
Квантовые компьютеры по определению могут решать множество задач экспоненциально быстрее, чем классические компьютеры. Нужно признать, что мы еще не достигли появления полезных квантовых вычислений, но когда мы сможем решить эту проблему, то извлеченная польза затронет почти все научные дисциплины. В этом обзоре мы рассмотрим, как современные квантовые алгоритмы могут сделать революцию в вычислительной биологии и биоинформатике.
От способности обрабатывать огромные объемы информации и намного эффективнее использовать алгоритмы машинного обучения, до алгоритмов квантового моделирования, которые могут улучшить вычисления (как по качественным, так и по количественным показателям) для дизайна новых лекарств, предсказания структуры белка, анализа различных процессов в биологическом организме и т.д. Эти захватывающие ум перспективы подвержены сегодня излишнему инфо хайпу, а значит важно обозначить предостережения и проблемы в этой новой технологии.
Предупреждение: в основе обзора статья группы европейских исследователей из Великобритании и Швейцарии (Carlos Outeiral, Martin Strahm, Jiye Shi, Garrett M. Morris, Simon C. Benjamin, Charlotte M. Deane. «The prospects of quantum computing in computational molecular biology», WIREs Computational Molecular Science published by Wiley Periodicals LLC, 2020). Самые сложные части статьи, связанные с изощренными математическими моделями не попадут в обзор. Но материал изначально сложный, от читателя требуются знания математики и квантовой физики.
Но если вы намерены начать изучать применение квантовых технологий в биоинформатике, то для того чтобы сначала въехать в тему, предлагается послушать небольшой доклад Виктора Соколова – старшего научного сотрудника M&S Decisions, в котором обозначаются некоторые современные проблемы моделирования лекарств:
С момента появления высокопроизводительных вычислений, алгоритмы и математические модели используются для решения проблем биологических наук — от изучения сложности генома человека до моделирования поведения биомолекул. Вычислительные методы сегодня регулярно используются для анализа и извлечения важной информации из биологических экспериментов, а также для прогнозирования поведения биологических объектов и систем. Фактически, 10 из 25 наиболее цитируемых научных работ касаются вычислительных алгоритмов, используемых в биологии [см. здесь], включая квантовое моделирование [здесь, тут, здесь и здесь], выравнивание последовательностей [здесь, здесь и здесь], вычислительную генетику [см. здесь] и дифракцию рентгеновских лучей в обработке данных [см. здесь и здесь].
Несмотря на такой прогресс, многие проблемы в биологии остаются неразрешимыми, с точки зрения их решения с помощью существующих вычислительных технологий. Лучшие алгоритмы для таких задач, как прогнозирование сворачивания белка, вычисление аффинности связывания лиганда с макромолекулой или поиск оптимального крупномасштабного геномного выравнивания, требуют вычислительных ресурсов, которые выходят за рамки даже самых мощных суперкомпьютеров, существующих сегодня.
Решение этих проблем может заключаться в смене парадигмы в вычислительных технологиях. В 1980-х годах независимо друг от друга, Ричард Фейнман [см. здесь] и Юрий Манин [см. здесь] предложили использовать квантово-механические эффекты для создания нового, более мощного поколения компьютеров.
Квантовая теория оказалась весьма успешным описанием физической реальности и привела с момента ее появления в начале 20-го века к таким достижениям, как лазеры, транзисторы и полупроводниковые микропроцессоры. Квантовый компьютер использует самые эффективные алгоритмы, используя операции, которые невозможны в классических машинах. Квантовые процессоры не работают быстрее, чем классические компьютеры, но работают совершенно по-другому, достигая беспрецедентного ускорения, избегая ненужных вычислений. Например, расчет полной электронной волновой функции средней молекулы лекарственного средства на любом современном суперкомпьютере с использованием обычных алгоритмов, как ожидается, займет больше времени, чем полный возраст нашей Вселенной [см. здесь], в то время как даже небольшой квантовый компьютер может решить эту проблему в сроки обозримые несколькими днями. Воодушевленные такими перспективами квантового преимущества, инженеры и ученые продолжают изыскания в области создания квантового процессора. Однако, технические трудности в производстве, управлении и защите квантовых систем невероятно сложны, и первые прототипы появились только в последнее десятилетие.
Важно заметить, что технические проблемы построения квантовых компьютеров не остановили разработку квантовых вычислительных алгоритмов. Даже при отсутствии аппаратного обеспечения алгоритмы можно анализировать математически, а появление высокопроизводительных симуляторов квантовых компьютеров, а также ранних прототипов в последние несколько лет позволили продвинуться в дальнейших исследованиях.
Некоторые из этих алгоритмов уже показали многообещающие потенциальные области применения в биологии. Например, алгоритм оценки квантовой фазы позволяет экспоненциально быстрее вычислять собственные значения [см. здесь], что может быть использовано для понимания крупномасштабной корреляции между частями белка или определения центральности графа в биологической сети. Квантовый алгоритм Харроу-Хасидима-Ллойда (HHL) [см. здесь] может решать некоторые линейные системы экспоненциально быстрее, чем любой известный классический алгоритм, а также может применять статистические методы обучения с гораздо быстрым процессом адаптации и возможностью управления большим количеством данных.
Алгоритмы квантовой оптимизации имеют широкое поле применения в области сворачивания белков и выборки конформеров, а также в проблемах, связанных с поиском минимумов или максимумов [см. здесь]. Наконец, недавно была разработана технология для моделирования квантовых систем, которые обещают, например, производить точные прогнозы взаимодействия лекарственного средства с рецепторами [см. здесь] или участвовать в изучении и понимании сложных процессов и химических механизмов, таких как фотосинтез [см. здесь]. Квантовые вычисления могут существенно изменить методы самой биологии, как это сделали в свое время классические вычисления.
Недавние заявления о квантовом превосходстве со стороны Google [см. здесь], хотя и оспариваемые IBM [см. здесь], указывают на то, что эра квантовых вычислений не за горами. Первые процессоры, использующие квантовые эффекты для выполнения вычислений невозможных для классических компьютерных технологий, ожидаются в течение следующего десятилетия [см. здесь].
В этом обзоре мы разберем ключевые моменты, где квантовые вычисления показывают перспективу для вычислительной биологии. В этих обзорах проанализировано потенциальное влияние квантовых вычислений в различных областях, включая машинное обучение [см. здесь, тут и здесь], квантовую химию [см. здесь, тут и здесь] и синтез лекарств [см. здесь]. Также недавно был опубликован отчет семинара NIMH по квантовым вычислениям в биологических науках [см. здесь].
В этом обзоре сначала дадим краткое описание того, что подразумевается под квантовыми вычислениями, и краткое введение в принципы квантовой обработки информации. Затем обсудим три основные области вычислительной биологии, где квантовые вычисления уже показали многообещающие алгоритмические разработки: статистические методы, расчеты электронной структуры и оптимизация. В стороне останутся некоторые важные темы, например, строковые алгоритмы, которые могут повлиять на анализ последовательности [см. здесь], алгоритмы формирования медицинских изображений [см. здесь], численные алгоритмы для дифференциальных уравнений [здесь ] и другие математические задачи или методы анализа биологических сетей [здесь]. Наконец, мы обсудим потенциальное влияние квантовых вычислений на вычислительную биологию в среднесрочной и долгосрочной перспективе.
Квантовые компьютеры обещают решить проблемы биологических наук, такие например как, прогнозирование белково-лигандных взаимодействий или понимание коэволюции аминокислот в белках. И не просто решить, а сделать это экспоненциально быстрее, чем можно представить это с любым современным компьютером. Однако это изменение парадигмы требует фундаментальных изменений в нашем мышлении: квантовые компьютеры сильно отличаются от своих классических предшественников. Физические явления, которые лежат в основе квантового преимущества, часто являются нелогичными и противоречат здравому смыслу, а использование квантового процессора требует фундаментальных изменений в нашем понимании программирования. В этом разделе мы представляем принципы квантовой информации и то, как она обрабатывается для выполнения вычислений.
Мы объясняем, как информация работает по-разному в квантовой системе, где она хранится в кубитах, и как этой информацией можно манипулировать с помощью квантовых вентилей. Подобно переменным и функциям языка программирования, кубиты и квантовые вентили определяют основные элементы любого алгоритма. Также разберем почему создание квантового компьютера технически крайне сложный процесс и что может быть достигнуто с помощью ранних прототипов, которые ожидаются в ближайшие годы. Это введение будет охватывать только основные моменты; для всестороннего изучения читайте книгу Nielsen и Chuang [здесь].
Первая проблема в представлении квантовых вычислений — это представление о том, как они обрабатывают информацию. В квантовом процессоре информация обычно хранится в кубитах, которые являются квантовым аналогом классических битов. Кубит — это физическая система, подобная иону, ограниченному магнитным полем [см. здесь] или поляризованным фотоном [см. здесь], но о нем часто говорят абстрактно. Подобно коту Шредингера, кубит может принимать не только состояния 0 или 1, но также любую возможную комбинацию обоих состояний. Когда кубит наблюдается непосредственно, он больше не будет находиться в суперпозиции, которая разрушится до одного из возможных состояний, также, как кот Шредингера оказывается мертвым или живым после открытия ящика [см. здесь]. Что еще более важно, когда несколько кубитов объединены, они могут стать коррелированными, и взаимодействия с любым из них имеют последствия для всего коллективного состояния. Явление корреляции между множественными кубитами, известное как квантовое запутывание, является фундаментальным ресурсом квантовых вычислений.
В классической информации фундаментальной единицей информации является бит, система с двумя идентифицируемыми состояниями, часто обозначаемыми 0 и 1. Квантовый аналог, кубит, представляет собой систему с двумя состояниями, состояния которой помечены как |0? и |1?. Мы используем обозначение Дирака, где |*? идентифицирует квантовое состояние. Основное различие между классической и квантовой информацией заключается в том, что кубит может находиться в любой суперпозиции состояний |0? и |1?:
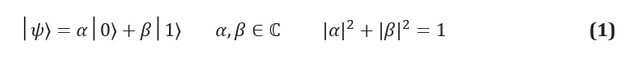
Комплексные коэффициенты ? и ? известны как амплитуды состояний, и они связаны с другим ключевым понятием квантовой механики: эффект физического измерения. Поскольку кубиты являются физическими системами, всегда можно придумать протокол для измерения их состояния. Если, например, состояния |0? и |1? соответствуют состояниям спина электрона в магнитном поле, то измерение состояния кубита является просто измерением энергии системы. Постулаты квантовой механики диктуют, что если система находится в суперпозиции возможных результатов измерения, то акт измерения должен изменить само состояние. Система суперпозиции развалится на стадии измерения; измерение, таким образом, уничтожает информацию, переносимую амплитудами в кубите.
Важные последствия для вычислений возникают, когда мы рассматриваем системы множественных кубитов, которые могут испытывать квантовую запутанность. Запутывание — это явление, при котором группа кубитов коррелируется, и любая операция над одним из этих кубитов будет влиять на общее состояние всех из них. Каноническим примером квантовой запутанности является парадокс Эйнштейна-Подольского-Розена, представленный в 1935 году [см. здесь]. Рассмотрим систему из двух кубитов, где, поскольку каждый из отдельных кубитов может принимать любую суперпозицию состояний {|0? и |1?}, составная система может принимать любую суперпозицию состояний {|00?,|01?,|10?,|11?} (и, соответственно, система N-кубитов может принимать любую из двоичных строк, от {|0...0? до |1...1?}. Одной из возможных суперпозиций системы являются так называемые состояния Белла, одно из которых имеет следующий вид:

Если мы выполним измерение на первом кубите, мы сможем наблюдать только |0? или |1?, каждый из которых будет иметь вероятность 1/2. Это не вносит никаких изменений в отношении случая одного кубита. Если исход для первого кубита был |0?, система будет свернута до системы |01?, и поэтому любое измерение на втором кубите даст |1? с вероятностью 1; аналогично, если результат первого измерения был |1?, измерение на втором кубите даст |0?. Операция (в данном случае измерение с результатом «0»), примененная к первому кубиту, влияет на результаты, которые можно увидеть при последующем измерении второго кубита.
Существование запутанности является основополагающим для полезных квантовых вычислений. Было доказано, что любой квантовый алгоритм, который не использует запутывание, может быть применен в классическом компьютере без существенной разницы в скорости [см. здесь и здесь]. Интуитивно, причина — это объем информации, которой может управлять квантовый компьютер. Если N кубитовая система не запутана, то амплитуды ее состояния могут быть описаны амплитудами каждого однокбитового состояния, то есть 2N амплитуды. Однако, если система запутана, все амплитуды будут независимыми, и регистр кубита сформирует -мерный вектор. Способность квантовых компьютеров манипулировать огромными объемами информации с помощью нескольких операций является одним из главных преимуществ квантовых алгоритмов и подкрепляет их способность решать проблемы экспоненциально быстрее классических компьютерных технологий.
Информация, хранящаяся в кубитах, обрабатывается с помощью специальных операций, известных как квантовые вентили. Квантовые вентили — это физические операции, такие как например, лазерный импульс, направленный на ионный кубит, или набор зеркал и светоделителей, через которые должен двигаться фотонный кубит. Однако, вентили часто они рассматриваются как абстрактные операции. Постулаты квантовой механики накладывают некоторые строгие условия на природу квантовых вентилей в замкнутых системах, что позволяет представлять их в виде унитарных матриц, которые представляют собой линейные операции, сохраняющие нормализацию квантовой системы.
В частности, квантовый вентиль, примененный к запутанному регистру из N кубитов, эквивалентен умножению матрицы ? на вектор входа . Способность квантового компьютера хранить и выполнять вычисления огромных объемов информации — порядка — путем манипулирования несколькими элементами — порядка N — формирует основу его способности обеспечивать потенциально экспоненциальное преимущество над классическими компьютерами.
По сути, квантовые вентили — это любая разрешенная операция в системе кубитов. Постулаты квантовой механики накладывают два строгих ограничения на форму квантовых вентилей. Квантовые операторы являются линейными. Линейность — это математическое условие, которое, тем не менее, имеет глубокие последствия для физики квантовых систем и, следовательно, каким образом их можно использовать для вычислений. Если к суперпозиции состояний применяется линейный оператор , то результатом является суперпозиция отдельных состояний, на которые воздействует оператор. В кубите это означает:
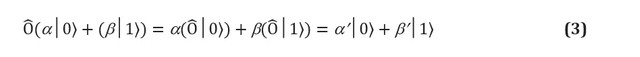
Линейные операторы могут быть представлены в виде матриц, которые являются просто таблицами, обозначающими влияние линейного оператора на каждое базисное состояние. На рисунке 1 (в, г) показано матричное представление одного из двух кубитных и двух однобитных вентилей.
Однако не каждая матрица представляет действительные квантовые вентили. Мы ожидаем, что квантовые вентили, примененные к совокупности кубитов, дадут другой действительный набор кубитов, в частности, нормированный (например, в уравнении (3) мы ожидаем, что ). Это условие выполняется только в том случае, если матрица, представляющая квантовые вентили, является унитарной, то есть U†U = UU† = I, где U† — это матрица U, в которой строки и столбцы были переставлены, и каждое комплексное число было сопряжено (т.е. каждый мнимый элемент приобретает отрицательный фактор). Произвольная унитарная матрица ? представляет собой полностью допустимый N-кубитный квантовый вентиль.
В классических вычислениях существует только один нетривиальный вентиль для одного бита: вентиль NOT, который преобразует 0 в 1 и наоборот. В квантовых вычислениях существует бесконечное число унитарных матриц 2 ? 2, и любая из них является возможным однокубитным квантовым вентилем. Одним из первых успехов квантовых вычислений стало открытие, что это огромное количество возможностей может быть реализовано с помощью набора универсальных вентилей, влияющих на один и два кубита [см. здесь]. Другими словами, учитывая произвольные квантовые вентили, существует схема, построенная из одно- и двухкубитных вентилей, которая может привести ее в действие с произвольной точностью. К сожалению, это не означает, что приближение является эффективным. Большинство квантовых вентилей можно аппроксимировать только экспоненциальным числом вентилей из нашего универсального набора. Даже если эти вентили можно использовать для решения полезных задач, их реализация займет экспоненциально большое количество времени и может нивелировать любое квантовое преимущество.

РИСУНОК 1 (а) Сравнение классического бита с квантовым битом или «кубитом». В то время как классический бит может принимать только одно из двух состояний, 0 или 1, квантовый бит может принимать любое состояние вида . Одиночные кубиты часто изображаются с использованием представления сферы Блоха, где ? и ? понимаются как азимутальный и полярный углы в сфере единичного радиуса. (б) Схема кубита с ионной ловушкой, один из наиболее распространенных подходов к экспериментальным квантовым вычислениям. Ион (часто ) удерживается в высоком вакууме с помощью электромагнитных полей и подвергается воздействию сильного магнитного поля. Уровни сверхтонкой структуры разделяются в соответствии с эффектом Зеемана, и два выбранных уровня выбираются как состояния |0? и |1?. Квантовые вентили реализуются соответствующими лазерными импульсами, часто с участием других электронных уровней. Эта диаграмма была адаптирована из [см. здесь]. (в) Диаграмма квантовой схемы, реализующей X или квант контролируемого отрицания (CNOT).
Показано представление и изменение в сфере Блоха. (г) Квантовая схема для генерации состояния Белла , используя вентиль Адамара и вентиль CNOT (контролируемое отрицание). Пунктирная линия в середине контура указывает состояние после применения вентиля Адамара.
Квантовые алгоритмы могут решать интересные проблемы только в том случае, если они запускаются на соответствующем квантовом оборудовании. Существует много конкурирующих предложений по созданию квантового процессора на основе захватываемых ионов [см. здесь], сверхпроводящих схем [см. здесь] и фотонных устройств [см. здесь]. Тем не менее, все они сталкиваются с общей проблемой: ошибки во время вычислений, которые могут в буквальном смысле развалить вычислительный процесс. Одним из краеугольных камней квантовых вычислений является обнаружение того, что эти ошибки могут быть устранены с помощью квантовых кодов, исправляющих ошибки. К сожалению, эти коды также требуют очень большого увеличения числа кубитов, поэтому для достижения отказоустойчивости необходимы значительные технические усовершенствования.
Есть много источников ошибок, которые могут повлиять на квантовый процессор. Например, связь кубита с окружающей средой может привести к коллапсу системы в одно из ее классических состояний — процесс, известный как декогеренция. Небольшие флуктуации могут трансформировать квантовые вентили, которые в итоге, приведут к результатам, отличным от ожидаемых. Наименее подверженные ошибкам вентили на сегодняшний день были зарегистрированы в процессоре с захваченными ионами, с частотой появления одной ошибки на однокубитных вентилей и с 0,1% долей ошибок для двукубитовых вентилей [здесь и здесь]. Для сравнения, в недавней работе, проведенной Google, сообщалось о точности воспроизведения 0,1% для вентилей с одним кубитом и 0,3% для вентилей с двумя кубитами в сверхпроводящем процессоре [см. здесь]. Учитывая, что отказ одного шлюза может испортить расчет, нетрудно увидеть, что распространение ошибки может сделать вычисление бессмысленным уже после небольшой последовательности элементов.
Одним из главных направлений квантовых вычислений является разработка квантовых кодов, исправляющих ошибки. В 1990-х годах несколько исследовательских групп доказали, что эти коды могут достигать отказоустойчивых вычислений, при условии, что частоты ошибок вентилей находятся под определенным порогом, который зависит от кода [см. здесь, тут, здесь и здесь]. Один из самых популярных подходов, код поверхности, может работать с частотой ошибок, приближающейся к 1% [см. здесь].
К сожалению, квантовые коды с исправлением ошибок требуют использования большого количества реальных физических кубитов для кодирования абстрактного логического кубита, который используется для вычислений, и эти издержки растут с увеличением частоты ошибок. Например, квантовый алгоритм для факторизации простых чисел [см. здесь] мог бы в бесшумных условиях разложить 2000-битное число, используя приблизительно 4000 кубитов и, при частоте 16 ГГц, этот процесс занял бы около одного дня работы. Если частоту ошибок принять за 0,1%, этот же алгоритм, использующий код поверхности для исправления ошибок среды, потребует нескольких миллионов кубитов и такого же количества времени [см. здесь]. Учитывая, что текущая запись для управляемого, программируемого квантового процессора составляет 53 кубита [см. здесь], в этом исследовательском направлении предстоит еще долгий путь.
Многие группы предприняли усилия для разработки алгоритмов, которые можно запускать в так называемых шумовых квантовых процессорах среднего масштаба [см. здесь]. Например, вариационные алгоритмы объединяют классический компьютер с небольшим квантовым процессором, выполняя большое количество коротких квантовых вычислений, которые могут быть реализованы до того, как шум начнет оказывать существенные препятствия.
Эти алгоритмы часто используют параметризованную квантовую схему, которая выполняет особенно сложную задачу, и используют классический компьютер для оптимизации параметров. Способом разрешения является область уменьшения ошибок, в которой вместо достижения отказоустойчивости была предпринята попытка максимально уменьшить ошибки с минимальными усилиями для запуска более крупных цепей вентилей. Существует ряд подходов, которые включают применение дополнительных операций для отбрасывания прогонов вычислений с ошибками [см. здесь] или манипулирование частотой ошибок для экстраполяции до правильного результата [см. здесь и тут]. Хотя для основных областей применения потребуются очень большие отказоустойчивые квантовые компьютеры; ожидается, что устройства, доступные в течение следующего десятилетия, смогут решить эти проблемы [см. здесь].
В вычислительной биологии, где целью часто является сбор огромных объемов данных, статистические методы и машинное обучение являются ключевыми методами. Например, в геномике в аннотации информации о генах широко используются скрытые марковские модели (англ. hidden Markov models — HMM) [см. здесь]; при открытии лекарств был разработан широкий спектр статистических моделей для оценки молекулярных свойств или для предсказания связи лиганда с белком [см. здесь]; а в структурной биологии глубокие нейронные сети использовались как для предсказания белковых связей [см. здесь] и вторичной структуры [см. здесь], так и совсем недавно уже и трехмерных белковых структур [см. здесь].
Обучение и разработка таких моделей часто требует большого объема вычислений. Основным катализатором последних достижений в области машинного обучения стало понимание того, что графические процессоры общего назначения (GPU) могут значительно ускорить процедуру обучения. Обеспечивая экспоненциально более быстрые алгоритмы для машинного обучения модели квантовых вычислений могут обеспечить аналогичный интерес в фокусе применения к научным задачам.
В этом разделе мы объясним, как квантовые вычисления могут ускорить многочисленные статистические методы обучения.
Сначала мы рассмотрим преимущества, которые предоставляет квантовый компьютер для машинного обучения. За исключением идеализированных примеров, квантовые компьютеры могут изучать не больше информации, чем классический компьютер [см. здесь]. Однако в принципе они могут быть намного быстрее и способны обрабатывать гораздо больше данных, чем их классические аналоги. Например, человеческий геном содержит 3 миллиарда пар оснований, которые могут храниться в 1,2 ? классических битах — приблизительно 1,5 гигабайта. Регистр из N кубитов включает в себя амплитуд, каждая из которых может представлять классический бит, устанавливая k-ю амплитуду в 0 или 1 с соответствующим коэффициентом нормализации. Следовательно, человеческий геном может храниться в ~34 кубитах. Хотя эта информация не может быть извлечена из квантового компьютера, до тех пор, пока не подготовлено определенное состояние, на нем можно будет выполнить определенные алгоритмы машинного обучения. Что еще более важно, удвоение размера регистра до 68 кубитов оставляет достаточно места для хранения полного генома каждого живого человека в мире. Представление и анализ таких огромных объемов данных вполне соответствовал бы возможностям даже небольшого отказоустойчивого квантового компьютера.
Операции по обработке этой информации также могут выполняться экспоненциально быстрее. Например, алгоритмы множественного машинного обучения ограничены длительной инверсией ковариационной матрицы со штрафом на размерности матрицы. Однако алгоритм, предложенный Харроу, Хассидимом и Ллойдом [см. здесь], позволяет инвертировать матрицу в при некоторых условиях. Ключевое понимание заключается в том, что, в отличие от графических ускорителей, которые ускоряют вычисления за счет массивного параллелизма, квантовые алгоритмы имеют преимущество в сложности непосредственно используемых вычислительных алгоритмов. В некоторых случаях, особенно при существующем экспоненциальном ускорении, квантовые компьютеры среднего размера могут решать задачи обучения, доступные только для крупнейших классических суперкомпьютеров, доступных сегодня.
Улучшенное хранение и обработка данных имеет вторичные преимущества. Одной из сильных сторон нейронных сетей является их способность находить краткое представление данных [см. здесь]. Поскольку квантовая информация является более общей, чем классическая информация (в конце концов, состояния классического бита подразделяются на собственные состояния |0? и |1? или кубит), вполне возможно, что модели обучения с квантовой машиной могут лучше усваивать информацию, чем классические модели. С другой стороны, квантовые алгоритмы со сложностью логарифмического времени также позволяют повысить конфиденциальность данных [см. здесь]. Поскольку для обучения модели требуется , а требует реконструкции матрицы, для достаточно большого набора данных невозможно восстановить значительную часть информации, хотя все еще возможно эффективное обучение модели. В контексте биомедицинских исследований это может способствовать обмену данными при обеспечении конфиденциальности.
К сожалению, хотя алгоритмы квантового машинного обучения на бумаге могут значительно превзойти классические аналоги, практические трудности все еще остаются. Квантовые алгоритмы часто представляют собой подпрограммы, которые преобразуют вход в выход. Проблемы возникают именно на этих двух этапах: как подготовить адекватный ввод и как извлечь информацию из вывода [см. здесь]. Предположим, например, что мы используем алгоритм HHL [см. здесь] для решения линейной системы вида . В конце подпрограммы алгоритм выдаст регистр кубитов в следующем состоянии:
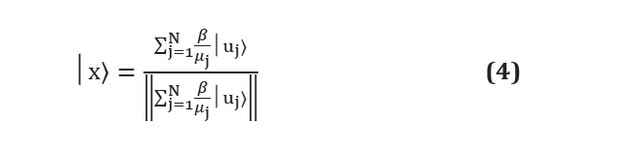
Здесь и — собственные векторы и собственные значения A, а — j-й коэффициент выражается через собственные векторы A, а знаменатель является просто константой нормализации. Видно, что это соответствует коэффициентам , которые хранятся в амплитудах различных состояний как и не доступны напрямую. Измерение регистра кубита приведет к его коллапсу в одно из состояний собственного вектора, а для переоценки амплитуд каждого требуются измерения , что в первую очередь перевешивает любое преимущество квантового алгоритма.
HHL и многие другие алгоритмы полезны только для вычисления глобального свойства решения, например, ожидаемого значения. Другими словами, HHL не может обеспечить решение системы уравнений или инвертировать матрицу за логарифмическое время, если нас не интересуют только глобальные свойства решения, которые могут быть получены с помощью нескольких физически наблюдаемых измерений. Это ограничивает использование некоторых подпрограмм, но было много предложений обойти эту проблему.
Ввод информации в квантовый компьютер является гораздо более серьезной проблемой. Большинство алгоритмов обучения квантовой машины предполагают, что квантовый компьютер имеет доступ к набору данных в виде состояния суперпозиции; например, существует регистр кубитов, который находится в состоянии вида:

Здесь — |bin(j)? это состояние, которое действует как индекс, а — соответствующая амплитуда. Это может быть использовано, например, для хранения элементов вектора или матрицы. В принципе, существует квантовая схема, которая может подготовить это состояние, действуя, скажем, в состоянии |0...0?. Однако его реализация может быть очень сложной, поскольку мы ожидаем, что аппроксимация случайного квантового состояния будет экспоненциально сложной и уничтожит любое возможное квантовое преимущество.
Большинство квантовых алгоритмов предполагают доступ к квантовой оперативной памяти (англ. quantum random access memory — QRAM) [см. здесь], которая является устройством черного ящика, способным построить эту суперпозицию. Хотя были предложены некоторые чертежи [см. здесь и здесь], насколько нам известно, пока нет работающего устройства. Более того, даже если бы такое устройство было доступно, нет гарантии, что оно не создаст узких мест, которые перевесят преимущества квантового алгоритма. Например, недавнее предложение на основе схем для QRAM [см. здесь] показывает неизбежные линейные затраты на число состояний, которые перевешивают любой алгоритм логарифмического времени. Наконец, даже если QRAM не вводит никаких дополнительных затрат, все равно необходимо будет выполнить классическую предварительную обработку данных — для примера генома потребуется доступ к 12 эксабайтам классического хранилища.
Наконец, мы должны подчеркнуть, что алгоритмы обучения квантовой машины не свободны от одной из наиболее распространенных проблем в практических приложениях: нехватки соответствующих данных. Доступность большого количества данных имеет решающее значение для успеха многих практических применений ИИ в молекулярной науке, например, в разработке молекул de novo [см. здесь]. Однако мощь квантовых алгоритмов может оказаться полезной, поскольку научные и технологические разработки, такие как появление лабораторий с самостоятельным управлением [см. здесь] предоставляют все больше и больше данных.
Квантовое машинное обучение может изменить методы обработки и анализа биологических данных. Однако, текущие практические проблемы реализации квантовых технологий все еще значительны.
Обучение без учителя включает в себя несколько методов извлечения информации из немаркированных наборов данных. В биологии, где секвенирование следующего поколения и большое международное сотрудничество стимулировали сбор данных, эти методы нашли широкое применение, например, для выявления связей между семействами биомолекул [см. здесь] или аннотированных геномов [см. здесь].
Одним из наиболее популярных алгоритмов обучения без учителя является анализ главных компонентов (англ. principal component analysis — PCA), который пытается уменьшить размерность данных путем нахождения линейных комбинаций признаков, которые максимизируют дисперсию [см. здесь]. Этот метод широко используется во всех видах наборов данных высокой размерности, включая данные РНК-микрочипов и масс-спектрометрии [см. здесь]. Квантовый алгоритм для проведения PCA был предложен группой исследователей [см. здесь]. По сути, этот алгоритм строит ковариационную матрицу данных в квантовом компьютере и использует подпрограмму, известную как оценка квантовой фазы, для вычисления собственных векторов в логарифмическом времени. Выходные данные алгоритма представляют собой состояние суперпозиции вида:

Здесь — это j-ая главная компонента, а — соответствующее собственное значение. Поскольку PCA интересуется большими собственными значениями, которые являются основными компонентами дисперсии, измерение конечного состояния даст подходящий главный компонент с высокой вероятностью. Повторение алгоритма несколько раз обеспечит набор основных компонентов. Эта процедура способна уменьшить размерность огромного количества информации, которая может храниться в квантовом компьютере.
Квантовый алгоритм также был предложен для конкретного метода анализа топологических данных, а именно для устойчивых гомологий [см. здесь]. Анализ топологических данных пытается извлечь информацию, используя топологические свойства в геометрии наборов данных; он был использован, например, при изучении агрегации данных [см. здесь] и сетевого анализа [см. здесь]. К сожалению, лучшие классические алгоритмы имеют экспоненциальную зависимость в размерности задачи, что ограничивает ее применение. Алгоритм Ллойда и соавт. также использует подпрограмму квантовой оценки фазы для экспоненциального ускорения диагонализации матрицы, достигая сложности . Наличие эффективного алгоритма для проведения топологического анализа может стимулировать его применение для анализа проблем биологических наук.
Контролируемое обучение относится к набору методов, с помощью которых можно делать прогнозы на основе помеченных данных. Цель состоит в том, чтобы построить модель, которая может классифицировать или предсказать свойства невидимых примеров. Контролируемое обучение широко используется в биологии для решения таких разнообразных задач, как прогнозирование аффинности связывания лиганда с белком [см. здесь] и диагностика заболеваний с помощью компьютера [см. здесь]. Разберем три подхода контролируемого обучения.
Машина опорных векторов (англ. support vector machine — SVM) — это алгоритм машинного обучения, который находит оптимальную гиперплоскость, разделяющую классы данных. SVM широко использовалась в фармацевтической промышленности для классификации данных малых молекул [см. здесь]. В зависимости от ядра, обучение SVM обычно занимает от до . Ребентрост [см. здесь] представил квантовый алгоритм, который может обучать SVM с полиномиальным ядром в , и позже он был расширен до ядра радиальной базисной функции (англ. radial basis function — RBF) [см. здесь]. К сожалению, неясно, как реализовать нелинейные операции, которые широко используются в SVM, учитывая, что квантовые операции ограничены, чтобы быть линейными. С другой стороны, квантовый компьютер допускает другие виды ядер, которые не могут быть реализованы в классическом компьютере [см. здесь].
Гауссова регрессия процесса (GP) — это метод, обычно используемый для построения суррогатных моделей, например, в байесовской оптимизации [см. здесь]. GP также широко используются для создания количественных моделей структура-активность (англ. quantitative structure–activity relationship — QSAR) свойств лекарств [см. здесь], а в последнее время также для моделирования молекулярной динамики [см. здесь]. Одним из недостатков регрессии GP является высокая величина инверсии ковариационной матрицы. Чжао с коллегами [см. здесь] предложили использовать алгоритм HHL для линейных систем, чтобы инвертировать эту матрицу, достигая экспоненциального ускорения (пока матрица разрежена и хорошо обусловлена) — свойства, которое часто достигается ковариационными матрицами. Что еще более важно, этот алгоритм был расширен для вычисления логарифма предельного правдоподобия [см. здесь], что является важным шагом для оптимизации гиперпараметров.
Одним из наиболее распространенных методов в вычислительной биологии является скрытая Марковская модель (англ. hidden Markov model — HMM), широко используемая в вычислительной аннотации генов и выравнивании последовательностей [см. здесь]. Этот метод содержит ряд скрытых состояний, каждое из которых связано с цепью Маркова; переходы между скрытыми состояниями приводят к изменениям в базовом распределении. В принципе, HMM не может быть непосредственно реализован в квантовом компьютере: выборка требует какого-то измерения, которое нарушит работу системы. Однако существует формулировка в терминах открытых квантовых систем, то есть квантовой системы, которая находится в контакте с окружающей средой, которая допускает марковскую систему [см. здесь]. Хотя не было предложено никаких улучшений классического алгоритма Баума – Уэлча для обучения HMM, было обнаружено, что квантовые HMM более выразительны: они могут воспроизводить распределение с меньшим количеством скрытых состояний [см. здесь]. Это может привести к более широкому применению метода в вычислительной биологии.
Недавние разработки в области машинного обучения были стимулированы открытием того факта, что множественные слои искусственных нейронных сетей могут обнаруживать сложные структуры в необработанных данных [см. здесь]. Глубокое обучение начало проникать в каждую научную дисциплину, и в вычислительной биологии его успехи включают точное предсказание связей в белках [см. здесь], улучшенную диагностику некоторых заболеваний [см. здесь], молекулярный дизайн [см. здесь] и моделирование [см. здесь и тут].
Учитывая значительные достижения в изучении нейронных сетей, была проделана значительная работа по разработке квантовых аналогов, которые могут способствовать дальнейшим улучшениям технологии.
Название искусственной нейронной сети часто относится к многослойному персептрону нейронной сети, где каждый нейрон принимает взвешенную линейную комбинацию своих входов и возвращает результат через нелинейную функцию активации. Основная проблема при разработке квантового аналога заключается в том, как реализовать нелинейную функцию активации с использованием линейных квантовых вентилей. В последнее время появилось множество предложений, и некоторые идеи включают измерения [см. здесь, тут и здесь], диссипативные квантовые вентили [тут ], квантовые вычисления с непрерывной переменной [здесь] и введение дополнительных кубитов для построения линейных вентилей, которые имитируют нелинейность [см. здесь]. Эти подходы направлены на реализацию квантовой нейронной сети, которая, как ожидается, будет более выразительной, чем классическая нейронная сеть, благодаря большей мощности квантовой информации. Преимущества или недостатки масштабирования обучения многослойного персептрона в квантовом компьютере неясны, хотя основное внимание уделяется возможной повышенной выразительности этих моделей.
Огромное количество недавних усилий было сосредоточено на машинах Больцмана, рекуррентных нейронных сетях, способных выступать в качестве генеративных моделей. После обучения они могут генерировать новые образцы, похожие на тренировочный набор.
Генеративные модели имеют важные приложения, например, в молекулярном дизайне de novo [см. здесь и здесь]. Хотя машины Больцмана очень мощные, чтобы вычислить градиенты и провести обучение необходимо решить сложную задачу выборки из распределения Больцмана, что ограничивает их практическое применение. Квантовые алгоритмы были предложены с использованием машины D-Wave [см. здесь, тут и здесь] или схемного алгоритма [см. здесь]; эта выборка из распределения Больцмана квадратично быстрее, чем это возможно в классическом исполнении [см. здесь].
Недавно была предложена эвристика для эффективной тренировки квантовых машин Больцмана, основанная на термализации системы [см. здесь]. Более того, в некоторых работах были предложены квантовые реализации порождающих состязательных сетей (англ. generative adversarial networks — GAN) [см. здесь, здесь и здесь]. Эти разработки предполагают улучшение генеративных моделей по мере развития аппаратного обеспечения квантовых вычислений.
Согласно представлениям моделей, химия регулируется переносом электронов. Химические реакции, а также взаимодействия между химическими объектами также контролируются распределением электронов и ландшафтом свободной энергии, который они формируют. Такие проблемы, как прогнозирование связывания лиганда с белком или понимание каталитического пути фермента, сводятся к пониманию электронной среды. К сожалению, моделирование этих процессов чрезвычайно сложно. Наиболее эффективный алгоритм для вычисления энергии системы электронов, полная конфигурация взаимодействия (англ. full configuration interaction — FCI), которая экспоненциально масштабируется с ростом количества электронов, и даже молекулы с несколькими атомами углерода едва доступны для вычислительных исследований [см. здесь]. Хотя существует множество приближенных методов, глубоко и обширно описанных в публикациях по теории функционала плотности [см. здесь и здесь], они могут быть неточными и даже резко потерпеть неудачу во многих представляющих интерес ситуациях, таких как моделирование переходного состояния реакции [см. здесь]. Точный и эффективный алгоритм изучения электронной структуры позволил бы лучше понять биологические процессы, а также открыл возможности для разработки биологических взаимодействий следующего поколения.
Квантовые компьютеры изначально были предложены в качестве метода более эффективного моделирования квантовых систем. В 1996 году Сет Ллойд продемонстрировал, что это возможно для некоторых видов квантовых систем [здесь], а десятилетие спустя Алан Аспуру-Гузик и коллеги показали, что химические системы являются одним из таких случаев [здесь]. В течение последних двух десятилетий проводились значительные исследования по тонкой настройке методов моделирования для химических систем, которые могут рассчитывать свойства, представляющие исследовательский интерес.
В принципе, квантовый компьютер способен эффективно решать полностью коррелированную проблему электронной структуры (уравнения FCI), что станет первым шагом для точной оценки энергий связи, а также для моделирования динамики химических систем. Классическая вычислительная химия была сосредоточена почти исключительно на приближенных методах, которые были полезны, например, для оценки термохимических величин малых молекул [здесь], но этого может быть недостаточно для процессов, связанных с разрывом или образованием связей. В отличие от этого, квантовые процессоры могут потенциально решить электронную проблему путем прямой диагонализации матрицы FCI, давая точный результат в пределах определенного базисного набора и, таким образом, решая множество проблем, возникающих из-за неправильного описания физики молекулярных процессов (например, поляризация лигандов). Более того, в отличие от классических подходов, они не обязательно требуют итеративного процесса, хотя первоначальное предположение все еще играет важную роль.
Хотя квантовые компьютеры не так глубоко изучены, они также преодолевают предельные приближения, которые были необходимы в классических вычислениях. Например, формулировка квантового моделирования в реальном пространстве автоматически учитывает ядерную волновую функцию в отсутствие приближения Борна – Оппенгеймера [здесь]. Это позволяет изучать неадиабатические эффекты некоторых систем, которые, как известно, важны для мутации ДНК [см. здесь] и механизма действия многих ферментов [здесь]. Также были предложены приложения квантовых вычислений для релятивистского моделирования систем [см. здесь], которые полезны для изучения переходных металлов, появляющихся в активных центрах многих ферментов.
В статье Райхера и его коллег [см. здесь] выявлено представление о шкале времени расчетов электронных структур в квантовом компьютере. Авторы рассмотрели кофактор FeMo фермента нитрогеназы, механизм фиксации азота которого до сих пор не изучен и является слишком сложным, чтобы его можно было изучить с помощью современных вычислительных подходов. Минимальный базовый расчет FCI для FeMoCo потребует нескольких месяцев и около 200 миллионов кубитов наивысшего класса существующего сегодняшний день. Тем не менее, эти оценки должны измениться с быстрым развитием технологий. За 3 года, прошедшие после публикации, алгоритмические достижения уже снизили временные требования на несколько порядков [см. здесь]. В дополнение к более мощным методам электронной структуры, быстрые версии современных приближенных методов, которые были исследованы недавно [см. здесь и здесь], могут значительно ускорить прототипирование, что могло бы быть полезным, например, при исследовании координат реакций ферментативных реакций, область которой является проблемой для вычислительной энзимологии [здесь]. Более того, благодаря лучшему пониманию межмолекулярных взаимодействий, катализируемому доступом к полностью коррелированным вычислениям или доступом к более быстрой пропускной способности, которая улучшает параметризацию, квантовое моделирование может значительно улучшить методы неквантового моделирования, такие как силовые поля.
И последнее, на что следует обратить внимание: в отличие от других областей исследования алгоритмов, таких как обучение на квантовых машинах, существует ряд краткосрочных алгоритмов квантового моделирования, которые можно запускать на нетребовательных, уже существующем оборудовании. Многочисленные экспериментальные группы по всему миру сообщили об успешных демонстрациях этих алгоритмов [здесь, здесь, тут и здесь].
К сожалению, есть и некоторые недостатки в квантовом моделировании систем. Как обсуждалось выше, очень трудно извлечь информацию из квантового компьютера. Восстановить всю волновую функцию сложнее, чем вычислить классическим способом. Это важный недостаток для химических задач, где аргументы, основанные на электронной структуре, являются главным источником понимания. Однако по сравнению с машинным обучением преимущества значительно перевешивают недостатки, и ожидается, что квантовое моделирование станет одним из первых полезных приложений практических квантовых вычислений [см. здесь].
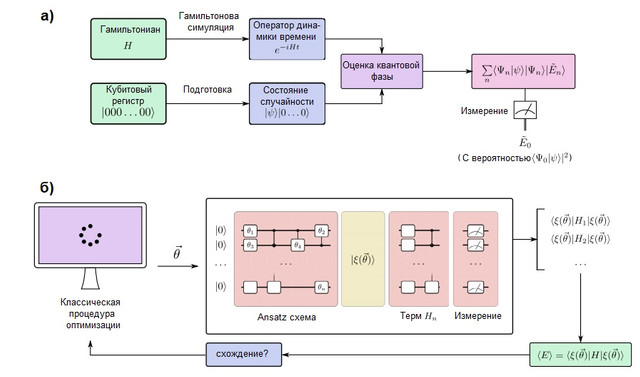
РИСУНОК 2. (а) Алгоритм квантового моделирования в отказоустойчивом квантовом компьютере. Кубиты разделены на два регистра: один готовится в состоянии , которое напоминает целевую волновую функцию, а другой остается в состоянии . Алгоритм квантовой оценки фазы (QPE) используется для нахождения собственных значений оператора эволюции времени , который подготовлен с использованием методов Гамильтонового моделирования. После QPE измерение квантового компьютера дает энергию основного состояния с вероятностью , поэтому важно подготовить состояние предположения с ненулевым перекрытием с истинной волновой функцией. (б) Вариационный алгоритм квантового моделирования в краткосрочном квантовом компьютере. Этот алгоритм объединяет квантовый процессор с классической процедурой оптимизации для выполнения нескольких коротких прогонов, которые выполняются достаточно быстро, чтобы избежать ошибок. Квантовый компьютер готовит состояние догадки с квантовой цепью анзаца, зависящей от нескольких параметров . Отдельные члены гамильтониана измеряются один за другим (или в коммутирующих группах, использующих более продвинутые стратегии), получая оценку ожидаемой энергии для конкретного вектора параметров. Затем параметры оптимизируются классической процедурой оптимизации до сходимости. Вариационный подход был распространен на многие алгоритмические задачи, помимо квантового моделирования.
Квантовые компьютеры, которые могут моделировать большие химические системы, должны быть отказоустойчивыми для того, чтобы выполнять произвольно глубокие алгоритмы без ошибок. Такой квантовый компьютер способен моделировать химическую систему, отображая поведение его электронов на поведение его кубитов и квантовых вентилей. Процесс квантового моделирования концептуально очень прост и изображен на рисунке 2 (а). Мы подготовим регистр кубитов, которые могут хранить волновую функцию, и реализуем унитарную эволюцию гамильтониана с помощью методов гамильтонового моделирования, которые обсуждаются ниже. С этими элементами квантовая подпрограмма, известная как квантовая фазовая оценка, способна найти собственные векторы и собственные значения системы. А именно, если регистр кубита изначально находится в состоянии |0?, конечное состояние будет:

Другими словами, конечное состояние представляет собой суперпозицию собственных значений и собственных векторов системы. Основное состояние затем измеряется с вероятностью . Чтобы максимизировать эту вероятность, исходное состояние устанавливается легким для подготовки, но также физически мотивированным состоянием, которое, как ожидается, будет похоже на точное основное состояние. Типичным примером является состояние Хартри-Фока, хотя для сильно коррелированных систем были исследованы и другие идеи [см. здесь].
Существует два распространенных способа представления электронов в молекуле: основанные на сетке и орбитальные или базисные методы (полный разбор см. в работе МакАрдла и его коллег [здесь]). В методах базисного набора электронная волновая функция представляется в виде суммы детерминантов Слейтера электронных орбиталей, которые могут быть непосредственно сопоставлены с регистром кубита [здесь и здесь]. Это требует выбора базиса и предварительного расчета электронных интегралов. С другой стороны, в сеточных методах задача формулируется как решение обыкновенного дифференциального уравнения в сетке. Преимущество моделирования на основе сетки заключается в том, что не требуется приближение Борна – Оппенгеймера или базового набора. Однако они не являются антисимметричными от природы, что требуется по принципу Паули из квантовой механики, поэтому необходимо обеспечить антисимметрию с помощью процедуры сортировки [здесь]. Методы, основанные на сетке, обсуждались в контексте моделирования химической динамики [см. здесь] и вычисления тепловой константы скорости [см. здесь]. Несмотря на различия, рабочий процесс квантового моделирования идентичен, как показано на рисунке 2.
Существует также несколько способов построения оператора . Мы представим простейшую технику, Троттеризацию, также известную как подбор формулы продукта [см. здесь]; полный обзор см. [здесь и здесь]. Троттеризация основана на предпосылке, что молекулярный гамильтониан может быть расщеплен как сумма членов, описывающих одно- и двухэлектронные взаимодействия. Если это так, то оператор можно реализовать в терминах соответствующих операторов для каждого члена в гамильтониане, используя формулу Троттера – Судзуки [здесь]:
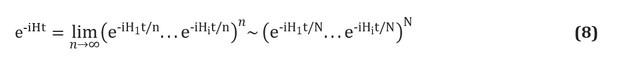
Например, при втором квантовании каждый член в этом выражении будет иметь вид или
или 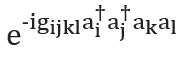 , где
, где  — соответственно операторы уничтожения и рождения. Явные, подробные конструкции схемы, представляющей эти термины, были даны Уитфилд и его коллегами [см. здесь]. После вычисления членов и , известных как электронные интегралы, величина полностью определяется. Также можно использовать формулы Троттера–Судзуки высшего порядка, чтобы уменьшить ошибку. Существует много других гамильтоновых методов моделирования. Примером мощного и изощренного метода являются кубитизация [здесь] и квантовая обработка сигналов [см. здесь], которые имеют доказуемо оптимальное асимптотическое масштабирование, хотя неясно, приведет ли это к лучшему практическому применению.
— соответственно операторы уничтожения и рождения. Явные, подробные конструкции схемы, представляющей эти термины, были даны Уитфилд и его коллегами [см. здесь]. После вычисления членов и , известных как электронные интегралы, величина полностью определяется. Также можно использовать формулы Троттера–Судзуки высшего порядка, чтобы уменьшить ошибку. Существует много других гамильтоновых методов моделирования. Примером мощного и изощренного метода являются кубитизация [здесь] и квантовая обработка сигналов [см. здесь], которые имеют доказуемо оптимальное асимптотическое масштабирование, хотя неясно, приведет ли это к лучшему практическому применению.
Многие проблемы вычислительной биологии и других дисциплин могут быть сформулированы как нахождение глобального минимума или максимума сложной, многомерной функции. Например, считается, что нативная структура белка является глобальным минимумом его гиперповерхности свободной энергии [см. здесь]. В другой области определение групп в сети взаимодействующих белков или биологических объектов эквивалентно нахождению оптимального подмножества узлов [см. здесь]. К сожалению, за исключением нескольких простых систем, проблемы оптимизации часто очень сложны. Хотя существуют эвристики для поиска приближенных решений, они, как правило, дают только локальные минимумы, и во многих случаях даже эвристика неразрешима. Способность квантовых компьютеров ускорять решения таких проблем оптимизации или находить лучшие решения была исследована подробно.
Тема оптимизации в квантовом компьютере сложна, поскольку зачастую не очевидно, может ли квантовый компьютер обеспечить какое-либо ускорение. В этом разделе мы представим обзор некоторых идей квантовой оптимизации. Хотя гарантии улучшения не так ясны, если сравнивать, например, с квантовым моделированием, от которого ожидается, что в долгосрочной перспективе оно будет полезным.
Квантовая адиабатическая оптимизация — один из самых популярных подходов в оптимизации, обусловленный наличием машин D-Wave [см. здесь], которые изначально реализуют этот подход. Адиабатические квантовые вычисления [здесь] основаны на адиабатической теореме квантовой механики [см. здесь]. Согласно этой теореме, если система подготовлена в основном состоянии гамильтониана, и этот гамильтониан изменяется достаточно медленно, система всегда будет оставаться в своем мгновенном основном состоянии. Это может быть использовано для выполнения вычислений путем кодирования задачи (например, функции оценки, которую мы надеемся минимизировать) в виде гамильтониана, и постепенного развития к этому гамильтониану из некоторой исходной системы, которая может быть тривиально подготовлена в ее основном состоянии. В общем, адиабатическая эволюция выражается так:

Здесь и — такие функции, что и для определенного времени T. Например, мы могли бы рассмотреть программу линейного отжига с и . Множество работ посвящено обсуждению времени выполнения адиабатического алгоритма, но общая эвристика заключается в том, что время выполнения максимально пропорционально обратному квадрату минимальной спектральной щели (наименьшей разности энергий между основным и первым возбужденными состояниями) во время адиабатической эволюции . Считается, что адиабатические квантовые вычисления (и квантовые вычисления в целом) не способны эффективно решить класс NP-полных задач, или, по крайней мере, ни один из этих способов не выдержал тщательной проверки [см. здесь].
В принципе, адиабатические квантовые вычисления эквивалентны универсальным квантовым вычислениям [см. здесь]. Эта универсальность имеет место только в том случае, если эволюция допускает нестохастичность, а это означает, что гамильтониан имеет неотрицательные недиагональные элементы в некоторой точке эволюции. Наиболее популярная экспериментальная реализация адиабатических квантовых вычислений, коммерциализированная компанией D-Wave Systems Inc., использует стохастические гамильтонианы, и поэтому она неуниверсальна. В профессиональной литературе есть некоторые опасения, что это разнообразие квантовых вычислений может быть классически симулируемым [здесь], что означает, что экспоненциальное ускорение может быть невозможным. Несмотря на эти опасения, этот способ широко использовался в качестве метаэвристического метода оптимизации, и недавно было показано, что он превосходит моделируемый отжиг [см. здесь].
Квантовая оптимизация была изучена за пределами адиабатической модели. Алгоритм квантовой приближенной оптимизации (англ. e quantum approximate optimization algorithm — QAOA) [см. здесь, тут и здесь] — это вариационный алгоритм оптимизации в квантовом компьютере, который вызвал значительный интерес в литературе. Было несколько экспериментальных реализаций QAOA в квантовых процессорах, например, [см. здесь] Рисунок 3.

РИСУНОК 3. (а) Моделирование адиабатического квантового компьютера, реализующего упрощенную задачу сворачивания белка, описанную [здесь]. Цвет кодирует десятичную логарифмическую вероятность конкретной двоичной строки. В конце вычисления два решения с самой низкой энергией имеют вероятность измерения, близкую к 0,5. За конечное время эволюция никогда не бывает полностью адиабатической, а другие двоичные строки имеют остаточные вероятности измерения. (б) Описание адиабатического процесса квантовых вычислений. Потенциал, управляющий кубитами, медленно изменяется, заставляя их вращаться. Обратите внимание, что представление сферы Блоха является неполным, так как оно не отображает корреляции между различными кубитами, которые необходимы для квантового преимущества. В конце эволюции система кубитов находится в классическом состоянии (или суперпозиции классических состояний), представляющем решение с наименьшей энергией. (в) Уровни энергии во время адиабатической квантовой эволюции. Количество времени, необходимое для обеспечения квазиадиабатической эволюции, определяется минимальной разностью энергий между уровнями, которая обозначена пунктирной линией
Прогнозирование структуры белка без матрицы по-прежнему остается основной открытой нерешенной проблемой в вычислительной биологии. Решение этой проблемы найдет широкое применение в молекулярной инженерии и дизайне лекарств. Согласно гипотезе фолдинга белка, нативная структура белка считается глобальным минимумом его свободной энергии [см. здесь], хотя существует много контрпримеров. Учитывая обширное конформационное пространство, доступное даже для небольших пептидов, исчерпывающие классические симуляции неразрешимы. Однако многие задаются вопросом, могут ли квантовые вычисления помочь решить эту проблему.
Литература по квантовым вычислениям сфокусирована на модели белковой решетки, где пептид моделируется как самоходная структура решетки, хотя некоторые другие модели также недавно начали применяться в практике вычислений [см. здесь]. Каждый узел решетки соответствует вычету, а взаимодействия между пространственными соседними узлами вносят вклад в энергетическую функцию. Существует несколько схем энергетического контакта, но только две были использованы в квантовых приложениях: гидрофобно-полярная модель [см. здесь], которая рассматривает только два класса аминокислот, и модель Миядзава-Джерниган [см. здесь], содержащая взаимодействия для каждой пары остатков. Хотя эти модели являются заметным упрощением, они предоставили существенное понимание принципов сворачивания белка [см. здесь] и были предложены в качестве грубого инструмента для изучения конформационного пространства перед дальнейшим детальным уточнением [см. здесь и здесь].
Почти вся работа была сосредоточена на адиабатических квантовых вычислениях, поскольку даже модельные пептиды требуют большого количества кубитов, а квантовые машины D-Wave являются самыми большими квантовыми устройствами, доступными на сегодняшний день.
Однако в недавно опубликованной статье Фингерхата и его коллег [см. здесь] была совершена попытка описания использования алгоритма QAOA. Оба метода имеют сходные характеристики, если задача о решетке белка закодирована как оператор Гамильтона. Этот метод впервые был рассмотрен Пердомо [см. здесь], который предложил использовать регистр кубитов для кодирования декартовых координат N аминокислот на D-мерной кубической решетке со сторонами N. Энергетическая функция выражается в гамильтониане, содержащем термы для вознаграждения контактов с белками: сохранить Первичную структуру и избегать аминокислотных совпадений. Вскоре после этой знаменательной статьи появилась еще одна статья, где обсуждалось построение более эффективных по битам моделей для двумерной решетки [см. здесь].
Эти кодировки были протестированы на реальном оборудовании в 2012 году, когда Пердомо с коллегами [см. здесь] вычислили конформацию самой низкой энергии пептида PSVKMA на квантовой машине D-Wave. Недавно исследовательская группа Бабея расширила кодировки «поворот» и «ромб» для трехмерных моделей и внедрили алгоритмические улучшения, которые уменьшают сложность и скорость перемещения кодирования Гамильтона [см. здесь]. В их работе использовался процессор D-Wave 2000Q для определения основного состояния хиголина (10 остатков) на квадратной решетке и триптофана (8 остатков) на кубической решетке, которые являются крупнейшими пептидами, исследованными на сегодняшний день. Эти экспериментальные реализации используют метод, в котором часть пептида является фиксированной. Это позволяет вводить большие задачи в квантовый компьютер за счет возможности исследования количества изучаемых проблемных параметров.
Нахождение конформации с наименьшей энергией в решеточной модели представляет собой трудную NP задачу [см. здесь и здесь], означающую, что при стандартных гипотезах не существует классического алгоритма для решения. Кроме того, в настоящее время считается, что квантовые компьютеры не могут предложить экспоненциальное ускорение для NP-полных и более сложных задач [см. здесь], хотя они могут предложить преимущества масштабирования, которые известны в литературе как «ограниченное квантовое ускорение» [см. здесь]. Недавно исследовательская группа Оутерела применила численное моделирование для исследования этого факта, заключив, что есть доказательства ограниченного квантового ускорения, хотя для этого результата могут потребоваться адиабатические машины, использующие коррекцию ошибок или квантовое моделирование в отказоустойчивых универсальных машинах [см. здесь].
Хотя большая часть литературы сосредоточена на модели белковой решетки, в недавно вышедшей статье [здесь] была предпринята попытка использовать квантовый отжиг для осуществления выборки ротамеров в энергетической функции Розетты [см. здесь]. Авторы использовали процессор D-Wave 2000Q для нахождения масштабирования, который казался почти постоянным по сравнению с классическим моделируемым отжигом. Очень похожий подход был представлен группой Марчанда [см. здесь] для выборки конформеров.
Квантовый компьютер может хранить и манипулировать огромным объемом информации, и выполнять алгоритмы со скоростью экспоненциально быстрее, чем любая классическая вычислительная технология. Потенциал даже небольших квантовых компьютеров может спокойно превзойти лучшие суперкомпьютеры существующие сегодня, что в итоге в рамках определенных задач может оказать преобразующее воздействие для вычислительной биологии, обещая перевести проблемы из разряда нерешаемых в трудные, а сложные в рутинные. Первые квантовые процессоры, которые могут решить полезные задачи, как ожидается, появятся в течение следующего десятилетия. Поэтому понимание того, что квантовые компьютеры могут и не могут делать, является приоритетом для каждого ученого в области вычислительных технологий.
Хотя мы только вступаем в эру практических квантовых вычислений, уже можно рассмотреть контуры новой квантовой вычислительной биологии на ближайшие десятилетия. Мы надеемся, что этот обзор вызовет интерес у специалистов по вычислительной биологии к технологиям, которые могут вскоре изменить область их экспериментальной и исследовательской деятельности. А специалисты по квантовым вычислениям в свою очередь смогут помочь биологам существенно развить уровень вычислительной биологии и биоинформатики, от которых ожидается множество значимых результатов для всего человечества.
От способности обрабатывать огромные объемы информации и намного эффективнее использовать алгоритмы машинного обучения, до алгоритмов квантового моделирования, которые могут улучшить вычисления (как по качественным, так и по количественным показателям) для дизайна новых лекарств, предсказания структуры белка, анализа различных процессов в биологическом организме и т.д. Эти захватывающие ум перспективы подвержены сегодня излишнему инфо хайпу, а значит важно обозначить предостережения и проблемы в этой новой технологии.
Предупреждение: в основе обзора статья группы европейских исследователей из Великобритании и Швейцарии (Carlos Outeiral, Martin Strahm, Jiye Shi, Garrett M. Morris, Simon C. Benjamin, Charlotte M. Deane. «The prospects of quantum computing in computational molecular biology», WIREs Computational Molecular Science published by Wiley Periodicals LLC, 2020). Самые сложные части статьи, связанные с изощренными математическими моделями не попадут в обзор. Но материал изначально сложный, от читателя требуются знания математики и квантовой физики.
Но если вы намерены начать изучать применение квантовых технологий в биоинформатике, то для того чтобы сначала въехать в тему, предлагается послушать небольшой доклад Виктора Соколова – старшего научного сотрудника M&S Decisions, в котором обозначаются некоторые современные проблемы моделирования лекарств:
Введение
С момента появления высокопроизводительных вычислений, алгоритмы и математические модели используются для решения проблем биологических наук — от изучения сложности генома человека до моделирования поведения биомолекул. Вычислительные методы сегодня регулярно используются для анализа и извлечения важной информации из биологических экспериментов, а также для прогнозирования поведения биологических объектов и систем. Фактически, 10 из 25 наиболее цитируемых научных работ касаются вычислительных алгоритмов, используемых в биологии [см. здесь], включая квантовое моделирование [здесь, тут, здесь и здесь], выравнивание последовательностей [здесь, здесь и здесь], вычислительную генетику [см. здесь] и дифракцию рентгеновских лучей в обработке данных [см. здесь и здесь].
Несмотря на такой прогресс, многие проблемы в биологии остаются неразрешимыми, с точки зрения их решения с помощью существующих вычислительных технологий. Лучшие алгоритмы для таких задач, как прогнозирование сворачивания белка, вычисление аффинности связывания лиганда с макромолекулой или поиск оптимального крупномасштабного геномного выравнивания, требуют вычислительных ресурсов, которые выходят за рамки даже самых мощных суперкомпьютеров, существующих сегодня.
Решение этих проблем может заключаться в смене парадигмы в вычислительных технологиях. В 1980-х годах независимо друг от друга, Ричард Фейнман [см. здесь] и Юрий Манин [см. здесь] предложили использовать квантово-механические эффекты для создания нового, более мощного поколения компьютеров.
Квантовая теория оказалась весьма успешным описанием физической реальности и привела с момента ее появления в начале 20-го века к таким достижениям, как лазеры, транзисторы и полупроводниковые микропроцессоры. Квантовый компьютер использует самые эффективные алгоритмы, используя операции, которые невозможны в классических машинах. Квантовые процессоры не работают быстрее, чем классические компьютеры, но работают совершенно по-другому, достигая беспрецедентного ускорения, избегая ненужных вычислений. Например, расчет полной электронной волновой функции средней молекулы лекарственного средства на любом современном суперкомпьютере с использованием обычных алгоритмов, как ожидается, займет больше времени, чем полный возраст нашей Вселенной [см. здесь], в то время как даже небольшой квантовый компьютер может решить эту проблему в сроки обозримые несколькими днями. Воодушевленные такими перспективами квантового преимущества, инженеры и ученые продолжают изыскания в области создания квантового процессора. Однако, технические трудности в производстве, управлении и защите квантовых систем невероятно сложны, и первые прототипы появились только в последнее десятилетие.
Важно заметить, что технические проблемы построения квантовых компьютеров не остановили разработку квантовых вычислительных алгоритмов. Даже при отсутствии аппаратного обеспечения алгоритмы можно анализировать математически, а появление высокопроизводительных симуляторов квантовых компьютеров, а также ранних прототипов в последние несколько лет позволили продвинуться в дальнейших исследованиях.
Некоторые из этих алгоритмов уже показали многообещающие потенциальные области применения в биологии. Например, алгоритм оценки квантовой фазы позволяет экспоненциально быстрее вычислять собственные значения [см. здесь], что может быть использовано для понимания крупномасштабной корреляции между частями белка или определения центральности графа в биологической сети. Квантовый алгоритм Харроу-Хасидима-Ллойда (HHL) [см. здесь] может решать некоторые линейные системы экспоненциально быстрее, чем любой известный классический алгоритм, а также может применять статистические методы обучения с гораздо быстрым процессом адаптации и возможностью управления большим количеством данных.
Алгоритмы квантовой оптимизации имеют широкое поле применения в области сворачивания белков и выборки конформеров, а также в проблемах, связанных с поиском минимумов или максимумов [см. здесь]. Наконец, недавно была разработана технология для моделирования квантовых систем, которые обещают, например, производить точные прогнозы взаимодействия лекарственного средства с рецепторами [см. здесь] или участвовать в изучении и понимании сложных процессов и химических механизмов, таких как фотосинтез [см. здесь]. Квантовые вычисления могут существенно изменить методы самой биологии, как это сделали в свое время классические вычисления.
Недавние заявления о квантовом превосходстве со стороны Google [см. здесь], хотя и оспариваемые IBM [см. здесь], указывают на то, что эра квантовых вычислений не за горами. Первые процессоры, использующие квантовые эффекты для выполнения вычислений невозможных для классических компьютерных технологий, ожидаются в течение следующего десятилетия [см. здесь].
В этом обзоре мы разберем ключевые моменты, где квантовые вычисления показывают перспективу для вычислительной биологии. В этих обзорах проанализировано потенциальное влияние квантовых вычислений в различных областях, включая машинное обучение [см. здесь, тут и здесь], квантовую химию [см. здесь, тут и здесь] и синтез лекарств [см. здесь]. Также недавно был опубликован отчет семинара NIMH по квантовым вычислениям в биологических науках [см. здесь].
В этом обзоре сначала дадим краткое описание того, что подразумевается под квантовыми вычислениями, и краткое введение в принципы квантовой обработки информации. Затем обсудим три основные области вычислительной биологии, где квантовые вычисления уже показали многообещающие алгоритмические разработки: статистические методы, расчеты электронной структуры и оптимизация. В стороне останутся некоторые важные темы, например, строковые алгоритмы, которые могут повлиять на анализ последовательности [см. здесь], алгоритмы формирования медицинских изображений [см. здесь], численные алгоритмы для дифференциальных уравнений [здесь ] и другие математические задачи или методы анализа биологических сетей [здесь]. Наконец, мы обсудим потенциальное влияние квантовых вычислений на вычислительную биологию в среднесрочной и долгосрочной перспективе.
1. Квантовая обработка информации
Квантовые компьютеры обещают решить проблемы биологических наук, такие например как, прогнозирование белково-лигандных взаимодействий или понимание коэволюции аминокислот в белках. И не просто решить, а сделать это экспоненциально быстрее, чем можно представить это с любым современным компьютером. Однако это изменение парадигмы требует фундаментальных изменений в нашем мышлении: квантовые компьютеры сильно отличаются от своих классических предшественников. Физические явления, которые лежат в основе квантового преимущества, часто являются нелогичными и противоречат здравому смыслу, а использование квантового процессора требует фундаментальных изменений в нашем понимании программирования. В этом разделе мы представляем принципы квантовой информации и то, как она обрабатывается для выполнения вычислений.
Мы объясняем, как информация работает по-разному в квантовой системе, где она хранится в кубитах, и как этой информацией можно манипулировать с помощью квантовых вентилей. Подобно переменным и функциям языка программирования, кубиты и квантовые вентили определяют основные элементы любого алгоритма. Также разберем почему создание квантового компьютера технически крайне сложный процесс и что может быть достигнуто с помощью ранних прототипов, которые ожидаются в ближайшие годы. Это введение будет охватывать только основные моменты; для всестороннего изучения читайте книгу Nielsen и Chuang [здесь].
1.1. Элементы квантовых алгоритмов
1.1.1. Квантовая информация: введение в кубит
Первая проблема в представлении квантовых вычислений — это представление о том, как они обрабатывают информацию. В квантовом процессоре информация обычно хранится в кубитах, которые являются квантовым аналогом классических битов. Кубит — это физическая система, подобная иону, ограниченному магнитным полем [см. здесь] или поляризованным фотоном [см. здесь], но о нем часто говорят абстрактно. Подобно коту Шредингера, кубит может принимать не только состояния 0 или 1, но также любую возможную комбинацию обоих состояний. Когда кубит наблюдается непосредственно, он больше не будет находиться в суперпозиции, которая разрушится до одного из возможных состояний, также, как кот Шредингера оказывается мертвым или живым после открытия ящика [см. здесь]. Что еще более важно, когда несколько кубитов объединены, они могут стать коррелированными, и взаимодействия с любым из них имеют последствия для всего коллективного состояния. Явление корреляции между множественными кубитами, известное как квантовое запутывание, является фундаментальным ресурсом квантовых вычислений.
В классической информации фундаментальной единицей информации является бит, система с двумя идентифицируемыми состояниями, часто обозначаемыми 0 и 1. Квантовый аналог, кубит, представляет собой систему с двумя состояниями, состояния которой помечены как |0? и |1?. Мы используем обозначение Дирака, где |*? идентифицирует квантовое состояние. Основное различие между классической и квантовой информацией заключается в том, что кубит может находиться в любой суперпозиции состояний |0? и |1?:
Комплексные коэффициенты ? и ? известны как амплитуды состояний, и они связаны с другим ключевым понятием квантовой механики: эффект физического измерения. Поскольку кубиты являются физическими системами, всегда можно придумать протокол для измерения их состояния. Если, например, состояния |0? и |1? соответствуют состояниям спина электрона в магнитном поле, то измерение состояния кубита является просто измерением энергии системы. Постулаты квантовой механики диктуют, что если система находится в суперпозиции возможных результатов измерения, то акт измерения должен изменить само состояние. Система суперпозиции развалится на стадии измерения; измерение, таким образом, уничтожает информацию, переносимую амплитудами в кубите.
Важные последствия для вычислений возникают, когда мы рассматриваем системы множественных кубитов, которые могут испытывать квантовую запутанность. Запутывание — это явление, при котором группа кубитов коррелируется, и любая операция над одним из этих кубитов будет влиять на общее состояние всех из них. Каноническим примером квантовой запутанности является парадокс Эйнштейна-Подольского-Розена, представленный в 1935 году [см. здесь]. Рассмотрим систему из двух кубитов, где, поскольку каждый из отдельных кубитов может принимать любую суперпозицию состояний {|0? и |1?}, составная система может принимать любую суперпозицию состояний {|00?,|01?,|10?,|11?} (и, соответственно, система N-кубитов может принимать любую из двоичных строк, от {|0...0? до |1...1?}. Одной из возможных суперпозиций системы являются так называемые состояния Белла, одно из которых имеет следующий вид:
Если мы выполним измерение на первом кубите, мы сможем наблюдать только |0? или |1?, каждый из которых будет иметь вероятность 1/2. Это не вносит никаких изменений в отношении случая одного кубита. Если исход для первого кубита был |0?, система будет свернута до системы |01?, и поэтому любое измерение на втором кубите даст |1? с вероятностью 1; аналогично, если результат первого измерения был |1?, измерение на втором кубите даст |0?. Операция (в данном случае измерение с результатом «0»), примененная к первому кубиту, влияет на результаты, которые можно увидеть при последующем измерении второго кубита.
Существование запутанности является основополагающим для полезных квантовых вычислений. Было доказано, что любой квантовый алгоритм, который не использует запутывание, может быть применен в классическом компьютере без существенной разницы в скорости [см. здесь и здесь]. Интуитивно, причина — это объем информации, которой может управлять квантовый компьютер. Если N кубитовая система не запутана, то амплитуды ее состояния могут быть описаны амплитудами каждого однокбитового состояния, то есть 2N амплитуды. Однако, если система запутана, все амплитуды будут независимыми, и регистр кубита сформирует -мерный вектор. Способность квантовых компьютеров манипулировать огромными объемами информации с помощью нескольких операций является одним из главных преимуществ квантовых алгоритмов и подкрепляет их способность решать проблемы экспоненциально быстрее классических компьютерных технологий.
1.1.2. Квантовые вентили
Информация, хранящаяся в кубитах, обрабатывается с помощью специальных операций, известных как квантовые вентили. Квантовые вентили — это физические операции, такие как например, лазерный импульс, направленный на ионный кубит, или набор зеркал и светоделителей, через которые должен двигаться фотонный кубит. Однако, вентили часто они рассматриваются как абстрактные операции. Постулаты квантовой механики накладывают некоторые строгие условия на природу квантовых вентилей в замкнутых системах, что позволяет представлять их в виде унитарных матриц, которые представляют собой линейные операции, сохраняющие нормализацию квантовой системы.
В частности, квантовый вентиль, примененный к запутанному регистру из N кубитов, эквивалентен умножению матрицы ? на вектор входа . Способность квантового компьютера хранить и выполнять вычисления огромных объемов информации — порядка — путем манипулирования несколькими элементами — порядка N — формирует основу его способности обеспечивать потенциально экспоненциальное преимущество над классическими компьютерами.
По сути, квантовые вентили — это любая разрешенная операция в системе кубитов. Постулаты квантовой механики накладывают два строгих ограничения на форму квантовых вентилей. Квантовые операторы являются линейными. Линейность — это математическое условие, которое, тем не менее, имеет глубокие последствия для физики квантовых систем и, следовательно, каким образом их можно использовать для вычислений. Если к суперпозиции состояний применяется линейный оператор , то результатом является суперпозиция отдельных состояний, на которые воздействует оператор. В кубите это означает:
Линейные операторы могут быть представлены в виде матриц, которые являются просто таблицами, обозначающими влияние линейного оператора на каждое базисное состояние. На рисунке 1 (в, г) показано матричное представление одного из двух кубитных и двух однобитных вентилей.
Однако не каждая матрица представляет действительные квантовые вентили. Мы ожидаем, что квантовые вентили, примененные к совокупности кубитов, дадут другой действительный набор кубитов, в частности, нормированный (например, в уравнении (3) мы ожидаем, что ). Это условие выполняется только в том случае, если матрица, представляющая квантовые вентили, является унитарной, то есть U†U = UU† = I, где U† — это матрица U, в которой строки и столбцы были переставлены, и каждое комплексное число было сопряжено (т.е. каждый мнимый элемент приобретает отрицательный фактор). Произвольная унитарная матрица ? представляет собой полностью допустимый N-кубитный квантовый вентиль.
В классических вычислениях существует только один нетривиальный вентиль для одного бита: вентиль NOT, который преобразует 0 в 1 и наоборот. В квантовых вычислениях существует бесконечное число унитарных матриц 2 ? 2, и любая из них является возможным однокубитным квантовым вентилем. Одним из первых успехов квантовых вычислений стало открытие, что это огромное количество возможностей может быть реализовано с помощью набора универсальных вентилей, влияющих на один и два кубита [см. здесь]. Другими словами, учитывая произвольные квантовые вентили, существует схема, построенная из одно- и двухкубитных вентилей, которая может привести ее в действие с произвольной точностью. К сожалению, это не означает, что приближение является эффективным. Большинство квантовых вентилей можно аппроксимировать только экспоненциальным числом вентилей из нашего универсального набора. Даже если эти вентили можно использовать для решения полезных задач, их реализация займет экспоненциально большое количество времени и может нивелировать любое квантовое преимущество.
РИСУНОК 1 (а) Сравнение классического бита с квантовым битом или «кубитом». В то время как классический бит может принимать только одно из двух состояний, 0 или 1, квантовый бит может принимать любое состояние вида . Одиночные кубиты часто изображаются с использованием представления сферы Блоха, где ? и ? понимаются как азимутальный и полярный углы в сфере единичного радиуса. (б) Схема кубита с ионной ловушкой, один из наиболее распространенных подходов к экспериментальным квантовым вычислениям. Ион (часто ) удерживается в высоком вакууме с помощью электромагнитных полей и подвергается воздействию сильного магнитного поля. Уровни сверхтонкой структуры разделяются в соответствии с эффектом Зеемана, и два выбранных уровня выбираются как состояния |0? и |1?. Квантовые вентили реализуются соответствующими лазерными импульсами, часто с участием других электронных уровней. Эта диаграмма была адаптирована из [см. здесь]. (в) Диаграмма квантовой схемы, реализующей X или квант контролируемого отрицания (CNOT).
Показано представление и изменение в сфере Блоха. (г) Квантовая схема для генерации состояния Белла , используя вентиль Адамара и вентиль CNOT (контролируемое отрицание). Пунктирная линия в середине контура указывает состояние после применения вентиля Адамара.
1.2. Квантовое оборудование
Квантовые алгоритмы могут решать интересные проблемы только в том случае, если они запускаются на соответствующем квантовом оборудовании. Существует много конкурирующих предложений по созданию квантового процессора на основе захватываемых ионов [см. здесь], сверхпроводящих схем [см. здесь] и фотонных устройств [см. здесь]. Тем не менее, все они сталкиваются с общей проблемой: ошибки во время вычислений, которые могут в буквальном смысле развалить вычислительный процесс. Одним из краеугольных камней квантовых вычислений является обнаружение того, что эти ошибки могут быть устранены с помощью квантовых кодов, исправляющих ошибки. К сожалению, эти коды также требуют очень большого увеличения числа кубитов, поэтому для достижения отказоустойчивости необходимы значительные технические усовершенствования.
Есть много источников ошибок, которые могут повлиять на квантовый процессор. Например, связь кубита с окружающей средой может привести к коллапсу системы в одно из ее классических состояний — процесс, известный как декогеренция. Небольшие флуктуации могут трансформировать квантовые вентили, которые в итоге, приведут к результатам, отличным от ожидаемых. Наименее подверженные ошибкам вентили на сегодняшний день были зарегистрированы в процессоре с захваченными ионами, с частотой появления одной ошибки на однокубитных вентилей и с 0,1% долей ошибок для двукубитовых вентилей [здесь и здесь]. Для сравнения, в недавней работе, проведенной Google, сообщалось о точности воспроизведения 0,1% для вентилей с одним кубитом и 0,3% для вентилей с двумя кубитами в сверхпроводящем процессоре [см. здесь]. Учитывая, что отказ одного шлюза может испортить расчет, нетрудно увидеть, что распространение ошибки может сделать вычисление бессмысленным уже после небольшой последовательности элементов.
Одним из главных направлений квантовых вычислений является разработка квантовых кодов, исправляющих ошибки. В 1990-х годах несколько исследовательских групп доказали, что эти коды могут достигать отказоустойчивых вычислений, при условии, что частоты ошибок вентилей находятся под определенным порогом, который зависит от кода [см. здесь, тут, здесь и здесь]. Один из самых популярных подходов, код поверхности, может работать с частотой ошибок, приближающейся к 1% [см. здесь].
К сожалению, квантовые коды с исправлением ошибок требуют использования большого количества реальных физических кубитов для кодирования абстрактного логического кубита, который используется для вычислений, и эти издержки растут с увеличением частоты ошибок. Например, квантовый алгоритм для факторизации простых чисел [см. здесь] мог бы в бесшумных условиях разложить 2000-битное число, используя приблизительно 4000 кубитов и, при частоте 16 ГГц, этот процесс занял бы около одного дня работы. Если частоту ошибок принять за 0,1%, этот же алгоритм, использующий код поверхности для исправления ошибок среды, потребует нескольких миллионов кубитов и такого же количества времени [см. здесь]. Учитывая, что текущая запись для управляемого, программируемого квантового процессора составляет 53 кубита [см. здесь], в этом исследовательском направлении предстоит еще долгий путь.
Многие группы предприняли усилия для разработки алгоритмов, которые можно запускать в так называемых шумовых квантовых процессорах среднего масштаба [см. здесь]. Например, вариационные алгоритмы объединяют классический компьютер с небольшим квантовым процессором, выполняя большое количество коротких квантовых вычислений, которые могут быть реализованы до того, как шум начнет оказывать существенные препятствия.
Эти алгоритмы часто используют параметризованную квантовую схему, которая выполняет особенно сложную задачу, и используют классический компьютер для оптимизации параметров. Способом разрешения является область уменьшения ошибок, в которой вместо достижения отказоустойчивости была предпринята попытка максимально уменьшить ошибки с минимальными усилиями для запуска более крупных цепей вентилей. Существует ряд подходов, которые включают применение дополнительных операций для отбрасывания прогонов вычислений с ошибками [см. здесь] или манипулирование частотой ошибок для экстраполяции до правильного результата [см. здесь и тут]. Хотя для основных областей применения потребуются очень большие отказоустойчивые квантовые компьютеры; ожидается, что устройства, доступные в течение следующего десятилетия, смогут решить эти проблемы [см. здесь].
2. Статистические методы и машинное обучение
В вычислительной биологии, где целью часто является сбор огромных объемов данных, статистические методы и машинное обучение являются ключевыми методами. Например, в геномике в аннотации информации о генах широко используются скрытые марковские модели (англ. hidden Markov models — HMM) [см. здесь]; при открытии лекарств был разработан широкий спектр статистических моделей для оценки молекулярных свойств или для предсказания связи лиганда с белком [см. здесь]; а в структурной биологии глубокие нейронные сети использовались как для предсказания белковых связей [см. здесь] и вторичной структуры [см. здесь], так и совсем недавно уже и трехмерных белковых структур [см. здесь].
Обучение и разработка таких моделей часто требует большого объема вычислений. Основным катализатором последних достижений в области машинного обучения стало понимание того, что графические процессоры общего назначения (GPU) могут значительно ускорить процедуру обучения. Обеспечивая экспоненциально более быстрые алгоритмы для машинного обучения модели квантовых вычислений могут обеспечить аналогичный интерес в фокусе применения к научным задачам.
В этом разделе мы объясним, как квантовые вычисления могут ускорить многочисленные статистические методы обучения.
2.1. Преимущества и недостатки квантового машинного обучения
Сначала мы рассмотрим преимущества, которые предоставляет квантовый компьютер для машинного обучения. За исключением идеализированных примеров, квантовые компьютеры могут изучать не больше информации, чем классический компьютер [см. здесь]. Однако в принципе они могут быть намного быстрее и способны обрабатывать гораздо больше данных, чем их классические аналоги. Например, человеческий геном содержит 3 миллиарда пар оснований, которые могут храниться в 1,2 ? классических битах — приблизительно 1,5 гигабайта. Регистр из N кубитов включает в себя амплитуд, каждая из которых может представлять классический бит, устанавливая k-ю амплитуду в 0 или 1 с соответствующим коэффициентом нормализации. Следовательно, человеческий геном может храниться в ~34 кубитах. Хотя эта информация не может быть извлечена из квантового компьютера, до тех пор, пока не подготовлено определенное состояние, на нем можно будет выполнить определенные алгоритмы машинного обучения. Что еще более важно, удвоение размера регистра до 68 кубитов оставляет достаточно места для хранения полного генома каждого живого человека в мире. Представление и анализ таких огромных объемов данных вполне соответствовал бы возможностям даже небольшого отказоустойчивого квантового компьютера.
Операции по обработке этой информации также могут выполняться экспоненциально быстрее. Например, алгоритмы множественного машинного обучения ограничены длительной инверсией ковариационной матрицы со штрафом на размерности матрицы. Однако алгоритм, предложенный Харроу, Хассидимом и Ллойдом [см. здесь], позволяет инвертировать матрицу в при некоторых условиях. Ключевое понимание заключается в том, что, в отличие от графических ускорителей, которые ускоряют вычисления за счет массивного параллелизма, квантовые алгоритмы имеют преимущество в сложности непосредственно используемых вычислительных алгоритмов. В некоторых случаях, особенно при существующем экспоненциальном ускорении, квантовые компьютеры среднего размера могут решать задачи обучения, доступные только для крупнейших классических суперкомпьютеров, доступных сегодня.
Улучшенное хранение и обработка данных имеет вторичные преимущества. Одной из сильных сторон нейронных сетей является их способность находить краткое представление данных [см. здесь]. Поскольку квантовая информация является более общей, чем классическая информация (в конце концов, состояния классического бита подразделяются на собственные состояния |0? и |1? или кубит), вполне возможно, что модели обучения с квантовой машиной могут лучше усваивать информацию, чем классические модели. С другой стороны, квантовые алгоритмы со сложностью логарифмического времени также позволяют повысить конфиденциальность данных [см. здесь]. Поскольку для обучения модели требуется , а требует реконструкции матрицы, для достаточно большого набора данных невозможно восстановить значительную часть информации, хотя все еще возможно эффективное обучение модели. В контексте биомедицинских исследований это может способствовать обмену данными при обеспечении конфиденциальности.
К сожалению, хотя алгоритмы квантового машинного обучения на бумаге могут значительно превзойти классические аналоги, практические трудности все еще остаются. Квантовые алгоритмы часто представляют собой подпрограммы, которые преобразуют вход в выход. Проблемы возникают именно на этих двух этапах: как подготовить адекватный ввод и как извлечь информацию из вывода [см. здесь]. Предположим, например, что мы используем алгоритм HHL [см. здесь] для решения линейной системы вида . В конце подпрограммы алгоритм выдаст регистр кубитов в следующем состоянии:
Здесь и — собственные векторы и собственные значения A, а — j-й коэффициент выражается через собственные векторы A, а знаменатель является просто константой нормализации. Видно, что это соответствует коэффициентам , которые хранятся в амплитудах различных состояний как и не доступны напрямую. Измерение регистра кубита приведет к его коллапсу в одно из состояний собственного вектора, а для переоценки амплитуд каждого требуются измерения , что в первую очередь перевешивает любое преимущество квантового алгоритма.
HHL и многие другие алгоритмы полезны только для вычисления глобального свойства решения, например, ожидаемого значения. Другими словами, HHL не может обеспечить решение системы уравнений или инвертировать матрицу за логарифмическое время, если нас не интересуют только глобальные свойства решения, которые могут быть получены с помощью нескольких физически наблюдаемых измерений. Это ограничивает использование некоторых подпрограмм, но было много предложений обойти эту проблему.
Ввод информации в квантовый компьютер является гораздо более серьезной проблемой. Большинство алгоритмов обучения квантовой машины предполагают, что квантовый компьютер имеет доступ к набору данных в виде состояния суперпозиции; например, существует регистр кубитов, который находится в состоянии вида:
Здесь — |bin(j)? это состояние, которое действует как индекс, а — соответствующая амплитуда. Это может быть использовано, например, для хранения элементов вектора или матрицы. В принципе, существует квантовая схема, которая может подготовить это состояние, действуя, скажем, в состоянии |0...0?. Однако его реализация может быть очень сложной, поскольку мы ожидаем, что аппроксимация случайного квантового состояния будет экспоненциально сложной и уничтожит любое возможное квантовое преимущество.
Большинство квантовых алгоритмов предполагают доступ к квантовой оперативной памяти (англ. quantum random access memory — QRAM) [см. здесь], которая является устройством черного ящика, способным построить эту суперпозицию. Хотя были предложены некоторые чертежи [см. здесь и здесь], насколько нам известно, пока нет работающего устройства. Более того, даже если бы такое устройство было доступно, нет гарантии, что оно не создаст узких мест, которые перевесят преимущества квантового алгоритма. Например, недавнее предложение на основе схем для QRAM [см. здесь] показывает неизбежные линейные затраты на число состояний, которые перевешивают любой алгоритм логарифмического времени. Наконец, даже если QRAM не вводит никаких дополнительных затрат, все равно необходимо будет выполнить классическую предварительную обработку данных — для примера генома потребуется доступ к 12 эксабайтам классического хранилища.
Наконец, мы должны подчеркнуть, что алгоритмы обучения квантовой машины не свободны от одной из наиболее распространенных проблем в практических приложениях: нехватки соответствующих данных. Доступность большого количества данных имеет решающее значение для успеха многих практических применений ИИ в молекулярной науке, например, в разработке молекул de novo [см. здесь]. Однако мощь квантовых алгоритмов может оказаться полезной, поскольку научные и технологические разработки, такие как появление лабораторий с самостоятельным управлением [см. здесь] предоставляют все больше и больше данных.
Квантовое машинное обучение может изменить методы обработки и анализа биологических данных. Однако, текущие практические проблемы реализации квантовых технологий все еще значительны.
2.2. Алгоритмы квантового машинного обучения
2.2.1. Обучение без учителя
Обучение без учителя включает в себя несколько методов извлечения информации из немаркированных наборов данных. В биологии, где секвенирование следующего поколения и большое международное сотрудничество стимулировали сбор данных, эти методы нашли широкое применение, например, для выявления связей между семействами биомолекул [см. здесь] или аннотированных геномов [см. здесь].
Одним из наиболее популярных алгоритмов обучения без учителя является анализ главных компонентов (англ. principal component analysis — PCA), который пытается уменьшить размерность данных путем нахождения линейных комбинаций признаков, которые максимизируют дисперсию [см. здесь]. Этот метод широко используется во всех видах наборов данных высокой размерности, включая данные РНК-микрочипов и масс-спектрометрии [см. здесь]. Квантовый алгоритм для проведения PCA был предложен группой исследователей [см. здесь]. По сути, этот алгоритм строит ковариационную матрицу данных в квантовом компьютере и использует подпрограмму, известную как оценка квантовой фазы, для вычисления собственных векторов в логарифмическом времени. Выходные данные алгоритма представляют собой состояние суперпозиции вида:
Здесь — это j-ая главная компонента, а — соответствующее собственное значение. Поскольку PCA интересуется большими собственными значениями, которые являются основными компонентами дисперсии, измерение конечного состояния даст подходящий главный компонент с высокой вероятностью. Повторение алгоритма несколько раз обеспечит набор основных компонентов. Эта процедура способна уменьшить размерность огромного количества информации, которая может храниться в квантовом компьютере.
Квантовый алгоритм также был предложен для конкретного метода анализа топологических данных, а именно для устойчивых гомологий [см. здесь]. Анализ топологических данных пытается извлечь информацию, используя топологические свойства в геометрии наборов данных; он был использован, например, при изучении агрегации данных [см. здесь] и сетевого анализа [см. здесь]. К сожалению, лучшие классические алгоритмы имеют экспоненциальную зависимость в размерности задачи, что ограничивает ее применение. Алгоритм Ллойда и соавт. также использует подпрограмму квантовой оценки фазы для экспоненциального ускорения диагонализации матрицы, достигая сложности . Наличие эффективного алгоритма для проведения топологического анализа может стимулировать его применение для анализа проблем биологических наук.
2.2.2. Контролируемое обучение
Контролируемое обучение относится к набору методов, с помощью которых можно делать прогнозы на основе помеченных данных. Цель состоит в том, чтобы построить модель, которая может классифицировать или предсказать свойства невидимых примеров. Контролируемое обучение широко используется в биологии для решения таких разнообразных задач, как прогнозирование аффинности связывания лиганда с белком [см. здесь] и диагностика заболеваний с помощью компьютера [см. здесь]. Разберем три подхода контролируемого обучения.
Машина опорных векторов (англ. support vector machine — SVM) — это алгоритм машинного обучения, который находит оптимальную гиперплоскость, разделяющую классы данных. SVM широко использовалась в фармацевтической промышленности для классификации данных малых молекул [см. здесь]. В зависимости от ядра, обучение SVM обычно занимает от до . Ребентрост [см. здесь] представил квантовый алгоритм, который может обучать SVM с полиномиальным ядром в , и позже он был расширен до ядра радиальной базисной функции (англ. radial basis function — RBF) [см. здесь]. К сожалению, неясно, как реализовать нелинейные операции, которые широко используются в SVM, учитывая, что квантовые операции ограничены, чтобы быть линейными. С другой стороны, квантовый компьютер допускает другие виды ядер, которые не могут быть реализованы в классическом компьютере [см. здесь].
Гауссова регрессия процесса (GP) — это метод, обычно используемый для построения суррогатных моделей, например, в байесовской оптимизации [см. здесь]. GP также широко используются для создания количественных моделей структура-активность (англ. quantitative structure–activity relationship — QSAR) свойств лекарств [см. здесь], а в последнее время также для моделирования молекулярной динамики [см. здесь]. Одним из недостатков регрессии GP является высокая величина инверсии ковариационной матрицы. Чжао с коллегами [см. здесь] предложили использовать алгоритм HHL для линейных систем, чтобы инвертировать эту матрицу, достигая экспоненциального ускорения (пока матрица разрежена и хорошо обусловлена) — свойства, которое часто достигается ковариационными матрицами. Что еще более важно, этот алгоритм был расширен для вычисления логарифма предельного правдоподобия [см. здесь], что является важным шагом для оптимизации гиперпараметров.
Одним из наиболее распространенных методов в вычислительной биологии является скрытая Марковская модель (англ. hidden Markov model — HMM), широко используемая в вычислительной аннотации генов и выравнивании последовательностей [см. здесь]. Этот метод содержит ряд скрытых состояний, каждое из которых связано с цепью Маркова; переходы между скрытыми состояниями приводят к изменениям в базовом распределении. В принципе, HMM не может быть непосредственно реализован в квантовом компьютере: выборка требует какого-то измерения, которое нарушит работу системы. Однако существует формулировка в терминах открытых квантовых систем, то есть квантовой системы, которая находится в контакте с окружающей средой, которая допускает марковскую систему [см. здесь]. Хотя не было предложено никаких улучшений классического алгоритма Баума – Уэлча для обучения HMM, было обнаружено, что квантовые HMM более выразительны: они могут воспроизводить распределение с меньшим количеством скрытых состояний [см. здесь]. Это может привести к более широкому применению метода в вычислительной биологии.
2.2.3. Нейронные сети и глубокое обучение
Недавние разработки в области машинного обучения были стимулированы открытием того факта, что множественные слои искусственных нейронных сетей могут обнаруживать сложные структуры в необработанных данных [см. здесь]. Глубокое обучение начало проникать в каждую научную дисциплину, и в вычислительной биологии его успехи включают точное предсказание связей в белках [см. здесь], улучшенную диагностику некоторых заболеваний [см. здесь], молекулярный дизайн [см. здесь] и моделирование [см. здесь и тут].
Учитывая значительные достижения в изучении нейронных сетей, была проделана значительная работа по разработке квантовых аналогов, которые могут способствовать дальнейшим улучшениям технологии.
Название искусственной нейронной сети часто относится к многослойному персептрону нейронной сети, где каждый нейрон принимает взвешенную линейную комбинацию своих входов и возвращает результат через нелинейную функцию активации. Основная проблема при разработке квантового аналога заключается в том, как реализовать нелинейную функцию активации с использованием линейных квантовых вентилей. В последнее время появилось множество предложений, и некоторые идеи включают измерения [см. здесь, тут и здесь], диссипативные квантовые вентили [тут ], квантовые вычисления с непрерывной переменной [здесь] и введение дополнительных кубитов для построения линейных вентилей, которые имитируют нелинейность [см. здесь]. Эти подходы направлены на реализацию квантовой нейронной сети, которая, как ожидается, будет более выразительной, чем классическая нейронная сеть, благодаря большей мощности квантовой информации. Преимущества или недостатки масштабирования обучения многослойного персептрона в квантовом компьютере неясны, хотя основное внимание уделяется возможной повышенной выразительности этих моделей.
Огромное количество недавних усилий было сосредоточено на машинах Больцмана, рекуррентных нейронных сетях, способных выступать в качестве генеративных моделей. После обучения они могут генерировать новые образцы, похожие на тренировочный набор.
Генеративные модели имеют важные приложения, например, в молекулярном дизайне de novo [см. здесь и здесь]. Хотя машины Больцмана очень мощные, чтобы вычислить градиенты и провести обучение необходимо решить сложную задачу выборки из распределения Больцмана, что ограничивает их практическое применение. Квантовые алгоритмы были предложены с использованием машины D-Wave [см. здесь, тут и здесь] или схемного алгоритма [см. здесь]; эта выборка из распределения Больцмана квадратично быстрее, чем это возможно в классическом исполнении [см. здесь].
Недавно была предложена эвристика для эффективной тренировки квантовых машин Больцмана, основанная на термализации системы [см. здесь]. Более того, в некоторых работах были предложены квантовые реализации порождающих состязательных сетей (англ. generative adversarial networks — GAN) [см. здесь, здесь и здесь]. Эти разработки предполагают улучшение генеративных моделей по мере развития аппаратного обеспечения квантовых вычислений.
3. Эффективное моделирование квантовых систем
Согласно представлениям моделей, химия регулируется переносом электронов. Химические реакции, а также взаимодействия между химическими объектами также контролируются распределением электронов и ландшафтом свободной энергии, который они формируют. Такие проблемы, как прогнозирование связывания лиганда с белком или понимание каталитического пути фермента, сводятся к пониманию электронной среды. К сожалению, моделирование этих процессов чрезвычайно сложно. Наиболее эффективный алгоритм для вычисления энергии системы электронов, полная конфигурация взаимодействия (англ. full configuration interaction — FCI), которая экспоненциально масштабируется с ростом количества электронов, и даже молекулы с несколькими атомами углерода едва доступны для вычислительных исследований [см. здесь]. Хотя существует множество приближенных методов, глубоко и обширно описанных в публикациях по теории функционала плотности [см. здесь и здесь], они могут быть неточными и даже резко потерпеть неудачу во многих представляющих интерес ситуациях, таких как моделирование переходного состояния реакции [см. здесь]. Точный и эффективный алгоритм изучения электронной структуры позволил бы лучше понять биологические процессы, а также открыл возможности для разработки биологических взаимодействий следующего поколения.
Квантовые компьютеры изначально были предложены в качестве метода более эффективного моделирования квантовых систем. В 1996 году Сет Ллойд продемонстрировал, что это возможно для некоторых видов квантовых систем [здесь], а десятилетие спустя Алан Аспуру-Гузик и коллеги показали, что химические системы являются одним из таких случаев [здесь]. В течение последних двух десятилетий проводились значительные исследования по тонкой настройке методов моделирования для химических систем, которые могут рассчитывать свойства, представляющие исследовательский интерес.
3.1. Преимущества и недостатки квантового моделирования
В принципе, квантовый компьютер способен эффективно решать полностью коррелированную проблему электронной структуры (уравнения FCI), что станет первым шагом для точной оценки энергий связи, а также для моделирования динамики химических систем. Классическая вычислительная химия была сосредоточена почти исключительно на приближенных методах, которые были полезны, например, для оценки термохимических величин малых молекул [здесь], но этого может быть недостаточно для процессов, связанных с разрывом или образованием связей. В отличие от этого, квантовые процессоры могут потенциально решить электронную проблему путем прямой диагонализации матрицы FCI, давая точный результат в пределах определенного базисного набора и, таким образом, решая множество проблем, возникающих из-за неправильного описания физики молекулярных процессов (например, поляризация лигандов). Более того, в отличие от классических подходов, они не обязательно требуют итеративного процесса, хотя первоначальное предположение все еще играет важную роль.
Хотя квантовые компьютеры не так глубоко изучены, они также преодолевают предельные приближения, которые были необходимы в классических вычислениях. Например, формулировка квантового моделирования в реальном пространстве автоматически учитывает ядерную волновую функцию в отсутствие приближения Борна – Оппенгеймера [здесь]. Это позволяет изучать неадиабатические эффекты некоторых систем, которые, как известно, важны для мутации ДНК [см. здесь] и механизма действия многих ферментов [здесь]. Также были предложены приложения квантовых вычислений для релятивистского моделирования систем [см. здесь], которые полезны для изучения переходных металлов, появляющихся в активных центрах многих ферментов.
В статье Райхера и его коллег [см. здесь] выявлено представление о шкале времени расчетов электронных структур в квантовом компьютере. Авторы рассмотрели кофактор FeMo фермента нитрогеназы, механизм фиксации азота которого до сих пор не изучен и является слишком сложным, чтобы его можно было изучить с помощью современных вычислительных подходов. Минимальный базовый расчет FCI для FeMoCo потребует нескольких месяцев и около 200 миллионов кубитов наивысшего класса существующего сегодняшний день. Тем не менее, эти оценки должны измениться с быстрым развитием технологий. За 3 года, прошедшие после публикации, алгоритмические достижения уже снизили временные требования на несколько порядков [см. здесь]. В дополнение к более мощным методам электронной структуры, быстрые версии современных приближенных методов, которые были исследованы недавно [см. здесь и здесь], могут значительно ускорить прототипирование, что могло бы быть полезным, например, при исследовании координат реакций ферментативных реакций, область которой является проблемой для вычислительной энзимологии [здесь]. Более того, благодаря лучшему пониманию межмолекулярных взаимодействий, катализируемому доступом к полностью коррелированным вычислениям или доступом к более быстрой пропускной способности, которая улучшает параметризацию, квантовое моделирование может значительно улучшить методы неквантового моделирования, такие как силовые поля.
И последнее, на что следует обратить внимание: в отличие от других областей исследования алгоритмов, таких как обучение на квантовых машинах, существует ряд краткосрочных алгоритмов квантового моделирования, которые можно запускать на нетребовательных, уже существующем оборудовании. Многочисленные экспериментальные группы по всему миру сообщили об успешных демонстрациях этих алгоритмов [здесь, здесь, тут и здесь].
К сожалению, есть и некоторые недостатки в квантовом моделировании систем. Как обсуждалось выше, очень трудно извлечь информацию из квантового компьютера. Восстановить всю волновую функцию сложнее, чем вычислить классическим способом. Это важный недостаток для химических задач, где аргументы, основанные на электронной структуре, являются главным источником понимания. Однако по сравнению с машинным обучением преимущества значительно перевешивают недостатки, и ожидается, что квантовое моделирование станет одним из первых полезных приложений практических квантовых вычислений [см. здесь].
3.2. Отказоустойчивые квантовые вычисления
РИСУНОК 2. (а) Алгоритм квантового моделирования в отказоустойчивом квантовом компьютере. Кубиты разделены на два регистра: один готовится в состоянии , которое напоминает целевую волновую функцию, а другой остается в состоянии . Алгоритм квантовой оценки фазы (QPE) используется для нахождения собственных значений оператора эволюции времени , который подготовлен с использованием методов Гамильтонового моделирования. После QPE измерение квантового компьютера дает энергию основного состояния с вероятностью , поэтому важно подготовить состояние предположения с ненулевым перекрытием с истинной волновой функцией. (б) Вариационный алгоритм квантового моделирования в краткосрочном квантовом компьютере. Этот алгоритм объединяет квантовый процессор с классической процедурой оптимизации для выполнения нескольких коротких прогонов, которые выполняются достаточно быстро, чтобы избежать ошибок. Квантовый компьютер готовит состояние догадки с квантовой цепью анзаца, зависящей от нескольких параметров . Отдельные члены гамильтониана измеряются один за другим (или в коммутирующих группах, использующих более продвинутые стратегии), получая оценку ожидаемой энергии для конкретного вектора параметров. Затем параметры оптимизируются классической процедурой оптимизации до сходимости. Вариационный подход был распространен на многие алгоритмические задачи, помимо квантового моделирования.
Квантовые компьютеры, которые могут моделировать большие химические системы, должны быть отказоустойчивыми для того, чтобы выполнять произвольно глубокие алгоритмы без ошибок. Такой квантовый компьютер способен моделировать химическую систему, отображая поведение его электронов на поведение его кубитов и квантовых вентилей. Процесс квантового моделирования концептуально очень прост и изображен на рисунке 2 (а). Мы подготовим регистр кубитов, которые могут хранить волновую функцию, и реализуем унитарную эволюцию гамильтониана с помощью методов гамильтонового моделирования, которые обсуждаются ниже. С этими элементами квантовая подпрограмма, известная как квантовая фазовая оценка, способна найти собственные векторы и собственные значения системы. А именно, если регистр кубита изначально находится в состоянии |0?, конечное состояние будет:
Другими словами, конечное состояние представляет собой суперпозицию собственных значений и собственных векторов системы. Основное состояние затем измеряется с вероятностью . Чтобы максимизировать эту вероятность, исходное состояние устанавливается легким для подготовки, но также физически мотивированным состоянием, которое, как ожидается, будет похоже на точное основное состояние. Типичным примером является состояние Хартри-Фока, хотя для сильно коррелированных систем были исследованы и другие идеи [см. здесь].
Существует два распространенных способа представления электронов в молекуле: основанные на сетке и орбитальные или базисные методы (полный разбор см. в работе МакАрдла и его коллег [здесь]). В методах базисного набора электронная волновая функция представляется в виде суммы детерминантов Слейтера электронных орбиталей, которые могут быть непосредственно сопоставлены с регистром кубита [здесь и здесь]. Это требует выбора базиса и предварительного расчета электронных интегралов. С другой стороны, в сеточных методах задача формулируется как решение обыкновенного дифференциального уравнения в сетке. Преимущество моделирования на основе сетки заключается в том, что не требуется приближение Борна – Оппенгеймера или базового набора. Однако они не являются антисимметричными от природы, что требуется по принципу Паули из квантовой механики, поэтому необходимо обеспечить антисимметрию с помощью процедуры сортировки [здесь]. Методы, основанные на сетке, обсуждались в контексте моделирования химической динамики [см. здесь] и вычисления тепловой константы скорости [см. здесь]. Несмотря на различия, рабочий процесс квантового моделирования идентичен, как показано на рисунке 2.
Существует также несколько способов построения оператора . Мы представим простейшую технику, Троттеризацию, также известную как подбор формулы продукта [см. здесь]; полный обзор см. [здесь и здесь]. Троттеризация основана на предпосылке, что молекулярный гамильтониан может быть расщеплен как сумма членов, описывающих одно- и двухэлектронные взаимодействия. Если это так, то оператор можно реализовать в терминах соответствующих операторов для каждого члена в гамильтониане, используя формулу Троттера – Судзуки [здесь]:
Например, при втором квантовании каждый член в этом выражении будет иметь вид
или , где — соответственно операторы уничтожения и рождения. Явные, подробные конструкции схемы, представляющей эти термины, были даны Уитфилд и его коллегами [см. здесь]. После вычисления членов и , известных как электронные интегралы, величина полностью определяется. Также можно использовать формулы Троттера–Судзуки высшего порядка, чтобы уменьшить ошибку. Существует много других гамильтоновых методов моделирования. Примером мощного и изощренного метода являются кубитизация [здесь] и квантовая обработка сигналов [см. здесь], которые имеют доказуемо оптимальное асимптотическое масштабирование, хотя неясно, приведет ли это к лучшему практическому применению.4. Задачи оптимизации
Многие проблемы вычислительной биологии и других дисциплин могут быть сформулированы как нахождение глобального минимума или максимума сложной, многомерной функции. Например, считается, что нативная структура белка является глобальным минимумом его гиперповерхности свободной энергии [см. здесь]. В другой области определение групп в сети взаимодействующих белков или биологических объектов эквивалентно нахождению оптимального подмножества узлов [см. здесь]. К сожалению, за исключением нескольких простых систем, проблемы оптимизации часто очень сложны. Хотя существуют эвристики для поиска приближенных решений, они, как правило, дают только локальные минимумы, и во многих случаях даже эвристика неразрешима. Способность квантовых компьютеров ускорять решения таких проблем оптимизации или находить лучшие решения была исследована подробно.
Тема оптимизации в квантовом компьютере сложна, поскольку зачастую не очевидно, может ли квантовый компьютер обеспечить какое-либо ускорение. В этом разделе мы представим обзор некоторых идей квантовой оптимизации. Хотя гарантии улучшения не так ясны, если сравнивать, например, с квантовым моделированием, от которого ожидается, что в долгосрочной перспективе оно будет полезным.
4.1. Оптимизация в квантовом процессоре
Квантовая адиабатическая оптимизация — один из самых популярных подходов в оптимизации, обусловленный наличием машин D-Wave [см. здесь], которые изначально реализуют этот подход. Адиабатические квантовые вычисления [здесь] основаны на адиабатической теореме квантовой механики [см. здесь]. Согласно этой теореме, если система подготовлена в основном состоянии гамильтониана, и этот гамильтониан изменяется достаточно медленно, система всегда будет оставаться в своем мгновенном основном состоянии. Это может быть использовано для выполнения вычислений путем кодирования задачи (например, функции оценки, которую мы надеемся минимизировать) в виде гамильтониана, и постепенного развития к этому гамильтониану из некоторой исходной системы, которая может быть тривиально подготовлена в ее основном состоянии. В общем, адиабатическая эволюция выражается так:
Здесь и — такие функции, что и для определенного времени T. Например, мы могли бы рассмотреть программу линейного отжига с и . Множество работ посвящено обсуждению времени выполнения адиабатического алгоритма, но общая эвристика заключается в том, что время выполнения максимально пропорционально обратному квадрату минимальной спектральной щели (наименьшей разности энергий между основным и первым возбужденными состояниями) во время адиабатической эволюции . Считается, что адиабатические квантовые вычисления (и квантовые вычисления в целом) не способны эффективно решить класс NP-полных задач, или, по крайней мере, ни один из этих способов не выдержал тщательной проверки [см. здесь].
В принципе, адиабатические квантовые вычисления эквивалентны универсальным квантовым вычислениям [см. здесь]. Эта универсальность имеет место только в том случае, если эволюция допускает нестохастичность, а это означает, что гамильтониан имеет неотрицательные недиагональные элементы в некоторой точке эволюции. Наиболее популярная экспериментальная реализация адиабатических квантовых вычислений, коммерциализированная компанией D-Wave Systems Inc., использует стохастические гамильтонианы, и поэтому она неуниверсальна. В профессиональной литературе есть некоторые опасения, что это разнообразие квантовых вычислений может быть классически симулируемым [здесь], что означает, что экспоненциальное ускорение может быть невозможным. Несмотря на эти опасения, этот способ широко использовался в качестве метаэвристического метода оптимизации, и недавно было показано, что он превосходит моделируемый отжиг [см. здесь].
Квантовая оптимизация была изучена за пределами адиабатической модели. Алгоритм квантовой приближенной оптимизации (англ. e quantum approximate optimization algorithm — QAOA) [см. здесь, тут и здесь] — это вариационный алгоритм оптимизации в квантовом компьютере, который вызвал значительный интерес в литературе. Было несколько экспериментальных реализаций QAOA в квантовых процессорах, например, [см. здесь] Рисунок 3.
РИСУНОК 3. (а) Моделирование адиабатического квантового компьютера, реализующего упрощенную задачу сворачивания белка, описанную [здесь]. Цвет кодирует десятичную логарифмическую вероятность конкретной двоичной строки. В конце вычисления два решения с самой низкой энергией имеют вероятность измерения, близкую к 0,5. За конечное время эволюция никогда не бывает полностью адиабатической, а другие двоичные строки имеют остаточные вероятности измерения. (б) Описание адиабатического процесса квантовых вычислений. Потенциал, управляющий кубитами, медленно изменяется, заставляя их вращаться. Обратите внимание, что представление сферы Блоха является неполным, так как оно не отображает корреляции между различными кубитами, которые необходимы для квантового преимущества. В конце эволюции система кубитов находится в классическом состоянии (или суперпозиции классических состояний), представляющем решение с наименьшей энергией. (в) Уровни энергии во время адиабатической квантовой эволюции. Количество времени, необходимое для обеспечения квазиадиабатической эволюции, определяется минимальной разностью энергий между уровнями, которая обозначена пунктирной линией
4.2. Предсказание структуры белка
Прогнозирование структуры белка без матрицы по-прежнему остается основной открытой нерешенной проблемой в вычислительной биологии. Решение этой проблемы найдет широкое применение в молекулярной инженерии и дизайне лекарств. Согласно гипотезе фолдинга белка, нативная структура белка считается глобальным минимумом его свободной энергии [см. здесь], хотя существует много контрпримеров. Учитывая обширное конформационное пространство, доступное даже для небольших пептидов, исчерпывающие классические симуляции неразрешимы. Однако многие задаются вопросом, могут ли квантовые вычисления помочь решить эту проблему.
Литература по квантовым вычислениям сфокусирована на модели белковой решетки, где пептид моделируется как самоходная структура решетки, хотя некоторые другие модели также недавно начали применяться в практике вычислений [см. здесь]. Каждый узел решетки соответствует вычету, а взаимодействия между пространственными соседними узлами вносят вклад в энергетическую функцию. Существует несколько схем энергетического контакта, но только две были использованы в квантовых приложениях: гидрофобно-полярная модель [см. здесь], которая рассматривает только два класса аминокислот, и модель Миядзава-Джерниган [см. здесь], содержащая взаимодействия для каждой пары остатков. Хотя эти модели являются заметным упрощением, они предоставили существенное понимание принципов сворачивания белка [см. здесь] и были предложены в качестве грубого инструмента для изучения конформационного пространства перед дальнейшим детальным уточнением [см. здесь и здесь].
Почти вся работа была сосредоточена на адиабатических квантовых вычислениях, поскольку даже модельные пептиды требуют большого количества кубитов, а квантовые машины D-Wave являются самыми большими квантовыми устройствами, доступными на сегодняшний день.
Однако в недавно опубликованной статье Фингерхата и его коллег [см. здесь] была совершена попытка описания использования алгоритма QAOA. Оба метода имеют сходные характеристики, если задача о решетке белка закодирована как оператор Гамильтона. Этот метод впервые был рассмотрен Пердомо [см. здесь], который предложил использовать регистр кубитов для кодирования декартовых координат N аминокислот на D-мерной кубической решетке со сторонами N. Энергетическая функция выражается в гамильтониане, содержащем термы для вознаграждения контактов с белками: сохранить Первичную структуру и избегать аминокислотных совпадений. Вскоре после этой знаменательной статьи появилась еще одна статья, где обсуждалось построение более эффективных по битам моделей для двумерной решетки [см. здесь].
Эти кодировки были протестированы на реальном оборудовании в 2012 году, когда Пердомо с коллегами [см. здесь] вычислили конформацию самой низкой энергии пептида PSVKMA на квантовой машине D-Wave. Недавно исследовательская группа Бабея расширила кодировки «поворот» и «ромб» для трехмерных моделей и внедрили алгоритмические улучшения, которые уменьшают сложность и скорость перемещения кодирования Гамильтона [см. здесь]. В их работе использовался процессор D-Wave 2000Q для определения основного состояния хиголина (10 остатков) на квадратной решетке и триптофана (8 остатков) на кубической решетке, которые являются крупнейшими пептидами, исследованными на сегодняшний день. Эти экспериментальные реализации используют метод, в котором часть пептида является фиксированной. Это позволяет вводить большие задачи в квантовый компьютер за счет возможности исследования количества изучаемых проблемных параметров.
Нахождение конформации с наименьшей энергией в решеточной модели представляет собой трудную NP задачу [см. здесь и здесь], означающую, что при стандартных гипотезах не существует классического алгоритма для решения. Кроме того, в настоящее время считается, что квантовые компьютеры не могут предложить экспоненциальное ускорение для NP-полных и более сложных задач [см. здесь], хотя они могут предложить преимущества масштабирования, которые известны в литературе как «ограниченное квантовое ускорение» [см. здесь]. Недавно исследовательская группа Оутерела применила численное моделирование для исследования этого факта, заключив, что есть доказательства ограниченного квантового ускорения, хотя для этого результата могут потребоваться адиабатические машины, использующие коррекцию ошибок или квантовое моделирование в отказоустойчивых универсальных машинах [см. здесь].
Хотя большая часть литературы сосредоточена на модели белковой решетки, в недавно вышедшей статье [здесь] была предпринята попытка использовать квантовый отжиг для осуществления выборки ротамеров в энергетической функции Розетты [см. здесь]. Авторы использовали процессор D-Wave 2000Q для нахождения масштабирования, который казался почти постоянным по сравнению с классическим моделируемым отжигом. Очень похожий подход был представлен группой Марчанда [см. здесь] для выборки конформеров.
Выводы
Квантовый компьютер может хранить и манипулировать огромным объемом информации, и выполнять алгоритмы со скоростью экспоненциально быстрее, чем любая классическая вычислительная технология. Потенциал даже небольших квантовых компьютеров может спокойно превзойти лучшие суперкомпьютеры существующие сегодня, что в итоге в рамках определенных задач может оказать преобразующее воздействие для вычислительной биологии, обещая перевести проблемы из разряда нерешаемых в трудные, а сложные в рутинные. Первые квантовые процессоры, которые могут решить полезные задачи, как ожидается, появятся в течение следующего десятилетия. Поэтому понимание того, что квантовые компьютеры могут и не могут делать, является приоритетом для каждого ученого в области вычислительных технологий.
Хотя мы только вступаем в эру практических квантовых вычислений, уже можно рассмотреть контуры новой квантовой вычислительной биологии на ближайшие десятилетия. Мы надеемся, что этот обзор вызовет интерес у специалистов по вычислительной биологии к технологиям, которые могут вскоре изменить область их экспериментальной и исследовательской деятельности. А специалисты по квантовым вычислениям в свою очередь смогут помочь биологам существенно развить уровень вычислительной биологии и биоинформатики, от которых ожидается множество значимых результатов для всего человечества.


xtovo
зачем повторять банальности? всё упирается в qbits.
все знают квантовую физику
здесь реальная физика, а не мозгоёбство…
как это получить?
++
Мне напоминает эпоху, когда теоретики соревновались с
Эйнштейном в создании какой-то теории Всего.
Такие же люди, которые не написали ни одной работающей программы, как эксперты, что-то пишут.
+++
модераторам — извините за резкость. Отличная статья. Обзор.