
Говорят, что в каждой шутке есть доля правды. Если говорить о нашем первоапрельском приколе, то в нем эта доля стремилась ко всем ста процентам. Нам захотелось обыграть классический мем о Stack Overflow и немного уклониться от одного из наших фундаментальных принципов. Источником вдохновения послужили попортившие крови основателям компании ресурсы, которые открывают ответы на вопросы по программированию только для платных пользователей. А как бы изменился мир, если бы мы вдруг сделали возможность копировать текст со Stack Overflow доступной только за деньги?
Ну, пошутили и хватит. Надеемся, что все посмеялись и никто сильно не испугался. Но подождите, мы еще закончили. Настроив систему так, чтобы она реагировала на каждый ввод команды Command+C, мы сообразили, что у нас появился шанс получить больше информации о том, что люди делают на сайте. Мы успешно фиксировали каждую операцию копирования на Stack Overflow в течение двух недель, и вот что из этого получилось.
Один из четверых пользователей, открывающих страницу с вопросом на Stack Overflow, что-нибудь копирует с нее в течение первых пяти минут после захода на сайт. Суммарно мы насчитали 40 623 987 копирований из 7 305 042 постов в период с двадцать шестого марта по девятое апреля. Текст из ответов люди копируют примерно в десять раз чаще, чем из вопросов и где-то в тридцать пять раз чаще, чем из комментариев. Блоки кода подвергаются копированию в десять раз чаще, чем сопровождающий текст, а копирование со страниц вопросов без принятых ответов, на удивление, ведется активнее, чем там, где они есть.
Соответственно, если вам когда-нибудь было стыдно за то, что вы копируете готовый код, вместо того чтобы писать его с нуля – пусть ваша совесть будет спокойна! Зачем изобретать велосипед, если кто-то уже разрешил за вас все сложности? Мы называем это многократным использованием – то, что когда-то узнал, создал, доказал кто-то другой, теперь послужит вам. И в этом нет ничего плохого: так вы можете быстрее учиться, оперативнее получать рабочий код и меньше мотать себе нервы. Весь наш сайт стоит на концепции многократного использования знаний – сообщество Stack Overflow сильно, прежде всего, своим альтруистичным подходом к наставничеству.
Вполне позволительно залезть на плечи гигантам и позаимствовать уроки, которые они успели усвоить до вас, чтобы создать нечто новое и ценное. При этом, копируя, все-таки стоит придерживаться некоторых проверенных практик, чтобы ненароком не допустить возникновения багов или прорех в безопасности, так что удостоверьтесь, что хорошо во всем разобрались, прежде чем просто схватить кусок и вставить. Ну и само собой, нельзя забывать, что некоторые фрагменты кода можно использовать только с лицензиями. А в остальном мы полностью поддерживаем всех, кто хочет извлечь пользу из наработок, созданных сообществом.
Как человек, который многие годы без зазрения совести сдирал код со Stack Overflow, я не удивился, когда события копирования стали поступать миллионами. Удивило меня другое: сколько ответов на разные вопросы дала нам эта информация. Сколько людей в реальности копирует контент со Stack Overflow? Копируют один только код или что-то еще? Копируют ли активнее вопросы с принятыми ответами? Чтобы придать своему анализу какое-то направление мы с командой составили список вопросов, которые нас интересовали. Началось всё с простой шутки, а вылилось в серьезное исследование, пролившее свет на многие вещи и давшее толчок многочисленным обсуждениям о развитии и совершенствовании платформы в будущем.
При помощи самодельного инструмента для веб-трекинга мы создали кастомные события, чтобы фиксировать каждый случай, когда пользователь что-то копирует с сайта. Благодаря этим событиям нам удалось отследить самые разные характеристики: тэги, тип контента (вопрос, ответ или комментарий, блок кода или обычный текст), репутация копирующего, рейтинг поста, регион, статус поста – принят или нет. В общем, сохраняли мы практически всё, кроме собственно текста, который копировался.
Данные мы собирали полные две недели, с двадцать шестого марта по девятое апреля. Все выкладки, которые приводятся ниже, относятся к пользовательскому поведению в этом периоде.
Результаты верхнего уровня подтвердили то, что давным-давно звучало в шутках: на Stack Overflow все только и делают, что копируют. Также мы быстро убедились, что копирование как тип поведения подчиняется тем же закономерностям, которые уже выявлены для трафика сайта. Активнее всего люди копируют в будни, в рабочие часы. Регионы, где наш сайт пользуется наивысшей популярностью, дают больше всего копирований: Азия – 33%, Европа – 30% и Северная Америка – 26%. Ну и наконец, 86% копирующих – анонимные пользователи (то есть у них нулевая репутация). Когда мы стали подробнее вникать, кто копирует и что именно, стало интереснее.
Для начала нам захотелось проверить: окажутся ли пользователи с высокой репутацией самыми активными в копировании?

Из графика видно, что большая часть копирования осуществляется пользователями с нулевой репутацией – то есть анонимами, потому что любой, кто создал аккаунт, сразу получает один плюс. Возможно, какая-то доля этих событий приходится на пользователей, которые не зашли в свой существующий аккаунт. Это, к сожалению, никак не проверишь.
Так как основная масса пользователей у нас имеет низкую репутацию, давайте попробуем снять разбивку по группам, чтобы нормализовать данные. Обратим теперь внимание не на общее число копирований, а на число копирований на одного пользователя, чтобы увидеть, как отличается средний показатель в зависимости от репутации.

Если изучить эту визуализацию, прослеживается следующая закономерность: с ростом репутации число копирований на пользователя начинает снижаться. Корреляция присутствует, но не слишком выраженная, поэтому я не могу с полной уверенностью сказать, что пользователи с хорошей или плохой репутацией однозначно копируют активнее. Разработчики, которые еще только нарабатывают навыки, часто имеют невысокую репутацию и при этом склонны искать ресурсы, которые могут ускорить процесс обучения. По мере накапливания знаний они наращивают и репутацию и начинают работать с задачами, которые требуют хорошо откалиброванных решений – такие не всегда удается найти на Stack Overflow.
Ход мысли здесь выстраивается так: раз ответ приняли, значит, он, наверное, самый лучший, а раз так, то его и копировать должны с удвоенной энергией. Однако если взглянуть на статистику, то мы увидим, что в 52,4% случаев копируются не принятые ответы. Впрочем, если говорить о средних значениях, то на один уникальный пост с принятым ответом приходится семь копирований, а с не принятым – только пять. Получается, что не принятые посты дают больше копирований, но у принятых активнее разворачивается тот самый процесс многократного использования знаний.

Следует отметить, что существуют и такие вопросы, у которых в принципе нет принятых ответов. Взять, допустим, вот этот ответ: за него проголосовали 4 984 уникальных пользователя, а скопировали 7 943 за время нашего исследования. Но спрашивающий его не принял. Да и никакой другой тоже не принял – возможно, это как-то связано с тем, что он вообще не появлялся на сайте с 2010 года. Но многие другие полезные ответы находятся в том же положении.
Итак, принятые ответы не имеют преимущества при копировании, но уж высокий рейтинг-то точно должен влиять, верно? Давайте проверим.

Как мы видим, в категории ответов в группах от одного и до тысячи голосов всё идет довольно ровно. А вот в случае с вопросами большинство копирований приходится на посты с рейтингом от одного до пяти. Подозреваю, это потому, что люди копируют их для перепоста, пока наконец не появится ответ.
Как и в ситуации с пользователями, основная масса постов на сайте имеет довольно низкий рейтинг. Для нормализации посмотрим, сколько копирований приходится на один пост.
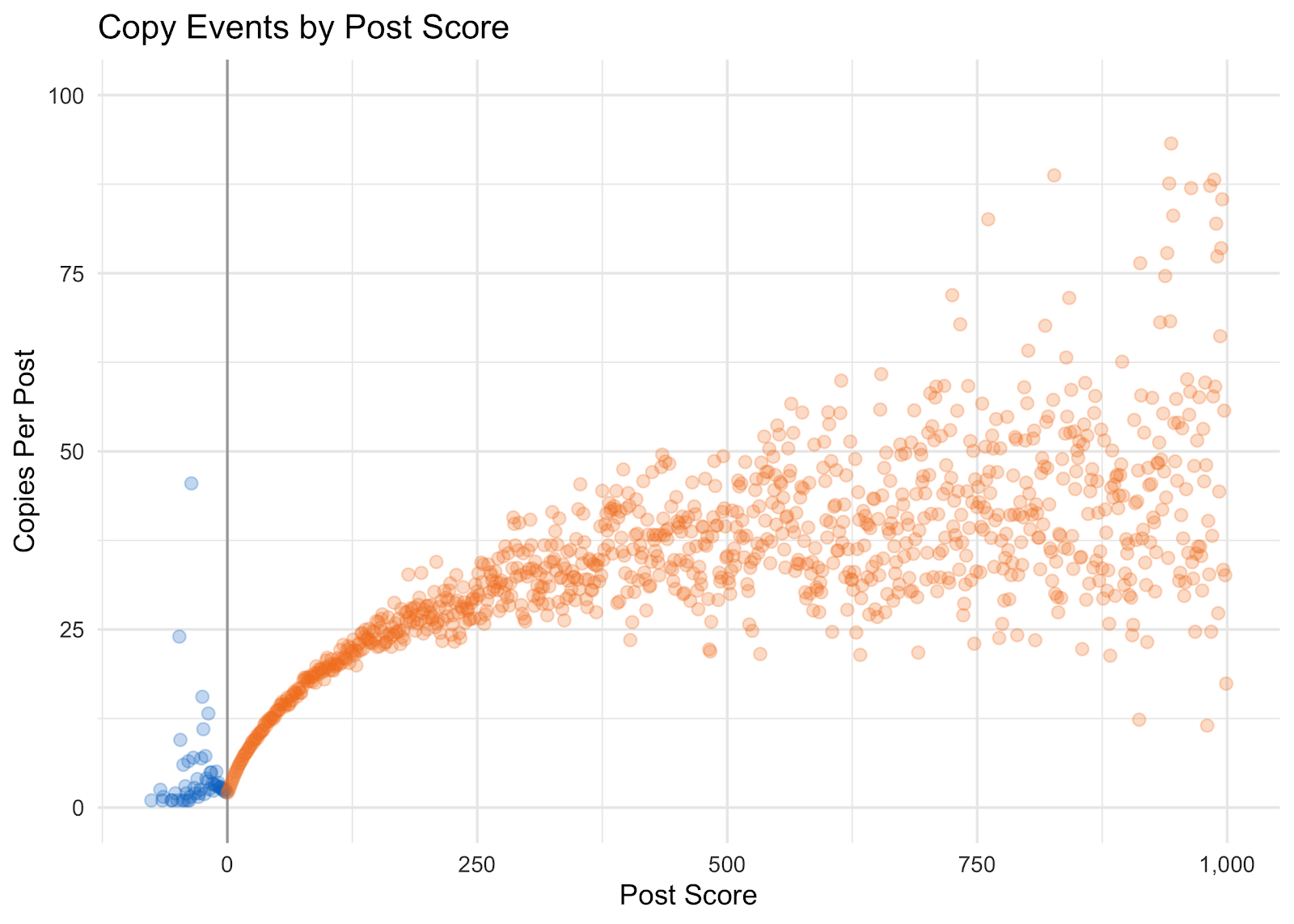
Здесь ясно видно, что число копирований возрастает вместе с рейтингом. И это логично: сообщество охотнее подхватывает то, что уже наработало хорошие показатели.
Ну а как обстоят дела с этими синими точками, которые представляют посты с отрицательным рейтингом? Зачем вообще копировать то, что никто не одобряет? Что ж, давайте не будем торопиться с выводами.
Посмотрите на этот ответ. Из всех ответов с отрицательным рейтингом он у нас собрал максимум копирований – 288 штук при рейтинге -2. Если вчитаться в текст, можно заметить, что он в более сжатом виде излагает то же самое, что говорится в самом популярном ответе с рейтингом 29 и 493 копированиями в общей сложности. Пусть ответ с отрицательным рейтингом и не выбился вперед по числу копирований, но все-таки принцип «ниасилил» тут явно сыграл в его пользу.
Именно на этот вопрос мне больше всего хотелось получить ответ. К сожалению, из-за масштабов исследования и объемов доступных ресурсов провести парсинг вложенных тегов не удалось. Скажем, в тэге html не учитываются посты, у которых проставлено сочетание тэгов |html|css|.
Чаще всего контент копировали из самых популярных и активных тегов на сайте, чему никто не удивился. Мне только одно бросилось в глаза: python фигурирует сразу в четырех группах тегов из первой десятки. Три из них имеют прямое отношение к анализу данных: |python|pandas|, |python|pandas|dataframe| и |python|matplotlib|. Я сам к этой теме неравнодушен, так что очень рад, что так много людей осваивает эти инструменты.

Вдобавок к информации о тегах с наибольшим общим количеством копирований мне хотелось вычислить теги с наивысшим соотношением числа копирований к количеству постов. Я установил минимальный порог в десять постов, и, как видите, оказалось, что чем больше в тегах конкретики, тем больше копирований они собирают на пост.

Ну а теперь перейдем к тому, что, думаю, у многих вызывает любопытство. Какой пост собрал максимальное число копирований?
Ответ с блоком кода
Рад сообщить, что победителем вышел ответ на вопрос How to iterate over rows in a DataFrame in Pandas, у которого 3 497 голосов и 11,829 копирований. Его разместили в 2013 году, и он до сих пор продолжает выручать тысячи людей каждую неделю.
Ответ с обычным текстом
Если же говорить о контенте, не содержащем кода, тут выходит вперед пост на тему TypeError: this.getOptions is not a function [closed] с 218 голосами и 1 570 копированиями. Нет возможности проверить, но я полагаю, что копируют фрагмент `sass-loader@10.1.1`.
Вопрос с блоком кода
Среди вопросов у нас лидирует How to create an HTML button that acts like a link? – 2 147 голосов и 3 665 копирований.
Вопрос с обычным текстом
Ну и наконец, самым популярным вопросом без кода оказался Updates were rejected because the tip of your current branch is behind its remote counterpart – 322 голоса и 261 копирований. С ним есть сложности, потому что в тексте содержится много git-команд, которые не оформлены как блоки кода – возможно, активно копируются как раз-таки они. Но так как сам текст, который подвергался копированию, мы не сохраняли, никто никогда не узнает.
Комментарии
Важно помнить, что Stack Overflow – это не только вопросы-ответы. Иногда и одного толкового комментария бывает достаточно. Вот парочка из тех, которые копировались особенно активно!
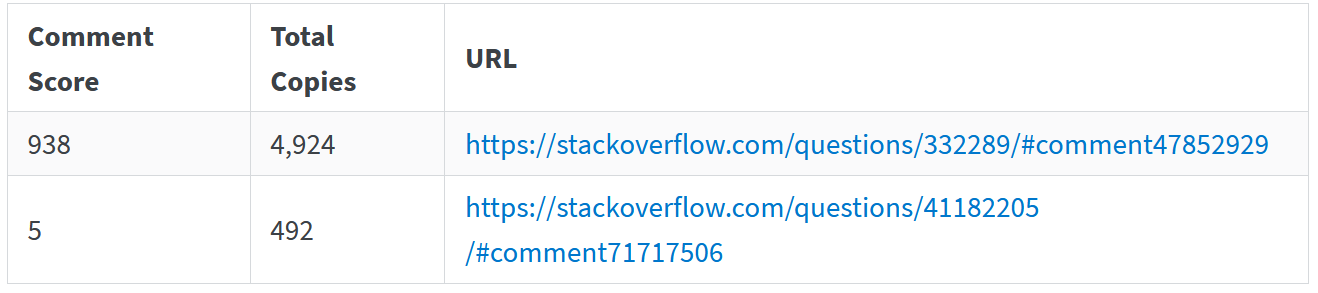
Первый – это абсолютный лидер среди комментариев по всему сайту, а второй – темная лошадка: он собрал всего-то пять голосов, но зато по числу копирований занимает шестое место.
Ну, пошутили и хватит. Надеемся, что все посмеялись и никто сильно не испугался. Но подождите, мы еще закончили. Настроив систему так, чтобы она реагировала на каждый ввод команды Command+C, мы сообразили, что у нас появился шанс получить больше информации о том, что люди делают на сайте. Мы успешно фиксировали каждую операцию копирования на Stack Overflow в течение двух недель, и вот что из этого получилось.
Вы не одни такие
Один из четверых пользователей, открывающих страницу с вопросом на Stack Overflow, что-нибудь копирует с нее в течение первых пяти минут после захода на сайт. Суммарно мы насчитали 40 623 987 копирований из 7 305 042 постов в период с двадцать шестого марта по девятое апреля. Текст из ответов люди копируют примерно в десять раз чаще, чем из вопросов и где-то в тридцать пять раз чаще, чем из комментариев. Блоки кода подвергаются копированию в десять раз чаще, чем сопровождающий текст, а копирование со страниц вопросов без принятых ответов, на удивление, ведется активнее, чем там, где они есть.
Соответственно, если вам когда-нибудь было стыдно за то, что вы копируете готовый код, вместо того чтобы писать его с нуля – пусть ваша совесть будет спокойна! Зачем изобретать велосипед, если кто-то уже разрешил за вас все сложности? Мы называем это многократным использованием – то, что когда-то узнал, создал, доказал кто-то другой, теперь послужит вам. И в этом нет ничего плохого: так вы можете быстрее учиться, оперативнее получать рабочий код и меньше мотать себе нервы. Весь наш сайт стоит на концепции многократного использования знаний – сообщество Stack Overflow сильно, прежде всего, своим альтруистичным подходом к наставничеству.
Вполне позволительно залезть на плечи гигантам и позаимствовать уроки, которые они успели усвоить до вас, чтобы создать нечто новое и ценное. При этом, копируя, все-таки стоит придерживаться некоторых проверенных практик, чтобы ненароком не допустить возникновения багов или прорех в безопасности, так что удостоверьтесь, что хорошо во всем разобрались, прежде чем просто схватить кусок и вставить. Ну и само собой, нельзя забывать, что некоторые фрагменты кода можно использовать только с лицензиями. А в остальном мы полностью поддерживаем всех, кто хочет извлечь пользу из наработок, созданных сообществом.
Как человек, который многие годы без зазрения совести сдирал код со Stack Overflow, я не удивился, когда события копирования стали поступать миллионами. Удивило меня другое: сколько ответов на разные вопросы дала нам эта информация. Сколько людей в реальности копирует контент со Stack Overflow? Копируют один только код или что-то еще? Копируют ли активнее вопросы с принятыми ответами? Чтобы придать своему анализу какое-то направление мы с командой составили список вопросов, которые нас интересовали. Началось всё с простой шутки, а вылилось в серьезное исследование, пролившее свет на многие вещи и давшее толчок многочисленным обсуждениям о развитии и совершенствовании платформы в будущем.
Данные
При помощи самодельного инструмента для веб-трекинга мы создали кастомные события, чтобы фиксировать каждый случай, когда пользователь что-то копирует с сайта. Благодаря этим событиям нам удалось отследить самые разные характеристики: тэги, тип контента (вопрос, ответ или комментарий, блок кода или обычный текст), репутация копирующего, рейтинг поста, регион, статус поста – принят или нет. В общем, сохраняли мы практически всё, кроме собственно текста, который копировался.
Данные мы собирали полные две недели, с двадцать шестого марта по девятое апреля. Все выкладки, которые приводятся ниже, относятся к пользовательскому поведению в этом периоде.
Результаты верхнего уровня подтвердили то, что давным-давно звучало в шутках: на Stack Overflow все только и делают, что копируют. Также мы быстро убедились, что копирование как тип поведения подчиняется тем же закономерностям, которые уже выявлены для трафика сайта. Активнее всего люди копируют в будни, в рабочие часы. Регионы, где наш сайт пользуется наивысшей популярностью, дают больше всего копирований: Азия – 33%, Европа – 30% и Северная Америка – 26%. Ну и наконец, 86% копирующих – анонимные пользователи (то есть у них нулевая репутация). Когда мы стали подробнее вникать, кто копирует и что именно, стало интереснее.
Соотносится ли высокая репутация с усиленным копированием?
Для начала нам захотелось проверить: окажутся ли пользователи с высокой репутацией самыми активными в копировании?
Из графика видно, что большая часть копирования осуществляется пользователями с нулевой репутацией – то есть анонимами, потому что любой, кто создал аккаунт, сразу получает один плюс. Возможно, какая-то доля этих событий приходится на пользователей, которые не зашли в свой существующий аккаунт. Это, к сожалению, никак не проверишь.
Так как основная масса пользователей у нас имеет низкую репутацию, давайте попробуем снять разбивку по группам, чтобы нормализовать данные. Обратим теперь внимание не на общее число копирований, а на число копирований на одного пользователя, чтобы увидеть, как отличается средний показатель в зависимости от репутации.
Если изучить эту визуализацию, прослеживается следующая закономерность: с ростом репутации число копирований на пользователя начинает снижаться. Корреляция присутствует, но не слишком выраженная, поэтому я не могу с полной уверенностью сказать, что пользователи с хорошей или плохой репутацией однозначно копируют активнее. Разработчики, которые еще только нарабатывают навыки, часто имеют невысокую репутацию и при этом склонны искать ресурсы, которые могут ускорить процесс обучения. По мере накапливания знаний они наращивают и репутацию и начинают работать с задачами, которые требуют хорошо откалиброванных решений – такие не всегда удается найти на Stack Overflow.
Чаще ли копируют принятые ответы?
Ход мысли здесь выстраивается так: раз ответ приняли, значит, он, наверное, самый лучший, а раз так, то его и копировать должны с удвоенной энергией. Однако если взглянуть на статистику, то мы увидим, что в 52,4% случаев копируются не принятые ответы. Впрочем, если говорить о средних значениях, то на один уникальный пост с принятым ответом приходится семь копирований, а с не принятым – только пять. Получается, что не принятые посты дают больше копирований, но у принятых активнее разворачивается тот самый процесс многократного использования знаний.
Следует отметить, что существуют и такие вопросы, у которых в принципе нет принятых ответов. Взять, допустим, вот этот ответ: за него проголосовали 4 984 уникальных пользователя, а скопировали 7 943 за время нашего исследования. Но спрашивающий его не принял. Да и никакой другой тоже не принял – возможно, это как-то связано с тем, что он вообще не появлялся на сайте с 2010 года. Но многие другие полезные ответы находятся в том же положении.
Активнее ли копируют посты с высоким рейтингом?
Итак, принятые ответы не имеют преимущества при копировании, но уж высокий рейтинг-то точно должен влиять, верно? Давайте проверим.
Как мы видим, в категории ответов в группах от одного и до тысячи голосов всё идет довольно ровно. А вот в случае с вопросами большинство копирований приходится на посты с рейтингом от одного до пяти. Подозреваю, это потому, что люди копируют их для перепоста, пока наконец не появится ответ.
Как и в ситуации с пользователями, основная масса постов на сайте имеет довольно низкий рейтинг. Для нормализации посмотрим, сколько копирований приходится на один пост.
Здесь ясно видно, что число копирований возрастает вместе с рейтингом. И это логично: сообщество охотнее подхватывает то, что уже наработало хорошие показатели.
А посты с плохим рейтингом кто-нибудь копирует?
Ну а как обстоят дела с этими синими точками, которые представляют посты с отрицательным рейтингом? Зачем вообще копировать то, что никто не одобряет? Что ж, давайте не будем торопиться с выводами.
Посмотрите на этот ответ. Из всех ответов с отрицательным рейтингом он у нас собрал максимум копирований – 288 штук при рейтинге -2. Если вчитаться в текст, можно заметить, что он в более сжатом виде излагает то же самое, что говорится в самом популярном ответе с рейтингом 29 и 493 копированиями в общей сложности. Пусть ответ с отрицательным рейтингом и не выбился вперед по числу копирований, но все-таки принцип «ниасилил» тут явно сыграл в его пользу.
Из каких тэгов копируют чаще всего?
Именно на этот вопрос мне больше всего хотелось получить ответ. К сожалению, из-за масштабов исследования и объемов доступных ресурсов провести парсинг вложенных тегов не удалось. Скажем, в тэге html не учитываются посты, у которых проставлено сочетание тэгов |html|css|.
Чаще всего контент копировали из самых популярных и активных тегов на сайте, чему никто не удивился. Мне только одно бросилось в глаза: python фигурирует сразу в четырех группах тегов из первой десятки. Три из них имеют прямое отношение к анализу данных: |python|pandas|, |python|pandas|dataframe| и |python|matplotlib|. Я сам к этой теме неравнодушен, так что очень рад, что так много людей осваивает эти инструменты.
Топ 10 тегов, теперь с числом копирований на пост
Вдобавок к информации о тегах с наибольшим общим количеством копирований мне хотелось вычислить теги с наивысшим соотношением числа копирований к количеству постов. Я установил минимальный порог в десять постов, и, как видите, оказалось, что чем больше в тегах конкретики, тем больше копирований они собирают на пост.
Какие посты копировали больше всего?
Ну а теперь перейдем к тому, что, думаю, у многих вызывает любопытство. Какой пост собрал максимальное число копирований?
Ответ с блоком кода
Рад сообщить, что победителем вышел ответ на вопрос How to iterate over rows in a DataFrame in Pandas, у которого 3 497 голосов и 11,829 копирований. Его разместили в 2013 году, и он до сих пор продолжает выручать тысячи людей каждую неделю.
Ответ с обычным текстом
Если же говорить о контенте, не содержащем кода, тут выходит вперед пост на тему TypeError: this.getOptions is not a function [closed] с 218 голосами и 1 570 копированиями. Нет возможности проверить, но я полагаю, что копируют фрагмент `sass-loader@10.1.1`.
Вопрос с блоком кода
Среди вопросов у нас лидирует How to create an HTML button that acts like a link? – 2 147 голосов и 3 665 копирований.
Вопрос с обычным текстом
Ну и наконец, самым популярным вопросом без кода оказался Updates were rejected because the tip of your current branch is behind its remote counterpart – 322 голоса и 261 копирований. С ним есть сложности, потому что в тексте содержится много git-команд, которые не оформлены как блоки кода – возможно, активно копируются как раз-таки они. Но так как сам текст, который подвергался копированию, мы не сохраняли, никто никогда не узнает.
Комментарии
Важно помнить, что Stack Overflow – это не только вопросы-ответы. Иногда и одного толкового комментария бывает достаточно. Вот парочка из тех, которые копировались особенно активно!
Первый – это абсолютный лидер среди комментариев по всему сайту, а второй – темная лошадка: он собрал всего-то пять голосов, но зато по числу копирований занимает шестое место.










Refridgerator
Я однажды скопировал код со Stack Overflow, а он оказался с подвохом — вместо метода ToArray() в нём использовался GetBuffer(), что в 2 раза увеличивало размер сериализуемого объекта. Обнаружил это случайно при отладке много лет позже.
fedorro
Если это про MemoryStream, то ToArray — это байты которые в него записали, а GetBuffer — это весь буфер, в том числе нулевые байты, мусор, или ещё что там могло быть. Так что не просто «увеличивало размер в два раза», а записывало помимо самих данных ещё много чего лишнего.
Refridgerator
Я не стал об этом писать, потому что это и так очевидно. К слову, мусора там не было — только нули. Как и должно быть, потому c# всё по умолчанию инициализирует нулями.