
Привет, Хабр! Представляю вашему вниманию перевод статьи «Demystifying memory management in modern programming languages» за авторством Deepu K Sasidharan.
В данной серии статей мне бы хотелось развеять завесу мистики над управлением памятью в программном обеспечении (далее по тексту — ПО) и подробно рассмотреть возможности, предоставляемые современными языками программирования. Надеюсь, что мои статьи помогут читателю заглянуть под капот этих языков и узнать для себя нечто новое.
Углублённое изучение концептов управления памятью позволяет писать более эффективное ПО, потому как стиль и практики кодирования оказывают большое влияние на принципы выделения памяти для нужд программы.
Управление памятью — это целый набор механизмов, которые позволяют контролировать доступ программы к оперативной памяти компьютера. Данная тема является очень важной при разработке ПО и, при этом, вызывает затруднения или же вовсе остаётся черным ящиком для многих программистов.
Когда программа выполняется в операционный системе компьютера, она нуждается в доступе к оперативной памяти (RAM) для того, чтобы:
Помимо места, используемого для загрузки своего собственного байт-кода, программа использует при работе две области в оперативной памяти — стек (stack) и кучу (heap).
Стек используется для статичного выделения памяти. Он организован по принципу «последним пришёл — первым вышел» (LIFO). Можно представить стек как стопку книг — разрешено взаимодействовать только с самой верхней книгой: прочитать её или положить на неё новую.
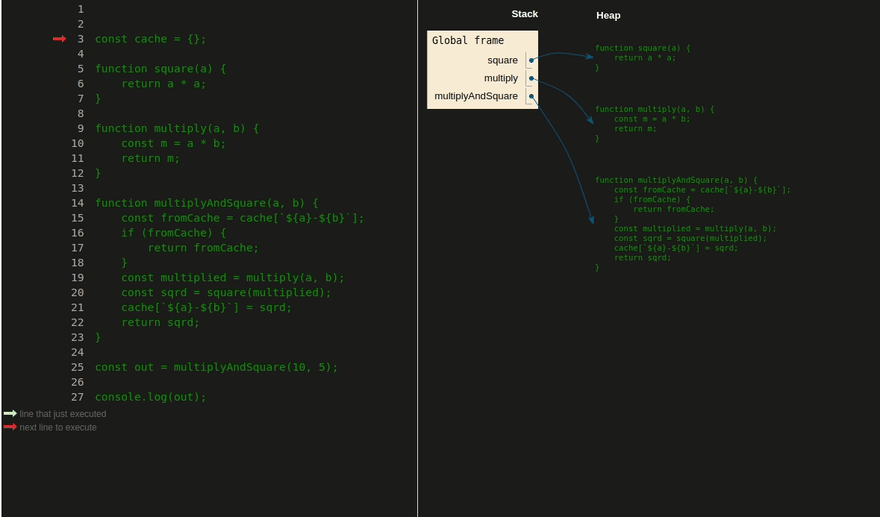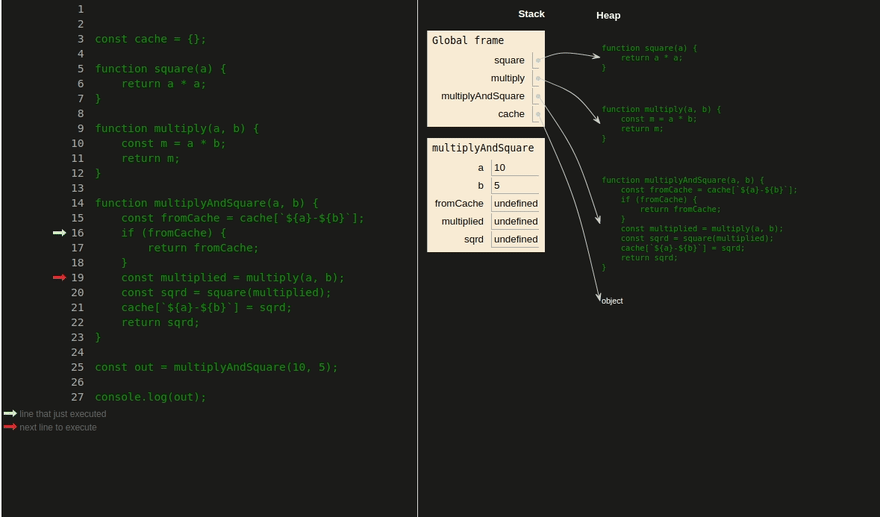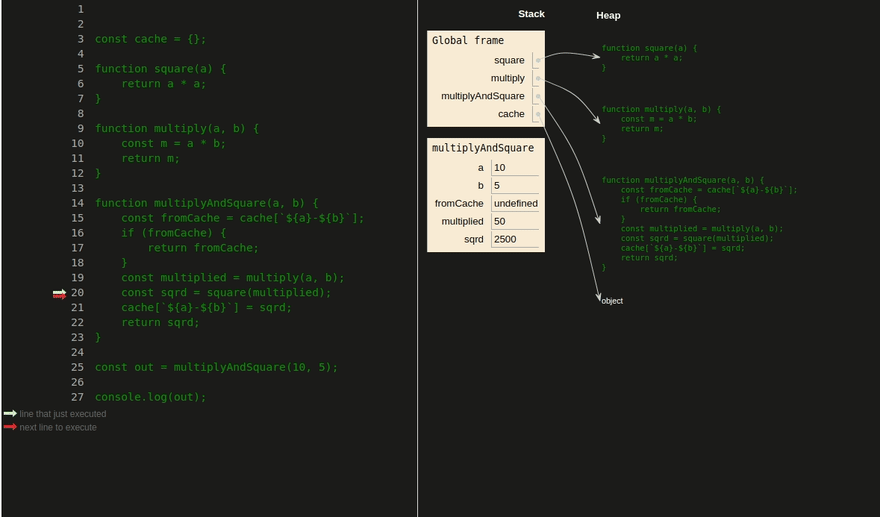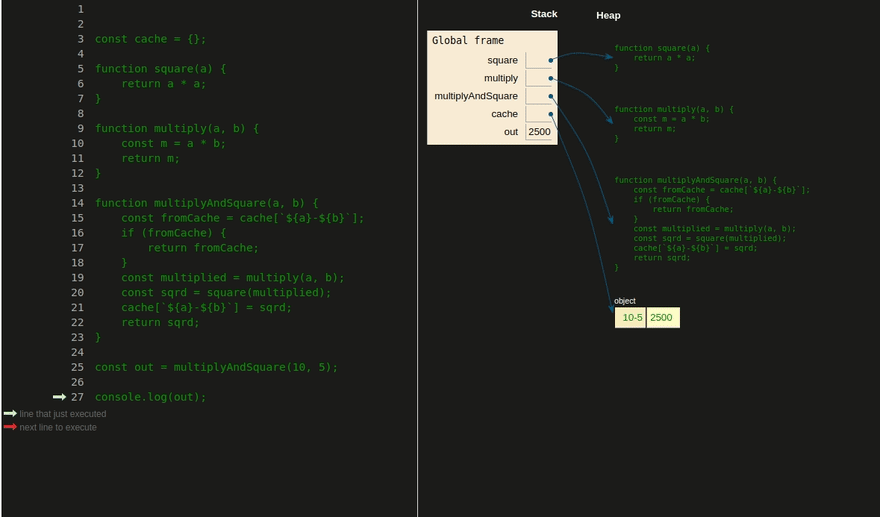
Использование стека в JavaScript. Объекты хранятся в куче и доступны по ссылкам, которые хранятся в стеке. Тут можно посмотреть в видеоформате
Куча используется для динамического выделения памяти, однако, в отличие от стека, данные в куче первым делом требуется найти с помощью «оглавления». Можно представить, что куча это такая большая многоуровневая библиотека, в которой, следуя определённым инструкциям, можно найти необходимую книгу.
В отличие от жёстких дисков, оперативная память весьма ограниченна (хотя и жёсткие диски, безусловно, тоже не безграничны). Если программа потребляет память не высвобождая её, то, в конечном итоге, она поглотит все доступные резервы и попытается выйти за пределы памяти. Тогда она просто упадет сама, или, что ещё драматичнее, обрушит операционную систему. Следовательно, весьма нежелательно относиться легкомысленно к манипуляциям с памятью при разработке ПО.
Современные языки программирования стараются максимально упростить работу с памятью и снять с разработчиков часть головной боли. И хотя некоторые почтенные языки всё ещё требуют ручного управления, большинство всё же предоставляет более изящные автоматические подходы. Порой в языке используется сразу несколько подходов к управлению памятью, а иногда разработчику даже доступен выбор какой из вариантов будет эффективнее конкретно для его задач (хороший пример — C++). Перейдём к краткому обзору различных подходов.
Язык не предоставляет механизмов для автоматического управления памятью. Выделение и освобождение памяти для создаваемых объектов остаётся полностью на совести разработчика. Пример такого языка — C. Он предоставляет ряд методов (malloc, realloc, calloc и free) для управления памятью — разработчик должен использовать их для выделения и освобождения памяти в своей программе. Этот подход требует большой аккуратности и внимательности. Так же он является в особенности сложным для новичков.
Сборка мусора — это процесс автоматического управления памятью в куче, который заключается в поиске неиспользующихся участков памяти, которые ранее были заняты под нужды программы. Это один из наиболее популярных вариантов механизма для управления памятью в современных языках программирования. Подпрограмма сборки мусора обычно запускается в заранее определённые интервалы времени и бывает, что её запуск совпадает с ресурсозатратными процессами, в результате чего происходит задержка в работе приложения. JVM (Java/Scala/Groovy/Kotlin), JavaScript, Python, C#, Golang, OCaml и Ruby — вот примеры популярных языков, в которых используется сборщик мусора.
RAII — это программная идиома в ООП, смысл которой заключается в том, что выделяемая для объекта область памяти строго привязывается к его времени существования. Память выделяется в конструкторе и освобождается в деструкторе. Данный подход был впервые реализован в C++, а так же используется в Ada и Rust.
Данный подход весьма похож на сборку мусора с подсчётом ссылок, однако, вместо запуска процесса подсчёта в определённые интервалы времени, инструкции выделения и освобождения памяти вставляются на этапе компиляции прямо в байт-код. Когда же счётчик ссылок достигает нуля, память освобождается как часть нормального потока выполнения программы.
Автоматический подсчёт ссылок всё так же не позволяет обрабатывать циклические ссылки и требует от разработчика использования специальных ключевых слов для дополнительной обработки таких ситуаций. ARC является одной из особенностей транслятора Clang, поэтому присутствует в языках Objective-C и Swift. Так же автоматический подсчет ссылок доступен для использования в Rust и новых стандартах C++ при помощи умных указателей.
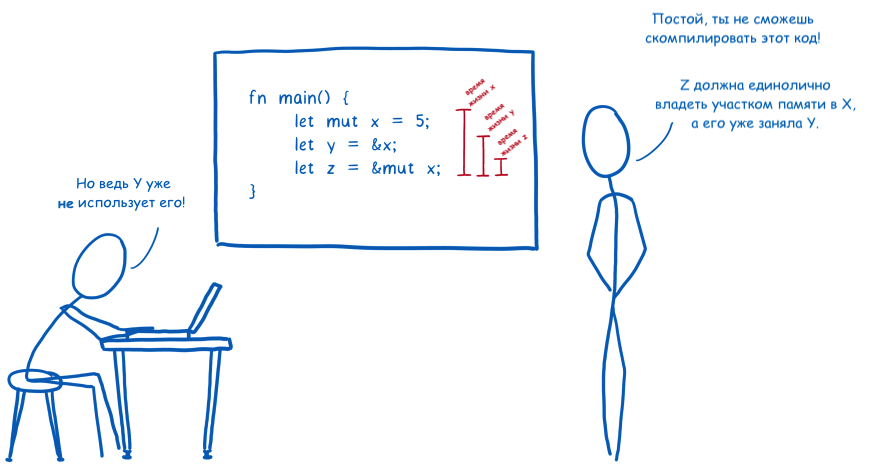
Это сочетание RAII с концепцией владения, когда каждое значение в памяти должно иметь только одну переменную-владельца. Когда владелец уходит из области выполнения, память сразу же освобождается. Можно сказать, что это примерно как подсчёт ссылок на этапе компиляции. Данный подход используется в Rust и при этом я не смог найти ни одного другого языка, который бы использовал подобный механизм.
В данной статье были рассмотрены основные концепции в сфере управления памятью. Каждый язык программирования использует собственные реализации этих подходов и оптимизированные для различных задач алгоритмы. В следующих частях, мы подробнее рассмотрим решения для управления памятью в популярных языках.
Читайте так же другие части серии:
Если вам понравилась статья, пожалуйста, поставьте плюс или напишите комментарий.
Вы можете подписаться на автора статьи в Twitter и на LinkedIn.
Иллюстрации:
Визуализация стека сделана с помощью pythontutor.
Иллюстрация концепции владения: Link Clark, The Rust team под Creative Commons Attribution Share-Alike License v3.0.
За вычитку перевода отдельное спасибо Александру Максимовскому и Катерине Шибаковой
В данной серии статей мне бы хотелось развеять завесу мистики над управлением памятью в программном обеспечении (далее по тексту — ПО) и подробно рассмотреть возможности, предоставляемые современными языками программирования. Надеюсь, что мои статьи помогут читателю заглянуть под капот этих языков и узнать для себя нечто новое.
Углублённое изучение концептов управления памятью позволяет писать более эффективное ПО, потому как стиль и практики кодирования оказывают большое влияние на принципы выделения памяти для нужд программы.
Часть 1: Введение в управление памятью
Управление памятью — это целый набор механизмов, которые позволяют контролировать доступ программы к оперативной памяти компьютера. Данная тема является очень важной при разработке ПО и, при этом, вызывает затруднения или же вовсе остаётся черным ящиком для многих программистов.
Для чего используется оперативная память?
Когда программа выполняется в операционный системе компьютера, она нуждается в доступе к оперативной памяти (RAM) для того, чтобы:
- загружать свой собственный байт-код для выполнения;
- хранить значения переменных и структуры данных, которые используются в процессе работы;
- загружать внешние модули, которые необходимы программе для выполнения задач.
Помимо места, используемого для загрузки своего собственного байт-кода, программа использует при работе две области в оперативной памяти — стек (stack) и кучу (heap).
Стек
Стек используется для статичного выделения памяти. Он организован по принципу «последним пришёл — первым вышел» (LIFO). Можно представить стек как стопку книг — разрешено взаимодействовать только с самой верхней книгой: прочитать её или положить на неё новую.
- благодаря упомянутому принципу, стек позволяет очень быстро выполнять операции с данными — все манипуляции производятся с «верхней книгой в стопке». Книга добавляется в самый верх, если нужно сохранить данные, либо берётся сверху, если данные требуется прочитать;
- существует ограничение в том, что данные, которые предполагается хранить в стеке, обязаны быть конечными и статичными — их размер должен быть известен ещё на этапе компиляции;
- в стековой памяти хранится стек вызовов — информация о ходе выполнения цепочек вызовов функций в виде стековых кадров. Каждый стековый кадр это набор блоков данных, в которых хранится информация, необходимая для работы функции на определённом шаге — её локальные переменные и аргументы, с которыми её вызывали. Например, каждый раз, когда функция объявляет новую переменную, она добавляет её в верхний блок стека. Затем, когда функция завершает свою работу, очищаются все блоки памяти в стеке, которые функция использовала — иными словами, очищаются все блоки ее стекового кадра;
- каждый поток многопоточного приложения имеет доступ к своему собственному стеку;
- управление стековой памятью простое и прямолинейное; оно выполняется операционной системой;
- в стеке обычно хранятся данные вроде локальных переменных и указателей;
- при работе со стеком есть вероятность получать ошибки переполнения стека (stack overflow), так как максимальный его размер строго ограничен. Например, ошибка при составлении граничного условия в рекурсивной функции совершенно точно приведёт к переполнению стека;
- в большинстве языков существует ограничение на размер значений, которые можно сохранить в стек;
Использование стека в JavaScript. Объекты хранятся в куче и доступны по ссылкам, которые хранятся в стеке. Тут можно посмотреть в видеоформате
Куча
Куча используется для динамического выделения памяти, однако, в отличие от стека, данные в куче первым делом требуется найти с помощью «оглавления». Можно представить, что куча это такая большая многоуровневая библиотека, в которой, следуя определённым инструкциям, можно найти необходимую книгу.
- операции на куче производятся несколько медленнее, чем на стеке, так как требуют дополнительного этапа для поиска данных;
- в куче хранятся данные динамических размеров, например, список, в который можно добавлять произвольное количество элементов;
- куча общая для всех потоков приложения;
- вследствие динамической природы, куча нетривиальна в управлении и с ней возникает большинство всех проблем и ошибок, связанных с памятью. Способы решения этих проблем предоставляются языками программирования;
- типичные структуры данных, которые хранятся в куче — это глобальные переменные (они должны быть доступны для разных потоков приложения, а куча как раз общая для всех потоков), ссылочные типы, такие как строки или ассоциативные массивы, а так же другие сложные структуры данных;
- при работе с кучей можно получить ошибки выхода за пределы памяти (out of memory), если приложение пытается использовать больше памяти, чем ему доступно;
- размер значений, которые могут храниться в куче, ограничен лишь общим объёмом памяти, который был выделен операционной системой для программы.
Почему эффективное управление памятью важно?
В отличие от жёстких дисков, оперативная память весьма ограниченна (хотя и жёсткие диски, безусловно, тоже не безграничны). Если программа потребляет память не высвобождая её, то, в конечном итоге, она поглотит все доступные резервы и попытается выйти за пределы памяти. Тогда она просто упадет сама, или, что ещё драматичнее, обрушит операционную систему. Следовательно, весьма нежелательно относиться легкомысленно к манипуляциям с памятью при разработке ПО.
Различные подходы
Современные языки программирования стараются максимально упростить работу с памятью и снять с разработчиков часть головной боли. И хотя некоторые почтенные языки всё ещё требуют ручного управления, большинство всё же предоставляет более изящные автоматические подходы. Порой в языке используется сразу несколько подходов к управлению памятью, а иногда разработчику даже доступен выбор какой из вариантов будет эффективнее конкретно для его задач (хороший пример — C++). Перейдём к краткому обзору различных подходов.
Ручное управление памятью
Язык не предоставляет механизмов для автоматического управления памятью. Выделение и освобождение памяти для создаваемых объектов остаётся полностью на совести разработчика. Пример такого языка — C. Он предоставляет ряд методов (malloc, realloc, calloc и free) для управления памятью — разработчик должен использовать их для выделения и освобождения памяти в своей программе. Этот подход требует большой аккуратности и внимательности. Так же он является в особенности сложным для новичков.
Сборщик мусора
Сборка мусора — это процесс автоматического управления памятью в куче, который заключается в поиске неиспользующихся участков памяти, которые ранее были заняты под нужды программы. Это один из наиболее популярных вариантов механизма для управления памятью в современных языках программирования. Подпрограмма сборки мусора обычно запускается в заранее определённые интервалы времени и бывает, что её запуск совпадает с ресурсозатратными процессами, в результате чего происходит задержка в работе приложения. JVM (Java/Scala/Groovy/Kotlin), JavaScript, Python, C#, Golang, OCaml и Ruby — вот примеры популярных языков, в которых используется сборщик мусора.
- Сборщик мусора на основе алгоритма пометок (Mark & Sweep): Это алгоритм, работа которого происходит в две фазы: первым делом он помечает объекты в памяти, на которые имеются ссылки, а затем освобождает память от объектов, которые пометки не получили. Этот подход используется, например, в JVM, C#, Ruby, JavaScript и Golang. В JVM существует на выбор несколько разных алгоритмов сборки мусора, а JavaScript-движки, такие как V8, используют алгоритм пометок в дополнение к подсчёту ссылок. Такой сборщик мусора можно подключить в C и C++ в виде внешней библиотеки.
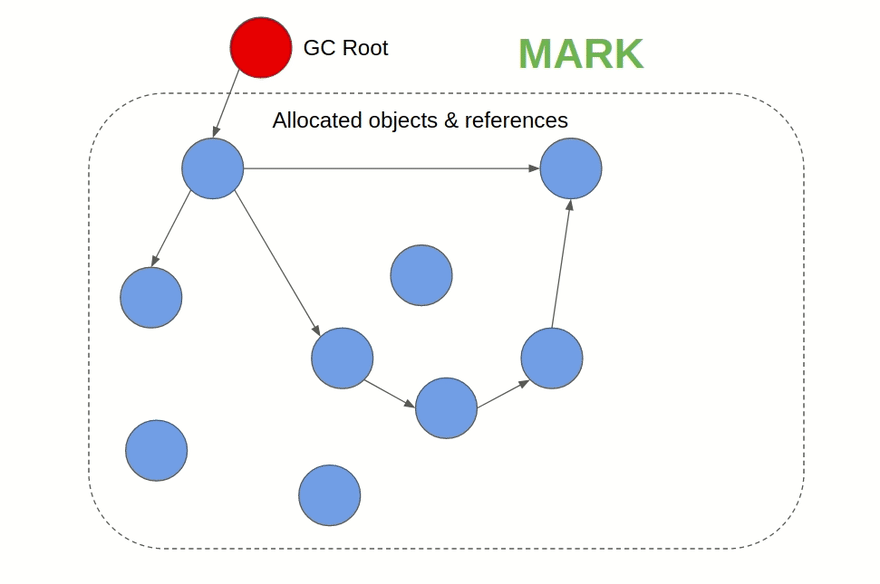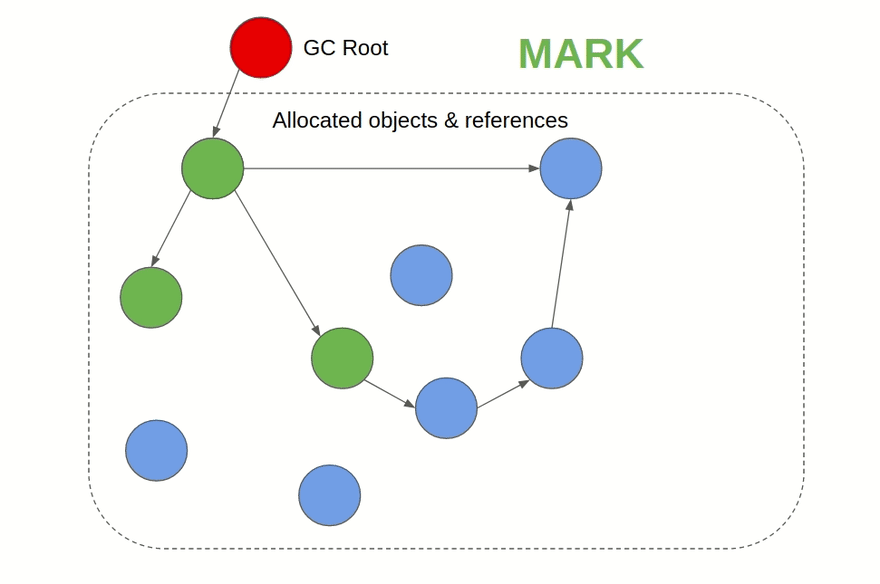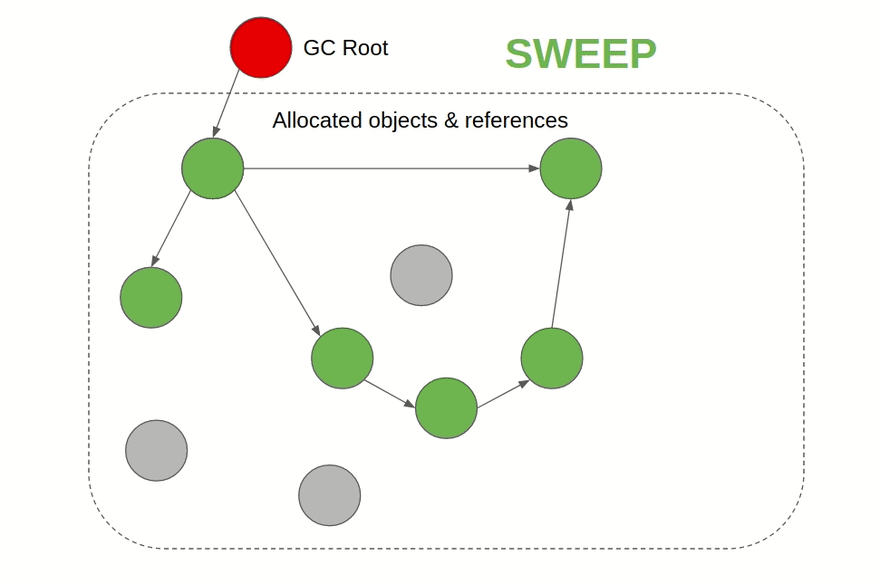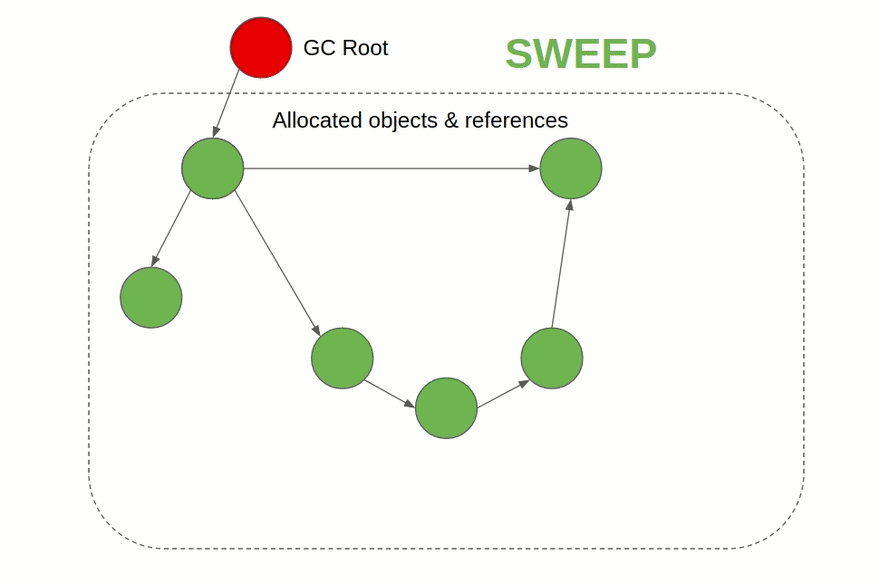
Визуализация алгоритма пометок: помечаются связанные ссылками объекты, а затем удаляются недостижимые
- Сборщик мусора с подсчётом ссылок: для каждого объекта в куче ведётся счётчик ссылок на него — если счётчик достигает нуля, то память высвобождается. Данный алгоритм в чистом виде не способен корректно обрабатывать циклические ссылки объекта на самого себя. Сборщик мусора с подсчётом ссылок, вместе с дополнительными ухищрениями для выявления и обработки циклических ссылок, используется, например, в PHP, Perl и Python. Этот алгоритм сборки мусора так же может быть использован и в C++;
Получение ресурса есть инициализация (RAII)
RAII — это программная идиома в ООП, смысл которой заключается в том, что выделяемая для объекта область памяти строго привязывается к его времени существования. Память выделяется в конструкторе и освобождается в деструкторе. Данный подход был впервые реализован в C++, а так же используется в Ada и Rust.
Автоматический подсчёт ссылок (ARC)
Данный подход весьма похож на сборку мусора с подсчётом ссылок, однако, вместо запуска процесса подсчёта в определённые интервалы времени, инструкции выделения и освобождения памяти вставляются на этапе компиляции прямо в байт-код. Когда же счётчик ссылок достигает нуля, память освобождается как часть нормального потока выполнения программы.
Автоматический подсчёт ссылок всё так же не позволяет обрабатывать циклические ссылки и требует от разработчика использования специальных ключевых слов для дополнительной обработки таких ситуаций. ARC является одной из особенностей транслятора Clang, поэтому присутствует в языках Objective-C и Swift. Так же автоматический подсчет ссылок доступен для использования в Rust и новых стандартах C++ при помощи умных указателей.
Владение
Это сочетание RAII с концепцией владения, когда каждое значение в памяти должно иметь только одну переменную-владельца. Когда владелец уходит из области выполнения, память сразу же освобождается. Можно сказать, что это примерно как подсчёт ссылок на этапе компиляции. Данный подход используется в Rust и при этом я не смог найти ни одного другого языка, который бы использовал подобный механизм.
В данной статье были рассмотрены основные концепции в сфере управления памятью. Каждый язык программирования использует собственные реализации этих подходов и оптимизированные для различных задач алгоритмы. В следующих частях, мы подробнее рассмотрим решения для управления памятью в популярных языках.
Читайте так же другие части серии:
- > Часть 1: Введение в управление памятью
- Part 2: Memory management in JVM(Java, Kotlin, Scala, Groovy)
- Part 3: Memory management in V8(JavaScript/WebAssembly)
- Part 4: Memory management in Go (in progress)
- Part 5: Memory management in Rust (in progress)
- Part 6: Memory management in Python (in progress)
- Part 7: Memory management in C++ (in progress)
- Part 8: Memory management in C# (in progress)
Ссылки
- http://homepages.inf.ed.ac.uk
- https://javarevisited.blogspot.com
- http://net-informations.com
- https://gribblelab.org
- https://medium.com/computed-comparisons
- https://en.wikipedia.org/wiki/Garbage*collection*(computer_science)
- https://en.wikipedia.org/wiki/Automatic_Reference_Counting
- https://blog.sessionstack.com
Если вам понравилась статья, пожалуйста, поставьте плюс или напишите комментарий.
Вы можете подписаться на автора статьи в Twitter и на LinkedIn.
Иллюстрации:
Визуализация стека сделана с помощью pythontutor.
Иллюстрация концепции владения: Link Clark, The Rust team под Creative Commons Attribution Share-Alike License v3.0.
За вычитку перевода отдельное спасибо Александру Максимовскому и Катерине Шибаковой



QtRoS
Про стек я бы ещё добавил, что в случае с примитивными типами данных никакой очистки не требуется — по выходу из функции указатель стека меняется, значения остаются где были, и затем естественным образом перезаписываются следующим вызовом. Или просто остаются там лежать в роли т.н. "мусора со стека".