

В маркетинговых материалах по защите от DDoS-атак, публикуемых всевозможными компаниями, раз за разом встречаются ошибки одного и того же плана. А именно, приводятся взятые из чьих-либо отчётов данные о зафиксированных атаках объёмом, например, 400 Гбит/с, делается вывод, что всё плохо и нужно срочно что-то делать, но при этом в характеристиках предлагаемых услуг указан верхний предел объёма фильтруемых атак в 10 Гбит/с. И такие несоответствия возникают довольно часто.
Происходит это потому, что специалисты, которые создают саму услугу, не очень верят в то, что столь мощные атаки вообще реальны. Потому что ни сами эти специалисты, ни кто-либо, кого они знают, с такими атаками не сталкивались. И потому возникает актуальный для e-commerce вопрос: какие угрозы действительно сейчас актуальны, а какие маловероятны? Как оценивать риски? Обо всём этом и многом другом рассказывается в докладе Артёма Гавриченкова на конференции Bitrix Summer Fest.
Классификация атак
Давайте для начала поговорим о том, какие вообще бывают атаки. В качестве критерия для классификации возьмём объект атаки, то есть что именно выводится из строя. В этом случае можно выделить четыре основных класса атак, осуществляемых на разных уровнях согласно модели OSI.
Первый класс (L2) — «забивание» канала. Это атаки, которые направлены на лишение доступа к внешней сети вследствие исчерпания канальной ёмкости. Абсолютно неважно, каким именно образом. Как правило, для этой цели используются массированные, с точки зрения трафика, атаки типа «что-нибудь»-Amplification (NTP-, DNS-, RIP-… Amplification может быть любой, не имеет смысла перечислять). Вообще, к данному классу атак относятся всевозможные flood’ы, в том числе ICMP Flood и пр. Основная задача состоит в том, чтобы в канал размером, скажем, 1 гигабит/с залить хотя бы 1,1 гигабит/с. Этого будет достаточно для прекращения доступа.
Второй класс (L3) — нарушение функционирования сетевой инфраструктуры. К этому классу относятся, в числе прочего, атаки, приводящие к проблемам с маршрутизацией в рамках протокола BGP, с анонсами сетей (Hijacking) — или атаки, следствием которых становятся проблемы на транзитном сетевом оборудовании: например, переполнение таблицы отслеживания соединений. Атаки данного класса отличаются большим разнообразием.
Третий класс (L4) — эксплуатация слабых мест TCP-стека, то есть атаки на транспортном уровне. Этот транспортный протокол, лежащий в основе HTTP и ряда других протоколов, довольно сложно устроен. Например, в нём используется большая таблица открытых соединений, каждое из которых является, фактически, конечным автоматом. И именно атаки на этот автомат составляют третий класс DDoS-нападений. К третьему классу можно отнести и атаку типа SYN Flood в том случае, если она не нанесла урона на двух предыдущих уровнях, дошла до самого сервера и вследствие этого априори является атакой на TCP-стек. Также сюда можно отнести открытие большого числа соединений (TCP Connection Flood), что приводит к переполнению таблицы протокола. К третьему классу, как правило, относится также использование таких инструментов, как SlowLoris и Slow POST.
Четвёртый класс (L7) — деградация Web-приложения. Сюда относятся всевозможные «кастомные» атаки, начиная от типичного GET/POST/HTTP Flood до нападений, нацеленных на многократно повторяющиеся поиск и извлечение конкретной информации из БД, памяти или с диска, пока у сервера просто не закончатся ресурсы.
Обратите внимание, что оценивать атаку в гигабитах имеет смысл, в основном, на самом низком уровне (L2). Потому что для вывода из строя, к примеру, MySQL с помощью расширенного поиска по всем товарам много гигабит не надо, как и ума. Достаточно использовать от 5000 ботов, которые активно запрашивают поиск и обновляют страницу, возможно даже, одну и ту же (зависит от настроек кэширования на сервере жертвы). При таких атаках проблемы возникнут у многих. Кто-то «просядет» при атаке 50 000 ботов, самые устойчивые системы выдержат атаку вплоть до 100 000 ботов. При этом в прошлом году максимальное зарегистрированное количество одновременно атакующих ботов достигло 419 000.
Защита от атак
Давайте посмотрим, что можно противопоставить на каждом из вышеперечисленных уровней.
L2. Против лома нет приема, окромя другого лома. Если полоса атаки превышает 100 гигабит/с, то эти гигабиты нужно где-то обрабатывать, например, на стороне провайдера или датацентра, и проблема всегда будет в «последней миле». С помощью технологии BGP Flow Spec можно фильтровать часть атак по сигнатурам пакетов — скажем, Amplification легко отсекается по порту источника. Однако подобный способ довольно дорог и не от всего способен защитить.
L3. На L3 необходимо анализировать сетевую инфраструктуру, причём не только свою. Классический пример — в 2008 году Пакистан из-за собственной ошибки перехватывал префиксы у YouTube посредством BGP Hijacking. То есть значительная часть трафика этого видеохостинга перенаправлялась в Пакистан. К сожалению, автоматически с подобной напастью бороться невозможно, всё придётся делать вручную. Но до того, как начнётся борьба, ещё нужно будет определить, что данная проблема (кража префикса) вообще возникла. Если это произошло, то необходимо обратиться к сетевому оператору, к администрации датацентра, к хостеру и т.д. Они помогут в решении проблемы. Но для этого нужна продвинутая аналитика сетевой инфраструктуры, потому что признаком Hijacking служит, в общем случае, только то, что, начиная с какого-то момента, анонсы данной сети в интернете пошли «нетипичные», не такие, как были в течение длительного времени до этого. Соответственно, для своевременного обнаружения необходимо иметь, как минимум, историю анонсов.
Если у вас своей автономной системы (AS) нет, то можно считать, что борьба с атаками на этом уровне более-менее является долгом вашего датацентра (или провайдера). Однако заранее обычно нельзя сказать, насколько тот или иной датацентр всерьёз подходит к данной проблеме.
L4. Для защиты от атак на четвёртом уровне необходимо проводить анализ поведения TCP-клиентов, TCP-пакетов на сервере, эвристический анализ.
L7. На L7 необходимо проводить поведенческий, корреляционный анализ, заниматься мониторингом. Не имея в наличии инструментов для аналитики и мониторинга, взять и настроить тот же Nginx так хорошо, чтобы он отбил любые атаки, невозможно, борьба с атаками всё равно превратится в ручную работу.
Оценка рисков
Итак, где мы принимаем и обрабатываем входящие HTTP-запросы:
- Купленный или арендованный «физический» сервер
- «Облачный» хостинг
- CDN
Для оценки рисков можно применять такой полезный инструмент, как матрица вероятности и воздействия (Probability & Impact Matrix).
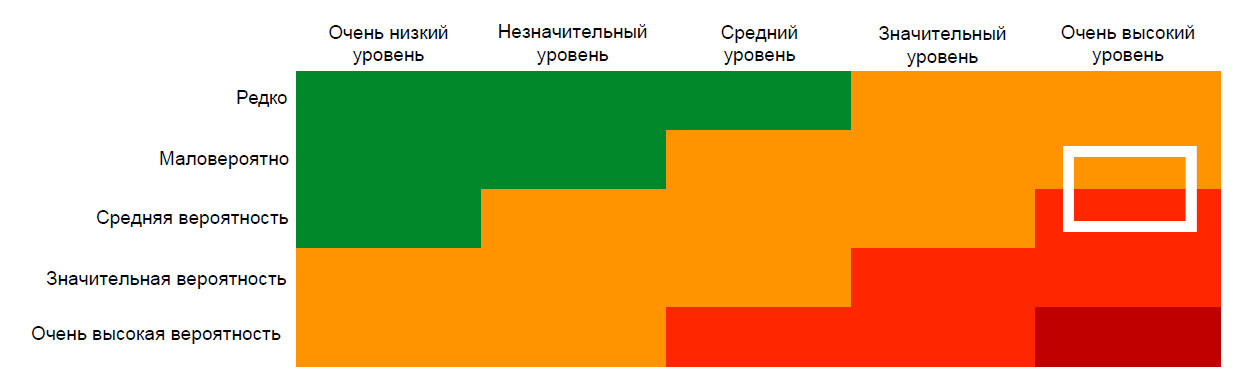
По горизонтальной оси откладывается серьёзность последствий того или иного события, а по вертикальной оси — его вероятность. Белой рамкой в данном случае обозначен текущий уровень риска для DDoS-атак.
От чего зависит вероятность проведения атаки? В первую очередь, атаки — это инструмент конкурентной борьбы. Если в вашем сегменте рынка более-менее спокойно, то, скорее всего, атак долгое время не будет. Но если конкуренция возрастает, то нужно готовиться к защите, и белую рамку нужно перемещать вниз по оси.
Но самое страшное в DDoS-атаке — impact, воздействие. Допустим, нападение осуществляется на вашего хостера. Даже если в этот момент обратиться к поставщику anti-DDoS-решений, то не факт, что он сможет помочь. Проблема в том, что ваш IP-адрес, на котором находится «ваше всё» — от Web-сервера до БД и прочих важнейших компонентов — уже известен атакующим. И даже если вы укажете в DNS какой-то другой адрес, с определённой вероятностью это не сыграет никакой роли и атака будет продолжена напрямую. В лучшем случае, вам придётся съехать с этого хостинга. И в этом случае ваши проблемы можно оценить как «очень серьёзные», потому что трудно придумать что-то хуже для IT-проекта, чем переезд на неподготовленную площадку в рабочее время, при лежащем сервере. Ну вот, разве что, патч Бармина — тот да, точно хуже :)
Почему недостаточно сменить IP на том же хостинге? Потому что новый адрес будет из той же автономной системы (AS). А сегодня злоумышленники уже умеют смотреть на список префиксов автономной системы. Поэтому найти вас на новом адресе труда не составит, достаточно атаковать все адреса в автономной системе.
Давайте попробуем оценить, насколько тот или иной сетевой ресурс подвержен атакам того или иного сетевого уровня.
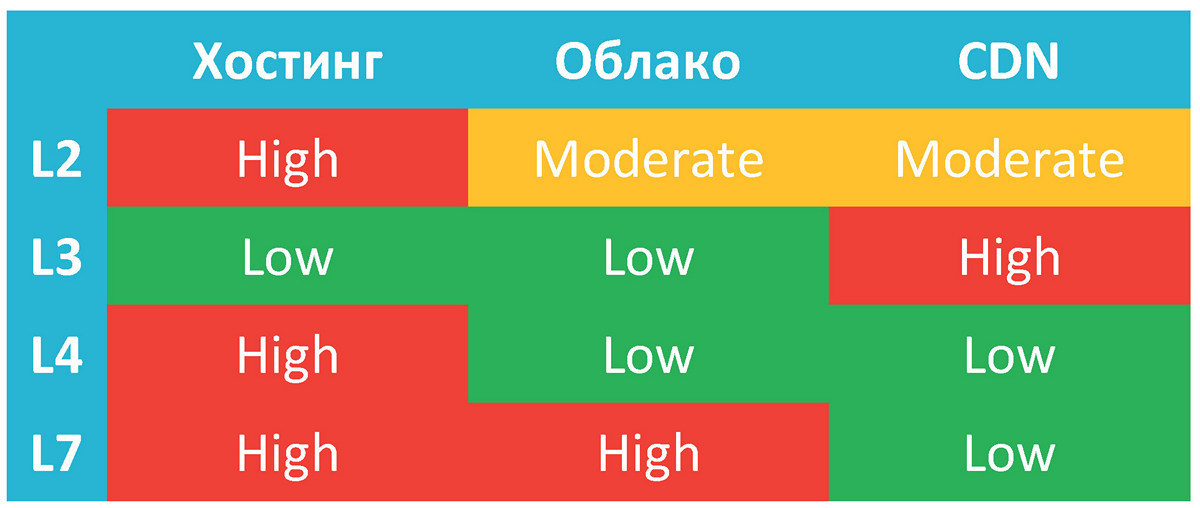
Хостинг. Большинство хостингов не смогут отфильтровать мощные атаки, чей трафик существенно превышает 100 Гбит/с. В том числе и на последней миле до вашего сервера. Поэтому вам придётся самостоятельно обрабатывать весь, или почти весь, флуд, который к вам придёт. И на седьмом уровне вам придётся самостоятельно проводить аналитику, потому что это ваш сервер и ваши проблемы.
На L3 опасность не очень высока, потому что, скорее всего, ради вашего ресурса не будут, скажем, воровать префикс у всего хостинга. Это очень трудоёмко и дорого для злоумышленника. Это можно сделать, но нужно очень веское основание. Хотя, конечно, из всякого жизненного правила бывают исключения, особенно если в сетевой инфраструктуре хостинга есть проблемы с производительностью.
Есть важный момент: очень многие вендоры предлагают для защиты дорогостоящее оборудование, которое ставится в вашу стойку и в него включается uplink и downlink, ведущий к вашему серверу. Проблема здесь вот в чём: сеть не более устойчива, чем устойчива «последняя миля», включая используемое вами оборудование. И у вас в любом случае должен быть запас производительности, чтобы в час пик загрузка процессора не была близка к 100%. В противном случае любой незначительный скачок может привести к отказу. Если атакующие неопытны, и вы можете справиться своими силами, то всё равно вам нужен запас прочности, пока вы изучаете запросы, пишете скрипты для автобана, настраиваете fail2ban и т.д.
Также нужно отметить, что если вы физически располагаетесь на ресурсах, которые не защищены, то смена DNS с вероятностью до 30% вам не поможет. Об этом говорит опыт недавних атак на американские финансовые компании. Так что с большой долей уверенности можно сказать, что вам придётся быстро переезжать с незащищённого хостинга.
Облако. У облака обязательно должна быть Anycast-сеть, то есть один и тот же префикс должен быть анонсирован из многих мест в мире. Потому что в одном месте атаку на сотни гигабит не переварить, а через год можно ожидать уже терабитные атаки. Благодаря распределённой структуре опасность атак на канал сильно снижается. Но даже в условиях Anycast-сети атака в 400-500 гигабит/с — это очень много. К этому нужно готовиться, но не все это делают.
Сеть должна быть распределённой, чтобы злоумышленник не мог эксплуатировать её инфраструктуру. Необходим запас по производительности (желательно, двукратный), потому что никакое количество ресурсов вас не спасёт, допустим, от эксплуатации проблем при обращении к базе.
И наконец, самое «забавное» заключается в том, что облако способно переварить очень много пользовательского трафика, но вам придется его оплатить. Когда счёт достигнет десятков тысяч долларов за прошедший месяц, то вам начнут обрывать телефон, а то и просто отключат по причине вашей неплатёжеспособности. Так что пребывание в облаке всё равно не решает целиком проблему защиты от атак. Оно лишь повышает устойчивость до того, как вы встали под защиту.
CDN. CDN рассчитан на обработку больших объемов трафика, так что со «статикой» (изображения, CSS и пр.) он справится легко. С канальной ёмкостью тут всё то же самое, что и у облака. Но на уровне инфраструктуры гораздо интереснее. У CDN всегда есть DNS-сервер, на который завязаны все услуги ресурса. Если в случае облака инфраструктура сети может быть скрыта за простым Anycast’ом, то у CDN в 99,9% случаев вы будете видеть DNS-маршрутизатор, который перенаправляет пользователя на ближайшую точку CDN. Кроме того, у CDN будут точки, вынесенные из Anycast и из своей сети и расположенные в чужих сетях, поближе к пользователю. Соответственно, они не будут защищены по умолчанию. Их просто невозможно защитить. И здесь всё зависит от того, насколько у CDN защищен его DNS, насколько тот готов к экстренному выключению из сети атакованных нод. Но такое встречается нечасто. DNS-сервер, который занимается раскидыванием пользователей по регионам, должен быть защищён, устойчив и продуман.
Общие советы по сетевой архитектуре
- Anycast-адрес — это очень полезно. И самое главное, что его можно арендовать. Балансировка и резервирование Anycast-маршрутизатором — это в разы надежнее, чем DNS-балансировка.
- Обратите внимание, что IPv4 заканчиваются, и сейчас, если вы – крупная организация, есть возможность получить последний кусок этого пространства адресов. Это нужно использовать, потому что в будущем вам достанется только IPv6, а в этом пространстве пользователей не очень много.
- Лучше отвязать приложение от физического сервера. Слово «Docker» так и просится на язык, но я не хочу здесь привязываться к какой-то определённой технологии. Если вы размещаете где-то приложение, то запаситесь набором документации, инсталляционных скриптов, автоматизируйте развёртывание и конфигурирование — в общем, сделайте что угодно, чтобы быть готовым развернуть такое же приложение с той же базой на сервере на другой площадке. Потому что проблемы могут начаться не только у вас, но и — независимо от вас — у тех, у кого вы размещаетесь. Это довольно частая ситуация.
На сегодняшний день средний уровень угроз достиг такого уровня, что самостоятельно с ними справляться очень сложно. Атакующему гораздо легче организовать нападение, чем жертве — защититься. А после двух суток без сна, абсолютно любой системный администратор больше ничего не в состоянии противопоставить атакующему. Поэтому мы запустили новую услугу для клиентов 1С-Битрикс: десять дней в год работы бесплатно. Под атакой, не под атакой — неважно. Так что если у вас случается беда, то в панели управления вашего сайта последней версии «1С-Битрикс: Управление сайтом» есть заветная кнопка, пожалуйста, нажимайте на неё, не стесняйтесь.
Комментарии (8)

andreili
05.10.2015 11:24Не так давно наш сайт переживал DDoS-атаку от одного недоброжелателя, обидевшегося на админский состав. Во всех случаях хостер просто обрубал нам внешний интерфейс на первом гигабайте траффика (обрубал на 12 часов!!!!!). Причем отрубал молча, без оповещения по почте и СМС. о чем мы узнавали только по факту — либо кто-то из нас замечал не работающий сайт, либо «хомячки» комментировали в ВК, что «аааа, сайт опять упал!!!!».
В первый раз просто подождали конца атаки (около 2-х часов прошло до того момента, пока мы узнали о атаке и лежащем сайте) и отписались поддержке, что бы они включили нам сеть. При этом они предупредили, что повторное обращение такого рода не будет обработано ими, надо самим принимать меры.
Во второй раз (через пару дней после первого) атака повторилась. Мы пошли на крайние меры — быстро склонировали сервер (что сразу сменило IP-адрес сервера) и пустили его через CloudFlare (хватило бесплатного тарифа). Через полчаса после начала атаки сервер уже вполне себе жил и показывал «хомячкам» запрашиваемое.
После этого переписывался с хостером — по результатам этой переписки я понял, что вся работа по фильтрации таких запросов лежит на нас, и делать это надо до нашего внешнего интерфейса.

trurl123
05.10.2015 12:34-1Почему-то на хабре стараются впендюрить картинку для привлечения внимания. Хоть ассоциация темы с картинкой есть, но суть картинки далека от темы.

tomoto
05.10.2015 12:59+1А картинки эти я видел в презентации Qrator. А блог Bitrix. Что-то не сходится… или сходится?



sandman
06.10.2015 04:37>Для защиты от атак на четвёртом уровне необходимо проводить анализ поведения TCP-клиентов, TCP-пакетов на сервере, эвристический анализ.
А можно здесь немного подробней? Не до конца понятно, гдe tcpdump включать, на балансерах или на всех prod-серверах?
aalebedev
Хорошая статья, пишите в этом духе. Хочется больше подробностей о методах защиты.