
Как-то раз стало интересно, какие темы выделит LDA (латентное размещение Дирихле) на материалах «Живого Журнала». Как говорится, есть интерес — нет проблем.
Для начала немного про LDA на пальцах, вдаваться в математические подробности не будем (кому интересно — почитает). Итак, LDA — является одним из наиболее распространенных алгоритмов для моделирования тем. Каждый документ (будь то статья, книга или любой другой источник текстовых данных) представляет собой смесь тем, а каждая тема представляет собой смесь слов.
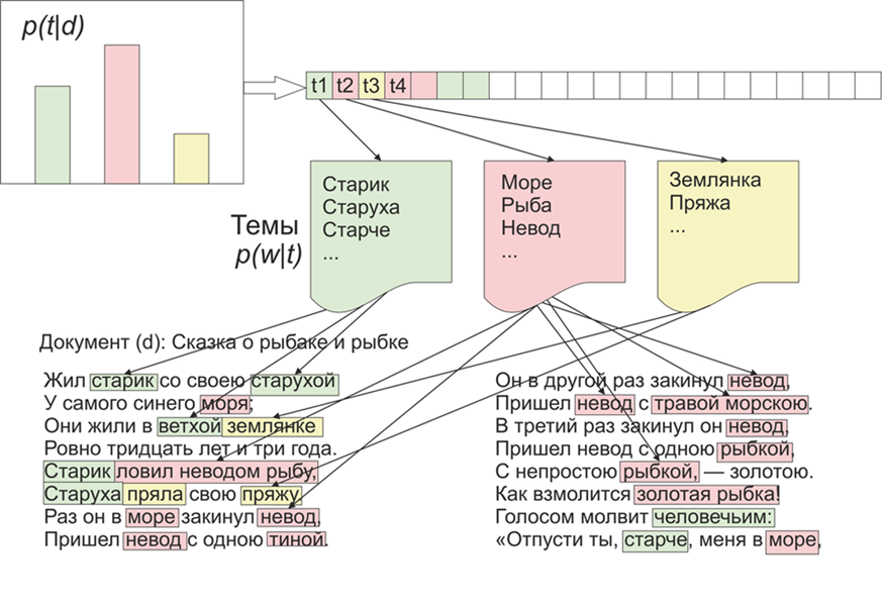
Картинка взята из Википедии
Таким образом, задача LDA состоит в том, чтобы по коллекции документов найти группы слов, которые образуют темы. Потом на основе тем можно проводить кластеризацию текстов или просто выделять ключевые слова.
С сайта LifeJournal было получено порядка 1800 статей, все они были приведены в формат jsonl
Неочищенные статьи я оставлю на Яндекс диске. Проведем некоторую очистку и нормализацию данных: выбросим комментарии, удалим стоп-слова (список вместе с исходным кодом доступен на github), приведем все слова к строчному написанию, удалим пунктуацию и слова, содержащие 3 буквы и меньше. Но одна из основных операций предобработки: удаление часто встречающихся слов, в принципе, можно ограничиться удалением только стоп-слов, но тогда часто употребляемые слова будут входить практически во все темы с большой вероятностью. В таком случае можно будет провести постобработку и удалить подобные слова. Выбор остается за Вами.
Далее приведем все слова к нормальной форме: для этого воспользуемся библиотекой pymorphy2, которую можно установить через pip.
Да, мы потеряем информацию о форме слов, но в данном контексте больше интересует совстречаемость слов друг с другом. На этом наша предобработка закончена, она не является полной, но она достаточна для того, чтобы посмотреть как работает алгоритм LDA.
Далее тот пункт, о котором упоминалось выше, в принципе, можно не делать, но на мой взгляд, результаты получаются адекватнее, опять-таки какой порог будет, решать вам, можно, например, построить функцию, зависящую от средней длины документов и их количества:
Перейдем непосредственно к обучению модели, для это нам понадобится установить библиотеку gensim, которая содержит в себе кучу прикольных плюшек. Сначала необходимо закодировать все слова, это за нас сделает функция Dictionary, затем заменим слова на их числовые эквиваленты. Закомментированный вариант вызова LDA является более долгим, так как обновляется после каждого документа, вы можете поиграть с настройками и выбрать подходящий вариант.
После окончания работ программы темы можно посмотреть с помощью команды
, где i — номер темы, а topn — количество слов в теме, которые будут выведены.
Теперь небольшой бонус для визуализации тем, для этого необходимо установить библиотеку wordcloud (вроде, подобные утилиты есть и в matplotlib). Данный код визуализирует темы и сохраняет их в текущую папку.
Ну и напоследок несколько примеров получившихся у меня тем:


Экспериментируйте и сможете получить еще более осмысленные результаты.
Для начала немного про LDA на пальцах, вдаваться в математические подробности не будем (кому интересно — почитает). Итак, LDA — является одним из наиболее распространенных алгоритмов для моделирования тем. Каждый документ (будь то статья, книга или любой другой источник текстовых данных) представляет собой смесь тем, а каждая тема представляет собой смесь слов.
Картинка взята из Википедии
Таким образом, задача LDA состоит в том, чтобы по коллекции документов найти группы слов, которые образуют темы. Потом на основе тем можно проводить кластеризацию текстов или просто выделять ключевые слова.
С сайта LifeJournal было получено порядка 1800 статей, все они были приведены в формат jsonl
Неочищенные статьи я оставлю на Яндекс диске. Проведем некоторую очистку и нормализацию данных: выбросим комментарии, удалим стоп-слова (список вместе с исходным кодом доступен на github), приведем все слова к строчному написанию, удалим пунктуацию и слова, содержащие 3 буквы и меньше. Но одна из основных операций предобработки: удаление часто встречающихся слов, в принципе, можно ограничиться удалением только стоп-слов, но тогда часто употребляемые слова будут входить практически во все темы с большой вероятностью. В таком случае можно будет провести постобработку и удалить подобные слова. Выбор остается за Вами.
stop=open('stop.txt')
stop_words=[]
for line in stop:
stop_words.append(line)
for i in range(0,len(stop_words)):
stop_words[i]=stop_words[i][:-1]
# specific regular expresion for this texts
texts=[re.split( r' [\w\.\&\?!,_\-#)(:;*%$№"\@]*Добавить в' ,texts[i])[0].replace("\n","") for i in range(0,len(texts))]
# remove punctuation
texts=[test_re(line) for line in texts]
texts=[t.lower() for t in texts]
# remove stop words
texts = [[word for word in document.split() if word not in stop_words] for document in texts]
texts=[[word for word in document if len(word)>=3]for document in texts]
Далее приведем все слова к нормальной форме: для этого воспользуемся библиотекой pymorphy2, которую можно установить через pip.
morph = pymorphy2.MorphAnalyzer()
for i in range(0,len(texts)):
for j in range(0,len(texts[i])):
texts[i][j] = morph.parse(texts[i][j])[0].normal_formДа, мы потеряем информацию о форме слов, но в данном контексте больше интересует совстречаемость слов друг с другом. На этом наша предобработка закончена, она не является полной, но она достаточна для того, чтобы посмотреть как работает алгоритм LDA.
Далее тот пункт, о котором упоминалось выше, в принципе, можно не делать, но на мой взгляд, результаты получаются адекватнее, опять-таки какой порог будет, решать вам, можно, например, построить функцию, зависящую от средней длины документов и их количества:
counter = collections.Counter()
for t in texts:
for r in t:
counter[r]+=1
limit = len(texts)/5
too_common = [w for w in counter if counter[w] > limit]
too_common=set(too_common)
texts = [[word for word in document if word not in too_common] for document in texts]Перейдем непосредственно к обучению модели, для это нам понадобится установить библиотеку gensim, которая содержит в себе кучу прикольных плюшек. Сначала необходимо закодировать все слова, это за нас сделает функция Dictionary, затем заменим слова на их числовые эквиваленты. Закомментированный вариант вызова LDA является более долгим, так как обновляется после каждого документа, вы можете поиграть с настройками и выбрать подходящий вариант.
texts=preposition_text_for_lda(my_r)
dictionary = gensim.corpora.Dictionary(texts)
corpus = [dictionary.doc2bow(text) for text in texts]
#lda = gensim.models.ldamodel.LdaModel(corpus=corpus, id2word=dictionary, num_topics=10, update_every=1, chunksize=1, passes=1)
lda = gensim.models.ldamodel.LdaModel(corpus=corpus, id2word=dictionary, num_topics=10)После окончания работ программы темы можно посмотреть с помощью команды
lda.show_topic(i,topn=30), где i — номер темы, а topn — количество слов в теме, которые будут выведены.
Теперь небольшой бонус для визуализации тем, для этого необходимо установить библиотеку wordcloud (вроде, подобные утилиты есть и в matplotlib). Данный код визуализирует темы и сохраняет их в текущую папку.
from wordcloud import WordCloud, STOPWORDS
for i in range(0,10):
a=lda.show_topic(i,topn=30)
wordcloud = WordCloud(
relative_scaling = 1.0,
stopwords = too_common # set or space-separated string
).generate_from_frequencies(dict(a))
wordcloud.to_file('society'+str(i)+'.png')
Ну и напоследок несколько примеров получившихся у меня тем:
Экспериментируйте и сможете получить еще более осмысленные результаты.