
В этом посте представлен перевод статьи на Medium от Sarah Wooders, Peter Schafhalter, and Joey Gonzalez. Перевод подготовлен при поддержке сообщества аналитического курса DataLearn и телеграм-канала Инжиниринг Данных
Нам нужен обоснованный способ управления состоянием в ML конвейерах, работающих в реальном времени.

Восход* Хранилищ Признаков
По мере того как все больше моделей развертывается в современных конвейерах, снова и снова возникает понимание, что данные и их фичаризация** (featurization) важнее всего остального. Последнее поколение систем больших данных масштабировало ML на реальные датасеты, теперь хранилища данных быстро становятся новым рубежом для подключения моделей к данным в реальном времени [1].
Поддержание признаков в актуальном состоянии является критически важным для точности модели, но дорогостоящим и тяжело масштабируемым
Хранилища признаков, как следует из названия, хранят признаки, полученные из необработанных данных, и предоставляют их последующим моделям для обучения и ифнеренса***. Например, в хранилище признаков могут храниться последние несколько страниц, которые просматривал пользователь (т.е. скользящее окно по маршруту переходов по сайту), а также последние предсказанные демографические данные пользователя (т.е. предсказание некоторой модели), которые могут быть ценными признаками для модели таргетинга рекламы.
К сожалению, многие хранилища признаков, создаваемые сегодня, представляют собой Франкенштейнов из систем пакетной обработки, потоковых систем, систем кэширования и систем хранения данных.
В этом посте мы (1) определим, что такое хранилища признаков и как они используются сегодня, (2) выделим некоторые ограничения в дизайне текущего поколения хранилищ признаков и (3) опишем, как инновации в дизайне хранилищ признаков могут изменить промышленное машинное обучение, управляя состоянием в конвейерах обучения и инференса более обоснованным образом.
Примечания переводчика.
* В оригинале используется аббревиатура RISE (в переводе восход) --- Real-time Intelligent Secure Explainable Systems. Так называется лаборатория, в чьём блоге опубликована статья.
** Featurization --- термин, используемый для обозначения процесса преобразования сырых, не всегда численных, данных к виду вектора чисел, на котором модель лучше учится. Пример: векторизация слов текста с помощью TF-IDF
*** Инференс (inference) --- этап работы модели машинного обучения, на котором алгоритм используется для преобразования входных данных для получения выводов. Выводы могут принимать разную форму, от скалярной величины, характеризующей вероятность события, до многомерного тензора, представляющего собой изображение лица человека.
Предпосылки
Зачем хранилища признаков?
Простой ML конвейер обучает модель на основе статического набора данных, а затем предоставляет модель для ответа на пользовательские запросы об инференсе.

Однако для того, чтобы адаптироваться к постоянно меняющемуся миру, современные ML конвейеры должны принимать решения, которые зависят от данных в реальном времени [2]. Например, модель, предсказывающая время прибытия, может использовать такие характеристики, как время выполнения недавнего заказа в ресторане, или модель рекомендации контента может учитывать последние клики пользователя. Поэтому обучение и инференс моделей опираются на признаки, получаемые в реальном времени в результате соединения, преобразования и агрегирования входящих потоков данных. Поскольку этап фичаризации может быть дорогостоящим, признаки должны быть предварительно вычислены и закэшированы, чтобы избежать избыточных вычислений и удовлетворить жесткие требования к времени задержки предсказания.

Что такое хранилище признаков?
Хранилища признаков используются для хранения и поставки признаков в нескольких частях конвейера, что позволяет проводить совместные вычисления и оптимизацию. Хотя различные хранилища признаков различаются по своей функциональности, они обычно управляют следующим:
Поставкой признаков для удовлетворения различных требований к задержке запросов. Признаки обычно размещаются как в быстром "онлайн хранилище" (для запросов во время инференса), так и в долговечном "офлайн хранилище" (для запросов во время обучения).
Делают признаки совместимыми и дополняемыми. Как только признак определен, его должно быть легко соединить с последующими моделями, получить из него дополнительные признаки или переопределить схему признака или функцию фичаризации.
Поддержание признаков, полученных из данных реального времени. Поддержание таких характеристик требует больших ресурсов, и устаревшие характеристики могут негативно повлиять на эффективность прогнозирования.
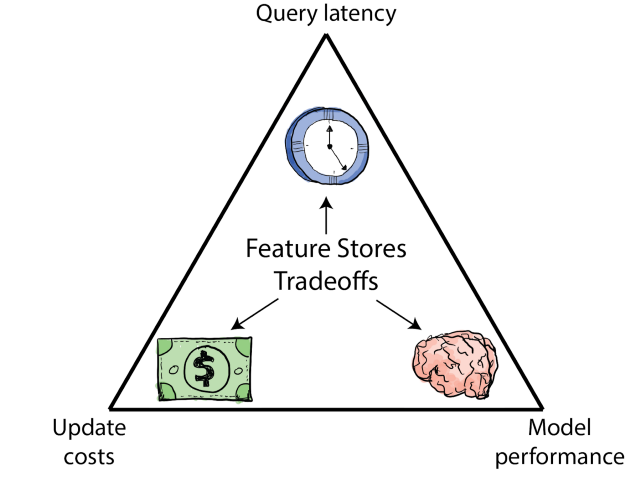
Некоторые признаки (например, результаты агрегации по временному окну длиной в 1 минуту) очень чувствительны к устареванию и должны быть сверхсвежими, в то время как другие (например, 30-дневные окна) могут нуждаться только в периодическом пакетном обновлении. Как система, которая взаимодействует как с обновлениями признаков, так и с запросами на их получение, хранилища функций имеют хороший задел на оптимальное соотношение между свежестью, задержкой и стоимостью.
Хранилища признаков сегодня: Вызовы и ограничения
На сегодня уже многие компании имеют внутренние разработки хранилищ данных. Сделано это для того, чтобы признаки были доступны для моделей, развернутых в продуктиве.
В таблице выше примеры использования хранилищ признаков
Сегодня хранилища признаков строятся на базе существующих систем потоковой передачи, пакетной обработки, кэширования и хранения данных. Хотя каждая из этих систем в отдельности решает сложные задачи, их ограничения создают проблемы для хранилищ признаков.
Системы пакетной обработки, такие как Spark, позволяют выполнять сложные запросы к статическим наборам данных, но вносят чрезмерную задержку при поставка признаков и вызывают полный перерасчет при пополнении данных.
Потоковые системы, такие как Flink и Spark Streaming, обеспечивают конвейерные вычисления с низкой задержкой, но оказываются неэффективными, когда требуется поддерживать большое количество состояний. Лямбда-архитектуры объединяют пакетные и потоковые системы, но приводят к дорогостоящим дублирующим вычислениям и сложному обслуживанию как потоковых, так и пакетных кодовых баз.
Потоковые базы данных с материализованными представлениями (materialized views) обладают преимуществами быстрого вычисления и хранения, но их трудно адаптировать к произвольным операциям фичаризации. Их задержки также могут быть слишком высокими для обслуживания предсказаний.
Хранилища в оперативной памяти типа "ключ-значение", такие как Redis, обеспечивают быстрый доступ к признакам, но их обычно сложно последовательно обновлять и дорого масштабировать.
Многие требования к хранилищам признаков можно удовлетворить с помощью комбинации этих систем. Однако полученный в результате конвейер является жестким и трудно оптимизируемым как целое. Например, определение приоритетов задач фичаризации на основе их влияния на общую точность прогнозирования потребует координации между хранилищем данных, принимающим запросы, потоковой системой, передающей обновления в реальном времени, и системой пакетной обработки исторических данных. Вместо того, чтобы неуклюже комбинировать несколько движков вычислений с несколькими базами данных для достижения различных целей по задержке, хранилища признаков должны использовать преимущества своего доступа к входящим событиям и шаблонам запросов для оптимизации задержки, стоимости вычислений и точности прогнозирования централизованным образом.
Будущее хранилищ признаков
Мы считаем, что хранилища признаков могут предложить централизованное управление состояниями для ML конвейеров и имеют большой потенциал для этого:
Управляение жизненным циклом данных (Lineage Management). Хранилища признаков открывают дверь к новой, ориентированной на данные абстракции для разработки и настройки конвейеров машинного обучения. Сложность существующих конвейеров машинного обучения часто затрудняет обеспечение базовой воспроизводимости, применение изменений в конвейере или оптимизацию всего конвейера. Хотя тщательное версионирование и синхронизация могут в определенной степени решить эти проблемы, сложно представить применении этих методов к постоянно меняющимся наборам данных. Ориентированный на данные взгляд на конвейеры (например, рассмотрение конвейеров данных как материализованных представлений) имеет потенциал для введения новых абстракций, которые упростят процесс распространения изменений данных и операторов.
Сквозная оптимизация. Хранилища признаков имеют все шансы обеспечить новую сквозную оптимизацию в конвейерах данных для машинного обучения. Существующие системы производят вычисления либо событиями, либо запросами, что затрудняет планирование задач таким образом, чтобы оптимизировать такие метрик, как производительность прогнозирования и стоимость. Специалисты-практики должны иметь возможность настраивать свои конвейеры для оптимизации затрачиваемых средств (ленивые вычисления/ обновления, приблизительные результаты), задержки выводов (немедленные вычисления) или общей производительности прогнозирования (обновление признаков с наибольшим влиянием).
Масштабируемое управление состоянием. Хранилища признаков требуют масштабируемой поддержки и сохранения состояния в конвейерах ML. Промышленные ML конвейеры, работающие в реальном времени, часто нуждаются в поддержании десятков миллионов характеристик, полученных из множества входящих плотных потоков данных. Наборы признаков могут быть слишком большими, чтобы хранить их в памяти или обновлять при каждом входящем событии из потока, как это по умолчанию делает система обработки потоков, но при этом их необходимо обновлять чаще, чем это позволяет система пакетной обработки.
Заключение
Мы активно изучаем дизайн систем хранилищ признаков, поэтому дайте нам знать, если вы заинтересованы в том, чтобы быть в курсе последних новостей или сотрудничать!
Если вы хотите принять участие в наших исследованиях, не стесняйтесь обращаться по адресу wooders@berkeley.edu.
Заметки
[1] Под "данными реального времени" мы подразумеваем данные, которые необходимо оперативно обрабатывать в режиме реального времени, как в контексте поставки прогнозов в режиме онлайн, так и для поддержания свежести данных для функций.
[2] Обновления данных "реального времени" обычно должны составлять порядка нескольких секунд, но могут варьироваться в зависимости от рабочей нагрузки.
Благодарности
Спасибо Manmeet Gujral, Gaetan Castelein, и Kevin Stumpf из Tecton, а также Joe Hellerstein, Natacha Crooks, Simon Mo, Richard Liaw, и другим членам RISELab за предоставленную обратную связь по этому посту.
Библиография
https://nchammas.com/writing/data-pipeline-materialized-view
https://scattered-thoughts.net/writing/an-opinionated-map-of-incremental-and-streaming-systems
https://doordash.engineering/2020/11/19/building-a-gigascale-ml-feature-store-with-redis/
https://netflixtechblog.com/system-architectures-for-personalization-and-recommendation-e081aa94b5d8
https://huyenchip.com/2020/12/27/real-time-machine-learning.html#stream_pipeline
dimoobraznii
Спасибо за перевод. Очень мало материалов на русском на стыке ML и data engineering. Как раз сейчас думаем строить хранилище признаков с помощью Databricks и mlflow.