
Пользуетесь ли вы структурами данных и алгоритмами в повседневной работе? Я обратил внимание на то, что всё больше и больше людей считает алгоритмы чем-то таким, чем, без особой связи с реальностью, технические компании, лишь по собственной прихоти, интересуются на собеседованиях. Многие жалуются на то, что задачи на алгоритмы — это нечто из области теории, имеющей слабое отношение к настоящей работе. Такой взгляд на вещи, определённо, распространился после того, как Макс Хауэлл, автор Homebrew, опубликовал твит о том, что произошло с ним на собеседовании в Google:
Google: 90% наших инженеров пользуются программой, которую вы написали (Homebrew), но вы не можете инвертировать бинарное дерево на доске, поэтому — прощайте.
Хотя и у меня никогда не возникало нужды в инверсии бинарного дерева, я сталкивался с примерами реального использования структур данных и алгоритмов в повседневной работе, когда трудился в Skype/Microsoft, Skyscanner и Uber. Сюда входило написание кода и принятие решений, основанное на особенностях структур данных и алгоритмов. Но соответствующие знания я, по большей части, использовал для того чтобы понять то, как созданы некие системы, и то, почему они созданы именно так. Знание соответствующих концепций упрощает понимание архитектуры и реализации систем, в которых эти концепции используются.

В эту статью я включил рассказы о ситуациях, в которых структуры данных, вроде деревьев и графов, а так же различные алгоритмы, были использованы в реальных проектах. Здесь я надеюсь показать читателю то, что базовые знания структур данных и алгоритмов — это не бесполезная теория, нужная только для собеседований, а что-то такое, что, весьма вероятно, по-настоящему понадобится тому, кто работает в быстрорастущих инновационных технологических компаниях.
Здесь речь пойдёт о совсем небольшом количестве алгоритмов, но в том, что касается структур данных, могу отметить, что я коснусь тут практически всех из них. Никого не должно удивлять то, что я — не фанат таких вопросов, задаваемых на собеседованиях, в которых алгоритмам уделяется неоправданно много внимания, которые оторваны от практики и нацелены на экзотические структуры данных вроде красно-чёрных деревьев или АВЛ-деревьев. Я никогда такие вопросы на собеседованиях не задавал и задавать их не буду. В конце этой статьи я поделюсь своими мыслями о подобных собеседованиях. Но, несмотря на вышесказанное, знания о базовых структурах данных имеют огромную ценность. Эти знания позволяют подбирать именно то, что нужно для решения определённых практических задач.
А теперь давайте перейдём к примерам использования структур данных и алгоритмов в реальной жизни.
Когда мы разрабатывали Skype для Xbox One, код приходилось писать для чистой ОС Xbox, в которой не было необходимых нам библиотек. Мы разрабатывали одно из первых полномасштабных приложений для этой платформы. Нам нужна была система навигации по приложению, с которой можно было бы работать и пользуясь сенсорным экраном, и отдавая приложению голосовые команды.
Мы создали базовый навигационный фреймворк, основанный на WinJS. Для того чтобы это сделать, нам понадобилось поддерживать граф, похожий на DOM, что требовалось для организации наблюдения за элементами, с которыми мог взаимодействовать пользователь. Для поиска таких элементов мы выполняли обход DOM, который сводился к обходу дерева, то есть — существующей структуры DOM-элементов. Это — классический пример BFS или DFS (breadth-first search или depth-first search — поиск в ширину или поиск в глубину).
Если вы занимаетесь веб-разработкой — это значит, что вы уже работаете с древовидной структурой, а именно — с DOM. У всех узлов DOM могут быть дочерние узлы. Браузер выводит узлы на экран после обхода дерева DOM. Если вам надо найти конкретный элемент, то для решения этой задачи можно воспользоваться встроенными методами DOM. Например — методом getElementById. Альтернативой этого может стать разработка собственного BFS- или DFS-решения для обхода узлов и поиска того, что нужно. Например, нечто подобное сделано здесь.
Многие фреймворки, которые рендерят элементы пользовательского интерфейса, используют, в своих недрах, древовидные структуры. Так, React поддерживает виртуальную DOM и использует интеллектуальный алгоритм согласования (сравнения). Это позволяет добиваться высокой производительности за счёт того, что повторному рендерингу подвергаются только изменённые части интерфейса. Здесь можно найти визуализацию этого процесса.
В мобильной архитектуре Uber, RIBs, тоже используются деревья. Это роднит данную архитектуру с большинством других UI-фреймворков, которые выводят на экраны иерархические структуры элементов. В архитектуре RIBs поддерживается, с целью управления состоянием, дерево RIB. Прикрепляя к нему RIBs и открепляя их от него, управляют их рендерингом. Работая с RIBs, мы иногда делали наброски, пытаясь понять, вписывается ли RIBs в существующую иерархию, и обсуждали то, должны ли у RIBs, о котором идёт речь, быть видимые элементы. То есть — говорили о том, будет ли эта структура принимать участие в формировании визуального представления интерфейса, или она будет использоваться лишь для управления состоянием.

Переходы между состояниями при использовании RIBs. Здесь можно найти подробности о RIBs
Если вам когда-нибудь понадобится визуализировать иерархические элементы, то знайте, что обычно для этого используются древовидные структуры, их обход и рендеринг посещённых элементов. Я сталкивался со множеством внутренних инструментов, которые используют этот подход. Пример такого инструмента — средство для визуализации RIBs, созданное командой Mobile Platform из Uber. Вот доклад на эту тему.
Skyscanner — это проект, который направлен на поиск наиболее выгодных предложений по авиабилетам. Поиск таких предложений выполняется путём просмотра и анализа всех существующих в мире маршрутов и их комбинирования. Суть этой задачи больше относится к автоматическому сбору данных поисковым роботом, а не к кэшированию всех этих данных, так как авиакомпании самостоятельно вычисляют время ожидания следующего рейса. Но возможность планирования путешествия с посещением нескольких городов сводится к задаче поиска кратчайшего пути.
Планирование путешествий с посещением нескольких городов стало одной из возможностей, на реализацию которой у Skyscanner ушло довольно много времени. При этом сложности, в основном, относились к самой разрабатываемой системе. Лучшие предложения такого рода находят, используя алгоритмы поиска кратчайшего пути — вроде алгоритма Дейкстры или A*. Маршруты полётов представляют в виде ориентированного графа. Каждому его ребру назначен вес в виде стоимости билета. При поиске наилучшего маршрута нахождение самого дешёвого пути между двумя городами выполняется с использованием реализации модифицированного алгоритма A*. Если вам интересна тема подбора авиабилетов и поиска кратчайших маршрутов, то вот хорошая статья, посвящённая использованию BFS для решения подобных задач.
Правда, в случае со Skyscanner то, какой именно алгоритм был использован для решения задачи, было не особенно важно. Кэширование, использование поисковых роботов, организация работы с различными сайтами — всё это было куда сложнее, чем подбор алгоритма. Но при этом разные варианты задачи поиска кратчайшего пути возникают во множестве различных компаний, занимающихся планированием путешествий и оптимизирующих стоимость таких путешествий. Неудивительно то, что эта тема была предметом закулисных разговоров и в Skyscanner.
У меня редко бывали причины для самостоятельной реализации алгоритмов сортировки или для глубокого изучения тонкостей их устройства. Но, несмотря на это, интересно было разобраться в том, как работают такие алгоритмы — от пузырьковой сортировки, сортировки вставками, сортировки слиянием и сортировки выбором, до самого сложного алгоритма — быстрой сортировки. Я обнаружил, что редко возникает потребность в реализации подобных алгоритмов, особенно если не нужно писать функцию сортировки, являющуюся частью какой-нибудь библиотеки.
В Skype мне, правда, пришлось прибегнуть к практическому использованию моих знаний об алгоритмах сортировки. Один из наших программистов решил реализовать, для вывода контактов, сортировку вставками. В 2013 году, когда Skype подключался к сети, контакты загружались партиями. Для загрузки их всех требовалось некоторое время. В результате тот программист подумал, что лучше будет строить список контактов, упорядоченных по именам, используя сортировку вставками. Мы много обсуждали этот алгоритм, размышляли о том, почему бы просто не использовать что-то такое, что уже реализовано. В результате больше всего времени у нас ушло на то, чтобы как следует протестировать нашу реализацию алгоритма и проверить её производительность. Лично я не видел особого смысла в создании собственной реализации этого алгоритма. Но тогда проект был на такой стадии, на которой у нас было время на подобные дела.
Конечно, есть реальные ситуации, в которых эффективная сортировка играет в некоем проекте очень важную роль. И если разработчик может самостоятельно, основываясь на особенностях данных, выбирать наиболее подходящий алгоритм, это может дать заметный прирост производительности решения. Сортировка вставками может оказаться очень кстати там, где работают с большими наборами данных, передаваемых куда-либо в режиме реального времени, и тут же визуализируют эти данные. Сортировка слиянием может хорошо показывать себя при использовании подходов типа «разделяй и властвуй», в том случае, если речь идёт о работе с большими объёмами данных, хранящихся в разных узлах. Мне с подобными системами работать не доводилось, поэтому я пока продолжаю считать алгоритмы сортировки чем-то таким, что имеет ограниченное применение в повседневной работе. Это, правда, не касается важности понимания того, как именно работают разные алгоритмы сортировки.
Структура данных, которой я регулярно пользовался — это хеш-таблица. Сюда же можно отнести и хеш-функции. Это — полезнейший инструмент, которым можно пользоваться для решения самых разных задач — от подсчёта количества неких сущностей, обнаружения дубликатов, кеширования, до сценариев, вроде шардинга, используемых в распределённых системах. Хеш-таблицы — это, после массивов, структура данных, которая встречается в программировании чаще всего. Я ей пользовался в бесчисленном количестве ситуаций. Она есть почти во всех языках программирования, и её, если нужно, просто реализовать самостоятельно.
Стек — это структура данных, которая знакома каждому, кто занимался отладкой кода, написанного на языке, который поддерживает трассировку стека. Если говорить о стеке как о структуре данных, то я, в ходе работы, столкнулся с несколькими задачами, для решения которых она понадобилась. Но надо отметить, что со стеками я как следует познакомился, занимаясь отладкой и профилированием производительности кода. Стеки — это, кроме того, естественный выбор структуры данных, используемой при выполнении обхода дерева в глубину.
Мне редко приходилось прибегать к использованию очередей, но в кодовых базах различных проектов они мне встречались достаточно часто. Скажем, в очереди что-то помещали и что-то из них извлекали. Обычно очереди используются для реализации обхода деревьев в ширину, для решения этой задачи они подходят идеально. Очереди можно использовать и во многих других ситуациях. Однажды мне попался код для планирования заданий, в котором я обнаружил пример достойного применения очереди с приоритетом, реализованной средствами Python-модуля heapq, когда первыми выполнялись самые короткие задания.
Важные данные, которые пользователи вводят в мобильные приложения или в веб-приложения, нужно, перед передачей по сети, зашифровать. А расшифровывают их лишь там, где они нужны. Для того чтобы организовать такую схему работы, на клиентских и серверных частях приложений должны присутствовать реализации криптографических алгоритмов.
Разбираться в криптографических алгоритмах — это очень интересно. При этом для решения неких задач не стоит предлагать собственные алгоритмы. Это — одна из худших идей, которая может прийти в голову программисту. Вместо этого берётся существующий, хорошо документированный стандарт и используются встроенные примитивы соответствующих фреймворков. Обычно в качестве стандарта, выбираемого при реализации криптографических решений, выступает AES. Он достаточно надёжен для того чтобы шифровать с его помощью секретную информацию в США. Не существует известных работающих атак на протокол. AES-192 и AES-256 обычно, для решения большинства практических задач, достаточно надёжны.
Когда я пришёл в Uber, мобильная система шифрования и система шифрования веб-приложения уже были реализованы, в их основе лежали вышеописанные механизмы, поэтому у меня был повод для изучения подробностей об AES (Advanced Encryption Standard), о HMAC (Hashed Message Authentication Codes), об алгоритме RSA и о прочих подобных вещах. Интересно было и дойти до понимания того, как доказывают криптостойкость последовательности действий, применяемой при шифровании. Например, если говорить об аутентифицированном шифровании с присоединёнными данными, оказывается, что анализируя режимы encrypt-and-MAC, MAC-then-encrypt и encrypt-then-MAC, можно доказать криптостойкость лишь одного из них, хотя это и не означает того, что остальные не являются криптостойкими.
Вам вряд ли когда-нибудь придётся самостоятельно реализовывать криптографические примитивы, если только вы не будете заниматься реализацией совершенно нового криптографического фреймворка. Но вы вполне можете столкнуться с необходимостью принятия решений о том, какие именно примитивы использовать, и о том, как их комбинировать. Знания в сфере криптографических алгоритмов могут вам понадобиться и для того чтобы понять, почему в некоей системе применяется определённый подход к шифрованию данных.
В ходе работы над одним из проектов нам, в мобильном приложении, понадобилось реализовать сложную бизнес-логику. А именно, основываясь на полудюжине правил, нужно было показать один из нескольких экранов. Эти правила были очень сложными, что объяснялось тем, что в расчёт надо было принимать результаты последовательности проверок и предпочтения пользователя.
Программист, который приступил к решению этой задачи, сначала попробовал выразить все эти правила в виде инструкций if-else. Это привело к появлению чрезвычайно запутанного кода. В итоге решено было воспользоваться деревом решений. С его помощью было несложно произвести все необходимые проверки. Его было сравнительно просто реализовать. Кроме того, если нужно, его можно было, без особых проблем, изменить. Нам нужно было создать собственную реализацию дерева решений, такого, чтобы проверка условий осуществлялась бы на его рёбрах. Это — всё, что нам было нужно от этого дерева. Хотя мы могли бы сэкономить время, потраченное на реализацию дерева, воспользовавшись другим подходом, команда решила, что особое дерево будет легче поддерживать, и приступила к работе. Выглядит это дерево примерно так: рёбра символизируют результаты проверки условий (это — бинарные результаты, или результаты, представленные диапазонами значений), а листовые узлы дерева описывают экраны, на которые нужно выполнять переходы.
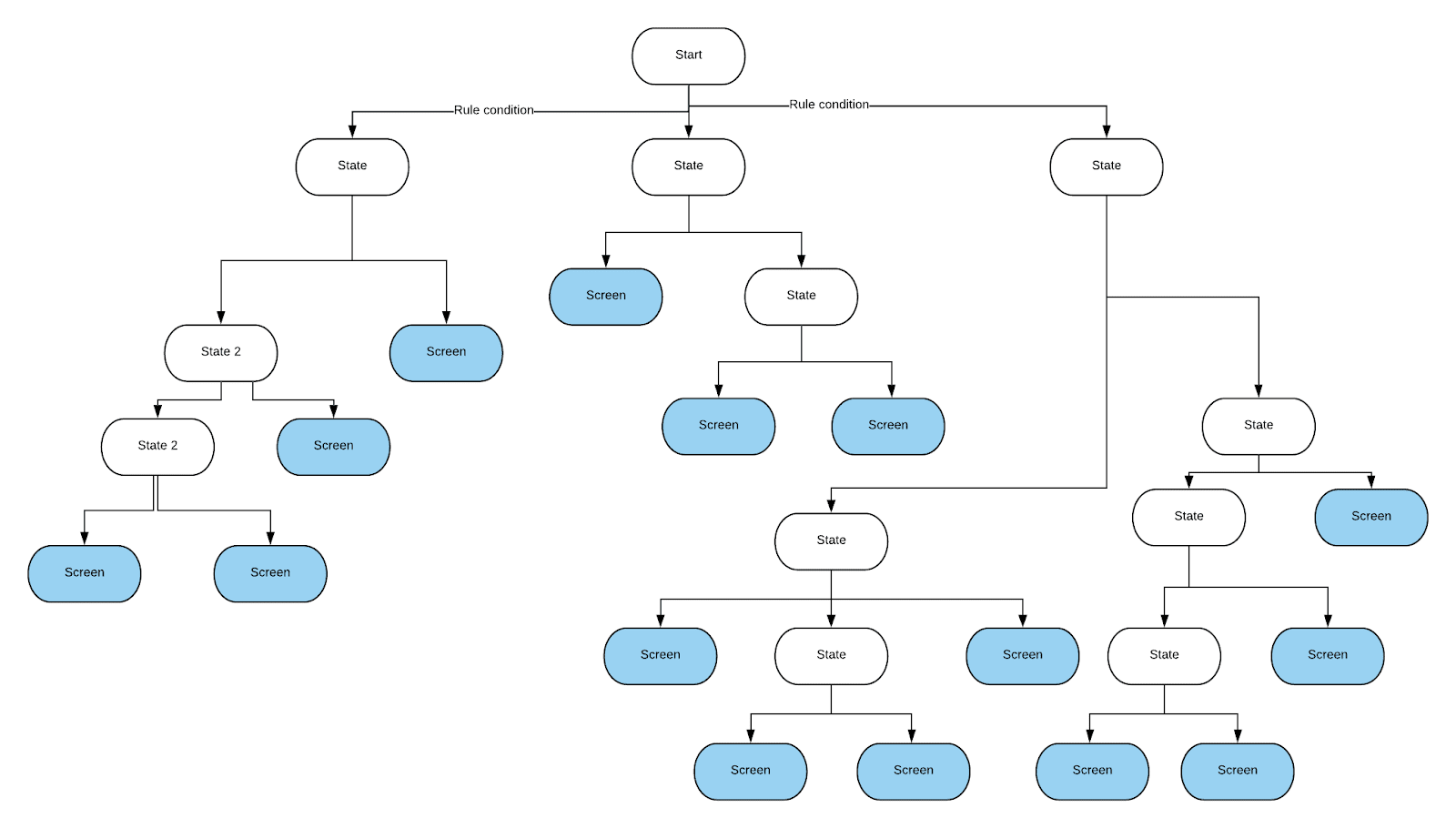
Структура созданного нами дерева решений, используемого для выяснения того, какой именно экран нужно показать. При принятии решения используется сложный набор правил
В системе сборки мобильной версии приложения Uber, называемой SubmitQueue, тоже использовалось дерево решений, но оно формировалось динамически. Команде Developer Experience нужно было решить сложную проблему выполнения ежедневного слияния (merge) сотен веток-источников изменений с целевой веткой. При этом на выполнение каждой сборки нужно было около 30 минут. Сюда входили компиляция, выполнение модульных и интеграционных тестов, а также тестов интерфейса. Распараллеливание сборок было недостаточно хорошим решением, так как в различных сборках часто были перекрывающиеся изменения, что вызывало конфликты слияния. На практике это означало, что иногда программистам приходилось ждать 2-3 часа, прибегать к команде rebase, и снова запускать процесс слияния веток, надеясь, что в этот раз они не столкнутся с конфликтом.
Команда Developer Experience применила инновационный подход, который заключался в прогнозировании конфликтов слияния и в соответствующем размещении сборок в очереди. Делалось это с использованием особого бинарного дерева принятия решений (speculation tree).

В SubmitQueue используется бинарное дерево принятия решений, рёбра которого снабжены комментариями о прогнозируемых вероятностях. Этот подход позволяет определить то, какие наборы сборок можно выполнять параллельно. Делается это ради сокращения времени между получением и исполнением задач и ради повышения пропускной способности системы. В ветку master при этом должен попадать только полностью проверенный и работоспособный код
Специалисты команды Developer Experience, создавшие эту систему, написали отличный материал о ней. А вот — ещё одна статья на ту же тему, хорошо иллюстрированная. Результатом внедрения данной системы стало создание гораздо более быстрой, чем раньше, системы сборки проектов. Она позволила оптимизировать время сборки проектов и помогла облегчить жизнь сотен мобильных программистов.
Это — последний проект, о котором я хочу тут рассказать. Он был полностью основан на одной особенной структуре данных. Именно занимаясь им я об этой структуре данных и узнал. Речь идёт о шестиугольной сетке с иерархическими индексами.
Одной из самых сложных и интересных проблем в Uber была оптимизация стоимости поездок и распределения заказов по партнёрам. Цены на поездки могут динамически меняться, водители постоянно находятся в движении. Инженерами Uber была создана сеточная система H3. Она предназначена для визуализации и анализа данных по городам в разных масштабах. Структура данных, которая используется для решения вышеозначенных задач, представляет собой шестиугольную сетку с иерархическими индексами. Для визуализации данных используется пара специализированных внутренних инструментов.

Разбиение карты на шестиугольные ячейки
Эта структура данных отличается собственной системой индексирования, обхода, собственными определениями отдельных областей сетки, собственными функциями. Детальное описание этого всего можно найти в документации к соответствующему API. Подробности об H3 можно почитать здесь. Вот — исходный код. Здесь можно найти рассказ о том, как и почему была создана эта система.
Опыт работы над этой системой позволил мне прочувствовать то, что создание собственных специализированных структур данных может иметь смысл при решении весьма специфических задач. Существует совсем немного задач, в решении которых можно применить шестиугольную сетку, если не учитывать разбиение на фрагменты карт с сопоставлением с каждым получившимся фрагментом данных разных уровней. Но, как и в других случаях, если вы знакомы с другими структурами данных, понять эту будет гораздо проще. А человеку, который разобрался с шестиугольной сеткой, проще будет создать новую структуру данных, предназначенную для решения задач, похожих на те которые решают с помощью такой сетки.
Выше я рассказал о том, с какими структурами данных и алгоритмами я столкнулся, долгое время работая в различных компаниях. Предлагаю сейчас вернуться к тому твиту Макса Хауэлла, который я упоминал в самом начале материала. Там Макс жаловался на то, что на собеседовании в Google ему предложили инвертировать бинарное дерево на доске. Он этого не сделал. Ему указали на дверь. В этой ситуации я — на стороне Макса.
Я считаю, что знания о том, как работают популярные алгоритмы, или о том, как устроены экзотические структуры данных, это — не те знания, которые нужны для работы в технологической компании. Нужно знать о том, что такое алгоритм, нужно уметь самостоятельно придумывать простые алгоритмы, например, работающие по «жадному» принципу. Ещё нужно обладать знаниями о самых распространённых структурах данных, вроде хеш-таблиц, очередей и стеков. Но что-то достаточно специфическое, вроде алгоритма Дейкстры или A*, или чего-то ещё более сложного, это — не то, что нужно заучивать наизусть. Если вам эти алгоритмы реально понадобятся — вы легко сможете найти справочные материалы по ним. Я, например, если говорить об алгоритмах, не относящихся к алгоритмам сортировки, обычно стремился разобраться с ними в общих чертах и понять их сущность. То же касается и экзотических структур данных вроде красно-чёрных деревьев и АВЛ-деревьев. У меня никогда не возникало нужды в их использовании. А если бы они мне и понадобились — я всегда мог бы освежить знания о них, прибегнув к соответствующим публикациям. Я, проводя собеседования, как я уже говорил, никогда не задаю подобные вопросы и не планирую их задавать.
Я за практические задачи, имеющие отношение к программированию, при решении которых можно применить множество подходов: от методов «грубой силы» и «жадных» вариантов алгоритмов до более продвинутых алгоритмических идей. Например, я полагаю, что вполне нормальной является задача, касающаяся выравнивания текста по ширине, вроде этой. Мне, например, пришлось решать эту задачу при создании компонента для рендеринга текста на Windows Phone. Решить эту задачу можно, просто воспользовавшись массивом и несколькими инструкциями if-else, не прибегая к каким-то мудрёным структурам данным.
На самом деле, многие команды и компании преувеличивают значимость алгоритмических задач. Мне понятна привлекательность вопросов по алгоритмам. Они позволяют оценить соискателя за короткое время, вопросы легко переделывать, а значит, если вопросы, которые кому-то задавали, станут достоянием общественности, это особых проблем не вызовет. Вопросы по алгоритмам хорошо подходят для организации испытаний большого количества соискателей. Например, можно создать пул, состоящий из более чем сотни вопросов, и случайным образом раздать их соискателям. Вопросы, касающиеся динамического программирования и экзотических структур данных, встречаются всё чаще и чаще. Особенно — в Кремниевой долине. Эти вопросы могут помочь компаниям в найме сильных программистов. Но эти же вопросы способны закрыть дорогу в компании тем людям, которые преуспели в делах, где глубокие знания алгоритмов не нужны.
Если вы — из компании, которая нанимает только тех, кто едва ли не с рождения обладает глубокими знаниями сложных алгоритмов, я предлагаю вам хорошо подумать о том, те ли это люди, что вам нужны. Я, например, нанимал прекрасные команды в Skyscanner (Лондон) и в Uber (Амстердам), не задавая соискателям хитрых вопросов по алгоритмам. Я ограничивался самыми обычными структурами данных и проверкой возможностей собеседуемых, имеющих отношение к решению задач. То есть — им нужно было знать о распространённых структурах данных и уметь придумывать простые алгоритмы для решения стоящих перед ними задач. Структуры данных и алгоритмы — это всего лишь инструменты.
Если вы работаете в динамичной инновационной технологической компании, то вы, наверняка, в коде продуктов этой компании, столкнётесь с реализациями самых разных структур данных и алгоритмов. Если вы занимаетесь разработкой чего-то совершенно нового, то вам часто придётся искать структуры данных, упрощающие решение встающих перед вами задач. В подобных ситуациях вам, чтобы сделать правильный выбор, пригодятся общие знания об алгоритмах и структурах данных и об их плюсах и минусах.
Структуры данных и алгоритмы — это инструменты, которыми вы должны уверенно пользоваться, создавая программы. Зная эти инструменты, вы увидите много такого, что вам уже известно, в кодовых базах, в которых они используются. Кроме того, подобные знания позволят вам с гораздо большей уверенностью решать сложные задачи. Вы будете знать о теоретических ограничениях алгоритмов, о том, каким оптимизациям их можно подвергнуть. Это поможет вам, в итоге, выйти на решение, которое, с учётом всех необходимых компромиссов, окажется настолько хорошим, насколько это возможно.
Если вы хотите лучше изучить структуры данных и алгоритмы — вот несколько советов и ресурсов:
А с какими структурами данных и алгоритмами сталкивались на практике вы?

Google: 90% наших инженеров пользуются программой, которую вы написали (Homebrew), но вы не можете инвертировать бинарное дерево на доске, поэтому — прощайте.
Хотя и у меня никогда не возникало нужды в инверсии бинарного дерева, я сталкивался с примерами реального использования структур данных и алгоритмов в повседневной работе, когда трудился в Skype/Microsoft, Skyscanner и Uber. Сюда входило написание кода и принятие решений, основанное на особенностях структур данных и алгоритмов. Но соответствующие знания я, по большей части, использовал для того чтобы понять то, как созданы некие системы, и то, почему они созданы именно так. Знание соответствующих концепций упрощает понимание архитектуры и реализации систем, в которых эти концепции используются.
В эту статью я включил рассказы о ситуациях, в которых структуры данных, вроде деревьев и графов, а так же различные алгоритмы, были использованы в реальных проектах. Здесь я надеюсь показать читателю то, что базовые знания структур данных и алгоритмов — это не бесполезная теория, нужная только для собеседований, а что-то такое, что, весьма вероятно, по-настоящему понадобится тому, кто работает в быстрорастущих инновационных технологических компаниях.
Здесь речь пойдёт о совсем небольшом количестве алгоритмов, но в том, что касается структур данных, могу отметить, что я коснусь тут практически всех из них. Никого не должно удивлять то, что я — не фанат таких вопросов, задаваемых на собеседованиях, в которых алгоритмам уделяется неоправданно много внимания, которые оторваны от практики и нацелены на экзотические структуры данных вроде красно-чёрных деревьев или АВЛ-деревьев. Я никогда такие вопросы на собеседованиях не задавал и задавать их не буду. В конце этой статьи я поделюсь своими мыслями о подобных собеседованиях. Но, несмотря на вышесказанное, знания о базовых структурах данных имеют огромную ценность. Эти знания позволяют подбирать именно то, что нужно для решения определённых практических задач.
А теперь давайте перейдём к примерам использования структур данных и алгоритмов в реальной жизни.
Деревья и обход деревьев: Skype, Uber и UI-фреймворки
Когда мы разрабатывали Skype для Xbox One, код приходилось писать для чистой ОС Xbox, в которой не было необходимых нам библиотек. Мы разрабатывали одно из первых полномасштабных приложений для этой платформы. Нам нужна была система навигации по приложению, с которой можно было бы работать и пользуясь сенсорным экраном, и отдавая приложению голосовые команды.
Мы создали базовый навигационный фреймворк, основанный на WinJS. Для того чтобы это сделать, нам понадобилось поддерживать граф, похожий на DOM, что требовалось для организации наблюдения за элементами, с которыми мог взаимодействовать пользователь. Для поиска таких элементов мы выполняли обход DOM, который сводился к обходу дерева, то есть — существующей структуры DOM-элементов. Это — классический пример BFS или DFS (breadth-first search или depth-first search — поиск в ширину или поиск в глубину).
Если вы занимаетесь веб-разработкой — это значит, что вы уже работаете с древовидной структурой, а именно — с DOM. У всех узлов DOM могут быть дочерние узлы. Браузер выводит узлы на экран после обхода дерева DOM. Если вам надо найти конкретный элемент, то для решения этой задачи можно воспользоваться встроенными методами DOM. Например — методом getElementById. Альтернативой этого может стать разработка собственного BFS- или DFS-решения для обхода узлов и поиска того, что нужно. Например, нечто подобное сделано здесь.
Многие фреймворки, которые рендерят элементы пользовательского интерфейса, используют, в своих недрах, древовидные структуры. Так, React поддерживает виртуальную DOM и использует интеллектуальный алгоритм согласования (сравнения). Это позволяет добиваться высокой производительности за счёт того, что повторному рендерингу подвергаются только изменённые части интерфейса. Здесь можно найти визуализацию этого процесса.
В мобильной архитектуре Uber, RIBs, тоже используются деревья. Это роднит данную архитектуру с большинством других UI-фреймворков, которые выводят на экраны иерархические структуры элементов. В архитектуре RIBs поддерживается, с целью управления состоянием, дерево RIB. Прикрепляя к нему RIBs и открепляя их от него, управляют их рендерингом. Работая с RIBs, мы иногда делали наброски, пытаясь понять, вписывается ли RIBs в существующую иерархию, и обсуждали то, должны ли у RIBs, о котором идёт речь, быть видимые элементы. То есть — говорили о том, будет ли эта структура принимать участие в формировании визуального представления интерфейса, или она будет использоваться лишь для управления состоянием.
Переходы между состояниями при использовании RIBs. Здесь можно найти подробности о RIBs
Если вам когда-нибудь понадобится визуализировать иерархические элементы, то знайте, что обычно для этого используются древовидные структуры, их обход и рендеринг посещённых элементов. Я сталкивался со множеством внутренних инструментов, которые используют этот подход. Пример такого инструмента — средство для визуализации RIBs, созданное командой Mobile Platform из Uber. Вот доклад на эту тему.
Взвешенные графы и поиск кратчайшего пути: Skyscanner
Skyscanner — это проект, который направлен на поиск наиболее выгодных предложений по авиабилетам. Поиск таких предложений выполняется путём просмотра и анализа всех существующих в мире маршрутов и их комбинирования. Суть этой задачи больше относится к автоматическому сбору данных поисковым роботом, а не к кэшированию всех этих данных, так как авиакомпании самостоятельно вычисляют время ожидания следующего рейса. Но возможность планирования путешествия с посещением нескольких городов сводится к задаче поиска кратчайшего пути.
Планирование путешествий с посещением нескольких городов стало одной из возможностей, на реализацию которой у Skyscanner ушло довольно много времени. При этом сложности, в основном, относились к самой разрабатываемой системе. Лучшие предложения такого рода находят, используя алгоритмы поиска кратчайшего пути — вроде алгоритма Дейкстры или A*. Маршруты полётов представляют в виде ориентированного графа. Каждому его ребру назначен вес в виде стоимости билета. При поиске наилучшего маршрута нахождение самого дешёвого пути между двумя городами выполняется с использованием реализации модифицированного алгоритма A*. Если вам интересна тема подбора авиабилетов и поиска кратчайших маршрутов, то вот хорошая статья, посвящённая использованию BFS для решения подобных задач.
Правда, в случае со Skyscanner то, какой именно алгоритм был использован для решения задачи, было не особенно важно. Кэширование, использование поисковых роботов, организация работы с различными сайтами — всё это было куда сложнее, чем подбор алгоритма. Но при этом разные варианты задачи поиска кратчайшего пути возникают во множестве различных компаний, занимающихся планированием путешествий и оптимизирующих стоимость таких путешествий. Неудивительно то, что эта тема была предметом закулисных разговоров и в Skyscanner.
Сортировка: Skype (или что-то вроде этого)
У меня редко бывали причины для самостоятельной реализации алгоритмов сортировки или для глубокого изучения тонкостей их устройства. Но, несмотря на это, интересно было разобраться в том, как работают такие алгоритмы — от пузырьковой сортировки, сортировки вставками, сортировки слиянием и сортировки выбором, до самого сложного алгоритма — быстрой сортировки. Я обнаружил, что редко возникает потребность в реализации подобных алгоритмов, особенно если не нужно писать функцию сортировки, являющуюся частью какой-нибудь библиотеки.
В Skype мне, правда, пришлось прибегнуть к практическому использованию моих знаний об алгоритмах сортировки. Один из наших программистов решил реализовать, для вывода контактов, сортировку вставками. В 2013 году, когда Skype подключался к сети, контакты загружались партиями. Для загрузки их всех требовалось некоторое время. В результате тот программист подумал, что лучше будет строить список контактов, упорядоченных по именам, используя сортировку вставками. Мы много обсуждали этот алгоритм, размышляли о том, почему бы просто не использовать что-то такое, что уже реализовано. В результате больше всего времени у нас ушло на то, чтобы как следует протестировать нашу реализацию алгоритма и проверить её производительность. Лично я не видел особого смысла в создании собственной реализации этого алгоритма. Но тогда проект был на такой стадии, на которой у нас было время на подобные дела.
Конечно, есть реальные ситуации, в которых эффективная сортировка играет в некоем проекте очень важную роль. И если разработчик может самостоятельно, основываясь на особенностях данных, выбирать наиболее подходящий алгоритм, это может дать заметный прирост производительности решения. Сортировка вставками может оказаться очень кстати там, где работают с большими наборами данных, передаваемых куда-либо в режиме реального времени, и тут же визуализируют эти данные. Сортировка слиянием может хорошо показывать себя при использовании подходов типа «разделяй и властвуй», в том случае, если речь идёт о работе с большими объёмами данных, хранящихся в разных узлах. Мне с подобными системами работать не доводилось, поэтому я пока продолжаю считать алгоритмы сортировки чем-то таким, что имеет ограниченное применение в повседневной работе. Это, правда, не касается важности понимания того, как именно работают разные алгоритмы сортировки.
Хеш-таблицы и хеширование: везде
Структура данных, которой я регулярно пользовался — это хеш-таблица. Сюда же можно отнести и хеш-функции. Это — полезнейший инструмент, которым можно пользоваться для решения самых разных задач — от подсчёта количества неких сущностей, обнаружения дубликатов, кеширования, до сценариев, вроде шардинга, используемых в распределённых системах. Хеш-таблицы — это, после массивов, структура данных, которая встречается в программировании чаще всего. Я ей пользовался в бесчисленном количестве ситуаций. Она есть почти во всех языках программирования, и её, если нужно, просто реализовать самостоятельно.
Стеки и очереди: время от времени
Стек — это структура данных, которая знакома каждому, кто занимался отладкой кода, написанного на языке, который поддерживает трассировку стека. Если говорить о стеке как о структуре данных, то я, в ходе работы, столкнулся с несколькими задачами, для решения которых она понадобилась. Но надо отметить, что со стеками я как следует познакомился, занимаясь отладкой и профилированием производительности кода. Стеки — это, кроме того, естественный выбор структуры данных, используемой при выполнении обхода дерева в глубину.
Мне редко приходилось прибегать к использованию очередей, но в кодовых базах различных проектов они мне встречались достаточно часто. Скажем, в очереди что-то помещали и что-то из них извлекали. Обычно очереди используются для реализации обхода деревьев в ширину, для решения этой задачи они подходят идеально. Очереди можно использовать и во многих других ситуациях. Однажды мне попался код для планирования заданий, в котором я обнаружил пример достойного применения очереди с приоритетом, реализованной средствами Python-модуля heapq, когда первыми выполнялись самые короткие задания.
Криптографические алгоритмы: Uber
Важные данные, которые пользователи вводят в мобильные приложения или в веб-приложения, нужно, перед передачей по сети, зашифровать. А расшифровывают их лишь там, где они нужны. Для того чтобы организовать такую схему работы, на клиентских и серверных частях приложений должны присутствовать реализации криптографических алгоритмов.
Разбираться в криптографических алгоритмах — это очень интересно. При этом для решения неких задач не стоит предлагать собственные алгоритмы. Это — одна из худших идей, которая может прийти в голову программисту. Вместо этого берётся существующий, хорошо документированный стандарт и используются встроенные примитивы соответствующих фреймворков. Обычно в качестве стандарта, выбираемого при реализации криптографических решений, выступает AES. Он достаточно надёжен для того чтобы шифровать с его помощью секретную информацию в США. Не существует известных работающих атак на протокол. AES-192 и AES-256 обычно, для решения большинства практических задач, достаточно надёжны.
Когда я пришёл в Uber, мобильная система шифрования и система шифрования веб-приложения уже были реализованы, в их основе лежали вышеописанные механизмы, поэтому у меня был повод для изучения подробностей об AES (Advanced Encryption Standard), о HMAC (Hashed Message Authentication Codes), об алгоритме RSA и о прочих подобных вещах. Интересно было и дойти до понимания того, как доказывают криптостойкость последовательности действий, применяемой при шифровании. Например, если говорить об аутентифицированном шифровании с присоединёнными данными, оказывается, что анализируя режимы encrypt-and-MAC, MAC-then-encrypt и encrypt-then-MAC, можно доказать криптостойкость лишь одного из них, хотя это и не означает того, что остальные не являются криптостойкими.
Вам вряд ли когда-нибудь придётся самостоятельно реализовывать криптографические примитивы, если только вы не будете заниматься реализацией совершенно нового криптографического фреймворка. Но вы вполне можете столкнуться с необходимостью принятия решений о том, какие именно примитивы использовать, и о том, как их комбинировать. Знания в сфере криптографических алгоритмов могут вам понадобиться и для того чтобы понять, почему в некоей системе применяется определённый подход к шифрованию данных.
Деревья решений: Uber
В ходе работы над одним из проектов нам, в мобильном приложении, понадобилось реализовать сложную бизнес-логику. А именно, основываясь на полудюжине правил, нужно было показать один из нескольких экранов. Эти правила были очень сложными, что объяснялось тем, что в расчёт надо было принимать результаты последовательности проверок и предпочтения пользователя.
Программист, который приступил к решению этой задачи, сначала попробовал выразить все эти правила в виде инструкций if-else. Это привело к появлению чрезвычайно запутанного кода. В итоге решено было воспользоваться деревом решений. С его помощью было несложно произвести все необходимые проверки. Его было сравнительно просто реализовать. Кроме того, если нужно, его можно было, без особых проблем, изменить. Нам нужно было создать собственную реализацию дерева решений, такого, чтобы проверка условий осуществлялась бы на его рёбрах. Это — всё, что нам было нужно от этого дерева. Хотя мы могли бы сэкономить время, потраченное на реализацию дерева, воспользовавшись другим подходом, команда решила, что особое дерево будет легче поддерживать, и приступила к работе. Выглядит это дерево примерно так: рёбра символизируют результаты проверки условий (это — бинарные результаты, или результаты, представленные диапазонами значений), а листовые узлы дерева описывают экраны, на которые нужно выполнять переходы.
Структура созданного нами дерева решений, используемого для выяснения того, какой именно экран нужно показать. При принятии решения используется сложный набор правил
В системе сборки мобильной версии приложения Uber, называемой SubmitQueue, тоже использовалось дерево решений, но оно формировалось динамически. Команде Developer Experience нужно было решить сложную проблему выполнения ежедневного слияния (merge) сотен веток-источников изменений с целевой веткой. При этом на выполнение каждой сборки нужно было около 30 минут. Сюда входили компиляция, выполнение модульных и интеграционных тестов, а также тестов интерфейса. Распараллеливание сборок было недостаточно хорошим решением, так как в различных сборках часто были перекрывающиеся изменения, что вызывало конфликты слияния. На практике это означало, что иногда программистам приходилось ждать 2-3 часа, прибегать к команде rebase, и снова запускать процесс слияния веток, надеясь, что в этот раз они не столкнутся с конфликтом.
Команда Developer Experience применила инновационный подход, который заключался в прогнозировании конфликтов слияния и в соответствующем размещении сборок в очереди. Делалось это с использованием особого бинарного дерева принятия решений (speculation tree).
В SubmitQueue используется бинарное дерево принятия решений, рёбра которого снабжены комментариями о прогнозируемых вероятностях. Этот подход позволяет определить то, какие наборы сборок можно выполнять параллельно. Делается это ради сокращения времени между получением и исполнением задач и ради повышения пропускной способности системы. В ветку master при этом должен попадать только полностью проверенный и работоспособный код
Специалисты команды Developer Experience, создавшие эту систему, написали отличный материал о ней. А вот — ещё одна статья на ту же тему, хорошо иллюстрированная. Результатом внедрения данной системы стало создание гораздо более быстрой, чем раньше, системы сборки проектов. Она позволила оптимизировать время сборки проектов и помогла облегчить жизнь сотен мобильных программистов.
Шестиугольные сетки, иерархические индексы: Uber
Это — последний проект, о котором я хочу тут рассказать. Он был полностью основан на одной особенной структуре данных. Именно занимаясь им я об этой структуре данных и узнал. Речь идёт о шестиугольной сетке с иерархическими индексами.
Одной из самых сложных и интересных проблем в Uber была оптимизация стоимости поездок и распределения заказов по партнёрам. Цены на поездки могут динамически меняться, водители постоянно находятся в движении. Инженерами Uber была создана сеточная система H3. Она предназначена для визуализации и анализа данных по городам в разных масштабах. Структура данных, которая используется для решения вышеозначенных задач, представляет собой шестиугольную сетку с иерархическими индексами. Для визуализации данных используется пара специализированных внутренних инструментов.
Разбиение карты на шестиугольные ячейки
Эта структура данных отличается собственной системой индексирования, обхода, собственными определениями отдельных областей сетки, собственными функциями. Детальное описание этого всего можно найти в документации к соответствующему API. Подробности об H3 можно почитать здесь. Вот — исходный код. Здесь можно найти рассказ о том, как и почему была создана эта система.
Опыт работы над этой системой позволил мне прочувствовать то, что создание собственных специализированных структур данных может иметь смысл при решении весьма специфических задач. Существует совсем немного задач, в решении которых можно применить шестиугольную сетку, если не учитывать разбиение на фрагменты карт с сопоставлением с каждым получившимся фрагментом данных разных уровней. Но, как и в других случаях, если вы знакомы с другими структурами данных, понять эту будет гораздо проще. А человеку, который разобрался с шестиугольной сеткой, проще будет создать новую структуру данных, предназначенную для решения задач, похожих на те которые решают с помощью такой сетки.
Структуры данных и алгоритмы на собеседованиях
Выше я рассказал о том, с какими структурами данных и алгоритмами я столкнулся, долгое время работая в различных компаниях. Предлагаю сейчас вернуться к тому твиту Макса Хауэлла, который я упоминал в самом начале материала. Там Макс жаловался на то, что на собеседовании в Google ему предложили инвертировать бинарное дерево на доске. Он этого не сделал. Ему указали на дверь. В этой ситуации я — на стороне Макса.
Я считаю, что знания о том, как работают популярные алгоритмы, или о том, как устроены экзотические структуры данных, это — не те знания, которые нужны для работы в технологической компании. Нужно знать о том, что такое алгоритм, нужно уметь самостоятельно придумывать простые алгоритмы, например, работающие по «жадному» принципу. Ещё нужно обладать знаниями о самых распространённых структурах данных, вроде хеш-таблиц, очередей и стеков. Но что-то достаточно специфическое, вроде алгоритма Дейкстры или A*, или чего-то ещё более сложного, это — не то, что нужно заучивать наизусть. Если вам эти алгоритмы реально понадобятся — вы легко сможете найти справочные материалы по ним. Я, например, если говорить об алгоритмах, не относящихся к алгоритмам сортировки, обычно стремился разобраться с ними в общих чертах и понять их сущность. То же касается и экзотических структур данных вроде красно-чёрных деревьев и АВЛ-деревьев. У меня никогда не возникало нужды в их использовании. А если бы они мне и понадобились — я всегда мог бы освежить знания о них, прибегнув к соответствующим публикациям. Я, проводя собеседования, как я уже говорил, никогда не задаю подобные вопросы и не планирую их задавать.
Я за практические задачи, имеющие отношение к программированию, при решении которых можно применить множество подходов: от методов «грубой силы» и «жадных» вариантов алгоритмов до более продвинутых алгоритмических идей. Например, я полагаю, что вполне нормальной является задача, касающаяся выравнивания текста по ширине, вроде этой. Мне, например, пришлось решать эту задачу при создании компонента для рендеринга текста на Windows Phone. Решить эту задачу можно, просто воспользовавшись массивом и несколькими инструкциями if-else, не прибегая к каким-то мудрёным структурам данным.
На самом деле, многие команды и компании преувеличивают значимость алгоритмических задач. Мне понятна привлекательность вопросов по алгоритмам. Они позволяют оценить соискателя за короткое время, вопросы легко переделывать, а значит, если вопросы, которые кому-то задавали, станут достоянием общественности, это особых проблем не вызовет. Вопросы по алгоритмам хорошо подходят для организации испытаний большого количества соискателей. Например, можно создать пул, состоящий из более чем сотни вопросов, и случайным образом раздать их соискателям. Вопросы, касающиеся динамического программирования и экзотических структур данных, встречаются всё чаще и чаще. Особенно — в Кремниевой долине. Эти вопросы могут помочь компаниям в найме сильных программистов. Но эти же вопросы способны закрыть дорогу в компании тем людям, которые преуспели в делах, где глубокие знания алгоритмов не нужны.
Если вы — из компании, которая нанимает только тех, кто едва ли не с рождения обладает глубокими знаниями сложных алгоритмов, я предлагаю вам хорошо подумать о том, те ли это люди, что вам нужны. Я, например, нанимал прекрасные команды в Skyscanner (Лондон) и в Uber (Амстердам), не задавая соискателям хитрых вопросов по алгоритмам. Я ограничивался самыми обычными структурами данных и проверкой возможностей собеседуемых, имеющих отношение к решению задач. То есть — им нужно было знать о распространённых структурах данных и уметь придумывать простые алгоритмы для решения стоящих перед ними задач. Структуры данных и алгоритмы — это всего лишь инструменты.
Итоги: структуры данных и алгоритмы — это инструменты
Если вы работаете в динамичной инновационной технологической компании, то вы, наверняка, в коде продуктов этой компании, столкнётесь с реализациями самых разных структур данных и алгоритмов. Если вы занимаетесь разработкой чего-то совершенно нового, то вам часто придётся искать структуры данных, упрощающие решение встающих перед вами задач. В подобных ситуациях вам, чтобы сделать правильный выбор, пригодятся общие знания об алгоритмах и структурах данных и об их плюсах и минусах.
Структуры данных и алгоритмы — это инструменты, которыми вы должны уверенно пользоваться, создавая программы. Зная эти инструменты, вы увидите много такого, что вам уже известно, в кодовых базах, в которых они используются. Кроме того, подобные знания позволят вам с гораздо большей уверенностью решать сложные задачи. Вы будете знать о теоретических ограничениях алгоритмов, о том, каким оптимизациям их можно подвергнуть. Это поможет вам, в итоге, выйти на решение, которое, с учётом всех необходимых компромиссов, окажется настолько хорошим, насколько это возможно.
Если вы хотите лучше изучить структуры данных и алгоритмы — вот несколько советов и ресурсов:
- Почитайте о хеш-таблицах, связных списках, деревьях, графах, кучах, очередях, стеках. Поэкспериментируйте с ними, используя тот язык, на котором пишете. Вот хороший обзор, посвящённый структурам данных. А вот — место, где можно попрактиковаться.
- Почитайте книгу «Грокаем алгоритмы». Это, как мне кажется, лучший путеводитель по алгоритмам, предназначенный для самых разных категорий программистов. Это — доступное иллюстрированное руководство, в котором содержится всё, что большинству специалистов нужно знать по данной теме. Я уверен в том, что вам не понадобится больше знаний об алгоритмах, чем те, что вы сможете найти в этой книге.
- Вот ещё пара книг: «Алгоритмы. Руководство по разработке» и «Алгоритмы на Java, 4-е издание». Я воспользовался ими для того чтобы освежить в памяти университетские знания об алгоритмах. Я их, правда, до конца не дочитал. Они показались мне достаточно сухими и неприменимыми к моей повседневной работе.
А с какими структурами данных и алгоритмами сталкивались на практике вы?







Kanut
Я не только пользуюсь алгоритмами, я их ещё и регулярно пишу. Я вообще себе слабо могу представить как должна выглядеть программа без алгоритмов. Потому что:
И структурами данных пользуется и их регулярно пишут сами подавляющее большинство программистов. Потому что те же классы это уже структуры данных…
wataru
Ну как вы не понимаете, это другое. Многие презирают именно те продвинутые алгоритмы и структуры данных, которые проходят в Computer Science. А от O() просто шарахаются как от грязных ругательств. И сильно недовольны, что это спрашивают на интервью.
Kanut
Ну я как бы тоже не особо люблю всякие там тестовые задания и просьбы написать "сортировку пузырьком" во время собеседований.
Но всё таки когда пишешь статьи на хабр, то на мой взгляд надо ну хоть немного разбираться в терминологии и этом самом ИТ...
tvictor
В целом статья именно об этом — о том, что в FAANG и других компаниях из Долины очень любят алгоритмические задачи на собеседованиях. И там не спрашивают сортировку пузырьком, там спрашивают более сложные алгоритмы и структуры данных. И автор говорит, что это не очень хорошо.
Эта статья — не оригинал, а перевод.
А какие алгоритмы и структуры данных (ну, помимо классов, конечно) вы регулярно пишите?
Kanut
Значит надо при переводе использовать правильную терминологию. Или может быть стоит задуматься что там пишет автор и стоит ли его вообще переводить.
А это принципиально важно в данном контексте? Речь о том что у вас по хорошему любой код состоит из алгоритмов и/или структур данных. Поэтому вопрос «Пользуетесь ли вы структурами данных и алгоритмами в повседневной работе?» звучит для меня абсолютно дико.
tvictor
Я считаю, в переводе надо использовать ту терминологию, которую использует автор оригинала. Ну, либо писать свою собственную статью-обсуждение оригинала.
Мне просто интересно. Я понимаю, что вы пользуетесь классами, массивами, хеш-таблицами и подобными. Но фраза, что вы пишите структуры данных и алгоритмы (мне видится, что вы их сами пишите, а не используете встроенные в язык) вызывает интерес. Я сейчас как раз изучаю алгоритмы/структуры и мне интересно, что именно вы используете, а тем более пишите сами, в повседневной работе.
А алгоритмы тем более. Какие алгоритмы используются постоянно? Я не считаю написание метода в классе написанием алгоритма.
Kanut
Классы, структуры, массивы, деревья, листы, стэки, очереди, словари… Мне даже сложно сказать какие структуры данных я не использую.
Я выше привёл общепризнанное определение алгоритма. По этому определению написание метода в классе вполне себе может являться написанием алгоритма. Ну или каким определением алгоритма пользуетесь вы?
Для того чтобы ответить на этот вопрос мне сначала надо понять что вы понимаете под словом «алгоритм».
ganqqwerty
А всё это вы используете напрямую, или опосредовано, через библиотеки? Для какого класса задач?
Kanut
Я если честно не совсем понимаю вопрос. Чем «напрямую» отличается от «опосредовано, через библиотеки» и как одно должно быть возможно без другого? И что такое «классы задач» и какие вообще бывают?
wataru
Тем, что во втором случае не надо ничего знать про эти самые алгоритмы-шмагоритмы.
Математика программистам не нужна же. /s
Kanut
Ну я вполне себе часто использую просто библиотеки и не заморачиваюсь как оно там внутри имплементированно.
Если это важно, то прежде чем использовать библиотеку я как минимум смотрю что они там делают или хотя бы читаю в доках какая там сложность в тех или иных ситуациях.
А иногда приходится и самому всё это писать.
П.С: Ну и самые для меня «сложные алгоритмы» это пожалуй был расчёт оптимальной загрузки/маршрута для грузовиков. Вот там у меня мозги кипели. Правда писал я не один и среди нас были и математики.
ganqqwerty
Ну не надо прямо сгущать краски. Просто во втором случае можно довольно долго работать как слесарь, а не как инженер, и произвести довольно много полезного и приносящего деньги кода. А в первом случае — надо уж совсем по-честному погружаться в алгоритмику с головой.
SpiderEkb
Тут вопрос несколько спорный.
Пользуясь библиотеками, но не вникая в их устройство в рискуете получить неэффективный код, сами того не понимая.
Как пример, в QT был реализован алгоритм SkipList. Но. Один из параметров, существенно влияющий как на производительность, так и на потребление памяти, был тупо установлен в некоторое усредненное значение и при этом скрыт от пользователя. Не понимая алгоритма и не вникая в его конкретную реализацию пользователь получал снижение производительности при увеличении потребления памяти.
И таких примеров я на своем веку встречал предостаточно.
К сожалению, сейчас такой код вполне себе приносит деньги. Т.е. слабали, спихнули заказчику, получили свои деньги и свалили. А через какое-то время заказчик вынужден искать людей, которые все это будут править или переделывать. Например, когда возрастет нагрузка и все это перестанет справляться.
И с таким тоже приходилось сталкиваться, увы.
Kanut
Абсолютно верно. Но просто очень часто эффективность вашего кода вас интересует только в определённых границах. И до тех пор пока эти границы не нарушаются, оптимизация кода «вручную» это никому не нужная потеря времени и/или денег.
И такое бывает. Но с другой стороны если заказчик указал что он собирается использовать вашу систему с определённой нагрузкой, а сам потом вдруг решает увеличить нагрузку на несколько порядков, то это уже он сам и виноват.
SpiderEkb
Я бы согласился, не будь у нас в бэклоге огромного пула задач на оптимизацию.
Вот это реальная потеря времени и денег.
Причем, во многих задачах явно видно что просто человек сделал как попроще, не задумываясь о том, а нет ли решения более эффективного. И выбор его на этапе начальной разработки обошелся бы намного дешевле последующей доработки с неизбежным ретестом.
Kanut
Ну я бы тогда пожалуй сказал что это у вас что-то идёт не так.
У нас огромного пула задач на оптимизацию нет. Да и вообще оптимизация, которой мы занимаемся «за свой счёт» а не по заказу клиента, у нас достаточно редкое событие.
Но да, если на код ревью всплывает ну вот совсем плохо оптимизированное решение, то человеку об этом говорят. Или если тесты показывают что-то странное в этом плане, то тоже разбираемся обычно.
SpiderEkb
Просто у нас за долгое время накоплена огромная кодовая база. И на проме очень много чего работает.
Ну и нагрузка порядка 3млрд изменений (только изменений) БД в сутки. И таблиц в БД тысячи.
Всего очень много. И оптимизация занятие вынужденное. Когда в пике нагрузка серверов (кластер из трех серверов по 16 12-ядерных SMT8 процессоров POWER9 в каждом) превышает 90%, мы вынуждены что-то с этим делать. Ибо остановка какой-либо системы это не только репутационные потери, но и в некоторых ситуациях штрафы со многими нулями от регулятора (да, там все регламентировано, в том числе и предельные времена простоя отдельных систем).
Kanut
И поэтому я с вами абсолютно согласен что вам очень хорошо надо следить за производительностью. И в такой ситуации я бы тоже сторонние библиотеки использовал очень осторожно.
Но вот например у нас сейчас был запрос oт клиента добавить ему возможность дампа отдельных регионов памяти и просмотра этих дампов в хексе. Регионы при этом по спецификации не могут быть больше 256МБ. И я конечно могу написать сам с нуля этот самый hex viewer, но есть куча библиотек, которые 256МБ «рендерят» за секунду. И зачем мне тогда тратить на это время и деньги клиента?
SpiderEkb
Ну я не говорил что против использования стороннего кода. Просто нужно с умом делать все и точно понимать что за этим стоит.
Естественно, что у нас тоже есть не критичные к производительности задачи и там не так пристально к эффективности относимся.
SpiderEkb
Что понимать под «пишете сами»? Разработку собственного алгоритма? Разработку собственной реализации описанного где-то алгоритма (или адоптацию его под свою задачу)?
Весть процесс разаработки есть построение некоторого алгоритма для решения поставленной задачи.
ganqqwerty
Ну слушайте, я вот последние лет пять занимаюсь маппингом json-ов на формочки и маппингом формочек на json-ы. Можно конечно, считать, что это тоже алгоритмы, просто очень простые, но размеры логических блоков, которыми я оперирую очень уж высоки (недавно поймал себя на том, что не помнил, можно ли у строки взять по индексу символ, типа так: s[3]).
Я про нормальные алгоритмы из книжек, где надо оптимизировать какую-нить функцию, применить каких-нить maxheap-ов и фильтров Блума, да хотя бы граф какой-нибудь обойти.