
Прим. перев.: Содержимое этой статьи не совсем типично для нашего блога. Однако, как многим известно, etcd находится в самом сердце Kubernetes, из-за чего данное исследование, проведённое независимым консультантом в области надёжности, оказалось интересным и в среде инженеров, эксплуатирующих данную систему. Кроме того, оно интересно в разрезе того, как Open Source-проекты, уже зарекомендовавшие себя в production, совершенствуются даже на таком, весьма «низком», уровне.

Хранилище пар «ключ-значение» (KV) etcd представляет собой распределённую базу данных, основанную на алгоритме консенсуса Raft. В ходе анализа, проведенного в 2014 году, мы обнаружили, что etcd 0.4.1 по умолчанию была подвержена так называемым stale reads (операциям чтения, возвращающим старое, неактуальное значение из-за запаздывания синхронизации — прим. перев.). Мы решили вернуться к etcd (в этот раз — к версии 3.4.3), чтобы снова детально оценить ее потенциал в области надежности и безопасности.
Мы обнаружили, что операции с парами «ключ-значение» строго сериализуемы и что процессы-наблюдатели (watches) доставляют каждое изменение ключа по порядку. Однако блокировки (locks) в etcd принципиально небезопасны, а связанные с ними риски усугубляются багом, в результате которого не проверяется актуальность lease после ожидания блокировки. Комментарий разработчиков etcd к нашему отчету вы можете прочитать в блоге проекта.
Спонсором исследования выступил фонд Cloud Native Computing Foundation (CNCF), входящий в The Linux Foundation. Оно проводилось в полном соответствии с этической политикой Jepsen.
KV-хранилище etcd — это распределённая система, предназначенная для использования в качестве основы для координации. Как Zookeeper и Consul, etcd хранит небольшие объемы редко обновляемых состояний (по умолчанию до 8 Гб) в виде карты key-value и обеспечивает строго сериализуемые чтение, запись и микротранзакции по всему хранилищу данных, а также примитивы координации вроде блокировок (locks), отслеживания (watches) и выбора лидера. Многие распределённые системы, такие как Kubernetes и OpenStack, используют etcd для хранения метаданных кластеров, для координации согласованных представлений о данных, выбора лидера и т.п.
В 2014 мы уже проводили оценку etcd 0.4.1. Тогда мы обнаружили, что по умолчанию оно подвержено stale reads из-за оптимизации. В то время, как в работе о принципах Raft обсуждается необходимость разбиения операций чтения на потоки и их пропускания через систему консенсуса для обеспечения жизнеспособности, etcd выполняло чтение на любом лидере локально, не проверяя наличие более актуального состояния на более новом лидере. Команда разработчиков etcd внедрила опциональный флаг кворума, а в API etcd версии 3.0 по умолчанию появилась линеаризуемость для всех операций кроме операций отслеживания.
API etcd 3.0 концентрируется на плоской карте KV, где ключи и значения представляют собой непрозрачные (opaque) байтовые массивы. С помощью диапазонных запросов можно имитировать иерархические ключи. Пользователи могут читать, писать и удалять ключи, а также отслеживать поток обновлений для одного ключа или диапазона ключей. Инструментарий etcd дополняют lease'ы (переменные объекты с ограниченным временем жизни, которые поддерживаются в активном состоянии heartbeat-запросами клиента), lock'и (выделенные именованные объекты, привязанные к lease'ам) и выбор лидеров.
В версии 3.0 etcd предлагает ограниченный транзакционный API для атомарных операций со множеством ключей. В этой модели транзакция представляет собой некое условное выражение с предикатом, истинной ветвью и ложной ветвью. В качестве предиката может выступать конъюнкция нескольких поключевых сравнений: равенство или различные неравенства, по версиям одного ключа, глобальной ревизии etcd или текущему значению ключа. Истинная и ложная ветви могут включать множественные операции чтения и записи; все они применяются атомарно в зависимости от результата оценки предиката.
По состоянию на октябрь 2019-го в документации к API etcd заявляется, что «все вызовы API демонстрируют последовательную согласованность — самую сильную форму гарантии согласованности, доступную в распределённых системах». Это не так: последовательная согласованность строго слабее линеаризуемости, а линеаризуемость определённо достижима в распределённых системах. Далее в документации заявляется, что «в ходе операции чтения etcd не гарантирует передачу [самого недавнего (измеренного внешними часами по итогам завершения запроса)] доступного на любом представителе кластера значения». Это также слишком консервативное утверждение: если etcd обеспечивает линеаризуемость, операции чтения всегда связаны с самым последним зафиксированным состоянием в порядке линеаризации.
В документации также утверждается, что etcd гарантирует сериализуемую изоляцию: все операции (даже те, которые затрагивают несколько ключей) выполняются в некотором общем порядке. Авторы описывают сериализуемую изоляцию как «самый сильный уровень изоляции, доступный в распределённых системах». Это (в зависимости от того, что вы понимаете под «уровнем изоляции») также неверно; строгая сериализуемость сильнее простой сериализуемости, при этом первая также достижима в распределённых системах.
В документации говорится, что все операции (кроме отслеживания) в etcd линеаризуемы по умолчанию. При этом линеаризуемость определяется как согласованность со слабо синхронизированными глобальными часами. Следует отметить, что такое определение не только несовместимо с определением линеаризуемости Херлихи и Винга (Herlihy & Wing), но также подразумевает нарушение причинности: узлы с опережающим часами будут пытаться считывать результаты операций, которые ещё даже не начинались. Мы предполагаем, что etcd всё же не является машиной времени, и, поскольку в его основе лежит алгоритм Raft, должно применяться общепринятое определение линеаризуемости.
Поскольку KV-операции в etcd сериализуемы и линеаризуемы, мы считаем, что на самом деле etcd по умолчанию обеспечивает строгую сериализацию. Это имеет смысл, поскольку все ключи etcd находятся в единой машине состояний, а полную упорядоченность всех операции на этой машине состояний обеспечивает Raft. По сути, весь набор данных etcd представляет собой единый линеаризуемый объект.
Опциональный флаг
Для создания набора тестов мы воспользовались соответствующей библиотекой Jepsen. Анализу подверглась версия etcd 3.4.3 (самая свежая по состоянию на октябрь'19), работающая на кластерах Debian Stretch, состоящих из 5 узлов. Мы внедрили ряд неисправностей в эти кластеры, включая сетевые разделения, изолирующие отдельные узлы, разделение кластера на большинство и меньшинство, а также нетранзитивные разбиения с перекрывающимся большинством. «Роняли» и приостанавливали случайные подмножества узлов, а также умышленно выводили из строя лидеров. Вводили временные искажения до нескольких сотен секунд, как на многосекундных интервалах, так и на миллисекундных (быстрое «мерцание»). Поскольку etcd поддерживает динамическое изменение числа компонентов, мы случайным образом добавляли и удаляли узлы во время тестирования.
Тестовые нагрузки включали регистры, наборы и транзакционные тесты для проверки операций над KV, а также специализированные нагрузки для lock'ов и watch'ей.
Для оценки надёжности etcd при KV-операциях был разработан тест с регистрами, в ходе которого производились случайные операции чтения, записи, сравнения/установки (compare-and-set) над единичными ключами. Оценку результатов проводили с помощью инструмента для проверки линеаризуемости Knossos с использованием модели регистра сравнения/установки и информации о версиях.
Для количественной оценки stale reads был разработан тест, использовавший транзакцию сравнения и установки (compare-and-set) для чтения набора целых чисел из одного ключа и последующего добавления значения к этому набору. В процессе теста мы также проводили параллельное считывание всего набора. После завершения испытания анализировались результаты на предмет наличия случаев, когда элемент, о котором было известно, что он должен присутствовать в наборе, отсутствовал в результатах чтения. Эти случаи использовались для количественной оценки stale reads и потерянных обновлений.
Для проверки строгой сериализуемости был разработан append-тест, в ходе которого транзакции параллельно читали и добавляли значения к спискам, состоящим из уникальных наборов целых чисел. Каждый список хранился в одном ключе etcd, и проводились добавления в рамках каждой транзакции, читая каждый ключ, который нужно было изменить в одной транзакции, а затем эти ключи записывались и выполнялись чтения во второй транзакции, которая защищалась, чтобы гарантировать, что ни один записанный ключ не изменился с момента первого чтения. В конце теста мы построили график зависимости между транзакциями на основе приоритета в реальном времени и отношений операций чтения и добавления. Проверка этого графика на наличие циклов позволила определить, были ли операции строго сериализуемыми.
В то время как etcd запрещает транзакциям записывать один и тот же ключ множество раз, можно создавать транзакции, предусматривающие до одной записи на каждый ключ. Мы также убедились, что операции чтения в рамках одной транзакции отражали предыдущие операции записи из той же транзакции.
Как координационный сервис, etcd обещает встроенную поддержку распределённой блокировки. Мы исследовали эти блокировки двумя способами. Сначала генерировали рандомизированные запросы lock и unlock, получая lease для каждого lock'а и оставляя его открытым с помощью встроенной в Java-клиент etcd
Для более практического теста (и получения количественной оценки частоты сбоя блокировок) мы использовали lock'и etcd для организации взаимного исключения при внесении обновлений в набор в in-memory и искали потерянные обновления в этом наборе. Этот тест позволил нам прямым образом подтвердить, могут ли системы, использующие etcd как мьютекс, безопасно обновлять внутреннее состояние.
Третий вариант lock-теста задействовал guard'ы на lease key для модификации набора, хранящегося в etcd.
Чтобы проверить, что watch'и предоставляют информацию о каждом обновлении ключа, в рамках теста создавался один ключ и ему вслепую присваивались уникальные целочисленные значения. Тем временем клиенты совместно отслеживали этот ключ по нескольку секунд за раз. Каждый раз после инициации watch'а клиент начинал с той ревизии, на которой остановился в прошлый раз.
В конце этого процесса мы убедились, что каждый клиент наблюдал одну и ту же последовательность изменений ключа.
При отслеживании (watching) ключа клиенты могут указать начальную ревизию, которая является «опциональной ревизией, с которой (включительно) начинается слежение». Если пользователь желает увидеть каждую операцию с неким ключом, он может указать первую ревизию etcd. Что это за ревизия? Модель данных и глоссарий не дают ответа на этот вопрос; ревизии описываются как монотонно возрастающие 64-битные счетчики, но непонятно, начинает ли etcd с 0 или 1. Разумно предположить, что отсчет идет с нуля (так, на всякий случай).
Увы, это неправильно. Запрос 0-ой ревизии приводит к тому, что etcd начинает транслировать обновления, начиная с текущей ревизии на сервере плюс один, а не с самой первой. Запрос 1-ой ревизии выдаёт все изменения. Такое поведение нигде не задокументировано.
Мы считаем, что на практике эта тонкость вряд ли приведет к проблемам в production, поскольку большинство кластеров не задерживаются на первой ревизии. Кроме того, etcd все равно сжимает историю с течением времени, поэтому в реальных условиях приложения, скорее всего, в любом случае не требуют чтения всех версий, начиная с 1-ой ревизии. Подобное поведение оправдано, однако ему не помешало бы соответствующее описание в документации.
Документация к API для lock'ов гласит, что заблокированный ключ «может использоваться совместно с транзакциями для гарантирования того, что обновления в etcd происходят только тогда, когда сохраняется принадлежность блокировки». Странно, но в ней не приводятся какие-либо гарантии для самих блокировок и не объясняется их предназначение.
Впрочем, в других материалах maintainer'ы etcd все же делятся информацией об использовании блокировок. Например, в анонсе о выходе etcd 3.2 описывается применение
Именно такой пример приводится в
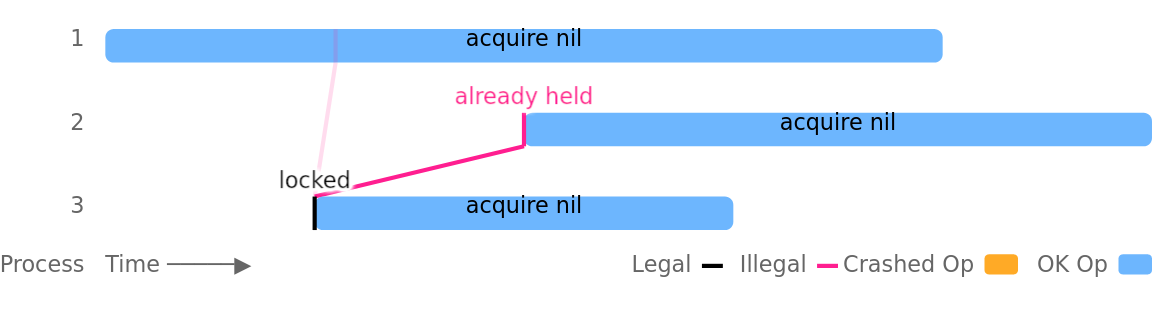
Увы, это небезопасно, поскольку позволяет нескольким клиентам одновременно удерживать одну и ту же блокировку. Проблема усугубляется приостановкой процессов, падениями или разделениями сети, однако она также может возникать во вполне здоровых кластерах без каких-либо внешних сбоев. Например, в этом тестовом прогоне процесс номер 3 успешно устанавливает блокировку, а процесс 1 параллельно получает ту же самую блокировку ещё до того, как у процесса 3 появляется возможность её снять:
Сильнее всего нарушение мьютекса было заметно на lease'ах с коротким TTL: TTL в 1, 2 и 3 секунды были не в состоянии обеспечить взаимное исключение спустя всего несколько минут тестирования (даже в здоровых кластерах). Приостановки процессов и сетевые разбиения ещё быстрее приводили к проблемам.
В одном из вариантов нашего lock-теста мьютексы etcd использовались для защиты совместных обновлений набора целых чисел (как и предлагает документация etcd). Каждое обновление считывало текущее значение выборки in-memory, и, примерно через одну секунду, записывало эту коллекцию обратно с добавлением уникального элемента. При lease'ах с двухсекундным TTL, пяти параллельных процессах и приостановке процесса каждые пять секунд, мы смогли вызвать устойчивую потерю примерно 18 % подтвержденных обновлений.
Эта проблема усугублялась внутренним механизмом работы с блокировками в etcd. Если клиент дожидался снятия блокировки другим клиентом, терял свой lease, и после этого блокировка снималась, сервер не перепроверял lease, чтобы убедиться, что она по-прежнему действительна, прежде чем проинформировать клиента, что блокировка теперь за ним.
Включение дополнительной проверки lease, а также выбор более длительных TTL и внимательная настройка выборных (election) таймаутов позволят снизить частоту возникновения этой проблемы. Однако полностью устранить нарушения мьютексов не получится, поскольку распределённые блокировки фундаментально небезопасны в асинхронных системах. Д-р Martin Kleppmann убедительно описывает это в своей статье о распределённых блокировках. По его словам, службы блокировки обязаны приносить в жертву правильность, чтобы поддерживать жизнеспособность в асинхронных системах: если процесс падает, контролируя блокировку, службе блокировки нужен некий способ, чтобы принудительно снять блокировку. Однако если процесс на самом деле не упал, а просто медленно работает или временно недоступен, снятие блокировки может привести к тому, что она будет удерживаться в нескольких местах одновременно.
Но даже если распределённая служба блокировки воспользуется, скажем, неким магическим детектором сбоев и на самом деле сможет гарантировать взаимное исключение, в случае некоторого нелокального ресурса её использование всё равно будет небезопасным. Допустим, процесс А посылает сообщение базе данных D, удерживая блокировку. После чего процесс А падает, а процесс B получает блокировку и тоже посылает сообщение базе D. Проблема в том, что сообщение от процесса А (из-за асинхронности) может прийти после сообщения от процесса B, нарушив взаимное исключение, которое была призвана обеспечить блокировка.
Чтобы предотвратить эту проблему, необходимо полагаться на то, что сама система хранения будет поддерживать корректность транзакций или, если служба блокировки предоставляет такой механизм, использовать «заградительный» (fencing) токен, который будет включаться во все операции, производимые держателем блокировки. Он позволит гарантировать, что никакие операции предыдущего держателя блокировки внезапно не возникнут между операциями текущего владельца блокировки. Например, в службе блокировки Chubby от Google подобные токены зовутся sequencers. В etcd можно использовать ревизию ключа блокировки в качестве глобально упорядоченного заградительного токена.
Кроме того, ключи блокировки в etcd можно использовать для защиты транзакционных обновлений в самой etcd. Проверяя в рамках транзакции версию ключа блокировки, пользователи могут предотвратить транзакцию, если блокировка уже не удерживается (т.е. версия lock-ключа больше нуля). В наших тестах подобный подход позволил успешно изолировать операции чтения-изменения-записи, в которых запись была единственной транзакцией, защищенной блокировкой. Этот подход обеспечивает изоляцию, аналогичную заградительным токенам, но (как и заградительные токены) не гарантирует атомарность: процесс может упасть или потерять мьютекс во время обновления, состоящего из множества операций, оставив etcd в логически противоречивом состоянии.
Итоги работ в issues проекта:
В наших тестах etcd 3.4.3 оправдал ожидания в отношении KV-операций: мы наблюдали строго сериализуемую согласованность операций чтения, записи и даже мульти-ключевых транзакций, несмотря на приостановки процессов, падения, манипуляции с часами и сетью, а также изменение числа участников кластера. Строго сериализуемое поведение реализовалось по умолчанию в операциях KV; выполнение чтений с установленным флагом
Отслеживания (watches) работали корректно — по крайней мере, на единичных ключах. До тех пор, пока сжатия истории не уничтожали старые данные, watch'и успешно выдавали каждое обновление ключа.
Однако оказалось, что lock'и в etcd (как и все распределённые блокировки) не обеспечивают взаимное исключение. Различные процессы могут одновременно удерживать блокировку — даже в здоровых кластерах с идеально синхронизированными часами. В документации с API блокировок об этом ничего не было сказано, а представленные примеры lock'ов были небезопасными. Впрочем, часть проблем с блокировками должна была уйти после выпуска этого патча.
В результате нашего сотрудничества команда etcd внесла ряд поправок в документацию (они уже появились в GitHub и будут опубликованы в следующих версиях сайта проекта). Страничка API гарантий на GitHub теперь гласит, что по умолчанию etcd строго сериализуема, а утверждение о том, что последовательный и сериализуемый являются самыми сильными уровнями согласованности, доступными в распределенных системах, удалено. В отношении ревизий теперь указано, что начинать следует с единицы (1), хотя в документации к API по-прежнему ничего не говорится о том, что попытка начать с 0-ой ревизии приведет к «выдаче событий, произошедших после текущей ревизии плюс 1» вместо ожидаемой «выдачи всех событий». Документация о проблемах с безопасностью блокировок находится в стадии разработки.
Некоторые изменения документации, например, описание особого поведения etcd при попытке считывания, начиная с нулевой ревизии, всё ещё требуют внимания.
Как обычно, мы подчёркиваем, что Jepsen предпочитает экспериментальный подход к проверке безопасности: мы можем подтвердить наличие багов, но не их отсутствие. Значительные усилия прилагаются для поиска проблем, однако не можем доказать общую корректность etcd.
Если вы используете lock'и в etcd, задумайтесь о том, нужны ли они вам для обеспечения безопасности или для простого повышения производительности путём вероятностного ограничения параллелизма. Блокировки etcd вполне можно использовать для повышения производительности, однако их применение для целей безопасности может быть рискованным.
В частности, если вы используете блокировку etcd для защиты общего ресурса вроде файла, базы данных или сервиса, этот ресурс должен гарантировать безопасности и без блокировок. Один из способов достичь этого — использовать монотонный заградительный токен. Им может выступать, например, ревизия etcd, связанная с текущим ключом удерживаемой блокировки. Общий ресурс должен гарантировать, что как только клиент использовал токен
Мы подозреваем, что обычные пользователи вряд ли столкнутся с этой проблемой. Но если вы всё же полагаетесь на чтение всех изменений из etcd, начиная с первой ревизии, помните, что в качестве параметра нужно передавать 1, а не 0. Наши опыты показывают, что нулевая ревизия в данном случае означает «текущая ревизия», а не «самая ранняя».
Наконец, lock'и etcd (как и все распределённые блокировки) вводят пользователей в заблуждение: у них может возникнуть желание использовать их как обычные блокировки, однако они будут весьма удивлены, когда поймут, что эти lock'и не обеспечивают взаимное исключение. В документации к API, публикации в блогах, issues на GitHub ничего не говорится об этом риске. Мы рекомендуем включить в документацию etcd информацию о том, что lock'и не обеспечивают взаимное исключение и привести примеры использования заградительных токенов для обновления состояний общих ресурсов вместо примеров, которые могут привести к потере обновлений.
Проект etcd уже несколько лет считается стабильным: алгоритм Raft в его основе хорошо себя зарекомендовал, API для KV-операций прост и понятен. Хотя некоторые дополнительные функции недавно получили новый API, его семантика относительно проста. Мы считаем, что уже достаточно изучили базовые команды вроде
На данный момент мы провели недостаточно подробную оценку удалений (deletions): могут быть граничные случаи, связанные с версиями и ревизиями, когда объекты постоянно создаются и удаляются. В будущих тестах мы намерены подвергнуть операции удаления более внимательному изучению. Также мы не тестировали диапазонные запросы или операции отслеживания со множеством ключей, хотя подозреваем, что их семантика похожа на операции с единичными ключами.
В тестах использовались приостановка процессов, падения, манипуляции с часами, проводились разделения сети и менялся состав кластера; за кадром остались проблемы вроде повреждения диска и другие византийские отказы на уровне одного узла. Эти возможности могут стать предметом изучения в ходе будущих исследований.
Работа была проведена при финансовой поддержке Cloud Native Computing Foundation, входящего в состав The Linux Foundation, и соответствует принципам этической политики Jepsen. Мы хотим поблагодарить команду etcd за ее помощь, и следующих её представителей в особенности: Chris Aniszczyk, Gyuho Lee, Xiang Li, Hitoshi Mitake, Jingyi Hu и Brandon Philips.
Читайте также в нашем блоге:
Хранилище пар «ключ-значение» (KV) etcd представляет собой распределённую базу данных, основанную на алгоритме консенсуса Raft. В ходе анализа, проведенного в 2014 году, мы обнаружили, что etcd 0.4.1 по умолчанию была подвержена так называемым stale reads (операциям чтения, возвращающим старое, неактуальное значение из-за запаздывания синхронизации — прим. перев.). Мы решили вернуться к etcd (в этот раз — к версии 3.4.3), чтобы снова детально оценить ее потенциал в области надежности и безопасности.
Мы обнаружили, что операции с парами «ключ-значение» строго сериализуемы и что процессы-наблюдатели (watches) доставляют каждое изменение ключа по порядку. Однако блокировки (locks) в etcd принципиально небезопасны, а связанные с ними риски усугубляются багом, в результате которого не проверяется актуальность lease после ожидания блокировки. Комментарий разработчиков etcd к нашему отчету вы можете прочитать в блоге проекта.
Спонсором исследования выступил фонд Cloud Native Computing Foundation (CNCF), входящий в The Linux Foundation. Оно проводилось в полном соответствии с этической политикой Jepsen.
1. Предыстория
KV-хранилище etcd — это распределённая система, предназначенная для использования в качестве основы для координации. Как Zookeeper и Consul, etcd хранит небольшие объемы редко обновляемых состояний (по умолчанию до 8 Гб) в виде карты key-value и обеспечивает строго сериализуемые чтение, запись и микротранзакции по всему хранилищу данных, а также примитивы координации вроде блокировок (locks), отслеживания (watches) и выбора лидера. Многие распределённые системы, такие как Kubernetes и OpenStack, используют etcd для хранения метаданных кластеров, для координации согласованных представлений о данных, выбора лидера и т.п.
В 2014 мы уже проводили оценку etcd 0.4.1. Тогда мы обнаружили, что по умолчанию оно подвержено stale reads из-за оптимизации. В то время, как в работе о принципах Raft обсуждается необходимость разбиения операций чтения на потоки и их пропускания через систему консенсуса для обеспечения жизнеспособности, etcd выполняло чтение на любом лидере локально, не проверяя наличие более актуального состояния на более новом лидере. Команда разработчиков etcd внедрила опциональный флаг кворума, а в API etcd версии 3.0 по умолчанию появилась линеаризуемость для всех операций кроме операций отслеживания.
API etcd 3.0 концентрируется на плоской карте KV, где ключи и значения представляют собой непрозрачные (opaque) байтовые массивы. С помощью диапазонных запросов можно имитировать иерархические ключи. Пользователи могут читать, писать и удалять ключи, а также отслеживать поток обновлений для одного ключа или диапазона ключей. Инструментарий etcd дополняют lease'ы (переменные объекты с ограниченным временем жизни, которые поддерживаются в активном состоянии heartbeat-запросами клиента), lock'и (выделенные именованные объекты, привязанные к lease'ам) и выбор лидеров.
В версии 3.0 etcd предлагает ограниченный транзакционный API для атомарных операций со множеством ключей. В этой модели транзакция представляет собой некое условное выражение с предикатом, истинной ветвью и ложной ветвью. В качестве предиката может выступать конъюнкция нескольких поключевых сравнений: равенство или различные неравенства, по версиям одного ключа, глобальной ревизии etcd или текущему значению ключа. Истинная и ложная ветви могут включать множественные операции чтения и записи; все они применяются атомарно в зависимости от результата оценки предиката.
1.1 Гарантии согласованности в документации
По состоянию на октябрь 2019-го в документации к API etcd заявляется, что «все вызовы API демонстрируют последовательную согласованность — самую сильную форму гарантии согласованности, доступную в распределённых системах». Это не так: последовательная согласованность строго слабее линеаризуемости, а линеаризуемость определённо достижима в распределённых системах. Далее в документации заявляется, что «в ходе операции чтения etcd не гарантирует передачу [самого недавнего (измеренного внешними часами по итогам завершения запроса)] доступного на любом представителе кластера значения». Это также слишком консервативное утверждение: если etcd обеспечивает линеаризуемость, операции чтения всегда связаны с самым последним зафиксированным состоянием в порядке линеаризации.
В документации также утверждается, что etcd гарантирует сериализуемую изоляцию: все операции (даже те, которые затрагивают несколько ключей) выполняются в некотором общем порядке. Авторы описывают сериализуемую изоляцию как «самый сильный уровень изоляции, доступный в распределённых системах». Это (в зависимости от того, что вы понимаете под «уровнем изоляции») также неверно; строгая сериализуемость сильнее простой сериализуемости, при этом первая также достижима в распределённых системах.
В документации говорится, что все операции (кроме отслеживания) в etcd линеаризуемы по умолчанию. При этом линеаризуемость определяется как согласованность со слабо синхронизированными глобальными часами. Следует отметить, что такое определение не только несовместимо с определением линеаризуемости Херлихи и Винга (Herlihy & Wing), но также подразумевает нарушение причинности: узлы с опережающим часами будут пытаться считывать результаты операций, которые ещё даже не начинались. Мы предполагаем, что etcd всё же не является машиной времени, и, поскольку в его основе лежит алгоритм Raft, должно применяться общепринятое определение линеаризуемости.
Поскольку KV-операции в etcd сериализуемы и линеаризуемы, мы считаем, что на самом деле etcd по умолчанию обеспечивает строгую сериализацию. Это имеет смысл, поскольку все ключи etcd находятся в единой машине состояний, а полную упорядоченность всех операции на этой машине состояний обеспечивает Raft. По сути, весь набор данных etcd представляет собой единый линеаризуемый объект.
Опциональный флаг
serializable понижает уровень операций чтения со строгой до обычной сериализуемой согласованности, разрешая чтение устаревшего зафиксированного состояния. Обратите внимание, что флаг serializable не оказывает влияния на сериализуемость истории; KV-операции etcd сериализуемы во всех случаях.2. Разработка теста
Для создания набора тестов мы воспользовались соответствующей библиотекой Jepsen. Анализу подверглась версия etcd 3.4.3 (самая свежая по состоянию на октябрь'19), работающая на кластерах Debian Stretch, состоящих из 5 узлов. Мы внедрили ряд неисправностей в эти кластеры, включая сетевые разделения, изолирующие отдельные узлы, разделение кластера на большинство и меньшинство, а также нетранзитивные разбиения с перекрывающимся большинством. «Роняли» и приостанавливали случайные подмножества узлов, а также умышленно выводили из строя лидеров. Вводили временные искажения до нескольких сотен секунд, как на многосекундных интервалах, так и на миллисекундных (быстрое «мерцание»). Поскольку etcd поддерживает динамическое изменение числа компонентов, мы случайным образом добавляли и удаляли узлы во время тестирования.
Тестовые нагрузки включали регистры, наборы и транзакционные тесты для проверки операций над KV, а также специализированные нагрузки для lock'ов и watch'ей.
2.1 Регистры
Для оценки надёжности etcd при KV-операциях был разработан тест с регистрами, в ходе которого производились случайные операции чтения, записи, сравнения/установки (compare-and-set) над единичными ключами. Оценку результатов проводили с помощью инструмента для проверки линеаризуемости Knossos с использованием модели регистра сравнения/установки и информации о версиях.
2.2 Наборы
Для количественной оценки stale reads был разработан тест, использовавший транзакцию сравнения и установки (compare-and-set) для чтения набора целых чисел из одного ключа и последующего добавления значения к этому набору. В процессе теста мы также проводили параллельное считывание всего набора. После завершения испытания анализировались результаты на предмет наличия случаев, когда элемент, о котором было известно, что он должен присутствовать в наборе, отсутствовал в результатах чтения. Эти случаи использовались для количественной оценки stale reads и потерянных обновлений.
2.3 Append-тест
Для проверки строгой сериализуемости был разработан append-тест, в ходе которого транзакции параллельно читали и добавляли значения к спискам, состоящим из уникальных наборов целых чисел. Каждый список хранился в одном ключе etcd, и проводились добавления в рамках каждой транзакции, читая каждый ключ, который нужно было изменить в одной транзакции, а затем эти ключи записывались и выполнялись чтения во второй транзакции, которая защищалась, чтобы гарантировать, что ни один записанный ключ не изменился с момента первого чтения. В конце теста мы построили график зависимости между транзакциями на основе приоритета в реальном времени и отношений операций чтения и добавления. Проверка этого графика на наличие циклов позволила определить, были ли операции строго сериализуемыми.
В то время как etcd запрещает транзакциям записывать один и тот же ключ множество раз, можно создавать транзакции, предусматривающие до одной записи на каждый ключ. Мы также убедились, что операции чтения в рамках одной транзакции отражали предыдущие операции записи из той же транзакции.
2.4 Lock'и
Как координационный сервис, etcd обещает встроенную поддержку распределённой блокировки. Мы исследовали эти блокировки двумя способами. Сначала генерировали рандомизированные запросы lock и unlock, получая lease для каждого lock'а и оставляя его открытым с помощью встроенной в Java-клиент etcd
функции keepalive до высвобождения. Мы провели проверку результатов в Knossos, чтобы понять, формируют ли они линеаризуемую реализацию lock-сервиса.Для более практического теста (и получения количественной оценки частоты сбоя блокировок) мы использовали lock'и etcd для организации взаимного исключения при внесении обновлений в набор в in-memory и искали потерянные обновления в этом наборе. Этот тест позволил нам прямым образом подтвердить, могут ли системы, использующие etcd как мьютекс, безопасно обновлять внутреннее состояние.
Третий вариант lock-теста задействовал guard'ы на lease key для модификации набора, хранящегося в etcd.
2.5 Отслеживание
Чтобы проверить, что watch'и предоставляют информацию о каждом обновлении ключа, в рамках теста создавался один ключ и ему вслепую присваивались уникальные целочисленные значения. Тем временем клиенты совместно отслеживали этот ключ по нескольку секунд за раз. Каждый раз после инициации watch'а клиент начинал с той ревизии, на которой остановился в прошлый раз.
В конце этого процесса мы убедились, что каждый клиент наблюдал одну и ту же последовательность изменений ключа.
3. Результаты
3.1 Отслеживание с 0-ой ревизии
При отслеживании (watching) ключа клиенты могут указать начальную ревизию, которая является «опциональной ревизией, с которой (включительно) начинается слежение». Если пользователь желает увидеть каждую операцию с неким ключом, он может указать первую ревизию etcd. Что это за ревизия? Модель данных и глоссарий не дают ответа на этот вопрос; ревизии описываются как монотонно возрастающие 64-битные счетчики, но непонятно, начинает ли etcd с 0 или 1. Разумно предположить, что отсчет идет с нуля (так, на всякий случай).
Увы, это неправильно. Запрос 0-ой ревизии приводит к тому, что etcd начинает транслировать обновления, начиная с текущей ревизии на сервере плюс один, а не с самой первой. Запрос 1-ой ревизии выдаёт все изменения. Такое поведение нигде не задокументировано.
Мы считаем, что на практике эта тонкость вряд ли приведет к проблемам в production, поскольку большинство кластеров не задерживаются на первой ревизии. Кроме того, etcd все равно сжимает историю с течением времени, поэтому в реальных условиях приложения, скорее всего, в любом случае не требуют чтения всех версий, начиная с 1-ой ревизии. Подобное поведение оправдано, однако ему не помешало бы соответствующее описание в документации.
3.2 Мифические lock'и
Документация к API для lock'ов гласит, что заблокированный ключ «может использоваться совместно с транзакциями для гарантирования того, что обновления в etcd происходят только тогда, когда сохраняется принадлежность блокировки». Странно, но в ней не приводятся какие-либо гарантии для самих блокировок и не объясняется их предназначение.
Впрочем, в других материалах maintainer'ы etcd все же делятся информацией об использовании блокировок. Например, в анонсе о выходе etcd 3.2 описывается применение
etcdctl для блокировки совместного изменения файла на диске. Кроме того, в issue на GitHub с вопросом о конкретном предназначении блокировок один из разработчиков etcd ответил следующее:В моем понимании блокировка в etcd является сервисом, который пользователи (или другие системы) могут использовать для ограничения доступа к любому ресурсу, который они хотят защитить (это необязательно должен быть ресурс в базе данных etcd), что-то вроде:
- включить блокировку в etcd;
- сделать что-то (опять же, необязательно связанное с базой etcd);
- отключить упомянутую выше блокировку.
Именно такой пример приводится в
документации к etcdctl: блокировка использовалась для защиты команды put, но не привязывала ключ блокировки к обновлению.Увы, это небезопасно, поскольку позволяет нескольким клиентам одновременно удерживать одну и ту же блокировку. Проблема усугубляется приостановкой процессов, падениями или разделениями сети, однако она также может возникать во вполне здоровых кластерах без каких-либо внешних сбоев. Например, в этом тестовом прогоне процесс номер 3 успешно устанавливает блокировку, а процесс 1 параллельно получает ту же самую блокировку ещё до того, как у процесса 3 появляется возможность её снять:
Сильнее всего нарушение мьютекса было заметно на lease'ах с коротким TTL: TTL в 1, 2 и 3 секунды были не в состоянии обеспечить взаимное исключение спустя всего несколько минут тестирования (даже в здоровых кластерах). Приостановки процессов и сетевые разбиения ещё быстрее приводили к проблемам.
В одном из вариантов нашего lock-теста мьютексы etcd использовались для защиты совместных обновлений набора целых чисел (как и предлагает документация etcd). Каждое обновление считывало текущее значение выборки in-memory, и, примерно через одну секунду, записывало эту коллекцию обратно с добавлением уникального элемента. При lease'ах с двухсекундным TTL, пяти параллельных процессах и приостановке процесса каждые пять секунд, мы смогли вызвать устойчивую потерю примерно 18 % подтвержденных обновлений.
Эта проблема усугублялась внутренним механизмом работы с блокировками в etcd. Если клиент дожидался снятия блокировки другим клиентом, терял свой lease, и после этого блокировка снималась, сервер не перепроверял lease, чтобы убедиться, что она по-прежнему действительна, прежде чем проинформировать клиента, что блокировка теперь за ним.
Включение дополнительной проверки lease, а также выбор более длительных TTL и внимательная настройка выборных (election) таймаутов позволят снизить частоту возникновения этой проблемы. Однако полностью устранить нарушения мьютексов не получится, поскольку распределённые блокировки фундаментально небезопасны в асинхронных системах. Д-р Martin Kleppmann убедительно описывает это в своей статье о распределённых блокировках. По его словам, службы блокировки обязаны приносить в жертву правильность, чтобы поддерживать жизнеспособность в асинхронных системах: если процесс падает, контролируя блокировку, службе блокировки нужен некий способ, чтобы принудительно снять блокировку. Однако если процесс на самом деле не упал, а просто медленно работает или временно недоступен, снятие блокировки может привести к тому, что она будет удерживаться в нескольких местах одновременно.
Но даже если распределённая служба блокировки воспользуется, скажем, неким магическим детектором сбоев и на самом деле сможет гарантировать взаимное исключение, в случае некоторого нелокального ресурса её использование всё равно будет небезопасным. Допустим, процесс А посылает сообщение базе данных D, удерживая блокировку. После чего процесс А падает, а процесс B получает блокировку и тоже посылает сообщение базе D. Проблема в том, что сообщение от процесса А (из-за асинхронности) может прийти после сообщения от процесса B, нарушив взаимное исключение, которое была призвана обеспечить блокировка.
Чтобы предотвратить эту проблему, необходимо полагаться на то, что сама система хранения будет поддерживать корректность транзакций или, если служба блокировки предоставляет такой механизм, использовать «заградительный» (fencing) токен, который будет включаться во все операции, производимые держателем блокировки. Он позволит гарантировать, что никакие операции предыдущего держателя блокировки внезапно не возникнут между операциями текущего владельца блокировки. Например, в службе блокировки Chubby от Google подобные токены зовутся sequencers. В etcd можно использовать ревизию ключа блокировки в качестве глобально упорядоченного заградительного токена.
Кроме того, ключи блокировки в etcd можно использовать для защиты транзакционных обновлений в самой etcd. Проверяя в рамках транзакции версию ключа блокировки, пользователи могут предотвратить транзакцию, если блокировка уже не удерживается (т.е. версия lock-ключа больше нуля). В наших тестах подобный подход позволил успешно изолировать операции чтения-изменения-записи, в которых запись была единственной транзакцией, защищенной блокировкой. Этот подход обеспечивает изоляцию, аналогичную заградительным токенам, но (как и заградительные токены) не гарантирует атомарность: процесс может упасть или потерять мьютекс во время обновления, состоящего из множества операций, оставив etcd в логически противоречивом состоянии.
Итоги работ в issues проекта:
- Watches beginning at revision 0 start later — не решено;
- Locks return after blocking without checking ownership — в master;
- Locks are not documented as unsafe — не решено.
4. Обсуждение
В наших тестах etcd 3.4.3 оправдал ожидания в отношении KV-операций: мы наблюдали строго сериализуемую согласованность операций чтения, записи и даже мульти-ключевых транзакций, несмотря на приостановки процессов, падения, манипуляции с часами и сетью, а также изменение числа участников кластера. Строго сериализуемое поведение реализовалось по умолчанию в операциях KV; выполнение чтений с установленным флагом
serializable приводило к появлению stale reads (о чём и написано в документации).Отслеживания (watches) работали корректно — по крайней мере, на единичных ключах. До тех пор, пока сжатия истории не уничтожали старые данные, watch'и успешно выдавали каждое обновление ключа.
Однако оказалось, что lock'и в etcd (как и все распределённые блокировки) не обеспечивают взаимное исключение. Различные процессы могут одновременно удерживать блокировку — даже в здоровых кластерах с идеально синхронизированными часами. В документации с API блокировок об этом ничего не было сказано, а представленные примеры lock'ов были небезопасными. Впрочем, часть проблем с блокировками должна была уйти после выпуска этого патча.
В результате нашего сотрудничества команда etcd внесла ряд поправок в документацию (они уже появились в GitHub и будут опубликованы в следующих версиях сайта проекта). Страничка API гарантий на GitHub теперь гласит, что по умолчанию etcd строго сериализуема, а утверждение о том, что последовательный и сериализуемый являются самыми сильными уровнями согласованности, доступными в распределенных системах, удалено. В отношении ревизий теперь указано, что начинать следует с единицы (1), хотя в документации к API по-прежнему ничего не говорится о том, что попытка начать с 0-ой ревизии приведет к «выдаче событий, произошедших после текущей ревизии плюс 1» вместо ожидаемой «выдачи всех событий». Документация о проблемах с безопасностью блокировок находится в стадии разработки.
Некоторые изменения документации, например, описание особого поведения etcd при попытке считывания, начиная с нулевой ревизии, всё ещё требуют внимания.
Как обычно, мы подчёркиваем, что Jepsen предпочитает экспериментальный подход к проверке безопасности: мы можем подтвердить наличие багов, но не их отсутствие. Значительные усилия прилагаются для поиска проблем, однако не можем доказать общую корректность etcd.
4.1 Рекомендации
Если вы используете lock'и в etcd, задумайтесь о том, нужны ли они вам для обеспечения безопасности или для простого повышения производительности путём вероятностного ограничения параллелизма. Блокировки etcd вполне можно использовать для повышения производительности, однако их применение для целей безопасности может быть рискованным.
В частности, если вы используете блокировку etcd для защиты общего ресурса вроде файла, базы данных или сервиса, этот ресурс должен гарантировать безопасности и без блокировок. Один из способов достичь этого — использовать монотонный заградительный токен. Им может выступать, например, ревизия etcd, связанная с текущим ключом удерживаемой блокировки. Общий ресурс должен гарантировать, что как только клиент использовал токен
y для выполнения некоторой операции, любая операция с токеном x < y будет отвергаться. Такой подход не обеспечивает атомарность, однако он гарантирует, что операции в рамках блокировки выполняются по порядку, а не вперемешку.Мы подозреваем, что обычные пользователи вряд ли столкнутся с этой проблемой. Но если вы всё же полагаетесь на чтение всех изменений из etcd, начиная с первой ревизии, помните, что в качестве параметра нужно передавать 1, а не 0. Наши опыты показывают, что нулевая ревизия в данном случае означает «текущая ревизия», а не «самая ранняя».
Наконец, lock'и etcd (как и все распределённые блокировки) вводят пользователей в заблуждение: у них может возникнуть желание использовать их как обычные блокировки, однако они будут весьма удивлены, когда поймут, что эти lock'и не обеспечивают взаимное исключение. В документации к API, публикации в блогах, issues на GitHub ничего не говорится об этом риске. Мы рекомендуем включить в документацию etcd информацию о том, что lock'и не обеспечивают взаимное исключение и привести примеры использования заградительных токенов для обновления состояний общих ресурсов вместо примеров, которые могут привести к потере обновлений.
4.2 Дальнейшие планы
Проект etcd уже несколько лет считается стабильным: алгоритм Raft в его основе хорошо себя зарекомендовал, API для KV-операций прост и понятен. Хотя некоторые дополнительные функции недавно получили новый API, его семантика относительно проста. Мы считаем, что уже достаточно изучили базовые команды вроде
get и put, транзакции, блокировки и отслеживания. Однако существуют и другие тесты, которые стоило бы выполнить.На данный момент мы провели недостаточно подробную оценку удалений (deletions): могут быть граничные случаи, связанные с версиями и ревизиями, когда объекты постоянно создаются и удаляются. В будущих тестах мы намерены подвергнуть операции удаления более внимательному изучению. Также мы не тестировали диапазонные запросы или операции отслеживания со множеством ключей, хотя подозреваем, что их семантика похожа на операции с единичными ключами.
В тестах использовались приостановка процессов, падения, манипуляции с часами, проводились разделения сети и менялся состав кластера; за кадром остались проблемы вроде повреждения диска и другие византийские отказы на уровне одного узла. Эти возможности могут стать предметом изучения в ходе будущих исследований.
Работа была проведена при финансовой поддержке Cloud Native Computing Foundation, входящего в состав The Linux Foundation, и соответствует принципам этической политики Jepsen. Мы хотим поблагодарить команду etcd за ее помощь, и следующих её представителей в особенности: Chris Aniszczyk, Gyuho Lee, Xiang Li, Hitoshi Mitake, Jingyi Hu и Brandon Philips.
P.S. от переводчика
Читайте также в нашем блоге: