
 Привет, меня зовут Костя Кардаманов, я работаю в отделе технологий разработки Яндекса. Обычно такой же фразой я приветствую и кандидатов на собеседовании. А сегодня я хотел бы рассказать вам, как и зачем мы проводим интервью по дизайну систем с бэкенд-разработчиками. Сразу скажу: для фронтендеров, мобильных разработчиков и ML-инженеров подобный тип собеседований применим слабо, так что эти специальности мы здесь обсуждать не будем.
Привет, меня зовут Костя Кардаманов, я работаю в отделе технологий разработки Яндекса. Обычно такой же фразой я приветствую и кандидатов на собеседовании. А сегодня я хотел бы рассказать вам, как и зачем мы проводим интервью по дизайну систем с бэкенд-разработчиками. Сразу скажу: для фронтендеров, мобильных разработчиков и ML-инженеров подобный тип собеседований применим слабо, так что эти специальности мы здесь обсуждать не будем. Технический уровень кандидата у нас оценивается за счет всего двух типов интервью: секции с кодом и секции дизайна компьютерных систем. Первый тип мы назначаем всем претендентам вне зависимости от их уровня, а вот у кандидатов, которые претендуют на должность старшего специалиста, нужно проверять не только способность писать эффективный и работоспособный код, но и способность разрабатывать сложные системы в целом.
Что такое дизайн информационных систем
Основная цель любой IT-компании — производить сервисы, которые решают задачи пользователей. Мы должны уметь собирать элементы системы в единый механизм, который будет эффективно выполнять поставленную цель, и если первый тип собеседований нацелен в первую очередь на проверку необходимого минимума, то интервью про дизайн систем проверяет достаточность навыков кандидата в достижении конечной цели. Далекому от IT пользователю принципы и устройство систем могут казаться бесконечно сложными, но мы, их разработчики, должны иметь (не обязательно детальное) представление о принципах функционирования и роли каждого компонента.
Опытный читатель может сказать — в мире полно платных и бесплатных решений, из которых я могу собрать систему как из деталей конструктора, зачем мне понимать устройство этих деталей? Если мне нужна база данных, я возьму PostgreSQL и буду хранить свои данные в нем, для обработки HTTPS-запросов использую nginx, а сервис реализую на популярном фреймворке для написания HTTP-сервисов моего любимого языка программирования. Наверное, это будет отличным решением, если вы собрались писать сервис для небольшой аудитории, но сервисы большой компании обычно немного сложнее устроены и сильнее нагружены.
Например, выбирая базу данных, вы должны принять решение о том, нужна ли вам классическая реляционная СУБД или подойдет noSQL-решение? Возможно, системе будет достаточно более простого key-value-хранилища: вам не придется тратить время на настройку, а время отклика такой системы будет в разы меньше, что положительно скажется на скорости работы приложения. А какую конкретно базу данных выбрать, если вам достаточно KVS? Aerospike? Redis? Couchbase? Memcached? Может быть, вам нужно рассмотреть еще и HBase в этом классе? Вы должны знать о существовании всех этих типов хранилищ, их основные отличия и области применения, чтобы уметь делать разумный выбор.
Выбирая конкретный компонент, вы должны иметь представление еще и о его устройстве, основных преимуществах и принципах работы. Иначе может оказаться, что Memcached используется для хранения персистентных данных, а в Redis в перспективе (через несколько лет жизни проекта) потребуется хранить несколько терабайт относительно редко изменяемых данных — нам важнее свойства и предоставляемые системой гарантии, чем конкретное название. С другой стороны, система должна быть минимально сложной и дешевой в разработке и эксплуатации. Если вы можете использовать готовое решение для выполнения нужной функции, то тратить ресурсы на разработку собственной альтернативы будет неразумно — в каждом случае вы должны подходить к выбору взвешенно и осознанно.
В реалиях деятельности компаний масштаба Яндекса обычно оказывается, что все используемые решения очень быстро перестают помещаться на один сервер, а, учитывая требования высокой доступности, обязательно располагаются в нескольких локациях. И как только система становится распределенной, сложность ее дизайна и реализации увеличивается на порядки. На Хабре есть познавательный рассказ о том, как много нужно учесть при реализации распределенных систем.
Хороший разработчик должен представлять систему в четырех измерениях: не только понимать назначение и взаимосвязь ее компонент, оценивать способность системы выполнять заданные функции и выдерживать проектные нагрузки прямо сейчас, но и представлять ее развитие во времени на несколько лет вперед — насколько легко компоненты могут быть заменены при необходимости, как могут меняться требования к функциональности и объему данных в будущем, какая часть системы потребует модернизации, что может стать «бутылочным горлышком» (то есть какая часть наиболее чувствительна к нагрузке) и что может стать причиной отказа.
Возможность сохранения работоспособности системы в нештатных условиях, продумывание сценариев отказов и мер по их предотвращению — тоже ответственность разработчика. Вспомните хотя бы заблуждения про распределенные вычисления — сформированные более 20 лет назад суждения не стали менее актуальны. Сейчас эксплуатация и гарантия высокой доступности сервисов — это отдельная большая область знаний, известная как SRE. Как и TDD, де-факто ставший стандартом в разработке модулей и компонент, невероятно важным аспектом в проектировании и эксплуатации сложных систем становятся метрики проекта. Они не только показывают работоспособность системы в моменте, но позволяют выполнять корректировку планов развития системы по выводам из ретроспективного анализа этих метрик. Вообще, в проектировании систем уже давно используют подход metrics first — сначала необходимо определить или построить метрику, которую вы улучшаете, и только затем начать менять систему.
Помимо всего этого, вы должны уметь четко, ясно и аргументированно выражать свое мнение, чтобы его могли понимать и обсуждать разработчики в команде: давно прошли времена, когда человек мог в одиночку спроектировать и реализовать систему уровня разрабатываемых сейчас в крупных IT-компаниях. Этот навык нужен любому разработчику, претендующему на роль архитектора. Даже если вы единственный технический лидер небольшого проекта, и у вас нет необходимости согласовывать изменения с другими, все равно важно объяснять причины и факторы конкретного решения менее опытным разработчикам. Иначе как им получать опыт и качественно развиваться?
Программисты, разработчики, инженеры и архитекторы
Нет единого мнения, можно ли считать синонимами слова «программист» и «разработчик». Я в числе тех, кто видит значительную разницу. Первый термин ближе к слову «кодер» и вроде бы не подразумевает комплексного подхода к созданию проектов в том виде, как это описано выше. А разработчик обязан думать обо всем перечисленном. Я бы даже сказал, что это должен быть именно инженер-разработчик, потому что инжене?рия — область деятельности, связанная с применением результатов исследований на практике. Кстати, вот очень интересная интерпретация названий должностей разработчиков от valyard.
При этом в Яндексе редко встречается должность архитектора (как и проекты с длительностью реализации в 139+ лет), а дизайн основных сервисов — это результат коллективной деятельности разных специалистов. И неопытные инженеры, и эксперты — все, хоть и в разной степени, вносят свой вклад в развитие проектов. С другой стороны, нам не нужны простые исполнители, набирающие код «под диктовку»: проще и быстрее реализовать идею самостоятельно, благо современные инструменты разработки очень упростили эту задачу. То есть мы все разработчики. Так чем один разработчик отличается от другого? Почему одним предлагается проходить дополнительные испытания, а другим — нет? С точки зрения влияния решений инженера на проект можно разделить специалистов на три категории: младший, опытный и старший разработчик.
В первую категорию попадают те, кто недавно начал свою карьеру в IT, уже имеет технические знания, однако отсутсвие опыта и дополнительных навыков не позволяет им реализовывать сложные решения. Опытные разработчики могут выполнять сложные задачи, хорошо представляют архитектуру системы в целом, могут принимать решения о развитии компонент. К старшим разработчикам относятся люди, чья деятельность значительно влияет на проект не только объемом производимых изменений, но и их качеством, которое измеряется по перечисленным выше критериям. Такого человека можно назвать и архитектором тоже.
Так как объем изменений, вносимых в систему старшими разработчиками, очень большой, больше и риск возникновения потенциальных проблем. Рассматривая кандидатов на такие должности, мы хотим убедиться, что человек способен справиться с возлагаемой на него ответственностью.
Многие уверены, что у инженерной должности есть «потолок»: однажды для дальнейшего профессионального роста нужно начинать управлять людьми и становиться руководителем. У нас это не так — во многих командах есть люди, которые de jure или de facto стали техническими лидерами. Инженеры в нашей компании имеют равные с руководителями возможности карьерного и, соответственно, материального роста. Старший разработчик в какой-то момент становится экспертом, его решения начинают влиять если не на всю компанию в целом, то уже точно на значительную ее часть. И число таких людей в компании пропорционально числу руководителей с подобным уровнем ответственности.
Процесс
Итак, мы разобрались с предметной областью и терминологией. Как же проходят интервью для старших разработчиков? За очень ограниченный промежуток времени требуется оценить многие компетенции кандидата. Для этого мы даем задание по разработке сложной, высоконагруженной и отказоустойчивой системы. В качестве основы для задания мы берем реально существующую систему — например, Яндекс Go. В процессе решения задания придется много разговаривать, но мы ожидаем, что кандидат будет основным участником беседы — интервьюер на технических собеседованиях играет второстепенную роль и берет инициативу только в крайних случаях.
Базовый план собеседования по задачам дизайна систем достаточно прост, как и список критериев, по которому будет оцениваться решение задачи. Постарайтесь их запомнить и придерживаться в процессе беседы.
Пример задачи, на основе которого я буду строить рассуждения в этой статье
Представим, что вам нужно спроектировать высоконагруженную систему сокращения URL. Она будет применяться во всех продуктах компании масштаба Facebook с возможностью использования в бесплатной и платной версии. Платная версия не ограничивает RPS, количество ссылок на аккаунт, время жизни и позволяет создавать ссылки из меньшего количества символов.
Уточнение задачи: формализация требований, оценка аудитории, порядок нагрузки
В реальной жизни решения, связанные с дизайном систем, часто происходят в условиях нехватки данных. Я уже говорил о том, как важны метрики проекта для его правильного развития. Конечно, аналитики и менеджеры продукта постараются обеспечить вас наиболее полной информацией, но и этого может быть мало. Если вводных недостаточно, можно и нужно выдвигать обоснованные гипотезы на основе той информации, которая вам уже известна: например, сколько людей живут на планете и сколько из них пользуются интернетом.
Определите ключевые функциональные требования к будущей системе: какими свойствами она должна обладать в базе, а какими можно пожертвовать, каковы требования к времени ответа, доступности. Рекомендую записывать полученные требования, чтобы никакие из них не упустить в процессе беседы.
На примере нашей задачи можно было бы построить такой диалог:
— Объем переходов по ссылкам?
— 500 тыс. RPS в пике.
— Используем протокол HTTP или HTTPS?
— Оба, но нужно расчитывать на преимущественное использование HTTPS.
— Количество ссылок в базе?
— Всего — миллиард, у платных аккаунтов — миллион.
— Количество аккаунтов?
— Сотни тысяч бесплатных, тысячи платных.
— Есть ли требование на скорость ответа системы?
— 150 мс для 95% запросов на чтение.
— Каковы требования к отказоустойчивости?
— Четыре девятки на чтение.
— Требования на согласованность данных?
— Данные должны быть строго согласованы для новых ссылок; при модификации существующих ссылок допускается чтение неактуальных данных в течение нескольких секунд после обновления.
— Какое ограничение на частоту запросов действует для ссылок бесплатного аккаунта?
— Тысяча запросов в минуту.
— Как часто регистрируются новые ссылки?
— Сотни тысяч в день.
— Будет ли анонимный доступ для реализации ссылок?
— В базовой версии можно не реализовывать, в расширенной — можно подумать (с ограничениями на добросовестное использование системы).
Потоки данных, API, основные блоки системы
Когда готовы требования к системе, нужно понять, как она будет обрабатывать данные — что пользователи в систему отправляют и что получают в ответ. Получив ответы на эти вопросы, мы сможем понять, как должен выглядеть программный интерфейс системы. Описывая потоки данных, мы начнем определять то, из каких основных сервисов и компонент должна состоять система, а требования к API позволят уточнить их характеристики. Попытайтесь выписать основные сущности и сигнатуры базовых API-методов — это поможет вам в дальнейшем описании системы и структурировании решения.
В нашем примере можно выделить несколько основных функциональных блоков:
- Подсистема управления данными и администрирования аккаунта (control plane)
Нам потребуется API для управления аккаунтом и регистрации ссылок, но это не повлияет существенным образом на дизайн системы в целом. Остановимся на том, что потребуется реализовать следующие функциональные блоки API:
— авторизацию
— управление аккаунтом
— получение статистики по текущим зарегистрированным ссылкам
— поиск, модификацию и удаление зарегистрированных ссылок
Так как для работы потребуется веб-интерфейс, предлагается реализовать управление аккаунтом на базе REST API — это позволит и достаточно просто реализовать UI, и предоставить API для взаимодействия со сторонними системами.
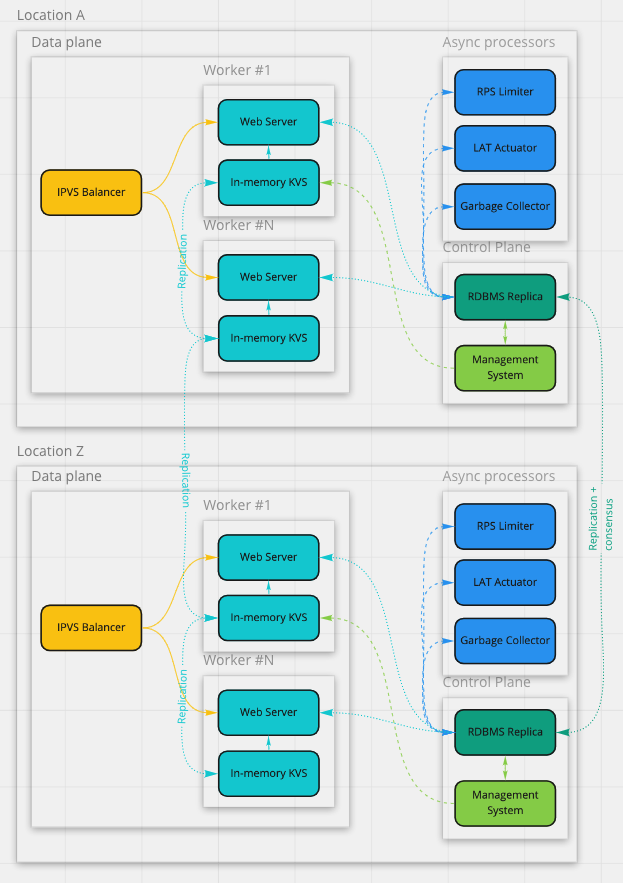
Для перехода по ссылке реализуем возможность HTTP(S)-запроса с ID ссылки, который отдает стандартное перенаправление черезHTTP 302 Moved Permanently.- Кодирование ссылок
Желательно исключить возможность перебора, поэтому для генерации идентификаторов будем использовать random. Для кодирования одного миллиарда ссылкок будет достаточно 32 бит, для кодирования одного миллиона платных ссылок — 20 бит. Используем alphanumerics для кодирования идентификатора ссылок, это даст нам 36 вариантов каждого символа, соответственно по 6 и 4 символа для кодирования необходимого диапазона ссылок. Добавим по одному разряду в каждую категорию для исключения проблемы перебора, получим 7 и 5 символов соответственно.- Хранение данных
Используем любую реляционную СУБД для хранения информации об аккаунтах и зарегистрированных для них ссылок. Порядок нагрузки на изменение данных в СУБД предполагается достаточно небольшой (порядка 1-2 RPS), чтобы с этим мог справиться один сервер, а вот нагрузка на чтение будет настолько высокой, что будет заведомо превосходить возможности одного сервера. Предлагается дополнить контур для чтения данных проксирующим KV-хранилищем, способным быстро обрабатывать большое количество запросов преимущественно из памяти. Подойдет любое NoSQL-хранилище, способное обслуживать запросы из памяти (in-memory KV store).- Обработка запросов на чтение (data plane)
Для обеспечения отказоустойчивости будем использовать несколько HTTP-серверов на базе любого популярного веб-сервера, дополненных нашим собственным модулем для получения ссылок и контроля скорости обработки запросов. Это позволит увеличить пропускную способность системы и сократит время ответа. Для балансировки запросов между HTTP-серверами можно использовать либо DNS, либо L3-балансировщик на базе IPVS по простейшей схеме round robin плюс проверки на доступность инстанса через health checks.- Ограничение пропускной способности
При обработке запроса необходимо будет подсчитывать количество запросов для ссылок определенного пользователя. Для этого нам потребуется централизованный сервис RPS limiter'а, сохраняющего информацию о количестве запросов по аккаунтам пользователей. Так как объем запросов к сервису будет достаточно большой, но нам не требуется высокая надежность хранения его состояния, можно реализовать этот сервис самостоятельно: хранить состояние в памяти и опционально периодически сохранять снимок (snapshot) в персистентное хранилище. Альтернативное решение: использовать основную СУБД для хранения состояния — веб-воркеры смогут получать снимок этого состояния самостоятельно (непосредственно из СУБД). Актуализировать состояние можно в независимом процессе.- Актуализация времени доступа к ссылкам
Чтобы минимизировать время обработки запроса на чтение, имеет смысл сделать асинхронным процесс обновления времени доступа к ссылкам. Лучше всего здесь подойдет распределенная очередь по типу multiple producers single consumer. Скорее всего, такая очередь уже реализована или легко реализуется на базе выбранного нами KV store.
Детальная схема с компонентами и их ролями, устройство наиболее важной части системы, структура базы данных
Построив верхнеуровневую схему, можно начинать добавлять в нее детали. Например, если в системе предполагается централизованное хранилище, о тонкостях выбора которого мы уже рассказали ранее, то нужно описать концептуальную модель хранимых в нем данных. По детальной схеме проекта можно будет определить наиболее нагруженные и критичные к производительности компоненты, которым следует уделить повышенное внимание с точки зрения разработки — продумать, какие структуры данных и алгоритмы следует в них применять.
При этом постарайтесь сохранять систему сбалансированной с точки зрения сложности. Если вы считаете, что для каких-то компонент можно использовать стандартное решение или известный фреймворк, предложите его — не усложняйте систему без лишней необходимости.
На этом этапе может потребоваться записать структуру хранения данных или описать предлагаемый алгоритм (хотя бы в псевдокоде) для наиболее сложного компонента системы.
Для нашего примера опишем устройство и схему работы каждого из функциональных блоков, которые мы определили на предыдущем этапе:
- Подсистема управления данными и администрирования аккаунта (control plane)
Здесь нет ничего сложного — поскольку в этой части системы ожидаются единицы RPS по нагрузке, можно использовать любой удобный фреймворк для разработки RESTful-сервисов. Для размещения сервиса с требуемым уровнем отказоустойчивости будет достаточно использовать несколько виртуальных серверов. Для балансировки запросов можно использовать общий пул IPVS-балансировщиков с подсистемой data plane: даже если пропускная способность на уровне data plane будет превышена, на доступности control plane это не скажется.
Так как будут работать несколько равнозначных веб-серверов под общим балансировщиком, при работе с базой данных обязательно потребуется использовать транзакции для исключения состояния гонки (race condition).
Основное хранилище можно организовать всего в двух таблицах.
CREATE TABLE Account ( account_id INTEGER NOT NULL PRIMARY KEY, login VARCHAR NOT NULL UNIQUE, type BOOLEAN NOT NULL )
Объем таблицы — порядка сотен тысяч записей, на каждую запись тратятся десятки байт, суммарно — единицы мегабайт данных.
CREATE TABLE Link ( link_id INTEGER NOT NULL PRIMARY KEY, account_id INTEGER NOT NULL REFERENCES Account, ttl INTEGER, created DATETIME NOT NULL, accessed DATETIME NOT NULL, url VARCHAR NOT NULL )
Объем таблицы — порядка одного миллиарда записей, на каждую запись тратятся сотни байт, суммарно — сотни гигабайт данных.
Для организации хранения нам потребуется любое managed-решение для реляционных СУБД, которое доступно у большинства облачных провайдеров. Суммарный объем хранимых данных — достаточно небольшой, чтобы уместиться на один физический сервер без необходимости шардирования. Подсистема управления данными не сгенерирует значительной нагрузки по CPU. СУБД можно располагать по схеме primary плюс набор hot standby-реплик.
При любом изменении содержимого таблицыLink(при добавлении/модификации/удалении) нужно будет синхронизировать подсистему обработки запросов на чтение на сервера KV store. Для этого можно использовать доступные системы репликации данных для выбранного KV store. Либо — реализовать собственную через дополнительную таблицу журнализации транзакций в основную СУБД примерно следующего вида:
CREATE TABLE Oplog ( id INTEGER NOT NULL SERIAL PRIMARY KEY, link_id INTEGER NOT NULL, account_id INTEGER NOT NULL, optime DATETIME NOT NULL, url VARCHAR NOT NULL )
Алгоритм применения журнала и решения проблемы использования данных с отстающих реплик можно обсудить в секции дополнительных вопросов.
Выбирая решение с двумя уровнями хранения данных, нужно понимать: мы сильно повышаем сложность всего решения, которая в данном случае выражается в проблеме согласованности данных в обоих подсистемах хранения. Нужно обязательно рассмотреть варианты, когда запрос выполнился в одной подсистеме храненения, но по какой-то причине не выполнился во второй. В таких случаях применяют механизм двухфазного коммита, достаточно дорогой в реализации. Здесь можно упростить решение — коммитить транзакцию в основную СУБД после подтверждения записи от большинства реплик (majority) со стороны KV store. Это может привести к накоплению мусора в KV store, что, в свою очередь, можно адресовать реализацией фонового процесса периодической сборки мусора.- Подсистема обработки запросов на чтение (data plane)
- При обработке запроса модуль веб-сервера будет действовать по следующему алгоритму:
- По ID ссылки получит из KV store информацию по полному URL и
account_idвладельца.- Выяснит текущую активность по
account_id. Для этого можно было бы выполнить синхронный запрос в RPS limiter, но такой способ увеличит критический путь обработки запроса. Поэтому лучше использовать read-only-таблицу видаaccount_id -> RPSв разделяемой памяти, которую раз в секунду будет обновлять специализированный процесс. Объем необходимой памяти — достаточно небольшой, сотни тысяч ключей по четыре байта каждый плюс по байту на значения счетчика и ограничения по аккаунту. Хранить можно в виде простого сортированного списка — это несколько мегабайт данных. Если выяснилось, что значение счетчика превысило квоту аккаунта, отвечатьHTTP 429 Too Many Requestsи завершать обработку запроса.- Зарегистрирует обращение по ссылке и сформирует ответ на HTTP-запрос. Допускается, что задержка на актуализацию времени обращения по ссылке может быть достаточно большой, поэтому нет необходимости актуализировать время обращения синхронно на каждый запрос. То же самое относится и к подсчету скорости обращения по ссылкам аккаунтов, так что обработку этой информации можно отложить. Эта информация не очень важна и с точки зрения основных требований к системе, поэтому можно некоторое время накапливать ее в памяти воркера веб-сервера — так мы значительно уменьшим количество данных, пересылаемых между воркерами.
Для накопления информации о доступах аккаунтов к ссылкам можно накапливать таблицуaccount_id -> counterи отправлять ее в RPS limiter раз в секунду. Для накопления информации о доступе к ссылкам можно просто накапливать множество (set) идентификаторов ссылок и раз в минуту отправлять его в распределенную очередь.- Хранилище ссылок
- Как предлагалось ранее, используем KV store как read-only-зеркало основной СУБД, в котором будет организовано хранение пар
link_id -> {url, account_id}. Такое хранилище должно обслуживать порядка 100 тысяч RPS на одном сервере, сами данные займут порядка сотни гигабайт (миллиард ссылок по 100 байт на ссылку) при минимальных затратах ресурсов CPU. Следовательно, данные можно не шардировать, а реплицировать.- Так как чтение выполняется с secondary-инстансов KV store, которые могут отставать, потребуется дополнительный путь для обеспечения согласованности данных для новых ссылок. Можно дополнительно реализовать уровень (L1) LRU-кэширования на уровне веб-сервера: при отсутствии идентификатора ссылки в KV store (L2) обратиться в центральное хранилище, результат ответа сохранить в L1-кеш, тем самым ограничивая нагрузку на основную СУБД.
- Актуализация времени доступа к ссылкам (LAT actuator)
Как предлагалось ранее, сервер-воркеры раз в минуту отправляют в распределенную очередь на базе KV store множество идентификаторов ссылок, которые были на них запрошены. Мы реализуем небольшой сервисный процесс, который забирает все накопившиеся данные из очереди, производит слияние множеств и выполняет простойUPDATEв базе, актуализируя время доступа ссылок запросом видаUPDATE Link SET accessed = now() WHERE link_id IN (...). Для отказоустойчивости запускаем несколько равнозначных процессов, которые на каждую итерацию захватывают поле в служебной таблице запросомSELECT ... FOR UPDATE.- RPS limiter
Выбирая между двумя вариантами — реализовать отдельный gRPC-сервис или хранить состояние в основой СУБД, — будем в первую очередь руководствоваться принципом минимизации расходов при сохранении приемлемого уровня качества и рисков отказов. Если поток обновлений или чтений будет высоким, имеет смысл выбирать первый вариант, в другом случае — второй. Предлагается реализовать сервис на основе хранения состояния в централизованной базе с асинхронным процессом актуализации этого состояния. У такого решения есть плюсы:
— Не требуется реализовывать дополнительной централизованный сервис с репликацией, консенсусом и прочими сложностями построения распределенных сервисов.
— Состояние будет персистентным и согласованным для всех потребителей.
Минусы решения тоже очевидны:
— Относительно высокая задержка в актуализации снимка данных. Здесь мы ожидаем задержку порядка единиц секунд — приемлемо с точки зрения качества работы и рисков для сервиса.
— Риск отказов data plane, то есть потенциальное снижение доступности сервиса (например, при перевыборах в случае переключения primary-инстанса СУБД). Эту угрозу можно адресовать тем, что веб-воркеры будут использовать снимок состояния из разделяемой памяти, который актуализируется на основе данных основной СУБД — асинхронно в отдельном потоке сервера.
— Риск превышения допустимой нагрузки на СУБД. Адресуем угрозу тем, что не будем выполнять прямую запись в основную СУБД со стороны data plane, а сделаем этот процесс асинхронным на основе распределенной очереди (по аналогии с процессом актуализации времени доступа к ссылкам).
Получаем следующую картину: веб-серверы с достаточно малым периодом, порядка 100 мс, забирают полное состояние RPS limiter'а из базы. Это достаточно небольшой объем данных:
CREATE TABLE RPSLimit ( account_id INTEGER NOT NULL REFERENCES Account, balance SMALLINT NOT NULL, -- остаток квоты аккаунта limit SMALLINT NOT NULL -- общая квота аккаунта )
Можно предположить, что в таблице будут тысячи записей, поскольку окно квотирования небольшое, а записи с нулевым потреблением мы будем исключать из таблицы. Таким образом ожидаем, что общий объем снимка состояния составит порядка полумегабайта. Объем данных на чтение из СУБД будет увеличиваться прямо пропорционально количеству потребителей и обратно пропорционально периоду обновления данных снимка — нужно подобрать оптимальные значения этого параметра, исходя из предполагаемого количества серверов и допустимой нагрузки на СУБД. Нет необходимости хранить структурированные данные в СУБД: можно сохранять только полный снимок состояния, сериализованный в бинарный формат (допустим, protobuf), и дополнительно сжимать его. Это даст на порядок меньший объем хранимых данных и снизит нагрузку на СУБД, позволив нам уменьшить период обновления данных:
CREATE TABLE RPSLimitSnapshot ( data BYTEA NOT NULL )
Сам процесс RPS limiter'а должен выполнять две функции:
— Получать обновления из распределенной очереди о количестве запросов по аккаунтам. Очередь формируется серверами по аналогии с LAT actuator. При этом процесс выполняет предварительную агрегацию сигналов в памяти и сохраняет снимок состояния в СУБД, добавляя полученные из очереди счетчики со значениями, которые хранятся в памяти.
— Актуализировать счетчики потребления. Здесь можно использовать алгоритм протекающего ведра (leaky bucket): серверы присылают статистику по количеству обработанных запросов, которые вычитаются из емкости корзины (balance) при обработке событий; через каждый квант времени в корзину добавляется фиксированная емкость; при достижении полной емкости корзины (когдаbalanceравенlimit) запись про этотaccount_idможно удалять из состояния. Само состояние можно считывать из СУБД один раз после захвата блокировки и хранить в памяти процесса. Сам алгоритм, кроме простоты реализации, добавляет полезную опцию использования burst budget — возможность кратковременно превысить установленные пределы на количество запросов.- Асинхронные сервисные процессы
Кроме перечисленных выше подсистем должен быть реализован еще один вспомогательный фоновый процесс — поиск и удаление ссылок с закончившимся временем жизни, сборка мусора от незавершенных транзакций в основной СУБД. Этот процесс может запускаться по таймеру и захватывать блокировку по аналогии с процессом выше.
С учетом всего вышесказанного, вот как можно схематично изобразить устройство системы:
Оценка объема необходимых вычислительных ресурсов, поиск узких мест
Когда схема сервиса становится достаточно ясна, можно переходить к оценке необходимых вычислительных ресурсов. Если компонент предполагает интенсивные вычисления или обработку большого объема данных, необходимо оценить затраты процессорного времени на выполнение алгоритмов, объемы оперативной памяти, накопителей данных, пропускной способности сети. Здесь вам обязательно понадобится вспомнить latency numbers every programmer should know. Может оказаться, что вычислительных возможностей современных серверов будет недостаточно для размещения одного или нескольких компонентов системы. Тогда надо принимать сложное решение — либо менять базовый алгоритм/структуру данных, либо переходить к горизонтальному масштабированию. Последний вариант обычно представляется более выигрышным в долгосрочной перспективе. Но у любого решения есть своя цена, в данном случае придется заплатить усложнением дизайна системы и дополнительными затратами на эксплуатацию.
Проведем такой анализ для нашего примера
- Подсистема управления данными и администрирования аккаунта (control plane)
Для бэкенда, обслуживающего REST API создания ссылок и управления ими, достаточно минимального виртуального сервера с единицами CPU в нескольких локациях (для обеспечения отказоустойчивости). Для самой базы потребуется достаточно много дискового места и порядка десяти CPU на обслуживание запросов — здесь доминантным ресурсом будет дисковое пространство, такой инстанс скорее всего займет полноценный сервер. Считаем, что выбранное нами managed-решение для СУБД имеет встроенные механизмы по автоматическому переключению primary-инстанса на основе алгоритмов распределенного консенсуса. Поэтому нам потребуется три таких сервера для отказоустойчивости.- Подсистема обработки запросов на чтение (data plane)
Здесь дефицитный ресурс — это CPU: обслуживать HTTP over SSL на порядок затратнее, чем plain HTTP. И хотя SSL handshakes будут обрабатываться за счет специальных инструкций процессора, надеятся на SSL session не приходится. Дело в том, что на каждый идентификатор ссылки будет происходить один запрос с каждого клиента. То есть мы можем рассчитывать максимум на обслуживание ~20 тысяч запросов на сервер. Это значительно ниже предела обслуживания запросов в KV store, который составляет порядка 100 тысяч RPS. Поскольку KV store не должен активно использовать CPU для своей работы, а доминантным ресурсом является именно CPU, можно установить по инстансу KV store рядом с каждым из серверов. Для обслуживания запросов из стоящего рядом сервера инстансу не потребуется значимых CPU-мощностей. При этом он сможет хорошо утилизировать доступную на сервере память. Бонусом мы получим снижение нагрузки на сетевую подсистему сервера и небольшое повышение надежности системы в целом. Таким образом, нам потребуется 25 серверов с парами вида «сервер + KV store» (назовем такой сервер воркером) для необходимой пропускной способности.
Нам также нужна избыточность на случай отказов. Раз распределенный консенсус в этом контуре не используется, количество регионов не играет роли. Сервис должен переживать отказ одного из регионов, при отказе должно оставаться 25 работоспособных воркеров. Выгоднее всего будет выбрать вариант с девятью серверами в четырех ДЦ. Для IPVS-балансировщиков потребуется 4 сервера — столько же, сколько и регионов, чтобы исключить проблемы удлинения маршрута обработки запросов (выхода маршрута обработки запроса за пределы ДЦ). Итого 40 серверов, с учетом мощностей для СУБД — 43 сервера. Такое количество обеспечит достаточный уровень отказоустойчивости, плюс останется запас на случай обновления или выхода из строя до двух воркеров в период недоступности одного из регионов.- Время ответа системы
Оно будет определяться двумя основными факторами:
- Удаленностью клиента от обслуживающего запрос HTTP-сервера. Пинг между Нью-Йорком и Москвой составляет порядка 120 мс. Значит, на ответ HTTP-сервера остается порядка 30 мс.
- Временем обработки запроса воркером:
— Время ответа KV store составит единицы миллисекунд на localhost без дополнительного проксирования
— Сам сервер будет обслуживать запрос тоже за единицы миллисекунд
— Маршрутизация внутри ДЦ незначительна мала — сотни микросекунд
В сумме время обработки запросов должно уложиться в 10 мс, что дает нам очень хороший запас по требованиям ко времени ответа сервиса.
Учитывая перечисленные выше факторы, мы, чтобы удовлетворить требованию по скорости обслуживания запросов, можем не реализовывать дополнительное географическое распределение сервиса.
Топология сервиса, вопросы эксплуатации: балансировка, обработка отказов, мониторинг, обслуживание, работа в экстремальных условиях
Убедившись в работоспособности системы, можно переходить к заключительной части основного блока беседы — эксплуатации.
Для начала опишите, как система должна быть расположена топологически, сколько потребуется дата-центров, CDN, как будет устроено кэширование и балансировка запросов в такой топологии.
Расскажите, как система должна переживать отказы единичных серверов и целых дата-центров, какими метриками вы сможете контролировать ее работоспособность. У вас должен быть план действий на случай попадания в основной контур сборки, которая содержит критическую ошибку в одном из компонентов или в данных; на случай превышения штатной нагрузки в разы или даже на порядки. Объясните, как избежать отказов в обслуживании в такой ситуации — чем можно пожертвовать для выживания.
Опишите, как вы предполагаете обновлять компоненты системы или основного хранилища, менять схему данных; как убедиться, что очередной релиз не содержит проблем в части работоспособности компонент или в производительности. В заключение вспомните функциональные требования к системе, выписанные в самом начале беседы. Подумайте, как вы могли бы их дополнительно контролировать на основе данных, поступающих из системы и внешних источников.
Применительно к нашей задаче можно обсудить следующие аспекты
Основную часть про балансировку запросов мы уже осветили выше. Здесь можно дополнительно указать, что нагрузка будет распределяться равномерно, так как на всех уровнях балансировки используется простая схема round robin.
Сценарии отказов
- Отказ IPVS-балансировщика: нагрузка распределяется по оставшимся трем, есть многократный запас по мощности.
- Отказ веб-сервера и/или KV store: нагрузка распределяется по оставшимся восьми серверам в ДЦ. При доступности остальных дата-центров в период пиковой нагрузки мы должны сохранять доступность шести воркеров в ДЦ. При доступности меньшего количества воркеров нужно исключить ДЦ из балансировки.
- Отказ secondary-инстанса центральной СУБД: не влияет на систему.
- Отказ primary-инстанса центральной СУБД: влияет на времена обработки запросов в подсистеме управления данными и администрирования аккаунта, но не влияет на время обслуживания GET-запросов.
- Отказы RPS limiter'а и вспомогательных подсистем: не влияют на работоспособность основных функций, однако повышают риски отказа этих функций.
- Меры предотвращения отказов из-за значительного превышения нагрузки на чтение:
— С непродолжительными пиками система будет справляться, увеличивая время ответа за счет накопления очереди запросов на воркерах. Здесь у нас есть запас по требованиям ко времени ответа.
— Стоит использовать алгоритмы определения подозрительного трафика на уровне IPVS-серверов — хосты и подсети с высокой активностью, blacklist'ы, формируемые воркерами.
— Необходимо добавлять в blacklist источники, запрашивающие слишком большое количество одинаковых или несуществующих ссылок.
— А также понижать уровень криптографической устойчивости SSL-сертификата на серверах.
Мониторинги
- Все мониторинги агрегируем по классам серверов:
— primary-инстанс центральной СУБД
— secondary-инстансы центральной СУБД
— KV store
— Веб-сервер
— IPVS-балансировщики
— RPS limiter
— вспомогательные сервисы- Потребление системных ресурсов (CPU, RAM, disk IO, network IO) на серверах в целом и в процессах подсистем.
- Количество обработанных запросов, время обработки запроса с разделением по квантилям.
- Количество ответов веб-серверов по кодам ответов. Но здесь потребуется защита от шума, такого как часто запрашиваемые несуществующие ссылки и аккаунты с закончившейся квотой.
Логирование и трассировка
Хранить логи веб-серверов при таких объемах запросов будет очень затратно. С другой стороны, даже на минимальном уровне логирования скорость записи логов может повлиять на производительность системы. Поэтому записываем логи на SSD/NVMe-носитель, ротируем достаточно часто, после чего сжимаем их и перекладываем в систему хранения с минимальной стоимостью хранения за единицу объема. Для разных периодов архивов можно использовать разные уровни избыточности. В качестве первого уровня хранения логично применять HDD на том же сервере. Для отладки проблем подойдет более детальная трассировка каждого k-го запроса и/или по опциональному параметру в запросе.
Обновление
Так как каждый сервер подсистемы обработки запросов на чтение независим, и мы можем терять до трех воркеров в ДЦ без потери качества, стоит обновлять систему по три воркера за раз, пока не обновится весь ДЦ. Обновляем ДЦ строго последовательно, контролируя основные показатели работоспособности и сравнивая их с остальными.
Для тестирования обновлений можно использовать отдельный тестовый контур меньшего размера с репликой данных, дублируя на этот контур каждый k-й запрос из продакшен-контура. Обновление центральной СУБД можно выполнять с небольшим даунтаймом. Это не повлияет на требования к доступности системы на чтение, если предварительно протестировать обновление на тестовом контуре.
Дополнительные вопросы
Если у вас осталось немного времени после основной части беседы, можно обсудить что-нибудь еще. Например, плюсы и минусы одного из предлагаемых фреймворков, базы, структуры или алгоритмов, подробности их устройства. Можно затронуть дополнительные аспекты эксплуатации: контроль и оценку качества работы системы с точки зрения пользователей, локализацию и персонализацию ответов, контуры тестирования, rolling releases и continuous deployment, версионирование данных, быстрые срезы данных для работы при экстремальных нагрузках, способы поиска проблем и варианты отладки в работающем кластере.
Подготовка к интервью
К собеседованию, как и к любому другому испытанию, необходимо готовиться, если вы хотите повысить шансы на успех (иначе зачем тратить на это свое время?). Даже если вы разрабатываете системы подобного класса каждый день, часть моментов могут забыться, за время вашей работы могли появиться новые системы и подходы к решению задач проектирования. Поэтому освежите свои знания. Подготовку стоит начать с изучения литературы и докладов о дизайне реально существующих систем. Ссылки на нужные ресурсы вы найдете ниже.
Когда почувствуете себя готовым к интервью, можно попробовать потренироваться. Возьмите большой лист бумаги или маркерную доску и попытайтесь представить дизайн любой из известных вам сложных систем или сервисов. Это может быть система хранения данных, видеохостинг, поиск, лента новостей из социальных сетей, мессенджер, система обработки заказов.
Попробуйте продумать ее дизайн по плану выше. Если есть возможность — позовите знакомого разработчика вас послушать. Даже если он не поймет какой-нибудь части рассказа, вы все равно узнаете, насколько доступным и логичным у вас получается описание системы.
Какие материалы можно использовать для подготовки:
- Книги
— Эндрю Таненбаум — Распределенные системы. Принципы и парадигмы
— Брендан Бёрнс — Распределенные системы. Паттерны проектирования
— Martin Kleppmann — Designing Data-Intensive Applications
— Бетси Бейер, Крис Джоунс, Дженнифер Петофф, Нейл Ричард Мёрфи — Site Reliability Engineering. Надежность и безотказность как в Google - Доклады
Видео с докладами с любых конференций по высоконагруженным системам, например HighLoad++. - Методичка
The System Design Primer — отличная методичка. В ней много полезной информации — правда, без теоретической подготовки будет легко запутаться. - Курсы
Есть множество разнообразных видеокурсов на тему System Design Interview. К сожалению, большинство из них платные, а предлагаемые решения часто оказываются не самыми лучшими. Поэтому ничего конкретного советовать не буду, проходить их или нет — решайте сами. Гарантировать или хотя бы значительно увеличить вероятность успеха они не смогут. Но, наверное, добавят вам уверенности в собственных силах.
Хорошая теоретическая подготовка и немного практики в области дизайна систем обязательно пригодятся вам в жизни и помогут профессионально расти. Творческих вам успехов.







Kiel
Нет ничего сложного и затем текста в пол )
Спасибо за статью
kardamanov Автор
:) Тут я хотел сказать что в данной подсистеме нет ничего необычного — про устройство систем такого класса уже есть 100500 статей.