» из резервных копий на теперь доступное дисковое пространство.
- Пришлось временно (на пару дней) пожертвовать работоспособностью почты, ради дополнительных 6 терабайт свободного пространства в хранилище, чтобы запустить ключевые сервисы, от которых зависел доход Компании.
- Сохранены «на память» тысячи строк чата с англоязычными коллегами из VMware, вот коротенькая выдержка из наших разговоров:
I understood that you are now migrating all the VMs out of vSAN datastore.
May I know, how the migration task is going on.? How many VMs left and how much time is expected to migrate the remaining VMs. ?
There are 6 vms still need to be migrated. 1 of them is fail so far.
How much time is expected to complete the migration for the working VMs..?
I think atleast 2-3 hours
ok
Can you please SSH to vCenter server ?
you on it
/localhost/Datacenter ###CLUB/computers/###Cluster> vsan.check_state .
2019-02-02 05:22:34 +0300: Step 1: Check for inaccessible vSAN objects
Detected 3 objects to be inaccessible
Detected 7aa2265c-6e46-2f49-df40-20677c0084e0 on esxi-dl560-gen10-2.####.lan to be inaccessible
Detected 99c3515c-bee0-9faa-1f13-20677c038dd8 on esxi-dl560-gen10-3.####.lan to be inaccessible
Detected f1ca455c-d47e-11f7-7e90-20677c038de0 on esxi-dl560-gen10-1.####.lan to be inaccessible
2019-02-02 05:22:34 +0300: Step 2: Check for invalid/inaccessible VMs
Detected VM 'i.#####.ru' as being 'inaccessible'
2019-02-02 05:22:34 +0300: Step 3: Check for VMs for which VC/hostd/vmx are out of sync
Did not find VMs for which VC/hostd/vmx are out of sync
/localhost/Datacenter ###CLUB/computers/###Cluster>
Thank you
second vm with issues: sd.####.ruКак эта проблема проявлялась (помимо наглухо упавших сервисов организации).
Экспоненциальный рост ошибок контрольной суммы (CRC) «на ровном месте» в процессе обмена данными с дисками в режиме HBA. Как это можно проверить — в консоли каждого узла ESXi ввести следующую команду:
while true; do clear; for disk in $(localcli vsan storage list | grep -B10 'ity Tier: tr' |grep "VSAN UUID"|awk '{print $3}'|sort -u);do echo ==DISK==$disk====;vsish -e get /vmkModules/lsom/disks/$disk/checksumErrors | grep -v ':0';done; sleep 3; doneВ результате выполнения, вы сможете увидеть ошибки CRC по каждому диску в vSAN кластере данного узла (нулевые значения не будут отображаться). Если у вас имеются положительные значения, и более того, они постоянно растут, значит появилась причина постоянно возникающих задач в разделе Monitor -> vSAN -> Resincing objects, в кластере.
Как восстанавливать диски виртуальных машин, которые никак не клонируются и не мигрируют стандартными средствами?
Кто бы мог подумать, с помощью мощной команды «cat»:
1. cd в директорию виртуальной машины на vSAN
[root@esxi-dl560-gen10-1:~] cd /vmfs/volumes/vsanDatastore/estaff
2. grep vmdk объектов для получения их uuid
[root@esxi-dl560-gen10-1:/vmfs/volumes/vsan:52f53dfd12dddc84-f712dbefac32cd1a/2636a75c-e8f1-d9ca-9a00-20677c0084e0] grep vsan *vmdk
estaff.vmdk:RW 10485760 VMFS "vsan://3836a75c-d2dc-5f5d-879c-20677c0084e0"
estaff_1.vmdk:RW 41943040 VMFS "vsan://3736a75c-e412-a6c8-6ce4-20677c0084e0"
[root@esxi-dl560-gen10-1:/vmfs/volumes/vsan:52f53dfd12dddc84-f712dbefac32cd1a/2636a75c-e8f1-d9ca-9a00-20677c0084e0]
3. создать директорию для VM в хранилище, куда восстанавливаем:
mkdir /vmfs/volumes/POWERVAULT/estaff
4. Скопировать туда vmx и дескрипторы
cp *vmx *vmdk /vmfs/volumes/POWERVAULT/estaff
5. начать копировать данные с помощью средства, которому наплевать на их целостность ^_^
/usr/lib/vmware/osfs/bin/objtool open -u 3836a75c-d2dc-5f5d-879c-20677c0084e0; sleep 1; cat /vmfs/devices/vsan/3836a75c-d2dc-5f5d-879c-20677c0084e0 >> /vmfs/volumes/POWERVAULT/estaff/estaff-flat.vmdk
6. cd в директорию назначения:
cd /vmfs/volumes/POWERVAULT/estaff
7. поменять в дескрипторе - estaff.vmdk путь к файлу самого диска
[root@esxi-dl560-gen10-1:/tmp] cat estaff.vmdk
# Disk DescriptorFile
version=4
encoding="UTF-8"
CID=a7bb7cdc
parentCID=ffffffff
createType="vmfs"
# Extent description
RW 10485760 VMFS "vsan://3836a75c-d2dc-5f5d-879c-20677c0084e0" <<<<< вот тут меняем на "estaff-flat.vmdk"
# The Disk Data Base
#DDB
ddb.adapterType = "ide"
ddb.deletable = "true"
ddb.geometry.cylinders = "10402"
ddb.geometry.heads = "16"
ddb.geometry.sectors = "63"
ddb.longContentID = "6379fa7fdf6009c344bd9a64a7bb7cdc"
ddb.thinProvisioned = "1"
ddb.toolsInstallType = "1"
ddb.toolsVersion = "10252"
ddb.uuid = "60 00 C2 92 c7 97 ca ae-8d da 1c e2 3c df cf a5"
ddb.virtualHWVersion = "8"
[root@esxi-dl560-gen10-1:/tmp]Как узнать naa.хххх… дисков в дисковых группах:
[root@esxi-dl560-gen10-1:/vmfs/volumes] vdq -Hi
Mappings:
DiskMapping[0]:
SSD: naa.5000c5003024eb43
MD: naa.5000cca0aa0025f4
MD: naa.5000cca0aa00253c
MD: naa.5000cca0aa0022a8
MD: naa.5000cca0aa002500
DiskMapping[2]:
SSD: naa.5000c5003024eb47
MD: naa.5000cca0aa002698
MD: naa.5000cca0aa0029c4
MD: naa.5000cca0aa002950
MD: naa.5000cca0aa0028cc
DiskMapping[4]:
SSD: naa.5000c5003024eb4f
MD: naa.5000c50030287137
MD: naa.5000c50030287093
MD: naa.5000c50030287027
MD: naa.5000c5003024eb5b
MD: naa.5000c50030287187
Как узнать UUIDы vSAN по каждому naa....:
[root@esxi-dl560-gen10-1:/vmfs/volumes] localcli vsan storage list | grep -B15 'ity Tier: tr' | grep -E '^naa|VSAN UUID'
naa.5000cca0aa002698:
VSAN UUID: 52247b7d-fed5-a2f2-a2e8-5371fa7ef8ed
naa.5000cca0aa0029c4:
VSAN UUID: 52309c55-3ecc-3fe8-f6ec-208701d83813
naa.5000c50030287027:
VSAN UUID: 523d7ea5-a926-3acd-2d58-0c1d5889a401
naa.5000cca0aa0022a8:
VSAN UUID: 524431a2-4291-cb49-7070-8fa1d5fe608d
naa.5000c50030287187:
VSAN UUID: 5255739f-286c-8808-1ab9-812454968734
naa.5000cca0aa0025f4: <<<<<<<
VSAN UUID: 52b1d17e-02cc-164b-17fa-9892df0c1726
naa.5000cca0aa00253c:
VSAN UUID: 52bd28f3-d84e-e1d5-b4dc-54b75456b53f
naa.5000cca0aa002950:
VSAN UUID: 52d6e04f-e1af-cfb2-3230-dd941fd8a032
naa.5000c50030287137:
VSAN UUID: 52df506a-36ea-f113-137d-41866c923901
naa.5000cca0aa002500:
VSAN UUID: 52e2ce99-1836-c825-6600-653e8142e10f
naa.5000cca0aa0028cc:
VSAN UUID: 52e89346-fd30-e96f-3bd6-8dbc9e9b4436
naa.5000c50030287093:
VSAN UUID: 52ecacbe-ef3b-aa6e-eba3-6e713a0eb3b2
naa.5000c5003024eb5b:
VSAN UUID: 52f1eecb-befa-12d6-8457-a031eacc1cabИ самое главное.
Проблема оказалась в некорректной работе прошивки RAID контроллера и драйвера HPE с vSAN.
Ранее, в VMware 6.7 U1, совместимая прошивка для контроллера HPE Smart Array P816i-a SR Gen10 в vSAN HCL значилась версии 1.98 (которая оказалась фатальной для нашей организации), а теперь там указана 1.65.
Более того, версия 1.99, которая решала проблему на тот момент (31 января 2019 года) уже была в закромах HPE, но они ее не передавали ни VMware ни нам, ссылаясь на отсутствие сертификации, несмотря на наши увещевания об отказе от ответственности и всё такое, мол нам главное решить проблему с хранилищем и всё.
В итоге, проблему удалось окончательно решить лишь через три месяца, когда вышла версия прошивки 1.99 для контроллера дисков!
Какие выводы я сделал?
- У нас есть дополнительное хранилище (помимо обязательных резервных копий), на которое в случае чего можно мигрировать всем колхозом.
- Не буду покупать самое свежее железо! Лучше годик подождать.
- Не буду использовать всё доступное пространство ради «хотелок» бизнеса, буду начинать «ныть» о покупке новых «хранилок» сразу после того, как останется менее 30% свободного пространства на всех доступных «железках».
- HPE, в лице местного представителя, так и не признала свою ошибку и ничем нам не помогла.
- Я считаю, что вина в случившемся лежит полностью на:
- HPE -эта компания показала во всей красе качество своей поддержки в критической ситуации. И в целом, количество багов в оборудовании Enterprise сегмента заставляет меня тревожиться за наше будущее. Конечно, это лишь моё мнение, и оно ни к чему не подталкивает).
- Мне — не предусмотрел ситуацию, когда может понадобиться дополнительное дисковое пространство для размещения копий всех серверов Компании в случае нештатных ситуаций.
- Дополнительно, в свете всего произошедшего, для VMware я больше не буду покупать железки для крупных компаний, каких-либо вендоров, отличных от DELL. Почему, потому что DELL, насколько мне известно, приобрела VMware, и теперь интеграция железа и софта в данном направлении ожидается максимально тесная.
Как говорится, обжегся на молоке, дуй на воду.
Вот и всё, ребята. Желаю вам никогда не попадать в такие жуткие ситуации.
Как вспомню, аж вздрогну!





















BobbieZi
Теперь в мире есть ещё один мудрый и образованый IT директор…