

В прошлый раз мы с вами научились делать параллельные книги и сделали русско-английский вариант отрывка романа Харпер Ли "Убить пересмешника". Сегодня мы сделаем следующий шаг и создадим полноценную многоязычную книгу на восьми языках.
Напомню, что целью этого проекта является создание инструмента, который поможет людям, изучающим и преподающим иностранные языки, создавать учебные материалы и параллельные книги для улучшения навыков чтения. Глобальная проблема состоит в том, что трудно найти интересный для изучения материал с параллельным переводом, тогда как найти книгу в оригинале и ее русскую редакцию по отдельности гораздо проще.
Семь книг
Проделаем все на примере романа Булгакова "Мастер и Маргарита", потому что он очень популярен в мире и был переведен на множество языков. Я нашел его версии на английском и немецком (германские языки); белорусском, чешском и украинском (славянские языки); а также на венгерском и китайском языках. Все семь текстов мы выровняем с русским оригиналом, получим семь книг. Затем выровняем их между собой и получим возможность выбирать любые комбинации языков для своей книги в любом порядке. Полные версии книг можно будет скачать в формате pdf в конце статьи.
Начнем с пары венгерский-русский.

Шаг 1. Подготовка текстов
Кратко напомню основные правила подготовки текстов (подробнее смотрите в первой статье, ссылку найдете ниже).
Правила
- Удалить заведомо лишние строки (информацию об издателе, посвящение, номера страниц, примечания).
- Проставить метки для автора и названия.
- Проставить метки для заголовков (H1 самый большой, H5 самый маленький), количество заголовков в текстах должно быть одинаковым.
- Убедиться, что в тексте нет строк, которые кончаются точкой и при этом не являются концом абзаца (иначе целый абзац разобьется в этом месте на два).
Четвертое правило можно соблюсти для одного текста, так как при создании книги можно будет выбрать на основе какого из них брать информацию о разбиении на абзацы. В нашем случае возьмем русский, потому что мы будем выравнивать все остальные тексты к нему. К тому же для найденного мной оригинального текста это правило уже соблюдено.
Метки
Язык разметки представляет из себя набор меток, которые ставятся в конце предложения:
| Метка | Значение | Установка |
|---|---|---|
| %%%%%title. | Название произведения | Вручную |
| %%%%%author. | Автор | Вручную |
| %%%%%h1. %%%%%h2. %%%%%h3. %%%%%h4. %%%%%h5. | Заголовки | Вручную |
| %%%%%divider. | Разделитель | Вручную |
| %%%%%. | Новый абзац | Автоматически |
Благодаря меткам мы извлечем из сырого текста данные о названии произведения, его авторе, названии и местонахождении глав. Это понадобится нам при создании книги.
Текст
В результате должны получиться тексты, похожие на следующие:
Мастер и Маргарита%%%%%title.
М.А. Булгаков%%%%%author.
ЧАСТЬ ПЕРВАЯ%%%%%h1.
Глава 1%%%%%h2.
Никогда не разговаривайте с неизвестными%%%%%h2.
Однажды весною, в час небывало жаркого заката, в Москве, на Патриарших прудах, появились два гражданина. Первый из них, одетый в летнюю серенькую пару, был маленького роста, упитан, лыс, свою приличную шляпу пирожком нес в руке, а на хорошо выбритом лице его помещались сверхъестественных размеров очки в черной роговой оправе. Второй – плечистый, рыжеватый, вихрастый молодой человек в заломленной на затылок клетчатой кепке – был в ковбойке, жеваных белых брюках и в черных тапочках.
...MIHAIL BULGAKOV%%%%%author.
A MESTER ES MARGARITA%%%%%title.
ELSO KONYV%%%%%h1.
ELSO FEJEZET%%%%%h2.
Ne alljunk szoba ismeretlenekkel%%%%%h2.
Egy meleg tavaszi esten, az alkonyat orajaban, a Patriarsije Prudin ket ferfiu
jelent meg. Az egyik negyveneves forma, koverkes, alacsony, kopasz fekete
emberke, szurke nyari oltonyt viselt, elegans kalapjat kezeben tartotta, gondosan
borotvalt arcat istentelen nagy meretu, fekete csontkeretes papaszem ekesitette.
Tarsa joval fiatalabb s vallasabb volt nala, borzas hajan tarkojaig hatratolt kockas
sapka; oltozeke kockas sportingbol, gyurott feher nadragbol, fekete szandalbol
allt.
...Количество меток одного типа должно быть одинаковым среди всех текстов. Иначе где-то будет номер и название главы, а где-то нет. После того как мы приготовили тексты, переходим к выравниванию.
Шаг 2. Выравнивание
Как и в прошлый раз, выравнивать будем библиотекой lingtrain-aligner. Код открыт, так что приглашаю в репозиторий.
Попробовать в Colab
Чтобы попробовать выровнять свои тексты без написания кода используйте вот этот Colab блокнот, который мы использовали в прошлый раз. В нем есть инструкции и некоторые комментарии к процессу. В конце можно будет скачать получившуюся двуязычную параллельную книгу как html страничку.
Попробовать локально
pip install lingtrain-alignerСначала немного служебного кода:
# Импортируем необходимые модули
from lingtrain_aligner import preprocessor, splitter, aligner, resolver, reader, vis_helper
# Подготовленные тексты для выравнивания
text1_input = "master_hu.txt"
text2_input = "master_ru.txt"
with open(text1_input, "r", encoding="utf8") as input1:
text1 = input1.readlines()
with open(text2_input, "r", encoding="utf8") as input2:
text2 = input2.readlines()
# Путь до самого главного файла, в котором будет содержаться вся информация о выравнивании
db_path = "master_hu.db"
# Определим языки (важно для разбиения на предложения)
lang_from = "hu"
lang_to = "ru"
# Выберем модель
models = ["sentence_transformer_multilingual", "sentence_transformer_multilingual_labse"]
model_name = models[0]
# Добавим метки абзацев
text1_prepared = preprocessor.mark_paragraphs(lines1_prepared)
text2_prepared = preprocessor.mark_paragraphs(lines2_prepared)
# Разобьем тексты на строки
splitted_from = splitter.split_by_sentences_wrapper(lines1_prepared, lang_from, leave_marks=True)
splitted_to = splitter.split_by_sentences_wrapper(lines2_prepared, lang_to, leave_marks=True)Итого у нас получилось 9460 предложений на венгерском и 8996 предложений на русском. Их-то мы и хотим сопоставить друг другу таким образом, чтобы ничего не потерялось.
Создадим файл для выравнивания. Это SQLite база данных, которую мы заполним входными данными, для дальнейшей обработки.
aligner.fill_db(db_path, lang_from, lang_to, splitted_from, splitted_to)Чтобы выровнять первую тысячу строк, выполним следующую команду:
batch_ids = range(10)
aligner.align_db(db_path,
model_name,
batch_size=100,
window=60,
batch_ids=batch_ids,
save_pic=False,
embed_batch_size=25,
normalize_embeddings=True,
show_progress_bar=True
)Произойдет следующее — мы запустим процесс выравнивания (детали смотрите в предыдущей статье), для 10 отрезков (batch_ids — их номера) по 100 предложений (параметр batch_size). Параметр window задает "перехлест" между этими кусками, чтобы наверняка захватить целевые предложения. В данном случае этот параметр довольно большой, потому что на протяжении всей книги наша "ось выравнивания" может довольно значительно отклоняться.
В качестве спойлера скажу, что для большинства языков в данном случае такие настройки подойдут для всей книги. Для некоторых же текстов отклонения будут слишком сильными и нужно будет либо делать окно очень большим (это приведет к большему количеству ошибок и отрицательно скажется на качестве), либо двигаться медленнее и использовать параметр shift (о нем ниже).
Визуализация
Теперь у нас есть возможность посмотреть на результат первичного выравнивания при помощи модуля vis_helper:
vis_helper.visualize_alignment_by_db(db_path,
output_path="alignment_vis.png",
batch_size=100,
size=(800,800),
lang_name_from=lang_from,
lang_name_to=lang_to,
batch_ids=batch_ids,
plt_show=True)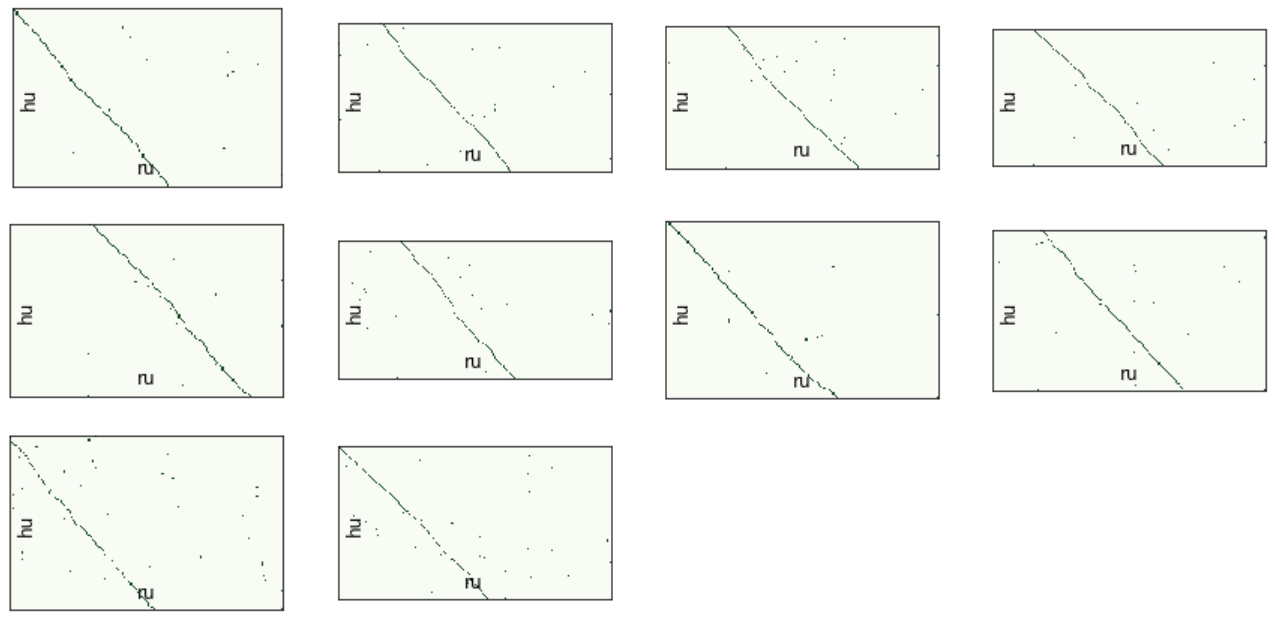
В параметр batch_ids мы передали те же номера батчей, что и при выравнивании. Если не передавать ничего, то получим картинки для всех данных.
Мы видим, что модель справилась довольно неплохо. Главное здесь, чтобы "ось выравнивания" не вышла за пределы окна, иначе модель не получит на вход отрезок со всеми правильными вариантами.
Теперь необходимо поставить на место выбросы.
Разрешение конфликтов
Механим разрешения конфликтов заключен в модуле resolver. Подробнее о нем, опять же, смотрите в предыдущей статье. Скажу лишь, что он находит промежутки между удачными отрезками выравнивания, и пытается подобрать для этих промежутков подходящий вариант разрешения. Соответственно, параметрами мы можем задавать минимальную длину хорошей цепочки и максимальную длину для конфликта. На практике, хорошо работает такой подход — трижды проходим по всему выравниванию с постепенным увеличением максимальной длины конфликта:
steps = 3
batch_id = -1 #пройти по всем батчам
for i in range(steps):
# Найти конфликты
conflicts, rest = resolver.get_all_conflicts(db_path, min_chain_length=2+i, max_conflicts_len=6*(i+1), batch_id=batch_id)
# Показать какие конфликты найдены
resolver.get_statistics(conflicts)
resolver.get_statistics(rest)
# Разрешить конфликты
resolver.resolve_all_conflicts(db_path, conflicts, model_name, show_logs=False)
if len(rest) == 0:
breakВ конце могут остаться единичные конфликты. Если такие есть, то добиваем их:
# Найти конфликты
conflicts, rest = resolver.get_all_conflicts(db_path, min_chain_length=2, max_conflicts_len=20, batch_id=-1)
# Показать какие конфликты найдены
resolver.get_statistics(conflicts)
resolver.get_statistics(rest)
# Разрешить конфликты
resolver.resolve_all_conflicts(db_path, conflicts, model_name, show_logs=False)
# Визуализировать выравнивание
vis_helper.visualize_alignment_by_db(db_path,
output_path="alignment_vis.png",
batch_size=100,
size=(800,800),
lang_name_from=lang_from,
lang_name_to=lang_to,
batch_ids=batch_ids,
plt_show=False)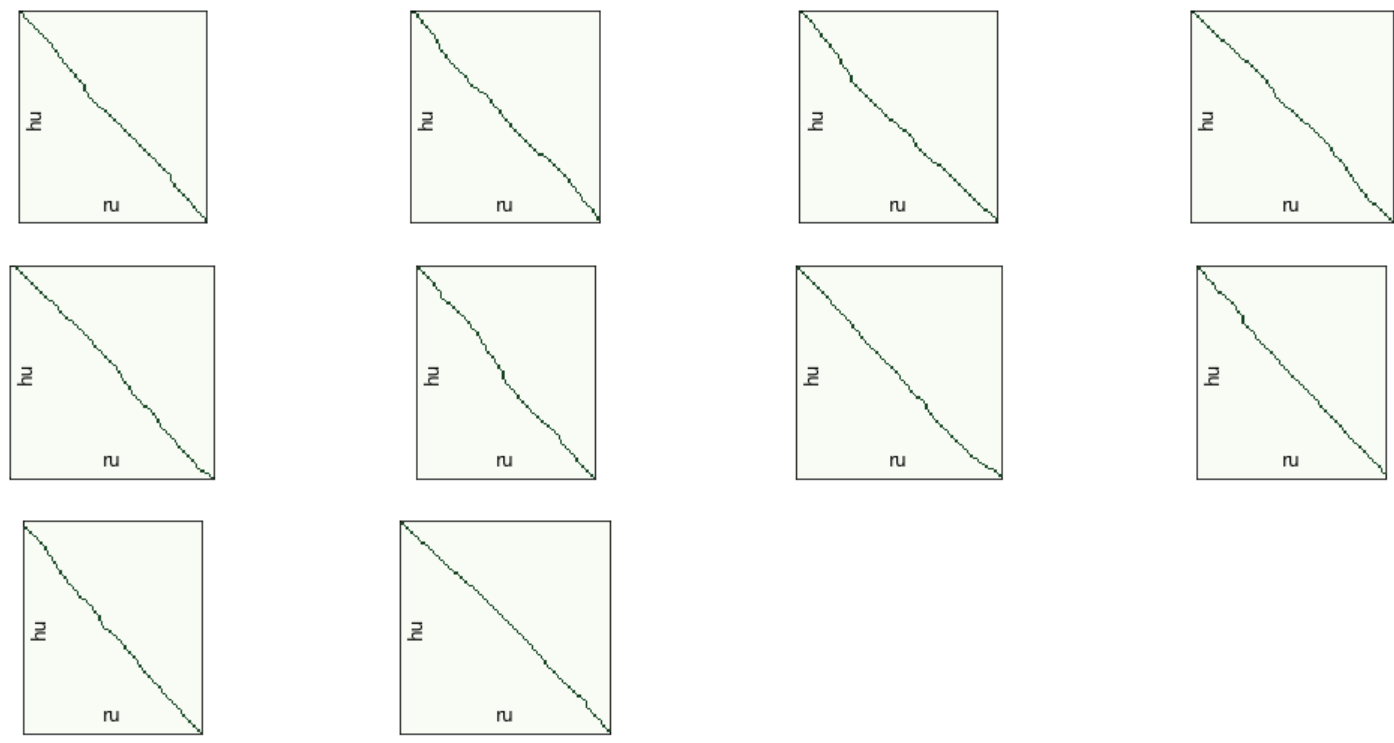
Цикл
Мы выровняли часть книги. Для продолжения выполним те же дейсвтия, но с другими батчами. Возьмем следующие 4000 строк. Мы выравнивали 10 кусков по 100 предложений, поэтому выполним следующую команду:
batch_ids = range(10, 50)
aligner.align_db(db_path, model_name, batch_size=100, window=60, batch_ids=batch_ids, save_pic=False,
embed_batch_size=25, normalize_embeddings=True, show_progress_bar=True
)После выравнивания этого куска (это займет чуть больше времени, на моем компьютере это около пяти минут) переходим к разрешению конфликтов, как было описано выше. Затем дальше, задавая новый диапазон строк. Так как предложений на венгерском у нас 9460, а разбитие идет по первому из заданных текстов, то батчей по 100 предложений у нас будет 95 штук.
Если задать диапазон
batch_ids = range(50, 100)то мы выровняем остаток (вторую половину) книги. После разрешения всех конфликтов у нас останется файл master_hu, содержащий в себе венгерско-русскую версию "Мастера и Маргариты".
Шаг 3. Создание двуязычной книги
Теперь, если мы воспользуемся модулем reader, то сможем сгенерировать русско-венгерскую редакцию книги:
from lingtrain_aligner import reader
# Читаем из абзацы и метаданные
paragraphs_from, paragraphs_to, meta = reader.get_paragraphs(db_path, direction="from")
# Создаем html с нашей книгой
reader.create_book(paragraphs_from, paragraphs_to, meta, output_path = "lingtrain.html")
Это обыкновенная html страничка со встроенными стилями. Для визуализации связей между предложениями можно задавать стили. Например, такой:
reader.create_book(paragraphs_from, paragraphs_to, meta, output_path = f"lingtrain.html", template="pastel_fill")
Можно задавать свои стили, они будут применены к предложениям каждого абзаца циклически:
# Любые применимые к span'ам стили
my_style = [
'{"background": "linear-gradient(90deg, #FDEB71 0px, #fff 150px)", "border-radius": "15px"}',
'{"background": "linear-gradient(90deg, #ABDCFF 0px, #fff 150px)", "border-radius": "15px"}',
'{"background": "linear-gradient(90deg, #FEB692 0px, #fff 150px)", "border-radius": "15px"}',
'{"background": "linear-gradient(90deg, #CE9FFC 0px, #fff 150px)", "border-radius": "15px"}',
'{"background": "linear-gradient(90deg, #81FBB8 0px, #fff 150px)", "border-radius": "15px"}'
]
reader.create_book(paragraphs_from, paragraphs_to, meta, output_path = f"lingtrain.html", template="custom", styles=my_style)
Выравниваем остальные книги
Таким образом, повторяя третий шаг для остальных текстов, мы получим помимо файла master_hu.db остальные шесть. Отмечу некоторые трудности, с которыми я столкнулся (и, вероятно, столкнетесь вы, когда будете выравнивать свою книгу).
Большая разница в количестве предложений
В английской редакции большое количество предложений в диалогах было переведено как отдельные части, тогда как в оригинале это была прямая речь.
1. – Фу ты черт! – воскликнул редактор, – ты знаешь, Иван, у меня сейчас едва удар от жары не сделался!
2. - Даже что-то вроде галлюцинации было, – он попытался усмехнуться, но в глазах его еще прыгала тревога, и руки дрожали.1. 'Pah, the devil!' exclaimed the editor.
2. 'You know, Ivan, I nearly had heat stroke just now!
3. There was even something like a hallucination...'
4. He attempted to smile, but alarm still jumped in his eyes and his hands trembled.В итоге имеем 9707 предложений на английском против 8996 на русском. Это довольно большое различие, поэтому после первичного выравнивания с параметром window=100 получаем более 1000 конфликтов.

К счастью, после разрешения конфликтов эти кусочки все равно склеятся обратно.

Такая же ситуация с китайским языком, там в целом есть тенденция перевода более короткими предложениями чем в оригинале.
Выход за пределы окна
Упомяну польский текст, который тоже был найден, но не подошел по следующей причине. В польском тексте (8190 предложений) у нас слишком часто отсутствуют целые куски текста. Поток выравнивания получается местами обрывистым и окна в 100 уже не хватает, — мы постоянно выходим за его пределы:
batch_ids = range(10,12)
aligner.align_db(db_path, model_name, batch_size=200, window=100, batch_ids=batch_ids, save_pic=False,
embed_batch_size=25, normalize_embeddings=True, show_progress_bar=True
)
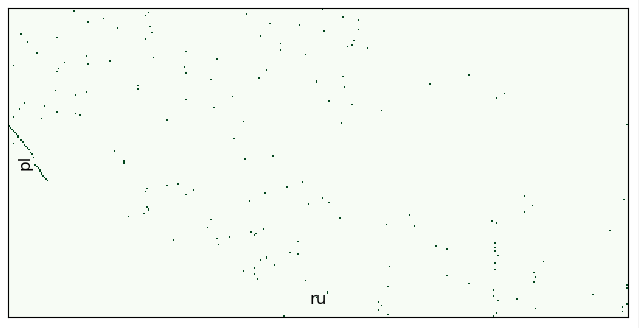
Дальнейшее расширение окна увеличит процент ошибок, поэтому мы перейдем в ручной режим и задействуем параметр shift. Этот параметр позволяет сдвигать поток второго текста при расчете батча:
batch_ids = range(10,12)
aligner.align_db(db_path, model_name, batch_size=200, window=100, batch_ids=batch_ids, save_pic=False,
embed_batch_size=25, normalize_embeddings=True, show_progress_bar=True,
shift=-100 #сдвигаем русский текст
)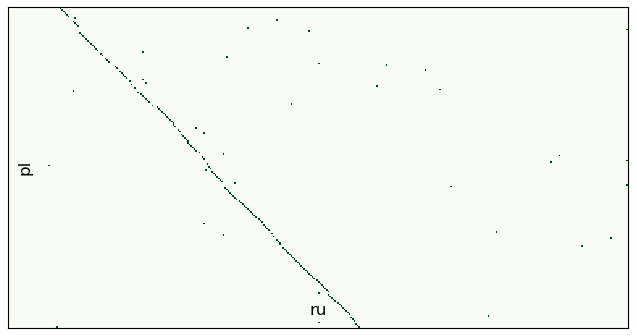

Плюсом такого подхода является то, что мы можем уменьшить окно, улучшив первоначальное качество. Минусом является большее количество итераций.
После разрешения конфликтов эти же куски выглядят так:


Отсутствие частей текста
Ручной режим не поможет нам восстановить разрывы, если в каком-то тексте нет соответствующего куска:


Разрешение таких конфликтов приведет к тому, что какому-то предложению станет соответствовать большой отрывок текста на другом языке. Если таких ситуаций одна-две на весь текст (так было с английским и белорусским текстами), то, в принципе, ничего страшного. В случае польского же отсутствовало более 20 отрывков, поэтому я решил его не добавлять.
Второй уровень выравнивания
К этому моменту мы получили семь файлов с выравниваниями master_*.
Их особенностью является то, что все они выровнены относительно одного языка (русского). Казалось бы, давайте просто возьмем абзацы и сходу получим необходимые локализации.
Делаем так и спустя несколько страниц получаем вот это:

Дело в том, что в некоторых текстах (на рисунке это немецкий) одно предложение могло соответствовать двум русским. Если при этом русские предложения считались разными абзацами, то эти абзацы будут слиты в один. Поэтому в обычной двуязычной книжке все будет хорошо, но относительно друг друга структура абзацев у выравниваний будет отличаться. На помощь приходят метаданные, которые хранятся в базе (наши *.db файлы).
Метаданные
В метаданных хранится информация о том, какое предложение какому абзацу соответствует. Можно получить структуру абзацев для каждого текста в виде массива чисел, показывающих номер последнего предложения в абзаце.
Эти массивы можно слить в один по принципу объединения более мелких интервалов:
par_struct_1 = [2, 5, 6, 8, 10, 12, ...]
par_struct_2 = [2, 6, 8, 10, 11, 12, ...]
res = [2, 6, 8, 10, 12, ...]Сгенерируем книгу на основе новой разбивки, получим следующий результат:

Стало выглядеть лучше, теперь абзацы формируются относительно русского языка на единой основе.
Индекс
Абзацы починили, но обратим внимание на подсветку предложений и увидим, что во многих местах она разъехалась:

Причина этого в том, что разные тексты имеют разные тенденции по делению на предложения. Чтобы синхронизировать еще и их, придется немного повозиться со следующей сущностью, — с индексом.
На архитектурном этапе я придумал хранить структуру выравнивания как индекс. После выравнивания он выглядит он так:
[
--первый батч
[
--первая пара предложений корпуса
[1, "[1,2]", 1, "[1]"],
--вторая и т.д.
[2, "[3]", 2, "[2]"],
[3, "[4,5]", 3, "[3]"],
[4, "[6]", 4, "[4,5,6]"],
...
],
--второй батч
[
[1, "[100]", 1, "[105]"],
...
],
...
]В этом примере в первом элементе мы склеили два оригинальных предложения "левого" текста и сопоставили ему первое предложение "правого". Числа в кавычках — ссылки на оригинальные предложения, вне кавычек — ссылки на фактические данные, которые можно редактировать.
Такая структура дает много возможностей:
- сохраняется информация о слиянии оригинальных строк
- можно добавлять новые элементы в любое место без перезаписи идентификаторов фактических строк
- можно удалять элементы из параллельного корпуса, удалив только из индекса
- можно редактировать данные, не меняя оригинальные строки
- можно пересчитывать отдельные батчи, не затрагивая остальные
Главное для нас здесь то, что из индекса мы можем вытащить структуру элемента корпуса относительно русского языка. Сопоставляя абзацы друг другу, мы опять будем сливать по минимальному принципу. В результате получим разбивку такого типа:
[[1], [2], [3]] -> [[1, 2, 3], [4], [5]] -> [[1], [2], [3]]
[[4]] -> [[6]] -> [[4]]
[[5]] -> [[7]] -> [[5, 6]]
...Здесь каждая строка — это абзац на трех языках, каждый подмассив а абзаце — это номера строк из целевого текста. Таким образом мы поделили каждый набор абзацев на одинаковое число соответствующих друг другу частей.
После исправлений
Посмотрим, как станет выглядеть подсветка теперь:

Так как мы объединяем структуру по минимальному принципу (в данном примере в китайском было меньше всего предложений на абзац), то подсветка стала ровнее, но беднее. Если убрать китайский, то она станет выглядеть так:

Шаг 4. Создание многоязычной книги
В большинстве случаев будет достаточно создания двуязычной параллельной книги и методов get_paragraphs() и create_book(). Но если вы дочитали до этого момента, то самое время попробовать сделать многоязычную книгу.
Логика по выравниванию абзацев для многоязычных книг содержится в методе get_paragraphs_polybook(), в который мы передадим все наши файлы. Так как при выравнивании система опирается на номера исходных строк, то в файлах не должно остаться конфликтов, иначе абзацы не будут сгенерированы. Проверить на отсутствие конфликтов можно таким кодом (как их разрешать вы уже знаете):
from lingtrain_aligner import resolver
conflicts_to_solve, rest = resolver.get_all_conflicts(db_path, min_chain_length=2, max_conflicts_len=20, batch_id=-1)
#перед генерацией не должно остаться никаких конфликтов
resolver.get_statistics(conflicts_to_solve)
resolver.get_statistics(rest)Далее получим набор подготовленных текстов на всех нужных языках:
from lingtrain_aligner import reader
db_path1 = "db/master_de.db"
db_path2 = "db/master_uk.db"
db_path3 = "db/master_be.db"
db_path4 = "db/master_zh.db"
db_path5 = "db/master_cz.db"
db_path6 = "db/master_en.db"
db_path7 = "db/master_hu.db"
paragraphs, metas = reader.get_paragraphs_polybook(
db_paths=[db_path1, db_path2, db_path3, db_path4, db_path5, db_path6, db_path7])Теперь самое интересное, — мы можем выбрать нужные нам языки и создать нашу книжку. Можно, например, взять английский и немецкий, многие учат эти языки в паре.
reader.create_polybook(
lang_ordered=["en", "de", "ru"],
paragraphs = paragraphs,
delimeters = delimeters,
metas = metas,
output_path = "lingtrain_master.tml",
template="none")
Параметр lang_ordered задает набор и порядок языков.
Можно сделать белорусско-китайскую версию:
reader.create_polybook(
lang_ordered=["be", "zh"],
paragraphs = paragraphs,
delimeters = delimeters,
metas = metas,
output_path = "lingtrain_master.html",
template="none")
Можно, конечно, и всё взять:
reader.create_polybook(
lang_ordered = ["ru", "en", "de", "be", "uk", "cz", "hu", "zh"],
paragraphs = paragraphs,
delimeters = delimeters,
metas = metas,
output_path = "lingtrain_master_total.html",
template="none")
Лучше оставлять те выравнивания (*.db файлы), языки которых, вам нужны. Это позволит сохранить как можно больше информации об абзацах. Со стилями все как раньше, можете задавать template (сейчас есть "pastel_fill", "pastel_start"), можете придумывать свои, — примеры есть выше и в блокноте на Colab. Если задать template="none", получится чистая книга.
Планы и поддержка
- Дальше планируется поддержать fb2 формат для читалок и добавить подстрочный перевод. Также хочу расширить возможности разметки, добавить вставку картинок. Затем оформить это в виде веб-приложения, чтобы люди могли создавать книги без написания кода.
- Скидывать тексты для тестирования и выравнивания, делиться предложениями и багами можно в канале http://t.me/lingtrain_books.
- Подержать проект финансово можно переводом. Деньги пойдут на хостинг веб-приложения и ускорят его разработку.
Ссылки
Все упомянутые в статье ссылки:
[2] Код lingtrain-aligner на github
[3] Google Colab блокнот с выравниванием
[4] Кот Бегемот с обложки был найден здесь
[5] PDF. Семь параллельных книг "Мастер и Маргарита"
[6] Телеграм-группа


NeoCode
Интересно, а какой нибудь классической оффлайн софтины для этого нет? Т.е. загружаешь две pdf-ки (txt, fb2, ...) в две части окна, и далее мышью сопоставляешь абзацы (с возможностью разбить абзац на два, склеить из двух один, пропустить кусок и т.п.)
averkij Автор
Это будет довольно долгий процесс. 3000 тысячи абзацев с одной стороны, 3500 с другой (на языке, который вы только изучаете). Мышь в руку и вперёд :)