
Никто не любит капчу. Угадай слово по плохой картинке, собери пазл, отличи светофор от гидранта, сложи два числа и так далее. Формы бывают разные, но суть всегда одна: мы тратим своё время и нервы.
Чуть больше года назад моя команда взялась за модернизацию старой капчи Яндекса. Обычно в таких задачах стремятся повысить качество и полноту отсева ботов, оставив человеку шанс прорваться через капчу. Но мы зашли с другой стороны: решили сделать капчу более дружелюбной к людям, не ухудшив при этом защиту от ботов. Казалось бы, наивный подход. Но у нас получилось.
Сегодня я расскажу об этом подробнее. Вы узнаете, как мы отказались от распознавания текста и перешли к его генерации. Покажу примеры дружелюбной капчи. Расскажу о необычном опыте применения капчи в образовании. А ещё покажу текущий вариант капчи без капчи и немного поразмышляю о будущем.
Несколько слов о том, зачем нужна капча. Уверен, это и так не секрет, но историю всё же стоит начать с основ, чтобы быть на одной волне.
Капча — это инструмент, который помогает сервису понять, обратился к нему человек или робот. Это полезно, потому что роботы создают нагрузку или даже занимаются откровенным вредительством. При этом нужно показывать капчу не всем, а только тем, чьи запросы похожи на автоматические. Для этого надо проанализировать запрос. Анализ — это уже давно не просто подсчёт числа заходов с конкретного IP. Факторов для анализа намного больше, чем один. С другой стороны — сервис с нагрузкой в сотни тысяч RPS и с жёстким требованием к скорости ответа пользователю. Если снизить скорость ответа, то пострадают пользователи. Если снизить полноту выявления ботов, то в итоге опять же пострадают пользователи. Значит, нужно искать баланс между этими крайностями. И получается, всегда будут люди, которым покажут капчу.
Первые шаги
Год назад наши пользователи видели примерно такие задания:

Два слова. Одно мы знаем. Другое хотим узнать. Вряд ли я открою большой секрет, если расскажу, что капчу часто применяют для обучения компьютерного зрения. Раньше так было и у нас.
В целом ничего жуткого, да? Но могу и жути нагнать. Вот примеры более сложных (но крайне редких) вариантов:

Мы, конечно, такое вычищали. Использовали для этого как классификаторы неоднозначно читаемых картинок, так и данные о поведении пользователей (если человек даже не пытается ввести текст, то это плохой сигнал). Но и после таких изменений людям было очень сложно. Можно сказать, что старая капча отлично экономила ресурсы: её не могли пройти ни боты, ни люди. Только 35% реальных пользователей справлялись с первой попытки. Очень страшное число. Нужно было что-то менять.
Начали с анализа наиболее частых ошибок. В топе оказались знаки препинания, верхний и нижний регистр букв, лишние пробелы. Посчитали, как у ботов с этими проблемами. Оказалось, что можно безболезненно отказаться от их учёта при проверке результата. Эти элементарные, быстрые решения принесли нам с ходу +15%. Но дальше простые идеи закончились. Нужно было подойти к задачке более глобально.
Свои картинки с текстом
Поговорим о картинках. Так как их мы не генерировали, а вырезали из готовых, иногда там встречались очень необычные тексты. Их вы уже видели выше: это и перевёрнутые штрихкоды, и логарифмы. Их можно фильтровать с переменным успехом, но гибкости в работе с ними нет. Нельзя оперативно управлять сложностью, контролировать допустимый словарный запас, выбирать язык для разных стран. Если хочешь полностью контролировать качество капчи, то выход только один — генерировать картинки самостоятельно. Так мы и поступили.
Мы хотели создать капчу, которая будет существенно легче читаться людьми, но не ботами. На входе у нас есть какой-то текст и какой-то фон. Осталось понять, что нужно с ними сделать, чтобы добиться желаемого.
Наиболее эффектно, пожалуй, выглядит способ точечно искажать исходную картинку так, чтобы машина видела в ней совершенно не то, что видит человек.

Но такой подход крайне чувствителен к изменениям алгоритмов распознавания на стороне роботов. Пришлось бы мониторить их особенно тщательно и слишком часто адаптироваться. Поэтому мы подошли более консервативно.
Задачу распознавания текста нейросетями сейчас решают хорошо, причём уже далеко не только лидеры индустрии. Но трудные задачки по-прежнему встречаются. Наиболее сложные датасеты с распознаванием слов на сегодняшний день представляют собой сильно искривлённые тексты (irregular text recognition).

Это то, с чем человек справляется относительно просто. Но не робот. Этот подход мы применили и у себя. Пример такой капчи:
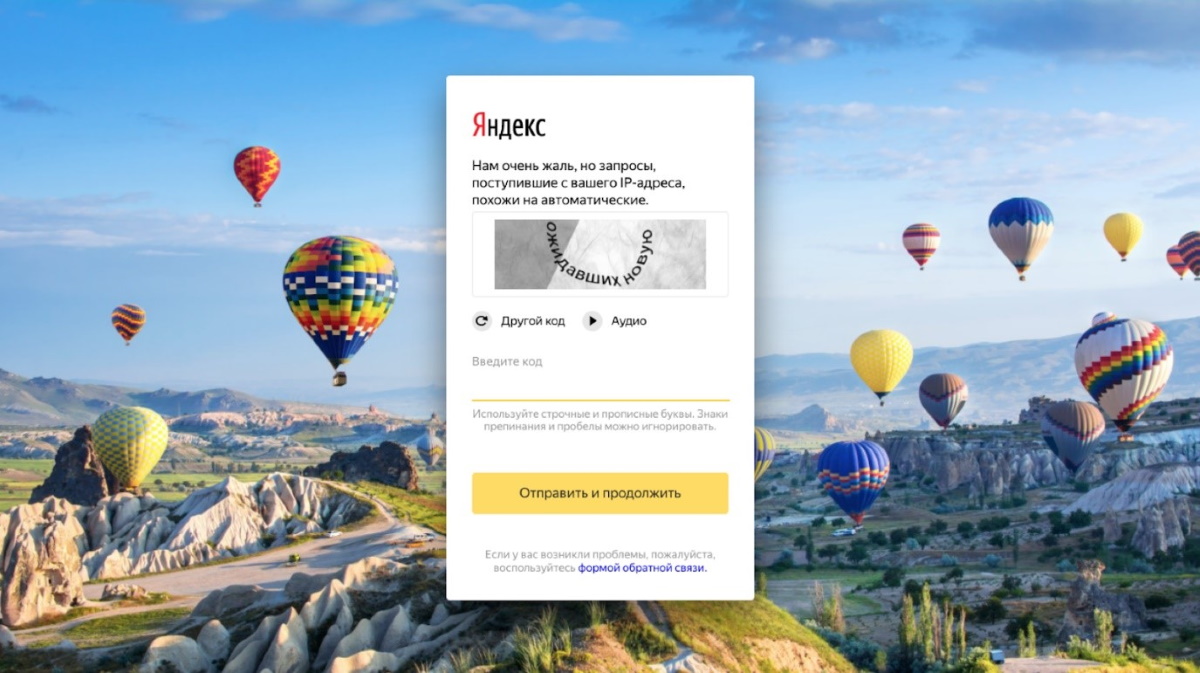
Выглядит проще, чем раньше? Наши пользователи тоже так считают: эту капчу легко преодолевают уже 85% пользователей. А вот ребятам, которые учатся обходить нашу капчу, работы прибавилось.

Конечно, со временем к ней адаптировались, но масштабы проблемы в итоге не больше, чем у старой капчи. При этом людям стало существенно проще.
Полезная и добрая капча
Успех с генерацией собственных картинок воодушевил нас. Мы осознали, что капче не обязательно быть исключительным злом в глазах пользователей. Она может быть такой, какой мы захотим её сделать. Например, полезной для людей.
Каждый октябрь в России отмечают День учителя. Мы решили отпраздновать его по-своему и с пользой. Собрали данные о том, в каких словах пользователи чаще всего делают ошибки. (Яндекс по понятным причинам неплохо в этом разбирается.) На базе этого словаря сгенерировали капчу, отметив те буквы, в которых люди ошибаются. Выкатили на огромную аудиторию. Ботам это ничем не помогло, а вот людям (хочется верить!) пользу принесло.
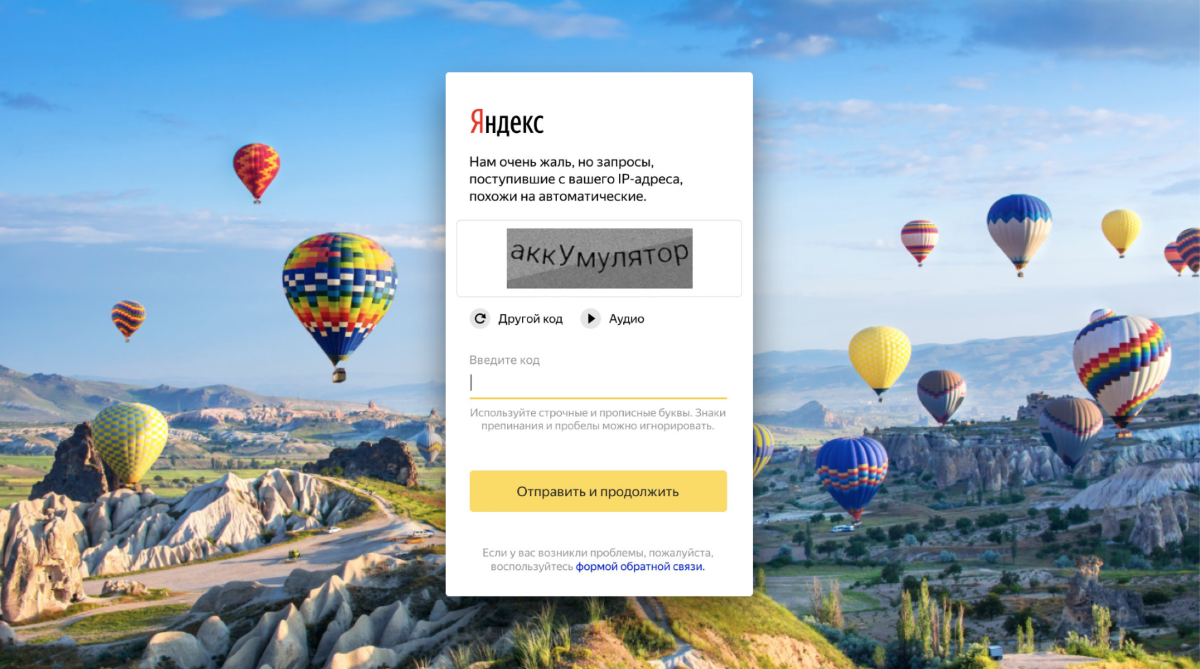
Ещё примеры:
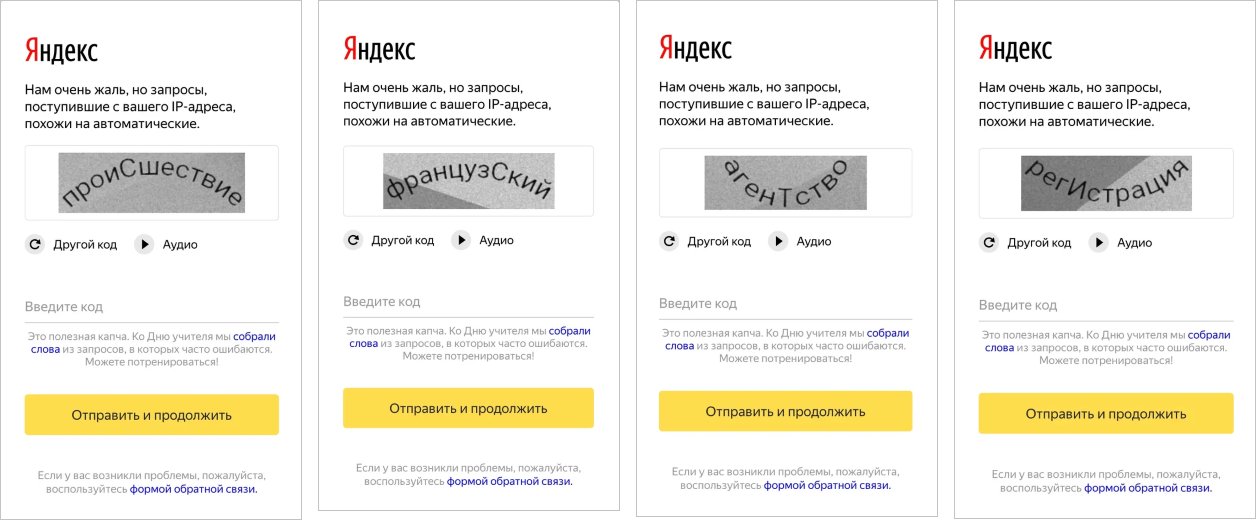
Другой пример работы с капчей, чуть ближе к концу 2020 года. Хотелось немного поднять пользователям настроение. Придумали использовать для генерации капчи не какие попало слова и фразы, а только те, что несут положительный эмоциональный заряд. Проще говоря, такие слова, которые как минимум не портят настроение ещё больше, а в идеале улучшают его.
Собрали данные с помощью толокеров. Сгенерировали. Получили капчу, которая содержала фразы «Приятных эмоций», «Вам всё по плечу», «Продуктивного дня» и подобные.
В общем, идей для работы с капчей много. Но нельзя забывать самую главную: лучшая капча — это та, которой нет.
Капча без капчи
Вернёмся в самое начало нашей истории. Там я рассказывал о том, что капчу предлагают только тем пользователям, чьи запросы в результате быстрого анализа показались нам подозрительными. Быстрый анализ отрабатывает примерно за одну (!) миллисекунду. Делать это дольше без вреда для высоконагруженного сервиса и миллионов пользователей нельзя. Это значит, что нужно использовать быстрые алгоритмы, а они не всегда самые точные. Из-за этого люди видят капчу. Как можно обойти это узкое место? Использовать промежуточный шаг!
Если быстрый анализ вынес вердикт о подозрительности запроса, то мы можем перенаправить его на страницу с капчей. Но саму капчу пока что не показывать. Потому что в этот момент у нас появляется время на второй, более глубокий и сложный анализ. Мы можем потратить намного больше, чем одна миллисекунда, а значит, спасти существенное количество наших пользователей от необходимости преодолевать пусть и не страшную, но всё же капчу.
Теперь это работает так. Если человеку не повезло попасть на страницу с капчей, то вместо капчи он видит предложение поставить галочку и подтвердить, что он не робот.

Пока пользователь ставит галочку, мы проводим дополнительный анализ с использованием более сложной ML-модели. Если всё хорошо, то возвращаем на сервис. Если «подозрительность» сохраняется, то показываем текстовую капчу.
И ещё кое-что важное. Переход от бинарных вердиктов (бот — не бот) на первом этапе к вероятностным («робот на N%») на втором позволяет нам управлять сложностью капчи! Если на втором этапе мы по-прежнему считаем запрос подозрительным, но степень уверенности в этом не такая высокая, то показываем простейшую капчу. А вот если мы уверены, что перед нами робот, то можем сложность и приподнять. Простое, но эффективное решение.
Несколько слов о значимости этого решения для людей. Выше мы радовались тому, что 85% (а не 35%, как было раньше) пользователей справляются с новой текстовой капчей с первой попытки. Но с галочкой «Я не робот» ситуация изменилась радикально: теперь более половины пользователей возвращаются в сервис вообще без необходимости разгадывать капчу! Вот такая вот капча без капчи.
За последний год мы прошли длинный путь, но идей на будущее от этого меньше не стало. Мы уже работаем над тем, чтобы получать более точные вердикты в реальном времени и без перенаправления на промежуточные страницы. И уже есть первые успехи. Один частный пример: теперь в Safari в режиме Инкогнито встретиться даже с галочкой «Я не робот» вероятность примерно в десять раз ниже, чем раньше. Кроме того, хотим пробовать новые, более добрые форматы капчи для тех случаев, когда без неё никак.
Формы капчи могут быть разные, но главное в том, чтобы относиться к людям по-человечески и уважать их время.

































redneko
Уважаемый Яндекс, я вот не робот, честное пионерское. Но капча ваша уже нереально задрала. Почему она вылезает, даже если пользователь залогинен, если из этой же сети стучится к вам ваша же колонка с Алисой? Всего-то стоило настроить IPv6 от HE. И даже белый статический IPv4 не спасает, хотя в tcpdump видно обмен с вашими сервисами, используя оба протокола. Раз вы презентуете себя как компания, славящаяся ML, то может стоит при обучении динамически учитывать еще и подсети своих пользователей, чтобы не заставлять их страдать?
P.S. Одна ваша капча однажды очень повеселила, попросив ввести фразу Avoid Smiling, напомнив что да, не время нынче улыбаться:)
toshchakov Автор
Спасибо за отзыв! К сожалению, роботы умеют имитировать людей (любой признак, в том числе авторизовываться в Я и прочее), поэтому полностью исключить ложноположительные срабатывания сложно. Но каждый такой пример помогает нам учиться. Поэтому прошу вас при следующем появлении капчи нажать на «обратную связь» и прислать нам детали. В текст сообщения допишите «привет от redneko с Хабра». Обязательно посмотрим.
redneko
Алексей, спасибо за обратную связь. Попробую сделать как вы сказали.
vmkazakoff
И теперь вам все ботоводы массово начнут слать обратную связь через ту кнопку, дописывая приветы с Хабра, в надежде что ваша модель пока обучается посчитает что это люди =]
toshchakov Автор
Могу сразу сказать, что это не поможет роботам )
Lev3250
То, что боты могут логиниться — ок.
Но почему каждый раз, когда я в инкогнито залогиненый (с рабочего компа) под аккаунтом с активным яндекс такси и привязанной картой с реальными оплатами, он всё равно спрашивает капчу.
Неужели для капчи не происходит проверка на акк-пустышку и реальный "человеческий"
vanxant
В зависимости от вашей продвинутости, вы сами можете запустить парсер яндекса, либо же за вас это мог сделать ботнет. Технически и то и то — это просто ещё одна вкладка или окно вашего же браузера со всеми вашими сессиями.
GennPen
dakuan
Если не секрет, что за роботы там такие, борьба с которыми требует применения таких радикальных средств? Это просто оружие массового поражения какое-то, вместе с роботами еще и кучу вполне себе людей отсекаете. Первая капча, которую я не смог решить. Буквально 2-3 недели назад пытался создать Яндекс-аккаунт. Сначала указал свой мобильный номер — превышен лимит звонков. Ладно, думаю, наверное, нужен российский номер. Достал мегафоновскую симку — та же история. Капча еще больше вопросов вызвала, даже гуглить пришлось как ее решать — нужен ли пробел между словами, учитывается ли регистр символов, нужно ли вводить спецсимволы и т.д. Попробовал все варианты, но в итоге так и не пробился — после ~70 попыток был вынужден признать, что я робот и пойти регистрироваться в Gmail.
Обычный европейский проводной провайдер, никаких VPN и средств анонимизации не использовал.
Gor40
А может ваша система не показывать капчу, если пользователь переходит в поиск по ссылке из вашей же Толоки?
mreugene
Та же самая ситуация в двух локациях с IPv6 от HE. Причем если изначально было только в режиме инкогнито — сейчас и при обычной работе встречается. Но стало лучше — сейчас капча только с чекбоксом отображается.
Ответ техподдержки Яндекса от 16.07.2020:
datacompboy
«2. Не нужно использовать язык запросов при использовании поиска: yandex.ru/support/search/query-language/search-operators.html»
я прямо даже и не знаю что такого нематерного сказать на это предложение…
toshchakov Автор
Согласен, формулировка не очень хорошая. Здесь по сути говорится, что роботы часто используют и полагаются на «язык запросов», поэтому этот фактор может быть достаточно значимым, при недостатке другой информации или при наличии других негативных сигналов. Но это точно не единственный фактор. И в обычной ситуации из-за использования «языка запросов» не должно быть капчи.
datacompboy
Я хочу сказать что если фича не для юзеров — отключите её. Говорить пользователю «не используйте наши фичи» это просто издевательство.
toshchakov Автор
Фича как раз для людей. Это формулировка ответа неудачная, исправим.
mixsture
Да нет, формулировка в целом смысл доносит. Он примерно такой: либо вы похожи на тетю Клаву (которая ничего в компьютерах не смыслит — какой уж там язык запросов), либо вы нам не нужны как клиент поиска.
И вот этот смысл ужасает. Я бы его перевернул, утрировал и посыпал сарказмом во фразу:
Яндекс — не место для профессионалов.
Вот примерно об этом же рассказывает redneko в соседних комментариях.
tendium
К сожалению, у Гугла подобная же логика. Стоит мне начать искать что-то специфическое, а гугл и так, и сяк не может дать ожидаемый ответ, то через 4-5 запросов я начинаю получать капчи. А я человек, честно-честно. Хотя...
redneko
Вот собственно о том и речь, что весь ответ техподдержки можно свести к классическому "нет человека — нет проблемы" и проще кинуть в бан всё адресное пространство ураганных электриков, чем немного изменить логику работы. Имхо, в мире розовых пони алгоритм мог бы быть чуть умнее — при подключении пользователя по IPv6 подсовывать скачивание пикселя с сервера, имеющего только v4 связность, запоминая связку обоих адресов (v4 и /64 или /48 адреса сети для v6), учитывая это как один из параметров антиспама и динамически вычислять скоринг, ориентируясь в том числе и на поведение остальных пользователей из этих сетей.
HardWrMan
Вот, кстати, да. Тоже залогинен, честный статичный IPv4 но ya.ru периодически рандомно выкидывает подобную капчу:

При этом я действительно могу искать разноплановую информацию: в одном окне датащит на детальку а в соседнем где купить сезаль. Я не бот, честно-честно!
HardWrMan
Ах! Сегодня впервые вместо капчи вылезла вот такая галочка:

Это прогресс, товарищи!
DistortNeo
Ещё веселее дела обстоят в гугле. Это когда ты сначала проходишь капчу, но в итоге тебя все равно не пускают под предлогом того, что с вашего IP делается слишком много автоматических запросов.
redneko
Было такое дело, давным-давно, когда сидел на местечковом говнопровайдере с DOCSIS, у которого за NAT сидела, наверное, половина города на одном IP. С тех пор у гугла таких финтов ушами не наблюдал ни разу, и к IPv6 у них вопросов нет.
DrZlodberg
Ничего не изменилось. У 2х провайдеров и с работы за NAT периодически вылетает даже на первый запрос.