
Gyozo Kmethy – исполнительный директор и президент ассоциации DLMS – и Milan Kozole – председатель технического комитета ассоциации DLMS – в своей статье «Efficiency of DLMS/COSEM for large systems with constrained resources» рассказывают о способах и средствах эффективного использования стека DLMS/COSEM, позволяющие до 10 раз сократить объем передаваемых данных и уменьшить количество информационных обменов между клиентом и сервером.
Введение
DLMS/COSEM – это ведущий мировой стандарт (IEC/EN 62056, EN 13757), регламентирующий обмен данными с интеллектуальными устройствами. В настоящее время применяется, преимущественно, в интеллектуальных системах учёта потребления. Как правило такие системы состоят из головной подсистемы, которая собирает данные с миллионов устройств, а также управляет этими устройствами, используя для этих целей различные среды передачи данных.
DLMS/COSEM включает в себя три основные составляющие: (1) объектная модель COSEM, с помощью которой описывается функциональность конечного устройства; (2) прикладной уровень DLMS, который определяет сервисы для доступа к объектам COSEM; и (3) коммуникационные профили, которые определяют то, как эти сервисы могут быть переданы через различные среды передачи данных. Кроме того, DLMS/COSEM основан на клиент-серверной архитектуре, где головная подсистема выполняет роль клиента, посылающего запросы конечному устройству, а конечное устройство – роль сервера, посылающего ответы на запросы клиента.
Некоторые сети связи и устройства, реализующие DLMS/COSEM, обладают достаточными ресурсами, но DLMS/COSEM всё чаще применяется там, где эти ресурсы ограничены. Ресурсы устройства могут быть ограничены его возможностью обработки и хранения данных или питанием от встроенных батарей в течении всего срока его службы. Сети связи могут быть ограничены по количеству и длине передаваемых пакетов данных, а ограниченность системы может быть обусловлена требованием соответствия заданным уровням обслуживания.
DLMS/COSEM был разработан с акцентом на эффективность, что позволяет успешно применять его в условиях ограниченности ресурсов, о которых было сказано выше. По мере распространения DLMS/COSEM в новые области применения, также развивались и способы повышения его эффективности.
Способы повышения эффективности DLMS/COSEM
Способы повышения эффективности DLMS/COSEM определены, как на уровне объектной модели COSEM, так и на прикладном уровне DLMS. Все они приведены в табл. 1.
Таблица 1 – Способы повышения эффективности DLMS/COSEM
Различные способы могут быть скомбинированы для достижения максимальной эффективности с учетом характеристик устройств и сетей передачи данных. Далее будет приведено краткое описание каждого способа повышения эффективности. Более подробная информация доступна в BlueBook, в которой описана объектная модель COSEM, и в GreenBook, в которой описан протокол прикладного уровня DLMS.
Разделение значений на динамические и статические
Объекты COSEM представляют данные, которые содержатся в атрибутах и включают в себя:
- атрибут
logical_name, который вместе с другими атрибутами определяет смысловое значение каждого элемента данных; - атрибут
value, представляющий значение параметра или значение, полученное в результате вычислений или измерений; - и другие атрибуты, представляющие метаданные, например, множители, единицы измерений, метки времени, статус и т.п.
Некоторые метаданные могут храниться в отдельных объектах COSEM, например, серийный номер прибора учёта, номер договора, цена за единицу и т.п.
Значения, полученные в результате вычислений или измерений, как правило являются динамическими, поэтому их приходиться передавать довольно часто. Метаданные, как правило статичны, поэтому их достаточно передать один раз, или во всяком случае передавать не так часто.
Разделение значений на динамические и статические значительно повышает эффективность за счёт сокращения объема передаваемых данных.
Агрегирование данных
Данный способ позволяет собрать любую комбинацию данных (значений атрибутов) в одном атрибуте. Таким образом доступ к данным может быть осуществлен за один вызов сервиса DLMS, что позволяет сократить количество сообщений при обмене данными. Агрегирование данных доступно c:
- объектами интерфейсного класса «Profile Generic», позволяющие захватывать значения нескольких атрибутов и сохранять их в атрибуте
buffer, с заданной периодичностью или при возникновении определенных событий. Значения в атрибутеbufferпредставляются в виде таблицы, имеющей несколько столбцов и строк/записей. Например, объектами данного интерфейсного класса являются: профиль нагрузки, журнал событий, профиль мгновенных значений; - объектами интерфейсного класса «Data Protection», позволяющие защитить значения агрегированных атрибутов криптографическими методами;
- объектами интерфейсного класса «Register table», позволяющие захватывать однотипные значения, представляя их в табличном виде. Например, объекты данного интерфейсного класса могут захватывать значения, связанные с гармониками, фазовыми углами, составом газа;
- объектами интерфейсного класса «Compact data», позволяющие захватывать не кодированные данные, которые затем могут быть загружены в предопределенный шаблон; см. ниже.
Использование селективной выборки
Когда данные уже агрегированы, может потребоваться выбрать только часть данных, например, для того чтобы получить только те данные, которые интересны именно сейчас или восстановить потерянные данные. Селективная выборка может быть абсолютной, например, когда указан временной интервал или диапазон записей, или относительной, например, относительно текущего времени или текущей записи. Селективная выборка доступна в объектах классов «Profile generic», «Data protection» и «Compact data».
Использование NULL-data сжатия
NULL-data сжатие эффективно при передаче массивов данных, подобных тем, что содержатся в атрибуте buffer объектов класса «Profile Generic», хранящие профиль нагрузки или журнал событий. Если текущие значения данных могут быть определенны из их предыдущих значений, то они заменяются на null-data, размер которого равен одному байту. Потому что значения данных либо не изменились (например, при чтении регистра или статуса было получено значение, равное предыдущему), либо эти изменения известны (например, в случае с метками времени, когда задано определённое расписание).
В разработке находится более совершенный способ, так называемое delta-array сжатие. Оно также применимо для передачи массивов данных и позволяет динамически использовать максимально короткий тип данных в зависимости от изменения значения.
Например, значение long-64-unsigned, которое занимает 9 байт (включая тег), может быть заменено на значение delta-unsigned, которое занимает всего 2 байта, если его изменение было небольшим.
Оба способа значительно сокращают размер сообщений.
Использование данных типа compact-array
Тип compact-array применим, когда массив содержит однотипные данные. В этом случае, типы данных, одинаковые для каждого элемента массива, передаются только один раз в виде одного значения. Данный способ повышения эффективности значительно сокращает накладные расходы, связанные с кодированием значений.
Использование интерфейсного класса «Compact data»
Интерфейсный класс «Compact data», который уже упоминался выше, разработан с целью захвата не кодированных данных в атрибут compact_buffer. Захватываемые данные могут иметь простой или сложный тип, кроме того к ним применима селективная выборка. Например, можно захватить атрибуты buffer объектов интерфейсного класса «Profile generic» в объекты класса «Compact data».
Тип и длина каждого элемента не кодированных данных описываются в шаблоне, который является значением атрибута template_description. Каждый шаблон имеет свой уникальный идентификатор template_id. В атрибуте compact_buffer содержатся как не кодированные данные, так и идентификатор template_id. Значение атрибута compact_buffer может быть прочитано по запросу клиента или отправлено ему в виде инициативного сообщения.
Данный способ повышения эффективности практически полностью устраняет накладные расходы на кодирование, сокращая их до одного байта.
Агрегирование сервисов
Сервисы DLMS – это средства для доступа к атрибутам и методам объекта COSEM. Запросы содержат ссылку на атрибут или метод, а ответы – результат операции. Запросы и ответы также могут содержать данные.
Агрегирование сервисов означает, что с помощью одного запроса/ответа можно обратиться к нескольким атрибутам и/или методам. Данный способ сокращает количество информационных обменов, необходимых для выполнения всех требуемых операций.
Сервисы типа WITH-LIST позволяют агрегировать сервисы одного и того же типа. Они доступны с сервисами GET, SET, ACTION, READ, WRITE и UnconfirmedWrite. Запросы типа WITH-LIST содержат список ссылок на атрибуты/методы и соответствующий им список данных, а ответы типа WITH-LIST – список результатов и список данных, если таковые есть.
Сервис ACCESS объединяет сервисы GET-SET-ACTION, предоставляя тем самым возможность чтения и записи атрибутов, а также вызова некоторого числа методов, за один запрос/ответ.
Использование составных сообщений
Превосходный способ повышения эффективности на прикладном уровне стека DLMS/COSEM предоставляет концепция составных сообщений. Она сочетает в себе несколько этапов процесса, который позволяет сократить как размер сообщения, так и количество информационных обменов, обеспечивая тем самым оптимальное использование пропускной способности канала связи. Схема, иллюстрирующая данную концепцию, приведена на рис. 1.

Рисунок 1 — Составные сообщения
На первом этапе кодируется xDLMS APDU, представляющий собой один сервис или несколько агрегированных сервисов прикладного уровня DLMS. APDU содержит данные, которые могут быть оптимизированы с помощью одного или нескольких способов повышения эффективности на уровне объектной модели COSEM, о которых было сказано выше.
На втором этапе возможно сжатие данных с применением алгоритма V.44.
На третьем этапе, по мере необходимости, возможно применение одного или нескольких уровней криптографической защиты для обеспечения конфиденциальности, подлинности и целостности передаваемых данных. Полученный APDU может быть передан с помощью механизма General Block Transfer в виде блоков данных. General Block Transfer позволяет осуществлять двунаправленный обмен данными, потоковую передачу и восстанавливать потерянные блоки данных.
Использование предустановленных и неразрывных ассоциаций приложений
Обмен данными в DLMS/COSEM осуществляется в рамках логического соединения между клиентом и сервером, так называемой ассоциации приложений. В ассоциации приложений идентифицируются партнеры (клиент и сервер) и определяется контекст взаимодействия в рамках сеанса связи, который включает информацию об использовании/неиспользовании криптографической защиты данных, список доступных сервисов и максимальный размер сообщений прикладного уровня.
В начале сеанса связи устанавливается ассоциация приложений и при необходимости осуществляется аутентификация двух взаимодействующих узлов. В конце сеанса связи эта ассоциация разрывается. Схематично процесс обмена данными между клиентом и сервером показан на рис. 2.
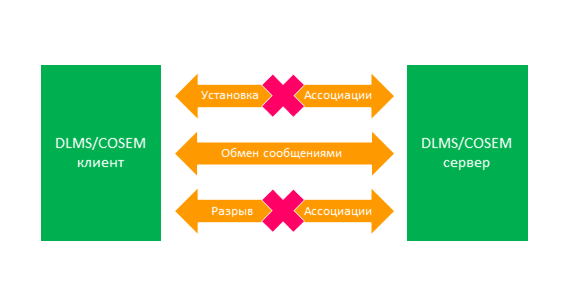
Рисунок 2 — Схема сеанса связи с явно установленным и предустановленным логическим соединением
В сетях с нестабильной связью соединение между клиентом и сервером может пропадать. При этом, когда теряется соединение на уровне протоколов, обеспечивающих передачу данных прикладного уровня DLMS, то явно установленная ассоциация приложений также разрывается.
Неразрывная ассоциация приложений позволяет продолжить информационный обмен при восстановлении соединения, без необходимости её повторной установки. Если требуется изменить её контекст, то в этом случае она принудительно разрывается и устанавливается заново с новым контекстом.
Предустановленная ассоциация приложений позволяет вовсе исключить процедуры, связанные с установкой и разрывом логического соединения между клиентом и сервером, если стороны информационного обмена заранее согласовали контекст взаимодействия, например, в соответствующей спецификации. Предустановленные ассоциации, в отличии от неразрывных, не могут быть разорваны.
Оба способа повышения эффективности позволяют уменьшить или вовсе исключить процедуры, связанные с установкой и разрывом логического соединения между клиентом и сервером.
Использование инициативных сообщений
В DLMS/COSEM определены два вида операций, как показано на рис. 3:
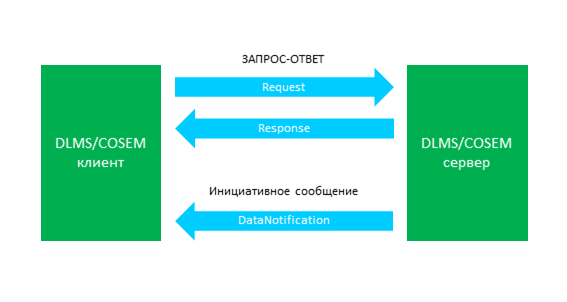
Рисунок 3 — Операции ЗАПРОС-ОТВЕТ и инициативные сообщения
- Операция ЗАПРОС-ОТВЕТ, при которой клиент (например, устройство сбора и передачи данных) отправляет ЗАПРОС серверу (например, прибор учёта), а сервер отправляет ОТВЕТ клиенту. К этому виду операций относятся следующие сервисы:
GET,SET,ACTION,ACCESSиRead/Write; - Инициативные сообщения – когда при определенных условиях, сервер отправляет определенным адресатам определенный набор данных. Клиент может в любой момент времени изменить те самые условия, адресаты и набор данных. Инициативные сообщения генерируются внутри сервера, при этом не требуется операции ЗАПРОС со стороны клиента. Однако клиент может удаленно инициировать в сервере процедуру передачи инициативного сообщения, например, для получения недостающих данных.
Для отправки инициативных сообщений используется сервис DataNotification и применяется способ повышения эффективности, описанный в разделе «Использование составных сообщений».
Использование широковещательных и многоадресных сообщений
Широковещательные и многоадресные сообщения используются для отправки данных с головной системы в множество конечных устройств, с помощью одного запроса. При условии, что среда передачи данных позволяет это делать. Такие сообщения могут быть использованы, например, для рассылки тарифного расписания, синхронизации часов и т.п.
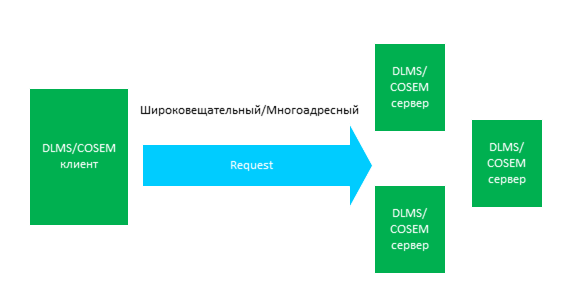
Кроме того, они могут применяться вместе с механизмом передачи образа «прошивки», который используется для загрузки и активации нового образа «прошивки» в группе устройств. Он позволяет восстанавливать потерянные блоки данных и гарантирует идентичность переданного и принятого образов «прошивок».
Заключение
Варианты применения в которых осуществлялось чтение больших объемов данных, включая значение атрибута object_list объекта интерфейсного класса «Association LN», чтение или инициативная передача профиля нагрузки для нескольких измерительных каналов вместе со статусной информацией и меткой времени, обновление образа «прошивки» с применением потоковой передачи и широковещательных или многоадресных сообщений, показали сокращение объема передаваемых данных до 10 раз и снижение количества информационных обменов, при использовании приведенных способов повышения эффективности.
