
Тысячам разработчиков в Яндексе каждый день нужно решать и выполнять множество самых разных задач: от простых скриптов, запускаемых по расписанию, до сложных релизных пайплайнов. Как построить эффективную систему выполнения задач общего назначения? Как сделать ее отказоустойчивой и масштабируемой одновременно? Как подружить в одном кластере гетерогенное железо и различные операционные системы? Как управлять тысячами серверов и не сойти с ума в процессе разработки и эксплуатации такой огромной системы? На все перечисленные вопросы я ответил в докладе на первой DevTools Party. Это новая серия митапов: будем выступать сами и приглашать экспертов из других компаний, чтобы обмениваться мнениями в сложной теме — инфраструктуре разработки.
— Всем привет, меня зовут Костя Кардаманов, я работаю в отделе технологий разработки Яндекса. Расскажу, как устроен наш гетерогенный кластер выполнения задач общего назначения. Прежде чем рассказывать о самом кластере, хочу рассказать об основных сервисах и инструментах, которые у нас есть.

Думаю, многие узнали, что за сцена изображена на фото. Конечно, это «Сотворение Адама» Микеланджело. Сами мы не боги, многие из нас даже не ангелы, но наша основная задача в том, чтобы оберегать, защищать и всячески помогать нашим разработчикам в их нелегком ежедневном труде по разработке ПО. Чтобы это делать, мы сделали множество разных сервисов и инструментов. В первую очередь, конечно, это монорепозиторий, где хранится код всех основных программных продуктов Яндекса. Объем монорепозитория — порядка шести терабайт, в него вносится порядка семи тысяч изменений каждый день.
Чтобы исходный код, который хранится в монорепозитории, можно было легко собирать и тестировать, у нас есть собственная система сборки. Ее основное отличие в том, что она двухстадийная — сначала строим сборочный граф, затем исполняем его.
Чтобы автоматизировать процессы, которые работают поверх монорепозитория и системы сборки, у нас есть собственная система CI/CD. Она, кроме автоматизации, также может переваривать весь огромный объем информации, который производится в процессе сборок.
Кроме этого, у нас есть автотесты, которые выполняются в прекоммитных проверках. Чтобы минимизировать время выполнения этих проверок, есть кластер распределенной сборки. Для выполнения всех остальных задач, связанных с производством, разработкой, сопровождением, эксплуатацией программных продуктов, есть кластер распределенной очереди задач общего назначения, о котором я сегодня вам расскажу.

Итак, небольшая статистическая справка. Сам проект появился в 2008 году как один из сервисов большого поиска. Здесь на скриншоте даже видно первый коммит в этот проект — полтора десятка Python файлов, здесь даже виден SQL-скрипт с основными сущностями, которые есть в нашем проекте, это задачи и ресурсы.
Сейчас, почти через 15 лет, это один из крупнейших Python-проектов в Яндексе, так как и он сам реализован на Python, и задачи, которые в нем запускаются, тоже в основном написаны на Python.
В самом кластере порядка 200 тысяч вычислительных ядер и почти петабайт оперативной памяти. Суммарное дисковое пространство в кластере — порядка полусотни петабайт. Каждый день в кластере выполняется порядка миллиона задач, которые порождают более двух миллионов ресурсов.
Сам кластер обладает очень высокими характеристиками надежности и отказоустойчивости, расположен в пяти дата-центрах. Его состояние сохраняется в централизованной СУБД, ее объем — порядка полтерабайта, в базе хранится примерно 400 миллионов различных объектов. Сама база шардирована на 20 шардов, для каждого шарда есть примерно пять реплик — это 100 реплик на базу.

Итак, прежде, чем начать рассказ об устройстве сервиса, надо определиться с основными терминами и сущностями, которыми он оперирует. Начнем с функций. Как я говорил, его основная функция — это сборка и тестирование, и важным кейсом использования кластера является оркестрация внешних систем, таких как управление определенными задачами, сборка логов, аналитика и так далее.
Например, CI-система, которая у нас есть, не имеет собственного рантайма. В качестве рантайма она использует кластер Sandbox. Точно так же поступают многие другие системы автоматизации, которые связаны с разработкой кода.
Одно из основных свойств системы — запуск по событиям, происходящим внутри и снаружи системы. Внешнее событие — это обычно обращение по API или иное событие, доставленное по событийной шине. Внутри это триггеры, которые обрабатывают связи задач. Есть и простейшие триггеры, например наступление некоторого момента времени.
Пример. У вас есть некоторая задача, цель которой — собирать статистику из вашей bug tracking-системы, формировать HTML-отчет и отправлять его по почте, например, себе же. Вы можете взять ваш любимый язык, написать код, пообщаться с трекером через его API, сформировать отчет и прислать его себе.
Но теперь вам надо это делать раз в час. Вы можете взять Cron-службу на вашем ноутбуке, зарегистрировать скрипт в ней и отчет будет исправно приходить каждый час, пока вы не закроете крышку, не выдернете шнур питания. В этот момент всё закончится.
Давайте разместим ваш скрипт на сервере в дата-центре. Наверное, это будет не самое эффективное использование вычислительных ресурсов, учитывая, что скрипт работает, допустим, 10 минут раз в час. Зато это будет значительно более надежное решение — пока рядом с дата-центром не решат построить новый микрорайон и бульдозер, который будет копать траншею, не порвет оптоволоконный кабель. Тогда скрипт снова не сможет отправить вам отчет.
Эта система легко решает подобный класс задач, буквально в пару кликов вы можете зарегистрировать запуск вашего скрипта по расписанию, и он будет запускаться вплоть до тепловой смерти вселенной.
Еще одно важное свойство системы — наличие стандартных решений. Так как ей пользуются многие команды разработки в Яндексе, скорее всего, когда вы решите написать свой собственный сценарий, окажется, что другая команда такой сценарий или такую задачу уже решала, и вам достаточно использовать их работу. Определить те параметры, которые вам требуются, и запустить эту работу для себя.
Сервис предоставляет гетерогенность, то есть он предоставляет все необходимые операционные системы, виды оборудования, чтобы можно было полноценно разрабатывать и выполнять программный код для любых сервисов, которые работают в компании. Это generic runtime, то есть запуск задач у нас в кластере — это способ взять небольшое количество вычислительных ресурсов в краткосрочную аренду.
Основные термины, которые мы будем использовать в нашем разговоре, — это, конечно, задачи. Задача — корневая сущность, которая и определяет, что будет выполняться на вычислительных ресурсах, которые вы получили в использование.
Задачи сами по себе параметризованные, ограниченные во времени, и их параметры разделяются на два больших класса:
Системные параметры определяют вид вычислительных ресурсов, которые вам требуются.
Пользовательские подразделяются на два подкласса: входные параметры требуются для запуска задачи; выходные могут быть вычислены задачей в процессе ее работы.
Параметры типизированы, то есть это простые типы, строки, числа, простейшие структуры. Есть важный тип параметров — ресурсы. Ресурс для задачи представляется в виде файла на диске, но с точки зрения системы ресурс — это некоторый набор метаданных, определяемых пользователем для их поиска и агрегации.
Важное свойство ресурсов: они неизменяемые. То есть некоторые данные, которые были задекларированы как ресурс, не могут быть изменены. Это одно из свойств, определяющих политику повторяемости в нашем кластере. Таким образом вместе с эталонным окружением, которое предоставляется для запуска задач, кластер гарантирует, что на результат выполнения данной конкретной задачи не повлияют никакие результаты задач, которые выполняются параллельно на этом сервере, выполнялись до или будут выполняться после. Вы можете взять копию задачи, которую запускали, например, год назад, перезапустить ее и получить точно такой же результат.
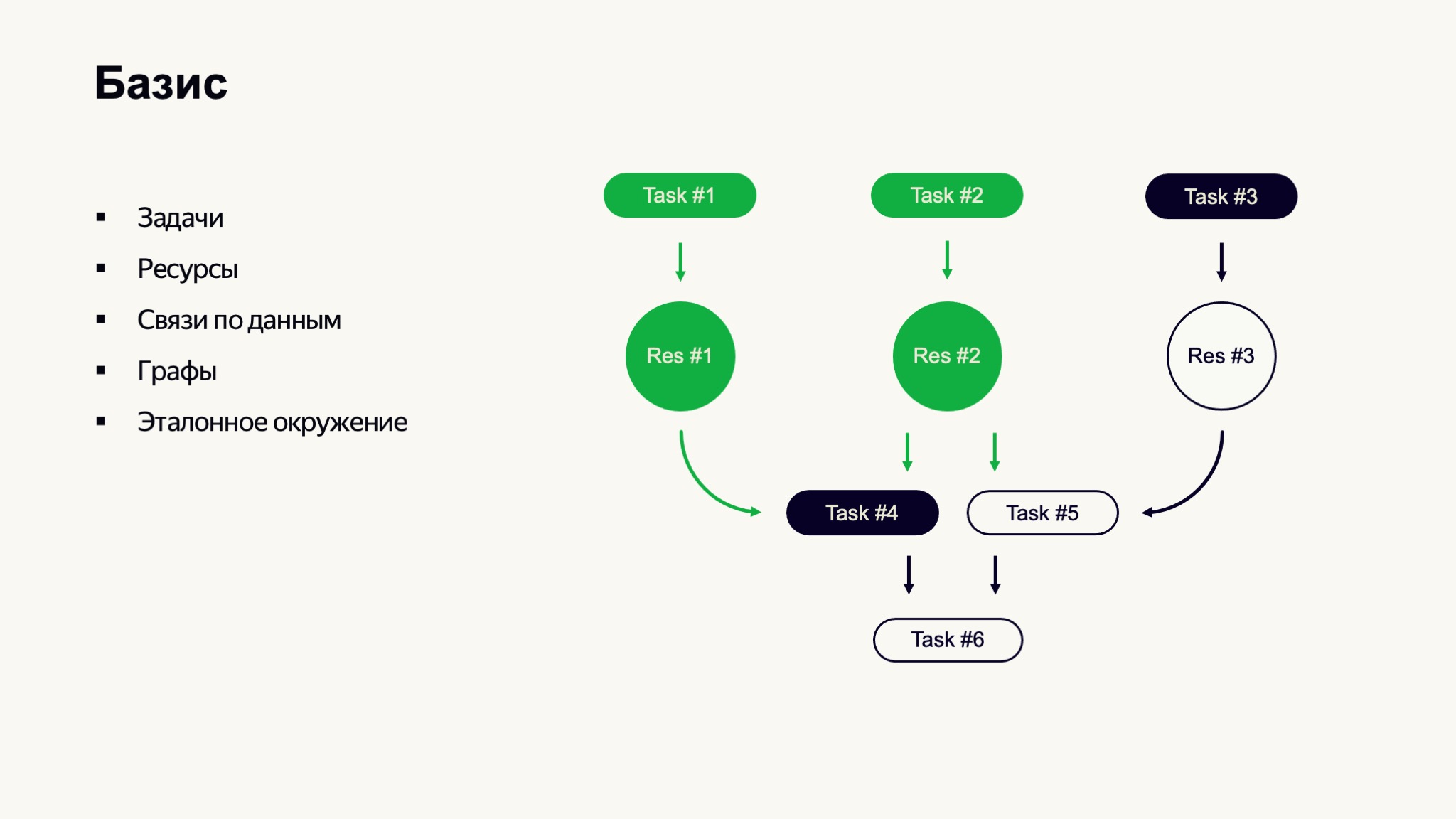
Задачи могут образовывать большие графы и пайплайны вычислений. На схеме я нарисовал простейший пайплайн, где задачи №1 и №2 уже завершились, подготовили данные, которые должны были подготовить, — они отмечены зеленым. Задача №3 еще выполняется, и данные еще не готовы. Так как данные для задачи №4 уже готовы, мы можем ее запустить, а задачи №5 и №6 ожидают в очереди своего выполнения.

Определившись с основными сущностями и понятиями, мы можем перейти к тому, как наш сервис устроен.
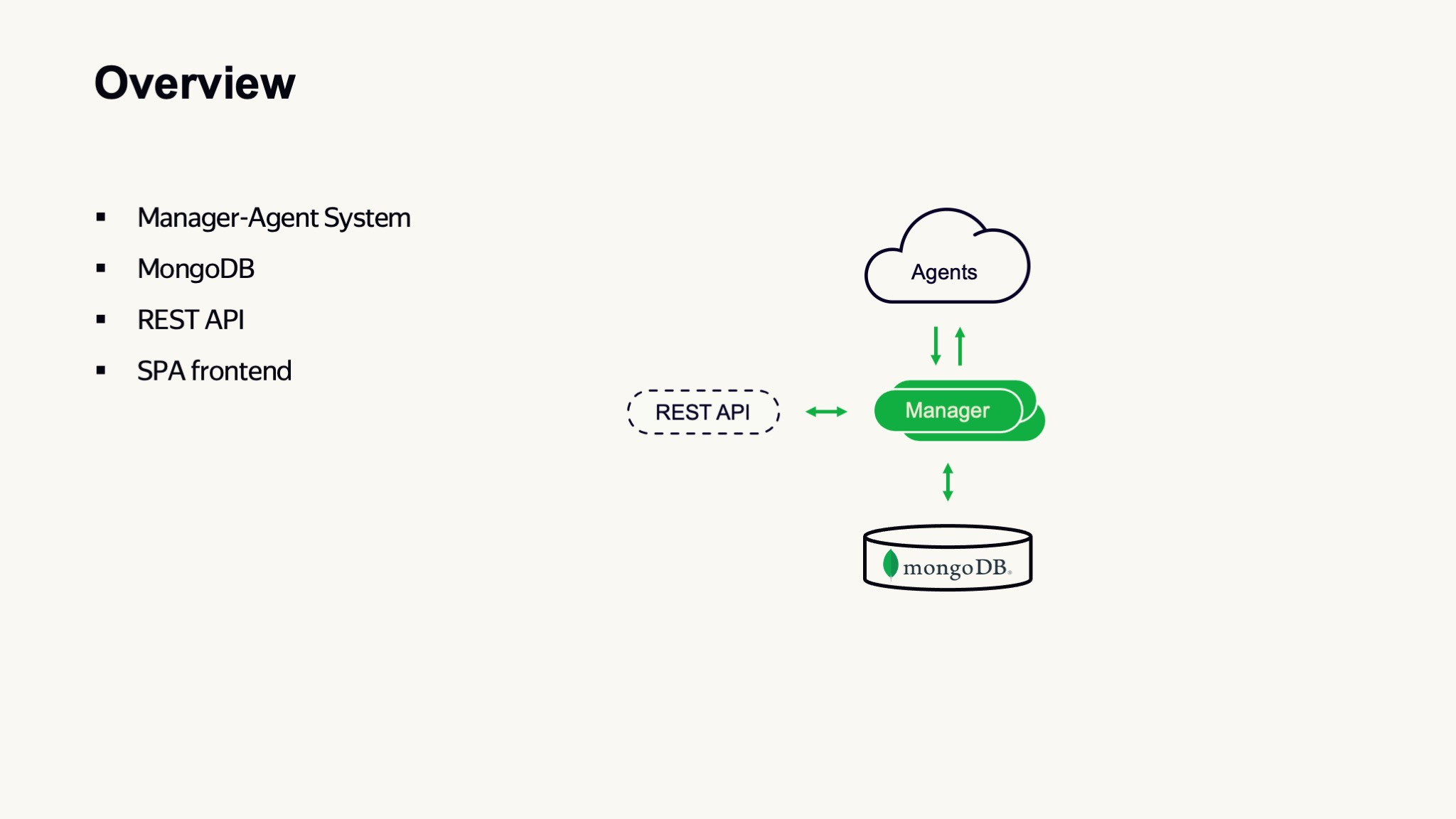
Если посмотреть на сервис с высоты полета МКС, то, наверное, можно сказать, что он устроен относительно просто — это классическая менеджер-агентская система, где есть небольшое количество управляющих серверов, а основные вычислительные мощности распределены среди агентов, которые предоставляют их выполняющимся задачам.
Здесь сразу можно заметить, что наша база данных — это MongoDB. Для взаимодействия с внешним миром и с другими системами мы используем REST API. Также мы используем RESAT API для взаимодействия между агентами и управляющими системами.
Наш фронтенд написан в виде single page application и исполняется полностью в браузере. С таким уровнем детализации можно сказать: ну автомобиль как автомобиль — четыре колеса, руль, ничего особенного. Поэтому нам надо взять виртуальный микроскоп и попробовать увеличить, например, один из наших управляющих серверов.

Как устроено ПО на наших управляющих серверах? В первую очередь — слой операционной системы, который предоставляет нам базовые интерфейсы, взаимодействие с оборудованием, с внешним миром. Вместе с ОС поставляется стандартный набор типовых пакетов для упрощения взаимодействия с ней.
На каждом сервере устанавливается целый набор инфраструктурных микросервисов, которые помогают вливать каждый сервер в нашу общую инфраструктуру. Это системы сбора логов, мониторингов, аналитики работоспособности сервера, различные транспортные агенты — всё, что нам помогает выстраивать общую инфраструктуру из этих серверов.
На базе ОС и инфраструктурных сервисов мы запускаем систему деплоя. Особенность нашей системы деплоя: все сервера с одинаковой ролью будут налиты идентично. Это важное свойство управления больших систем. Поскольку сервера налиты идентично и на них работает один и тот же набор процессов, а файлы на дисках тоже расположены одинаково, то если есть проблема, которая диагностируется на одном из серверов, скорее всего, точно такая же проблема будет и на другом сервере. Иначе это очень странная проблема, которую надо сразу бежать исследовать.
Система деплоя запускает наборы процессов, которые в Linux называются демонами. Здесь можно перечислять их слева направо. Первый блок, микросервисы, обеспечивают нормальное функционирование кластера как системы, выполняющей функции для пользователя.
Например, вспомним историю про сron-скрипт, который вы зарегистрировали в системе, чтобы он выполнялся по расписанию. У нас есть микросервис, который обрабатывает события таймера — при наступлении определенного времени инициирует создание новой задачи.
Есть микросервисы, распределяющие ресурсный кэш между машинами, которые занимаются сборкой мусора и так далее, их порядка 25.
Следующий большой блок — serverless processor, предназначенный для выполнения пользовательского кода до момента постановки задачи в очередь. Самый простой пример такой: у вас есть задача, собирающая некоторый бинарный файл, и у нее есть один параметр, который определяет, для какой ОС вы собираете этот бинарный файл. Если пользователь задал Windows, то перед постановкой в очередь для определения требований к агентам, на которых задача хочет выполниться, она может выполнить некоторый код. Этот код доопределит системные требования к задаче и укажет: «Я хочу выполняться только на Windows, пожалуйста, не пускайте меня на Linux».
Как я уже говорил, все состояние нашей системы хранится в распределенной СУБД. Здесь же на управляющих серверах находятся шарды нашей БД и установлен Zookeeper, который используется для распределенных блокировок. Так как управляющих серверов у нас больше одного, а точнее 15, важно, чтобы сервисы, способные дублировать свою работу, этим не занимались.
Например, если вы будете запускать микросервис, который делает задачи по расписанию на всех 15 серверах одновременно, а система деплоя именно это и обеспечивает, то вы каждый час будете получать 15 запусков вашего скрипта, 15 писем на почту. Это спам.
Чтобы такого не происходило, есть средство глобальной блокировки: один из инстансов захватывает блокировку, работает как primary-инстанс, остальные работают в режиме hot stand by, готовые продолжить работу в случае проблем с основным инстансом, восстановив свое состояние из СУБД.
Для работы с внешним миром есть API-сервер. Он написан на базе uWSGI и Flask, обрабатывает достаточно высокие нагрузки, порядка трех тысяч запросов в секунду. Разработка управляющих серверов, наверное, похожа на классическую веб-разработку с элементами экстрима. Если у вас есть возможность получить race condition или deadlock, вы обязательно его получите: если какой-то worker сейчас обрабатывает запрос, то где-то на другом сервере есть другой worker, который обрабатывает точно такой же запрос. Race conditions обязательно вылезут.
Здесь есть важный сервис, он называется диспетчер очереди, про него я поговорю чуть позже.

Агенты с точки зрения системы деплоя устроены примерно таким же образом, как управляющие сервера. Возможно, на них меньше микросервисов. Есть агент, который получает задание от управляющих серверов, есть агенты, которые занимаются управлением ресурсными кэшами, и другие вспомогательные сервисы.
Сами по себе агенты кроссплатформенные, умеют работать в Linux, Windows и Mac. Они также являются частью огромного распределенного ресурсного кэша системы. Если задаче требуются файлы, ресурсы для выполнения, задача агента — предоставить их, то есть до запуска системы они автоматически появятся в файловой системе и будут доступны задаче.
Чтобы эффективно использовать вычислительные ресурсы кластера, мы активно применяем виртуализацию. В случае Linux это, конечно, Linux Containers. Распределяем задачи так, чтобы один сервер мог выполнять множество задач.
Если разработка предыдущих типов серверов была больше похожа на веб-разработку, то здесь, конечно, системное программирование в полный рост. То есть здесь идет активная работа с интерфейсами системы, нужно понимать, чем отличаются разные операционные системы, как работает виртуализация, что такое виртуальные сети, как работает изоляция ресурсов — системное программирование как оно есть.

Итак, что же такое наш загадочный диспетчер очереди? Это сердце кластера, он обеспечивает две основные характеристики — с одной стороны, максимизирует утилизацию ресурсов в кластере, с другой, обеспечивает счастье пользователя. Счастье пользователя в нашей системе заключается в том, что те задачи, которые он запускает в кластере, выполняются за минимальное время на максимально доступных ресурсах.
Диспетчер очереди — это in-memory СУБД, построенная по классической схеме single primary — hot stand by. Stand by-реплики принимают изменения через operation log (oplog) от primary, он же выполняет операции записи и чтения, критичные к целостности. Secondary могут выполнять операции, не критичные к целостности.
В самом диспетчере очереди хранится состояние всех задач, которые сейчас ожидают исполнения, и их приоритетов, всех наших агентов, информация о доступности вычислительных ресурсов на них, о дисковом пространстве и так далее. Также диспетчер очереди владеет виртуальным ресурсами.
Есть виртуальный ресурс под названием «семафор». Как я говорил, частый паттерн использования нашего кластера — это оркестрация внешних процессов, например того же MapReduce. Уже не раз бывало так, что не каждый сервис мог выдержать нагрузку, которая подается из нашего кластера, и иногда это приводило к не очень веселым последствиям. Поэтому для контроля объема нагрузки на внешнюю систему используется виртуальный ресурс — семафор.
Каждая задача запускается в рамках некоторой вычислительной квоты, которая распределяется между командами. Эти квоты учитываются в процессе назначения задач на агентов и их исполнения.
С точки зрения дискретной математики диспетчер очереди решает задачу конвейерной оптимизации, это NP-полная задача. Если мы возьмем все варианты всех объектов и пересечем их, то получим порядка 10 квадриллионов вариантов, которые нам необходимо перебирать примерно 10 раз в секунду, чтобы эффективно назначить задачу на очередной слот исполнения на агенте.
Конечно, это огромный объем информации, на который потребуется огромное количество ресурсов, поэтому мы активно занимаемся различными оптимизациями. В этом месте используем кластеризацию данных, сводим задачу к тому, чтобы она могла быть выполнена одним сервером.

О квотах можно поговорить чуть подробнее. Конечно, мы любим всех наших разработчиков, и поэтому любой разработчик может прийти на наш кластер, поставить задачу исполняться, и она будет выполнена без каких-либо задержек. Это называется квота по умолчанию, которая есть у любой команды.
Кроме этого, если вернуться к примеру запуска сron-скрипта, вам, конечно, не надо будет заказывать какие-либо ресурсы сейчас, предварительно или потом, когда вы начали уже использовать. Кластер предоставит вам эти ресурсы и так. Но если у вас есть сложные процессы, которые требуют большого количества вычислительных мощностей, то, конечно, кластер не сможет вам эти ресурсы предоставить — как минимум, сразу же гарантировать. Поэтому вам потребуется предварительно составить заявку на дополнительные вычислительные ресурсы. С одной стороны, все разработчики равны, с другой, с точки зрения диспетчера очереди некоторые из них все-таки ровнее.
Важным свойством нашей системы квотирования является интегральное потребление. С точки зрения системы некоторый скрипт, которому требуется 10 минут времени и 10 вычислительных ядер — это все-таки значительно меньшее потребление, чем другой процесс, которые требует те же самые 10 ядер, но при этом ему нужна постоянная гарантия их наличия в кластере для выполнения некоторого пайплайна.
К примеру, когда мы обсуждали CI, то говорили о системе автоматической проверки и автосборки. Для данного процесса важно, чтобы результаты автоматической сборки доставлялись разработчику как можно быстрее. Поэтому такие процессы работают в режиме, близкому к realtime.
Противоположный пример — конвертация видео. Когда появляется новый сезон сериала, может потребоваться конвертировать его в различные форматы, оптимизированные для передачи через интернет. Такой сервис может создать большое количество задач, которые будут выполняться очень медленно, так как им гарантировано достаточно низкое количество ресурсов. Но, используя переподписку, они могут выполняться на мощностях кластера, которые простаивают и не используются другими компонентами.
Так что даже если у вашего проекта закончилась квота, скорее всего, за счет переподписки вы все равно будете получать вычислительные ресурсы для ваших задач.

Чтобы понимать, как работает наша система, хорошо ей или плохо, есть подсистема сбора данных. Это достаточно общий механизм, любой компонент системы в любой точке кластера на любом сервере может генерировать некоторые события, информационные сигналы, которые мы пересылаем через общую шину данных в единое хранилище СУБД ClickHouse.
Мы все эти сигналы собираем, причем сигналы самые разнообразные: запустилась где-то задача, остановилась, сгенерировалось исключение, мы потребовали файл из ресурсного кэша, нашли его или не нашли, обратились в API — все это события, которые через эту шину данных записываются в БД.
Всего таких событий происходит порядка 10 тысяч каждую секунду, и среди такого объема информации — даже на этом слайде — иногда можно увидеть, что что-то нашлось. В основном мы находим полезные сигналы, которые позволяют нам понимать, нормально ли функционирует кластер. Эта же подсистема позволяет нам контролировать процесс обновления. Как вы понимаете, пять тысяч серверов невозможно обновить по щелчку пальцев. Скорее всего, это никогда так не происходит, есть сервера, которые по каким-то причинам отстают — возможно, с ними плохая связь или требуется дополнительное вмешательство.
Мы никогда не выкатываем новую функциональность на все наши агенты, мы выкатываем на некоторую часть, дальше через нашу подсистему сбора данных и мониторинга определяем, что все работает штатно, что задачи пользователя ни в коем случае не пострадали из-за наших изменений. После этого можем продолжать обновление кластера.
Здесь, наверное, можно закончить рассказ об устройстве самого сервиса и перейти к обсуждению, как мы его разрабатываем. Можно подумать, что сам сервис разрабатывается как минимум полусотней разработчиков, а еще у нас есть армия системных администраторов, которые обслуживают наш огромный кластер. Это не совсем так.

Наша команда состоит из пяти разработчиков и одного прекрасного продакт-менеджера, в команде нет ни одного системного администратора. Чтобы достигать высоких результатов, работоспособности такой большой системы, конечно, мы активно используем дружбу с разнообразными роботами.
Мы переиспользуем технологии, которые родились в других отделах, экспертизу, которая там применяется для автоматизации процессов управления оборудованием, операционными системами и так далее. Предположим, на одном из серверов произошла проблема — он недоступен по SSH. Никто не идет разбираться с ним, в этот момент срабатывает автоматика, сервер автоматически переналивается. Если с ним по-прежнему проблема, он отправляется в автоматическую диагностику, если после диагностики выявлены проблемы — отправляется заявка, инженер в дата-центре вынимает его из стойки, ставит на его место новый. И всё, кластер работает по-прежнему.
Сам кластер достаточно устойчив к отказам, он обеспечивает перезапуск тех задач, которые произошли на отказавшем оборудовании. Он устойчив и к падению целых сегментов, таких как дата-центр.
Чтобы такую систему можно было разрабатывать силами относительно небольшой команды, конечно, требуется широкий кругозор: нужно разбираться во всех областях, которые я перечислял ранее. Но невозможно быть экспертом в каждой области, если у вас нет двух-трех голов и восьми пар рук. У нас замечательные разработчики, но они не мутанты. Поэтому мы активно используем специализацию, в каждой из областей у нас есть специалист, который может гарантировать, что решение в этой области будет написано эффективно. Наверное, это всё, что я хотел вам рассказать.
sse
Не замеряли качество своего шедулинга задач: насколько эффективно используется оборудование, может, целевая метрика есть какая-то? У Ali cloud есть интересные статьи про их системы планирования пакетных заданий
kardamanov Автор
Как я говорил в презентации, планировщик (диспетчер очереди), решает две основные задачи: максимизация утилизации оборудования и минимизация времени простоя задач в очереди. На синтетических тестах с условно бесконечным свободным местом на дисках он показывает очень высокий уровень утилизации агентов, в production-системе есть дополнительный фактор вытеснения ресурсов из кэша агента и освобождении дискового пространства — настройками агента можно регулировать скорость вытеснения — в таком случае утилизация кластера повышается, но понижается cache hit. Сейчас это статически настроенный параметр по результатам моделирования; есть идея добавить учет фактора голодания пользовательского пула из-за недостатка агентов с достаточным свободным местом для выполнения задач непосредственно в планировщик, но в целом по предварительным оценкам такая оптимизация значительно снижает время ожидания менее 1% задач.