

Нейронные сети повсеместно используются для выполнения самых разных задач, можно даже сказать, что это самый настоящий «универсальный солдат». Однако, может показаться, что начать работать с нейросетями довольно сложно, несмотря на наличие огромного количества информации в источниках, существование готовых фреймворков, например, tensorflow, pytorch и других.
И всё же, существует инструмент, позволяющий легко совершить «быстрый старт» и опробовать нейронные сети в деле самостоятельно – это fast ai. Вообще, fast ai – это прежде всего группа исследователей, занимающихся вопросами искусственного интеллекта и глубокого обучения в частности, которая выпустила одноимённую библиотеку в свободное пользование в 2018 году. Если говорить простыми словами – fast ai представляет собой надстройку над упомянутым выше фреймворком pytorch и упрощает работу с ним, делает это быстрее. Отсюда и слово «быстро» в названии статьи.
Пожалуй, перейдём к практике и покажем, насколько просто работать с fast ai на простом примере задачи классификации изображений – постараемся обучить нейронную сеть различать две модели автомобильной марки Subaru: Impreza и Legacy. Как и обычно, в первую очередь выполняем установку библиотеки, выполнив в консоли команду:
pip install fastaiСразу же убедимся в том, что библиотека была успешно установлена, выполнив команды:

Если интерпретатор python не будет «ругаться», значит всё хорошо. После этого в папке нашего python-проекта мы создаём ещё одну папку, назовём её images, куда будем сохранять изображения. В интернете мы нашли около двух сотен изображений интересующих нас автомобилей. Ракурсы немного разные, однако на всех фото видна передняя часть. Виды задней части мы не будем использовать, поскольку это усложнит задачу и потребует большего количества изображений. В папке images были созданы ещё две папки – Legacy и Impreza, куда мы поместим изображения соответствующих моделей:

Содержимое папки Impreza:

Содержимое папки Legacy:

Хранение изображений объектов разных классов в отдельных папках, во-первых, более удобно визуально и в плане добавления новых классов, во-вторых, позволит без лишних сложностей производить классификацию объектов нескольких классов.
Перейдём к коду. Начнём с импорта необходимых классов:
from fastai.vision.all import *Далее укажем путь к сохранённым изображениям:
path = r"C:\<your path>\images"Теперь необходимо написать функцию, которая позволит классификатору корректно разметить обучающую выборку изображений, но к этому мы вернёмся позже. Создаём объект класса DataBlock, являющийся контейнером, содержащим информацию о наших данных и о предобработке, которую нужно осуществить:
cars = DataBlock(blocks=(ImageBlock, CategoryBlock),
get_items=get_image_files,
splitter=RandomSplitter(),
get_y=label_function,
item_tfms=Resize(224, method=ResizeMethod.Pad))Параметру blocks мы передаём типы наших данных – изображения и категории (классы), get_items – название функции, которая выбирает все находящиеся в папке images изображения, splitter – как разделить выборку на тренировочную и тестовую (в данном случае – рандомно), get_y – функция для разметки изображений обучающей выборки, как раз то, о чём мы говорили выше. Остановимся здесь подробнее. Чтобы понять, как написать эту функцию, посмотрим, что возвращает get_image_files():

Это список, содержащий пути ко всем изображениям обучающей выборки. Поскольку в качестве выходных значений мы хотим видеть наименование класса (модели автомобиля), label_function должна возвращать название папки, в которой находится конкретное изображение:
label_function = lambda f: str(f).split("\\")[-2]Параметр item_tfms – как обработать изображения, здесь мы уменьшаем изображения до размера 224х224 (все изображения должны быть одного размера) и указываем метод, применяемый для изменения размера. ResizeMethod.Pad заполнит «пустые» части изображения (у большинства изображений не совпадает ширина и высота) зеркально, относительно границы изображения:

Возможно, мы хотим повернуть изображения на 45 градусов, для этого будем использовать класс Rotate(), указав для параметров max_deg, p и draw значения 45, 1.0 и 45 соответственно. Это означает, что все изображения (p=1.0) будут обязательно повёрнуты на 45 градусов (draw=45, max_deg=45). Если не изменять значение параметра draw по умолчанию (None), изображение будет повёрнуто на угол от –max_deg до max_deg, но не более. Если изменить значение параметра pad_mode, можно увидеть, как заполняется появившееся при повороте изображения пустое пространство. Для значений “zeros”, “border” и “reflection” соответственно:

Чтобы обесцветить изображение, можно воспользоваться классом Saturation(), передав параметрам max_lighting, p и draw значения 0.0, 1.0 и 0.0 (по аналогии с Rotate()):

В случае необходимости применения группы преобразований, следует воспользоваться функцией setup_aug_tfms:
batch_tfms = setup_aug_tfms([Resize(224, method=ResizeMethod.Pad), Rotate(max_deg=45, p=1, draw=45), Saturation(max_lighting=0.0, p=1.0, draw=0.0)])
Также существует возможность применить прочие трансформации, но в данном примере ограничимся изменением размера изображений.
Вызываем метод dataloaders() и передаём путь к папке с изображениями:
loader = cars.dataloaders(path)Это подготовит данные для модели. Теперь мы можем посмотреть, верно ли прошла разметка:
loader.show_batch(max_n=9)
Как видим, всё отработано корректно. Теперь осталось произвести обучение нейронной сети. Библиотека fast ai предоставляет возможность сконфигурировать свою нейронную сеть, но мы в данном примере воспользуемся предобученной свёрточной нейросетью resnet34, которая подходит для классификации изображений:
learn = cnn_learner(loader, resnet34, metrics=error_rate)У cnn_learner довольно много параметров, выше мы передали значения самым основным – dls (объект data loaders), arch (архитектура нейронной сети), metrics (метрики). Возможно, возникнет необходимость изменить параметр lr (learning rate), отвечающий за скорость обучения нейронной сети – чем выше значение lr, тем быстрее обучение, но снижается точность, и наоборот. Следует избегать слишком низких значений lr, поскольку помимо снижения скорости обучения это влечёт вероятность переобучения нейронной сети. Значение по умолчанию 0.001. Ещё один из параметров, которые мы рассмотрим – opt_func (оптимизатор), который используется для достижения лучших результатов обучения. По умолчанию, предлагается использовать оптимизатор Adam. В fast ai помимо Adam реализованы SGD, RMSProp, RAdam, QHAdam, LARS/LARC, LAMB.
Продолжим с оптимизатором Adam, вызываем метод fine_tune для обучения нейронки под нашу задачу:
learn.fine_tune(10)За 10 эпох мы достигли довольно неплохих результатов:
epoch |
train_loss |
valid_loss |
error_rate |
time |
10 |
0.111862 |
0.163019 |
0.062500 |
01:38 |
Отображаем результаты:
learn.show_results()
Теперь мы можем попробовать классифицировать изображение с автомобилем, которого не было в исходной выборке, вызвав метод predict и передав путь к изображению:


Модель классифицирована верно (напомним, “False” соответствует Impreza), вероятность составила 99%.
Как насчёт Legacy?

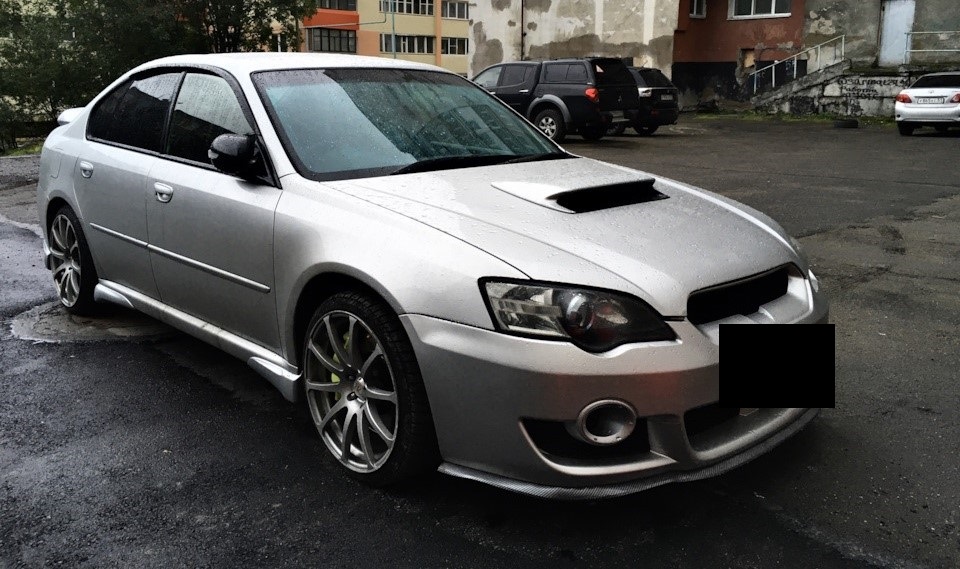

Модель классифицирована верно.
И всё это менее 20 строк кода. Разумеется, для более нетривиальных задач программа усложнится в некоторой степени. И тем не менее, можно сделать вывод, что fast ai оправдывает своё название и является довольно гибким и простым для быстрого старта инструментом.
Спасибо за внимание!
Комментарии (4)

Tiberiy1976
13.09.2021 23:47+2Есть сомнения, что на Керасе будет намного больше кода, но он документирован, понятен и предсказуем.

NewTechAudit Автор
14.09.2021 09:25Добрый день, спасибо за комментарии. В данной статье проводился обзор инструмента. Попробуем сравнить Fast ai с другими библиотеками на примере задачи, приближенной к реальной.
masai
Я бы не советовал использовать fastai. Авторы часто ломают обратную совместимость, а качество их кода порой оставляет желать лучшего. Каких-то особых преимуществ тоже нет. Всё равно для чего-то более-менее сложного придётся написать много кода, и тут fastai уже будет скорее мешать.
Для быстрого старта с PyTorch можно взять, например, pytorch-lightning и lightning-flash.
DOLARiON
Полностью согласен. В нашей специфике (у нас табличные данные) - мы используем AutoKeras и AutoSklern. Для быстрого старта - нам очень помогло. Рекомендую.