

Здравствуй, читатель. Хотелось бы ненадолго отвлечь твое внимание от новостей и историй данной технической статьей. Поэтому пусть такой "кликбейтный" затравочный заголовок не вводит тебя в заблуждение.
В этой статье я расскажу как сделать параллельную книгу, имея на руках два текста на разных языках. Я написал веб-приложение, которое упрощает процесс выравнивания, превращая сырые тексты в книги и параллельные корпуса. Хочу поделиться с сообществом этим проектом, а также узнать ваше мнение. Технические детали я описывал здесь и здесь, код приложения открытый. Поехали.
Установка
Приложение я оформил в виде docker контейнера, поэтому запустить его у себя на машине не должно составить труда. Также можно запустить приложение из исходников, инструкция есть в репозитории.
Итак, для запуска приложения у себя на компьютере нужно выполнить следующие команды:
docker pull lingtrain/aligner:habr
docker run -p 80:80 lingtrain/aligner:habrКонтейнер скачается с репозитория Docker Hub и запустится на 80-м порту. Откроем приложение в вашем любимом браузере по адресу localhost.
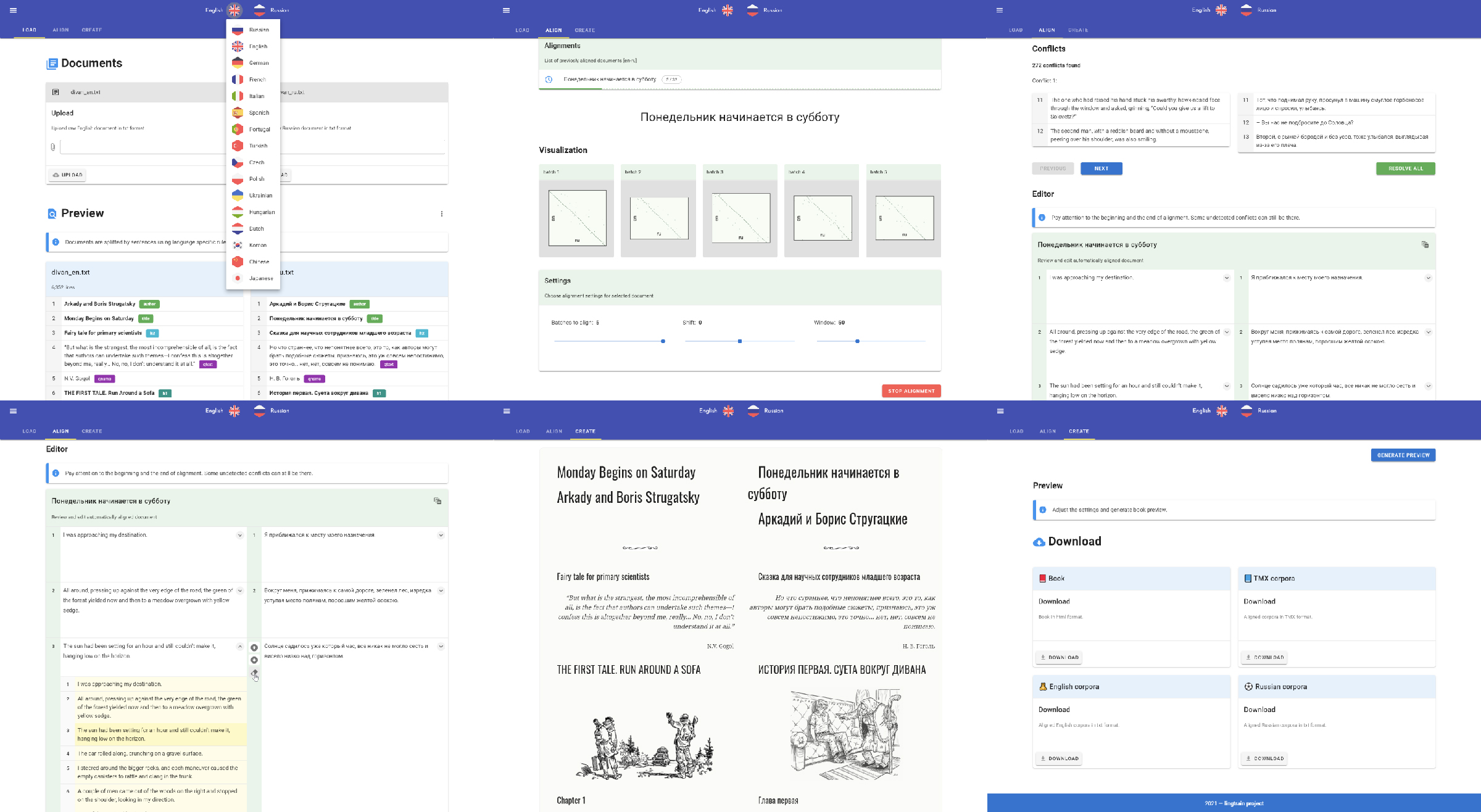
Сделаем три шага: загрузка, выравнивание, генерация.
Демо
Для демонстрации возможностей приложения я записал видео:
Дальше немного подробностей, о том за что отвечает каждый шаг.
Выбор языка
В шапке можно выбрать язык оригинала и перевода. Пока что я добавил 16 наиболее популярных языков. Сама модель не принимает на вход такой параметр как язык, потому что обладает единым словарем для всех токенов. Однако выбор языка в приложении позволяет проделать с входным текстом какие-то специфические для языка манипуляции (например, поправить пунктуацию) и улучшить качество разбиения по предложениям.
Если нужного языка в списке пока нет, то можно выбрать английский.
Загрузка
На первой вкладке необходимо загрузить два текстовых файла, из которых мы будем делать книгу. Это обычные тексты, которые необходимо предварительно разметить. При помощи разметки мы определим строки, которые являются названиями глав книги, эпиграфами и другой метадатой, также мы сможем расставить адреса картинок в необходимых местах. Разметка в выравнивании не участвует. Язык разметки был реализован следующим образом — в конце необходимой строки ставится тег; в начале выравнивания все такие строки извлекаются с сохранением их координат. При генерации они преобразуются в html элементы и расставляются по своим местам.
Сейчас поддерживаются следующие метки:
| Метка | Значение | Пример |
|---|---|---|
| %%%%%author. | Автор | Фрэнк Герберт%%%%%author. |
| %%%%%title. | Название | Дюна%%%%%title. |
| %%%%%qtext. | Цитата | Быстро — это медленно, но без перерывов%%%%%qtext. |
| %%%%%qname. | Подпись под цитатой | Японская поговорка%%%%%qname. |
| %%%%%image. | Изображение | https://ya.ru/image.png%%%%%image. |
| %%%%%h1. %%%%%h2. | Заголовки (большой и поменьше) | Глава 1%%%%%h2. |
| %%%%%divider. | Разделитель (завитушка) | %%%%%divider. |
Ещё есть метки для абзацев, которые сохраняют структуру документа, но они расставляются автоматически. Таким образом, нужно привести тексты вот к такому виду:
Аркадий и Борис Стругацкие%%%%%author.
Понедельник начинается в субботу%%%%%title.
Сказка для научных сотрудников младшего возраста%%%%%h2.
Но что страннее, что непонятнее всего, это то, как авторы могут брать подобные сюжеты, признаюсь, это уж совсем непостижимо, это точно… нет, нет, совсем не понимаю.%%%%%qtext.
Н. В. Гоголь%%%%%qname.
История первая. Суета вокруг дивана%%%%%h1.
https://habrastorage.org/webt/2m/5r/jd/2m5rjdep6ej2rna5rhfioluig1u.png%%%%%image.
Глава первая%%%%%h2.
Учитель: Дети, запишите предложение: «Рыба сидела на дереве».%%%%%qtext.
Ученик: А разве рыбы сидят на деревьях?%%%%%qtext.
Учитель: Ну… Это была сумасшедшая рыба.%%%%%qtext.
Школьный анекдот%%%%%qname.
Я приближался к месту моего назначения. Вокруг меня, прижимаясь к самой дороге, зеленел лес, изредка уступая место полянам, поросшим желтой осокою. Солнце садилось уже который час, все никак не могло сесть и висело низко над горизонтом. Машина катилась по узкой дороге, засыпанной хрустящим гравием. Крупные камни я пускал под колесо, и каждый раз в багажнике лязгали и громыхали пустые канистры.
Справа из леса вышли двое, ступили на обочину и остановились, глядя в мою сторону. Один из них поднял руку. Я сбросил газ, их рассматривая. Это были, как мне показалось, охотники, молодые люди, может быть, немного старше меня. Их лица понравились мне, и я остановился. Тот, что поднимал руку, просунул в машину смуглое горбоносое лицо и спросил, улыбаясь:
– Вы нас не подбросите до Соловца?
...Все метки кроме автора и названия опциональные. Если оформление книги не важно, то можете просто поудалять из текста заглавия и эпиграфы, а метки не расставлять.
После загрузки документа можно будет посмотреть на то, как текст разделился на предложения и провалидировать разметку. Будут видны все названия глав и прочее.
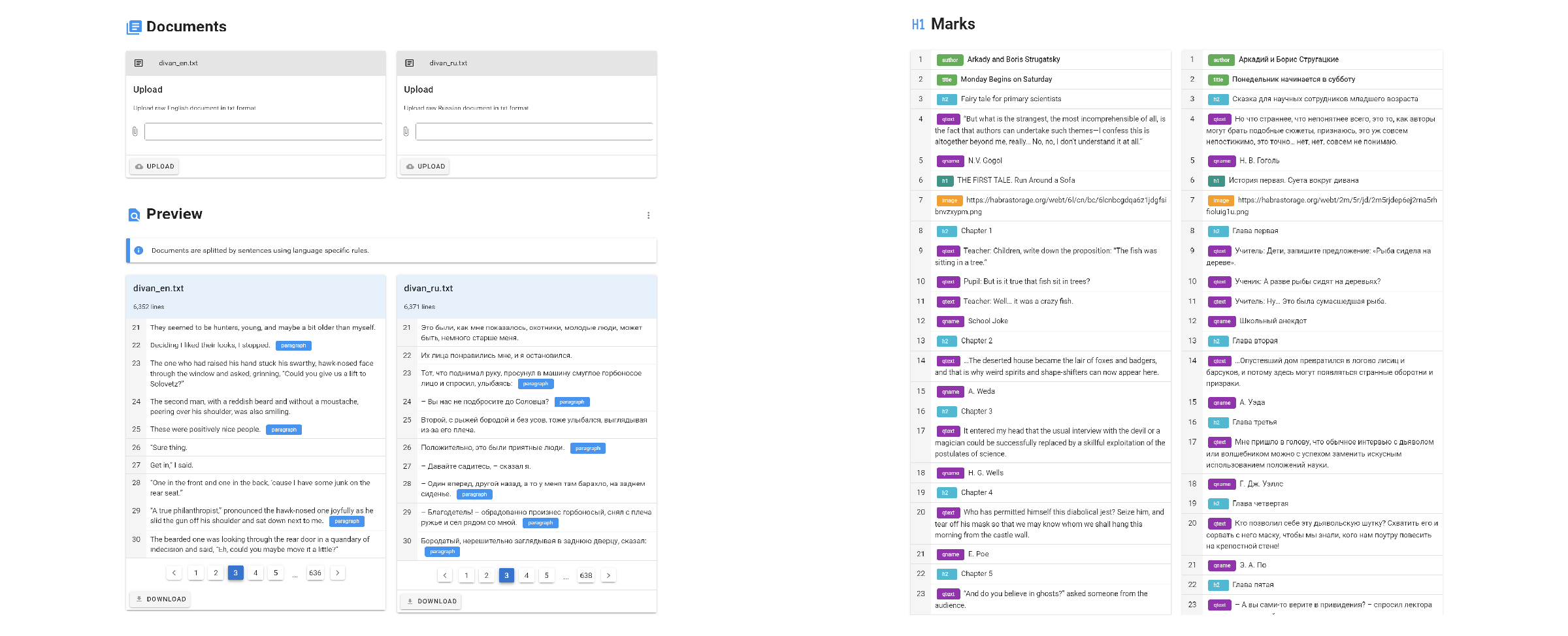
Для корректного оформления книги необходимо, чтобы количество соответствующих меток совпадало.
Выравнивание
На второй вкладке нужно выбрать загруженные ранее документы и посмотреть, насколько сильно отличается количество предложений. Если отличие в пределах 10%, то скорее всего это норма, — в зависимости от конкретного переводчика или языка у текстов могут быть различные тенденции деления по предложениям. Например, при переводе на китайский сложные предложения часто переводятся как несколько простых.
Если различие в количестве строк очень большое, то надо убедиться, что оба текста полные, — в них одинаковое количество глав, не выброшены большие куски и т.д. При выравнивании таких текстов будут большие разрывы, а книга получится "дырявой". В таком случае можно поискать тексты получше или довольствоваться тем, что есть.
Дальше нужно выбрать наши документы и создать выравнивание. После этого появятся настройки — количество батчей, сдвиг и окно.
Настройки
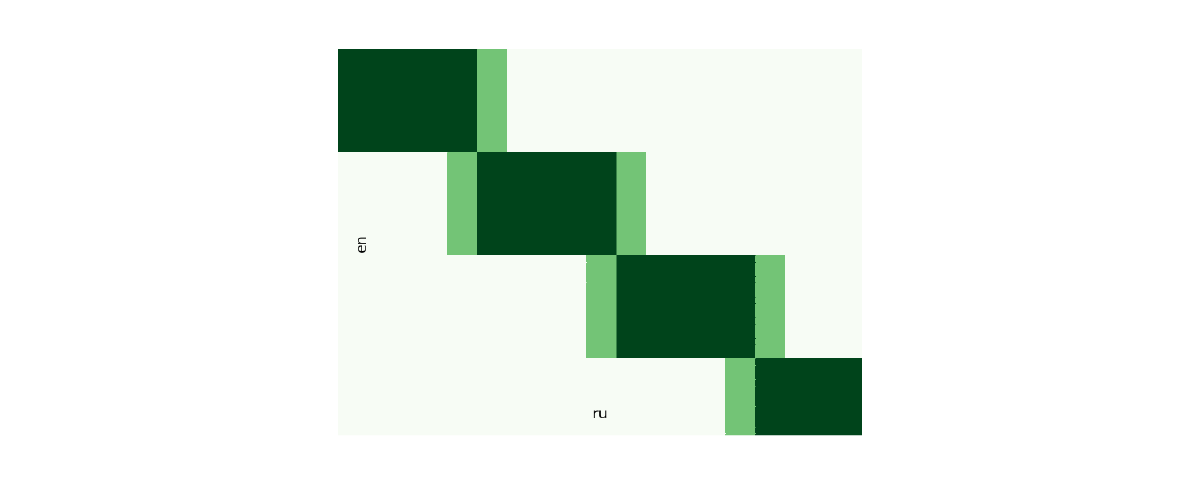
Количество батчей. Выравнивание идет по кускам размером 200 строк, можно задать количество таких кусков для обсчета в параллель. Максимально можно выровнять 5 батчей, то есть 1000 строк за раз.
Окно. При помощи размеров окна можно регулировать "нахлёст" батчей друг на друга, чтобы правильные варианты точно попадали в выравнивание.
Сдвиг. Если на каком-то участке слишком сильно отличается количество предложений между текстами, то правильные варианты могут не попасть в окно и модель будет выдавать случайные соответствия. Все это будет видно на визуализации и можно либо увеличить окно, либо отрегулировать поток сдвигом текста вперед или назад.
Визуализация
После первичного выравнивания станет доступна панель визуализации, на которой можно посмотреть как отработала наша модель.

Конфликты
На первом этапе модель подобрала для каждого предложения наилучшее соответствие. Но так как количество предложений различается, то остаются конфликты, на которые можно посмотреть в соответствующей секции. После этого можно автоматически их разрешить.

Визуализация при этом также обновится.

Редактор
Самая сложная часть приложения по части UI. В редакторе можно редактировать параллельный корпус (именно его мы сделали на предыдущих этапах), — добавлять и удалять строки, сливать их вместе и редактировать. При этом сохраняются идентификаторы строк, что позволит нам сохранить привязку к строкам источника. Так же в редакторе можно править конфликты, которые не исправились автоматически. Это может быть на концах корпуса, потому что система ориентируется на хорошие цепочки выравнивания, которых может не быть в начале и в конце.
Выглядит редактор так:

Кнопки управления появляются при наведении на ячейку.

Можно добавить в ячейку существующую строку, выбрав ее из списка.

Подстрочник
На случай работы с языками, в которых у вас нет уверенности, можно добавить подстрочный перевод.

Для этого надо скачать разбитый по предложениям текст, перевести его и загрузить обратно. Для перевода можно воспользоваться лайфхаком — открыть текст в браузере и перевести через функцию перевода странички. Такая функция, например, в Chrome предлагается автоматически.

Выровняв корпус и подредактировав его, можно перейти к третьей вкладке.
Генерация
Имея на руках готовое выравнивание можно либо извлечь из него параллельные корпуса (полезно для специалистов по машинному обучению и лингвистов), либо создать книгу (для изучающих или преподающих иностранные языки).
Книга
Прежде чем сгенерировать стилизованный html с книгой можно его немного настроить. Кроме выбора с какой стороны взять информацию о разбиении на абзацы, можно выбрать расположение текстов — какой слева, а какой справа. Также можно добавить подсветку соответствий предложений, выбрав стиль.
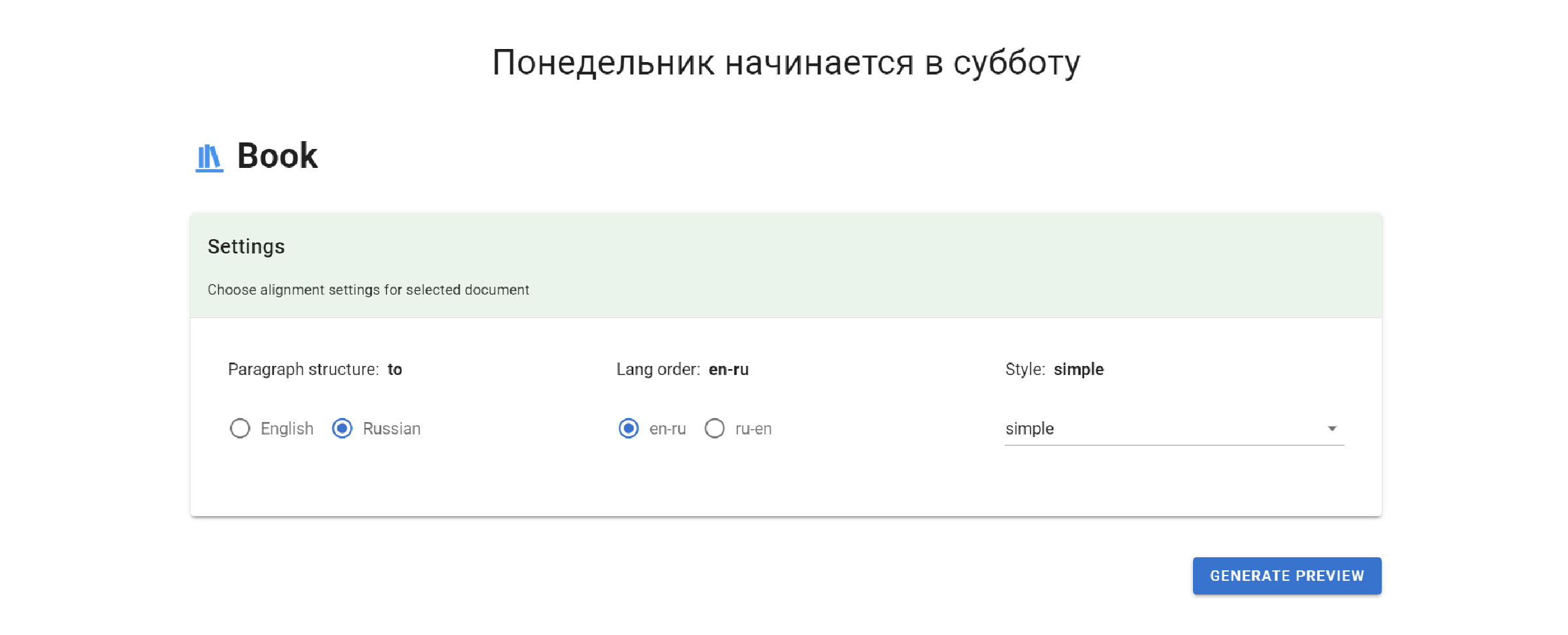
Можно просмотреть начало книги прямо на странице. Из меток, которые мы добавили, создадутся стилизованные заголовки, разделители, эпиграфы и прочее. Обычный текст будет объединен в абзацы, согласно автоматической разметке.

Параллельные корпуса
Можно извлечь из выравнивания параллельные корпуса по отдельности, а можно в формате TMX. Корпуса можно использовать при обучении языковых моделей и в других научно-прикладных задачах.

Скачать
Скачать результат можно в заключительной секции.
Эпилог
Мне, как фанату изучения языков, очень хочется, чтобы любой человек, который изучает или преподает языки смог бы быстро и просто сделать себе параллельную книгу. Ведь найти себе такую по душе сложнее чем две книжки по отдельности. Параллельные корпуса так же несут в себе большую пользу. Например, модели нейронного перевода обучаются именно на них.
Код проекта открытый, приложение написано на Vue и Python. Идеи и предложения приветствуются. Спасибо за внимание.











{kind=link}
BlackStar1991
Интересный проект, совершенно не понятно зачем вам это надо… но выглядит интересно. У меня вопрос, если в одном из языков предложение разобьется, скажем, на два абзаца, не поломается ли весь ваш код параллельной книги? Обязательно ли соблюдении количество, эммм «паралельных тегов»? Ведь при литературных переводах что-то может добавляться или убираться из текста в зависимости от желания переводчика
averkij Автор
Для меня польза в том, чтобы делать себе друзьям такие книжки. Я люблю изучать иностранные языки и это один способов их освоения, который мне подходит.
Если в одном из языков предложение разобъется на два, то в результате выравнивания оно будет склеено в одно, так что все должно быть хорошо. Более того, можно объединить несколько выравниваний и сделать книжку на трех и более языках. Про это писал тут.
Метки сами по себе нужны только для красивой разметки. Если их количество не будет совпадать, то просто каких-то названий глав или картинок не будет и все. Сама книга выравнивается без участия этих тегов.
gisly
Проект очень классный! И еще одно применение — помощь в создании параллельных корпусов (например, ruscorpora.ru/new/search-para-en.html), которые в свою очередь могут использоваться для научных исследований переводов и т. п.; автор писал вроде бы в предыдущих статьях, что помогает и в этом проекте.
averkij Автор
Да, с Национальным корпусом русского языка тоже сотрудничаю. Особенно с командой русско-китайского корпуса.
wtigga
Воу-воу, это очень круто.
Сервису надо жить в облаке :)
averkij Автор
Такие планы есть, надо под это дело архитектуру подогнать.