
В первой части описан тяжкий квест по оцифровке старых семейных видеозаписей с разбиением их на отдельные сцены. После обработки всех клипов я хотел организовать их просмотр в онлайне такой же удобный, как на YouTube. Поскольку это личные воспоминания семьи, на самом YouTube их выкладывать нельзя. Нужен более приватный хостинг, одновременно удобный и безопасный.
Первым делом я попробовал ClipBucket, который называет себя опенсорсным клоном YouTube, который можно установить у себя на сервере.

Удивительно, но у ClipBucket нет никаких инструкций по установке. Благодаря стороннему руководству я автоматизировал процесс установки с помощью Ansible, инструмента управления конфигурацией серверов.
Отчасти трудность заключалась в том, что скрипты установки ClipBucket полностью сломаны. В то время я работал в Google и по условиям контракта не имел права контрибутить в опенсорсный клон YouTube, но я запостил баг-репорт, из которого легко можно было сделать необходимые исправления. Шли месяцы, а они так и не поняли, в чём проблема. Вместо этого они добавляли всё больше багов в каждом релизе.
Компания ClipBucket работала по модели консалтинга — они выпускали свой код бесплатно и взимали плату за помощь в деплое. Постепенно до меня дошло, что компания, которая зарабатывает деньги на платной поддержке, вероятно, не очень заинтересована в том, чтобы клиенты самостоятельно устанавливали продукт.
После нескольких месяцев разочарования в ClipBucket я пересмотрел доступные варианты и нашёл MediaGoblin.
MediaGoblin — это автономная платформа для обмена медиафайлами
У MediaGoblin много вкусностей. В отличие от ClipBucket на неприглядном PHP, MediaGoblin написан на Python — на этом языке у меня большой опыт написания кода. Есть интерфейс командной строки, который позволяет легко автоматизировать загрузку видео. Самое главное, MediaGoblin поставляется в образе Docker, который исключает любые проблемы с установкой.
Я предположил, что деплой докер-образа MediaGoblin станет тривиальной задачей. Ну, вышло не совсем так.
В готовом образе не оказалось двух нужных функций:
Что ж, никаких проблем. Образ Docker идёт с открытым кодом, так что можно пересобрать его самостоятельно.
К сожалению, образ Docker больше не собирается из текущего репозитория MediaGoblin. Я попытался синхронизировать его с версией из последней успешной сборки, но и это не удалось. Хотя я использовал точно тот же код, внешние зависимости MediaGoblin изменились, нарушив сборку. Спустя десятки часов я снова и снова прогонял 10-15-минутный процесс сборки MediaGoblin, пока он наконец-то не заработал.
Несколько месяцев спустя произошло то же самое. В общей сложности за последние пару лет цепочка зависимостей MediaGoblin несколько раз ломала мою сборку, и последний раз это произошло только что, когда я писал эту статью. В конце концов я опубликовал собственный форк MediaGoblin c жёстко закодированными зависимостями и явно указанными версиями библиотек. Другими словами, вместо сомнительного утверждения, что MediaGoblin работает с любой версией celery >= 3.0, я установил конкретную зависимость на версию celery 4.2.1, потому что тестировал MediaGoblin с этой версией. Похоже, что продукту нужен механизм воспроизводимых сборок, но я ещё этим не занимался.
Так или иначе, после многих часов борьбы я наконец смог собрать и настроить MediaGoblin в образе Docker. Там уже было несложно пропустить ненужное транскодирование и поставить Nginx для аутентификации.
Поскольку MediaGoblin работал под управлением Docker на моём локальном компьютере, следующим шагом был деплой на облачном сервере, чтобы семья могла посмотреть видео.
Есть много платформ, которые принимают образ Docker и размещают его на общедоступном URL. Загвоздка в том, что в дополнение к самому приложению нужно было опубликовать 33 ГБ видеофайлов. Можно было жёстко закодировать их в докер-образ, но так получалось громоздко и некрасиво. Изменение одной строчки конфигурации потребовало бы повторного деплоя 33 ГБ данных.
Когда я использовал ClipBucket, то решил проблему с помощью gcsfuse — утилиты, которая позволяет операционной системе загружать в облачное хранилище Google Cloud каталоги как обычные пути к файловой системе. Я разместил видеофайлы в Google Cloud и использовал gcsfuse, чтобы они отображались в ClipBucket как локальные файлы.
Разница заключалась в том, что ClipBucket работал в настоящей виртуальной машине, а MediaGoblin — в контейнере Docker. Здесь монтирование файлов из облачного хранилища оказалось гораздо сложнее. Я потратил десятки часов на решение всех проблем и написал об этом целый пост в блоге.

Изначальная интеграция MediaGoblin с хранилищем Google Cloud, о которой я рассказывал в 2018 году
После нескольких недель наладки всех компонентов всё сработало. Не внося никаких изменений в код MediaGoblin, я читерски заставить его читать и записывать медиафайлы в облачное хранилище Google.
Единственной проблемой было то, что MediaGoblin стал работать неприлично медленно. Загрузка миниатюр видео на главную страницу занимало целых 20 секунд. Если во время просмотра видео вы прыгали вперёд, MediaGoblin останавливался на бесконечные 10 секунд, прежде чем возобновить воспроизведение.
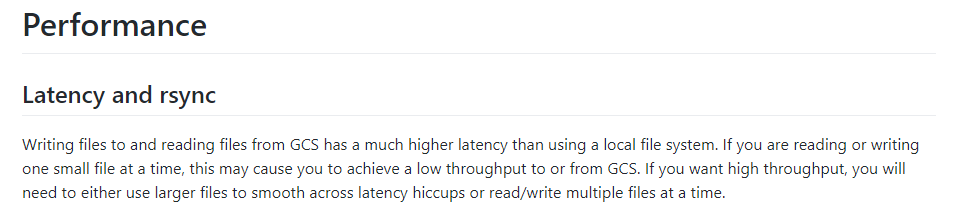
Основная проблема заключалась в том, что видео и картинки шли к пользователю длинным, окольным путём. Им приходилось идти из облачного хранилища Google через gcsfuse в MediaGoblin, Nginx — и только потом они попадали в браузер пользователя. Главным узким местом был gcsfuse, который не оптимизирован для быстрой работы. Разработчики предупреждают о больших задержках в работе утилиты прямо на главной странице проекта:
Предупреждения о низкой производительности в документации gcsfuse
В идеале браузер должен извлекать файлы непосредственно из Google Cloud, минуя все промежуточные слои. Как это сделать, не углубляясь в кодовую базу MediaGoblin и не добавляя сложную логику интеграции Google Cloud?
К счастью, я нашёл простое решение, хотя и немного уродливое. Я добавил в конфигурацию default.conf в Nginx такой фильтр:
В моей установке Nginx работал как прокси между MediaGoblin и конечным пользователем. Вышеприведённая директива предписывает Nginx выполнить поиск и замену всех HTML-ответов MediaGoblin, прежде чем передавать их конечному пользователю. Nginx заменяет все относительные пути к медиафайлам MediaGoblin на URL'ы из облачного хранилища Google.
Например, MediaGoblin генерирует такой HTML:
Nginx изменяет ответ:
Теперь всё складывается как положено:
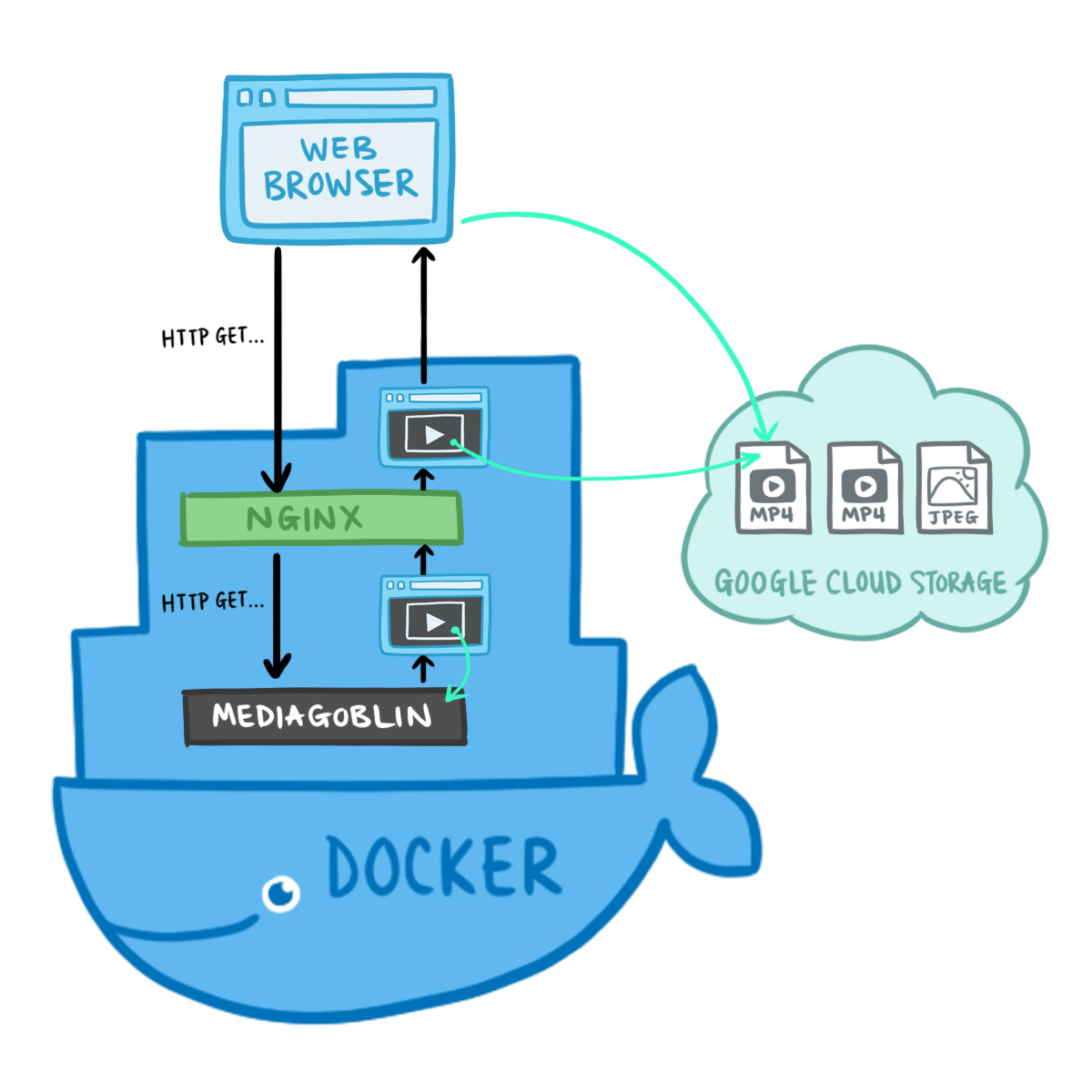
Nginx переписывает ответы от MediaGoblin, чтобы клиенты могли запрашивать медиафайлы непосредственно из облачного хранилища Google
Самое приятное в моём решении то, что оно не требует никаких изменений в коде MediaGoblin. Двухстрочная директива Nginx легко интегрирует MediaGoblin и Google Cloud, хотя эти сервисы совершенно ничего не знают друг о друге.
На этот момент у меня было полное, рабочее решение. MediaGoblin счастливо работал в собственном контейнере на облачной платформе Google, так что его не нужно было часто исправлять или обновлять. Всё в моем процессе было автоматизировано и воспроизводимо, позволяя простые правки или откат к предыдущим версиям.
Моей семье очень понравилось, как легко просматривать видео. С помощью вышеописанного хака Nginx работа с видео стала такой же быстрой, как на YouTube.
Экран просмотра выглядит следующим образом:
Содержимое каталога семейного видео по тегу «Лучшее»
Щелчок по миниатюре выводит такой экран:
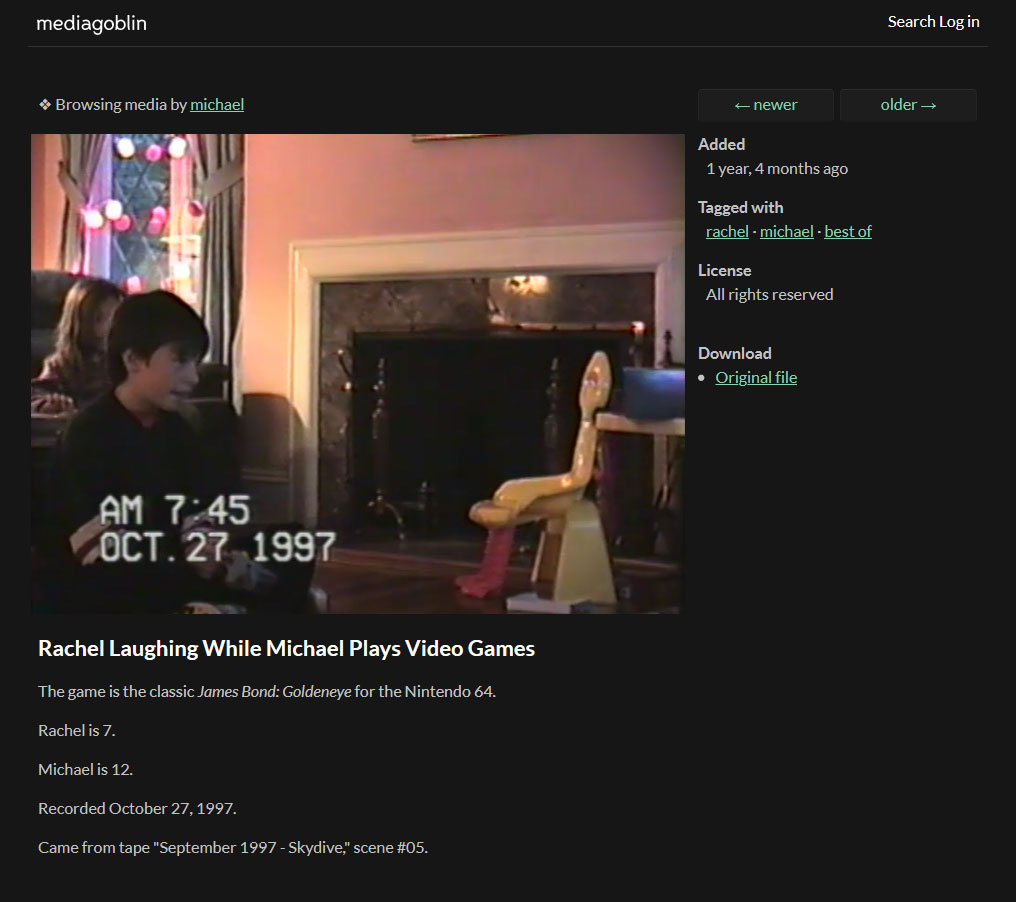
Просмотр отдельного клипа на медиасервере
После долгих лет работы мне было невероятно приятно дать родственникам возможность посмотреть наши видео в таком же удобном интерфейсе, как на YouTube, как я изначально и хотел.
Вы смотрите домашнее видео не часто, только каждые несколько месяцев. Моя семья коллективно сгенерировала около 20 часов трафика за год, но сервер работал круглосуточно. Я ежемесячно платил $15 за сервер, который простаивал 99,7% времени.
В конце 2018 года Google выпустила продукт Cloud Run. Киллер-фичей был запуск контейнеров Docker настолько быстро, что приложение могло отвечать на HTTP-запросы. То есть сервер мог оставаться в режиме ожидания — и запускаться только тогда, когда кто-то хотел на него зайти. Для редко запускаемых приложений вроде моего затраты снизились с 15 долларов в месяц до нескольких центов в год.
По причинам, которые я уже не помню, Cloud Run не работал с моим образом MediaGoblin. Но с появлением Cloud Run я вспомнил, что Heroku предлагает аналогичную услугу бесплатно, и их инструменты гораздо удобнее, чем у Google.
С бесплатным сервером приложений единственная статья расходов — это хранение данных. Стандартное региональное хранилище Google стоит 2,3 цента/ГБ. Видеоархив занимает 33 ГБ, поэтому я плачу всего 77 центов в месяц.
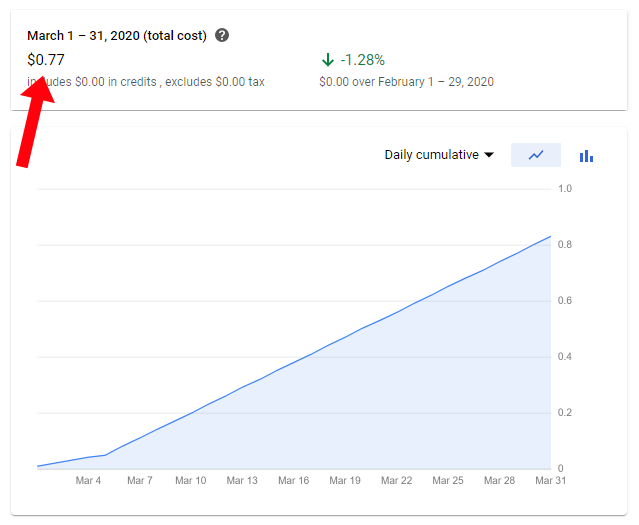
Стоимость этого решения составляет всего $0,77 в месяц
Очевидно, у меня процесс занял много времени. Но я надеюсь, что эта статья поможет вам сэкономить 80-90% усилий по оцифровке и публикации домашних видео. В отдельном разделе вы можете найти подробное пошаговое руководство по всему процессу, но вот несколько общих советов:
Шаг 3. Публикация
ClipBucket, опенсорсный клон YouTube, который можно установить на собственном сервере
Первым делом я попробовал ClipBucket, который называет себя опенсорсным клоном YouTube, который можно установить у себя на сервере.
Удивительно, но у ClipBucket нет никаких инструкций по установке. Благодаря стороннему руководству я автоматизировал процесс установки с помощью Ansible, инструмента управления конфигурацией серверов.
Отчасти трудность заключалась в том, что скрипты установки ClipBucket полностью сломаны. В то время я работал в Google и по условиям контракта не имел права контрибутить в опенсорсный клон YouTube, но я запостил баг-репорт, из которого легко можно было сделать необходимые исправления. Шли месяцы, а они так и не поняли, в чём проблема. Вместо этого они добавляли всё больше багов в каждом релизе.
Компания ClipBucket работала по модели консалтинга — они выпускали свой код бесплатно и взимали плату за помощь в деплое. Постепенно до меня дошло, что компания, которая зарабатывает деньги на платной поддержке, вероятно, не очень заинтересована в том, чтобы клиенты самостоятельно устанавливали продукт.
MediaGoblin, более современная альтернатива
После нескольких месяцев разочарования в ClipBucket я пересмотрел доступные варианты и нашёл MediaGoblin.
MediaGoblin — это автономная платформа для обмена медиафайлами
У MediaGoblin много вкусностей. В отличие от ClipBucket на неприглядном PHP, MediaGoblin написан на Python — на этом языке у меня большой опыт написания кода. Есть интерфейс командной строки, который позволяет легко автоматизировать загрузку видео. Самое главное, MediaGoblin поставляется в образе Docker, который исключает любые проблемы с установкой.
Docker — это технология, которая создаёт для приложения автономную среду, работающую в любом месте. Я использую Docker во многих своих проектах.
Удивительная трудность повторной докеризации MediaGoblin
Я предположил, что деплой докер-образа MediaGoblin станет тривиальной задачей. Ну, вышло не совсем так.
В готовом образе не оказалось двух нужных функций:
- Аутентификация
- MediaGoblin по умолчанию создаёт публичный медиапортал, а мне нужен был способ ограничить доступ посторонних.
- Транскодирование
- Каждый раз, когда вы загружаете видео, MediaGoblin пытается перекодировать его для оптимального стриминга. Если видео изначально готово для стриминга, транскодирование ухудшает качество.
- MediaGoblin предусматривает отключение транскодирования через параметры конфигурации, но в существующем образе Docker это невозможно сделать.
Что ж, никаких проблем. Образ Docker идёт с открытым кодом, так что можно пересобрать его самостоятельно.
К сожалению, образ Docker больше не собирается из текущего репозитория MediaGoblin. Я попытался синхронизировать его с версией из последней успешной сборки, но и это не удалось. Хотя я использовал точно тот же код, внешние зависимости MediaGoblin изменились, нарушив сборку. Спустя десятки часов я снова и снова прогонял 10-15-минутный процесс сборки MediaGoblin, пока он наконец-то не заработал.
Несколько месяцев спустя произошло то же самое. В общей сложности за последние пару лет цепочка зависимостей MediaGoblin несколько раз ломала мою сборку, и последний раз это произошло только что, когда я писал эту статью. В конце концов я опубликовал собственный форк MediaGoblin c жёстко закодированными зависимостями и явно указанными версиями библиотек. Другими словами, вместо сомнительного утверждения, что MediaGoblin работает с любой версией celery >= 3.0, я установил конкретную зависимость на версию celery 4.2.1, потому что тестировал MediaGoblin с этой версией. Похоже, что продукту нужен механизм воспроизводимых сборок, но я ещё этим не занимался.
Так или иначе, после многих часов борьбы я наконец смог собрать и настроить MediaGoblin в образе Docker. Там уже было несложно пропустить ненужное транскодирование и поставить Nginx для аутентификации.
Шаг 4. Хостинг
Поскольку MediaGoblin работал под управлением Docker на моём локальном компьютере, следующим шагом был деплой на облачном сервере, чтобы семья могла посмотреть видео.
MediaGoblin и проблема хранения видео
Есть много платформ, которые принимают образ Docker и размещают его на общедоступном URL. Загвоздка в том, что в дополнение к самому приложению нужно было опубликовать 33 ГБ видеофайлов. Можно было жёстко закодировать их в докер-образ, но так получалось громоздко и некрасиво. Изменение одной строчки конфигурации потребовало бы повторного деплоя 33 ГБ данных.
Когда я использовал ClipBucket, то решил проблему с помощью gcsfuse — утилиты, которая позволяет операционной системе загружать в облачное хранилище Google Cloud каталоги как обычные пути к файловой системе. Я разместил видеофайлы в Google Cloud и использовал gcsfuse, чтобы они отображались в ClipBucket как локальные файлы.
Разница заключалась в том, что ClipBucket работал в настоящей виртуальной машине, а MediaGoblin — в контейнере Docker. Здесь монтирование файлов из облачного хранилища оказалось гораздо сложнее. Я потратил десятки часов на решение всех проблем и написал об этом целый пост в блоге.
Изначальная интеграция MediaGoblin с хранилищем Google Cloud, о которой я рассказывал в 2018 году
После нескольких недель наладки всех компонентов всё сработало. Не внося никаких изменений в код MediaGoblin, я читерски заставить его читать и записывать медиафайлы в облачное хранилище Google.
Единственной проблемой было то, что MediaGoblin стал работать неприлично медленно. Загрузка миниатюр видео на главную страницу занимало целых 20 секунд. Если во время просмотра видео вы прыгали вперёд, MediaGoblin останавливался на бесконечные 10 секунд, прежде чем возобновить воспроизведение.
Основная проблема заключалась в том, что видео и картинки шли к пользователю длинным, окольным путём. Им приходилось идти из облачного хранилища Google через gcsfuse в MediaGoblin, Nginx — и только потом они попадали в браузер пользователя. Главным узким местом был gcsfuse, который не оптимизирован для быстрой работы. Разработчики предупреждают о больших задержках в работе утилиты прямо на главной странице проекта:
Предупреждения о низкой производительности в документации gcsfuse
В идеале браузер должен извлекать файлы непосредственно из Google Cloud, минуя все промежуточные слои. Как это сделать, не углубляясь в кодовую базу MediaGoblin и не добавляя сложную логику интеграции Google Cloud?
Трюк sub_filter в nginx
К счастью, я нашёл простое решение, хотя и немного уродливое. Я добавил в конфигурацию default.conf в Nginx такой фильтр:
sub_filter "/mgoblin_media/media_entries/" "https://storage.googleapis.com/MY-GCS-BUCKET/media_entries/";
sub_filter_once off;В моей установке Nginx работал как прокси между MediaGoblin и конечным пользователем. Вышеприведённая директива предписывает Nginx выполнить поиск и замену всех HTML-ответов MediaGoblin, прежде чем передавать их конечному пользователю. Nginx заменяет все относительные пути к медиафайлам MediaGoblin на URL'ы из облачного хранилища Google.
Например, MediaGoblin генерирует такой HTML:
<video width="720" height="480" controls autoplay>
<source
src="/mgoblin_media/media_entries/16/Michael-riding-a-bike.mp4"
type="video/mp4">
</video>Nginx изменяет ответ:
<video width="720" height="480" controls autoplay>
<source
src="https://storage.googleapis.com/MY-GCS-BUCKET/media_entries/16/Michael-riding-a-bike.mp4"
type="video/mp4">
</video>Теперь всё складывается как положено:
Nginx переписывает ответы от MediaGoblin, чтобы клиенты могли запрашивать медиафайлы непосредственно из облачного хранилища Google
Самое приятное в моём решении то, что оно не требует никаких изменений в коде MediaGoblin. Двухстрочная директива Nginx легко интегрирует MediaGoblin и Google Cloud, хотя эти сервисы совершенно ничего не знают друг о друге.
Примечание: это решение требует, чтобы файлы в облачном хранилище Google были доступны на чтение для всех. Чтобы снизить риск несанкционированного доступа, я использую длинное случайное название бакета (например, mediagoblin-39dpduhfz1wstbprmyk5ak29) и проверяю, что политика контроля доступа бакета не разрешает неавторизованным пользователям выводить содержимое каталога.Конечный продукт
На этот момент у меня было полное, рабочее решение. MediaGoblin счастливо работал в собственном контейнере на облачной платформе Google, так что его не нужно было часто исправлять или обновлять. Всё в моем процессе было автоматизировано и воспроизводимо, позволяя простые правки или откат к предыдущим версиям.
Моей семье очень понравилось, как легко просматривать видео. С помощью вышеописанного хака Nginx работа с видео стала такой же быстрой, как на YouTube.
Экран просмотра выглядит следующим образом:
Содержимое каталога семейного видео по тегу «Лучшее»
Щелчок по миниатюре выводит такой экран:
Просмотр отдельного клипа на медиасервере
После долгих лет работы мне было невероятно приятно дать родственникам возможность посмотреть наши видео в таком же удобном интерфейсе, как на YouTube, как я изначально и хотел.
Бонус: снижение затрат до уровня меньше 1 доллара в месяц
Вы смотрите домашнее видео не часто, только каждые несколько месяцев. Моя семья коллективно сгенерировала около 20 часов трафика за год, но сервер работал круглосуточно. Я ежемесячно платил $15 за сервер, который простаивал 99,7% времени.
В конце 2018 года Google выпустила продукт Cloud Run. Киллер-фичей был запуск контейнеров Docker настолько быстро, что приложение могло отвечать на HTTP-запросы. То есть сервер мог оставаться в режиме ожидания — и запускаться только тогда, когда кто-то хотел на него зайти. Для редко запускаемых приложений вроде моего затраты снизились с 15 долларов в месяц до нескольких центов в год.
По причинам, которые я уже не помню, Cloud Run не работал с моим образом MediaGoblin. Но с появлением Cloud Run я вспомнил, что Heroku предлагает аналогичную услугу бесплатно, и их инструменты гораздо удобнее, чем у Google.
С бесплатным сервером приложений единственная статья расходов — это хранение данных. Стандартное региональное хранилище Google стоит 2,3 цента/ГБ. Видеоархив занимает 33 ГБ, поэтому я плачу всего 77 центов в месяц.
Стоимость этого решения составляет всего $0,77 в месяц
Советы для тех, кто собирается попробовать
Очевидно, у меня процесс занял много времени. Но я надеюсь, что эта статья поможет вам сэкономить 80-90% усилий по оцифровке и публикации домашних видео. В отдельном разделе вы можете найти подробное пошаговое руководство по всему процессу, но вот несколько общих советов:
- На этапе оцифровки и редактирования сохраните как можно больше метаданных.
- Ценная информация часто записана на этикетках видеокассет.
- Записывайте, какой клип был снят с какой кассеты и в каком порядке.
- Запишите дату съёмки, которая может быть указана на видео.
- Подумайте об оплате услуг профессиональной оцифровки.
- Вам будет чрезвычайно сложно и дорого сравняться с ними по качеству оцифровки.
- Но держитесь подальше от компании под названием EverPresent (напишите мне, если нужны подробности).
- Если делаете оцифровку самостоятельно, закупите HDD.
- Несжатое видео стандартного разрешения занимает 100-200 МБ за минуту.
- Я всё хранил на своём Synology DS412+ (10 ТБ).
- Записывайте метаданные в каком-нибудь распространённом формате, который не привязан к определённому приложению.
- Описания клипов, коды времени, даты и т. д.
- Если вы сохраняете метаданные в формате конкретного приложения (или, что ещё хуже, не сохраняете вовсе), то не сможете переделать работу, если решите использовать другое решение.
- Во время редактирования вы видите много полезных метаданных на видео. Вы их потеряете, если не сохраните.
- Что происходит на видео?
- Кто там записан?
- Когда это записано?
- Отметьте любимые видео.
- Честно говоря, большинство домашних видеоматериалов довольно скучны.
- Я применяю тег “best of” к любимым клипам и открываю их, когда хочется посмотреть забавные видео.
- Как можно раньше организуйте комплексное решение, чтобы процесс шёл сразу от начала до конца.
- Я пытался сначала оцифровать все кассеты, затем отредактировать все кассеты и т. д.
- Жаль, что я не начал с одной кассеты и не проделал с ней всю работу. Тогда бы я понял, какие решения и на каких стадиях влияют на конечный результат.
- Сведите к минимуму перекодирование.
- Каждый раз, когда вы редактируете или перекодируете клип, вы ухудшаете его качество.
- Оцифруйте сырые кадры с максимальным качеством, а затем перекодируйте каждый клип ровно один раз в тот формат, который браузеры нативно воспроизводят.
- Используйте самое простое из возможных решений для публикации видеоклипов.
- Сделайте монтаж.
- Видеомонтаж — это интересный способ объединить лучшие моменты из нескольких видеороликов.
- Главное в монтаже — музыка. Например, потрясающе подходит тема Slow Snow от The National, это моё личное открытие.
farafonoff
В таких историях меня больше всего пугает недолговечность. У аккаунта на ютубе больше шансов пережить владельца, чем у такого персонального облака. (А у внешнего жесткого диска живучесть, мне кажется, еще выше).
SakuradaJun
Напоминаю:
https://habr.com/ru/news/t/475412/
Так что если выкладывать что-то в общий доступ, то не в один только ютуб, а на все площадки, поддерживающие загрузку фото и видео.