

Доброго времени суток, друзья!
В этой статье объясняются некоторые концепции из теории музыки, на основе которых работает Web Audio API (WAA). Зная эти концепции, вы сможете принимать взвешенные решения при проектировании аудио в приложении. Статья не сделает вас опытным инженером по звуку, но поможет понять, почему WAA работает так, как работает.
Аудио схема
Суть WAA заключается в выполнении некоторых операций со звуком внутри аудио контекста (audio context). Этот API был специально разработан для модульной маршрутизации (modular routing). Основные операции со звуком представляют собой узлы (audio nodes), связанные между собой и формирующие схему маршрутизации (audio routing graph). Несколько источников — с разными типами каналов — обрабатываются внутри единого контекста. Такая модульная схема обеспечивает необходимую гибкость для создания сложных функций с динамическими эффектами.
Аудио узлы связаны между собой через входы и выходы, формируют цепь, которая начинается от одного или нескольких источников, проходит через один или несколько узлов, и заканчивается в пункте назначения (destination). В принципе, можно обойтись и без пункта назначения, например, если мы хотим просто визуализировать некоторые аудио данные. Типичный рабочий процесс для веб аудио выглядит примерно так:
- Создаем аудио контекст
- Внутри контекста создаем источники — такие как <audio>, осциллятор (генератора звука) или поток
- Создаем узлы эффектов, такие как реверберация, биквадратный фильтр, паннер или компрессор
- Выбираем пункт назначения для аудио, такой как колонки компьютера пользователя
- Устанавливаем соединение между источниками через эффекты к пункту назначения

Обозначение канала
Количество доступных аудио каналов часто обозначается в числовом формате, например, 2.0 или 5.1. Это называется обозначением канала. Первая цифра означает полный диапазон частот, которые включает сигнал. Вторая цифра означает количество каналов, зарезервированных для выходов низкочастотного эффекта — сабвуферов.
Каждый вход или выход состоит из одного или более каналов, построенных по определенной аудио схеме. Существуют различные дискретные структуры каналов, такие как моно, стерео, квадро, 5.1 и т.д.
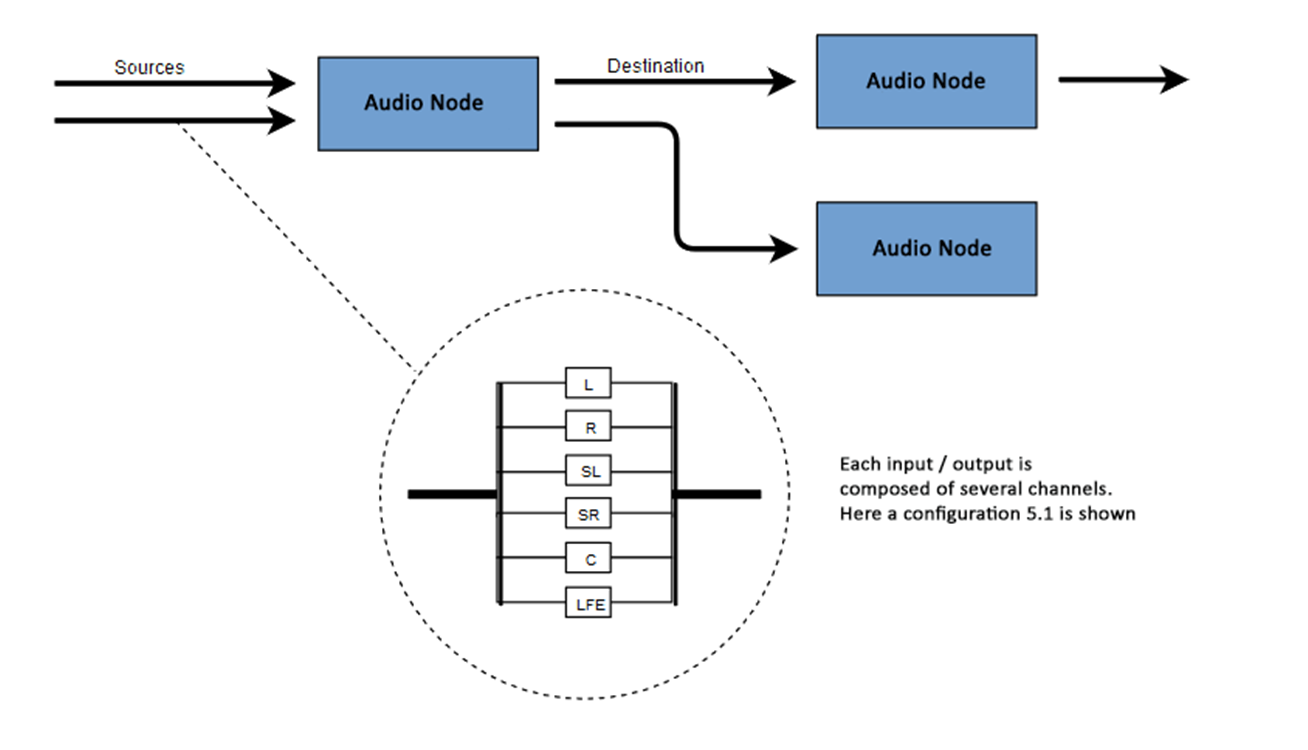
Аудио источники могут быть получены разными способами. Звук может быть:
- Сгенерирован JavaScript-кодом посредством аудио узла (такого как осциллятор)
- Создан из необработанных данных с помощью ИКМ (импульсно-кодовой модуляции)
- Получен из медиа элементов HTML (таких как <video> или <audio>)
- Получен из медиа потока WebRTC (такого как вебкамера или микрофон)
Аудио данные: что находится в семпле
Семплирование означает преобразование непрерывного сигнала в дискретный (разделенный) (аналогового сигнала в цифровой). Другими словами, непрерывная звуковая волна, такая как живой концерт, преобразуется в последовательность семплов, что позволяет компьютеру обрабатывать аудио отдельными блоками.
Аудио буфер: кадры, семплы и каналы
AudioBuffer в качестве параметров принимает количество каналов (1 для моно, 2 для стерео и т.д.), длину — количество кадров семпла внутри буфера, и частоту дискретизации — количество кадров в секунду.
Семпл — это простое 32-битное значение с плавающей точкой (float32), представляющее собой значение аудио потока в конкретный момент времени и в конкретном канале (левый или правый и др.). Кадр или кадр семпла — это набор значений всех каналов, воспроизводимых в определенный момент времени: все семплы всех каналов, воспроизводимые в одно и тоже время (два для стерео, шесть для 5.1 и т.д.).
Частота дискретизации — это количество семплов (или кадров, поскольку все семплы кадра проигрываются в одно время), воспроизводимые за одну секунду, измеряется в герцах (Гц). Чем выше частота, тем лучше качество звука.
Давайте посмотрим на моно и стерео буферы, каждый длиной в одну секунду, воспроизводимые с частотой 44100 Гц:
- Моно буфер будет иметь 44100 семплов и 44100 кадров. Значением свойства «length» будет 44100
- Стерео буфер будет иметь 88200 семплов, но также 44100 кадров. Значением свойства «length» будет 44100 — длина равняется количеству кадров

Когда начинается воспроизведение буфера, мы сначала слышим крайний левый кадр семпла, затем ближайший к нему правый и т.д. В случае стерео, мы слышим оба канала одновременно. Кадры семпла не зависят от количества каналов и предоставляют возможность для очень точной обработки аудио.
Заметка: чтобы получить время в секундах из количества кадров необходимо разделить количество кадров на частоту дискретизации. Чтобы получить количество кадров из количества семплов, делим последние на количество каналов.
Пример:
let context = new AudioContext()
let buffer = context.createBuffer(2, 22050, 44100)
Заметка: в цифровом аудио 44100 Гц или 44.1 кГц — это стандартная частота семплирования. Но почему 44.1 кГц?
Во-первых, потому что диапазон слышимых частот (частот, различимых человеческим ухом) варьируется от 20 до 20000 Гц. Согласно теореме Котельникова частота дискретизации должна более чем в два раза превышать наибольшую частоту в спектре сигнала. Поэтому частота семплирования должна быть больше 40 кГц.
Во-вторых, сигналы должны быть отфильтрованы с помощью фильтра нижних частот перед семплированием, в противном случае будет иметь место наложение спектральных «хвостов» (подмена частот, маскировка частот, алиасинг) и форма восстановленного сигнала будет искажена. В идеале, фильтр нижних частот должен пропускать частоты ниже 20 кГц (без ослабления) и отбрасывать частоты выше 20 кГЦ. На практике требуется некоторая переходная полоса (между полосой пропускания и полосой подавления), где частоты частично ослабляются. Более легким и экономичным способом это сделать является применение противоподменного фильтра. Для частоты дискретизации равной 44.1 кГц переходная полоса составляет 2.05 кГц.
В приведенном примере мы получим стерео буфер с двумя каналами, воспроизводимый в аудио контексте с частотой 44100 Гц (стандарт), длиной 0.5 секунды (22050 кадров / 44100 Гц = 0.5 с).
let context = new AudioContext()
let buffer = context.createBuffer(1, 22050, 22050)
В данном случае мы получим моно буфер с одним каналом, воспроизводимый в аудио контексте с частотой 44100 Гц, произойдет его передискретизация до 44100 Гц (и увеличение кадров до 44100), длиной 1 секунда (44100 кадров / 44100 Гц = 1 с).
Заметка: аудио передискретизация («ресемплирование») очень похоже на изменение размеров («ресайзинг») изображений. Допустим, у нас есть изображение размером 16х16, однако мы хотим заполнить этим изображением область размером 32х32. Мы делаем ресайзинг. Результат будет менее качественным (может быть размытым или рваным в зависимости от алгоритма увеличения), но это работает. Ресемплированное аудио — это тоже самое: мы сохраняем пространство, но на практике едва ли получится добиться высокого качества звучания.
Планарные и чередующиеся буферы
В WAA используется планарный формат буфера. Левый и правый каналы взаимодействуют следующим образом:
LLLLLLLLLLLLLLLLRRRRRRRRRRRRRRRR (для буфера, состоящего из 16 кадров)
В данном случае каждый канал работает независимо от других.
Альтернативой является использование чередующегося формата:
LRLRLRLRLRLRLRLRLRLRLRLRLRLRLRLR (для буфера, состоящего из 16 кадров)
Такой формат часто используется для декодирования MP3.
В WAA используется только планарный формат, поскольку он лучше подходит для обработки звука. Планарный формат преобразуется в чередующийся, когда данные отправляются на звуковую карту для воспроизведения. При декодировании MP3 происходит обратное преобразование.
Аудио каналы
Разные буферы содержат разное количество каналов: от простых моно (один канал) и стерео (левый и правый каналы) до более сложных наборов, таких как квадро и 5.1 с разным количеством семплов в каждом канале, что обеспечивает более насыщенное (богатое) звучание. Каналы обычно представлены аббревиатурами:
| Моно | 0: М: моно |
| Стерео | 0: L: левый 1: R: правый |
| Квадро | 0: L: левый 1: R: правый 3: SL: дополнительный левый (левый канал, создающий окружение; surround left) 4: SR: дополнительный правый (surround right) |
| 5.1 | 0: L: левый 1: R: правый 2: C: центральный 3: LFE: сабвуфер 4: SL: дополнительный левый 5: SR: дополнительный правый |
Смешивание вверх (up-mixing) и вниз (down-mixing)
Когда количество каналов на входе и выходе не совпадает, применяют смешивание вверх или вниз. Смешивание контролируется свойством AudioNode.channelInterpretation:
| Входные каналы | Выходные каналы | Правила смешивания |
|---|---|---|
| Стандартные схемы смешивания каналов — используются, когда свойство channelInterpretation устанавливается для speakers (колонок). | ||
| 1 (Моно) | 2 (Стерео) | Смешивание вверх из моно в стерео. Входной канал М используется для обоих выходных каналов (L и R). output.L = input.M output.R = input.M |
| 1 (Моно) | 4 (Квадро) | Смешивание вверх из моно в квадро. Входной канал М используется для основных каналов (L и R). Дополнительные каналы заглушаются. output.L = input.M output.R = input.M output.SL = 0 output.SR = 0 |
| 1 (Моно) | 6 (5.1) | Смешивание вверх из моно в 5.1. Входной канал М используется для центрального канала ©. Остальные каналы (L, R, LFE, SL и SR) заглушаются. output.L = 0 output.R = 0 output.C = input.M output.LFE = 0 output.SL = 0 output.SR = 0 |
| 2 (Стерео) | 1 (Моно) | Смешивание вниз из стерео в моно. Оба входных канала (L и R) объединяется в один выходной (M). output.M = 0.5 * (input.L + input.R) |
| 2 (Стерео) | 4 (Квадро) | Смешивание вверх из стерео в квадро. Входные каналы L и R используются для основных выходных каналов (L и R). Дополнительные каналы (SL и SR) заглушаются. output.L = input.L output.R = input.R output.SL = 0 output.SR = 0 |
| 2 (Стерео) | 6 (5.1) | Смешивание вверх из стерео в 5.1. Входные каналы L и R используются для основных выходных каналов (L и R). Дополнительные выходные каналы (SL и SR), центральный канал © и сабвуфер (LFE) заглушаются. output.L = input.L output.R = input.R output.C = 0 output.LFE = 0 output.SL = 0 output.SR = 0 |
| 4 (Квадро) | 1 (Моно) | Смешивание вниз из квадро в моно. Все четыре входных канала (L, R, SL и SR) объединяются в один выходной канал (M). output.M = 0.25 * (input.L + input.R + input.SL + input.SR) |
| 4 (Квадро) | 2 (Стерео) | Смешивание вниз из квадро в стерео. Оба левых входных канала (L и SL) объединяются в один выходной левый канал (L). Оба правых (R и SR) — в правый ®. output.L = 0.5 * (input.L + input.SL) output.R = 0.5 * (input.R + input.SR) |
| 4 (Квадро) | 6 (5.1) | Смешивание вверх из квадро в 5.1. Входные каналы L, R, SL и SR используются для соответствующих выходных каналов. Центральный входной канал © и сабвуфер (LFE) заглушаются. output.L = input.L output.R = input.R output.C = 0 output.LFE = 0 output.SL = input.SL output.SR = input.SR |
| 6 (5.1) | 1 (Моно) | Смешивание вниз из 5.1 в моно. Левые (L и SL), правые (R и SR) и центральный (С) входные каналы объединяются в один. Дополнительные каналы ослабляются, мощность основных боковых каналов снижается, что позволяет считать их одним каналом — это достигается путем умножения на v2 / 2. Сабвуфер (LFE) исключается. output.M = 0.7071 * (input.L + input.R) + input.C + 0.5 * (input.SL + input.SR) |
| 6 (5.1) | 2 (Стерео) | Смешивание вниз из 5.1 в стерео. Центральный канал © прибавляется к каждому боковому дополнительному каналу (SL и SR) и смешивается с каждым из основных боковых каналов (L и R). Для снижения мощности каждая комбинация центрального и дополнительного бокового каналов умножается на v2 / 2. Сабвуфер (LFE) исключается. output.L = input.L + 0.7071 * (input.C + input.SL) output.R = input.R + 0.7071 * (input.C + input.SR) |
| 6 (5.1) | 4 (Квадро) | Смешивание вниз из 5.1 в квадро. Центральный канал (С) смешивается с боковыми основными каналами (L и R). В каждой паре снижается мощность центрального канала посредством умножения на v2 / 2. Дополнительные боковые каналы остаются неизменными. Сабвуфер (LFE) исключается. output.L = input.L + 0.7071 * input.C output.R = input.R + 0.7071 * input.C output.SL = input.SL output.SR = input.SR |
| Нестандартные схемы смешивания каналов — используются, когда свойство channelInterpretation устанавливается для discrete. | ||
| любой (x) | любой (y), когда x<y | Дискретизация каналов вверх. Каждый выходной канал объединяется с его входным аналогом (имеющим тот же индекс). Каналы, не имеющие соответствующих входных каналов, заглушаются. |
| любой (x) | любой (y), когда x>y | Каждый выходной канал объединяется с его входным аналогом (имеющим тот же индекс). Каналы, не имеющие соответствующих выходных каналов, отбрасываются. |
Визуализация
Визуализация зиждется на получении выходных аудио данных, таких как данные об амплитуде или частоте, и их последующей обработке с помощью каких-либо графических технологий. В WAA имеется AnalyzerNode (анализатор), который не искажает проходящий через него сигнал. При этом он способен извлекать данные из аудио и передавать их дальше, например, в <canvas>.
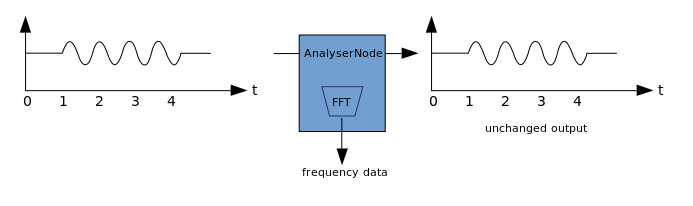
Для извлечения данных могут быть использованы следующие методы:
- AnalyzerNode.getFloatByteFrequencyData() — копирует текущие данные о частоте в массив Float32Array
- AnalyzerNode.getByteFrequencyData() — копирует текущие данные о частоте в массив Uint8Array (байтовый массив без знака)
- AnalyserNode.getFloatTimeDomainData() — копирует текущие данные о форме волны или шаге дискретизации в массив Float32Array
- AnalyserNode.getByteTimeDomainData() — копирует текущие данные о форме волны или шаге дискретизации в массив Uint8Array
Спатиализация
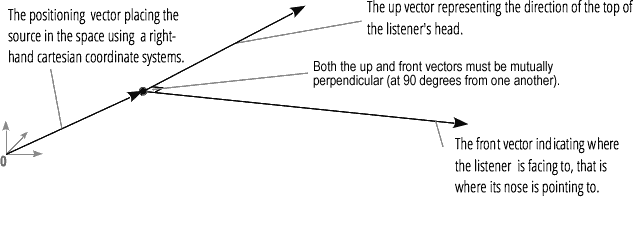
Аудио спатиализация (обрабатываемая PannerNode и AudioListener) позволяет моделировать позицию и направление сигнала в конкретной точке пространства, а также позицию слушателя.
Позиция паннера описывается с помощью правосторонних картезианских координат; для движения используется вектор скорости, необходимый для создания эффекта Доплера, для направления используется конус направленности. Этот конус может быть очень большим в случае разнонаправленных источников звука.

Позиция слушателя описывается так: движение — с использованием вектора скорости, направление, где находится голова слушателя — с использованием двух векторов направленности, спереди и сверху. Привязка осуществляется к верхней части головы и носу слушателя под прямым углом.
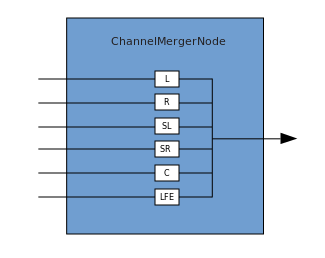
Соединение и разветвление
Соединение описывает процесс, в ходе которого ChannelMergerNode принимает несколько входных моно источников и соединяет их в один многоканальный сигнал на выходе.
Разветвление представляет собой обратный процесс (осуществляется посредством ChannelSplitterNode).
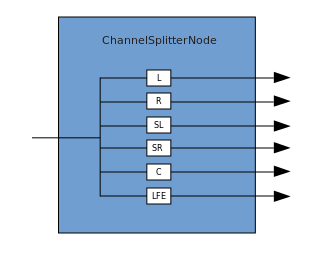
Пример работы с WAA можно посмотреть здесь. Исходный код примера находится здесь. Вот статья про то, как все это работает.
Благодарю за внимание.