
Примечание переводчика: В нашем блоге мы много пишем о построении облачного сервиса 1cloud, но немало интересного можно почерпнуть и из опыта по работе с инфраструктурой других компаний. Сегодня мы представляем вашему вниманию вторую и последнюю часть адаптированного перевода заметки инженерной команды Twitter о создании файловой системы для работы с кластерами Hadoop. Первая часть доступна по ссылке.

Помимо всего описанного в первой части статьи, инженеры Twitter создали проект под кодовым названием Nfly (N элементов в N ЦОД), с помощью которого реализуется большая часть функциональности HA и работы с множеством дата-центров в ViewFs, что позволяет избежать дупликации кода. Nfly может создавать одну ссылку пути ViewFs для множества кластеров.
При использовании Nfly взаимодействие осуществляется как бы с единой файловой системой, в то время как на самом деле, каждое событие записи применяется ко всем слинкованным кластерам, а чтение производится либо из ближайшего кластера (в соответствии с NetworkTopology) либо из того, где хранится самая свежая копия.
Nfly значительно упрощает работу с разными дата-центрами. С помощью репликации мульти-URI Inode микс разных физических частей собирается в единый логический доступный путь. Все это связано с привычным паттерном использования HDFS в сервисах высокой доступности Twitter. Сервисы хранят свои данные в логическом кластере C. Периодически (но не очень часто) создаются новые версии сервисных данных, которые считываются разными серверами. Когда сервис работает в дата-центре DC1, то ему удобнее читать из /DC1/C, чтобы снизить задержки. Однако, когда данные по пути /DC1/C недоступны, сервису предпочтительнее перенести процесс чтения на более медленный путь /DC2/C, но не «упасть», прекратив обслуживание пользователей.
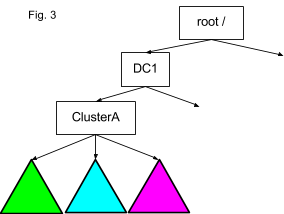
Обычно во ViewFs inode указывает на конкретный URI через ChRootedFileSystem. Как видно на графике выше, между узлами одна стрелка. Пользовательское пространство имен (зеленое) кластера ClusterA в дата-центре DC1 смонтировано через точку монтирования /DC1/clusterA/user->hdfs://dc1-A-user/user. Когда приложение проходит путь /DC1/clusterA/user/lohit он будет разрешен следующим образом. Корневая часть пути, помеченная жирным шрифтом между root/ и точкой монтирования внутри inode user (верхняя точка дерева пространства имен на графике) заменяется целевым значением ссылки hdfs://dc1-A-user/user. В итоге для доступа к физической файловой системе используется путь hdfs://dc1-A-user/user/lohit. В данном контексте замена корневой части адреса называется chrooting, отсюда и название ChRootedFileSystem. Таким образом, если в inode есть множество URI, можно спрятать за одним логическим путем множество физических файловых систем, которые могут находиться в разных дата-центрах.
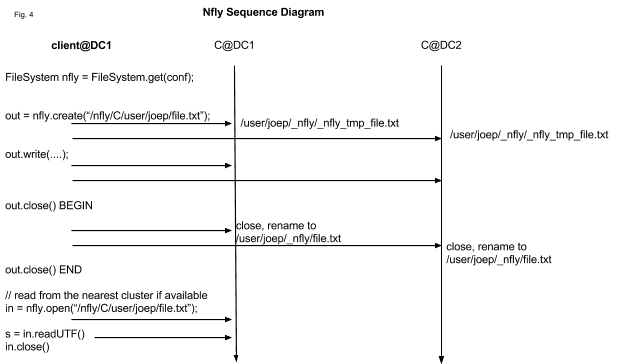
Также инженеры Twitter реализовали ссылку нового типа, которая указывает на список URI, обернутых в ChRootedFileSystem. Базовый принцип здесь заключается в том, что вызов записи распространяется к каждой файловой системе, представленной идентификатором URI, синхронно. На пути чтения клиент FileSystem берет URI, указывающий на ближайший пункт назначения, например, в том же самом дата-центре. Обычно это выглядит как /nfly/C/user->/DC1/C/user,/DC2/C/user,… Сценарий проиллюстрирован на диаграмме последовательности сообщений, представленной выше.
Набор экземпляров ChRootedFileSystem представлен объектом файловой системы Nfly, который используется для indoe точки монтирования. Файловая система Nfly использует один логический путь /nfly/C/user//path для множества физических путей. Она поддерживает настройку minReplication. Пока число URI, на которых обновление завершилось успешно, больше или равно minReplication, исключения логируются, но не показываются. Каждая операция обновления выполняется последовательно. Однако, команда Twitter планирует добавить функцию использования параллельной записи, если клиенту позволяет полоса пропускания.
При использовании Nfly создание файла или запись выполняется следующим образом:
Для запросов на запись поддерживается понятие локальности похожее на HDFS /DC/rack/node. URI сортируются с помощью управляющих элементов из NetworkTopology. Обычно это имена хостов в простых URI HDFS. Если управляющий элемент отсутствует (например, в случае локального file:///), то локальное имя хоста берется за InetAddress.getLocalHost(). Это позволяет гарантировать, что локальная файловая система всегда будет ближайшей к элементу, осуществляющему чтение. Для URI-идентификаторов Hadoop 2 HDFS, основанных на ID служб имен, а не на именах хостов, скрипт довольно просто видоизменить поскольку ID служб имен в системе Twitter уже содержат ссылку на дата-центр. Для стойки и конкретного узла можно вывести любую строку вида /DC/rack-nsid/node-nsid, поскольку для таких клиентов файловых систем важна «локальность» по отношению к ЦОД.
Существует две политики/дополнения к пути вызова чтения, которые делают эту операцию более дорогой с точки зрения вычислительных ресурсов, но улучшают пользовательский опыт.
Как сказано в первой части, управление конфигурациями ViewFs может быть очень сложным делом, а использование Nfly все еще больше усложняет. Однако TwitterViewwFs обеспечивает механизмы, обладающие большой гибкостью и позволяющие добавлять код для генерации полезных конфигураций Nfly «на лету». Если работник Twitter хочет получить домашние директории в логическом кластере C на всех дата-центрах для /nfly/C/user/, то ему просто нужно указать -Dfs.nfly.mount=C. Если же сотрудник затем захочет закешировать файлы локально в /local/user//C, нужно указать -Dfs.nfly.local=true.
Схема работы с множеством URI, представленная в Nfly, являет собой основу для развития read-only Merge FileSystem, которая прозрачно сливает inode из файловых систем. Инженеры Twitter сейчас работают над созданием подобной системы, которая позволит значительно снизить количество монтировочных таблиц в сравнении с подходом с использованием единого URI для inode. Основной сценарий использования Merge FileSystem — разбиение имеющегося пространства имен (например, пользовательского) на два пространства без необходимости изменения кода и расширения конфигурации. Подробнее разница показана на картинке ниже:

В этом материале команда Twitter поделилась своим подходом к управлению файловыми системами на Hadood: масштабированию для решения задач, связанных с хранением огромного количества данных с помощью федерализованных пространств имен, сохранив при этом простоту конфигурации с помощью ViewFs. Инженеры сервиса микроблогов расширили ViewFs, чтобы упростить работу с постоянно растущим числом кластеров и пространств имен в множестве дата-центров и добавили Nfly для доступности HDFS-данных для разных ЦОД.
Высокая доступность для среды из многих дата-центров
Помимо всего описанного в первой части статьи, инженеры Twitter создали проект под кодовым названием Nfly (N элементов в N ЦОД), с помощью которого реализуется большая часть функциональности HA и работы с множеством дата-центров в ViewFs, что позволяет избежать дупликации кода. Nfly может создавать одну ссылку пути ViewFs для множества кластеров.
При использовании Nfly взаимодействие осуществляется как бы с единой файловой системой, в то время как на самом деле, каждое событие записи применяется ко всем слинкованным кластерам, а чтение производится либо из ближайшего кластера (в соответствии с NetworkTopology) либо из того, где хранится самая свежая копия.
Nfly значительно упрощает работу с разными дата-центрами. С помощью репликации мульти-URI Inode микс разных физических частей собирается в единый логический доступный путь. Все это связано с привычным паттерном использования HDFS в сервисах высокой доступности Twitter. Сервисы хранят свои данные в логическом кластере C. Периодически (но не очень часто) создаются новые версии сервисных данных, которые считываются разными серверами. Когда сервис работает в дата-центре DC1, то ему удобнее читать из /DC1/C, чтобы снизить задержки. Однако, когда данные по пути /DC1/C недоступны, сервису предпочтительнее перенести процесс чтения на более медленный путь /DC2/C, но не «упасть», прекратив обслуживание пользователей.
Обычно во ViewFs inode указывает на конкретный URI через ChRootedFileSystem. Как видно на графике выше, между узлами одна стрелка. Пользовательское пространство имен (зеленое) кластера ClusterA в дата-центре DC1 смонтировано через точку монтирования /DC1/clusterA/user->hdfs://dc1-A-user/user. Когда приложение проходит путь /DC1/clusterA/user/lohit он будет разрешен следующим образом. Корневая часть пути, помеченная жирным шрифтом между root/ и точкой монтирования внутри inode user (верхняя точка дерева пространства имен на графике) заменяется целевым значением ссылки hdfs://dc1-A-user/user. В итоге для доступа к физической файловой системе используется путь hdfs://dc1-A-user/user/lohit. В данном контексте замена корневой части адреса называется chrooting, отсюда и название ChRootedFileSystem. Таким образом, если в inode есть множество URI, можно спрятать за одним логическим путем множество физических файловых систем, которые могут находиться в разных дата-центрах.
Также инженеры Twitter реализовали ссылку нового типа, которая указывает на список URI, обернутых в ChRootedFileSystem. Базовый принцип здесь заключается в том, что вызов записи распространяется к каждой файловой системе, представленной идентификатором URI, синхронно. На пути чтения клиент FileSystem берет URI, указывающий на ближайший пункт назначения, например, в том же самом дата-центре. Обычно это выглядит как /nfly/C/user->/DC1/C/user,/DC2/C/user,… Сценарий проиллюстрирован на диаграмме последовательности сообщений, представленной выше.
Набор экземпляров ChRootedFileSystem представлен объектом файловой системы Nfly, который используется для indoe точки монтирования. Файловая система Nfly использует один логический путь /nfly/C/user//path для множества физических путей. Она поддерживает настройку minReplication. Пока число URI, на которых обновление завершилось успешно, больше или равно minReplication, исключения логируются, но не показываются. Каждая операция обновления выполняется последовательно. Однако, команда Twitter планирует добавить функцию использования параллельной записи, если клиенту позволяет полоса пропускания.
При использовании Nfly создание файла или запись выполняется следующим образом:
- В целевой файловой системе, подвергшейся операции chroot, создается временный невидимый файл _nfly_tmp_file;
- Вызывается FSDataOutputStream, который «оборачивает» выходные потоки, возвращен A;
- Все вызовы на запись направляется к каждому выводному потоку;
- При закрытии потока, созданного B все n потоков закрываются и файлы переименовываются с _nfly_tmp_file в file. Все файлы получают mtime, соответствующий времени клиентской системы при начале этого шага;
- Если процесс для конечных узлов minReplication осуществился без ошибок, начиная с шага A до D, то файловая система рассматривает транзакцию, как логически завершенную. В противном случае, происходит попытка очистки временным файлов.
Для запросов на запись поддерживается понятие локальности похожее на HDFS /DC/rack/node. URI сортируются с помощью управляющих элементов из NetworkTopology. Обычно это имена хостов в простых URI HDFS. Если управляющий элемент отсутствует (например, в случае локального file:///), то локальное имя хоста берется за InetAddress.getLocalHost(). Это позволяет гарантировать, что локальная файловая система всегда будет ближайшей к элементу, осуществляющему чтение. Для URI-идентификаторов Hadoop 2 HDFS, основанных на ID служб имен, а не на именах хостов, скрипт довольно просто видоизменить поскольку ID служб имен в системе Twitter уже содержат ссылку на дата-центр. Для стойки и конкретного узла можно вывести любую строку вида /DC/rack-nsid/node-nsid, поскольку для таких клиентов файловых систем важна «локальность» по отношению к ЦОД.
Существует две политики/дополнения к пути вызова чтения, которые делают эту операцию более дорогой с точки зрения вычислительных ресурсов, но улучшают пользовательский опыт.
readMostRecent— Nfly сначала проверяет mtime для пути всех URI и сортирует их по убыванию от самого давнего к самому «свежему». Затем осуществляется сортировка набора идентификаторов URI с самым маленьким временем mtime способом, аналогичным описанному выше.repairOnRead— Nfly уже осуществила контакт с «подлежащими» конечными точками. С помощью repairOnRead файловая система Nfly дополнительно пытается обновить список конечных, добавив туда ближайшую доступную и наиболее недавнюю активную точку для пропущенных путей или давно не обновлявшихся версий.
Как сказано в первой части, управление конфигурациями ViewFs может быть очень сложным делом, а использование Nfly все еще больше усложняет. Однако TwitterViewwFs обеспечивает механизмы, обладающие большой гибкостью и позволяющие добавлять код для генерации полезных конфигураций Nfly «на лету». Если работник Twitter хочет получить домашние директории в логическом кластере C на всех дата-центрах для /nfly/C/user/, то ему просто нужно указать -Dfs.nfly.mount=C. Если же сотрудник затем захочет закешировать файлы локально в /local/user//C, нужно указать -Dfs.nfly.local=true.
Планы
Схема работы с множеством URI, представленная в Nfly, являет собой основу для развития read-only Merge FileSystem, которая прозрачно сливает inode из файловых систем. Инженеры Twitter сейчас работают над созданием подобной системы, которая позволит значительно снизить количество монтировочных таблиц в сравнении с подходом с использованием единого URI для inode. Основной сценарий использования Merge FileSystem — разбиение имеющегося пространства имен (например, пользовательского) на два пространства без необходимости изменения кода и расширения конфигурации. Подробнее разница показана на картинке ниже:
В этом материале команда Twitter поделилась своим подходом к управлению файловыми системами на Hadood: масштабированию для решения задач, связанных с хранением огромного количества данных с помощью федерализованных пространств имен, сохранив при этом простоту конфигурации с помощью ViewFs. Инженеры сервиса микроблогов расширили ViewFs, чтобы упростить работу с постоянно растущим числом кластеров и пространств имен в множестве дата-центров и добавили Nfly для доступности HDFS-данных для разных ЦОД.