
Для Ruby и Ruby on Rails разработчиков уровня Junior+, Middle
Мы часто пишем код, не вникая, сколько ресурсов уйдет на его выполнение. И это может быть ок. Но, во-первых, каждый нормальный разработчик старается становиться лучше и раскачивает свои скилы. Во-вторых, это легко может обернуться реальным багом с абсолютно не очевидными корнями, и вопрос-таки придется решать.
Загадочный баг
В моем случае эта проблема проявилась, когда девопсы перевели нашу CRM систему в Kubernetes. В ней перестал формироваться Excel отчет по заявкам, если задать ему временную выборку хотя бы за месяц. Sidekiq в какой-то момент просто прекращал выполнение джобы, не возвращая ошибок (хотя код сервиса предусматривает и запись exception-ов, и изменение статуса экспорта). Модель экспорта у нас просто зависала в статусе ‘in_progress’, но Sidekiq прекращал выполнять работу, никого в известность не ставя.
Забегая вперед, скажу, что причина оказалась в новых настройках контейнеров, которым девопсы жестко ограничили допустимое использование памяти, и если процесс выходил за рамки, то он просто тихо убивался. Таким образом, слишком грузные экспорты зависали в CRM, якобы в прогрессе, а пользователи ничего не могли поделать.
Не действуем "наощупь"
Оптимизировать "наугад" — вообще плохая идея. Чтобы понимать, есть ли в наших действиях какой-то толк, сформируем метрику. Для измерения памяти воспользуемся гемом benchmark-memory, и напишем нехитрый метод:
def benchmark_memory(&block)
Benchmark.memory do |x|
x.report('') do
yield
GC.start(full_mark: true, immediate_sweep: true) # принудительный запуск Garbage Collector'а, чтобы минимизировать разброс в результатах
end
end
endОбратите внимание на вызов Garbage Collector в конце. Не подчищенный «мусор» очень любит раздувать память. А эффективность работы GC сильно зависит от версии Ruby чем новее, тем лучше и быстрее он работает. Но нам, чтобы измерять проводимые оптимизации, нужен стабильный результат. Вот, например, как наш метод оценил бы экспорт 100 заявок без вызова GC:
Экспорт 100 заявок в один раз
50.966M memsize ( 1.445M retained)
850.405k objects ( 24.514k retained)
50.000 strings ( 50.000 retained)
Экспорт 100 заявок в другой раз
80.554M memsize ( 920.363k retained)
1.303M objects ( 17.565k retained)
50.000 strings ( 50.000 retained)В общем, включаем в методе запуск Garbage Collector’а, и теперь мы сможем легко измерить потребление памяти для любого процесса:
benchmark_memory { puts 1 }
Calculating -------------------------------------
1
464.000 memsize ( 0.000 retained)
2.000 objects ( 0.000 retained)
0.000 strings ( 0.000 retained)Здесь мы видим, что для простого вывода единицы в консоль нам требуется 464 байта.
Результаты для исходной реализации нашего экспорта выглядели так:
Экспорт 100 заявок:
1.482M memsize ( 1.480M retained)
24.814k objects ( 24.793k retained)
50.000 strings ( 50.000 retained)
Экспорт 1000 заявок:
12.811M memsize ( 12.809M retained)
226.587k objects ( 226.556k retained)
50.000 strings ( 50.000 retained)Для 100 заявок требуется полтора мегабайта, для 1000 заявок — почти в десять раз больше. Налицо линейная асимптотика — чем больше исходные данные, тем больше потребляемая память. Звучит логично, но это и есть, так называемое, раздувание памяти (ссылка на подробный материал об этом ниже). Получается, для корректной работы программы мы должны заранее учесть возможные ограничения на обращение к сервису экспорта, нас это не устраивает.
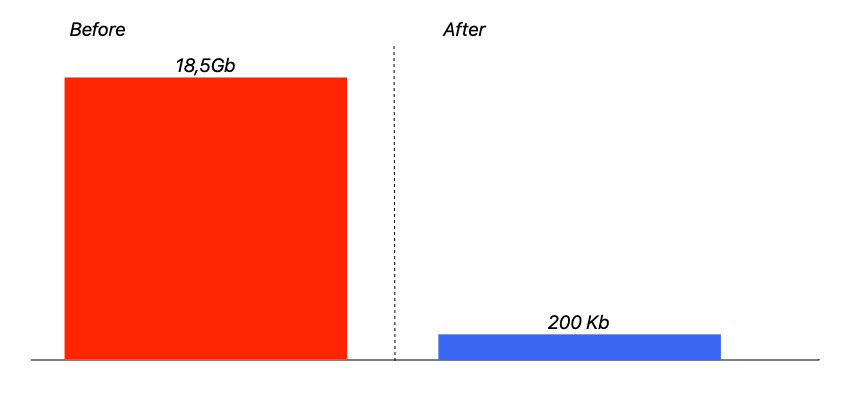
Кстати, из полученных данных мы можем примерно оценить, сколько памяти требовал от контейнера наш сервис на проде, когда убивался воркер сайдкика. Возьмем минимальный по потреблению памяти без Garbage Collector’а результат для 100 заявок — 50 Мб (отбросим даже дробную часть), то есть 500 Мб для 1000. В зависшей выборке было 38_000 заявок — значит потенциально сервис может "раздуть" потребление памяти до 18,5 Гб! (38 * 500 = 19_000 Мб =~ 18,5 Гб).
Как оптимизировать потребление памяти?
Оптимизация 1: Формат отчета
Первое, что пришло в голову — это изменить формат отчета, и перейти с xlsx на csv. Спросил у «бизнеса», оказалось, им без разницы. В итоге, такой мизерной «оптимизации» оказалось достаточно, чтобы на 40% сократить потребление памяти:
Экспорт 100 заявок в xlsx:
1.482M memsize ( 1.480M retained)
24.814k objects ( 24.793k retained)
50.000 strings ( 50.000 retained)
Экспорт 100 заявок в csv:
852.195k memsize ( 849.968k retained)
12.034k objects ( 12.007k retained)
50.000 strings ( 50.000 retained)Оптимизация 2: потоковая запись файла
Весь процесс формирования отчета можно изобразить такой схемой:
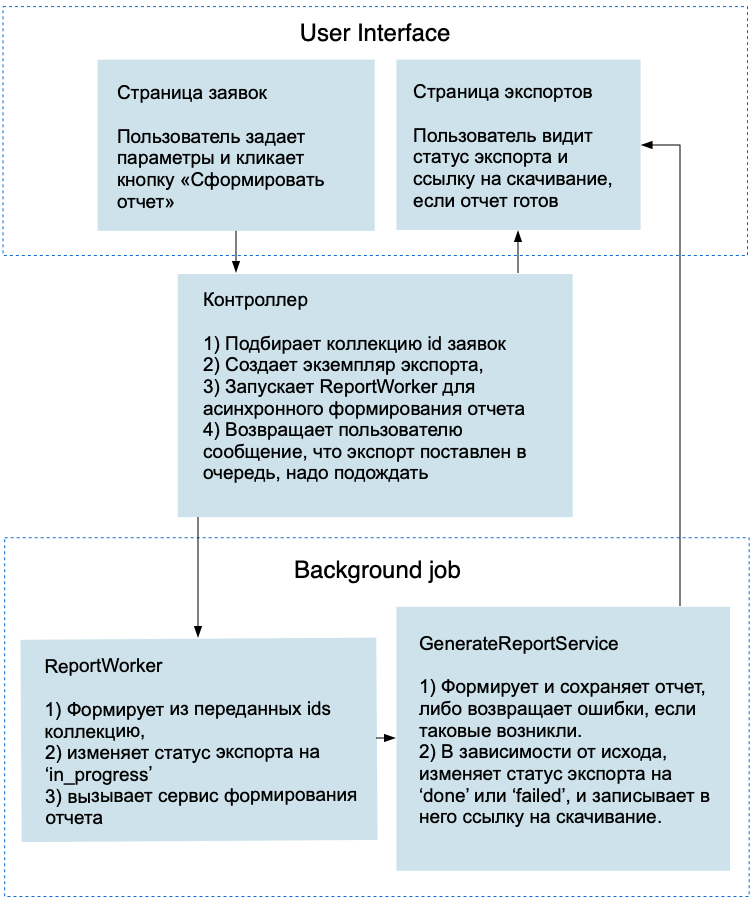
В принципе, уже при взгляде на нее не сложно догадаться, где раздувается память. В ReportWorker’е мы целиком формируем пулл объектов и передаем его наш сервис. Но можно попробовать записывать данные в потоковом режиме. Если передавать в сервис только массив айдишников, мы можем использовать в нем такой метод для формирования коллекции:
def export_collection(objects_ids)
Application.where(id: objects_ids.uniq).order(created_at: :desc)
endНо как сделать так, чтобы результаты запроса к базе не загружались в память целиком, а обрабатывались по очереди? Тут нам поможет метод ActiveRecord find_each:
def to_csv_export(objects_ids)
CSV.open(file_path, 'w') do |csv|
csv << export_headers # массив с заголовками отчета
export_collection(objects_ids).find_each do |application| # Не загружаем объекты в память, а итерируемся по ним поочередно
begin
csv << export_row(application.decorate) # метод для формирования строки отчета
rescue StandardError => e
errors << "#{application.id}: #{e}"
end
end
end
endВ итоге, следующий замер потребления памяти показал такие результаты:
Для 100 заявок:
166.688k memsize ( 165.445k retained)
1.729k objects ( 1.715k retained)
50.000 strings ( 50.000 retained)
Для 1000 заявок:
167.510k memsize ( 166.227k retained)
1.734k objects ( 1.719k retained)
50.000 strings ( 50.000 retained)То есть, как мы и ожидали, память не раздувается, независимо от того, какое количество заявок мы хотим выгрузить в файл.
Заключение:
Итак, парочка достаточно простых оптимизаций, — и отчет, который раньше требовал 18,5 Гб, теперь укладывается менее чем в 200 Кб. Можно было и эту цифру сократить, например, выгружая из базы данных не весь объект целиком, а лишь те поля, которые нам нужны. Но в нашем случае пришлось бы сильно пожертвовать читабельностью кода, а заданный бюджет и так вполне устраивает, поэтому оптимизировать память дальше я не стал. А вот скорость оставляла желать лучшего. Но о том, как мы справились с этой проблемой, я расскажу вам в следующем посте.
Спойлер: скорость нам удалось увеличить в 170 раз, и сократить время формирования отчета с нескольких часов до одной минуты



osmanpasha
Спасибо, было интересно.
Ruvaleev Автор
1) Я просто попытался воспроизвести в командной строке на сервере вызов сервиса с заданными параметрами, и меня выбрасывало из консоли со 137 ошибкой. Сделали вывод, что дело в памяти (уже с подобным сталкивались)
2) Сам отчет весил несколько мегабайт, может десятки. Запрос, на самом деле, я почти не оптимизировал, только перенес его из одного места в другой, и применил `find_each`. Но вообще память в Ruby раздувается достаточно легко, и самое главное — совсем не умеет «сдуваться» обратно ) Подробней о памяти можно вот в этом посте почитать что раздувает память в Ruby