
Что нужно чтобы создать искусственный интеллект? По какому пути идти до этой цели? Многие с уверенностью ответят, что научное сообщество уже полным ходом движется на этом пути. Что со следующими нейросетевыми моделями с еще большим количеством параметров, с еще более мощными нейроморфными компьютерами, и еще более масштабными датасетами на все случаи жизни, мы ворвёмся в эпоху мыслящих машин. На мой взгляд, это похоже на гонку за морковкой и скорее очевидным для всех такое положение дел станет тогда когда количество настраиваемых параметров в моделях, станет больше чем связей в человеческом мозгу, но ожидаемого эффекта не будет достигнуто.
В этой статья я обозначу путь выхода из порочного бега за морковкой, и расскажу о своём пути и наработках в своих исследованиях.
Первое, что нужно решить на пути к искусственному интеллекту – это проблему низкой эффективности обучения нейронных сетей. Глупо строить грандиозное высотное здание без фундамента, или на очень плохом фундаменте. Текущее положение дел в нейронных сетях – это очень плохой фундамент для искусственного интеллекта, но многие исследователи упорно продолжают строить свои концепции и модели интеллекта на этом фундаменте, вместо того, чтобы обратить своё внимание на очевидные проблемы: биологическая нейронная сеть обучается во много раз эффективнее искусственных нейронных сетей.
Да, биологические нейронные сети, можно сказать, находятся в постоянном непрерывном потоке информации, непрерывно получая сигналы от своих рецепторов. За сутки младенец может получить гигантское количество информации от своих органов зрения и слуха, эквивалентное видео и аудио, данным на многие и многие терабайты. Но если детально разобрать эту информацию, то действительно полезной для обучения, так скажем «размеченной» информации не так уж много. Можно сказать, что человек обучается на датасете очень плохого качества, большая часть примеров нерелевантна и не размечена, какая-то часть примеров сильно зашумлена, но при этом обучается он достаточно успешно и быстро.
Видимо компьютерные нейронные сети не соответствуют биологическим или обучение их мы производим совершенно не так, как это происходит в биологической нервной системе.
Необходимо сконцентрироваться на разработке суперэффективных нейронных сетей, а не на увеличении количества обучаемых параметров.
Причём во главу угла стоит ставить скорость обучения сети, а качество или точность сейчас второстепенны.
Только супер эффективная нейронная сеть (СНС) может быть фундаментом и основой для создания искусственного интеллекта.
Имея технологию СНС можно двигаться различными путями, как создавая когнитивные архитектуры на основе графов, гиперграфов и т.д. плюс СНС, так и двигаясь биологическим путём повторяя архитектуру биологического мозга. Я сторонник биологического подхода, хотя и не считаю этот путь единственным в достижении цели.
Маршрутная карта на пути к ИИ
- Первый этап. Создание модели сенсорных анализаторов в первую очередь зрительных и слуховых. Вообще сенсорные анализаторы биологической нервной системы и должны стать прообразом сверхэффективных нейронных сетей (СНС).
- Второй этап. Получение знаний о механизмах мгновенной, временной и долговременной памяти в концепции СНС. Биологические сенсорные анализаторы легко работают с контекстом, только понимание концепции памяти в биологических нейронных сетях позволит перенять возможность работать с контекстом, что сильно расширит возможности СНС.
- Третий этап. Создание моделей моторных сетей. Не смотря на гомогенность коры головного мозга моторные сети в некотором смысле более сложно устроены, чем сенсорные анализаторы, хотя есть некоторое глубокое сходство. Поэтому этот этап не будет затянутым. В моторные сети будут входить модель мозжечка, как структура, запоминающая и воспроизводящая короткие временные интервалы для точности движений. А так же некий механизм поощрения, для обеспечения обучению правильных движений, аналогичный дофаминовыми механизмами поощрения в биологическом мозге.
- Четвертый этап. Одним из важных форм моторных действий является речь. Возможно, по этой причине этот и предыдущий этапы будут воплощены синхронно. На этом этапе речь не будет в полной мере осознанной. Подобно человеку должны быть пройдены этапы развития речи, такие как гуление, произношение отдельных звуков, затем слов. Максимальный уровень владения речью на этом этапе, это называние предъявленных предметов, описание сцен, ответы на простые вопросы, чтение или декларация текста. На этом этапе буде заложена основа для сети речевого круга (О речевом круге я подробно писал в статье «Что такое сознание»).
- Пятый этап. Создание модели базовых эмоций и потребностей. Этот этап не будет являться чётким этапом, многие его концепции будут проявляться и на более ранних этапах. Главной фундаментальной эмоцией, которую необходимо моделировать – это эмоция новизны. Достаточно создать оценочный механизм новизны информации на различных уровнях абстрактности и производить на его основе модуляцию параметров сети. Любопытство необходимо для эффективного обучения.
Также нужно обеспечивать модели чувствами необходимыми для контроля их потребностей. К примеру, низкий заряд батареи робота мог бы создавать некие чувство голода для робота, и робот бы стремился удовлетворить его, то есть стал бы искать зарядное устройство или источник питания. Или создание некого чувства боли или дискомфорта, чтобы робот избегал травмирующих его ситуаций.
Еще одна полезная эмоция, которую легко можно подвергнуть моделированию это различного рода привязанности. В основе привязанностей лежит механизм импринтинга. Это будет полезно для различного рода роботов-помощников или роботов-питомцев, от которых требуется следовать за хозяином или некоторая преданность.
Человек более охотно будет взаимодействовать с интеллектом похожим на него, поэтому возможно появление более широкого спектра эмоциональных механизмов. К примеру, тревожности и страха, симпатии, радости и разочарования.
Что касается внедрения на уровень базовых эмоций законов робототехники Айзека Азимова, то они имеют высокий абстрактный характер, что сильно усложняет их моделирование. Сначала модель должна быть обучена на столько, чтобы можно было выявить репрезентацию образов «Человек» и «причинение вреда», подобно тому, как у человека можно найти «бабушкины нейроны». Затем можно связать эмоциональный механизм со стремлением избегать сочетания этих образов. Сложно сказать, насколько такой метод будет эффективным.
- Шестой этап. Можно сказать, что этот этап такой же сложный, как и первый, если не сложнее. Условно его можно его можно назвать этапом префронтальной коры. Префронтальной коре головного мозга присваивают высшую когнитивную деятельность, здесь можно сказать, расположено суждение и долгосрочное целеполагание. Префронтальная кора контролирует работу эмоциональных центров и центров потребностей, она регулирует то, насколько сильно они влияют на поведение.
Работа на этом этапе требует глубоких знаний о поведении человека. Только на этом этапе можно рассуждать и говорить о сознании и сознательном поведении. К этому этапу я отношу не только создание префронтальной коры, но и несколько важных биологических нейронных сетей и механизмов. К примеру, сеть «интерпретатор», которая стремиться дать обоснование любому нашему действию. Наличие таких сетей явно проявляется в экспериментах с участием людей с разделёнными полушариями мозга.
Или сеть ответственная за иллюзию квалия, создающие ощущения централизованного восприятия мира. Также механизм восприятия границ своего тела и действий, нарушение этого механизма у людей может приводить к навязчивому стремлению избавиться от части своего тела или не способность различать свои действия от действий другого человека.
Мы знаем, что нарушения в различных психических механизмах могут приводить к различным болезням аутистического спектра или различных форм шизофрении. На пути к искусственному интеллекту суждено встретится с примерами этих отклонений в искусственной психике, но у этого есть и полезное зерно. Работа над искусственным интеллектом позволит понять лучше природу психических болезней человека.
Гиперколончатая сеть, или гиперсеть
Сейчас мы находимся на первом этапе этой маршрутной карты, на этапе создания суперэффективных нейронных сетей. Для меня это не совсем первый этап, прежде пришлось разобраться в принципах работы периферийной нервной системы и в том, как работают нейронные сети в простых нервных системах и в целом создать не одну модель работы нейронов. Сейчас я разрабатываю модель главным структурным элементом, которой является не нейрон, а гиперколонка или кортикальный модуль. Отсюда и рабочее название гиперколончатая сесть или кратко гиперсеть.
Далее я расскажу подробней, на каких принципах она основана и то, как я её реализую.
Вторая сигнальная система – узлы
Давайте разберемся, как информация от рецепторов может репрезентоваться в коре, для этого нужно разобраться, как протекают два простых механизма иррадиация и индукция, известных уже более века.
Иррадиация – это стремление нервного возбуждения распространиться на соседние нейроны или соседнюю нервную ткань.

Обычно отростки клеток одной колонки могут, распространяется на соседние колонки, и оказывать в соседних колонках побудительное действие. Характер такого побудительного действия на соседние колонки можно представить в виде некоторого круглого ореола с максимальным воздействием в центре и с постепенным ослаблением при удалении от центра.

Индукция – это возникновение областей торможения на коре вокруг участка возбуждения. Это может быть связанно с тем, что отростки нейронов одной колонки на некотором расстоянии колонки могут образовывать связи с ингибирующими клетками других колонок. Характер ингибирующего (тормозящего) воздействия на соседние колонки можно представить следующим образом:

Эти процессы работают в коре головного мозга одновременно. Давайте смоделируем то как будет трансформироваться возбуждение, возникающее в коре под воздействием этих двух механизмов. Для этого был написан пиксельный шейдер – программа, выполняемая графическим процессором для каждого пикселя изображения.

В модели каждый пиксель изображения будет являться отдельным кортикальным модулем, чем ярче пиксель, тем сильнее общее возбуждение в колонке.
Пример работы шейдера, размер изображения 28х28 пикселей, радиус действия колонки 5 пикселей, шейдер применяется несколько раз:

Радиус действия колонки 7 пикселей:

Как видим, под действием механизмов иррадиации и индукции любая активность разбивается на небольшие очаги возбуждения. Размер этих очагов зависит от размера общего воздействия на соседние гиперколонки, а также на соотношение сил действия побудительных и тормозящих карт.

Эти очаги возбуждения как бы капсулируются, окружая себя областью тормозящего действия. Также их центральная часть при нескольких применениях вычислений шейдера к изображению, за счёт иррадиации становиться всё более активным, тем самым эти очаги становиться ярко выраженными и стабильными.
Эти очаги возбуждения в дальнейшем будем называть узлами (nodes). Узлы – это некоторое новое эмерджентное свойство коры, оно проявляется в результате взаимной работы двух механизмов иррадиации и индукции. Узлы не привязаны к размерам и положению ни нейронов, ни гипреколонок, они работают как бы над этими структурами. Именно комбинации и расположение узлов и является репрезентацией информации в коре головного мозга.
Узлы – это вторая сигнальная система, это символьное представление образов в мозге, это коги.
Удивительно то, насколько простыми и элегантными решениями пользуется кора и мозг в целом.
Чтобы разобраться в том, как узлы могут хранить в себе образы или части образов, требуется изучить ещё один механизм, работающий в коре.
Реверберация возбуждения
Реверберация возбуждения – это длительная циркуляция импульсов возбуждения в сетях нейронов или между различными структурами центральной нервной системы. Для нас большое значение имеют кортико-таламические реверберации и реверберации, возникающие между различными областями коры. Именно подобные реверберации и создают различные рисунки и ритмы при электроэнцефалографии мозга. Для подобных ревербераций необходимы нисходящие или обратные связи, которых как отмечается обычно в несколько раз больше, чем восходящих, прямых связей.

Для моделирования процесса реверберации нам потребуется четыре карты. Картами здесь я называю изображения, к которым мы будем применять некоторые пиксельные шейдеры, если это необходимо для нашей модели.

Карта таламического ядра, на которую мы будем проецировать некоторые образы, в данном случае примеры рукописных цифр из стандартного набора MNIST. Изображения в наборе MNIST имеют формат 28x28 пикселей, поэтому эту карту мы также установим 28x28 пикселей.
Карта коры будет составлять в данном варианте 21x21 пиксель.
Карта восходящих синаптических связей будет хранить в себе значения всех весов синапсов связывающих карту таламического ядра и карту коры. Условно каждый пиксель-гиперколонка коры будет иметь синапсы с 64-мя (ядро 8x8) пикселями карты таламического ядра. Если перемещать ядро 8x8 пикселей по карте таламического ядра шагом в один пиксель, то таким образом можно составить карту восходящих синаптических связей. Соответственно отсюда и получится размер карты коры 28 – 8 + 1 = 21, в свою очередь размер карты восходящих синаптических контактов будет составлять 168x168 пикселей (21 x 8 = 168).

Вес синапса будет определяться числом от 0 до 1 – это удобно для графического отображения на карте и позволяет хранить и обрабатывать эти параметры в форме изображений, что также удобно в работе с шейдерами, а также очень наглядно.
Еще один важный момент, в моделях, которые я буду описывать, присутствует всегда по две карты синаптических связей: одна карта побудительных синапсов, вторая карта тормозящих синапсов. Это всегда две одинаковые по размеру карты.
Известно, что тип синаптического контакта в биологической нервной системе в течение жизнедеятельности не меняется, то есть побудительный синапс не может стать тормозящим или наоборот. В компьютерных нейронных сетях знак веса синапса может легко изменяться в процессе обучения, что для модели претендующих на биологичность не является правильным.

В колонках коры помимо побудительных пирамидальных нейронов присутствуют множество тормозящих нейронов, и любой аксон от побудительной клетки направленный к колонке может создать синаптический контакт, как с побудительной, так и с тормозящей клеткой. Аналогично этому у нас имеется по две карты синаптических контактов, одна будет действовать со знаком «плюс», другая со знаком «минус». В обеих этих картах вес будет определяться числом от 0 до 1.
Значение весов восходящих синаптических контактов заполним случайными числами от 0 до 1.
Карта нисходящих синаптических связей будет иметь значительно больший размер. Как уже отмечалось нисходящих связей в биологическом мозге в несколько раз больше. В нашем случае мы выбираем такой размер карты, который позволит продемонстрировать концепцию хранения образов в узлах. Каждый пиксель-гиперколонка карты коры будет связан с каждым пикселем карты таламического ядра, то есть с каждым 784 пикселем (28 x 28 = 784), тогда размер карты составит 588x588 пикселей (21 x 28 = 588).
Изначально значение весов в карте нисходящих синаптических связей все будут равны 0, но данные веса мы изменим в процессе обучения.
Метод обучения, который мы в данном случае применим для нервной системы был экспериментально подтверждён. Он известен, как правило Хебба, самая простая его интерпретация: вместе срабатываем, значит укрепляем связь; а так же обратная сторона: не сработали вместе – связь ослабеваем.
Для начала предъявим нашей модели пример, проецируя его на карту таламического ядра. Затем через восходящие связи оказываем суммирующее воздействие на карту коры. Для каждого пикселя карты коры складываются все соответствующие ему значение весов из карты восходящих синаптических связей умноженное на значение уровня активности соответствующих пикселей карты таламического ядра. Значение весов из тормозящей карты восходящих синаптических связей будет складываться со знаком «минус». Полученная сумма умножается на подобранный коэффициент, именуемый коэффициент чувствительности. В данном случае он равен 0,5.
Если полученная сумма меньше или равна нулю, то активации пиксель-гиперколонки не происходит, его активность равна нулю. Если полученная сумма больше единицы, то значение пикселя карты коры будет равна единице, как максимальная степень активации гиперколонки. Если сумма имеет значение в интервале от 0 до 1, то пиксель-гиперколонка карты коры примет это значение.
Коэффициент чувствительности подбирается таким, чтобы в результате суммы не активизировалось сильно большое число гиперколонок карты коры, так как это приводит к взаимному подавлению активности при применении индукции. А также коэффициент чувствительности не должен быть сильно низким, потому что это может привести к очень низкой активности гиперколонок.

Далее к карте коры мы применяем шейдер механизмов иррадиации и индукции. Этот шейдер мы можем применить несколько раз. Как результат получаем на карте коры несколько узлов.
Затем обращаемся к карте нисходящих синаптических связей и применяем к ней правило Хебба для обучения. Причём мы его применяем следующим образом: в случае совместного срабатывания мы в значительной степени усиливаем синаптическую связь. Если пресинапс срабатывает, а постсинапс нет, то ослабеваем синаптическую связь лишь на небольшое значение. В данном случае, при совместном срабатывании вес синапса увеличится на 0,8, при отсутствии совместного срабатывания вес уменьшится только на 0,1. Большее значение имеет именно совпадения, чем их отсутствие. Обратите внимание, что настраивается пресинапс, а не постсинапс, хотя сейчас это не имеет критического значения, так как весь синапс у нас регулируется одним весом, но это имеет важное идеологическое значение. Дело в том, что в классических нейронных сетях акцент даётся на настройку постсинапсов, и полностью игнорируется изменения в пресинапсах, хотя в биологических нейронных сетях изменения происходят в обеих частях синапса, и в пресинапсе они зачастую более ярко выражены (Сравнение мозга с нейронной сетью).

Для тормозящей карты нисходящих синаптических связей логично применить правио Хебба наоборот, ингибирующая связь будет усиливаться, когда постсинапс не будет активироваться при активности пресинапса.
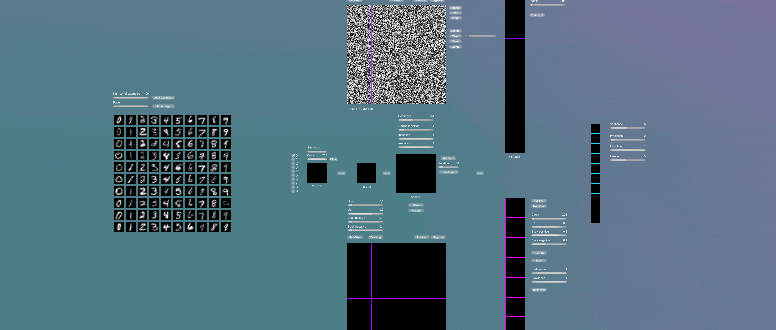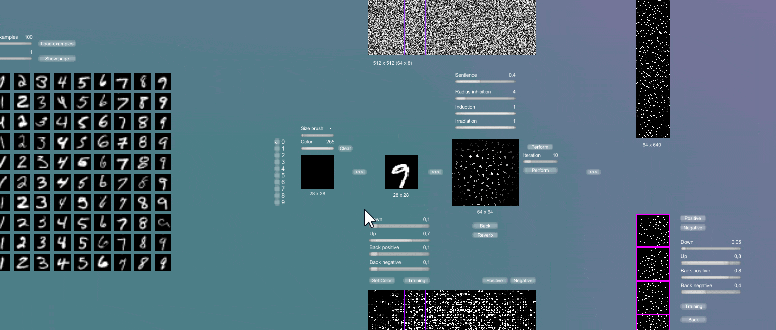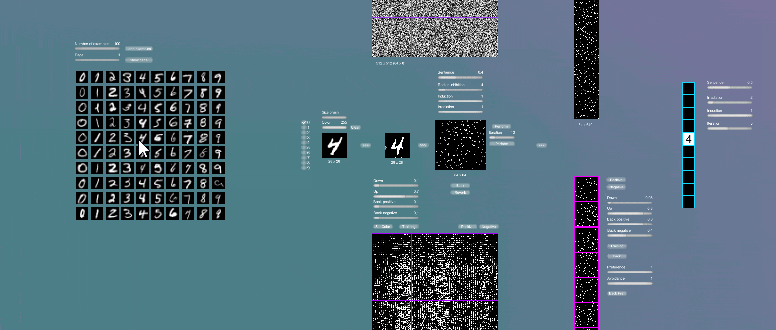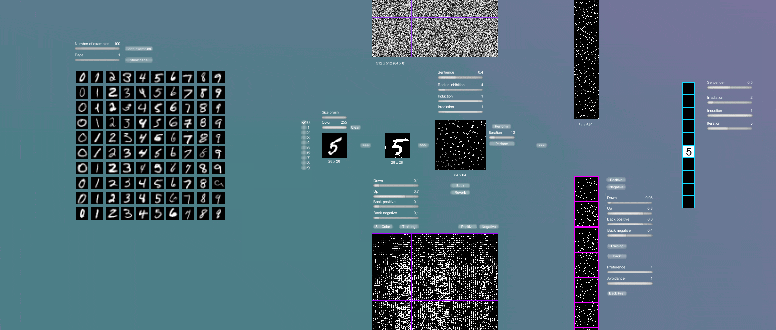
Так выглядят карты нисходящих синатических связей после обучения на ста примерах(по десять примеров на цифру).

Можно увидеть, что в картах нисходящих синаптических связей отражаются образы целых цифр, причём ы тех местах, которые соответствуют узлам, которые активизируются на данные образы. Это возможно потому, что выбранное количество обратных связей для каждой микроколонки охватывает всю карту таламического ядра, в случае если обратные связи охватывали только часть карты, то и гиперколонка могла бы хранить в себе только часть образа. Так в узлах может быть записаны некоторые образы или некоторые составные части образов.
Узел при его активации как бы «смотрит» на ту активность, которая его активизирует и сохраняет её в себе. В узлах хранятся как бы некие эталонные примеры образов.

Теперь после обучения карты нисходящих синаптических связей, можно запустить циклическую передачу возбуждения – реверберации.
Мы можем увидеть примеры того как изначальная проекция какого-нибудь примера на карту таламического ядра, будет преобразовываться в процессе ревербераций в некий эталонный вариант этой же цифры, и с этим вариантом реверберации будут стабильны.
Этот процесс очень похож на работу сетей Хопфилда, из-за наличия рекуррентных связей этот тип нейронных сетей, на мой взгляд, наиболее близок к работе биологических нейронных сетей. В отличие от сетей Хопфилда в нашем варианте присутствует некая сепарация на узлы, которая даёт некоторые преимущества. Количество входов и выходов в сетях Хопфилда одинаковое, каждый нейрон связан рекуррентной связью с другими нейронами. Получается, что каждый образ как бы храниться в весах каждого нейрона, что сильно уменьшает ёмкость сети. В нашем случае для хранения отдельных образов избираются отдельные группы колонок. Наш вариант сети более интерпретируемый, мы можем точно сказать, за какой образ ответственен тот или иной элемент. Здесь прослеживается явная репрезентация информации, аналогично наличию в коре мозга «нейронов бабушки» мы видим пиксели-колонки карты коры ответственный за образ той или иной цифры.
Моделирование действие LSD на кору больших полушарий
Это небольшое отступление продемонстрирует некоторое сходство нашей модели и работы биологического мозга. Дело в том, что для нас действие LSD на кору очень просто смоделировать. LSD своим действием мешает работе нейротрансмиттера ГАМК, который является главным ингибирующим нейромедиатором коры, он работает в механизме индукции. Поэтому чтобы это смоделировать, достаточно в настройках нашего пиксельного шейдера уменьшить степень действия индукции.

Как мы видим при этом привычные границы, и размеры узлов размываются и расширяются. Если еще уменьшить действие индукции то очаги активности могул сливаться, формируя некоторые узоры. Аналогичные явления могут происходить и в коре больших полушарий под действием LSD, о чём косвенно свидетельствует снимки МРТ сделанные у людей принявших LSD, активность коры в данном случае значительно большее и масштабнее, чем при обычной работе мозга. Учитывая, что практически каждая колонка хранит в себе образы или их части, то становиться понятным, почему происходит путаница и смешивание образов, понятны причины нарушения восприятия. Такие нарушения работы мозга не могут быть полезны для него.
Наркотики вредны для здоровья и здоровья мозга.
Обучение восходящих синаптических связей
Настройка восходящих синаптических связей, также имеет большое значение, так как их настойка определяет, где будут возникать узлы при применении иррадиации и индукции.
Для начала мы немного изменим и дополним нашу модель. Во-первых, мы увеличим размер карты коры, в биологическом мозге размер или площадь коры значительно превосходит размеры подкорковых и таламических ядер, с которыми она связана. Во-вторых, мы добавим ещё один уровень обработки информации, так как более высокие уровни имеют большое значение при обучении восходящих связей уровней ниже.
Чтобы увеличить размер карты коры, но при этом сохранить размеры карты таламического ядра (28x28 пикселей), нам придётся увеличить количество восходящих синаптических связей. Для этого мы применим некую модель нерва, которая представляет собой карту связей. Карта связей нерва это изображение, которое использует два цветовых канала для кодирования координаты пикселя карты источника сигнала.

Мы можем создать для начала карту связей нерва, в которой координаты пикселей карты источника согласовывались с самой картой связей нерва. И если мы применим такую карту нерва к нашей карте таламического ядра, то получим просто увеличенное изображение. Но если в данную карту связей нерва внести перемешивание пикселей, то использование такой карты приведёт к тому, что каждый пиксель карты источника представлен на карте нерва в виде множества пикселей и в зависимости от степени и способа перемешивания расположение этих пикселей будет разным. При перемешивании, в котором пиксели приставляются между собой на небольшое расстояние можно получить некое случайное скопление пикселей-представителей. Это очень похоже на то, как волокна из аксонов нейронов из наружного коленчатого тела складываются в нервы, в которых аксоны многократно разделяются, и концы аксонов рассредоточиваются по первичной зрительной коре, при этом сохраняя некоторую топографию сетчатки и при этом смешиваясь.
В нашем варианте на карту таламического ядра размером 28x28 пикселей мы применим карту связей нерва размером 512x512. Эта карта нерва будет связывать карту таламического ядра с картой коры размером 64x64 пикселя, то есть разбить всю карту связей нерва на квадраты 8x8 пикселей, то каждый такой квадрат включит в себя все связи пикселем-гиперколонкой (512 / 8 = 64).
Карты связей нерва не меняются в процессе обучения и работы сети, она задается перед началом работы с сетью, аналогично тому, как нервы формируются в мозге до рождения.

Соответственно карты восходящих синаптических связей будут иметь размер 512x512 пикселей.
Карта нисходящих синаптических связей будет иметь размер 1024x1024, по причине, что количество рекуррентных связей должно быть больше для стабильных ревербераций. Здесь каждому пикселю карты коры будет соответствовать 16x16 пикселей карты таламического ядра (64 x 16 = 1024).
Следующий уровень обработки информации представлен картой выхода, которая имеет размер 1x10, по одному пикселю на цифру, так как наша сеть нацелена на распознавание рукописных цифр из стандартного набора MNIST. Карта выхода связана с картой коры аналогично, как и карта таламического ядра с картой коры. Соответственно также имеются карты восходящих синаптических связей и карты, нисходящих синаптических связей, которые имею размерность 64x640 пикселей. Таким образом каждый пиксель карты коры имеет синаптический контакт с каждым пикселем карты выхода, для того чтобы пиксели карты выхода имели максимальное рецептивное поле. Нисходящие синаптические связи как уже отмечалось, обычно имеют большее количество, чем восходящие, но в данном случае они будут одинаковы в количестве потому, что это будет максимальный размер обратных синаптических связей. Так каждый пиксель карты выхода «видит» каждый пиксель карты коры.

Обучение или настройку карты восходящих синаптических связей второго уровня можно провести по правилу Хебба, которое мы уже применяли. При этом во время обучения мы будем считать активным или равным 1 пиксель карты выхода, который соответствует цифре, пример которой предъявлен сети. Тем самым мы как бы связываем некоторую активность на карте коры с требуемым выходом и укрепляем эту связь. Это похоже на формирование рефлекторной дуги условного рефлекса, как представительство цифры связывается связями с комбинацией активных пикселей в карте таламического ядра. Таким образом, фактически не связанные элементы прямыми контактами за счет рекуррентных связей могут связываться и укреплять свои связи между собой. И это может работать через множество уровней.
Но если обучать или настраивать по правилу Хебба карту восходящих синаптических связей первого уровня, это правило приводит к тому, что слабоактивные пиксель-гиперколонки за счёт усиления с ними связей будут усиливать свою активность до максимума, и это создаст большое количество активных пиксель-гиперколонок, что приводит к взаимному подавлению при применении индукции. И это приводит к сильному снижению качества сети.
Поэтому мы применим другой способ обучения. Он будет состоять из двух этапов. Первый этап – это инициализация образов. На этом этапе мы сформируем некое базовое представление о каждом распознаваемом образе цифры, на малом количестве примеров. Для этого достаточно от 10 до 100 примеров, или от 1 до 10 примеров на одну цифру. На этом этапе будут настраиваться все карты синаптических связей кроме карт восходящих синаптических связей первого уровня, но они должны быть заполнены случайными значениями.
Сначала проецируем пример на карту таламического ядра, затем производим суммацию с применением случайных весов карты синаптических связей. Прежде чем применить шейдер иррадиации и индукции мы можем повлиять на карту коры, так чтобы итоговые узлы не совпадали для разных цифр. Для этого обратимся к карте нисходящих связей второго уровня, которая хранит в себе «отпечатки» паттернов узлов для каждой цифры сформированной на основе предыдущего опыта. Соответственно если такого опыта не было, то на карту коры не будет оказано никакого влияния. К примеру, если примером является цифра «5», то к карте коры мы прибавим значения побудительной карты нисходящих синаптических связей сектора соответствующих образу цифры «5». Это повысит шансы на образование узлов в том же месте, где эти узлы образовывались в прошлом акте обучения цифре «5». Так же мы вычтем из карты коры значения остальных секторов не связанных с цифрой «5». Это способствует тому, что узлы не будут образовываться в тех местах, которые соответствуют другим цифрам.
После такой коррекции значений карты коры применяем пиксельный шейдер ответственный за иррадиацию и индукцию.
Затем настраиваем карты восходящих синаптических связей второго уровня по правилу Хебба, с учётом того что на карте выхода будет активным пиксель соответствующий предъявляемому примеру.
Так же по правилу Хебба настраиваем карты нисходящих синаптических связей второго и первого уровня.
Так выглядят синаптических связей после такого обучения на 100 примерах(a и b карты восходящих побудительный и тормозящих синаптических связей второго уровня; c и d карты нисходящих побудительных и тормозящих синаптических связей второго уровня; f и g карты нисходящих побудительных и тормозящих синаптических связей первого уровня):

Особое внимание обращаю на карту нисходящих синаптических связей второго уровня, на ней как бы запечатлены положения всех узлов на карте коры для каждой цифры. Причём узлы для отдельных цифр редко совпадают, то есть каждая цифра имеет свой уникальный паттерн узлов.

Мы переходим к следующему этапу обучения, в котором нам нужно главным образом настраивать карты восходящих синаптических связей первого уровня и желательно таким образом, чтобы предъявленный незнакомый сети пример формировал на карте коры соответствующий цифре примера паттерн узлов. Для этого после суммации мы будем получать разность между значениями карты коры и соответствующему примеру сектору карты нисходящих синаптических связей. Благодаря этой разности, возможно, настраивать веса в карте восходящих синаптических связей так, чтобы предъявленный пример приводил к активности соответствующие его образу цифры узлы.
На видео обучение сети на 100 случайных примерах и тест на 10 000 тестовых примерах. В зависимости от выбранных обучающих примеров, возможно, от случайно выбранных весов для карты восходящих синаптических связей сеть в таком тесте выдает результат в диапазоне от 40 до 60%, увеличение количества примеров не даёт улучшения качества. Это очень скромный результат, но для данной задачи требуется более сложная архитектура сети. Числа и знаки распознаются нашим мозгом на достаточно высоком абстрактном уровне. Соответственно в модели требуется больше уровней. А также в биологическом зрительном анализаторе применяется некоторый дополнительный механизм, специальный фильтр из сетей нейронов, которые реагируют на определённой ориентации раздражители. Этот фильтр упрощает обработку зрительной информации. Добавление подобного фильтра, так же должно улучшить качество нашей сети. Все эти модификации требуют дальнейших исследований, над которыми работа будет продолжаться. Цель статьи и это примера рассказать о некоторых теоритических аспектах модели и подхода в целом.
Обычно художник не рисует картины подобно плоттеру, начиная с верхнего угла нанося сразу все детали бедующего произведения. Художник для начала наносит на холст эскиз из тонких еле заметных линий обозначающий общий план художественного замысла. Постепенно картина обрастает деталями, все более и более мелкими, в конце наносятся лишь самые точные и едва заметные мазки кистью. Подобно этому нужно подходить к вопросу моделирования мозга. Безнадёжно пытаться подробно моделировать, последовательно создавая кортикальные модули с множеством синаптических связей с большим разнообразием типов нейронов и нейромедиаторов. Лучшее решение это создавать изначально простые симуляции отдельных механизмов постепенно добавляя в модели необходимые детали.
Попытка смоделировать взаимодействие двух простых механизмов в коре больших полушарий привела меня к идеи гиперсети описанной выше. Развитие идеи суперэффективных нейронных сетей в корне изменит положение вещей в сфере искусственного интеллекта. Для таких сетей не требуется большое количество обучающих данных, а значит, многие задачи которые сложно реализовать в машинном обучении из-за сложности сбора обучающих данных будут решены, да и скорость разработки в прикладных задачах значительно ускориться. Вычислительные ресурсы для обучения не будут требоваться столь высокими, а значит, не потребуется строить мощных компьютеров со специализированной архитектурой, что очень дорого и трудозатратно. Разработчики станут менее зависимы от технологий, данных и сервисов. Каждый сможет создавать крутое интеллектуальное программное обеспечение без существенных затрат. Что создаст лавину новых интересных технических решений в сфере ИИ.
P.S.
Моя работа продолжается, сейчас есть идеи развития и улучшения сети. До этого этапа я шёл более трёх лет, некоторые читатели, думаю, уже не рассчитывали на появление весомых этапов и статей в моей работе. Как только идея оглашена, она тут же воспринимается простой и очевидной, но за каждой важной идеей стоит большой труд и упорство. Предстоит еще много работы, поэтому подписывайтесь и распространяйте ссылки на статью. :-) Этим Вы мне поможете.
Download for Windows














rsashka
Первое, что нужно решить на пути к искусственному интеллекту — понять, что такое интеллект.
garwall
плюс много. и надо напоминать тот факт, на тьюринговских компьютерах он может и невозможным оказаться
michael_v89
Китайская комната это не доказывает, и вообще это уже разобрали давно, описано в разделе "Аргумент о системе".