
Если вы используете Zabbix для мониторинга ваших инфраструктурных объектов, но руки пока не добрались до сбора, хранении и анализа логов с этих объектов, то эта статья для вас.
Зачем собирать логи и хранить их? Кому это нужно?
Логирование, как еще говорят запись логов, позволяет дать ответы на вопросы, что? где? и при каких обстоятельствах происходило в ИТ-окружении несколько часов, дней, месяцев, даже лет назад. Постоянно появляющуюся ошибку сложно локализовать, даже зная когда и при каких обстоятельствах она проявляется не имея на руках логов. В логи пишется информация не только о возникновении тех или иных ошибок, но и информация более детальная, которая помогает разобраться в причинах возникновения.
После того как вы запустили свой продукт и ждете от него результата, работу продукта нужно постоянно мониторить, предотвращая сбои до того как их увидит потребитель.
А как проанализировать причину падения сервера, логи которого уже не доступны (заметание следов злоумышленника или какие-либо другие обстоятельства непреодолимой силы), правильно, поможет только централизованное хранение логов.
Если вы разработчик ПО и для отладки вам приходится “ходить” и смотреть логи на сервере - то удобный просмотр, анализ, фильтрация и поиск в веб-интерфейсе упростит ваши действия, и вы больше сможете сконцентрироваться на задаче дебага.
Анализ логов – помогает выявить конфликты в конфигурации сервисов, обнаружить источник возникновения «event»-ов, а также определить события информационной безопасности.
Вместе с сервисами мониторинга логирование существенно экономит время инженеров при расследовании тех или иных инцидентов.
Сравнение систем анализа логов
Польза и вред популярных решений по сбору логов уже была описана в статье тут . Коллеги провели анализ таких систем, как Splunk, Graylog и ELK. Выявили хорошие и не очень, для себя конечно, стороны в представленных решениях.
ELK оказался слишком громоздким и требовательным к ресурсам. А также очень непростым в плане настройки на больших инфраструктурах.
Splunk “отозвал” свое доверие пользователей, просто уйдя, не объясняя причин, с рынка России. Партнерам и клиентам Splunk пришлось находить новые решения и продукты.
Автор упомянутой статьи свой выбор остановил на Graylog и приводит примеры установки и настройки данного продукта.
Не был описан ряд систем, таких как Humio, Loki и Monq. Но раз Humio - это SaaS сервис и платный, а Loki - очень простой агрегатор логов без парсинга, обогащения и прочих полезных фич, рассмотрим только Monq. Monq - это целый набор продуктов для поддержки ИТ в рамках единой платформы, куда входит AIOps, автоматизация, синтетический и зонтичный мониторинг, а также анализ логов. Сегодня мы рассмотрим Monq Collector - абсолютно бесплатный инструмент сбора и анализа логов.
Архитектура monq Collector
Monq Collector - это бесплатно распространяемое ПО для сбора и анализа логов, предназначенное для установки в инфраструктуре клиента. Поставляется в виде образа виртуальной машины и скачать его можно тут. Документация на продукт и интерфейс доступны на русском и английском языке.
Одной из фич, данного средства по работе с логами, является возможность обрабатывать входящий поток данных на препроцессоре, при помощи создаваемых собственноручно: скриптов и парсеров, во встроенном IDE Lua. Это дает очень широкие возмоджности по фильтрации и трансформации данных. Этот функционал богаче, чем в том же graylog.
Другой отличительной способностью является архитектура продукта. Продукт спроектирован используя микросервисы. А хранение тех самых логов осуществляется в колоночной аналитической СУБД ClickHouse.
Ключевым преимуществом ClickHouse является высокая скорость выполнения SQL запросов на чтение (OLAP-сценарий), которая обеспечивается благодаря следующим отличительным особенностям:
векторные вычисления;
распараллеливание операций;
столбцовое хранение данных;
поддержка приближенных вычислений;
физическая сортировка данных по первичному ключу.
Но одна из самых важных особенностей ClickHouse - это очень эффективная экономия места на системах хранения данных. Средняя степень сжатия получается 1:20, что является очень неплохим результатом.
Нативный коннектор с Zabbix
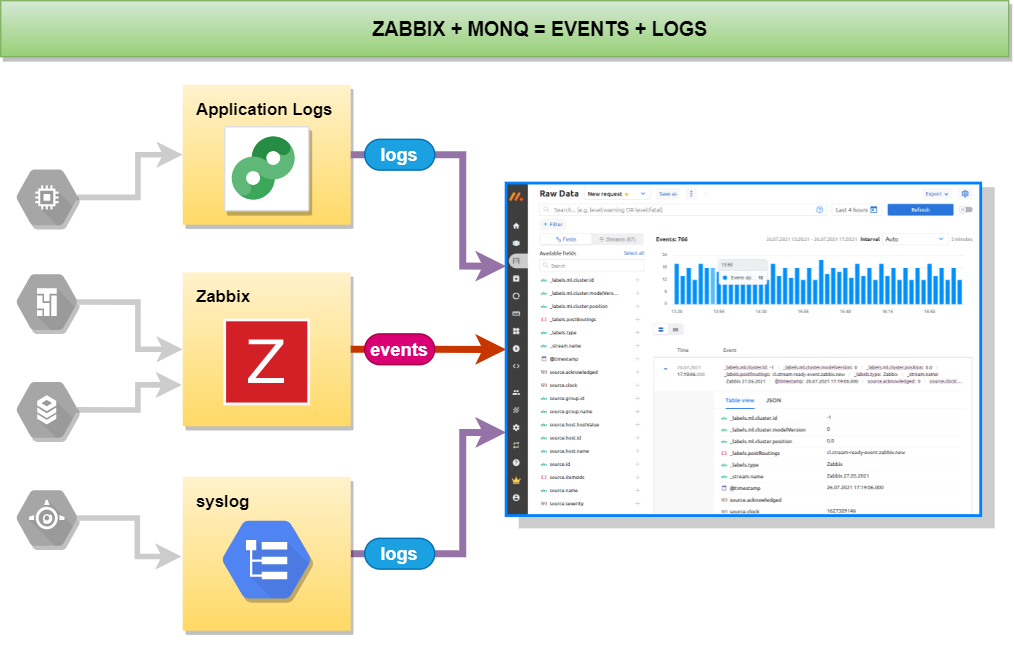
Если вы обратили внимание на заголовок статьи, то изначально мы хотели рассказать вам, чем же хорошо использование monq в компаниях, где используется Zabbix в качестве системы мониторинга инфраструктуры.
Во-первых, продукт по сбору и анализу логов предоставляется абсолютно бесплатно и без каких либо ограничений по трафику и времени.
Во-вторых, monq Collector включает в себя встроенный коннектор с Zabbix, который позволяет получать все события c триггеров Zabbix и далее просматривать их на одном экране с логами.
Для приема событий из Zabbix и других систем как Nagios, Prometheus, SCOM, Ntopng предусмотрены системные обработчики, с возможностью кастомизации кода или написания своих собственных обработчиков.

Например, можно произвести преобразование формата даты в удобный формат:
function is_array(t)
local i = 0
for _ in pairs(t) do
i = i + 1
if t[i] == nil then return false end
end
return true
end
function convert_date_time(date_string)
local pattern = "(%d+)%-(%d+)%-(%d+)(%a)(%d+)%:(%d+)%:([%d%.]+)([Z%p])(%d*)%:?(%d*)";
local xyear, xmonth, xday, xdelimit, xhour, xminute, xseconds, xoffset, xoffsethour, xoffsetmin
xyear, xmonth, xday, xdelimit, xhour, xminute, xseconds, xoffset, xoffsethour, xoffsetmin = string.match(date_string,pattern)
return string.format("%s-%s-%s%s%s:%s:%s%s", xyear, xmonth, xday, xdelimit, xhour, xminute, string.sub(xseconds, 1, 8), xoffset)
end
function alerts_parse(result_alerts, source_json)
for key, alert in pairs(source_json.alerts) do
alert["startsAt"]=convert_date_time(alert["startsAt"])
alert["endsAt"]=convert_date_time(alert["endsAt"])
result_alerts[#result_alerts+1]=alert
end
end
local sources_json = json.decode(source)
result_alerts = {};
if (is_array(sources_json)) then
for key, source_json in pairs(sources_json) do
alerts_parse(result_alerts, source_json)
end
else
alerts_parse(result_alerts, sources_json)
end
next_step(json.encode(result_alerts))В-третьих, если установить трайл или платное дополнение monq AIOps, то появляется еще ряд нативных функций связи Zabbix и monq, которые позволяют:
привязывать узлы и триггеры Zabbix к ресурсно-сервисной модели в monq
автоматически создавать правила корреляции (синтетические триггеры) monq c предустановленными фильтрами и правилами для событий поступающих от триггеров Zabbix
работать с низкоуровневым обнаружением (LLD) в Zabbix
Синтетические триггеры позволяют обрабатывать любые события, поступающие в систему мониторинга monq. Имеется возможность создать триггеры по шаблону или настроить его с нуля, при помощи скриптов, составленных на языке Lua во встроенном в веб-интерфейс IDE-редакторе.
При помощи Zabbix-коннектора в monq можно “перетащить” всю инфраструктуру и построить ресурсно-сервисную модель всей информационной системы. Это удобно, когда надо быстро найти локализацию проблемы, причину возникновения инцидента.

Назревает вопрос, а можно ли разграничить доступ к логам определенным категориям лиц? Например, чтобы логи ИБ были доступны определенной категории лиц? Можно.
Для этого в monq Collector построена очень гибкая ролевая модель с использованием рабочих групп. Пользователи системы могут одновременно иметь разные роли в разных рабочих группах. Подключая поток данных мы можем разрешить доступ на чтение или запись определенным ролям и назначить эти роли пользователям.

Как мне это поможет?
Попробуем описать небольшой вымышленный юзкейс.
У нас есть кластер под управлением Kubernetes. Есть несколько виртуальных машин в аренде. Все узлы мониторятся при помощи Zabbix. И есть сервис авторизации, который очень важен для нас, так как через него работает несколько корпоративных сервисов.
Zabbix периодически сообщает, что сервис авторизации недоступен, потом снова доступен через минуту или две.
Мы хотим найти причину падения сервиса и не вздрагивать от каждого “тыдын” из телефона
Zabbix отличное средство для мониторинга, но для расследования инцидентов этого не достаточно. Ошибки часто могут лежать в логах. И для этого мы будем собирать и анализировать логи в monq Collector.
Итак, по порядку:
1. Настраиваем сбор логов с nginx-ingress контроллера, который находится в кластере под управлением Kubernetes.
В данном случае мы будет передавать логи в коллектор при помощи утилиты fluent-bit. Приведем листинги конфигурационных файлов
[INPUT]
Name tail
Tag nginx-ingress.*
Path /var/log/containers/nginx*.log
Parser docker
DB /var/log/flb_kube.db
Mem_Buf_Limit 10MB
Skip_Long_Lines On
Refresh_Interval 10Подготовим парсеры для nginx, чтобы преобразовать raw в JSON:
[PARSER]
Name nginx
Format regex
Regex ^(?<remote>[^ ]*) (?<host>[^ ]*) (?<user>[^ ]*) \[(?<time>[^\]]*)\] "(?<method>\S+)(?: +(?<path>[^\"]*?)(?: +\S*)?)?" (?<code>[^ ]*) (?<size>[^ ]*)(?: "(?<
Time_Key time
Time_Format %d/%b/%Y:%H:%M:%S %z
....
[PARSER]
Name nginx-upstream
Format regex
Regex ^(?<remote>.*) \- \[(?<realip>.*)\] \- (?<user>.*) \[(?<time>[^\]]*)\] "(?:(?<method>\S+[^\"])(?: +(?<path>[^\"]*?)(?: +(?<protocol>\S*))?)?)?" (?<code>[^
Time_Key time
Time_Format %d/%b/%Y:%H:%M:%S %z
[PARSER]
Name nginx-error
Format regex
Regex ^(?<time>\d{4}\/\d{2}\/\d{2} \d{2}:\d{2}:\d{2}) \[(?<log_level>\w+)\] (?<pid>\d+).(?<tid>\d+): (?<message>.*), client: (?<client>.*), server: (?<server>.*)
Time_Key time
Time_Format %Y/%m/%d %H:%M:%S2. Отправляем логи в коллектор тоже при помощи fluent-bit (у монк коллектора в августе появится свой экстрактор, о нем напишу позже)
[OUTPUT]
Name http
Host monq.example.ru
Match *
URI /api/public/cl/v1/stream-data
Header x-smon-stream-key 06697f2c-2d23-45eb-b067-aeb49ff7591d
Header Content-Type application/x-ndjson
Format json_lines
Json_date_key @timestamp
Json_date_format iso8601
allow_duplicated_headers false3. Мониторинг инфраструктурных объектов ведется в Zabbix с корреляцией входящих потоков в monq.
4. Проходит некоторое время и в monq приходит событие из Zabbix, о том, что недоступен сервис аутентификации.
5. Почему? Что случилось? Открываем экран первичных событий monq, а там уже шквал событий от nginx-ingress-controller

6. При помощи аналитических инструментов первичного экрана, выясняем, что у нас сыпется 503 ошибка. За 30 минут уже 598 записей 31,31% от общего количества логов от nginx-ingress контроллера.

7. Из этого же окна фильтруем события, нажимаем на значение ошибки и выбираем “добавить в фильтр”. В результате в панели фильтра добавится параметр source.code = 503. Лишние данные логов с экрана будут убраны.
8. Переходим к анализу структурированных логов и видим, по какому URL-у возвращается ошибка, понимаем какой микросервис дает сбой и быстро решаем проблему пересозданием контейнера.

9. На будущее заводим логи с данного контейнера в monq и в следующий раз мы знаем о проблеме намного больше информации, которую можно передать разработчикам для правки кода.
Скоро в бесплатном функционале monq Collector появится алертинг и автоматизация, что позволит подобные ошибки сразу заводить в виде триггера. Пока подобный функционал доступен только в платном monq AIOps.
Тот кейс, что я привел выше это, конечно, не из реальной жизни, а больше демонстрация общих принципов. В жизни часто бывает все не так очевидно. Из практики:
2019 год, разрабатываем систему в которой 50+ контейнеров. В каждом релизе наш релиз-мастер тратил уйму времени разбираясь почему может ломаться связка межмикросервисного взаимодействия. Переходя между микросервисами и логами, каждый раз набивая kubectl get log, в одном окне, тоже самое во втором окне, потом в третьем. А еще надо тейлить логи веб сервера. Потом вспоминал, что в первом окне и т.п. А тут еще команда растет, всем давать доступ по ssh на сервер? Нет, нужен агрегатор.
Настроили отправку логов в ELK, собирали все что нужно, и тут, что-то случилось. В ELK каждый источник событий использует свой индекс и это не очень удобно. Команда все росла, появились аутсорсеры, мы поняли, что нужно разграничение прав по рабочим группам. Количество логов начало сильно расти, стала нужна кластеризация базы данных собственными средствами без применения бубна, нужен хайлоад. В ELK все это уже за деньги. Решили направить логи в monq Collector.
2021 год. Очередной релиз, все выкатили, кубер запустил контейнеры, zabbix алармит, что не работает авторизация, заходим в Collector, парсим по полям, видим где проблема. Видим по логам, что началась во столько-то, после выкатки того-то. Проблема решена быстро и просто, и это на объеме более 200 Гб логов в день, когда с хранилищем работают более 30 человек. И это реальный профит.
Всем хорошего времени суток и поменьше пятисотых!


Gelajr
После такой интересной статьи захотелось попробовать у себя monq, но вот беда, файл с ним качается с ужасающе медленной скоростью (если мануал скачивается мгновенно, то образ с машиной по несколько килобайт в час), а зеркал на просторе интернета обнаружено не было.
NuGan Автор
У меня скачался за 15 минут где-то. Залил сюда, чтоб уж наверняка.
Gelajr
Да, отсюда отлично качает, спасибо
Gelajr
Еще, кстати, регулярки для парсеров полностью не уместились у вас.
Появились некоторые общие впечатления.
Машина поставляется в конфигурации 8 ядер виртуальных и 4 гигабайта озу (если верно запомнилось). Установка-запуск проблем особых не вызывают.
Проблемы начинаются на этапе, когда из rundeck веб интерфейса мы запускаем джобы на установку инфраструктуры и самого монка. Сначала инфраструктура выдала ошибку сборки, что ей нужно не менее 10 ядер. Окей, ядра были накинуты. Потом вышла ошибка, что надо не меньше 16 гигов озу. Опытным путем было выяснено, что машине не всего нужно 16 гигов, а та память, которая уже используется машиной + 16 гигов сверху (возникает вопрос, почему бы разрабу не сделать виртуалку, которая сразу будет отвечать требованиям, раз уж машина целиком готовая поставляется).
В официальном мануале об этих моментах, конечно, ни слова.
Окей, собираем таки инфраструктуру, потом ставим монк. Дальше проблема: по какой-то причине при переходе на административную панель страница становится пустой. Оказалось, что видимо вот так коряво собралось (хотя логи все зеленые, с успешной сборкой). После удаления через monq erase и пересборки заново, наконец появились все вкладки, чтобы можно было скормить ключ лицензии.
Вроде бы все проблемы поборолись, пусть и методом тыка. Остается только добавить интеграции, настроить fluent beat на целевом сервере и наслаждаться жизнью.
К сожалению, опять же все не так безоблачно. Примеры настроек fluent beat все приведены для докеров и прочих кубернетисов. Тем, у кого не докер, остается, видимо, подбирать конфиг интуитивно (опять же, в офф мануале только самая база описана, никаких интересных подробностей, что не помогает совсем).
К сожалению, эта загвоздка пока что не преодолена, сбор логов пока настроить не удалось.
Вроде бы, проект интересный. Но везде как-то по мелочи недоделанный, решения нужно угадывать интуитивно + официальный мануал оставляет желать лучшего. В общем, это вам не zabbix (да, я понимаю, что заббикс занимается несколько другим, но пример, как надо делать мануалы, хороший).
Возможно, конечно, я ошибаюсь, и где-то лежит подробная инструкция с разными вариантами траблшутинга.
Monqlabuser
Спасибо за расширенный отзыв, для нас это очень важно. Системные требования у нас описаны тут https://docs.monqlab.com/current/ru/admin/requirements/ Что же касается примеров настройки сбора логов, в нашей документации приведены примеры для fluentd, fluentbit как базовые. Приводить примеры настройки сбора логов с различных систем, будь-то nginx, стандартный syslog или что-либо еще мы не стали, по причине их необъятного количества, и угодить всем пользователям тут не получится. Если вы нуждаетесь в поддержке, пожалуйста приходите в наш community - https://community.monqlab.com/