
CI (Continuous Integration) — в дословном переводе «непрерывная интеграция». Имеется в виду интеграция отдельных кусочков кода приложения между собой. Чем чаще мы собираем код воедино и проверяем:
Тем лучше! CI позволяет делать такие проверки автоматически. Он используется в продвинутых командах разработки, которые пишут не только код, но и автотесты. Его спрашивают на собеседованиях — хотя бы понимание того, что это такое. Да, даже у тестировщиков.
Поэтому я расскажу в статье о том, что это такое. Как CI устроен и чем он пригодится вашему проекту.

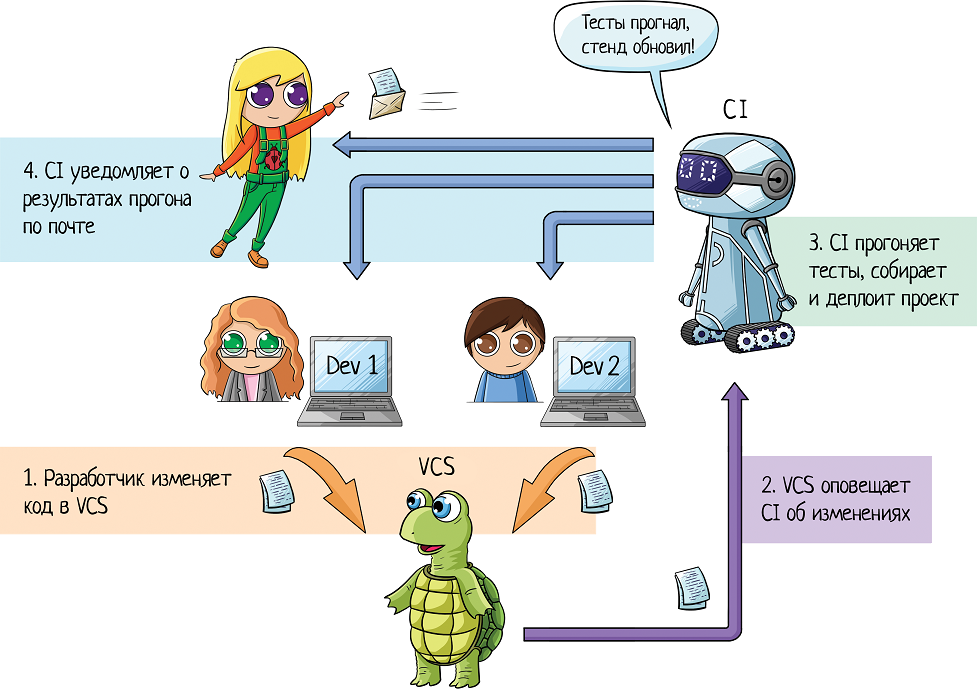
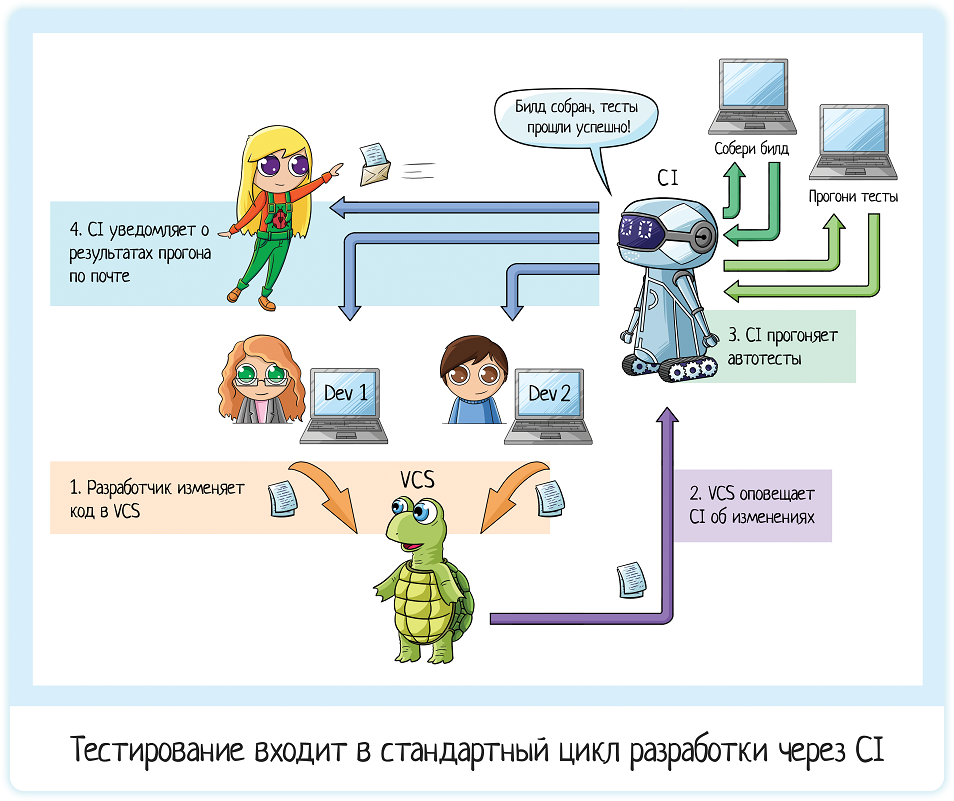
CI — это сборка, деплой и тестирование приложения без участия человека. Сейчас объясню на примере.
Допустим, что у нас есть два разработчика — Маша и Ваня. И тестировщица Катя.
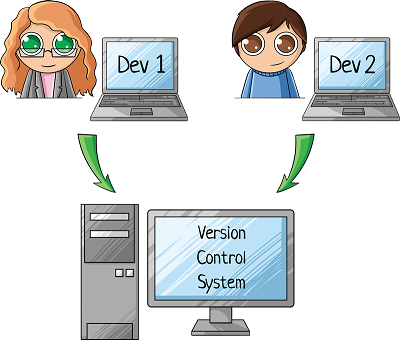
Маша пишет код. Добавляет его в систему контроля версий (от англ. Version Control System, VCS). Это что-то типа дропбокса для кода — место хранения, где сохраняются все изменения и в любой момент можно посмотреть кто, что и когда изменял.
Потом Ваня заканчивает свой кусок функционала. И тоже сохраняет код в VCS.
Но это просто исходный код — набор файликов с расширением .java, или любым другим. Чтобы Катя могла протестировать изменения, нужно:
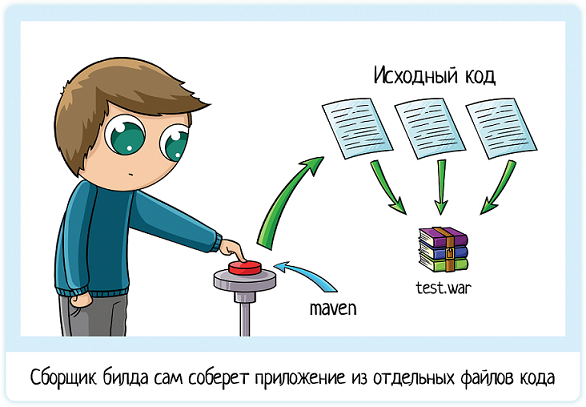
Сборка билда — это когда мы из набора файликов исходного кода создаем один запускаемый файл:

Собрать билд можно вручную, но это лишний геморрой: нужно помнить, что в каком порядке запустить, какие файлики зависят друг от друга, не ошибиться в команде… Обычно используют специальную программу. Для java это Ant, Maven или Gradle. С помощью сборщика вы один раз настраиваете процесс сборки, а потом запускаете одной командой. Пример запуска для Maven:
Это полуавтоматизация — все равно нужен человек, который введет команду и соберет билд «ручками». Допустим, этим занимаются разработчики. Когда Катя просит билд на тестирование, Ваня обновляет версию из репозитория и собирает билд.
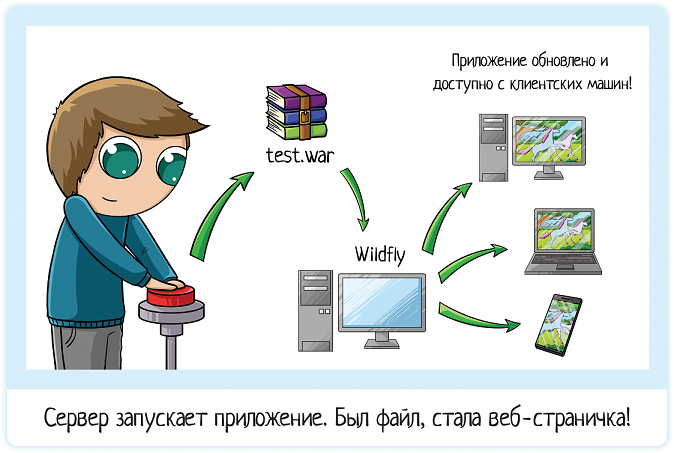
Но собрать билд ? получить приложение для тестирования. Его еще надо запустить! Этим занимается сервер приложения. Серверы бывают разные: wildfly, apache, jetty…
Если это wildfly, то нужно:
И это снова полуавтоматизация. Потому что разработчику нужно скопировать получившийся после сборки архив на тестовый стенд и включить службу. Да, это делается парой команд, но все равно человеком.
А вот если убрать из этой схемы человека — мы получим CI!

CI — это приложение, которое позволяет автоматизировать весь процесс. Оно забирает изменения из репозитория с кодом. Само! Тут есть два варианта настройки:
Когда CI получило изменения, оно запускает сборку билда и автотесты.
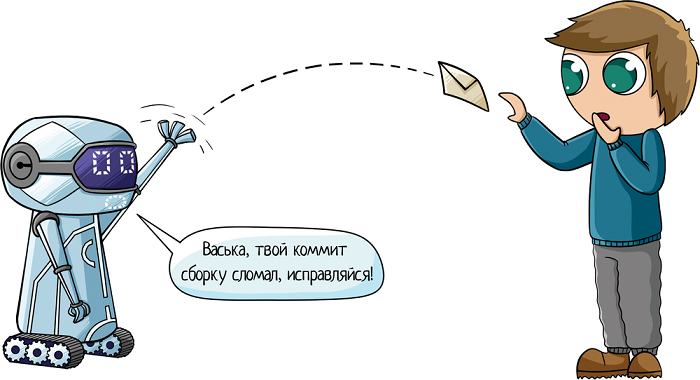
Если сборка провалилась (тесты упали, или не получилось собрать проект), система пишет элекронное письмо всем заинтересованным лицам:
Если сборка прошла успешно, CI разворачивает приложение на тестовой машине. И в итоге Катька может тестировать новую сборку!

Да, разумеется, один раз придется это все настроить — рассказать серверу CI, откуда забирать изменения, какие автотесты запускать, как собирать проект, куда его потом билдить… Но зато один раз настроил — а дальше оно само!
Автотесты тоже придется писать самим, но чтож поделать =)
Наиболее популярные — Jenkins и TeamCity.
Но есть куча других вариаций — CruiseControl, CruiseControl.Net, Atlassian Bamboo, Hudson, Microsoft Team Foundation Server.
Давайте посмотрим, как это выглядит с точки зрения пользователя. Я покажу на примере системы TeamCity.
Когда я захожу в систему, я вижу все задачи. Задачи бывают разные:
Задачи можно группировать. Вот, скажем, у нас есть проект CDI. Зайдя внутрь, я вижу задачи именно по этому проекту:

Помимо автоматизированного запуска, я могу в любой момент пересобрать билд, нажав на кнопку «Run»:

Это нужно, чтобы:
Когда я заходу внутрь любой задачи — я вижу историю сборок. Когда она запускалась? Кто при этом вносил изменения и сколько их было? Сколько тестов прошло успешно, а сколько развалилось?

Поэтому, даже если я не подписана на оповещения на электронную почту о состоянии сборок, я легко могу посмотреть, в каком состоянии сейчас система. Открываешь графический интерфейс программы и смотришь.
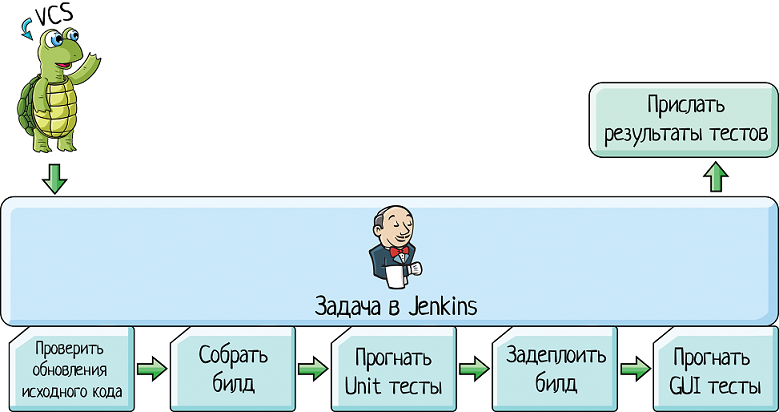
Как и где CI собирает билд и прогоняет автотесты? Я расскажу на примере TeamCity, но другие системы работают примерно также.
Сам TeamCity ничего не собирает. Сборка и прогон автотестов проходят на других машинах, которые называются «агенты»:
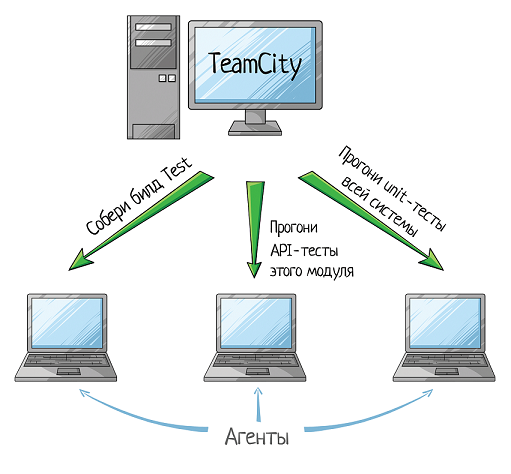
«Агент» — это простой компьютер. Железка или виртуальная машина, не суть. Но как этот комьютер понимает, что ему надо сделать?
В TeamCity есть сервер и клиент. Сервер — это то самое приложение, в котором вы потом будете тыкать кнопочки и смотреть красивую картинку «насколько все прошло успешно». Он устанавливается на одну машину.
А приложение-«клиент» устанавливается на машинах-«агентах». И когда мы нажимаем кнопку «Run» на сервере:
Сервер выбирает свободного клиента и передает ему все инструкции: что именно надо сделать. Клиент собирает билд, выполняет автотесты, собирает результат и возвращает серверу: «На, держи, отрисовывай».
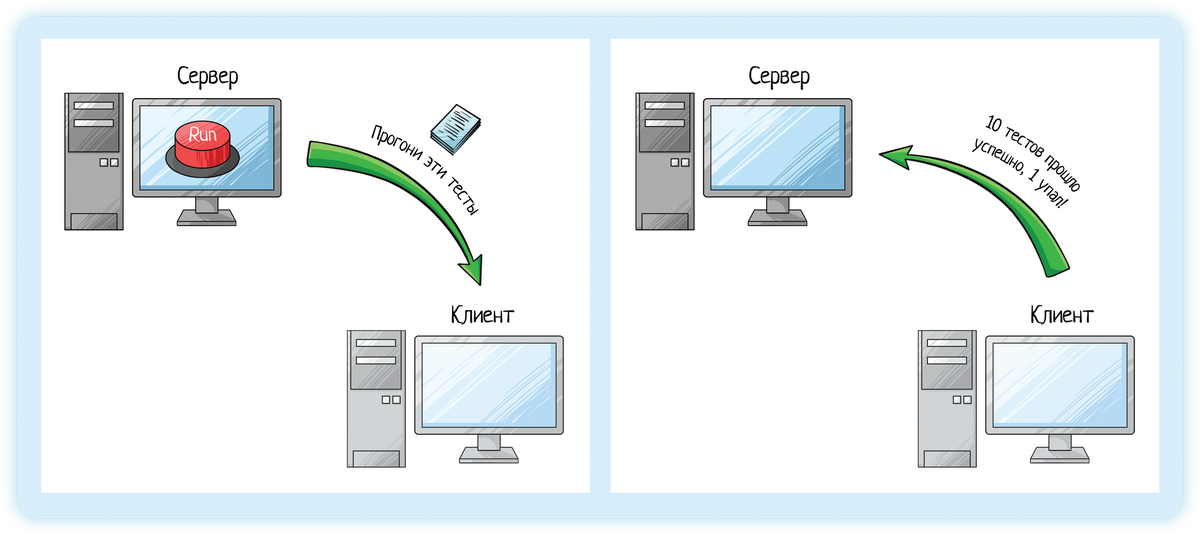
Сервер отображает пользователю результат плюс рассылает email всем заинтересованным лицам.
При этом мы всегда видим, на каком конкретно агенте проходила сборка:
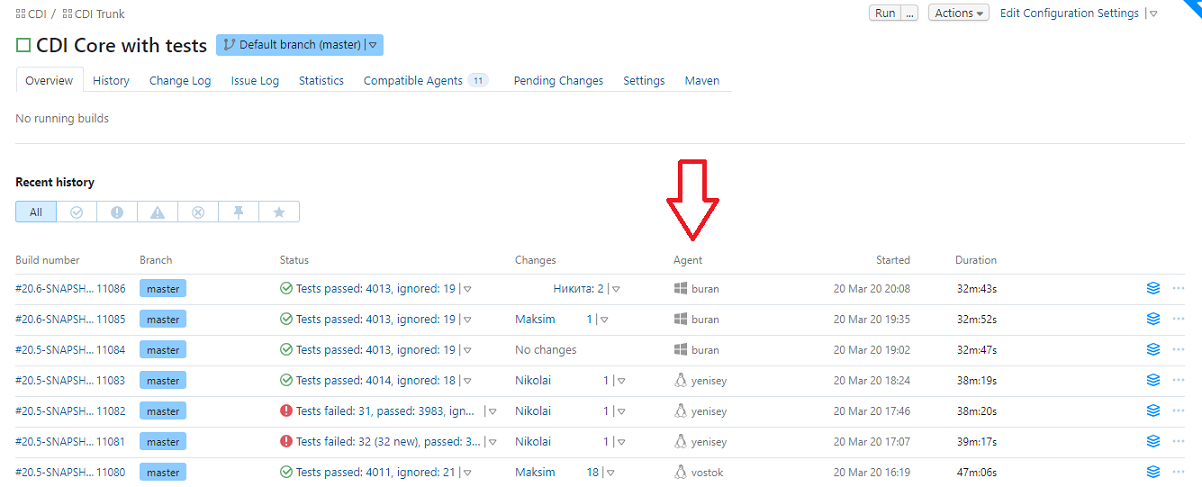
И можно самому выбирать, где прогонять автотесты. Потому что бывает, что автотесты падают только на одном билд-агенте. Это значит, что у него что-то не так с конфигурацией.
Мы также можем для каждой сборки настроить список агентов, на которых она может выполняться. Зачем? Например, у нас на половине агентов линукс, а на половине винда. А сборку мы только под одну систему сделали. Или на винде вылезает какой-то плавающий баг, но исправлять его долго и дорого, а все клиенте на линуксе — ну и зачем тогда?
А еще бывает, что агентов делят между проектами, чтобы не было драки — этот проект использует Бурана и Аполло, а тот Чип и Дейла. Фишка ведь в том, что на одном агенте может выполняться только одно задание. Поэтому нет смысла покупать под агент крутую тачку, сразу кучу тестов там все равно не прогнать.
В итоге как это работает: сначала админ закупает компьютеры под «агенты» и устанавливает на них клиентское приложение TeamCity. Слишком крутыми они быть не должны, потому что много задач сразу делать не будут.

При этом TeamCity вы платите за количество лицензий на билд-агентов. Так что чем меньше их будет, тем лучше.
На отдельной машине админ устанавливает сервер TeamCity. И конфигурирует его — настраивает сборки, указывает, какие сборки на каких машинах можно гонять, итд. На сервере нужно место для хранения артефактов — результатов выполнения сборки.
Дальше уже разработчик выбирает, какую сборку он хочет запустить и нажимает «Run». Что в этот момент происходит:
1. Сервер TeamCity проверяет по списку, на каких агентах эту сборку можно запускать. Потом он проверяет, кто из этих агентов в данный момент свободен:

Нашел свободного? Отдал ему задачку!

Если все агенты заняты, задача попадает в очередь. Очередь работает по принципу FIFO — first in, first out. Кто первый встал — того и тапки.

Очередь можно корректировать вручную. Так, если я вижу, что очередь забита сборками, которые запустила система контроля версий, я подниму свою на самый верх. Если я вижу, что сборки запускали люди — значит, они тоже важные, придется подождать.

Это нормальная практика, если мощностей агентов не хватает на всей и создается очередь. Смотришь, кто ее запустил:
Иногда можно даже отменить сборку от системы контроля версий, если уж очень припекло, а все агенты занятами часовыми тестами. В таком случае можно:
2. Агент выполняет задачу и возвращает серверу результат
3. Сервер отрисовывает результат в графическом интерфейсе и сохраняет артефакты. Так я могу зайти в TeamCity и посмотреть в артефактах полные логи прошедших автотестов, или скачать сборку проекта, чтобы развернуть ее локально.
Настоятельно рекомендуется настроить заранее количество сборок, которые CI будет хранить. Потому что если в артефактах лежат билды по 200+ мб и их будет много, то очередной запуск сборки упадет с ошибкой «кончилось место на диске»:

4. Сервер делает рассылку по email — тут уж как настроите. Он может и позитивную рассылку делать «сборка собралась успешно», а может присылать почту только в случае неудачи «Ой-ей-ей, что-то пошло не так!».
Я говорила о разных вариантах настройки интеграции CI — VCS:
Но когда какой используется?
Лучше всего, конечно, чтобы система контроля версий оповещала сервер CI. И запускать весь цикл на каждое изменение: собрать, протестировать, задеплоить. Тогда любое изменение кода сразу попадет на тестовое окружение, которое будет максимально актуальным.

Плюс каждое изменение прогоняет автотесты. И если тесты упадут, сразу ясно, чей коммит их сломал. Ведь раньше работало и после Васиных правок вдруг сломалось — значит, это его коммит привел к падению. За редким исключением, когда падение плавающее.

Но в реальной жизни такая схема редко применима. Только подумайте — у вас ведь может быть много проектов, много разработчиков. Каждый что-то коммитит ну хотя бы раз в полчаса. И если на каждый коммит запускать 10 сборок по полчаса — очереди в TeamCity никогда не разгребутся!
Другой вариант — закупить много агентов. Но это цена за саму машину + за лицензию в TeamCity, что уже сильно дороже, да еще и каждый месяц платить.
Поэтому обычно делают как:
1. Очень быстрые и важные сборки можно оставить на любой коммит — если это займет 1-2 минуты, пусть гоняется.

2. Остальные сборки проверяют, были ли изменения в VCS — например, раз в 15 минут. Если были, тогда запускаем.

3. Долгие тесты (например, тесты производительности) — раз в несколько дней ночью.

Если мы говорим о разработке своего приложения, то тестирование входит в стандартный цикл. Вы или ваши разработчики пишут автотесты, которые потом гоняет CI. Это могут быть unit, api, gui или нагрузочные тесты.
Но что, если вы тестируете черный ящик? Приложение есть, исходного кода нету. Это суровые реалии тестировщиков интеграции — поставщик отдает вам новый релиз приложения, который нужно проверить перед тем, как ставить в продакшен.
Вот, допустим, у вас есть API-тесты в Postman-е. Или GUI-тесты в Selenium. Можно ли настроить цикл CI для них?

Конечно, можно!
CI не ставит жестких рамок типа «я работаю только в проектах с автотестами» или «я работаю только когда есть доступ к исходному коду». Он может смотреть в систему контроля версий, а может и не смотреть. Это необязательное условие!
Написали автотесты? Скажите серверу CI, как часто их запускать — и наслаждайтесь результатом =)

CI — непрерывная интеграция. Это когда ваше приложение постоянно проверяется: все ли с ним хорошо? Проходят ли тесты? Собирается ли сборка? Причем все проверки проводятся автоматически, без участия человека.
Особенно актуально для команд, где над кодом одного приложения трудятся несколько разработчиков. Как это бывает? По отдельности части программы работают, а вот вместе уже нет. CI позволяет очень быстро обнаружить такие проблемы. А чем быстрее найдешь — тем дешевле исправить.

Отсюда и название — постоянная проверка интеграции кусочков кода между собой.
Типичные задачи CI:
И все это — автоматически, без вмешательства человека! То есть один раз настроили, а дальше оно само.
Если в проекте настроен CI, у вас будут постоянно актуальные тестовые стенды. И если в коде что-то сломается, вы узнаете об этом сразу, сервер CI пришлет письмо. А еще можно зайти в графический интерфейс и посмотреть — все ли сборки успешные, а тесты зеленые? Оценить картину по проекту за минуту.
См также:
Continuous Integration для новичков
PS — больше полезных статей ищите в моем блоге по метке «полезное». А полезные видео — на моем youtube-канале
- Собирается ли он?
- Проходят ли автотесты?
Тем лучше! CI позволяет делать такие проверки автоматически. Он используется в продвинутых командах разработки, которые пишут не только код, но и автотесты. Его спрашивают на собеседованиях — хотя бы понимание того, что это такое. Да, даже у тестировщиков.
Поэтому я расскажу в статье о том, что это такое. Как CI устроен и чем он пригодится вашему проекту.
Содержание
Что такое CI
CI — это сборка, деплой и тестирование приложения без участия человека. Сейчас объясню на примере.
Допустим, что у нас есть два разработчика — Маша и Ваня. И тестировщица Катя.
Маша пишет код. Добавляет его в систему контроля версий (от англ. Version Control System, VCS). Это что-то типа дропбокса для кода — место хранения, где сохраняются все изменения и в любой момент можно посмотреть кто, что и когда изменял.
Потом Ваня заканчивает свой кусок функционала. И тоже сохраняет код в VCS.
Но это просто исходный код — набор файликов с расширением .java, или любым другим. Чтобы Катя могла протестировать изменения, нужно:
- Собрать билд из исходного кода
- Запустить его на тестовой машине
Сборка билда — это когда мы из набора файликов исходного кода создаем один запускаемый файл:
Собрать билд можно вручную, но это лишний геморрой: нужно помнить, что в каком порядке запустить, какие файлики зависят друг от друга, не ошибиться в команде… Обычно используют специальную программу. Для java это Ant, Maven или Gradle. С помощью сборщика вы один раз настраиваете процесс сборки, а потом запускаете одной командой. Пример запуска для Maven:
mvn clean installЭто полуавтоматизация — все равно нужен человек, который введет команду и соберет билд «ручками». Допустим, этим занимаются разработчики. Когда Катя просит билд на тестирование, Ваня обновляет версию из репозитория и собирает билд.
Но собрать билд ? получить приложение для тестирования. Его еще надо запустить! Этим занимается сервер приложения. Серверы бывают разные: wildfly, apache, jetty…
Если это wildfly, то нужно:
- Подложить билд в директорию standalone/deployments
- Запустить сервер (предварительно один раз настроив службу)
И это снова полуавтоматизация. Потому что разработчику нужно скопировать получившийся после сборки архив на тестовый стенд и включить службу. Да, это делается парой команд, но все равно человеком.
А вот если убрать из этой схемы человека — мы получим CI!
CI — это приложение, которое позволяет автоматизировать весь процесс. Оно забирает изменения из репозитория с кодом. Само! Тут есть два варианта настройки:
- CI опрашивает репозиторий «Эй, ку-ку, у тебя есть изменения??» раз в N часов / минут, как настроите.

- Репозиторий машет CI рукой при коммите: «Эй, привет! А у меня обновление тут появилось!» (это git hook или аналог в вашей VCS)

Когда CI получило изменения, оно запускает сборку билда и автотесты.
Если сборка провалилась (тесты упали, или не получилось собрать проект), система пишет элекронное письмо всем заинтересованным лицам:
- Менеджеру проекта (чтобы знал, что делается!)
- Разработчику, который внес изменения
- Любому другому — как настроите, так и будет.
Если сборка прошла успешно, CI разворачивает приложение на тестовой машине. И в итоге Катька может тестировать новую сборку!
Да, разумеется, один раз придется это все настроить — рассказать серверу CI, откуда забирать изменения, какие автотесты запускать, как собирать проект, куда его потом билдить… Но зато один раз настроил — а дальше оно само!
Автотесты тоже придется писать самим, но чтож поделать =)
Если на пальцах, то система CI (Continuous Integration) – это некая программа, которая следит за вашим Source Control, и при появлении там изменений автоматически стягивает их, билдит, гоняет автотесты (конечно, если их пишут).
В случае неудачи она дает об этом знать всем заинтересованным лицам, в первую очередь – последнему коммитеру. (с) habr.com/ru/post/352282
Программы CI
Наиболее популярные — Jenkins и TeamCity.
Но есть куча других вариаций — CruiseControl, CruiseControl.Net, Atlassian Bamboo, Hudson, Microsoft Team Foundation Server.
Как это выглядит
Давайте посмотрим, как это выглядит с точки зрения пользователя. Я покажу на примере системы TeamCity.
Когда я захожу в систему, я вижу все задачи. Задачи бывают разные:
- Собрать билд
- Прогнать автотесты
- Развернуть приложение на тестовом стенде
- Прогнать на этом стенде GUI тесты (или тесты Postman-a)
- Оповестить всех заинтересованных по email о результатах сборки и тестирования
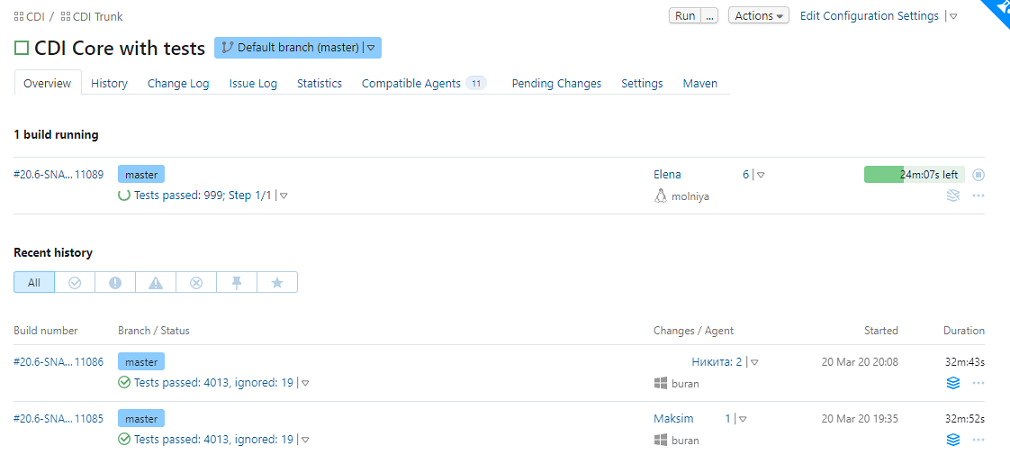
Задачи можно группировать. Вот, скажем, у нас есть проект CDI. Зайдя внутрь, я вижу задачи именно по этому проекту:
- CDI Archetype и CDI Core — это билды. Они проверяют, что приложение вообще собирается. Отрабатывают за пару минут и прогоняются на каждое изменение кода.
- CDI Core with tests — сборка проекта со всеми автотестами, которых, как видно на скрине, 4000+ штук. Тесты идут полчаса, но тоже прогоняются на каждый коммит.
Помимо автоматизированного запуска, я могу в любой момент пересобрать билд, нажав на кнопку «Run»:
Это нужно, чтобы:
- Перезапустить тесты, исправив косяк — это ведь может быть настройки окружения, а не кода. Поэтому исправление настройки не перезапустит тесты, которые следят только за системой контроля версий кода.
- Перезапустить билд, если TeamCIty настроен проверять изменения раз в час — а нам нужно сейчас проверить исправления
- Перезапустить билд, если в VCS исправления вносились не в этот проект, а в связанный.
- Проверить стабильность падения — иногда тесты падают по неведомым причинам, а если их перезапустить, отработают успешно.
Когда я заходу внутрь любой задачи — я вижу историю сборок. Когда она запускалась? Кто при этом вносил изменения и сколько их было? Сколько тестов прошло успешно, а сколько развалилось?
Поэтому, даже если я не подписана на оповещения на электронную почту о состоянии сборок, я легко могу посмотреть, в каком состоянии сейчас система. Открываешь графический интерфейс программы и смотришь.
Как CI устроен
Как и где CI собирает билд и прогоняет автотесты? Я расскажу на примере TeamCity, но другие системы работают примерно также.
Сам TeamCity ничего не собирает. Сборка и прогон автотестов проходят на других машинах, которые называются «агенты»:
«Агент» — это простой компьютер. Железка или виртуальная машина, не суть. Но как этот комьютер понимает, что ему надо сделать?
В TeamCity есть сервер и клиент. Сервер — это то самое приложение, в котором вы потом будете тыкать кнопочки и смотреть красивую картинку «насколько все прошло успешно». Он устанавливается на одну машину.
А приложение-«клиент» устанавливается на машинах-«агентах». И когда мы нажимаем кнопку «Run» на сервере:
Сервер выбирает свободного клиента и передает ему все инструкции: что именно надо сделать. Клиент собирает билд, выполняет автотесты, собирает результат и возвращает серверу: «На, держи, отрисовывай».
Сервер отображает пользователю результат плюс рассылает email всем заинтересованным лицам.
При этом мы всегда видим, на каком конкретно агенте проходила сборка:
И можно самому выбирать, где прогонять автотесты. Потому что бывает, что автотесты падают только на одном билд-агенте. Это значит, что у него что-то не так с конфигурацией.
Допустим, исходно у нас был только один билд-агент — Buran. Название может быть абсолютно любым, его придумывает администратор, когда подключает новую машину к TeamCity как билд-агента.
Мы собирали на нем проект, проводили автотесты — все работало. А потом закупили вторую машинку и назвали Apollo. Вроде настроили также, как Буран, даже операционную систему одинаковую поставили — CentOs 7.
Но запускаем сборку на Apollo — падает. Причем падает странно, не хватает памяти или еще чего-то. Перезапускаем на Apollo — снова падает. Запускаем на Буране — проходит успешно!
Начинаем разбираться и выясняем, что в Apollo забыли про какую-то настройку. Например, не увеличили количество открытых файловых дескриптеров. Исправили, прогнали сборку на Apollo — да, работает, ура!



Мы также можем для каждой сборки настроить список агентов, на которых она может выполняться. Зачем? Например, у нас на половине агентов линукс, а на половине винда. А сборку мы только под одну систему сделали. Или на винде вылезает какой-то плавающий баг, но исправлять его долго и дорого, а все клиенте на линуксе — ну и зачем тогда?
А еще бывает, что агентов делят между проектами, чтобы не было драки — этот проект использует Бурана и Аполло, а тот Чип и Дейла. Фишка ведь в том, что на одном агенте может выполняться только одно задание. Поэтому нет смысла покупать под агент крутую тачку, сразу кучу тестов там все равно не прогнать.
В итоге как это работает: сначала админ закупает компьютеры под «агенты» и устанавливает на них клиентское приложение TeamCity. Слишком крутыми они быть не должны, потому что много задач сразу делать не будут.
При этом TeamCity вы платите за количество лицензий на билд-агентов. Так что чем меньше их будет, тем лучше.
На отдельной машине админ устанавливает сервер TeamCity. И конфигурирует его — настраивает сборки, указывает, какие сборки на каких машинах можно гонять, итд. На сервере нужно место для хранения артефактов — результатов выполнения сборки.
У нас есть два проекта — Единый клиент и Фактор, которые взаимодействуют между собой. Тестировщик Единого клиента может не собирать Фактор локально. Он запускает сборку в TeamCity и скачивает готовый билд из артефактов!
Дальше уже разработчик выбирает, какую сборку он хочет запустить и нажимает «Run». Что в этот момент происходит:
1. Сервер TeamCity проверяет по списку, на каких агентах эту сборку можно запускать. Потом он проверяет, кто из этих агентов в данный момент свободен:
Нашел свободного? Отдал ему задачку!
Если все агенты заняты, задача попадает в очередь. Очередь работает по принципу FIFO — first in, first out. Кто первый встал — того и тапки.
Очередь можно корректировать вручную. Так, если я вижу, что очередь забита сборками, которые запустила система контроля версий, я подниму свою на самый верх. Если я вижу, что сборки запускали люди — значит, они тоже важные, придется подождать.
Это нормальная практика, если мощностей агентов не хватает на всей и создается очередь. Смотришь, кто ее запустил:
- Робот? Значит, это просто плановая проверка, что ничего лишнего не разломалось. Такая может и подождать 5-10-30 минут, ничего страшного
- Коллега? Ему эта сборка важна, раз не стал ждать планового запуска. Встаем в очередь, лезть вперед не стоит.
Иногда можно даже отменить сборку от системы контроля версий, если уж очень припекло, а все агенты занятами часовыми тестами. В таком случае можно:
- поднять свою очередь на самый верх, чтобы она запустилась на первом же освободившемся агенте
- зайти на агент, отменить текущую сборку
- перезапустить ее! Хоть она и попадет в самый низ очереди, но просто отменять сборку некрасиво
2. Агент выполняет задачу и возвращает серверу результат
3. Сервер отрисовывает результат в графическом интерфейсе и сохраняет артефакты. Так я могу зайти в TeamCity и посмотреть в артефактах полные логи прошедших автотестов, или скачать сборку проекта, чтобы развернуть ее локально.
Настоятельно рекомендуется настроить заранее количество сборок, которые CI будет хранить. Потому что если в артефактах лежат билды по 200+ мб и их будет много, то очередной запуск сборки упадет с ошибкой «кончилось место на диске»:
4. Сервер делает рассылку по email — тут уж как настроите. Он может и позитивную рассылку делать «сборка собралась успешно», а может присылать почту только в случае неудачи «Ой-ей-ей, что-то пошло не так!».
Интеграция с VCS
Я говорила о разных вариантах настройки интеграции CI — VCS:
- CI опрашивает репозиторий «Эй, ку-ку, у тебя есть изменения??» раз в N часов / минут, как настроите.
- Репозиторий машет CI рукой при коммите: «Эй, привет! А у меня обновление тут появилось!» (это git hook или аналог в вашей VCS)
Но когда какой используется?
Лучше всего, конечно, чтобы система контроля версий оповещала сервер CI. И запускать весь цикл на каждое изменение: собрать, протестировать, задеплоить. Тогда любое изменение кода сразу попадет на тестовое окружение, которое будет максимально актуальным.
Плюс каждое изменение прогоняет автотесты. И если тесты упадут, сразу ясно, чей коммит их сломал. Ведь раньше работало и после Васиных правок вдруг сломалось — значит, это его коммит привел к падению. За редким исключением, когда падение плавающее.
Но в реальной жизни такая схема редко применима. Только подумайте — у вас ведь может быть много проектов, много разработчиков. Каждый что-то коммитит ну хотя бы раз в полчаса. И если на каждый коммит запускать 10 сборок по полчаса — очереди в TeamCity никогда не разгребутся!
У нас у одного из продуктов есть core-модуль, а есть 15+ Заказчиков. В каждом свои автотесты. Сборка заказчика — это core + особенности заказчика. То есть изменение в корневом проекте может повлиять на 15 разных сборок. Значит, их все надо запустить при коммите в core.
Когда у нас было 4 билд-агента, все-все-все сборки и тесты по этим заказчикам запускались в ночь на вторник. И к 10 утра в TeamCity еще была очередь на пару часов.
Другой вариант — закупить много агентов. Но это цена за саму машину + за лицензию в TeamCity, что уже сильно дороже, да еще и каждый месяц платить.
Поэтому обычно делают как:
1. Очень быстрые и важные сборки можно оставить на любой коммит — если это займет 1-2 минуты, пусть гоняется.
2. Остальные сборки проверяют, были ли изменения в VCS — например, раз в 15 минут. Если были, тогда запускаем.
3. Долгие тесты (например, тесты производительности) — раз в несколько дней ночью.
CI в тестировании
Если мы говорим о разработке своего приложения, то тестирование входит в стандартный цикл. Вы или ваши разработчики пишут автотесты, которые потом гоняет CI. Это могут быть unit, api, gui или нагрузочные тесты.
Но что, если вы тестируете черный ящик? Приложение есть, исходного кода нету. Это суровые реалии тестировщиков интеграции — поставщик отдает вам новый релиз приложения, который нужно проверить перед тем, как ставить в продакшен.
Вот, допустим, у вас есть API-тесты в Postman-е. Или GUI-тесты в Selenium. Можно ли настроить цикл CI для них?
Конечно, можно!
CI не ставит жестких рамок типа «я работаю только в проектах с автотестами» или «я работаю только когда есть доступ к исходному коду». Он может смотреть в систему контроля версий, а может и не смотреть. Это необязательное условие!
Написали автотесты? Скажите серверу CI, как часто их запускать — и наслаждайтесь результатом =)
Итого
CI — непрерывная интеграция. Это когда ваше приложение постоянно проверяется: все ли с ним хорошо? Проходят ли тесты? Собирается ли сборка? Причем все проверки проводятся автоматически, без участия человека.
Особенно актуально для команд, где над кодом одного приложения трудятся несколько разработчиков. Как это бывает? По отдельности части программы работают, а вот вместе уже нет. CI позволяет очень быстро обнаружить такие проблемы. А чем быстрее найдешь — тем дешевле исправить.
Отсюда и название — постоянная проверка интеграции кусочков кода между собой.
Типичные задачи CI:
- Проверить, было ли обновление в коде
- Собрать билд
- Прогнать автотесты
- Развернуть приложение на тестовом стенде
- Прогнать на этом стенде GUI тесты (или тесты Postman-a)
- Оповестить всех заинтересованных по email о результатах сборки и тестирования
И все это — автоматически, без вмешательства человека! То есть один раз настроили, а дальше оно само.
Если в проекте настроен CI, у вас будут постоянно актуальные тестовые стенды. И если в коде что-то сломается, вы узнаете об этом сразу, сервер CI пришлет письмо. А еще можно зайти в графический интерфейс и посмотреть — все ли сборки успешные, а тесты зеленые? Оценить картину по проекту за минуту.
См также:
Continuous Integration для новичков
PS — больше полезных статей ищите в моем блоге по метке «полезное». А полезные видео — на моем youtube-канале



amarao
Столько красивых картинок с такими красивыми улыбающимися личиками. Нет, CI выглядит так:
Enjoy your CI.
Molechka Автор
Аха-хах ))) Ну да, так оно тоже выглядит )))
Eldhenn
А без CI как это выглядит? «Все ваши органы вместе не покроют убытков за эту ночь»?
amarao
Зависит от того, для чего CI. В целом, без CI можно иметь большой отдел manual QA, который проверит лучше, чем CI. Медленее, да, но лучше.
Я пока сам хихикал над своим комментарием задумался, "а почему же всё так плохо в CI?" Это очень интересная проблема, потому что любой человек, который с ними возился, знает — оно всё Очень Ужасное.
Моя текущая гипотеза — проблема в том, что вся система CI — это программа, большей частью построенная на сайд-эффектах, перемешанных на бизнес-логику и хаки (чтобы сцеплять куски друг с другом). Сама эта комбинация уже убийственная (если бы вы писали программы так, как пишутся CI-джобы, то первый залетевший байт разрушил бы цивилизацию), но есть ещё одно: так как у каждого компонента своё видение данных, для взаимодейтсвия между компонентами используется наименьшее общее в системе типов, т.е. нетипизированные параметры. Внутри которых находится плохо эксейпленнные данные других слоёв (условно — переменная CI'я с паролем, которая передаётся потом в командную строку кому-то там по пайплайну), полностью нетипизированные, плюс случайные фрагменты чужих соглашений об обозначении типов, которые могут иногда вызывать WTF (например, если у вас в пароле есть '$', удачи объяснить это башу).
Т.е. современный CI как система написания программ находится где-то на уровне раннего FORTRAN или даже раньше. Всё очень плохо, очень неудобно и требует глубокого понимания каждой компоненты для нормальной отладки. Поскольку каждой компоненты никто не знает, начинается нарастание магического мышления и тайного знания. Сплошные анти-паттерны.