

Градиентный спуск
Предполагается, что вы знакомы с понятием нейронной сети, вы имеете представление, какие задачи можно решать с помощью этого алгоритма машинного обучения и что такое параметры (веса) нейронной сети. Также, важно понимать, что градиент функции — это направление наискорейшего роста функции, а градиент взятый с минусом это направление наискорейшего убывания.  — это антиградиент функционала,
— это антиградиент функционала,
где  — параметры функции (веса нейронной сети),
— параметры функции (веса нейронной сети),  — функционал ошибки.
— функционал ошибки.
Обучение нейронной сети — это такой процесс, при котором происходит подбор оптимальных параметров модели, с точки зрения минимизации функционала ошибки. Иными словами, осуществяется поиск параметров функции, на которой достигается минимум функционала ошибки. Происходит это с помощью итеративного метода оптимизации функционала ---градиентного спуска. Процесс может быть записан следующим образом:


где  — это номер шага,
— это номер шага,  — размер шага обучения (learning rate). В результате шага оптимизации веса нейронной сети принимают новые значения.
— размер шага обучения (learning rate). В результате шага оптимизации веса нейронной сети принимают новые значения.
Виды градиентного спуска
- Пакетный градиентный спуск (batch gradient descent).
При этом подходе градиент функционала обычно вычисляется как сумма градиентов, учитывая каждый элемент обучения сразу. Это хорошо работает в случае выпуклых и относительно гладких функционалов, как например в задаче линейной или логистической регрессии, но не так хорошо, когда мы обучаем многослойные нейронные сети. Поверхность, задаваемая функционалом ошибки нейронной сети, зачастую негладкая и имеет множество локальных экстремумов, в которых мы обречены застрять, если двигаться пакетным градиентным спуском. Также обилие обучающих данных, делает задачу поиска градиента по всем примерам затратной по памяти.
- Стохастический градиентный спуск (stochastic gradient descent)
Этот подход подразумевает корректировку весов нейронной сети, используя аппроксимацию градиента функционала, вычисленную только на одном случайном обучающем примере из выборки. Метод привносит «шум» в процесс обучения, что позволяет (иногда) избежать локальных экстремумов. Также в этом варианте шаги обучения происходят чаще, и не требуется держать в памяти градиенты всех обучающих примеров. Под SGD часто понимают подразумевают описанный ниже.
- Mini-batch градиентный спуск
Гибрид двух подходов SGD и BatchGD, в этом варианте изменение параметров происходит, беря в расчет случайное подмножество примеров обучающей выборки. Благодаря более точной аппроксимации полного градиента, процесс оптимизации имеет большую эффективность, не утрачивая при этом преимущества SGD. Поведение трёх описанных варианта хорошо проиллюстрировано на картинке ниже.
 Источник
ИсточникВ общем случае, при работе с нейронными сетями, веса оптимизируют стохастическим градиентным спуском или его вариацией. Поговорим о двух модификациях, использующих скользящее среднее градиентов.
SGD с импульсом и Nesterov Accelerated Gradient
Следующие две модификации SGD призваны помочь в решении проблемы попадания в локальные минимумы при оптимизации невыпуклого функционала.
Гладкая выпуклая функция

Функция с множеством локальных минимумов (источник)
Первая модификация
При SGD с импульсом (или SGD with momentum) на каждой новой итерации оптимизации используется скользящее среднее градиента. Движение в направлении среднего прошлых градиентов добавляет в алгоритм оптимизации эффект импульса, что позволяет скорректировать направление очередного шага, относительно исторически доминирующего направления. Для этих целей достаточно использовать приближенное скользящее среднее и не хранить все предыдущие значения градиентов, для вычисления «честного среднего».
Запишем формулы, задающие этот подход:


 — это накопленное среднее градиентов на шаге , коэфициент
— это накопленное среднее градиентов на шаге , коэфициент ![\alpha \in [0,1]](https://habrastorage.org/getpro/habr/post_images/7f7/a58/e2b/7f7a58e2b810330107d983e85ffd1b0e.svg) требуется для сохранения истории значений среднего (обычно выбирается близким к
требуется для сохранения истории значений среднего (обычно выбирается близким к  .
.
Вторая модификация
Nesterov accelerated gradient отличается от метода с импульсом, его особенностью является вычисление градиента при обновлении в отличной точке. Эта точка берётся впереди по направлению движения накопленного градиента:

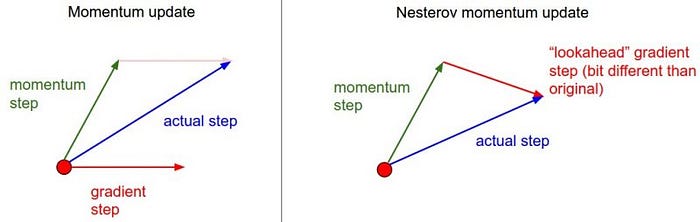
На картинке изображены различия этих двух методов.
источник
Красным вектором на первой части изображено направление градиента в текущей точке пространства параметров, такой градиент используется в стандартном SGD. На второй части красный вектор задает градиент сдвинутый на накопленное среднее. Зелеными векторами на обеих частях выделены импульсы, накопленные градиенты.
Заключение
В этой статье мы детально рассмотрели начала градиентного спуска с точки зрения оптимизации нейронных сетей. Поговорили о трёх разновидностях спуска с точки зрения используемых данных, и о двух модификациях SGD, использующих импульс, для достижения лучшего качества оптимизации невыпуклых и негладких функционалов ошибки. Дальнейшее изучение темы предполагает разбор адаптивных к частоте встречающихся признаков подходов таких как Adagrad, RMSProp, ADAM.
Данная статья была написана в преддверии старта курса «Математика для Data Science» от OTUS.
Приглашаю всех желающих записаться на demo day курса, в рамках которого вы сможете подробно узнать о курсе и процессе обучения, а также познакомиться с экспертами OTUS
— ЗАПИСАТЬСЯ НА DEMO DAY
fivehouse
Хотелось бы упомянуть, что в природных нейронных сетях нет никаких оптимизаторов. Что никак не мешает им обучаться в тысячи раз быстрее и точнее искусственных и на существенном меньших объемах данных. Видимо нужна статья где рассматриваются существенные различия природных и искусственных нейронных сетей.
zetyquickly Автор
Согласен, очень интересный вопрос, насколько похожи математические нейронные сети, созданные человеком, и сети в головах животных
defuz
fivehouse
:) Ой зря вы все это спросили.
Первые попытки встать на ноги человек делает где-то в период от полугода до года. И к 8-12 месяцам (за 3 месяца самообучения) почти все ходят достаточно внятно. Попытки меряются не минутами, а сессиями и количеством попыток. В среднем по 10-20 попыток в день дает 900-1800 попыток. За эти сессии достигается уровень, который и не снился существующим искусственным нейронным сетям ни за какое время потраченное ими. А человек продолжает обучаться и обучаться. Самообучается танцевать, бегать, прыгать и еще бог знает чему, на что в принипе не способна современная искусственная нейронная сеть.А вот для детенышей антилоп разница еще более впечатляющая. Детеныш уже через 1 час самообучения после рождения может идти со скоростью матери по природной среде. Через день самообучения детеныш достигает невероятных высот и навыков движения. И все это без каких либо оптимизаторов.
Достаточно посмотреть 2-3 картинки в течение 5 минут любого вида, чтобы потом никогда не спутать его ни с каким другим видом.
Не корректное сравнение. Ни одна искусственная нейронная сеть не знает и не понимает ни одного языка ни на каком уровне. В отличии от половины людей в возрасте 2-3х лет уже что-то говорящих. В мультиязычных средах и семьях дети за этот же период на базовом уровне выучивают по два-три языка. К четырем-пяти годам они полноценно говорят на всех языках входящих в мультиязычную среду. И все это без каких либо оптимизаторов. Ни одна искусственная нейронная сеть в мире не в состоянии полноценно выполнять переводы.
И да… Я, как и вы, не просто нейронная сеть. Множество ключевых блоков, которые есть в моем и вашем мозгу, в принципе не представимы современными искусственными нейронными сетями. Ни с какими оптимизаторами.
defuz
В своих рассуждениях вы упускаете важный момент: хотя человеку, казалось бы, нужно меньше попыток при обучении по-новому пользоваться своим телом (или изучить новый язык), все это происходит отнюдь не на пустом фундаменте.
Ох уже это глубокое и неуловимое «понимание смысла». Готовы дать строгое определение, что вообще это значит, чтобы наша дискуссия обрела, ну, смысл? Иначе получается что вы приводите в качестве достоинства некоторое субъективное ощущение, а не объективный фактор.Вы же не забыли внезапно как пользоваться ногами, как удерживать равновесие и где в вашем зрении верх, а где низ, когда впервые стали на лыжи, верно? Человеческая нейросеть учиться непрерывно по 16 часов каждый день годами (и еще оптимизирует усвоенные данные во сне), и только спустя 15-20 лет превращается в полноценного сознательного индивида, которого мы любим сравнивать с искусственными нейронными сетями.
Искусственные нейронные сети как правило начинают обучаться вообще с нуля буквально всему. И это не говоря уже о том, что многие навыки даны нам в виде безсознательных рефлексом (пример с антилопами отлично здесь подходит), что является просто читерством при сравнении с нейронными сетями.
Почему это? Может они делает это не совсем так же как это делают люди, но это не умаляет их достоинств. По многим критериям они уже превзошли людей переводчиков (из самого банального – словарная база). Вопрос около 5-10 лет, когда ни один человек в мире не сможет сравнится с искусственным интеллектом в этом состязании ни одному из критериев. А еще через 5 лет нейронная сеть будет способна сымитировать перевод любого из переводчиков, который вам больше нравится, да так что сам переводчик не поймет, его это перевод, или нет.
Готовы это доказать?
Любая нейронная сеть, это, по определению, большой аппроксиматор, оптимизированный для достижения поставленной цели с минимальным энергопотреблением.
Вот только ирония что мозг (не только человека, а любой) – это такой же оптимизатор, направленный на увеличение вероятности выживания при минимальном энергопотреблении, при чем буквально.
fivehouse
И это проблема искусственных нейронных сетей. Кто мешает это изменить?
Не согласен с последним утверждением. Мы ведем речь об обучении конкретному навыку — ходьбе. Если бы антилопа могла получать сразу все необходимые навыки для ходьбы, то антилопа сразу рождалась бы уже умеющая ходить. Но она именно учится. И снова же! В любом случае можно утверждать о принципиальной недостижимости результатов искусственными нейронными сетями, которые достигнет антилопа.Вы смело манипулируете предметом обсуждения, а от меня требуете строгих определений. Забавно. Тем не мение, я постараюсь дать определение.
Вообще «понимания смысла» не существует. Можно понимать смысл сообщения, смысл концепции, понимать язык.
Понимание сообщения это способность использовать сообщенную информацию в дальнейших рассуждениях.
Понимание концепции/слова это способность правильно использовать концепцию в общих рассуждениях, павильно строить словесные модели с использованием концепции.
Понимание языка это способность воспринимать и строить модели окружающего мира на этом языке.
Ох уж эти линейные экстраполяции в нелинейном мире.
— Дорогая, ты очень развратна и аморальна.
— Это еще почему?
— Вчера у тебя не было ни одного мужа. А сегодня один. Если ты что-то в себе не изменишь, то через год у тебя будет 365 мужей. Это очень аморально.
Фантазировать о будущем можно бесконечно.
Самое простое доказательство — это примитивные результаты не смотря на потраченные миллиарды денег. Также я утверждаю, что искусственные сети в том виде в котором они сейчас есть — это тупиковая ветвь развития.
Любой камень можно представить себе машиной, человеком и даже мозгом. При столь широких обобщениях утверждения начинают терять смысл. Статья же о математическом многомерном оптимизаторе. В реальном мозгу его нет. И мозг достигает гораздо большего, что наши недосети с оптимизаторами.