
Не знаю как вы, а я люблю ковыряться в кишочках разных систем. И в этой статье хочу рассказать о внутреннем устройстве Lua-таблиц и их особенностях. Lua — мой основной язык программирования по долгу службы, и чтобы писать хороший код, надо хоть немного понимать, что происходит за кулисами. Любопытных прошу за мной.
У Lua есть несколько реализаций и несколько версий. В статье речь пойдёт в основном о LuaJIT 2.1.0, которая используется в Tarantool. Наша версия немного пропатчена по сравнению с аутентичным LuaJIT'ом, но таблиц эти отличия не касаются.
Про таблицы в имплементации PUC-Rio есть другая хорошая презентация [1], если вам интересно.
Ликбез
Таблицы в Lua — единственный композитный тип данных, призванный подойти для любых целей. Таблицу можно использовать и как массив (если ключи целочисленные), или как key-value хранилище. В качестве ключа могут использоваться значения любого типа (кроме nil). Говоря научным языком, таблица — это ассоциативный массив [2].
-- Empty table
local t1 = {}
-- Table as an array
local t2 = { 'Sunday', 'Monday', 'Im tired' }
-- Table as a hashtable
local t3 = {
cat = 'meow',
dog = 'woof',
cow = 'moo',
}
-- Ordered map
local t4 = {
'k1', 'k2', 'k3' -- stored in the array part
['k1'] = 'v1', -- stored in the hash part
['k2'] = 'v2', -- stored in the hash part
['k3'] = 'v3', -- stored in the hash part
}Анатомия таблиц
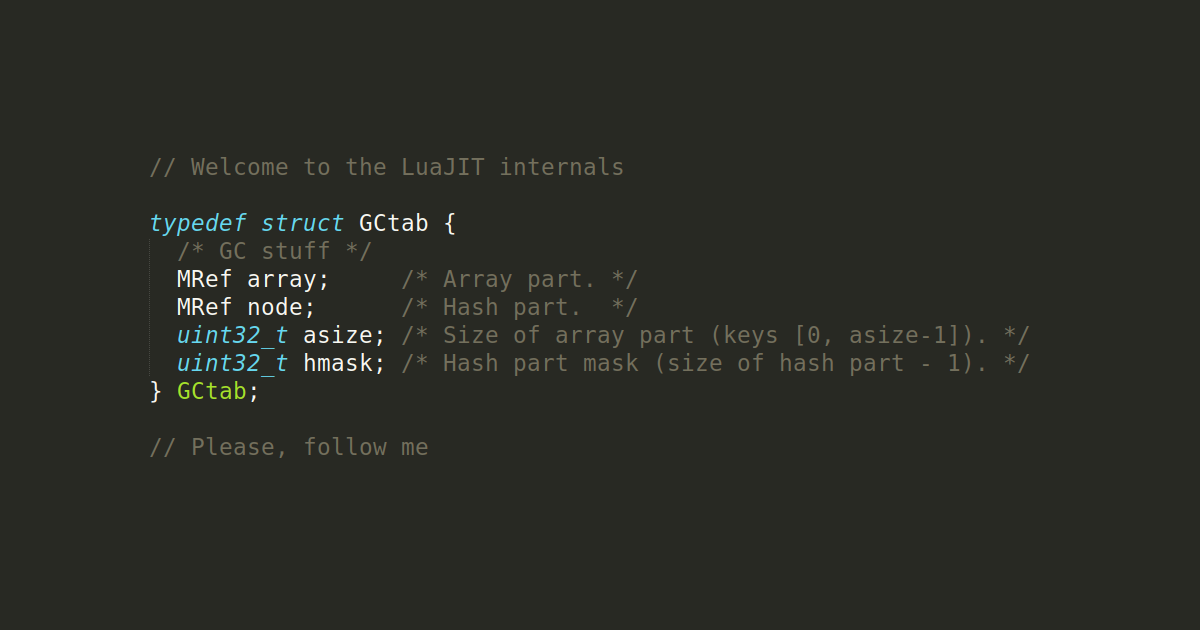
В исходниках LuaJIT [3] таблица представляется следующей структурой (часть полей, не относящиеся к теме, я опустил для простоты):
typedef struct GCtab {
/* GC stuff */
MRef array; /* Array part. */
MRef node; /* Hash part. */
uint32_t asize; /* Size of array part (keys [0, asize-1]). */
uint32_t hmask; /* Hash part mask (size of hash part - 1). */
} GCtab;У таблицы есть две части: массив и хеш-мап. Оба представлены непрерывными участками памяти. Я хотел было описать, какой логикой LuaJIT руководствуется при вставке новых элементов, но алгоритм этот достаточно сложный. Более того, мне, как разработчику на Lua, нет нужды строить догадки о том, как таблица выглядит изнутри. Важно другое: две таблицы могут содержать одни и те же ключи и значения, но отличаться внутренним представлением. И это внутреннее представление будет влиять на поведение некоторых функций, о чём я расскажу далее.
Для демонстрации я взял исходники LuaJIT и немного пропатчил метод tostring(), чтобы он распечатывал размер и всё содержимое сишной структуры в stdout при помощи printf().
Самую полную версию кода из публикации, включая все эксперименты, можно найти на гитхабе [4]. Концептуально код выглядит так:
diff --git a/src/lj_strfmt.c b/src/lj_strfmt.c
index d7893ce..45df53c 100644
--- a/src/lj_strfmt.c
+++ b/src/lj_strfmt.c
@@ -392,6 +392,51 @@ GCstr * LJ_FASTCALL lj_strfmt_obj(lua_State *L, cTValue *o)
if (tvisfunc(o) && isffunc(funcV(o))) {
p = lj_buf_wmem(p, "builtin#", 8);
p = lj_strfmt_wint(p, funcV(o)->c.ffid);
+ } else if (tvistab(o)) {
+ GCtab *t = tabV(o);
+ /* print array part */
+ printf("-- a[%d]: ", asize);
+ for (i = 0; i < asize; i++) {
+ // printf(...);
+ }
+
+ /* print hashmap part */
+ printf("-- h[%d]: ", hmask+1);
+ for (i = 0; i <= hmask; i++) {
+ // printf(...);
+ }
} else {
p = lj_strfmt_wptr(p, lj_obj_ptr(o));
}Давайте я покажу, как это работает:
t = {}
tostring(t)
-- table: 0x40eae3a8
-- a[0]:
-- h[1]: nil=nilМы создали пустую таблицу, и LuaJIT выделил память под 0 элементов массива и 1 элемент в хеш-мапе, в которую положил ключ nil и значение nil (т.е. ничего). Теперь попробуем эту таблицу наполнить:
t["a"] = "A"
t["b"] = "B"
t["c"] = "C"
tostring(t)
-- table: 0x40eae3a8
-- a[0]:
-- h[4]: b=B, nil=nil, a=A, c=CСтроковые ключи, как и следовало ожидать, добавляются в хеш-мап. Здесь уже можно разглядеть первую причину, по которой внутреннее представление таблиц может отличаться — коллизии хешей. Для разрешения коллизий LuaJIT использует открытую адресацию [5] гибрид открытой адресации и метода цепочек [5а] (спасибо Игорю Мунькину за разъяснения).
В зависимости от того, в каком порядке элементы добавлялись в таблицу, их порядок при итерировании будет отличаться. Для демонстрации я завёл ещё одну вспомогательную функцию traverse(), которая проходится по таблице циклом for и распечатывает её содержимое.
Полную версию кода по-прежнему можно найти на гитхабе [4]. Здесь я ради краткости демонстрирую только принцип его работы.
function traverse(fn, t)
local str = ''
for k, v, n in fn(t) do
str = str .. string.format('%s=%s ', k, v)
end
print(str)
endt1 = {a = 1, b = 2, c = 3}
tostring(t1)
-- table: 0x40eaeb08
-- a[0]:
-- h[4]: b=2, nil=nil, a=1, c=3
t2 = {c = 3, b = 2, a = 1}
tostring(t2)
-- table: 0x40ea7e70
-- a[0]:
-- h[4]: b=2, nil=nil, c=3, a=1
traverse(pairs, t1)
-- b=2, a=1, c=3
traverse(pairs, t2)
-- b=2, c=3, a=1И вот ещё один интересный факт о внутренней кухне таблиц: удаление значения не приводит к удалению ключа. Звучит немного по-капитански, но это так.
t2["c"] = nil
traverse(pairs, t2)
-- b=2, a=1
tostring(t2)
-- table: 0x411c83c0
-- a[0]:
-- h[4]: b=2, nil=nil, c=nil, a=1
print(next(t2, "c"))
-- aТак сделано специально, чтобы можно было удалять значения в цикле не нарушая порядок итерирования. А вот добавлять в таблицу новые ключи внутри цикла настоятельно не рекомендуется — может произойти реаллокация или рехешинг, и тогда итерация собьётся.
Дополнение от Игоря Мунькина: причина не в итерировании, а в lookup'е вообще. Коллизии разрешаются методом цепочек. В общем случае при удалении main node для искомого ключа, необходимо перевесить ссылку коллидирующего элемента на predecessor этой main ноды (в случае его наличия). Задача его поиска O(n), которую необходимо выполнять при удалении. При этом стоимость поиска при наличии dead node на пути разрешения коллизии не ухудшается. См. также [5а].
Массивы
Ладно, с итерацией по строковым ключам всё понятно, с них спросу нет. Давайте теперь поговорим о второй половине таблицы — о массиве:
t = {1, 2}
tostring(t)
-- table: 0x41735918
-- a[3]: nil, 1, 2
-- h[1]: nil=nilНад Lua часто шутят за то, что индексация в языке начинается с единицы. Интересно то, что LuaJIT всё равно выделяет память под нулевой элемент. Ему так проще избежать многократного добавления / вычитания единички.
Если вам кажется, что с массивами никаких сюрпризов быть не может, то спешу вас огорчить (или обрадовать) — может:
t = {[2] = 2, 1}
tostring(t)
-- table: 0x416a3998
-- a[2]: nil, 1
-- h[2]: nil=nil, 2=2Я немного изменил синтаксис, и один элемент элемент попал в массив, а второй в хеш-мапу. В общем, я предупредил: бесполезно делать предположения о внутреннем представлении, они будут нарушены в любой момент.
Ответ: интерпретатор LuaJIT, как и обычный Lua, генерирует в двух этих случаях разный байткод.
В первом случае место аллоцируется под два элемента массива, что логично.
$ luac -l - <<< "t1 = {1, 2}"
1 [1] NEWTABLE 0 2 0 -- 2 в массив, 0 в хеш-мап
...Во втором — по 1 элементу в массиве и в хеш-мапе.
$ luac -l - <<< "t2 = {[2] = 2, 1}"
1 [1] NEWTABLE 0 1 1 -- 1 в массив, 1 в хеш-мап
...И всё же, меня, как разработчика, заботит в первую очередь корректность моего кода. Если LuaJIT удобно представлять таблицы по-разному, это его право. Главное, чтобы я этого не замечал. Поэтому предлагаю пробежаться по функциям и проговорить ожидания.
Итератор pairs()
Итератор pairs() уже упоминался выше. Он не гарантирует порядок итерации. Даже в массиве. Изнутри LuaJIT pairs() проходит последовательно сначала по массиву, потом по хеш-мапе. Так что если числовые ключи каким-то образом попадут в хеш-мапу, то порядок итерации будет нарушен:
t = table.new(4, 4)
for i = 1, 8 do t[i] = i end
tostring(t)
-- table: 0x412c6df0
-- a[5]: nil, 1, 2, 3, 4
-- h[4]: 7=7, 8=8, 5=5, 6=6
traverse(pairs, t)
-- 1=1, 2=2, 3=3, 4=4, 7=7, 8=8, 5=5, 6=6Ответ: Функция table.new(narr, nrec) преаллоцирует память в нужном количестве — это биндинг стандартной функции lua_createtable(L, a, h) из Lua C API. Если размер таблицы известен заранее (например, при копировании), то этим можно сэкономить на реаллокациях во время её последующего наполнения.
Этот фокус работает исключительно благодаря преаллокации. Добавление в таблицу ещё одного элемента и последующий рехешинг (достаточно дорогая и сложная операция) лишит таблицу всей её загадочности:
t[9] = 9
tostring(t)
-- table: 0x411e1e30
-- a[17]: nil, 1, 2, 3, 4, 5, 6, 7, 8, 9, nil, nil, nil, nil, nil, nil, nil
-- h[1]: nil=nilЯ ни в коем случае не хочу показаться параноиком и сам считаю этот пример весьма неправдоподобным. В 99.9 % случаев "массивы" в Lua действительно будут представлены массивами, и порядок итерации будет последовательным.
Длина таблицы table.getn()
Куда чаще ошибки возникают из-за неправильно вычисленной длины массива. Главное, что о ней нужно знать — это определение из спецификации Lua [6].
3.4.6 – The Length Operator
The length of a table t is only defined if the table is a sequence, that is,
the set of its positive numeric keys is equal to {1..n} for some non-negative
integer n. In that case, n is its length. Note that a table like
{10, 20, nil, 40}
is not a sequence, because it has the key 4 but does not have the key 3. (So,
there is no n such that the set {1..n} is equal to the set of positive numeric
keys of that table.) Note, however, that non-numeric keys do not interfere with
whether a table is a sequence.Иными словами, не каждая таблица обладает свойством длины. Сюрприз — в Lua бывает undefined behavior. У таблиц с "дырками" попросту нет такого свойства. В имплементации LuaJIT функция lj_tab_len [7] прокомментирована следующим образом:
/*
** Try to find a boundary in table `t'. A `boundary' is an integer index
** such that t[i] is non-nil and t[i+1] is nil (and 0 if t[1] is nil).
*/
MSize LJ_FASTCALL lj_tab_len(GCtab *t);LuaJIT ищет в таблице "границу". Если в массиве есть пропущенные значения, а значит границ существует несколько, то LuaJIT в зависимости от обстоятельств может найти любую из них, и будет прав:
print(#{nil, 2})
-- 2
print(#{[2] = 2})
-- 0Ответ: Эти две таблицы отличаются внутренним представлением.
tostring({nil, 2})
-- table: 0x410d5528
-- a[3]: nil, nil, 2
-- h[1]: nil=nil
tostring({[2] = 2})
-- table: 0x410d5810
-- a[0]:
-- h[2]: nil=nil, 2=2LuaJIT ищет границу бинарным поиском, и первым делом проверяет последний элемент массива. Если он существует, поиск переходит в хеш-мапу, иначе продолжается в массиве.
И вот это уже не паранойя, прецеденты ошибок были. Длина таблицы неявно используется в других функциях, так что с undefined behavior лучше не шутить. Справедливости ради стоит отметить, что на массивах без дырок поведение строго детерминировано и от внутреннего представления не зависит.
Сортировка table.sort()
Сортировка таблиц всегда работает в диапазоне от 1 до #t, и нет никакого способа на это повлиять. Поэтому в тех функциях, которые работают с таблицей как с массивом, полезно проверять входные значения:
local function is_array(t)
if type(t) ~= 'table' then
return false
end
local i = 0
for _, _ in pairs(t) do
i = i + 1
if type(t[i]) == 'nil' then
return false
end
end
return true
endLua, правда, допускает существование длины даже при наличии строковых ключей, но коль речь идёт о типичных контрактах функций, от гибридных таблиц редко бывает толк.
Pack / unpack
А откуда вообще берутся массивы с дырками? Казалось бы, это какой-то редкий извращённый случай. Но нет, опасности подстерегают на каждом шагу:
local function vararg(...)
local args = {...}
-- #args == undefined behavior
endМноготочие здесь — не эллипсис, а обозначение переменного количества аргументов функции.
Потом кто-то вызывает эту функцию с аргументами vararg(nil, "err"), и вот уже ваша функция держит в руках дырявый массив. Если после этого вызвать unpack(t), то хвост может отвалиться (а может и нет, зависит от везения, это ведь UB).
Спецификация Lua [8] говорит следующее:
6.5 – Table Manipulation
unpack (list [, i [, j]])
Returns the elements from the given table. This function is equivalent to
return list[i], list[i+1], ···, list[j]
except that the above code can be written only for a fixed number of elements.
By default, i is 1 and j is the length of the list, as defined by the length
operator #list.Чтобы нечаянно не лишиться хвоста, вместо неявного unpack(t, 1, #t) всегда стоит явно писать unpack(t, 1, n), но где взять это n? Ответ на этот вопрос зависит от того, как такая таблица попала к вам в руки. Если из varargs, то можно использовать метод table.pack(), который возвращает гибрид:
t = table.pack(nil, 2)
tostring(t)
-- table: 0x41053540
-- a[3]: nil, nil, 2
-- h[2]: nil=nil, n=2
traverse(pairs, t)
-- 2=2, n=2
print(unpack(t, 1, t.n))
-- nil, 2 -- Всё нормально, это не UBВ LuaJIT (и в Tarantool) функция table.pack по-умолчанию недоступна, но её можно включить флагом компилятора -DLUAJIT_ENABLE_LUA52COMPAT. Но ещё проще реализовать эту функциональность самостоятельно:
function table.pack(...)
return {..., n = select('#', ...)}
endЗдесь уже используется чёрная магия select('#', ...) [9], но подробное описание её механики в этой статье не поместится. Я лишь намекну, что это касается стека Lua [10] — того механизма, который обеспечивает взаимодействие Lua и C (Lua C API). А нам пора двигаться дальше.
Итератор ipairs()
А вот это — хороший оператор. Достаточно предсказуемый. Об ipairs следует думать, как о сокращённой версии такого цикла while:
local i = 1
while type(t[i]) ~= 'nil' do
-- do something
i = i + 1
endНикакие отличия внутреннего представления на него повлиять не могут, и "дырки" не приводят к undefined behavior — итерация просто прекращается.
t = {1, 2, nil, 4}
print(#t) -- UB
-- 4
traverse(ipairs, t) -- Not UB
-- 1=1, 2=2Подводные камни FFI
Внимательный читатель мог заметить, что я уже два раза использовал странное выражение type(x) ~= 'nil'. Почему не просто x == nil? Причина этому в том, что в LuaJIT, в отличие от PUC-Rio Lua, есть волшебный тип cdata:
ffi = require('ffi')
NULL = ffi.new('void*', nil)
print(type(NULL))
-- cdata
print(type(nil))
-- nil
print(NULL == nil)
-- true
if NULL then print('NULL is not nil') end
-- NULL is not nilЭто знаменитая грабля в Tarantool, именуемая box.NULL. Обратите внимание — условие if NULL интерпретируется истинно (в отличие от if nil), несмотря на NULL == nil.
Ещё одна мина в LuaJIT — это использование FFI типов в качестве ключа таблицы. Эта тема совсем не часто обсуждается в мануалах по Lua, потому что никаких FFI типов в ванильном Lua нет. Но LuaJIT может преподнести сюрприз и прострелить колено. Вот, что на этот счёт говорит документация [11]:
Lua tables may be indexed by cdata objects, but this doesn't provide any useful
semantics — cdata objects are unsuitable as table keys!
A cdata object is treated like any other garbage-collected object and is hashed
and compared by its address for table indexing. Since there's no interning for
cdata value types, the same value may be boxed in different cdata objects with
different addresses. Thus t[1LL+1LL] and t[2LL] usually do not point to the
same hash slot and they certainly do not point to the same hash slot as t[2].Переводя на русский язык, у cdata-ключей хеш считается от указателя (читай void*), поэтому ведут они себя непредсказуемо, и на практике стоит всеми силами их избегать. Анекдот из жизни Tarantool:
tarantool> t = {1}; t[1ULL] = 2; t[1ULL] = 3;
---
...
tarantool> t
---
- 1: 1
1: 3
1: 2
...
tarantool> t[1ULL]
---
- null
...
Я надеюсь, никто в здравом уме не станет писать такое в коде, но cdata встречается не так уж редко, и прецеденты были. В качестве примера можно привести uuid [12] и clock.time64() из Tarantool. Или большие значения, хранящиеся в спейсах в unsigned формате.
И раз уж об этом зашла речь, получить неожиданные результаты можно и без использования FFI, хотя такого на практике я не встречал:
tarantool> t = {'normal one'}
t[1.0 + 2^-52] = '1.0 + 2^-52'
t[0.1 + 0.3*3] = '0.1 + 0.3*3'
---
...
tarantool> t
---
- 1: normal one
1: 1.0 + 2^-52
1: 0.1 + 0.3*3
...Повторение изученного
- Оператор длины таблицы
#tдетерминирован только на массивах без дырок. Остальное — Undefined behavior. - Функция
ipairs()итерируетсяwhile type(t[i]) ~= 'nil'— не по всем ключам, зато предсказуемо, и порядок гарантирован. - Функция
pairs()итерируется по всем ключам, но на порядок итерации влияет внутреннее представление таблицы. - Функции
unpack,table.sort,table.insert,table.remove, будучи вызванными с аргументами по-умолчанию, таят в себе undefined behavior благодаря#t. - Использование "странных" (ffi) значений в ключах таблицы даёт массу способов выстрелить себе в ногу. Их надо избегать.
Ссылки
[1] The basics and design of Lua table (или то же самое на slideshare.net).
[2] Programming in Lua — Tables
[3] GitHub — LuaJIT/LuaJIT — lj_obj.h
[4] GitHub — rosik/luajit:habr-luajit-tables
[5] Википедия — Хеш-таблица — Открытая адресация
[5a] GitHub — LuaJIT/LuaJIT — Issue #494.
[6] Lua 5.2 Reference manual — The Length Operator
[7] GitHub — LuaJIT/LuaJIT lj_tab.c
[8] Lua 5.1 Reference manual — Basic Functions — unpack
[9] Lua 5.1 Reference manual — Basic Functions — select
[10] Lua 5.1 Reference manual — The Stack
[11] GitHub — LuaJIT/LuaJIT — ext_ffi_semantics.html
[12] Tarantool » 2.2 » Reference » Built-in modules reference » Module uuid
[Bonus] Learn X in Y Minutes, where X=Lua
[Bonus] Хабр — Lua. Краткое введение в метатаблицы для чайников



mikeus
Прикольно. Исходя из здравого смысла я считал что варианты:
должны были бы давать одинаковое внутреннее представление таблиц (все с помощью массива).Тип
cdataв LuaJIT этоuserdataв ванильном Lua?Rosik Автор
А получается, что все три случая дают разный результат.
Deosis
А есть способ отличить такие таблицы в стандартном языке?
Если эти таблицы использовать в качестве ключа другой таблицы, то какой будет результат?
mikeus
Три самостоятельных ключа. Различные инстансы (объекты) таблиц сами по себе различны независимо от содержания
Rosik Автор
mikeus дело говорит. Идентичность таблиц проверяется по указателю — это те самые
table: 0x4082dfa8в статье. Иными словамиИ при поиске ключа поведение будет то же самое.
Rosik Автор
Userdata в LuaJIT никуда не делась, это часть спецификации языка.
Cdata — явление исключительно LuaJIT. В ванильном Lua его аналогов нет.