
Данная публикация предназначена для тех, кто интересуется устройством распределенных систем, брокерами сообщений и Apache Kafka. Здесь вы не найдете эксклюзивного материала или лайфхаков, задача этой статьи – заложить фундамент и рассказать о внутреннем устройстве упомянутого брокера. Таким образом, в следующих публикациях мы сможем делать ссылки на данную статью, рассказывая о более узкоспециализированных темах.
Привет! Меня зовут Дмитрий Шеламов и я работаю в Vivid.Money на должности backend-разработчика в отделе Customer Care. Наша компания – европейский стартап, который создает и развивает сервис интернет-банкинга для стран Европы. Это амбициозная задача, а значит и ее техническая реализация требует продуманной инфраструктуры, способной выдерживать высокие нагрузки и масштабироваться согласно требованиям бизнеса.
В основе проекта лежит микросервисная архитектура, которая включает в себя десятки сервисов на разных языках. В их числе Scala, Java, Kotlin, Python и Go. На последнем я пишу код, поэтому практические примеры, приведенные в этой серии статей, будут задействовать по большей части Go (и немного docker-compose).
Работа с микросервисами имеет свои особенности, одна из которых – организация коммуникаций между сервисами. Модель взаимодействия в этих коммуникациях бывает синхронной или асинхронной и может оказать существенное влияние на производительность и отказоустойчивость системы в целом.
Итак, представим что у нас есть два микросервиса (А и Б). Будем считать, что коммуникация между ними осуществляется через API и они ничего не знают о внутренней реализации друг друга, как и предписывает микросервисный подход. Формат передаваемых между ними данных заранее оговорен.
Задача перед нами стоит следующая: нам нужно организовать передачу данных от одного приложения к другому и, желательно, с минимальными задержками.
В самом простом случае поставленная задача достигается синхронным взаимодействием, когда А отправляет приложению Б запрос, после чего сервис Б его обрабатывает и, в зависимости от того, успешно или не успешно был обработан запрос, отправляет некоторый ответ сервису А, который этот ответ ожидает.
Если же ответ на запрос так и не был получен (например, Б рвет соединение до отправки ответа или А отваливается по таймауту), сервис А может повторить свой запрос к Б.
С одной стороны, такая модель взаимодействия дает определенность статуса доставки данных для каждого запроса, когда отправитель точно знает, были ли получены данные получателем и какие дальнейшие действия ему необходимо делать в зависимости от ответа.
С другой стороны, плата за это – ожидание. После отправки запроса сервис А (или поток, в котором выполняется запрос) блокируется до того момента, пока не получит ответ или не сочтет запрос неудавшимся согласно своей внутренней логике, после чего примет дальнейшие действия.
Проблема не только в том, что ожидание и простой имеют место быть, – задержки в сетевом взаимодействии неизбежны. Основная проблема заключается в непредсказуемости этой задержки. Участники коммуникации в микросервисном подходе не знают подробностей реализации друг друга, поэтому для запрашивающей стороны не всегда очевидно, обрабатывается ли ее запрос штатно или нужно переотправить данные.
Все, что остается А при такой модели взаимодействия – это просто ждать. Может быть наносекунду, а может быть час. И эта цифра вполне реальна в том случае, если Б в процессе обработки данных выполняет какие-либо тяжеловесные операции, вроде обработки видео.
Возможно, вам проблема не показалась существенной – одна железка ждет пока другая ответит, велика ли потеря?
Чтобы сделать эту проблему более личной, представим, что сервис А – это приложение, запущенное на вашем телефоне, и пока оно ожидает ответ от Б, вы видите на экране анимацию загрузки. Вы не можете продолжить пользоваться приложением до тех пор, пока сервис Б не ответит, и вынуждены ждать. Неизвестное количество времени. При том, что ваше время гораздо ценнее, чем время работы куска кода.
Подобные шероховатости решаются следующим образом – вы разделяете участников взаимодействия на два “лагеря”: одни не могут работать быстрее, как бы вы их ни оптимизировали (обработка видео), а другие не могут ждать дольше определенного времени (интерфейс приложения на вашем телефоне).
Затем вы заменяете cинхронное взаимодействие между ними (когда одна часть вынуждена ждать другую, чтобы удостовериться, что данные были доставлены и обработаны сервисом-получателем) на асинхронное, то есть модель работы по принципу отправил и забыл – в этом случае сервис А продолжит свою работу, не дожидаясь ответа от Б.
Но как в этом случае гарантировать то, что передача прошла успешно? Вы же не можете, допустим, загрузив видео на видеохостинг, вывести пользователю сообщение: «ваше видео может быть обрабатывается, а может быть и нет», потому что сервис, занимающийся загрузкой видео, не получил от сервиса-обработчика подтверждение, что видео дошло до него без происшествий.
В качестве одного из решений данной проблемы мы можем добавить между сервисами А и Б прослойку, которая будет выступать временным хранилищем и гарантом доставки данных в удобном для отправителя и получателя темпе. Таким образом мы сможем расцепить сервисы, синхронное взаимодействие которых потенциально может быть проблемным:
Под вышеобозначенные требования вполне подходит и обычная СУБД. Данные в ней можно хранить в течении продолжительного времени, не беспокоясь о потере информации. Также исключена и перегрузка получателей, ведь они вольны сами выбрать темп и объемы чтения предназначенных для них записей. Подтверждение же обработки можно реализовать, помечая прочитанные записи в соответствующих таблицах.
Однако выбор СУБД в качестве инструмента для обмена данными может привести к проблемам с производительностью с ростом нагрузки. Причина в том, что большинство баз данных не предназначены для такого сценария использования. Также во многих СУБД отсутствует возможность разделения подключенных клиентов на получателей и отправителей (Pub/Sub) – в этом случае, логика доставки данных должна быть реализована на клиентской стороне.
Вероятно, нам нужно нечто более узкоспециализированное, чем база данных.
Брокер сообщений (очередь сообщений) – это отдельный сервис, который отвечает за хранение и доставку данных от сервисов-отправителей к сервисам-получателям с помощью модели Pub/Sub.
Эта модель предполагает, что асинхронное взаимодействие осуществляется согласно следующей логике двух ролей:
Группирующим сообщения аттрибутом выступает очередь, которая нужна, чтобы разделять потоки данных, – таким образом, получатели могут подписываться только на те группы сообщений, которые их интересуют.
По аналогии с подписками на различных контент-платформах – подписавшись на определенного автора, вы можете фильтровать контент, выбирая смотреть только тот, который вам интересен.

Очередь можно представить как канал связи, натянутый между писателем и читателем. Писатели кладут сообщения в очередь, после чего они “проталкиваются” (push) читателям, которые подписаны на эту очередь. Один читатель получает одно сообщение за раз, после чего оно становится недоступно другим читателям.
Под сообщением же подразумевается единица данных, обычно состоящая из тела сообщения и метаданных брокера.
В общем случае, тело представляет из себя набор байт определенного формата.
Получатель обязательно должен знать этот формат, чтобы после получения сообщения иметь возможность десериализовать его тело для дальнейшей обработки.
Использовать можно любой удобный формат, однако, важно помнить об обратной совместимости, которую поддерживают, например, бинарный Protobuf и фреймворк Apache Avro.
По такому принципу работает большинство брокеров сообщений, построенных на AMQP (Advanced Message Queuing Protocol) – протоколе, который описывает стандарт отказоустойчивого обмена сообщениями посредством очередей.
Данный подход обеспечивает нам несколько важных преимуществ:
At most once исключает повторную обработку сообщений, однако допускает их потерю. В этом случае брокер будет доставлять сообщения получателям по принципу “отправил и забыл”. Если получатель не смог по какой-то причине обработать сообщение с первой попытки, брокер не будет осуществлять переотправку.
At least once, напротив, гарантирует получение сообщения получателем, однако при этом есть вероятность повторной обработки одних и тех же сообщений.
Зачастую эта гарантия достигается с помощью механизма Ack/Nack (acknowledgement/negative acknowledgement), который предписывает совершать переотправку сообщения, если получатель по какой-то причине не смог его обработать.
Таким образом, для каждого отправленного брокером (но еще не обработанного) сообщения существует три итоговых состояния — получатель вернул Ack (успешная обработка), вернул Nack (неуспешная обработка) или разорвал соединение. Последние два сценария приводят в переотправке сообщения и повторной обработке.
Однако брокер может произвести повторную отправку и при успешной обработке сообщения получателем. Например, если получатель обработал сообщение, но завершил свою работу, не отправив сигнал Ack брокеру.
В этом случае брокер снова положит сообщение в очередь, после чего оно будет обработано повторно, что может привести к ошибкам и порче данных, если разработчик не предусмотрел механизм устранения дублей на стороне получателя.
Стоит отметить, что существует еще одна гарантия доставки, которая называется “exactly once”. Ее трудно достичь в распределенных системах, но при этом она же является наиболее желаемой.
В этом плане, Apache Kafka, о которой мы будем говорить далее, выгодно выделяется на фоне многих доступных на рынке решений. Начиная с версии 0.11, Kafka предоставляет гарантию доставки exactly once в пределах кластера и транзакций, в то время как AMQP-брокеры таких гарантий предоставить не могут. Транзакции в Кафке – тема для отдельной публикации, сегодня же мы начнем со знакомства с Apache Kafka.
Мне кажется, что будет полезно для понимания начать рассказ о Кафке со схематичного изображения устройства кластера.
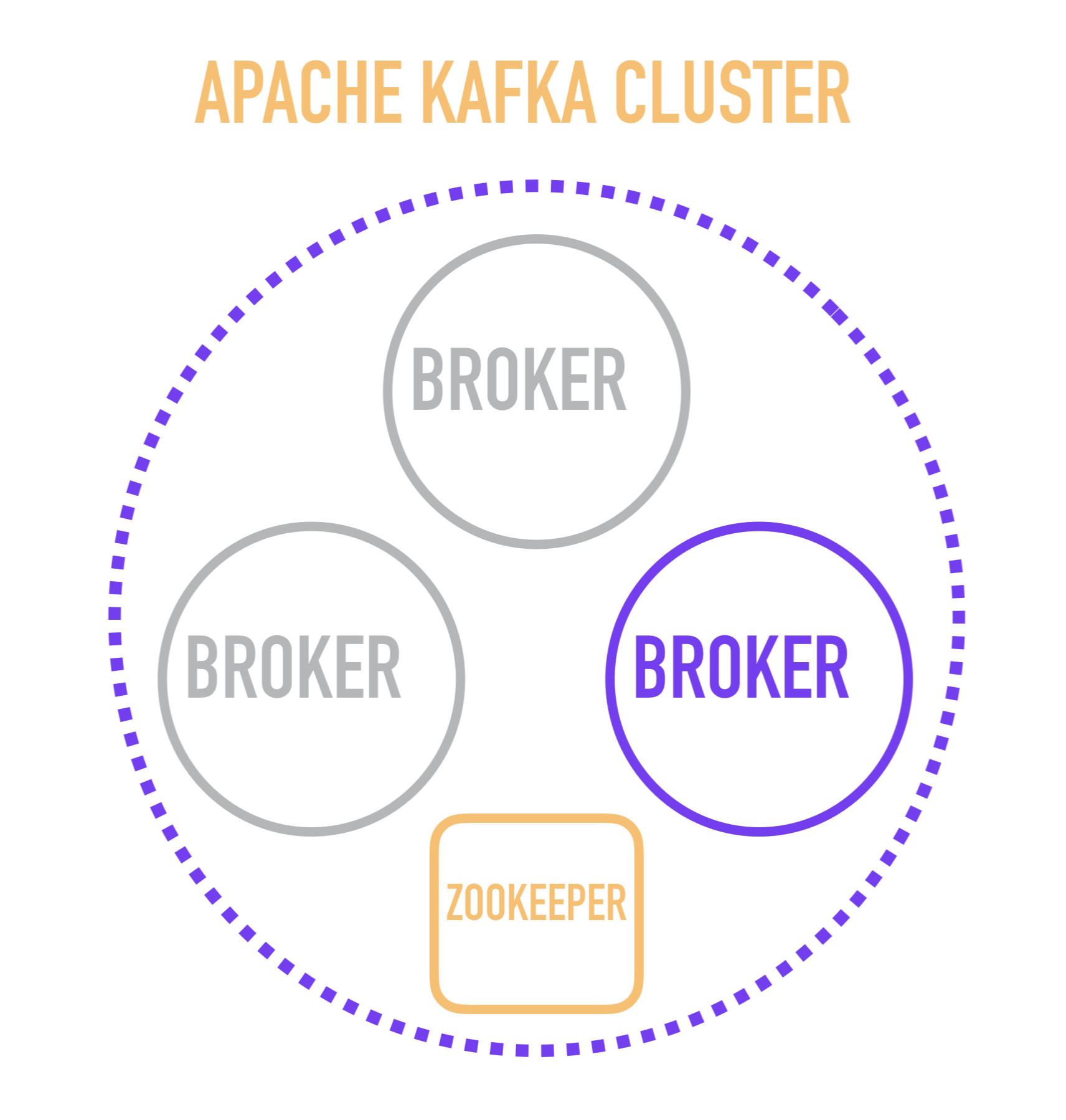
Отдельный сервер Кафки именуется брокером. Брокеры образуют собой кластер, в котором один из этих брокеров выступает контроллером, берущим на себя некоторые административные операции (помечен фиолетовым).
За выбор брокера-контроллера, в свою очередь, отвечает отдельный сервис – ZooKeeper, который также осуществляет service discovery брокеров, хранит конфигурации и принимает участие в распределении новых читателей по брокерам и в большинстве случаев хранит информацию о последнем прочитанном сообщении для каждого из читателей. Это важный момент, изучение которого требует опуститься на уровень ниже и рассмотреть, как отдельный брокер устроен внутри.
Структура данных, лежащая в основе Kafka, называется commit log или журнал фиксации изменений.

Новые элементы, добавляемые в commit log, помещаются строго в конец, и их порядок после этого не меняется, благодаря чему в каждом отдельном журнале элементы всегда расположены в порядке их добавления.
Свойство упорядоченности журнала фиксаций позволяет использовать его, например, для репликации по принципу eventual consistency между репликами БД: в них хранят журнал изменений, производимых над данными в мастер-ноде, последовательное применение которых на слейв-нодах позволяет привести данные в них к согласованному с мастером виду.
В Кафке эти журналы называются партициями, а данные, хранимые в них, называются сообщениями.
Что такое сообщение? Это основная единица данных в Kafka, представляющая из себя просто набор байт, в котором вы можете передавать произвольную информацию – ее содержимое и структура не имеют значения для Kafka. Сообщение может содержать в себе ключ, так же представляющий из себя набор байт. Ключ позволяет получить больше контроля над механизмом распределения сообщений по партициям.
Почему это может быть важно? Дело в том, что партиция не является аналогом очереди в Кафке, как может показаться на первый взгляд. Я напомню, что формально очередь сообщений – это средство для группирования и управления потоками сообщений, позволяющее определенным читателям подписываться только на определенные потоки данных.
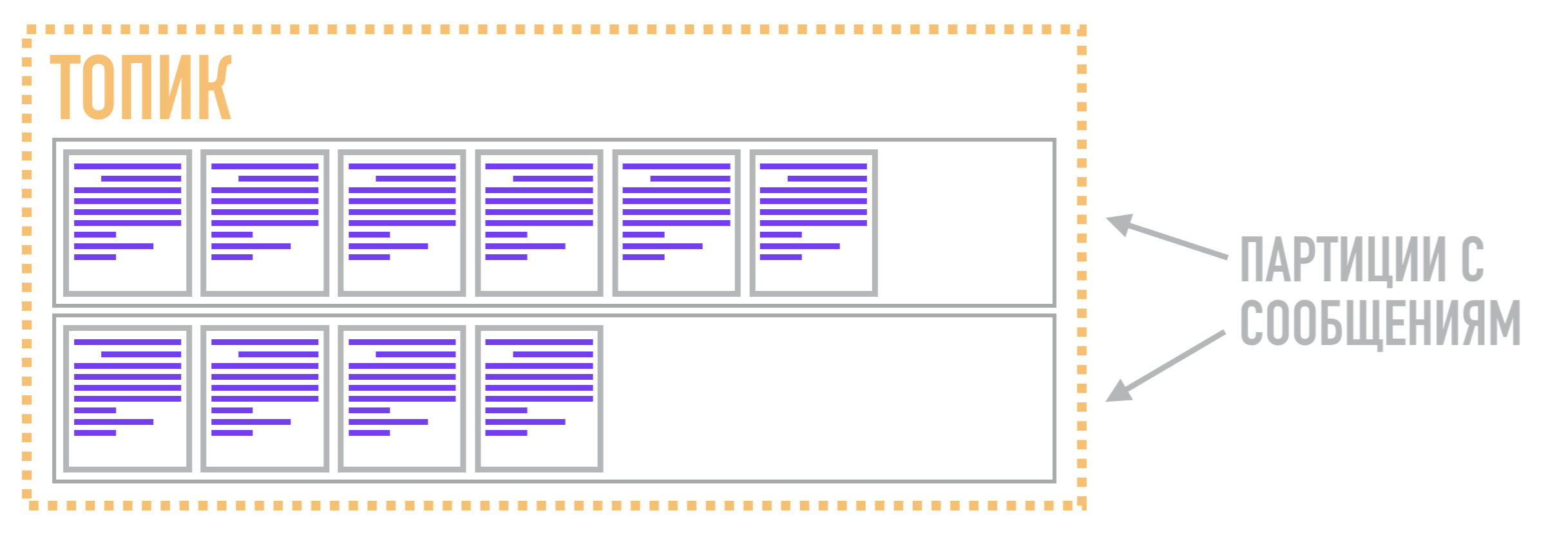
Так вот в Кафке функцию очереди выполняет не партиция, а topic. Он нужен для объединения нескольких партиций в общий поток. Сами же партиции, как мы сказали ранее, хранят сообщения в упорядоченном виде согласно структуре данных commit log. Таким образом, сообщение, относящееся к одному топику, может хранится в двух разных партициях, из которых читатели могут вытаскивать их по запросу.
Следовательно, единицей параллелизма в Кафке выступает не топик (или очередь в AMQP брокерах), а партиция. За счет этого Кафка может обрабатывать разные сообщения, относящиеся к одному топику, на нескольких брокерах одновременно, а также реплицировать не весь топик целиком, а только отдельные партиции, предоставляя дополнительную гибкость и возможности для масштабирования в сравнении с AMQP брокерами.
Обратите внимание, что я не случайно использовал слово “вытаскивает” по отношению к читателю.
В описанных ранее брокерах доставка сообщений осуществляется путем их проталкивания (push) получателям через условную трубу в виде очереди.
В Кафке процесса доставки как такового нет: каждый читатель сам ответственен за вытягивание (pull) сообщений из партиций, которые он читает.
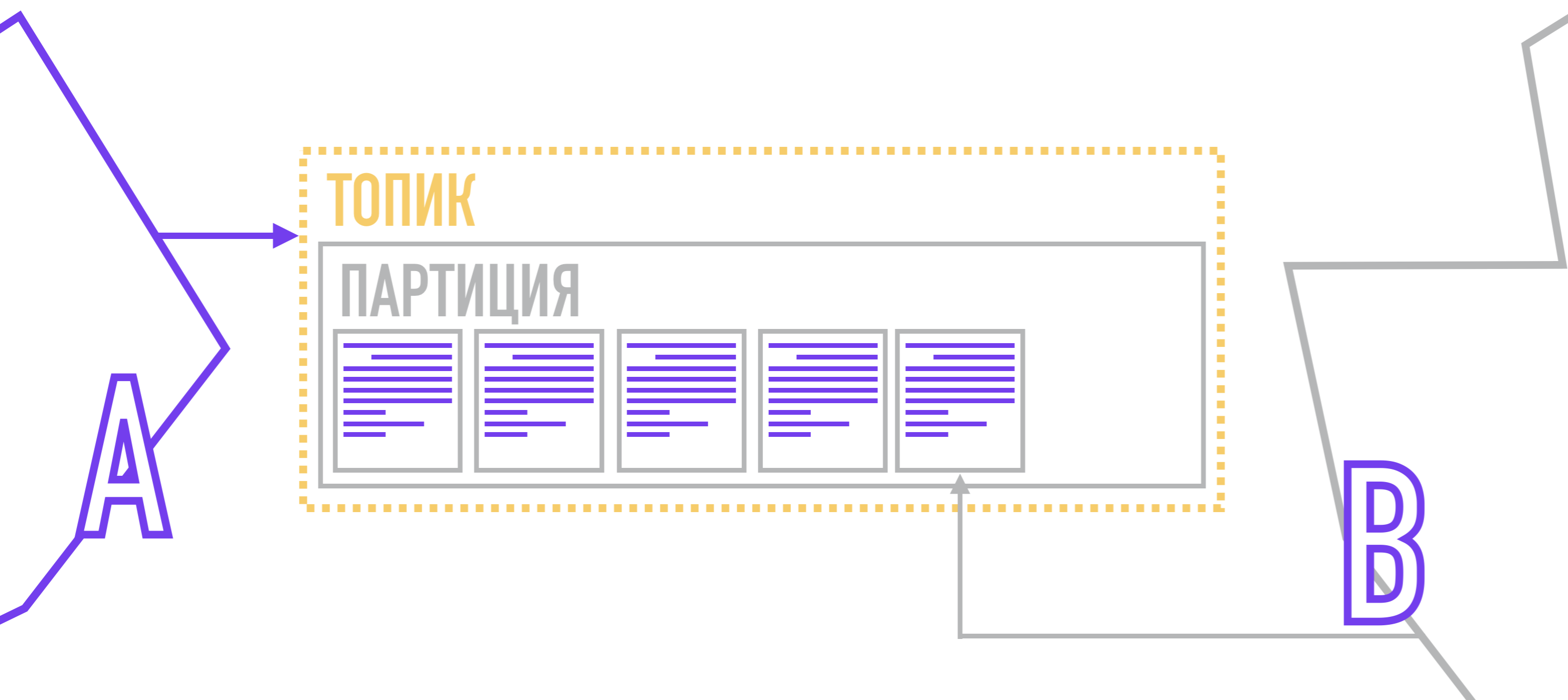
Производители, формируя сообщения, прикрепляют к нему ключ и номер партиции. Номер партиции может быть выбран рандомно (round-robin), если у сообщения отсутствует ключ.
Если вам нужен больший контроль, к сообщению можно прикрепить ключ, а затем использовать hash-функцию или написать свой алгоритм, по которому будет выбираться партиция для сообщения. После формирования, производитель отправляет сообщение в Кафку, которая сохраняет его на диск, помечая, к какой партиции оно относится.
Каждый получатель закреплен за определенной партицией (или за несколькими партициями) в интересующем его топике, и при появлении нового сообщения получает сигнал на вычитывание следующего элемента в commit log, при этом отмечая, какое последнее сообщение он прочитал. Таким образом при переподключении он будет знать, какое сообщение ему вычитать следующим.
К недостаткам данного подхода можно отнести работу с проблемными сообщениями. В отличие от классических брокеров, битые сообщения (которые не удается обработать с учетом существующей логики получателя или из-за проблем с десериализацей) нельзя бесконечно перезакидывать в очередь, пока получатель не научится их корректно обрабатывать.
В Кафке по умолчанию вычитывание сообщений из партиции останавливается, когда получатель доходит до битого сообщения, и до тех пор, пока оно не будет пропущено и закинуто в “карантинную” очередь (также именуемой “dead letter queue”) для последующей обработки, чтение партиции продолжить не получится.
Также в Кафке сложнее (в сравнении с AMQP-брокерами) реализовать приоритет сообщений. Это напрямую вытекает из того факта, что сообщения в партициях хранятся и читаются строго в порядке их добавления. Один из способов обойти данное ограничение в Кафке – создать нескольких топиков под сообщения с разным приоритетом (отличаться топики будут только названием), например, events_low, events_medium, events_high, а затем реализовать логику приоритетного чтения перечисленных топиков на стороне приложения-консьюмера.
Еще один недостаток данного подхода связан тем, что необходимо вести учет последнего прочитанного сообщения в партиции каждым из читателей. В силу простоты структуры партиций, эта информация представлена в виде целочисленного значения, именуемого offset (смещение). Оффсет позволяет определить, какое сообщение в данный момент читает каждый из читателей. Ближайшая аналогия оффсета — это индекс элемента в массиве, а процесс чтения похож на проход по массиву в цикле с использованием итератора в качестве индекса элемента.
Однако этот недостаток нивелируется за счет того, что Kafka, начиная с версии 0.9, хранит оффсеты по каждому пользователю в специальном топике __consumer_offsets (до версии 0.9 оффсеты хранились в ZooKeeper).
К тому же, вести учет оффсетов можно непосредственно на стороне получателей.

Также усложняется и масштабирование: напомню, что в AMQP брокерах для того, чтобы ускорить обработку потока сообщений, нужно просто добавить несколько экземпляров сервиса-читателя и подписать их на одну очередь, при этом не требуется вносить никаких изменений в конфигурации самого брокера.
Однако в Кафке масштабирование происходит несколько сложнее, чем в AMQP брокерах. Например, если вы добавите еще один экземпляр читателя и натравите его на ту же партицию, вы получите нулевой КПД, так как в этом случае оба экземпляра будут читать один и тот же набор данных.
Поэтому базовое правило масштабирования Кафки — количество конкурентных читателей (то бишь группа сервисов, реализующих одинаковую логику обработки (реплик)) топика не должно превышать количество партиций в этом топике, иначе какая-то пара читателей будут обрабатывать одинаковый набор данных.
Чтобы избежать ситуации с чтением одной партиции конкурентными читателями, в Кафке принято объединять несколько реплик одного сервиса в consumer Group, в рамках которого Zookeeper будет назначать одной партиции не более одного читателя.
Так как читатели привязываются непосредственно к партиции (при этом читатель обычно ничего не знает о количестве партиций в топике), ZooKeeper при подключении нового читателя производит перераспределение участников в Consumer Group таким образом, чтобы каждая партиция имела одного и только одного читателя.
Читатель обозначает свою Consumer Group при подключении к Kafka.
В то же время ничего не мешает вам повесить на одну партицию несколько читателей с разной логикой обработки. Например вы храните в топике список событий по действиям пользователей и хотите использовать эти события для формирования нескольких представлений одних и тех же данных (например для бизнес-аналитиков, продуктовых-аналитиков, системных-аналитиков и пакета Яровой) и последующей отправкой их в соответствующие хранилища.
Но здесь мы можем столкнуться с другой проблемой, порожденной тем, что Кафка использует структуру из топиков и партиций. Я напомню, что Кафка не гарантирует упорядоченность сообщений в рамках топика, только в рамках партиции, что может оказаться критичным, например, при формировании отчетов о действиях по пользователю и отправке их в хранилище as is.
Чтобы решить эту проблему, мы можем пойти от обратного: если все события, относящиеся к одной сущности (например, все действия относящиеся к одному user_id), будут всегда добавляться в одну и ту же партицию, они будут упорядочены в рамках топика просто потому, что находятся в одной партиции, порядок внутри которой гарантирован Кафкой.
Для этого нам и нужен ключ у сообщений: например, если мы будем использовать для выбора партиции, в которую будет добавлено сообщение, алгоритм, вычисляющий хэш от ключа, то сообщения с одинаковым ключом будут гарантированно попадать в одну партицию, а значит и вытаскивать получатель сообщения с одинаковым ключом в порядке их добавления в топик.
В кейсе с потоком событий о действиях пользователей ключом партицирования может выступать user_id.
Теперь пришло время поговорить о Retention Policy.
Это настройка, которая отвечает за удаление сообщений с диска при превышении пороговых значений даты добавления (Time Based Retention Policy) или занимаемого на диске пространства (Size Based Retention Policy).
Retention Policy можно настроить как для всего кластера, так и для отдельных топиков: например, сообщения в топике для отслеживания деи?ствии? пользователеи? можно хранить несколько днеи?, в то время как пуши – в течении нескольких часов. Удаляя данные согласно их актуальности, мы экономим место не диске, что может быть важно при выборе SSD в качестве основного дискового хранилища.
Еще одним способом оптимизации объема, занимаемого на диске, может быть использование Compaction Policy – эта настройка позволяет хранить только последнее сообщение по каждому ключу, удаляя все предыдущие сообщения. Это может быть полезно, когда нас интересует только последнее изменение.
Привет! Меня зовут Дмитрий Шеламов и я работаю в Vivid.Money на должности backend-разработчика в отделе Customer Care. Наша компания – европейский стартап, который создает и развивает сервис интернет-банкинга для стран Европы. Это амбициозная задача, а значит и ее техническая реализация требует продуманной инфраструктуры, способной выдерживать высокие нагрузки и масштабироваться согласно требованиям бизнеса.
В основе проекта лежит микросервисная архитектура, которая включает в себя десятки сервисов на разных языках. В их числе Scala, Java, Kotlin, Python и Go. На последнем я пишу код, поэтому практические примеры, приведенные в этой серии статей, будут задействовать по большей части Go (и немного docker-compose).
Работа с микросервисами имеет свои особенности, одна из которых – организация коммуникаций между сервисами. Модель взаимодействия в этих коммуникациях бывает синхронной или асинхронной и может оказать существенное влияние на производительность и отказоустойчивость системы в целом.
Асинхронное взаимодействие
Итак, представим что у нас есть два микросервиса (А и Б). Будем считать, что коммуникация между ними осуществляется через API и они ничего не знают о внутренней реализации друг друга, как и предписывает микросервисный подход. Формат передаваемых между ними данных заранее оговорен.
Задача перед нами стоит следующая: нам нужно организовать передачу данных от одного приложения к другому и, желательно, с минимальными задержками.
В самом простом случае поставленная задача достигается синхронным взаимодействием, когда А отправляет приложению Б запрос, после чего сервис Б его обрабатывает и, в зависимости от того, успешно или не успешно был обработан запрос, отправляет некоторый ответ сервису А, который этот ответ ожидает.
Если же ответ на запрос так и не был получен (например, Б рвет соединение до отправки ответа или А отваливается по таймауту), сервис А может повторить свой запрос к Б.
С одной стороны, такая модель взаимодействия дает определенность статуса доставки данных для каждого запроса, когда отправитель точно знает, были ли получены данные получателем и какие дальнейшие действия ему необходимо делать в зависимости от ответа.
С другой стороны, плата за это – ожидание. После отправки запроса сервис А (или поток, в котором выполняется запрос) блокируется до того момента, пока не получит ответ или не сочтет запрос неудавшимся согласно своей внутренней логике, после чего примет дальнейшие действия.
Проблема не только в том, что ожидание и простой имеют место быть, – задержки в сетевом взаимодействии неизбежны. Основная проблема заключается в непредсказуемости этой задержки. Участники коммуникации в микросервисном подходе не знают подробностей реализации друг друга, поэтому для запрашивающей стороны не всегда очевидно, обрабатывается ли ее запрос штатно или нужно переотправить данные.
Все, что остается А при такой модели взаимодействия – это просто ждать. Может быть наносекунду, а может быть час. И эта цифра вполне реальна в том случае, если Б в процессе обработки данных выполняет какие-либо тяжеловесные операции, вроде обработки видео.
Возможно, вам проблема не показалась существенной – одна железка ждет пока другая ответит, велика ли потеря?
Чтобы сделать эту проблему более личной, представим, что сервис А – это приложение, запущенное на вашем телефоне, и пока оно ожидает ответ от Б, вы видите на экране анимацию загрузки. Вы не можете продолжить пользоваться приложением до тех пор, пока сервис Б не ответит, и вынуждены ждать. Неизвестное количество времени. При том, что ваше время гораздо ценнее, чем время работы куска кода.
Подобные шероховатости решаются следующим образом – вы разделяете участников взаимодействия на два “лагеря”: одни не могут работать быстрее, как бы вы их ни оптимизировали (обработка видео), а другие не могут ждать дольше определенного времени (интерфейс приложения на вашем телефоне).
Затем вы заменяете cинхронное взаимодействие между ними (когда одна часть вынуждена ждать другую, чтобы удостовериться, что данные были доставлены и обработаны сервисом-получателем) на асинхронное, то есть модель работы по принципу отправил и забыл – в этом случае сервис А продолжит свою работу, не дожидаясь ответа от Б.
Но как в этом случае гарантировать то, что передача прошла успешно? Вы же не можете, допустим, загрузив видео на видеохостинг, вывести пользователю сообщение: «ваше видео может быть обрабатывается, а может быть и нет», потому что сервис, занимающийся загрузкой видео, не получил от сервиса-обработчика подтверждение, что видео дошло до него без происшествий.
В качестве одного из решений данной проблемы мы можем добавить между сервисами А и Б прослойку, которая будет выступать временным хранилищем и гарантом доставки данных в удобном для отправителя и получателя темпе. Таким образом мы сможем расцепить сервисы, синхронное взаимодействие которых потенциально может быть проблемным:
- Данные, которые теряются при аварийном завершении сервиса-получателя теперь могут быть снова получены из промежуточного хранилища, в то время как сервис-отправитель продолжает выполнять свою работу. Таким образом мы получаем механизм гарантии доставки;
- Эта прослойка также защищает получателей от скачков нагрузки, ведь получателю выдаются данные по мере их обработки, а не по мере их поступления;
- Запросы на выполнение тяжеловесных операций (таких как рендеринг видео) теперь могут быть переданы через эту прослойку, обеспечивая меньшую связность между быстрыми и медленными частями приложения.
Под вышеобозначенные требования вполне подходит и обычная СУБД. Данные в ней можно хранить в течении продолжительного времени, не беспокоясь о потере информации. Также исключена и перегрузка получателей, ведь они вольны сами выбрать темп и объемы чтения предназначенных для них записей. Подтверждение же обработки можно реализовать, помечая прочитанные записи в соответствующих таблицах.
Однако выбор СУБД в качестве инструмента для обмена данными может привести к проблемам с производительностью с ростом нагрузки. Причина в том, что большинство баз данных не предназначены для такого сценария использования. Также во многих СУБД отсутствует возможность разделения подключенных клиентов на получателей и отправителей (Pub/Sub) – в этом случае, логика доставки данных должна быть реализована на клиентской стороне.
Вероятно, нам нужно нечто более узкоспециализированное, чем база данных.
Брокеры сообщений
Брокер сообщений (очередь сообщений) – это отдельный сервис, который отвечает за хранение и доставку данных от сервисов-отправителей к сервисам-получателям с помощью модели Pub/Sub.
Эта модель предполагает, что асинхронное взаимодействие осуществляется согласно следующей логике двух ролей:
- Publishers публикуют новую информацию в виде сгруппированных по некоторому атрибуту сообщений;
- Subscribers подписываются на потоки сообщений с определенными атрибутами и обрабатывают их.
Группирующим сообщения аттрибутом выступает очередь, которая нужна, чтобы разделять потоки данных, – таким образом, получатели могут подписываться только на те группы сообщений, которые их интересуют.
По аналогии с подписками на различных контент-платформах – подписавшись на определенного автора, вы можете фильтровать контент, выбирая смотреть только тот, который вам интересен.
Очередь можно представить как канал связи, натянутый между писателем и читателем. Писатели кладут сообщения в очередь, после чего они “проталкиваются” (push) читателям, которые подписаны на эту очередь. Один читатель получает одно сообщение за раз, после чего оно становится недоступно другим читателям.
Под сообщением же подразумевается единица данных, обычно состоящая из тела сообщения и метаданных брокера.
В общем случае, тело представляет из себя набор байт определенного формата.
Получатель обязательно должен знать этот формат, чтобы после получения сообщения иметь возможность десериализовать его тело для дальнейшей обработки.
Использовать можно любой удобный формат, однако, важно помнить об обратной совместимости, которую поддерживают, например, бинарный Protobuf и фреймворк Apache Avro.
По такому принципу работает большинство брокеров сообщений, построенных на AMQP (Advanced Message Queuing Protocol) – протоколе, который описывает стандарт отказоустойчивого обмена сообщениями посредством очередей.
Данный подход обеспечивает нам несколько важных преимуществ:
- Слабая связанность. Она достигается за счет асинхронной передачи сообщений: то есть, отправитель скидывает данные и продолжает работать, не дожидаясь ответа от получателя, а получатель вычитывает и обрабатывает сообщения, когда удобно ему, а не когда они были отправлены. В данном случае очередь можно сравнить с почтовым ящиком, в который почтальон кладет ваши письма, а вы их забираете, когда удобно вам.
- Масштабируемость. Если сообщения появляются в очереди быстрее, чем консьюмер успевает их обрабатывать (речь идет не о пиковых нагрузках, а о стабильном разрыве между скоростью записи и обработки), мы можем запустить несколько экземпляров приложения-консьюмера и подписать их на одну очередь.
Этот подход называется горизонтальным масштабированием, а экземпляры одного сервиса принято называть репликами. Реплики сервиса-консьюмера будут читать сообщения из одной очереди и обрабатывать их независимо друг от друга. - Эластичность. Наличие между приложениями такой прослойки, как очередь, помогает справляться с пиковыми нагрузками: в этом случае очередь будет выступать буфером, в котором сообщения будут копиться и по мере возможности считываться консьюмером, вместо того, чтобы ронять приложение-получатель, отправляя данные ему напрямую.
- Гарантии доставки. Большинство брокеров предоставляют гарантии “at least once” и “at most once”.
At most once исключает повторную обработку сообщений, однако допускает их потерю. В этом случае брокер будет доставлять сообщения получателям по принципу “отправил и забыл”. Если получатель не смог по какой-то причине обработать сообщение с первой попытки, брокер не будет осуществлять переотправку.
At least once, напротив, гарантирует получение сообщения получателем, однако при этом есть вероятность повторной обработки одних и тех же сообщений.
Зачастую эта гарантия достигается с помощью механизма Ack/Nack (acknowledgement/negative acknowledgement), который предписывает совершать переотправку сообщения, если получатель по какой-то причине не смог его обработать.
Таким образом, для каждого отправленного брокером (но еще не обработанного) сообщения существует три итоговых состояния — получатель вернул Ack (успешная обработка), вернул Nack (неуспешная обработка) или разорвал соединение. Последние два сценария приводят в переотправке сообщения и повторной обработке.
Однако брокер может произвести повторную отправку и при успешной обработке сообщения получателем. Например, если получатель обработал сообщение, но завершил свою работу, не отправив сигнал Ack брокеру.
В этом случае брокер снова положит сообщение в очередь, после чего оно будет обработано повторно, что может привести к ошибкам и порче данных, если разработчик не предусмотрел механизм устранения дублей на стороне получателя.
Стоит отметить, что существует еще одна гарантия доставки, которая называется “exactly once”. Ее трудно достичь в распределенных системах, но при этом она же является наиболее желаемой.
В этом плане, Apache Kafka, о которой мы будем говорить далее, выгодно выделяется на фоне многих доступных на рынке решений. Начиная с версии 0.11, Kafka предоставляет гарантию доставки exactly once в пределах кластера и транзакций, в то время как AMQP-брокеры таких гарантий предоставить не могут. Транзакции в Кафке – тема для отдельной публикации, сегодня же мы начнем со знакомства с Apache Kafka.
Apache Kafka
Мне кажется, что будет полезно для понимания начать рассказ о Кафке со схематичного изображения устройства кластера.
Отдельный сервер Кафки именуется брокером. Брокеры образуют собой кластер, в котором один из этих брокеров выступает контроллером, берущим на себя некоторые административные операции (помечен фиолетовым).
За выбор брокера-контроллера, в свою очередь, отвечает отдельный сервис – ZooKeeper, который также осуществляет service discovery брокеров, хранит конфигурации и принимает участие в распределении новых читателей по брокерам и в большинстве случаев хранит информацию о последнем прочитанном сообщении для каждого из читателей. Это важный момент, изучение которого требует опуститься на уровень ниже и рассмотреть, как отдельный брокер устроен внутри.
Commit log
Структура данных, лежащая в основе Kafka, называется commit log или журнал фиксации изменений.
Новые элементы, добавляемые в commit log, помещаются строго в конец, и их порядок после этого не меняется, благодаря чему в каждом отдельном журнале элементы всегда расположены в порядке их добавления.
Свойство упорядоченности журнала фиксаций позволяет использовать его, например, для репликации по принципу eventual consistency между репликами БД: в них хранят журнал изменений, производимых над данными в мастер-ноде, последовательное применение которых на слейв-нодах позволяет привести данные в них к согласованному с мастером виду.
В Кафке эти журналы называются партициями, а данные, хранимые в них, называются сообщениями.
Что такое сообщение? Это основная единица данных в Kafka, представляющая из себя просто набор байт, в котором вы можете передавать произвольную информацию – ее содержимое и структура не имеют значения для Kafka. Сообщение может содержать в себе ключ, так же представляющий из себя набор байт. Ключ позволяет получить больше контроля над механизмом распределения сообщений по партициям.
Партиции и топики
Почему это может быть важно? Дело в том, что партиция не является аналогом очереди в Кафке, как может показаться на первый взгляд. Я напомню, что формально очередь сообщений – это средство для группирования и управления потоками сообщений, позволяющее определенным читателям подписываться только на определенные потоки данных.
Так вот в Кафке функцию очереди выполняет не партиция, а topic. Он нужен для объединения нескольких партиций в общий поток. Сами же партиции, как мы сказали ранее, хранят сообщения в упорядоченном виде согласно структуре данных commit log. Таким образом, сообщение, относящееся к одному топику, может хранится в двух разных партициях, из которых читатели могут вытаскивать их по запросу.
Следовательно, единицей параллелизма в Кафке выступает не топик (или очередь в AMQP брокерах), а партиция. За счет этого Кафка может обрабатывать разные сообщения, относящиеся к одному топику, на нескольких брокерах одновременно, а также реплицировать не весь топик целиком, а только отдельные партиции, предоставляя дополнительную гибкость и возможности для масштабирования в сравнении с AMQP брокерами.
Pull и Push
Обратите внимание, что я не случайно использовал слово “вытаскивает” по отношению к читателю.
В описанных ранее брокерах доставка сообщений осуществляется путем их проталкивания (push) получателям через условную трубу в виде очереди.
В Кафке процесса доставки как такового нет: каждый читатель сам ответственен за вытягивание (pull) сообщений из партиций, которые он читает.
Производители, формируя сообщения, прикрепляют к нему ключ и номер партиции. Номер партиции может быть выбран рандомно (round-robin), если у сообщения отсутствует ключ.
Если вам нужен больший контроль, к сообщению можно прикрепить ключ, а затем использовать hash-функцию или написать свой алгоритм, по которому будет выбираться партиция для сообщения. После формирования, производитель отправляет сообщение в Кафку, которая сохраняет его на диск, помечая, к какой партиции оно относится.
Каждый получатель закреплен за определенной партицией (или за несколькими партициями) в интересующем его топике, и при появлении нового сообщения получает сигнал на вычитывание следующего элемента в commit log, при этом отмечая, какое последнее сообщение он прочитал. Таким образом при переподключении он будет знать, какое сообщение ему вычитать следующим.
Какие преимущества имеет данный подход?
- Персистентность. В классических брокерах сообщение хранится в памяти брокера ровно до того момента, как брокер получит сигнал об успешной обработке сообщения читателем, который это сообщение вытащил из очереди. В Кафке же сообщения хранятся столько, сколько нужно (в зависимости от Retention Policy, об этом позднее), а значит из одной партиции одновременно могут читать сообщения несколько получателей.
- Message Replay. Читатели могут перечитывать сообщения сколько угодно раз, начиная с произвольного места в партиции. Это может быть полезно, например, для восстановления данных на стороне читателя при потере части изменений в БД.
- Упорядоченность. Она гарантируется в том числе потому, что нет механизма переотправки (в силу ненадобности) – в обычных брокерах в процессе доставки переотправлямые сообщения постоянно перетасовываются в очереди, так как они закидываются в нее снова после каждой неудачной попытки их обработать.
- Чтение и запись пачками. Читатель может читать сообщения пачками (batch) из одной партиции, а не по отдельности, как это происходит с обычными брокерами. Это бывает полезно для уменьшения сетевой задержки: при передаче большого количества сообщений (1кк и выше), гонять по сети каждое сообщение отдельно становится дорого.
Недостатки
К недостаткам данного подхода можно отнести работу с проблемными сообщениями. В отличие от классических брокеров, битые сообщения (которые не удается обработать с учетом существующей логики получателя или из-за проблем с десериализацей) нельзя бесконечно перезакидывать в очередь, пока получатель не научится их корректно обрабатывать.
В Кафке по умолчанию вычитывание сообщений из партиции останавливается, когда получатель доходит до битого сообщения, и до тех пор, пока оно не будет пропущено и закинуто в “карантинную” очередь (также именуемой “dead letter queue”) для последующей обработки, чтение партиции продолжить не получится.
Также в Кафке сложнее (в сравнении с AMQP-брокерами) реализовать приоритет сообщений. Это напрямую вытекает из того факта, что сообщения в партициях хранятся и читаются строго в порядке их добавления. Один из способов обойти данное ограничение в Кафке – создать нескольких топиков под сообщения с разным приоритетом (отличаться топики будут только названием), например, events_low, events_medium, events_high, а затем реализовать логику приоритетного чтения перечисленных топиков на стороне приложения-консьюмера.
Еще один недостаток данного подхода связан тем, что необходимо вести учет последнего прочитанного сообщения в партиции каждым из читателей. В силу простоты структуры партиций, эта информация представлена в виде целочисленного значения, именуемого offset (смещение). Оффсет позволяет определить, какое сообщение в данный момент читает каждый из читателей. Ближайшая аналогия оффсета — это индекс элемента в массиве, а процесс чтения похож на проход по массиву в цикле с использованием итератора в качестве индекса элемента.
Однако этот недостаток нивелируется за счет того, что Kafka, начиная с версии 0.9, хранит оффсеты по каждому пользователю в специальном топике __consumer_offsets (до версии 0.9 оффсеты хранились в ZooKeeper).
К тому же, вести учет оффсетов можно непосредственно на стороне получателей.
Также усложняется и масштабирование: напомню, что в AMQP брокерах для того, чтобы ускорить обработку потока сообщений, нужно просто добавить несколько экземпляров сервиса-читателя и подписать их на одну очередь, при этом не требуется вносить никаких изменений в конфигурации самого брокера.
Однако в Кафке масштабирование происходит несколько сложнее, чем в AMQP брокерах. Например, если вы добавите еще один экземпляр читателя и натравите его на ту же партицию, вы получите нулевой КПД, так как в этом случае оба экземпляра будут читать один и тот же набор данных.
Поэтому базовое правило масштабирования Кафки — количество конкурентных читателей (то бишь группа сервисов, реализующих одинаковую логику обработки (реплик)) топика не должно превышать количество партиций в этом топике, иначе какая-то пара читателей будут обрабатывать одинаковый набор данных.
Consumer Group
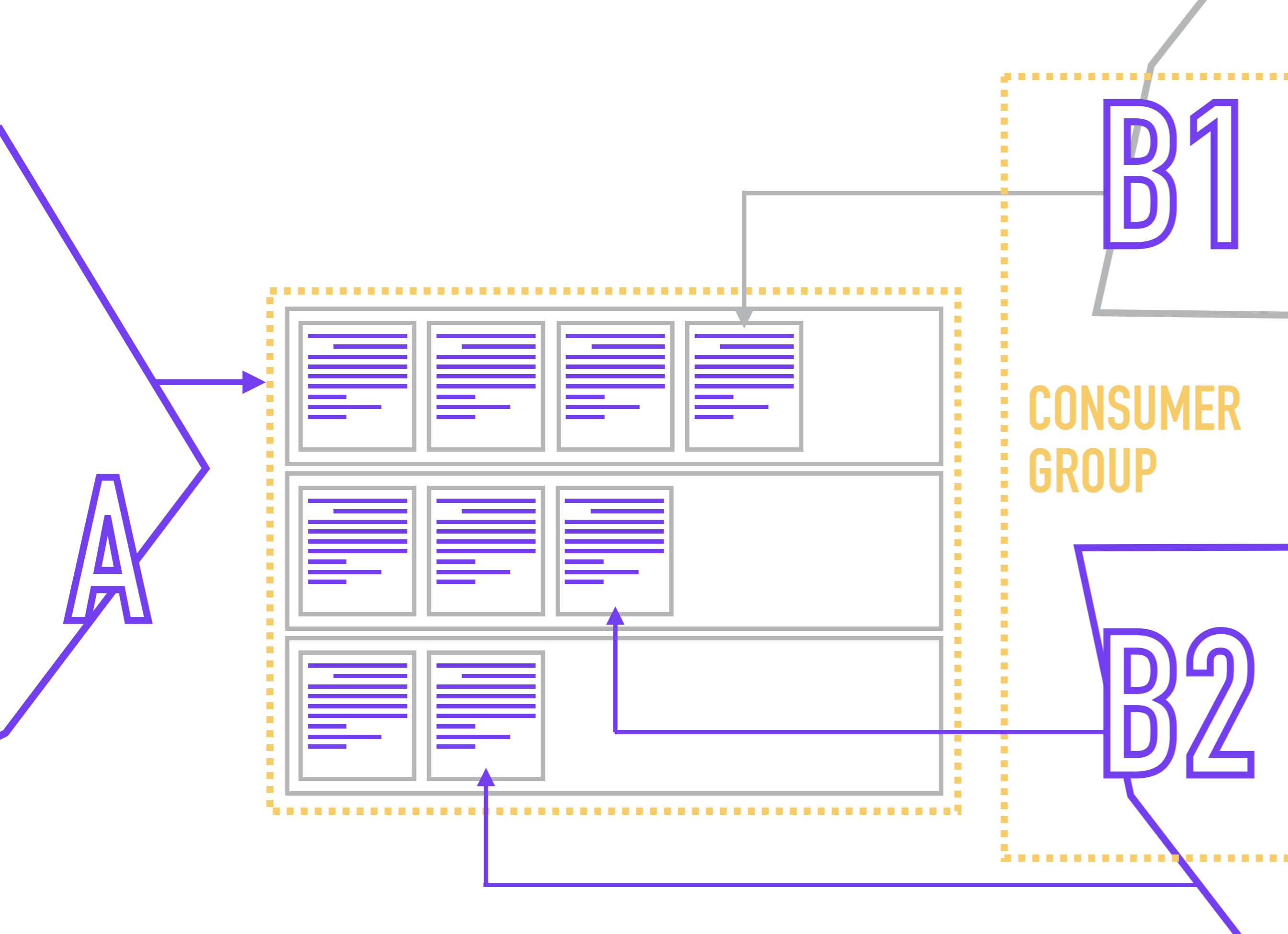
Чтобы избежать ситуации с чтением одной партиции конкурентными читателями, в Кафке принято объединять несколько реплик одного сервиса в consumer Group, в рамках которого Zookeeper будет назначать одной партиции не более одного читателя.
Так как читатели привязываются непосредственно к партиции (при этом читатель обычно ничего не знает о количестве партиций в топике), ZooKeeper при подключении нового читателя производит перераспределение участников в Consumer Group таким образом, чтобы каждая партиция имела одного и только одного читателя.
Читатель обозначает свою Consumer Group при подключении к Kafka.
В то же время ничего не мешает вам повесить на одну партицию несколько читателей с разной логикой обработки. Например вы храните в топике список событий по действиям пользователей и хотите использовать эти события для формирования нескольких представлений одних и тех же данных (например для бизнес-аналитиков, продуктовых-аналитиков, системных-аналитиков и пакета Яровой) и последующей отправкой их в соответствующие хранилища.
Но здесь мы можем столкнуться с другой проблемой, порожденной тем, что Кафка использует структуру из топиков и партиций. Я напомню, что Кафка не гарантирует упорядоченность сообщений в рамках топика, только в рамках партиции, что может оказаться критичным, например, при формировании отчетов о действиях по пользователю и отправке их в хранилище as is.
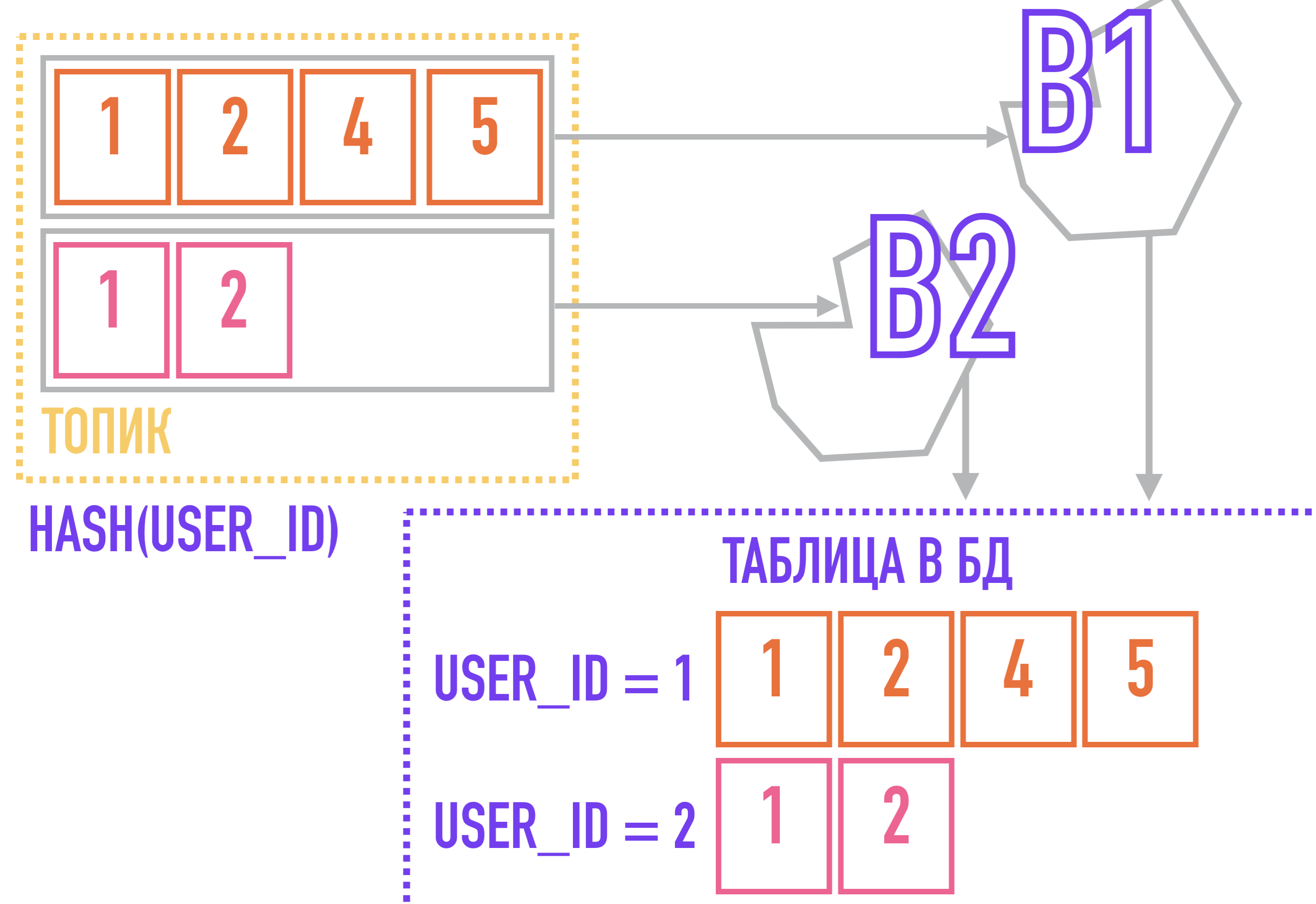
Чтобы решить эту проблему, мы можем пойти от обратного: если все события, относящиеся к одной сущности (например, все действия относящиеся к одному user_id), будут всегда добавляться в одну и ту же партицию, они будут упорядочены в рамках топика просто потому, что находятся в одной партиции, порядок внутри которой гарантирован Кафкой.
Для этого нам и нужен ключ у сообщений: например, если мы будем использовать для выбора партиции, в которую будет добавлено сообщение, алгоритм, вычисляющий хэш от ключа, то сообщения с одинаковым ключом будут гарантированно попадать в одну партицию, а значит и вытаскивать получатель сообщения с одинаковым ключом в порядке их добавления в топик.
В кейсе с потоком событий о действиях пользователей ключом партицирования может выступать user_id.
Retention Policy
Теперь пришло время поговорить о Retention Policy.
Это настройка, которая отвечает за удаление сообщений с диска при превышении пороговых значений даты добавления (Time Based Retention Policy) или занимаемого на диске пространства (Size Based Retention Policy).
- Если вы настроите TBRP на 7 суток, то все сообщения старше 7 суток будут помечаться для последующего удаления. Иными словами, эта настройка гарантирует, что в каждый момент времени будут доступны для чтения сообщения младше порогового “возраста”. Можно задавать в часах, минутах и милисекундах.
- SBRP работает аналогичным образом: при превышении порога занимаемого дискового пространства, сообщения будут помечаться для удаления с конца (более старые). Нужно иметь в виду: так как удаление сообщений происходит не мгновенно, занимаемый объем диска всегда будет чуть больше указанного в настройке. Задается в байтах.
Retention Policy можно настроить как для всего кластера, так и для отдельных топиков: например, сообщения в топике для отслеживания деи?ствии? пользователеи? можно хранить несколько днеи?, в то время как пуши – в течении нескольких часов. Удаляя данные согласно их актуальности, мы экономим место не диске, что может быть важно при выборе SSD в качестве основного дискового хранилища.
Compaction Policy
Еще одним способом оптимизации объема, занимаемого на диске, может быть использование Compaction Policy – эта настройка позволяет хранить только последнее сообщение по каждому ключу, удаляя все предыдущие сообщения. Это может быть полезно, когда нас интересует только последнее изменение.
Сценарии использования Kafka
- Отслеживание действий пользователей на клиентской части. При этом логгируемая информация может быть самой разной: от списка просмотренных страниц до щелчков мыши. Сообщения о действиях публикуются в один или несколько топиков, где потребителем может выступать, например, хранилище аналитических данных (Clickhouse можно подписать непосредственно на топик Кафки!) для дальнейшего построения отчетов или рекомендательных систем. ?
В Customer Care отделе Vivid.Money мы используем топик Кафки для доставки в аналитическое хранилище логов о действиях операторов в нашей CRM. - Обмен сообщениями. Кафка может выступать этаким единым интерфейсом для отправки различных уведомлений, пушей или электронных писем во всем проекте. Любой сервис может подключиться к Кафке и отправить сообщение в определенный топик для уведомлений, из которого на той стороне сервис-консьюмер (имеющий доступ к контактной информации клиентов) его считает, преобразует в формат пригодный для отправки нотификации непосредственно клиенту, и осуществит фактическую отправку.
Благодаря этому мы можем отправить пуш буквально из любой части нашей инфраструктуры, без необходимости получения контактных данных пользователя (и его предпочтений по способу связи) в инициирующем отправку нотификации сервисе. В свою свою очередь, успешно получив сообщение, Кафка гарантирует то, что оно будет доставлено клиенту, даже если на стороне сервиса нотификаций возникли неполадки. - Мониторинг. Через топики кафки можно организовать сбор и агрегацию логов и метрик для их централизованной обработки, используя ее как транспорт.
- Журнал фиксации (commit log). Можно дублировать в топик транзакции БД, чтобы сервисы-потребители синхронизировали состояние связанных данных уже в своих базах/сторонних системах.
Опять же, долгосрочное хранение сообщений позволяет выступать Кафке этаким буфером для изменений, который позволяет «переиграть» изменения из топика Кафки для приведения данных на стороне получателя к согласованному виду в случае сбоев приложений получателей или повреждению данных в их БД.
По такому принципу у нас в Customer Care организована синхронизация данных профиля клиента в используемых нами CRM-системах с изменениями данных пользователей в наших внутренних базах.
Подытожим основные преимущества Kafka
- В один топик может писать один или несколько производителей – идеально для агрегирования данных из большого количества источников, что становится особенно полезно при использовании Кафки в качестве системы доставки сообщений в микросервисной архитектуре;
- Несколько потребителей – с учетом особенностей механизма получения сообщений (pull) один и тот же поток сообщений может читать несколько потребителей, не мешая при этом друг другу. ?При этом конкурентных читателей (например, реплики одного сервиса) можно объединить в Consumer Group, а ZooKeeper, в свою очередь, будет следить, чтобы каждая партиция одновременно читалась не более, чем одним участником каждой группы;
- Хранение данных на диске в течение длительного времени позволяет не беспокоится о потере данных при резком росте нагрузки. Кафка, будучи своего рода буфером, компенсирует отставание потребителей, позволяя накапливать в себе сообщения до нормализации нагрузки или масштабирования консьюмеров. Также обеспечивается гибкая конфигурация, где отдельные потоки данных (топики) хранятся на диске с разным сроком;
- Хорошо масштабируется, засчет меньшей, в сравнении с AMQP брокерами, единицей параллелизма – партицией. Разные партиции могут храниться в разных брокерах, обеспечивая дополнительную гибкость при горизонтальном масштабировании;
- Быстродействие. В силу простоты механизма, при которой процесса доставки нет как такового, а процесс передачи данных представляет из себя запись-хранение-выдача, Кафка обладает очень большой пропускной способностью – она исчисляется миллионами сообщений в секунду.

devopg
хорошобы такую статью про ksql server, т.к. там вообще ничего не понятно как всё это дело горизонтально масштабируется…
так же при множества ksql server (горизонтальное масштабирование) не ясно как что работает при JOIN допустим стримов если ksql на разных машинах…
в общем масса вопросов как N-KSQL проецируются на 1 или N kafka (кластер)