

После полученных на предыдущие статьи о микропроцессоре Эльбрус откликов мне стало понятно, что для полноты картины не хватает рассмотрения вопроса – а что же делать? Можно ли каким-либо образом улучшить Эльбрус в качестве general-purpose CPU (на что намекали представители МЦСТ) и насколько? Можно ли его применить в каких-то локальных нишах? Давайте попытаемся разобрать данные вопросы.
Доработка микропроцессора Эльбрус для улучшения его характеристик в качестве general-purpose CPU
Как я упоминал в предыдущих статьях, проблемы VLIW-архитектур и статического планирования операций давно известны в индустрии. Поэтому в нашем анализе мы можем опираться не только на некоторые абстрактные идеи и соображения относительно архитектуры Эльбрус, но и на опыт разработки других VLIW-процессоров линеек Intel Itanium, Transmeta, Nvidia Denver, который зачастую очень показателен.
Итак, какие улучшения возможны в Эльбрусе, чтобы улучшить его характеристики в качестве GP CPU процессора?
Локальные микроархитектурные улучшения
Мы опустим мелкие изменения, которые фундаментально ни на что не повлияют. Но есть две вещи, которые жизненно необходимы для микроархитектуры Эльбрус – аппаратный префетчер данных (hardware prefetcher) и предсказатель ветвлений (branch predictor). Данные улучшения не дадут прироста на цифрах Spec CPU2006/2017, которые Алексей Маркин представил в своей статье, т.к. эти результаты получены на пиковых опциях с профилем (а значит, там сделан софтварный префетч и нет проблем с неудачными вызовами в горячих циклах). Но зато они существенно помогут при запуске «неоптимизированного» кода, как в примере с вызовом функции из первой статьи. Это не решит множества других проблем, но даст определённый прирост микроархитектурной скорости на реальных задачах.
Правда, здесь есть один важный нюанс: алгоритмы современных префетчеров и предсказателей достаточно нетривиальны, а в топовых процессорах они вылизывались десятилетиями. Поэтому сразу сделать хорошую реализацию этих модулей не получится - доведение до хороших характеристик потребует немало времени. В первых же версиях новые функциональности будут сбоить и иногда давать заметные ухудшения.
Также возникает проблема совместимости с кодом, откомпилированным под более ранние версии Эльбруса. И если добавление аппаратного префетчера можно сделать прозрачно, то внедрение предсказателя переходов в зависимости от реализации, либо вообще приведёт к несовместимости со старым кодом, либо не даст на старом коде никакого улучшения (вернее, даже даст ухудшение). Т.е. так или иначе, для получения преимуществ новых микроархитектурных улучшений потребуется перекомпиляция всей программной экосистемы.
Спикеры от МЦСТ заявляли, что предсказатель ветвлений планируется к реализации в новых версиях Эльбруса, а аппаратный префетчер чуть ли не уже реализован (правда, никакого упоминания об этом в публичных спецификациях я не нашёл).
Ну и не могу не отметить, что озвученные улучшения – это первый шаг к отходу от концепции статического планирования, сделанного «умным» компилятором.
Что касается других VLIW-процессоров общего назначения, то линейка Intel Itanium изначально имела branch predictor, а в процессе развития получила и hardware prefetcher. Что касается процессоров от Transmeta и Nvidia, то про их архитектуры намного меньше информации (они были скрыты под системами двоичной трансляции), точные данные мне неизвестны, но вероятнее всего, предсказатели ветвлений они в каком-то виде имели.
Динамические оптимизации
Собственно говоря, если обобщить мерцающие технические контраргументы в пользу микроархитектуры Эльбрус в различных дискуссиях, то они сводятся как раз к реализации «динамических оптимизаций». Примерно так это звучит со стороны неофициального телеграм-канала МЦСТ:
В МЦСТ работал сотрудник с такими же именем и фамилией, занимался двоичной трансляцией. Если это не совпадение, а детали и язык говорят, что это он, то Максим действительно знает архитектуру изнутри. Но против его аргументов есть контр-аргументы. Главный - что здесь рассмотрен случай компиляции помодульной, без использования какого-то профиля. А в нормальной "промышленной" реализации не хватает чисто софтварного инструмента - получения профиля от реального использования ПО и докомпиляция этого ПО с учётом профиля и всех имеющихся динамических библиотек.
Это не совсем тривиально, но именно с таким инструментом большинство аргументов Максима "против" можно снять.
И сама архитектура Эльбрус не стоит на месте, в неё добавляются динамические механизмы (уже добавлен префетчер, добавляются в следующей реализации предсказатели переходов и т.п.)
А так в статье Алексея Маркина (автора статьи в защиту Эльбруса):
Для качественной компиляции необходимо понимать, какие участки кода исполнялись больше, а какие меньше. Для этого существует понятие профилирующей компиляции. Это двупроходная сборка, на первом проходе которой выполняется сборка с опцией -fprofilegenerate, после чего программа запускается на обучающем наборе данных. Во время этого обучающего запуска программа выполняет сбор информации о переходах по ветвлениям, вызовах функций и исполнении циклов. На втором проходе производится сборка с опцией - fprofile-use, во время которой компилятор использует полученную информацию для определения оптимального набора и области применения оптимизаций. Использование этой технологии позволяет ускорить исполнение программ в среднем более чем на 17%. Такая схема бывает сложна для пользователя, более того она требует подбора тестовых данных таким образом чтобы программа исполнялась на тех же маршрутах что и при пользовательских данных
…
К перспективным исследованиям можно отнести использование возможностей аппаратного профилирования процессоров Эльбрус-16С для динамической оптимизации исполняемого кода
Показательно, что представители МЦСТ здесь явно признают наличие проблем производительности при компиляции без профиля, и даже совершенно верно указывают, что сбор профиля – это «не совсем тривиально».
Так что же означают эти туманные «динамические оптимизации»? На самом деле, всё достаточно банально – фактически речь идёт о реализации динамического оптимизатора наподобие JVM, который будет работать во время исполнения программы, в динамическом режиме собирая профиль и делая оптимизации, на нём основанные. А аппаратная поддержка тут нужна для сбора качественного профиля с минимальными накладными расходами.
Чисто в теории это - правильное направление. Например, VLIW-процессоры от компании Transmeta и линейка Nvidia Denver изначально исповедовали именно такой подход – они всегда работали ТОЛЬКО в режиме динамической трансляции. Таким образом они решали и проблему программной совместимости (эмулируя архитектуру x86 в случае Transmeta и ARM в случае Nvidia), и проблему отсутствия профиля. Потому что заставить всю программную экосистему переехать на компиляцию с профилем просто нереально, и в компании МЦСТ это тоже прекрасно понимают.
Но у этого решения есть вполне очевидная цена – необходимо разработать эффективный динамический оптимизатор, доработать программную экосистему, всё это интегрировать вместе, и к тому же опять перекомпилировать коды (потому что наиболее эффективная схема реализации динамических оптимизаций требует доработок компилятора lcc). Создать такое решение продуктового уровня даже при наличии опытной команды и достаточных ресурсов – это много лет разработки (я бы оценил в 5-10 лет), а в условиях кадрового голода МЦСТ у меня сомнения в реализуемости такого проекта в принципе. Недаром на текущий момент самые плохие цифры производительности у Эльбруса как раз на бенчмарках различных языков с динамической трансляцией байткода (Java, Javascript и т.д.). И опять-таки, это всё приводит к усложнению программного стэка (например, придётся отлаживать ошибки в коде, созданном динамически «на лету»), а как следствие - к увеличению количества сложных багов и проблем с интеграцией всего этого хозяйства.
Как «динамические оптимизации» улучшат ситуацию, даже если всё вышеописанное в конце концов сделать? Для цифр Spec CPU2006/2017 это снова не даст никакого роста производительности – напомню, что заявленные результаты от МЦСТ получены на пиковых уровнях оптимизации с профилем. Улучшения будут присутствовать опять-таки на «неоптимизированном коде» и составлять они будут в среднем порядка 17% - если ориентироваться на цифры, представленные Алексеем в своей статье (и эти цифры примерно согласуются с моими оценками).
Радикальная переработка микроархитектуры
Самый перспективный, но, к сожалению, нереалистичный вариант. Нереалистичный потому, что масштаб переделок таков, что он сопоставим с разработкой абсолютного нового процессора с нуля. При этом направление изменений будет диктовать отказ от множества особенностей Эльбруса, что по факту полностью девальвирует саму идею VLIW и статического планирования.
Но давайте подробнее. Для желающих глубже погрузиться в вопрос сложностей VLIW-архитектур, как их пытались решить и почему в итоге это направление было признано бесперспективным для general-purpose CPU, я настоятельно рекомендую поизучать историю линейки процессоров Intel Itanium. Как по мне, она крайне показательна. Ведь в разработку Intel Itanium были вложены огромные усилия и ресурсы – компания Intel видела в данной линейке свою будущую 64-битную архитектуру, из-за чего даже упустила создание x86-64 со стороны AMD, и была вынуждена догонять конкурента.
Особый интерес в плане изучения опыта Intel Itanium для нас представляет статья с говорящим названием «General Purpose VLIW is Dead»(ссылка). В ней описана микроархитектура уже 7-го поколения процессоров Itanium с кодовым именем Poulson. Это - вершина развития линейки Intel Itanium в плане микроархитектуры. Последнее, 8-ое поколение Kittson было де-факто тем же Poulson с улучшенными частотами. Посмотрим на схему микроархитектуры Poulson в сравнении с предшественником Tukwila:
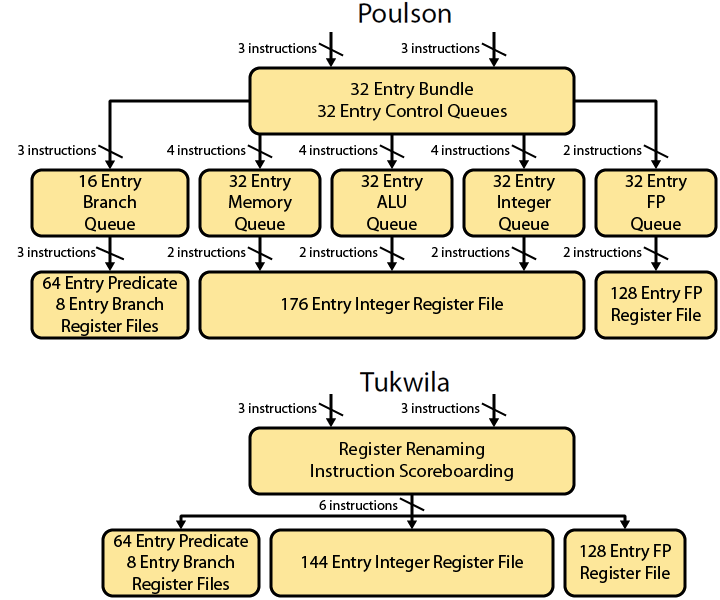
Для Tukwilla всё типично для VLIW-архитектуры – инструкции, поступая с декодера, читают значения из регистрового файла и отправляются дальше на исполнительные устройства (последние на картинке опущены).
А что мы видим для Poulson? Инструкции с декодера попадают в Instruction buffer, а дальше - Branch Queue, ALU Queue, Memory Queue и т.д. Хм, да это же попытка реализовать простейший ОоО в условиях VLIW! По этому поводу автор статьи пишет:
Tukwila and all earlier Itanium designs were VLIW microarchitectures; compiled bundles formed the basis of execution and instructions were statically scheduled. Any dependencies were resolved by global stalls. The global stall microarchitecture would halt the entire pipeline until the problem had been resolved.
Poulson is fundamentally different and much more akin to traditional RISC or CISC microprocessors. Instructions, rather than explicitly parallel bundles, are dynamically scheduled and executed. Dependencies are resolved by flushing bad results and replaying instructions; no more global stalls. There is even a minimal degree of out-of-order execution – a profound repudiation of some of the underlying assumptions behind Itanium
Последнее предложение подводит знаковую черту под концепцией VLIW-архитектур – в итоге своего развития они пришли к тому, что необходимо реализовывать ОоО-исполнение внутри процессора. А в таком случае все особенности VLIW – это лишь помеха. Поэтому отказ от VLIW-архитектур для general-purpose CPU стал неизбежностью.
В условиях Эльбруса всё аналогично. Если делать столь радикальные переделки микроархитектуры с реализацией ОоО во VLIW-архитектуре, то это колоссальная по сложности работа. Причём по её итогу придётся просто выбросить многие «фишки» Эльбруса, которые станут ненужными. А главное – сама концепция широкой команды в таком случае становится не только бессмысленной, но даже вредной. Поэтому намного проще взять обычную RISC архитектуру и сделать на её основе современный процессор с ОоО-исполнением. Это будет проще, быстрее, дешевле, а в итоге получится более быстрый и удобный для пользователей процессор.
Давайте подведём небольшой итог. Из реалистичного (префетчер, предсказатель ветвлений,и даже пусть динамические оптимизации) - в Эльбрусе можно сделать набор определённых улучшений, которые позволят улучшить производительность на реальных задачах. При этом из предыдущих статей помним, что верхний предел микроархитектурной скорости на Эльбрусе, рассчитанный по данным запусков на Spec CPU2017, в 3-4 раза уступает современным RISC/CISC процессорам с ОоО исполнением. Эта оценка не изменится. Для «неоптимизированного кода», где производительность может деградировать в разы от микроархитектурной скорости на Spec CPU2017, ситуация улучшится. Ввиду отсутствия Эльбрусов в свободном доступе нет возможности привести точные значение ускорения. Но, я бы грубо оценил, что на коде из реальной жизни средняя производительность сейчас падает в 2 раза по сравнению с цифрами на Spec CPU2017, т.е. Эльбрус по микроархитектурной скорости приблизительно в 6-8 раз хуже современных RISC/CISC аналогов. Предложенные улучшения подтянут это соотношение где-то к 5.
Из вышеизложенного, как мне кажется, вывод достаточно очевиден – попытка допилить Эльбрус принципиально ничего не изменит. Как general-purpose CPU он всё равно будет существенно уступать современным RISC/CISC аналогам именно в силу изначальной концепции, заложенной в архитектуру. Индустрия этот путь прошла, различные варианты решения проблемы известны и изучены, они не помогают. Яркий пример в этом отношении - история линейки Intel Itanium. Компания МЦСТ в данный момент лишь пытается повторить то, что 20 лет назад уже было опробовано. Но результат здесь уже известен заранее.
Потенциальные ниши для применения микропроцессора Эльбрус
Но бесперспективность Эльбруса как general-purpose CPU ещё не говорит о том, что не существует локальных ниш, в которых он может быть конкурентоспособен. Попробуем проанализировать, где микропроцессор Эльбрус всё же может найти своё применение.
-
Специализированные процессоры
Хотя VLIW-архитектуры больше не применяются в general-purpose CPU, тем не менее, они находят широкое применение в специализированных решениях, таких как DSP процессоры и графические процессоры (хотя в графике VLIW-архитектура тоже уже не самый оптимальный подход). Но переделывать Эльбрус в решения такого рода малоэффективно. Данный процессор изначально проектировался для серверного и десктопного сегментов, в нём множество вещей, не нужных для специализированных решений, и наоборот – нет необходимой специфики для других доменов. Можно на базе наработок Эльбруса создать какое-то решение, но это де-факто будет разработка нового специализированного чипа. Поэтому данное направление развития не является сколь-либо перспективным для Эльбруса, на мой взгляд.
-
Решения для безопасности
В Эльбрусе есть две функциональности связанные с безопасностью, отсутствующие в массовых процессорах, доступных сейчас на широком рынке – это отдельный стек вызовов и аппаратная поддержка тегированной памяти. В остальном он ничем принципиально не отличается по безопасности от современных RISC/CISC процессоров.
Отдельный стек вызовов – полезная «фишка», но проблема в том, что она закрывает только одну из множества потенциальных угроз – так называемую ROP-атаку. При прочих равных, это приятное дополнение, но только при условии, что по остальным характеристикам процессор конкурентоспособен. Т.к. для Эльбруса это не так, то ценность наличия отдельного стека вызовов становится нулевой.
А вот с тегированной памятью, на мой взгляд, ситуация интереснее. В теории, компиляция и запуск программы в таком режиме (называемым защищённым) позволяет обнаруживать различные ошибки и потенциальные уязвимости в коде. Сейчас в индустрии многие крупные компании тратят серьёзные ресурсы на поиск и исправление ошибок в своих продуктах, используя разные программные средства статического и динамического анализа корректности поведения программы. Вполне возможно, что для них будет интересно использовать программно-аппаратное решение на базе Эльбруса, если оно будет быстрее или качественнее. Правда, данный рынок крайне мал, и вряд ли там потребуется больше нескольких тысяч Эльбрусов. Но это уже задача для маркетологов МЦСТ - детальнее разобраться в потенциале данного направления
-
Запуск Windows-приложений
В контексте импортозамещения может возникнуть ситуация, когда некоторый софт будет возможно запустить только под Windows. И если сделать эффективное решение по двоичной трансляции для Linux-приложений можно без аппаратной поддержки, то запустить Windows без помощи со стороны процессора уже достаточно сложно и требует большого времени на разработку. В то же время в Эльбрусе аппаратная поддержка для двоичной трансляции и сам транслятор уже присутствуют. В том случае, если пользователи готовы смириться с существенной потерей в производительности, решение на базе Эльбруса вполне может им подойти. Но тут есть одна стратегическая проблема – если мы ставим процессоры в рамках импортозамещения, то странно для таких решений использовать ОС Windows. Т.е. переход на Linux-based дистрибутивы и перевод всего программного обеспечения под Linux в данном случае будет лишь вопросом времени. Поэтому Эльбрус здесь может выступать лишь как решение для переходного периода, и в перспективе этот рынок будет стремиться к нулю.
-
High Performance Computing (HPC)
Если мы внимательно посмотрим на характеристики процессора Эльбрус, то заметим, что он обладает достаточно внушительными показателями так называемых GFLOPS. Иными словами, потенциально, Эльбрус может совершать очень большое количество операций над вещественными данными за единицу времени. Например, для самого последнего процессора от МЦСТ Эльбрус – 16С этот параметр составляет 750 GFLOPS для вещественных чисел двойной точности. Этот показатель не просто внушителен в пересчёте на одно ядро, где он вплотную подбирается к самым топовым решениям от Intel, но даже очень прилично выглядит в абсолютных значениях. Самый производительный процессор от Intel, который я нашёл в данном списке, имеет 1612 GFLOPS, и это показатель для 28-ми ядерного решения!
Да, мы знаем, что на практике в Эльбрусе эти гигафлопсы плохо помогают на большинстве реальных задач от пользователей, но логично тогда поискать тот класс задач, где их можно всё-таки заиспользовать. И тут сразу напрашивается ответ – это High Performance Computing (HPC). Опять-таки, далеко не для всех задач в HPC количество гигафлопсов важно, но в общем и целом - это тот класс задач, где многие недостатки VLIW-архитектуры нивелируются, и Эльбрус может демонстрировать свой потенциал не только на бумаге. Тем более, что HPC вычисления, как правило, сопровождают достаточно квалифицированные специалисты, которые понимают специфику своих вычислений и по природе своей работы должны углубляться в особенности процессора и могут адаптировать программу под Эльбрус.
Из недостатков данного рынка применений для Эльбруса – он также крайне ограничен (сюда включаются как непосредственно суперкомпьютеры, так и часть пользователей, которым нужен запуск такого класса задач на своих машинах). Можно говорить о тысячах, возможно о десятках тысяч процессоров. Но всё равно это небольшие объёмы, которые будут держать реальную цену процессора очень высокой. Наличие вычислительного кластера, который хорошо считает только на определённых задачах, также не добавляет Эльбрусу плюсов в глазах потенциального клиента. Также здесь Эльбрус фактически вступает в конкуренцию с современными графическими картами, но т.к. в России они сейчас вообще не производятся, этот момент можно пока опустить.
Собственно, на мой взгляд, это все варианты, которые заслуживают обсуждения. Ситуации, когда приобретение процессора лишено экономической логики, рассматривать смысла не вижу - там возможно всё, что угодно.
Если внимательно посмотреть на вышенаписанное, то можно суммировать, что у Эльбруса, как представителя семейства VLIW-архитектуры, нет потенциала приблизиться к современным RISC/CISC процессорам по производительности на general-purpose нагрузках, даже с учётом доработок.
При этом возможные ниши для практического применения Эльбрусов существуют, но эти ниши достаточно узки и в большинстве случаев Эльбрусы в них могут быть безболезненно заменены обычными RISC/CISC процессорами.
Комментарии (212)

YuriPanchul
02.10.2021 20:20+2*** внедрение предсказателя переходов в зависимости от реализации, либо вообще приведёт к несовместимости со старым кодом, либо не даст на старом коде никакого улучшения (вернее, даже даст ухудшение). ***
А почему? Из-за введения каких-нибудь инструкций типа branch likely? Это совсем необязательно, branch predictor можно сделать прозрачным, только сливать конвейер при mispredict.

Armmaster Автор
02.10.2021 21:56+3Если сделать branch предиктор прозрачным - это вариант 1. Но в таком случае все nop'ы в старом коде останутся и бранч предиктор ничего не даст, только в момент перехода начнёт ещё иногда ошибаться и это даст ухудшения. Хотя может быть это можно как-т ооптимизировать, надо подумать.

BugM
03.10.2021 03:28+1Это же решается просто перекомпиляцией тех же исходников.
С учетом количества и массовости софта под Эльбрус перекомпиляция всего и раскатка в прод новых версий под новый процессор не выглядит нерешаемой задачей.
Armmaster Автор
03.10.2021 16:07Я не уверен, что это можно назвать простым, учитывая, сколько сейчас копий ломается вокруг портирования софта. В любом случае это лишняя работа, причём в контексте Эльбруса более объёмная, чем для других архитектур

Vedomir
02.10.2021 22:50+2Правда здесь есть один важный нюанс: алгоритмы современных префетчеров и предсказателей достаточно нетривиальны, а в топовых процессорах они вылизывались десятилетиями. Поэтому сразу сделать хорошую реализацию этих модулей не получится — доведение до хороших характеристик потребует немало времени. В первых же версиях новые функциональности будут сбоить и иногда давать заметные ухудшения.
Если я все правильно понял, то это проблема будет касаться и RISC out-of-order процессоров отечественной разработки не считая покупки уже готовых ядер от той же самой ARM где все это уже делалось кучу времени.Armmaster Автор
02.10.2021 23:00+4В целом - да. Хотя в случае RISC-V есть большая экосистема с разделением труда, где уже опытные люди будут писать сами ядра на HDL (включая branch predictor) и их оптимизировать, и цикл разработки там более короткий, что позволит быстрее довести реализации до хорошого уровня.

victor_1212
02.10.2021 23:56>В Эльбрусе есть две функциональности связанные с безопасностью, отсутствующие в массовых процессорах, доступных сейчас на широком рынке – это отдельный стек вызовов и аппаратная поддержка тегированной памяти.
на перспективу (далекую) развитие в этом направлении вероятно будет востребовано, учитывая опыт компании об этом стоит подумать, нечто подобное CRASH для специальных применений в первую очередь
ps
Б.А. вскользь упоминает об этом проекте в своей старой статье
Armmaster Автор
03.10.2021 00:11Вопрос в масштабе этого рынка. У меня есть сомнения, что он позволит хоть как-то окупить разработку процессора. Да и по факту мы видим, что на текущий момент никакого особого спроса по данной линии на Эльбрус нет.
victor_1212
03.10.2021 01:40+1>позволит хоть как-то окупить разработку процессора ...
правильно, не позволит очевидно, и спроса нет потому что пока гром не грянул, креститься никто не собирается, но именно это направление заслуживает внимания, и cpu cycles, как обычно строго imho

vladshulkevich
03.10.2021 18:03+1как я уже неоднократно предполагал, проблемы окупаемости нет. Причем тут масштаб рынка вообще не вкуриваю. Это "изделие военной техники".

surVrus
02.10.2021 23:57+4Благо дарю за статью! Очень познавательно.
Однако мне хотелось бы добавить одну бочку дегтя, к описанной ложке меда про потенциальные возможности Эльбруса.
И только в аспекте экономики и рынка. Технику и технологию оставлю в стороне.
Допустим, что у Эльбруса есть перспективы в какой-то нише. Эта ниша может быть в России, и может быть (чем черт не шутит) и в некоем экспортном потенциале.
Берем самый оптимистичный сценарий: всем чиновникам в России поставят только компы с Эльбрусами. Это от 2 до 3 млн компов. Плюс еще столько же всей их мишпухе. Выходит - от 4 до 6 млн штук. Каждому военному тоже по компу. Еще столько же выйдет (мы оптимисты!). Итого - от 8 до 12 млн штук весь рынок. Много это или мало? Мировой рынок компов (включая таблеты) в 2020 году около 460 млн штук. То есть вся эта байда с Эльбрусом - менее 3% от рынка. Если по-честному, то в пределах погрешности оценки этого самого рынка.
За что биться? все госзаказы, вся военка вместе взятая - это слезы и мелочи на экономической арене. Да и этот сегмент рынка - весьма "хрупкий". Рано или поздно кому-то в правительстве взбредет в голову вернуться к "интеграции" и "миру-мир" - и вся эта бредятина про "импортзамещение" сгинет без следа, вместе с Эльбрусом. Так не будет? Да только на моей памяти (за последние 40 лет) в России политический строй поменялся 2 раза. Про всякие там "политики гласности", и прочее - вообще вспоминать лень.
И что тогда? Не будет лоббирования "госзаказа" - рухнет вся структура Эльбруся. Потому как без такого "госзаказа" - она неконкурентноспособная, от слова "совсем". Нигде, никому кроме этого сегмента принудительного "госзаказа" не нужная.
Armmaster Автор
03.10.2021 00:19+3Если продавать любой российский general-purpose проц тиражом порядка 10 млн в год, это будет суперокупаемый продукт, а компания будет торговаться на бирже в топ-10.
Но в предыдущих статьях я уже высказал своё мнение, что:
По возможности процессор должен иметь экспортный потенциал.
Текущая помощь от государства должна в итоге к тому, чтобы отечественные компании, производящие процы, смогли выйти на горизонт конкурентоспособности, чтобы быть в состоянии вести экономическую деятельность с минимальной поддержкой от государства.
Ну т.е. мне кажется, это тезисы перекликаются с тем, что вы написали.

plumqqz
03.10.2021 00:57+2У Эльбруса как раз замечательный экспортный потенциал - это не штатовский процессор, а уверенно обстреливать штатовские корабли и самолеты хотели бы уметь очень многие страны, так что эльбрус может быть очень интересен; рынок, правда, все равно маленький.

checkpoint
03.10.2021 03:41+3Для того, что бы обстреливать чьи-то корабли нужны ПЛИС, процессоры в этой теме уже давно ушли на второй или третий план.
plumqqz
03.10.2021 14:39checkpoint
03.10.2021 23:18Про них и речь. Там все на ПЛИСах. ЦП используется в рабочих местах оператора, типа ПЭВМ ЕС1866, в которую просится что-то на базе ARM или MIPS.

mikhanoid
04.10.2021 17:20Плисы не везде «влезают» по своему энергопакету. DSP-процессоры используют не реже.
surVrus
03.10.2021 09:45а уверенно обстреливать штатовские корабли и самолеты
Не совсем понимаю, как связаны процессоры и обстрел каких-то кораблей. Если возможность обстрела кораблей существенно зависела бы от вычислительной мощности того, кто стреляет, то шансов их обстрелять не было бы никаких. Подключить неограниченные вычислительные мощности (тупо 100 500 000 процессоров) для США не представляет скорее всего никакой проблемы.
Кстати, если это могут быть любые процессоры, в том числе и Эльбрус. Американцы могут их свободно использовать в таком своем гипотетическом "супер оружии" Не?
Наверное и иным странам ничего не мешает использовать процессоры, разработки США, против кораблей США. Вроде нет никакого метода для процессора определить, в какой области знания работает программа на нем. Встроенного в процессор метода.
Ну и Ваши представления о текущем уровне военной техники сильно искажены. Ни в военке, ни в космосе, в "критических" и "важных" технологиях процессоры типа Эльбрус практически не используются. Скажем так, там используются намного более примитивные, более быстрые, более простые, более надежные, менее очевидные, но и более дорогие методы решения задач, которые на "гражданке" решаются при помощи процессоров.

Paskin
03.10.2021 13:40Разговоры про необходимость не-Штатовских процессоров вызваны обычно верой в то, что штатовские можно каким-то образом отключить в угрожаемый период - как правило, не подкрепленной знаниями, тем более - как это сделать, не "задев" свою же технику.
Эльбрусы вроде как собирались использовать во всяких АРМ и системах управления - хотя судя по тому, что даже в пропагандистских роликах команды все равно отдаются голосом по телефону - они действительно не mission-critical.
plumqqz
03.10.2021 14:41Вы это, например, Эрдогану объясните, который после попытки переворота вдруг озаботился не штатовской ПВО.

stranger_shaman
03.10.2021 16:04в этой не штатовской ПВО вовсю используются штатовские атмеги.

amartology
04.10.2021 12:13+4Вы бы не писали такое в интернет. С прошлой пятницы за такое можно уголовное дело получить.
odins1970
03.10.2021 16:13Вы можете гарантировать, что интерес Турции к системе ПВО российского производства не является частью ее игры с США , для выбивания себе экономических и политических льгот ???

sim2q
04.10.2021 09:59Никто не может гарантировать что то на 100%, но так получается, что "у нас" вообще ничего не будет

uzverkms
03.10.2021 12:09+1Настоящий взлёт x86 (Intel) случился не из-за необходимости кого-то обстреливать, а из-за выхода на широкий гражданский рынок.
surVrus
03.10.2021 10:26Если продавать любой российский general-purpose проц тиражом порядка 10 млн в год,
В том-то и беда, что я ошибся. У буржуев продают по 450 млн компов в год. А в России - весь рынок "компов для чиновников" и "военки" - 10-12 млн. Не на год, а вообще.
Да и скорее всего не смогут столько выпустить процессоров, если 10 млн в год компов надо делать.
По возможности процессор должен иметь экспортный потенциал.
Это да, тут я с Вами согласен. Но Эльбрус его не имеет, совсем не имеет. Ключевое слово тут "никогда".
смогли выйти на горизонт конкурентоспособности,
Это да, тоже все верно. Главное тут - сроки. Государство может (даже обязано) управлять развитием технологий, давать на это огромные деньги и ресурсы. Но с точно обозначенной экспортной целью и не менее жестко ограниченными сроками. Тогда обычно такая поддержка срабатывает.
это тезисы перекликаются с тем, что вы написали.
Да, совершенно с Вами согласен.

lelik363
03.10.2021 15:13За что биться? все госзаказы, вся военка вместе взятая — это слезы и мелочи на экономической арене.
Есть ещё IIOT — промышленная автоматизация и промышленный интернет. Рынок очень большой. А так как Россия страна с преимущественно холодным климатом, то процессоры с рабочим диапазоном температур -45С… +100С имеет хорошую перспективу.surVrus
03.10.2021 17:48+1Есть ещё IIOT
Есть такая песня. Но в ее тексте нет слова "Эльбрус".
При энергопотреблении от 50 Вт, перспективно использование такого процессора только в качестве системы отопления в квартире.
Насчет промышленной автоматизации - тут да, тут Вы правы. Но в этой области роль самих процессоров небольшая. Более важны всякие интерфейсы (ADC DAC входы-выходы). Причем чтобы все это было надежным, защищенным от разных помех, и т. п. То есть вся "обвязка" автоматики занимает намного больше места и более важна. А ее "от производителей Эльбруса" нет. Есть вполне себе обычные стандартные решения. И вот зачем тогда нужен очень дорогой супер-процессор, который еще и купить не так просто?
Да и в автоматике важную роль играет софтовая "обвязка" этого всего железа, привычки и предпочтения разработчиков. Чтобы туда влезть со своим продуктом надо потратить не один год.
lelik363
03.10.2021 21:10+1При энергопотреблении от 50 Вт, перспективно использование такого процессора только в качестве системы отопления в квартире.
Странное заявление. Во всем мире считают иначе. COM-HPC Ampere Altra 175W TDP — это один из примеров решения промышленного использования.surVrus
03.10.2021 22:09-2Согласен. Для 1-2% задач IIOT может быть такое применение, где TDP не играет особой роли.
И уупс, я пропустил в слове IIOT одну буковку I. Ошибочка, прошу прощения.
Я то думал про IOT, про него и написал.

OpenA
06.10.2021 06:44+2Я ничего не фантазирую а смотрю в ассемблер и на сообщения компилятора.
И он скомпилировал это без каких либо предупреждений, при этом в ассемблере хорошо видно что:
{ nop 2 return %ctpr3 addd,0,sm 0x0, 0x0, %dr21 ldgdw,2,sm 0x0, [ _f32s,_lts0 start ], %r0 addd,3,sm 0x0, 0x0, %dr23 ldgdw,5,sm 0x0, [ _f32s,_lts0 start ], %r1 } { sxt,2,sm 0x2, %r0, %dr20 sxt,5,sm 0x2, %r1, %dr22 } { movtq,0,sm %qr20, %qr20 shls,2,sm %r2, 0x2, %r0 movtq,3,sm %qr22, %qr22 }1. он загружает данные размером 32бита
2. кладет их в двойной регистр (младшую часть квадрорегистра), старшую часть заранее заполнил нулями,
3. и наконец делает над квадрорегистром адресное преобразование командой movtd (mov tag data или что то типа этого).
Скорее всего он создает таки локальный указатель на данные, по типу
(StructRGB *){0,0,0,}только с числом, используяarrкак переменную. Если это так то упало скорей всего из за+ indexнадо попробовать отставитьarr = (int*)startи посмотреть будет ли ссылка на число.А при чтении массива падать будет все равно потому что безопасный режим не разрешает читать неинициализированные данные надо его перед этим или заполнить или использовать memset(arr, 0 sizeof(int) * n)
Читать плачь про слишком строгие правила работы с указателем было забавно, учитывая что в других языках с ними вообще ничего нельзя делать, кроме как получить или передать. Запустите лучше вот такой код, если вам не сложно. Интересно все таки структура указателя, по ассемблеру получается что при складывании он увеличивает поле size, может расположение не такое просто.

a1batross
05.10.2021 13:03+2Вы показали код с UB, который стреляет вам в ногу. Какой нехороший защищенный режим, на нём код с UB не работает!
Armmaster Автор
03.10.2021 00:56+2В некоторых компаниях готовы переписывать код и тратить на это большие ресурсы, если это повысит надёжность кода. Поэтому я вполне могу предположить, что какая-нибудь крупная компания скажет - "окей, наша задача - портировать проект на Эльбрус в защищённом режиме. Если что-то не работает - значит это ошибка и мы переписываем код". Потом полученный результат возвращается обратно на родную систему и там уже компилируется в итоговый продукт. Безусловно, мало кто на такое пойдёт (я потому и написал, что потенциал рынка небольшой). Но в теории это возможно. Насколько для таких задая valgrind и/или sanitizer лучше - вопрос открытый. Возможно, что лучше. Тогда действительно защищенный режим будет никому не нужен.
OpenA
04.10.2021 23:09Там принципиальная проблема: в защищенном режиме 128-битовый указатель содержит размер выделенного блока, тэги, адресс начала блока и offset.
В коде часто встречается присвоение целому значению указателя, потом какая-то арифметика над этим целочисленным значением, а потом присвоение нового значения обратно в указатель.
Если речь про что то типа такого:
int *arr = malloc(sizeof(int) * n), start = (int)arr; ... if (index > n) { arr = start + (index - n); }То это скорее всего работать не будет, но будет работать вот так:
int *arr = malloc(sizeof(int) * n), *start = arr; ... if (index > n) { arr = start + (index - n); }Причина не в 128и битных указателях. В ассемблере адрес все равно ложится в виде числа на регистр, обращение к памяти происходит специальными командами, в том числе поддерживающими обращение по смещению. А вот сохранить на стек в виде указателя то что не является указателем уже нельзя, банально потому что указатель в безопасном режиме - это тип, а у типов строгие правила преобразования в (зависимости от языка).
В данном примере указатель складывается с целым, что по правилам Си дает указатель. Но вообще оказалось что работает и в первом случае, если расставить явные преобразования типов https://ce.mentality.rip/z/PcrYGM
К слову указатель на процедуру отличается, полагаю и работа с ним тоже. В любом случае весь вот этот безопасный режим это просто как аппаратная виртуальная машина для Си привносящая в него безопасность уровня джавы. И это не такой режим как в интеле при переключении 32/64 адресации, он работает как отдельное адресное пространство работа с которыми происходит через специальные команды. Функции из него наверное даже можно из небезопасного режима вызывать с некоторыми ограничениями, надо только в ОС реализовать поддержку.
a1batross
05.10.2021 02:40+2Представьте себе код в котором норма кастовать указатель в какой-нибудь int, считать это нормой и надеяться что это не выстрелит.
Ну ладно, кому-то и так сойдет.

vakhramov
03.10.2021 16:50+1Рынок персоналок? Есть места, где надо много вычислительных мощностей разного характера применять. Так что рынок процессоров - это не только рынок ПК.

Wan-Derer
05.10.2021 07:05+1всем чиновникам в России
Добавь школы/ВУЗы
в некоем экспортном потенциале.
Соседние страны, которым тоже постоянно грозят сцанкциями.
Страны, которые тоже хотят получить хоть что-нибудь неамериканское. Вспомним скандал с "прослушкой" германского начальства. Прекрасный был повод подкатить к бабуле и предложить! Почему не сделали - непонятно. Хотя может и сделали, просто нам не сказали.
ЗЫ: конкретно у Эльбруса тут м.б. внутренняя конкуренция. Вон, Байкал уже запилил десктопный проц и грозят серверным...
anonymous
00.00.0000 00:00Armmaster Автор
03.10.2021 00:29+1Я потому и написал - в теории. Там на самом деле можно вокруг этого играться и доводить до чего-то удобоваримого, наверное. По-крайне мере какие-то идеи были в эту сторону, но актуальной ситуации я не знаю. В конце концов, это не моя головная боль, пусть МЦСТ думает.
a1batross
05.10.2021 15:08Да куда отводить-то разговор? Я не читал ветку, мне в целом всё равно. :)
Но вот про uintptr_t я не знал. Как-то странно что его тоже не расширили. Подстава, однако.
Но я всё же про каст адреса в int где гарантии что адрес поместится нет. И вот тут будут проблемы не только с защищенным режимом, но и с LP64.
a1batross
05.10.2021 18:41+1Я повторюсь.
int, не long. И даже так, long не говорит о том, что указатель в него уместится.
Для этих вещей придумали (u)intptr_t и да, очень неочевидно что он не совпадает с указателем в режиме ptr128. Наверное это баг.Если бы я имел отношение к МЦСТ, я бы завёл им баг. Но на самом деле мне лично всё равно.

LiauchukIvan
03.10.2021 00:49+1Спасибо большое за очередную интереснейшую статью. Очень приятно, будучи чайником в вопросах архитектур ЦПУ, всё-таки понимать куда, как и почему мы движемся в данном направлении.
Касаемо практического применения Эльбрусов, какое у вас мнение о так называемых Горынычах, которые сейчас поставляются на базе этих процессоров, и вроде бы вполне успешно занимают свою нишу.
Armmaster Автор
03.10.2021 01:04Я не очень понимаю этого кадавра. Возможно, где-то "многоместные рабочие станции" имеют смысл, но со стороны они выглядят странно. Уж делать тогда нормальные тонкие клиенты на сервер. А тут полурешение какое-то.
В любом случае, для таких применений любой GP CPU будет лучше - это его нагрузка. Да тот же Байкал-М там превзойдёт Эльбрус-8С.

Civil
03.10.2021 02:10+1Я не очень понимаю этого кадавра.
Я могу предположить, что этот кадавр появился только потому, что Эльбрус - редкий зверь. Так можно попытаться представить что он стоит дешевле (в 4, кажется, раза, на 1 рабочее место). Главное не обострять внимание на том, что это обычное разделение одной машины (и на том, что это не уникальная для Эльбрусов вещь).
a1batross
04.10.2021 18:40+2А 8СВ нет.
Civil
05.10.2021 01:53В типичных для людей задачах - и его тоже, в несколько раз притом.
a1batross
05.10.2021 02:36+2Что такое типичные задачи? A57 не вытянет мои ежедневные типичные задачи. :)
Civil
05.10.2021 10:30-1Ну посмотрите чем типично люди занимаются (как на работе так и дома). Вот обобщенно-собирательный образ и будет этим "типичные задачи" (строго говоря большая часть это браузер и js для среднестатистического юзера).
И я не говорил что А57 их будет хорошо тянуть, просто 8СВ будет еще хуже.
a1batross
05.10.2021 13:07+2Кроме специфичного софта который прибит к x86, я не вижу чего-то сложного.
8СВ к вашему сожалению не настолько плох, я его видел в работе и поставил бы рядом с основным десктопом. За одним работать, а другому оставить роль аппаратного ускорителя вебни.
VLev
03.10.2021 01:08+1Спасибо за статью.
В отличие от двух предыдущих -- тут практически со всем согласен без оговорок.
Единственный вопрос (боюсь, риторический):
Почему за 20 лет существования микроархитектуры (например, в Verilog) и 12 лет существования Эльбрусов 6 чтоли поколений в железе так и не были реализованы указанные улучшения в микроархитектуре, а сильные стороны (FLOPs-ы) не были проявлены хотя бы в демонстрационном супере?
Про кластер в ЦИАМ знаю, но он ни разу не демонстрационный. Это всё равно как в чёрной дыре установить.
Armmaster Автор
03.10.2021 01:37+2Почему за 20 лет существования микроархитектуры (например, в Verilog) и 12 лет существования Эльбрусов 6 чтоли поколений в железе так и не были реализованы указанные улучшения в микроархитектуре
Сначала были объективные кадровые проблемы, после покупки МЦСТ Интелом. Опытных людей практически не осталось. Потом уже была просто боязнь руководства что-то радикально менять. Боялись, что не потянут.
а сильные стороны (FLOPs-ы) не были проявлены хотя бы в демонстрационном супере
Потому что PR отдел МЦСТ мало на что реально влияет, а руководство видит свою задачу в своевременной сдаче ОКРов.
livelace
03.10.2021 01:22+6Мне показалось, что ваша серия статей о процессорах Эльбрус несколько предвзята (я три дня гналась за вами, чтобы сказать,
как вы мне безразличныкак ваша архитектура неудачна).
Тем временем. Я не припомню, чтобы где-то заявлялось о завоевании рынка Intel/AMD. Напротив. Все заявления крутятся вокруг специализированных решений для государства/бизнеса. Если компания не ставит себе таких задач, то может не стоит от неё ждать преодоления воображаемых рубежей?
Я подверился и посмотрел свежее видео (https://www.youtube.com/watch?v=OXN_YfbfeBg&t=1219s), где все тезисы (звучащие многие года) остались прежними. Из изменении для себя отметил: появление СХД, работа в энергетике/газотранспорте, ноутбуки и т.д.
Давайте не будем «драматизировать» раньше времени. Процессоры, это ведь не только архитектура в вакууме, но и технологические решения и производственные мощности. Развернуть диван в сторону x86 всегда можно, особенно когда компетенции «вдруг» появились.

le2
03.10.2021 02:04я вижу такую киллер-фичу отечественных процессоров — у всех есть поддержка ecc-памяти из коробки.
Маркетологи Intel (и AMD) простым решением перевели свои массовые процессоры в разряд «детских», лишив их ecc.Civil
03.10.2021 02:16+3У AMD, кроме их APUшек, поддержка ECC есть везде. Этим они отличаются.
Дальше про массовые процессоры - каждому Core i есть соответствующий Xeon, у которого с ECC проблем нет. Например тому же i9-9900k соответствует Xeon E2288G и разница в рекомендованных ценах у них 50$ (539$ против 489$).
Плюс "детскость" относительная. Дома ECC не то чтобы нужен обычным пользователям.

sherbinko
03.10.2021 02:45Почему не нужен? В моих 32 G возникает в среднем 4 ошибки за день (по статистике).
Это довольно-таки ощутимо на мой взгляд. По крайней мере, синий экран периодически наблюдаю.
Civil
03.10.2021 03:01Потому что для решения такой проблемы есть замечательное слово: гарантия.
Для 32 ГБ 4 ошибки за день это чрезмерно много (должно быть около 0) и свидетельствует о проблемах с настройкой системы или битом железе. В такой же ситуации с ECC следует понимать, что шанс на более чем 1 одновременную ошибку - тоже очень не нулевой.
sherbinko
03.10.2021 20:55+1Никто не гарантирует корректную работу не-ECC памяти. Поэтому гарантия не поможет.
Согласно статистике, космическое излучение вызывает 4 переключения битов в день и это не много, а самый что ни на есть стандарт.
Если бы бы жил в Гималаях или Андах, ошибок я думаю было бы больше.
Понятно, что не все эти 32 G заняты данными и значимы, но тем не менее ...

edo1h
03.10.2021 22:47+1Согласно статистике, космическое излучение вызывает 4 переключения битов в день и это не много, а самый что ни на есть стандарт.
напомню, что стандартный ECC гарантированно обнаруживает и исправляет один искажённый бит в блоке из 72 бит (64 полезных), гарантированно же обнаруживает (но уже не может исправить) 2 искажённых бита.
блоки с большим числом искажённых бит могут ошибочно быть приняты за верные, но вероятность этого достаточно мала (если я правильно понимаю, не больше 1/256).
то есть нулевое число ошибок ECC в мониторинге фактически говорит о том, что искажений в читаемых из памяти данных не было.так вот, мой опыт не подтверждает вашу статистику: перед глазами десятки серверов с суммарно несколькими терабайтами памяти, на которых ECC за всё время эксплуатации не обнаруживает ни одной ошибки.
есть, разумеется, и сервера, на которых такие ошибки обнаруживаются, но пока все случаи обнаружения ошибок были типа «раньше ошибок совсем не было, сегодня начали сыпаться» и решались заменой оборудования (что никак не может быть объяснено космическими лучами).sherbinko
04.10.2021 01:13+1Очевидно под ошибками вы понимаете неисправленные ошибки (с 2-ми дефектными битами), иначе непонятно как вы умудрились ни одну исправленную поймать, вы же не в свинцовом саркофаге сервера держите.
Так что, сколько у вас исправленных ошибок - непонятно, очевидно их количество не может быть равно 0. В обычной памяти они бы привели к сбоям.
edo1h
04.10.2021 01:54+1Очевидно под ошибками вы понимаете неисправленные ошибки (с 2-ми дефектными битами),
нет, считаются все ошибки, вот вам пример с сервера с ошибками:
# edac-util -v mc0: 0 Uncorrected Errors with no DIMM info mc0: 0 Corrected Errors with no DIMM info mc0: csrow0: 0 Uncorrected Errors mc0: csrow0: mc#0csrow#0channel#0: 0 Corrected Errors mc0: csrow0: mc#0csrow#0channel#1: 0 Corrected Errors mc0: csrow1: 0 Uncorrected Errors mc0: csrow1: mc#0csrow#1channel#0: 0 Corrected Errors mc0: csrow1: mc#0csrow#1channel#1: 0 Corrected Errors mc0: csrow2: 0 Uncorrected Errors mc0: csrow2: mc#0csrow#2channel#0: 0 Corrected Errors mc0: csrow2: mc#0csrow#2channel#1: 405 Corrected Errors mc0: csrow3: 0 Uncorrected Errors mc0: csrow3: mc#0csrow#3channel#0: 0 Corrected Errors mc0: csrow3: mc#0csrow#3channel#1: 0 Corrected Errorsвы же не в свинцовом саркофаге сервера держите.
я думаю, что вы слишком близко к сердцу принимаете проблему космических лучей.
sherbinko
04.10.2021 03:29я думаю, что вы слишком близко к сердцу принимаете проблему космических лучей.
Вы думаете или знаете?
According to an Advanced Micro Devices, Inc. (AMD) study on soft error rates (SER), “a typical SER might be one bitflip per 2-4 weeks per gigabyte of DRAM.
Есть похожие статьи от гугла, церна со статистикой.
То что показывает 0 ошибок имхо может означать, что память простаивает и нет необходимости что-то проверять или корректировать.
Civil
04.10.2021 10:46Вы не учитываете условия и что старые статьи (статья гугла это 2009 год) не разделяла типы сломанного железа (ошибки контроллера памяти принимались за ошибки планки памяти). Есть более новая статья Facebook'а где эта проблема в методологии исправлена. И с ее учетом (после исключения из данных тех железок, где были проблемы с другими частями железа) выходит примерно 1 CE в 3 с небольшим дня на сервер (не на гигабайт).
И эта статистика в общем-то коррелирует с тем, что я наблюдал на прошлых работах (когда проблемы с железом были в моей зоне ответственности, статистики там конечно не так много - сотни и в лучшем случаи тысячи серверов и в среднем 128 ГБ всего оперативки на сервер).
Civil
04.10.2021 12:47Легко. Всю статью читать не обязательно важные выдержки следующие:
correctable errors among machines at the end of this section. To compare against prior work, we measured the correctable error incidence rate over the course of twelve months (7/13 up to and including 7/14, excluding 1/14) and found that, cumulatively across all months, around 9.62% of servers experience correctable memory errors. This is much lower than the yearly correctable error incidence rate reported in work from the field seven years ago
Figure 2 (left) shows the distribution of correctable errors among servers that had at least one correctable error. The x axis is the normalized device number, with devices sorted based on the number of errors they had during a month. The y axis shows the total number of errors a server had during the month in log scale. Notice that the maximum number of logged errors is in the millions. We observe that a small number of servers have a large number of errors. For example, the top 1% of servers with the most errors have over 97.8% of all observed correctable errors
However, if we examine the error rate for the majority of servers (by taking the median errors per server per month), we find that most servers have at most 9 correctable errors per server per mont
То есть на базе этого - для работоспособного железа 9 CE в месяц или 1 ошибка примерно раз в 3 дня.
В целом советую почитать исследование, оно обстоятельное и чуть ли не первое, которое пытается корректно отделить ошибки памяти от ошибок всего остального (например контроллера памяти). Чего не было в той работе, на которую Вы ссылались.
edo1h
04.10.2021 16:07+1То есть на базе этого — для работоспособного железа 9 CE в месяц или 1 ошибка примерно раз в 3 дня.
не совсем.
To compare against prior work, we measured the correctable error incidence rate over the course of twelve months (7/13 up to and including 7/14, excluding 1/14) and found that, cumulatively across all months, around 9.62% of servers experience correctable memory errors
у более чем 90% серверов за год не было ни одной ошибки, все остальные подсчёты (медианные 9 ошибок в месяц) относятся к серверам у которых ошибки были.
ИМХО в этом случае надо не считать ошибки, а менять железо )
Civil
04.10.2021 17:43Блин, я что-то когда читал этот момент упустил. Спасибо за поправку. Так что да, еще меньше выходит.
sherbinko
05.10.2021 20:27То есть на базе этого - для работоспособного железа 9 CE в месяц или 1 ошибка примерно раз в 3 дня.
Здесь вы просто выкинули сервера с большим количеством ошибок и после этого считаете среднее. Нормально, чо. Очень качественный подход :D. Очевидно, что на самом деле среднее арифметическое и даже геометрическое будет выше.
В самой статье, кстати, написано, что на 56 процентах серверов ошибки были Spurious, например, из-за излучения. И, кроме того, на "сбойных" серверах Spurious ошибки тоже могли быть, но они их не считали.
Если сервер не использует память и все его 128G простаивают или просто только пишут в память, но не читают, то никакой ошибки мы в этом случае не поймаем.
Или я ошибаюсь и контролёр памяти сам периодически опрашивает ячейки для проверки контрольной суммы?
Если же ошибки ловятся только когда софт пытается их прочитать, то какая ценность от этой статьи для оценки влияния излучения? Надо закреплять планки на стенде и гонять тесты.
edo1h
05.10.2021 21:38Здесь вы просто выкинули сервера с большим количеством ошибок и после этого считаете среднее. Нормально, чо. Очень качественный подход :D. Очевидно, что на самом деле среднее арифметическое и даже геометрическое будет выше.
нет же. сначала они выкинули >90% серверов, на которых ошибок не было вообще, потом на оставшихся посчитали медианное количество ошибок. что должно символизировать полученное число я не понимаю.
и да, выбрасывание серверов с большим количеством ошибок у меня не вызывает протеста: какой смысл их учитывать, очевидно же, что в их случае дело не в активности космических лучей, а в банальной неисправности оборудования.
а вот выбрасывание серверов без ошибок… иначе как желанием высосать статью из ничего я объяснить не могу. ибо с их учётом получается, что на исправном оборудовании вероятность ошибки << 1 в год, и именно эти ошибки мы можем попытаться связать с космическим излучением (но только попытаться, это лишь одна из множества причин, которые могут вызвать ошибки).
Или я ошибаюсь и контролёр памяти сам периодически опрашивает ячейки для проверки контрольной суммы?
такая опция есть, обычно называется patrol scrubbing. в статье написано, что на некоторых серверах она была включена.
ЕМНИП зависимость количества ошибок от этой опции в статье не изучалась.Если сервер не использует память и все его 128G простаивают или просто только пишут в память, но не читают
ну это не то, чтобы принципиально невозможный, но крайне маловероятный вариант.
Civil
06.10.2021 09:02+1Здесь вы просто выкинули сервера с большим количеством ошибок и после этого считаете среднее. Нормально, чо. Очень качественный подход :D. Очевидно, что на самом деле среднее арифметическое и даже геометрическое будет выше
Моя ошибка в другом - я выкинул 90% серверов где было 0 ошибок.
Хотя на базе этого можно сказать, что космическое излучение вызывает меньше 1 ошибки в 14 месяцев. (Насколько меньше- нужно знать количество серверов).
То есть все ошибки памяти - это строго брак железа.
Ну и среднее арифметическое по опредению бесполезно в такого рода исследованиях, о чем там пара абзацев и есть (оно склонно переоценивать вклад единичных выбросов, то есть в случае статьи это сервера с серьёзно побитой памятью)

beeruser
05.10.2021 16:38так вот, мой опыт не подтверждает вашу статистику: перед глазами десятки серверов с суммарно несколькими терабайтами памяти, на которых ECC за всё время эксплуатации не обнаруживает ни одной ошибки.
Так ваш опыт тоже даёт сильно специфическую картину мира.
Вы смотрите на планомерно обслуживаемые серверы с отобранной памятью одного вендора, работающей на стоковой частоте в тепличных условиях.
Это совсем другая ситуация по сравнению с тем, что имеют обычные юзвери.
В частности разработчики онлайн игр сталкиваются со всем зоопарком, собранным неизвестно из каких комплектующих, в т.ч. с разогнанными системами. В итоге ошибки памяти — частый гость. Банально, прилетает дамп, а там битик в команде перехода поменялся на противоположный и переход выполняется по другой ветке.
Маркетинг Интел настолько тупорылый, что они лишают ECC памяти людей, которым она на самом деле нужна =)edo1h
05.10.2021 17:50лишают ECC памяти людей, которым она на самом деле нужна =)
вы напрасно пытаетесь меня переубедить, я уже написал в соседнем комментарии, что мой следующий домашний компьютер будет с ecc.
просто я не хочу передёргивать и пугать массовыми битфлипами.
проблемы cо стабильностью работы памяти есть, но, как я опять же писал ранее, они больше не в том, что стабильная работа памяти без ECC невозможна, а в том, что без ECC сложно понять стабильно работает память или нет.P. S. видимо, таких как я недостаточно много, чтобы создать достаточный спрос на десктопные компьютеры с ECC.
amartology
05.10.2021 16:47+2(что никак не может быть объяснено космическими лучами).
Как специалист по космическим лучам и их взаимодействию с микросехмами, могу подтвердить, что четыре ошибки в день в 30 Гбайт на уровне моря не могут объясняться космическими лучами. Такого рода цифры возможны только высоко в горах или на самолетах.sherbinko
05.10.2021 20:34Какая норма будет для 32G?
amartology
05.10.2021 20:58+1Разумный уровень — где-то в районе 1e-12 upset/bit/day, то есть для 32 Гбайт памяти, выставленной чипами на свежий воздух на уровне моря, стоит ожидать цифры порядка одного сбоя в четыре дня. Если память находится в корпусе ПК, то можно смело увеличивать время ожидания на порядок. Если в корпусе ПК в помещении — то может и на два порядка.
Civil
04.10.2021 10:44+1Никто не гарантирует корректную работу не-ECC памяти.
Гарантирует закон. 4 бит-флипа в сутки - повод обратиться в гарантийку, вам не откажут и новая память будет работать лучше. Так было всегда и так остается до сих пор. Для не-ECC памяти должно быть строго меньше 1 бит-флипа в сутки.
Согласно статистике, космическое излучение вызывает 4 переключения битов в день и это не много, а самый что ни на есть стандарт.
Согласно современной статистике меньше 1 бит-флипа в день. В зависимости от исследования люди замечали от 1 ошибки в 2 дня (технически в 41 час) до 9 ошибок в месяц, на современном железе (1 ошибка в 3 дня).
sherbinko
04.10.2021 12:07Понятно, значит мои данные устарели. А что за закон, на который вы ссылаетесь?
К счастью, эти битфлипы легко проверить. Я написал простенькую программку, с огромным массивом на 2 миллиарда 64-bit integer-ов. Было бы интересно воочию увидеть хотя бы один битфлип )
Civil
04.10.2021 12:54А что за закон, на который вы ссылаетесь?
Обычный закон о защите прав потребителя в стране вашего проживания. 4 ошибки в день если вы их можете показать - основание для гарантийного случая (строго говоря 1 ошибка в день тоже), так как устройство нерабочее и если дело дойдет до суда то суд вы выиграете без проблем.
К счастью, эти битфлипы легко проверить. Я написал простенькую программку, с огромным массивом на 2 миллиарда 64-bit integer-ов. Было бы интересно воочию увидеть хотя бы один битфлип )
Строго говоря memtest такое умеет. Обычно для пользовательского железа достаточно воспроизводимых результатов на 24-х часовом прогоне теста, чтобы сервис-центр признал это проблемой.

sved
04.10.2021 13:144 ошибки в день если вы их можете показать - основание для гарантийного случая (строго говоря 1 ошибка в день тоже), так как устройство нерабочее и если дело дойдет до суда то суд вы выиграете без проблем.
Почему именно такие цифры? Это в законе написанно?
Civil
04.10.2021 13:33Почему именно такие цифры? Это в законе написанно?
Спросите у автора выше, я использовал его пример с 4-я ошибками в день.
Про 1 ошибку за сутки - если обращаться по гарантии к производителям памяти напрямую это примерно практическая граница когда они готовы поменять модули памяти без вопросов (речь идет о десктопных модулях). Так строго говоря я не удивлюсь, если по закону даже 1 ошибка за неделю будет основанием для гарантийного случая, если ты сможешь доказать что причиной ее возникновения является память.
edo1h
03.10.2021 04:08+1Почему не нужен? В моих 32 G возникает в среднем 4 ошибки за день (по статистике).
а как вы посчитали?
по серверам с ECC могу сказать, что норма — работа без ошибок, если появляется хотя бы ошибка в месяц, то модуль надо менять.проблема десктопов без ECC не в том, что на исправной памяти возникают ошибки, а в том, что:
- неисправная память встречается не так уж и редко;
- некогда исправная память может со временем стать неисправной;
- диагностика памяти — это многочасовые тесты, во время которых компьютером обычно нельзя пользоваться;
- каких-то специфичных симптомов, говорящих о том, что память надо бы протестировать, нет (симптомами могут быть и редкие вылеты программ, и зависания/перезагрузки, и порча файлов — всё это может вызываться кучей разных причин).
Дома ECC не то чтобы нужен обычным пользователям.
мне нужен. именно потому, что я хочу работать на компьютере, не не тестировать сутками память.
BugM
03.10.2021 04:13DDR5 только ECC. Проблема уже решена. Осталось подождать лет 10.
edo1h
03.10.2021 04:16увы, AFAIK не решена — в DDR5 ECC в памяти работает независимо от процессора, о скорректированной ошибке он просто не узнает.
хотя, возможно, как-то статистику ошибок с модулей памяти можно прочитать, есть же сейчас SPD, почему его нельзя расширить?BugM
03.10.2021 04:28Лично не сталкивался, и даже стандарт не читал полностью.
Но почему совсем независимо? Логично улучшить то что есть. А сейчас об ошибках ECC узнать можно. Зачем убирать эту возможность?
edo1h
03.10.2021 06:58так никто и не убирает, опциональный ECC сохраняется в том же виде, что и был. и всё так же остаётся опциональным.
Civil
04.10.2021 10:59+1Не надо путать on-die ECC с side-band ECC, почитайте небольшой обзор. Первое - да, будет в DDR5, так как первый покрывает бит-флипы в рамках чипа, но не в рамках передачи данных (когда про память говорят ECC то это именно inline ECC).
Осталось подождать лет 10.
Интеловский Alder Lake с DDR5 будет в этом году, AMDшный Zen 4 по слухам в начале следующего. Это таки меньше 10 лет.
sherbinko
03.10.2021 20:57по серверам с ECC могу сказать, что норма — работа без ошибок, если появляется хотя бы ошибка в месяц, то модуль надо менять.
На так о том и идёт речь - если нужно 0 ошибок, то нужно ECC. Без ECC ошибки неизбежны
edo1h
03.10.2021 21:44+1нет, опять не то.
я пытался сказать, ECC ценно в первую очередь не исправлением, а обнаружением ошибок.
Civil
04.10.2021 10:54+1мне нужен. именно потому, что я хочу работать на компьютере, не не тестировать сутками память.
Ну так и не тестируйте. Для домашнего использования ошибки памяти достаточно редки, что ими можно пренебречь.
каких-то специфичных симптомов, говорящих о том, что память надо бы протестировать, нет (симптомами могут быть и редкие вылеты программ, и зависания/перезагрузки, и порча файлов — всё это может вызываться кучей разных причин).
И да и нет - когда система была стабильна, а потом перестала - это повод усомниться в качестве оперативной памяти. Опять же это случается не так часто, чтобы на этот счет волноваться в рамках единичных компьютеров.
edo1h
04.10.2021 15:25Для домашнего использования ошибки памяти достаточно редки, что ими можно пренебречь.
вот буквально этим летом столкнулся с ошибками на домашнем компьютере, определение сбойного модуля, потом тестирование после замены — на это ушло в сумме не меньше 2 дней.
И да и нет — когда система была стабильна, а потом перестала — это повод усомниться в качестве оперативной памяти.
после любого вылета программы запускать суточный тест памяти?
нет, понятно, что с этим можно жить, но я давно решил для себя, что следующий домашний компьютер будет с ECC памятью.
Civil
04.10.2021 15:45после любого вылета программы запускать суточный тест памяти?
Если прям есть уверенность в безбажности софта - то не такой и плохой вариант. Так у подсистемы памяти характерная проблема в том что софт вылетает случайны и случайным образом и чаще всего всегда чуть по-разному (включая выдачу некорректных результатов).
вот буквально этим летом столкнулся с ошибками на домашнем компьютере, определение сбойного модуля, потом тестирование после замены — на это ушло в сумме не меньше 2 дней.
Да, это не очень удобно и не очень приятно, но я для себя не вижу проблем потратить два дня раз в несколько лет (я за несколько десятков лет владения ПК и ноутами помню ровно три случая неожиданных проблем с памятью (один раз было неприятно, на рабочем ноуте, но довольно очевидно - бит-флипы приводили к изменению текста в том числе в dmesg :), но так как это был ноут с распаяной памятью я так никогда и не узнал это память или что-то еще было виновато), а один раз проблемы были ожидаемы (умерший БП с искрами и дымом, который повредил вообще почти все, включая память, процессор и мать и половину жестких дисков).
В принципе еще лайф-хак - это махнуть память с какой-нибудь соседней системой, если возникли подозрения на проблемы. Иногда бывает проще чем гонять мем-тест.

AlexAV1000
04.10.2021 12:14Приветствую. Подскажите, где в системе посмотреть статистику, по ошибкам в ECC памяти?
edo1h
04.10.2021 15:47в серверах в веб-интерфейсе BMC обычно есть. или можно получить через ipmi лог ошибок, что-то вроде
ipmitool sel elistили в линуксе (уже не требует ipmi):
edac-util -vв windows тоже как-то можно, windows-машин без ipmi у меня нет, поэтому не смотрел.
BugM
03.10.2021 03:38+2NB: Я не являюсь специалистом в разработке процессоров. Хотя диплом на эту тему есть.
Я удивлен почему разработчики Эльбруса так провалили JIT подход. Казалось бы он идеален для них. Берем профиль с рантайма и оптимизируем код под ядро которое отлично умеет работать с оптимизированным кодом, но плохо работает со всем остальным. Профиль можно собирать сколь угодно долго, сохранять и использовать при следующих запусках. Хоть нейронки в оптимизатор прикручивай. Для general purpose софта крутящегося в проде годами и десятилетиями все расходы на рантайм оптимизацию все равно незаметными выйдут.
Из проблем видна проблема параллелизации алгоритмов (на уровне инструкций) и проблема сложности оптимизатора. И та и другая проблемы выглядят решаемыми. Сложно, местами очень сложно. Но ничего запрещенного математикой нет.
Потенциальный объем рынка для процессора для JIT софта безграничен. Деньги тут есть.
Armmaster Автор
03.10.2021 16:15Потому что хороший JIT очень непросто сделать, особенно в условиях Эльбруса. Да и долгое время была же концепция статического планирования. А делать JIT это фактически признать, что статический подход не работает. Но тогда логичный вопрос, зачем делать в софте то, что проще и эффективнее делать в железе? Это если кратко.
checkpoint
03.10.2021 04:03+2Хочу попросить автора статьи рассказать как в Эльбрусе осуществляется переключение контекста при работе в многозадачных ОС (Linux), а именно - что происходит с его регистровым файлом в котором 256 регистров. Логика посдказывает, что переброс такого объема данных в стек и обратно при переключении задач обходится не бесплатно.

Sabubu
03.10.2021 14:39+1Тормоза при переключении контекста (по крайней мере на Интел x86) обычно возникают не из-за необходимости выгружать регистры в стек, а из-за опустошения кешей данных, инструкций и TLB.
Выгрузка регистров в стек это операция последовательной записи и память при ней работает более-менее в оптимальном режиме.
checkpoint
03.10.2021 22:10На сколько я понимаю, выгрузка регистров в стек осуществляется через кеш всех уровней, что при уже совсем небольшом числе задач (нитей) приведет к загрязнению кеша (cache thrashing). Или же в системе команд Эльбруса имеется спец инструкция для выгрузки/загрузки блока регистров минуя кеш ? Если нет, то мы должны наблюдать интресный эффект - как только число задач превысит опредленный порог, произвоительность системы должна резко упасть, так как постоянная выгрузка/загрузка регистров будет опустошать кеш до такого состояния, что он будет непрерывно синхронизироваться с медленной памятью. Мне бы хотелось проверить это на пратике. К сожалению, доступа к машине с Эльбрусом сейчас нет.
Armmaster Автор
03.10.2021 22:29+1Можно выгружать регистры в память специальной операцией записи, минуя кэши. Но это приводит к другой проблеме - при переключении контекста обратно, придётся доставать их из памяти, что небыстро. Вообще, скорость переключения контекста в Эльбрусе это известная проблема. Кто-то на Elbrus Tech Day даже цифры приводил, по-моему. Можете там поискать, если очень интересно.
Armmaster Автор
03.10.2021 16:17+1Не бесплатно. Поэтому(и ещё из-за сложности ШК) обработка прерываний и переключения контекста на Эльбрусе существенно медленнее, чем на Risc/Cisc процессорах

unv_unv
03.10.2021 09:20+7Максим, очень жаль, что вы никак не отреагировали на разбор вашего реального примера с компиляцией внутреннего цикла из сортировки со вставками под Эльбрус. Вы и ваши единомышленники в комментариях утверждали, что скомпилированный вами результат в 13 тактов на итерацию является принципиально неустранимым недостатком эльбрусовского компилятора.
Однако пользователи antag и Дмитрий Щербаков разобрали данный фрагмент (https://habr.com/ru/post/576420/comments/#comment_23456356). Сначала оказалось, что с опцией оптимизации -O2 внутренний цикл компилируется уже в код с 7 тактами на итерацию (вы ещё забыли включить другую рекомендуемую для Эльбруса оптимизацию -ffast). Далее оказалось, что эвристика компилятора неверно определила цикл как выполняющийся с небольшим количеством итераций, что можно было обойти, добавив в исходник комментарий с подсказкой для компилятора — и в итоге внутренний цикл скомпилировался в код, выполняемый за 1 такт — втрое быстрее, чем код для Intel/AMD.
И очень разочаровывает, что вы ни в той статье не добавили Post Scriptum с указанием на этот разбор, ни в этой статье не обмолвились. При том, что это можно было хорошо обыграть в вашей парадигме — дескать, вот какие танцы с бубнами нужны, чтобы хорошо скомпилировать простую сортировку. Но даже это не интересно, не интересна реальность — интересны теоретические рассуждения в вакууме. Вот вы претендуете в своих текстах на поиск истины, а по факту оказывается, что истина не интересует, а интересует лишь пропаганда.
Armmaster Автор
03.10.2021 16:39+6является принципиально неустранимым недостатком эльбрусовского компилятора.
Нет, я не это утверждал, вы невнимательно читали статьи. Я утверждал, что принципиально невозможно эффективно откомпилировать код для Эльбруса без профиля (да и с профилем многие проблемы остаются). И чтобы добиться вменяемого перфа, надо лезть руками в код, его анализировать и оптимизировать. Что данный пример как раз отлично демонстрирует. Это был ответ на рассуждения Алексея, что в реальности всё неплохо, когда в реальности мы простейшую сортировку соптимизировать нормально.
Сначала оказалось, что с опцией оптимизации -O2 внутренний цикл компилируется уже в код с 7 тактами на итерацию (вы ещё забыли включить другую рекомендуемую для Эльбруса оптимизацию -ffast).
Всё это прекрасная демонстрация моих тезисов. Компилятор на -O4 генерирует код хуже, чем на -O2, а должно быть наоборот. А происходит это потому, что компилятор не понимает, какие участки надо реально оптимизировать, и начинает гадать.
- ffast я специально не включал, потому что она включает некоторые не совсем корректные оптимизации и ей часто не пользуются по данной причине. Да и в контексте данного примера она ни на что не должна влиять особо
Далее оказалось, что эвристика компилятора неверно определила цикл как выполняющийся с небольшим количеством итераций, что можно было обойти, добавив в исходник комментарий с подсказкой для компилятора
И снова прекрасная иллюстрация моей позиции - даже здесь компилятор не смог понять, что происходит (и это понятно, откуда ему знать?). Надо лезть в код и ставить подсказки.
втрое быстрее, чем код для Intel/AMD.
Насколько всё быстрее работает на мало мвльски реальном коде даже с подсказками (профилем) мы смогли увидеть на основе цифр Spec Cpu2017
При том, что это можно было хорошо обыграть в вашей парадигме — дескать, вот какие танцы с бубнами нужны, чтобы хорошо скомпилировать простую сортировку.
Мне казалось, что мой пример эту проблему и обыгрывает.
Вот вы претендуете в своих текстах на поиск истины, а по факту оказывается, что истина не интересует, а интересует лишь пропаганда.
Я ни на что не претендую, я лишь пытаюсь объяснить людям технические проблемы Эльбруса, из-за которых он не может и не сможет стать массовым gp cpu. А интересует меня одно - я хочу дожить до того момента, когда российские процессоры будут производиться в России десятками миллионов, а вести дискуссии на хабре я буду с компа с отечественным процом. И проблема в том, что если идти уже понятно что тупиковыми путями, то до такого момента могу не дожить не то, что я, но и мои дети
Thall
03.10.2021 19:40-3Хуавей не можем быть никак российским процессором )
Armmaster Автор
03.10.2021 19:40+1Хуавей здесь вообще непричём.
Thall
03.10.2021 23:04-3Я к тому что вы работает там ) ну либо в дочке его ядро ) поэтому и топите за риск 5 )
Armmaster Автор
03.10.2021 23:28+1Где я работаю и почему, можете спросить у Александра Кирыча. А то если я начну свою версию рассказывать, истории про проблемы архитектуры Эльбрус на этом фоне будут добрыми детскими сказками.
За Risc-V я не то, чтобы топлю. Я топлю за связку ARM-RISC-V на данном этапе. По той простой причине, что это объективно оптимальный вариант для России сейчас. Я бы с радостью поменял бы любую аббревиатуру на Эльбрус, но не привык заниматься самообманом. И всё вышесказанное никак не связано с тем, где и как я работаю.
Thall
04.10.2021 00:08-3Теперь я расскажу как это выглядит в моих глазах , аккаунт был зарегистрирован в 2014 году и был мертвым , с 2021 начали выходить ролики с Эльбрусом с просмотрами по 500 и более тысяч и тут бац и появился бывший сотрудник мцст который работает в другом месте и задвигает про Эльбрус … ну а дальше пусть люди сами размышляют что и как ) .
Armmaster Автор
04.10.2021 00:45+4Из перечисленных фактов можно напридумывать всё, что угодно. У вас есть что сказать по существу?
amartology
04.10.2021 12:20А как так вышло, что принадлежащая Алишеру Усманову компания Yadro у вас стала дочкой Huawei? Это Huawei тоже принадлежит Усманову, или Усманов принадлежит Huawei?
В первом случае Эльбрус не нужен, потому что Усманов с таким активом очень скоро решит вообще все проблемы российской микроэлектроники. Во втором случае, в общем, тоже.
А вот если Yadro и Huawei никак не связаны, то сотруднику Huawei нет никаких причин вставать на чью-то сторону в борьбе МЦСТ и Ядра.
bircoph
03.10.2021 23:17+3Исходный автор статьи перегибает палку и приукрашивает ОоО, мы это уже обсуждаем в соседних комментариях. Но и Вы, увы, лукавите и перегибаете палку.
Сначала оказалось, что с опцией оптимизации -O2 внутренний цикл компилируется уже в код с 7 тактами на итерацию (вы ещё забыли включить другую рекомендуемую для Эльбруса оптимизацию -ffast).
Ну давайте вместе почитаем документацию к -ffast из man lcc:
-ffast Включает опции -fstdlib, -faligned, -fno-math-errno, -fno-signed-zeros, -ffinite-math-only, -fno-rounding-math, -fcx-limited-range. -fprefetch, -fmalloc-opt, -floop-apb-conditional-loads, -fstrict-aliasing, -fext-strict-aliasing. Данная опция выключена по умолчанию, поскольку включает преобразования с вещественной арифметикой, которые могут приводить к некорректным результатам в случае программ, предполагающих строгое соблюдение стандартов IEEE или ISO для вещественных операций и функций. Тем не менее, она может существенно увеличить скорость программ, не требующих строго соблюдения этих стандартов. Кроме того, опция включает некоторые потенциально опасные оптимизации (такие как loop-apb для чтений под условием, malloc-opt, удаление операций целочисленного деления), которые в определённых случаях могут приводить к некорректному поведению программы.А заодно и -faligned, взводимого -ffast:
-faligned (-fno-aligned) Разрешить оптимизации, рассчитывающие исключительно на выровненные обращения в память. Смысл опции заключается в том, что программист как бы говорит компилятору "я обязуюсь, что в исходнике программы все обращения в память являются выровненными на свой формат", в результате чего компилятор может более эффективно выполнять некоторые оптимизации. Такими оптимизациями являются: apb (аппаратная подкачка массивов) и arracc (аппаратная поддержка доступа к массивам) для архитектур до elbrus-v4 включительно, автоматическая векторизация (в небольшой степени) и crp_opt (динамический разрыв зависимостей между чтениями и записями в память). Необходимость в данной опции вызвана аппаратными особенностями Эльбруса. В архитектурах до elbrus-v5 включительно невыровненные обращения в память работают значительно медленнее выровненных. В архитектурах до elbrus-v4 включительно аппаратная подкачка массивов не умеет работать по невыровненным адресам; в elbrus-v5 это ограничение снято для всех операций, кроме 16-байтных; начиная с elbrus-v6 ограничение снято полностью. Таким образом, для elbrus-v6 и выше опция -faligned имеет смысл только для оптимизации crp_opt. Использование опции -faligned при компиляции программы, содержащей невыровненные обращения в память, может привести к некорректному поведению программы. Для проверки выровненности обращений в память можно использовать опцию -faligned-check По умолчанию для языков C/C++ включен режим -fno-aligned, для Фортрана -falignedПо-моему, совершенно очевидно, что эта -ffast применим лишь в очень узких, специфических случаях; скорее всего, на специализированных числодробилках. А остальной софт будет страдать. Попробуйте собрать с -ffast, скажем, firefox.
рекомендуемую для Эльбруса оптимизацию -ffast
Ввиду выше процитированной официальной документации lcc, Ваше утверждение о рекомендуемости -ffast выглядит как издёвка. Да, это сильная оптимизация, но она ломает код, если не выполняется большое количество ограничений и условия. Так что называть её рекомендуемой — так себе рекомендация. Это полезно учитывать при написании кода под Эльбрус, но мало толку при адаптации уже существующего.

sabaca
03.10.2021 09:27+2Поэтому намного проще взять обычную RISC архитектуру и сделать на её основе современный процессор с ОоО-исполнением. Это будет проще, быстрее, дешевле, а в итоге получится более быстрый и удобный для пользователей процессор.
Спорное заявление. Сделать быстрый ОоО процессор совсем не просто и не дешево.
antag
03.10.2021 11:23+7При этом из предыдущих статей помним, что верхний предел микроархитектурной скорости на Эльбрусе, рассчитанный по данным запусков на Spec CPU2017, в 3-4 раза уступает современным RISC/CISC процессорам с ОоО исполнением.
Есть современный OoO процессор Ampere Altra. Для него есть результаты Spec CPU2017.
Сравниваем эту вашу "микроархитектурную скорость":
Ampere Altra: int: 1.20, fp: 0.875
Эльбрус-8СВ: int: 0.89, fp: 1.38
Так где тут 3-4 раза?
Для fp у эльбруса эта "микроархитектурная скорость" оказалась даже выше, чем у Altra Neoverse-N1. Или Neoverse-N1 - это тоже плохой представитель современного OoO процессора?

creker
03.10.2021 16:22-2Опять путаете карты, пересчитывая все на мегагерцы. Не нужно мутить воду, считайте на максимальных частотах. Altra действительно не самый лучший представитель. Последнее поколение амд эпик будет быстрее.
dubm
03.10.2021 23:28+2Забавно, автор статьи сам предложил мерять микроахритектурную скорость (то есть в пересчете на мегагерц), и вам показали, что автор не прав. Но вместо того, чтобы признать, начинают доставать странные аргументы про нелучших представителей, теплопакет и покажите нам 80 ядер.
Armmaster Автор
03.10.2021 23:33Автор статьи показывал проблемы Эльбруса на примере проблем микроархитектурной скорости. И что, они куда-то исчезли? Цифры спеков на Эльбрусе резко подросли?
На spec.org вроде ничего не поменялось, все данные те же. Такой же проигрыш в 3-4 раза (я уж не говорю, что при таких частотах как у EPIC эта цифра ещё подрастёт).
antag
04.10.2021 10:51+3тесты SPECrate_int CPU2017
EPYC 7713 128 cores - 778 Spec Int, Nominal: 2000 MHz.
Huawei Kunpeng 920 128 cores - 318 Spec Int, Nominal: 2600 MHz.
Потребление примерно по 200-225 Вт на процессор.
Техпроцесс - 7 нм. Число ядер совпадает, число каналов памяти тоже совпадает. Kunpeng проиграл в 2.44 раза в таких равных условиях. Так Kunpeng тоже нужно закопать?
Зачем нужен такой процессор (Kunpeng) и его ядро, проигрывающее более 2 раз по микроархитектурной скорости и по общей скорости всего процессора?
Armmaster Автор
04.10.2021 11:09-2Нет, Kunpeng надо развивать, потому что из него можно сделать Epyc, а из Эльбруса - нет. Об этом же все статьи - о перспективах. Можно было бы закрыть глаза на текущие катастрофические цифры перфа Эльбруса и объяснить их недостатком вложений. Но дело там как раз в архитектуре, она является якорем для развития. Даже вложив огромные ресурсы разрыв не преодолеть, тк микроархитектурная скорость Эльбруса на спеках близка к своим пределам
antag
04.10.2021 11:54+3Сделать самостоятельно Epyc сложно.
Я же исхожу из простых соображений.
Ядро Эльбрус-8СВ производительнее ядра Cortex-A57. А частоты у них совпадают на одинаковом техпроцессе.
Но никакое свое российское ядро в ближайшие годы не превзойдет ядро Cortex-A57 на одинаковом техпроцессе, а значит такое свое российское ядро не превзойдет ядро Эльбрус-8СВ по производительности. По потреблению и по площади могут выиграть у Эльбруса, но не смогут выиграть по производительности ядра. Если рассматривать только нагрузки INT, то можно выиграть у Эльбруса, но для нагрузок FP никто не сможет показать больше производительности на своем российском ядре.
А число ядер можно наращивать. Даже 48 ядер эльбруса можно сделать на 6 нм, если будет такая цель.
Armmaster Автор
04.10.2021 13:01+1Хорошо, давайте дальше сконцентрируемся именно на максимальной производительности ядра, чтобы упростить обсуждение.
Сделать самостоятельно Epyc сложно.
Сложно, но можно. Тем более не забываем, что если мы говорим даже про FP, то Epyc обыгрывает Эльбрус в 3 раза по микроархитектурной скорости, и даже Эльбрус-32С будет ещё раза в 1.5 по частоте проигрывать. Ну т.е. это 4.5 раза отрыв. Можно сделать ядро попроще, которое будет в 2 раза менее производительным, чем Epyc, что уже существенно проще. И оно всё равно в 2+ раза будет обыгрывать Эльбрус даже на FP и даже на Спеках. А если мы учтём, как дропается перф на реальных приложения у Эльбруса и сложности с ШК и компилятором, то какой вариант выберут пользователи? Ответ, по-моему, очевиден.
И хочу сказать ещё одну вещь. Если бы 20 лет назад МЦСТ не стало бы делать VLIW, а делало бы обычный RISC (впоследствие с ОоО), вкладывая в него все имеющиесяя ресуры, то сейчас такой бы процессор был может быть ни как Epyc, но на уровне средних цифр spec.org'а. И уж точно существенно лучше тех же Kunpeng или Ampere. Я хорошо знаю уровень инженеров внутри МЦСТ и могу сравнить его с разработчиками CPU от Калифорнии/Портленда до Шанхая. Не вижу причин, почему бы они не смогли сделать конкурнтоспособный OoO чип с инженерной точки зрения (вопрос менеджмента выведем за скобки). Поэтому я плохо воспринимаю аргумент "это же так сложно"
Ядро Эльбрус-8СВ производительнее ядра Cortex-A57
Строго говоря, это не совсем так, но в контексте Spec и FP - ок
А частоты у них совпадают на одинаковом техпроцессе
Вот это уже не верно - частоты у Cortex-A57 выше потенциально, это уже вопрос тонкостей физдизайна.
Но никакое свое российское ядро в ближайшие годы не превзойдет ядро Cortex-A57
Тут мне не совсем понятно, что вы называете "российским ядром". Ядро Байкал-S будет производительнее Cortex-A57, причём существенно. Перф RISC-V ядра от Syntacore тоже производительнее Cortex-A57. На самом деле задача создать ядро уровня Cortex-A57 или немного лучше не такая сложная.
но для нагрузок FP никто не сможет показать больше производительности на своем российском ядре
И да, тоже важный момент - если мы говорим про массовый рынок gp CPU, там такая производительность FP не нужна, именно поэтому на обычных процах её не особо форсят. Просто из-за проблем VLIW (где проще показать перф на FP) МЦСТ пришлось пиарить именно эту цифру. Но проблема в том, что для массового рынка она не так интересна.
А число ядер можно наращивать. Даже 48 ядер эльбруса можно сделать на 6 нм, если будет такая цель
Можно. Вопрос в теплопакете и сколько в такой теплопакет влезет OoO RISC-V ядер. А их влезет существенно больше. Причём и ядра ещё будут более производительные.
antag
04.10.2021 13:47Epyc обыгрывает Эльбрус в 3 раза по микроархитектурной скорости
AMD EPYC 7763: 352 Spec 2017 FP / 64 cores / 2450 MHz = 2.24
Эльбрус-8СВ fp: 1.38
И вот вам разница в 1.62 раза, а не в 3.
даже Эльбрус-32С будет ещё раза в 1.5 по частоте проигрывать.
Не будет. Серверный EPYC 7763 имеет те же 2450 MHz базовой частоты, как и потенциальный Эльбрус на 7 нм.
Не вижу причин, почему бы они не смогли сделать конкурнтоспособный OoO чип с инженерной точки зрения
Компания ARM разрабатывает ядра более 20 лет. И они в итоге сделали Cortex-A57 для Байкала. Почему же они такие слабаки? У них тоже слабые инженеры?
Ядро Байкал-S будет производительнее Cortex-A57, причём существенно.
Примерно на 30% на одинаковой частоте.
A75 - это очень хорошее ядро, но ядро Эльбрус-16С все равно быстрее на FP.
RISC-V ядра от Syntacore тоже производительнее Cortex-A57.
Нет, ядра Syntacore слабее, чем A57.
Самое производительное RISC-V ядро в мире - это новое ядро P550 от SiFive. И они только сейчас достали уровень Cortex-A75. Но физически этих ядер P550 еще нет. Причем SiFive - это мировой лидер по уровню инженеров. Российским разработчикам RISC-V ядер очень далеко до этого уровня.
В итоге российские разработчики в лучшем случае только через несколько лет и несколько итераций потенциально смогут выйти на уровень A75 по производительности. Но Эльбрус уже сейчас выше этого уровня по производительности FP на ядре.
Civil
04.10.2021 14:42-1Серверный EPYC 7763 имеет те же 2450 MHz базовой частоты
Вы делаете ту же ошибку что и другие люди, оперирующие базовой частотой - считаете что процессор всегда работает только на ней и никак иначе. А это в корне не верно (поищите в прошлых темах тред про это, tldr - надо смотреть на частотную формулу и что конкретное приложение утилизирует и в каком объеме). Строго говоря в таком контексте Ваш рассчет 100% неверный, потому что для 1 ядра у Epyc'ов boost гарантирован и вы получите там свои 3.5 ГГц (кстати непонятно почему вы не взяли 7713, у которого буст до 3.675 ГГц).
Опустим пока то, что у МЦСТ планы с реальностью не всегда соотносились и говорить о том что раз в роадмапе стоит для 6нм процессора цель в 2.5 ГГц, то ее обязательно достигнут - это немного преждевременно.
Ну и вам повторяли уже несколько раз - то что делаете вы - это в принципе некорректно, но вы продолжаете...
Компания ARM разрабатывает ядра более 20 лет. И они в итоге сделали Cortex-A57 для Байкала. Почему же они такие слабаки? У них тоже слабые инженеры?
ARM разрабатывает мобильные ядра более 20 лет. Строго говоря в серверный сегмент они начали смотреть только последние пару лет (а A57, который кстати делали не для байкала, а для телефонов, вообще ядро 2014 года). Те же A57 на 1.5-2 ГГц стояли в телефонах в 2014-2015 годах и прекрасно себя показывали в рамках теплопакета в 9-12 Вт (надо по процессорам смотреть, но это типичные значения для флагманов). Притом на 28-20 нм техпроцессах, еще и вкупе с видеоядром. Так что совсем непонятно к чему вопрос.
A75 - это очень хорошее ядро, но ядро Эльбрус-16С все равно быстрее на FP.
Я в комменте выше привел ссылочку на тестирование Эльбрус-8СВ и Байкал-М1. Посмотрите на более реальные приложения в нем (хотя там тоже хватает синтетики). Дело просто в том, что при очень хорошей теоретической пиковой производительности, ее еще нужно достичь в реальном использовании, а то иначе получится то что вы там можете видеть в Linpack и Blender - когда производительность Э8СВ и Байкал-М1 отличается далеко не вдвое.
Нет, ядра Syntacore слабее, чем A57.
Про них есть презентация 2019 года, где SCR7 показывает 5.00 Coremark/mhz, если посмотрите на байкал-м1 - у него 4.94 coremark/mhz. Понятно что это только 1 бенчмарк, но все таки.
Самое производительное RISC-V ядро в мире - это новое ядро P550 от SiFive.
Тут тоже не так все однозначно. Есть MicroMagic'овское ядро, которое выбивает 13000 coremark'ов суммарно.
Есть Alibaba XT910 - который они правда сравнивают с Cortex-A73, но он практически везде показывает результаты лучше, на десятки процентов. Еще и 150 GFLOP (FP32) на кластер (до 4-х кластеров в рамках одного чипа) заявляют.
Так что надо опять же определять критерии, по которым сравнение идет.
А про сложность создания эффективных OoO ядер - посмотрите на SonicBOOM - opensource risc-v ядро, которое делают в berkely, которое в среднем обгоняет Cortex-A73.
antag
04.10.2021 15:43+1потому что для 1 ядра у Epyc'ов boost гарантирован и вы получите там свои 3.5 ГГц
Нет. Рассматривали производительность всего процессора на всех потоках для fp нагрузок. И там никаких 3.5 ГГц не будет у Epyc, а будет близко к базовой частоте, или чуть выше.
показывает 5.00 Coremark/mhz, если посмотрите на байкал-м1 - у него 4.94 coremark/mhz.
Есть более полный источник с тестами SCR7 на Spec 2017:
https://youtu.be/JosuS-k-bLg?t=1111
Производительность SCR7 на 20% выше, чем у Cortex-A53. Тут совсем очевидно, что у A57 производительность сильно выше этого уровня SCR7.
Есть Alibaba XT910 - который они правда сравнивают с Cortex-A73, но он практически везде показывает результаты лучше, на десятки процентов.
Не видел такого сравнения. Я в тех, которые видел, получается примерно равенство с A73.
А про сложность создания эффективных OoO ядер - посмотрите на SonicBOOM - opensource risc-v ядро, которое делают в berkely, которое в среднем обгоняет Cortex-A73
A73 - это примерно уровень A57 по производительности.
Эти RISC-V тестировали только на симуляторах на отдельных узких бенчмарках. На реальном железе A57 вероятно будет быстрее.
Esperanto Maxion - это те же 6.0 SpecInt/GHz, как и A57.
Так Байкал-М (A57) получается быстрее всех существующих RISC-V ядер, или равен самым лучшим. А Эльбрус-8СВ быстрее, чем A57.
Дело просто в том, что при очень хорошей теоретической пиковой производительности, ее еще нужно достичь в реальном использовании
Но в Spec CPU2017 FP Эльбрусы показывают высокий результат - в 2 раза выше, чем A57, а в Spec CPU2017 INT - тоже на 30% выше, чем A57.
Armmaster Автор
04.10.2021 16:03A73 - это примерно уровень A57 по производительности.
Ну здрасте. A73 это +2 поколения от A57. Арм заявляет там +90% перформанса при переходе на A72 и ещё +30% при переходе на A73. Пусть эти цифры явно маркетинговые, но то, что там будет приличный привар на десятки процентов на спеках это очевидно.
Esperanto Maxion - это те же 6.0 SpecInt/GHz, как и A57.
как человек, имевший непосредственное отношение к разработке ET Maxion, могу сказать, что это просто допиленный Boom v2 и такой чип делается парой десятков инженеров за год при соответствующем опыте. Именно поэтому я могу утверждать, что чипы уровне A57 это очень несложно всё.
По поводу остального - это уже флуд пошёл, вы ходите по кругу. Будет Байкал-S, будут ядра от Syntacore в кремнии - там и поговорим.
antag
04.10.2021 16:46+2Ну здрасте. A73 это +2 поколения от A57. Арм заявляет там +90% перформанса при переходе на A72 и ещё +30% при переходе на A73. Пусть эти цифры явно маркетинговые, но то, что там будет приличный привар на десятки процентов на спеках это очевидно.
У вас полная каша в голове по оценке производительности ядер Cortex.
A73 делали не ради высокой производительности, а ради низкого потребления, А основные производительные ядра были A57, A72 и A76.
И все соотношения по основным ядрам есть вот на этой картинке:
https://3dnews.ru/assets/external/illustrations/2020/12/10/1027480/sm.Esperanto-Maxion2.800.jpg
Civil
04.10.2021 16:54A73 делали не ради высокой производительности, а ради низкого потребления, А основные производительные ядра были A57, A72 и A76.
Ваши заявления расходятся с заявлениями самого ARM. Не читайте русских газет, читайте нормальные источники, если хотите вменяемый анализ.
Собственно по ссылке есть слайды презентации Cortex A73 и там завялялось "Up to 30% higher performance" в сравнении с A72 (на практике имея в виду подсистему памяти, но 5-10% в других бенчмарках было в налчии). Шаг был меньше чем между A57 -> A72, это правда (и тут правда причина в том, что в мобильных телефонах A57 получился тем еще кипятильником), но говорить что A73 было не основным производительным ядром - это в высшей степени некорректно (также как и исключать A75 из этого списка).
antag
04.10.2021 20:57+1На ядрах A72 делали всякие серверные (Graviton, Kunpeng) и околосерверные процессоры, например, сетевые девайсы. Например, Tesla использует A72 в своих процессорах. На A73 ничего подобного не делали.
Отдельные графики ARM обычно делает так, что каждое новое поколение якобы много выигрывает у предыдущего. Но потом на итоговом графике оказывает, что суммарный выигрыш между A57 и A75 менее двух раз даже с учетом огромного роста частоты на графиках:
https://images.anandtech.com/doci/11441/arm-a75_a55-a75_efficiency.png
На этом же графике видно, что прирост производительности A73 от A72 был только за счет частоты.
Civil
05.10.2021 00:51Тем не менее, выкидывать A73, A74, A75, A78, X1, X2 и A710 из списка "основных" ядер в высшей степени некорректно, кажется я ясно пояснил почему.
Armmaster Автор
04.10.2021 17:07У вас полная каша в голове по оценке производительности ядер Cortex.
Смешно, особенно, когда такому аргументу следует вот это:
https://3dnews.ru/assets/external/illustrations/2020/12/10/1027480/sm.Esperanto-Maxion2.800.jpg
Ладно, я думаю, дискуссия окончена, если уж пошли в ход такие аргументы.
antag
04.10.2021 20:41+2Ладно, я думаю, дискуссия окончена, если уж пошли в ход такие аргументы.
И чем плохи мои аргументы, в которых есть ссылки на авторитетные источники ?
Там на той картинке хорошо видно, что A75 выигрывает 30% у A57 по микроархитектурной скорости, как я и написал ранее. Я смотрел другие известные мне источники. И там тоже была разница в 30% в среднем между A57 и A75 на одинаковой частоте.
У вас же есть ноутбук Huawei с ядрами A75. Cравните результаты Spec CPU2017 с известными результатами Байкал-М.
Соотношения будет примерно такими в хороших случаях:
2.96 GHz / 1.5 GHz * 1.30 = 2.56.
Но в нагрузках, которые зависят от памяти, может быть и меньше, чем 2.56.
Вы уже тестировали это. Но надо перевести те результаты из секунд в баллы Spec CPU2017, чтобы легче было сравнить с Байкалом-М и другими известными результатами Spec CPU2017.
Armmaster Автор
04.10.2021 21:03+1У вас полная каша в голове по оценке производительности ядер Cortex.
Я про вот эти аргументы.
Там на той картинке хорошо видно, что A75 выигрывает 30% у A57
На SpecInt, а всю дорогу мы говорили про SpecFp. Я же говорю, вы манипулируете цифрами постоянно.
И да, это не авторитетный источник.
Cравните результаты Spec CPU2017 с известными результатами Байкал-М
Хорошо, если будет возможность добраться до нормальных результатов сравнения A57/A75 - я их приведу.
antag
04.10.2021 21:51+1На SpecInt, а всю дорогу мы говорили про SpecFp. Я же говорю, вы манипулируете цифрами постоянно.
Там почти одинаковый прирост от A57 до A75
INT - примерно 30%
FP - примерно 35%
Civil
05.10.2021 01:05+1Там почти одинаковый прирост от A57 до A75
Вы привели ссылки на график, где SpecInt на A57 и A72 прогоняли авторы Maxion'а, а для A55, A75, A76 они взяли estimate числа от аналитиков.
Вы всерьез считаете, что это адекватный надежный источник данных?
Civil
04.10.2021 16:25+1Нет. Рассматривали производительность всего процессора на всех потоках для fp нагрузок. И там никаких 3.5 ГГц не будет у Epyc, а будет близко к базовой частоте, или чуть выше.
Звучит так, словно вы пытаетесь сейчас подобрать такие данные, чтобы получить нужный вам вывод (потому что абсолютно игнорируете все остальные доводы).
Для микроархитектурной скорости (и прежде чем заявлять что-то про частоты) стоит посмотреть на 1-поточную производительность на максимально доступных частотах - то есть на Ryzen 5950X с его 5.05 ГГц. Давайте тогда так возьмем, чтобы честно было.
Есть более полный источник с тестами SCR7 на Spec 2017:
Я вам привел ссылку на презентацию и Coremark, по которому SCR7 лучше чем A57 (пусть и не очень значительно). Так и что дальше?
что у A57 производительность сильно выше этого уровня SCR7.
Мне кажется, это стоит подкрепить цифрами в SpecINT 2017 по A53 и A57, иначе заявление спорное (синтетические бенчмарки тем и плохи, что показывают местами разный результат).
Не видел такого сравнения. Я в тех, которые видел, получается примерно равенство с A73.
Теперь видели. А по чистой FP производительности получаются результаты выше чем у практически любого существующего официального ARM-ядра.
Эти RISC-V тестировали только на симуляторах на отдельных узких бенчмарках. На реальном железе A57 вероятно будет быстрее.
Почему вероятно? Какой-то очень неочевидный вывод. Если почитаете статью про SonicBOOM - там симулировали процессор полность., а не отдельные блоки, также как для моделировали показатели для частоты 3.2 ГГц (раздел 7 соответствующей статьи). Эти отдельные узкие бенчмарки это CoreMark и SpecInt 2006 и 2017 Rate и получали показатели лучше чем Cortex-A73 (а в отдельных бенчмарках лучше чем Skylake).
Извините, но не вижу никаких обоснований тому почему бы в реальном железе это ядро показывало бы худший результат на МГц чем при моделировании.
Но в Spec CPU2017 FP Эльбрусы показывают высокий результат - в 2 раза выше, чем A57, а в Spec CPU2017 INT - тоже на 30% выше, чем A57.
Ну это полезный показатель, если вы работаете в SpecFP.
В остальных случаях - полезнее смотреть в целом на различные тесты, в том числе в реальных приложениях. Например посмотрите по приведенной ссылке на результаты в Блендере, где А57 показал почти такой же результат как Э-8СВ (при разнице в SpecFP в 2.5 раза, а блендер был в основе одного из под-тестов). Посмотрите на linpack (который не совсем бенчмарк в общем-то) и увидите что 2.5 раза в нем превращаются в 1.5 раза в линпаке. Посмотрите на более интересные бенчмарки в софте что будут использовать люди - то есть на интерпретируемые языки (веб-сервер), javascript (браузер) и прочее - там байкал превосходит эльбрус в 2 с лишним раза.
Опять выглядит так, что вы выбрали одну конкретную метрику и пытаетесь ее использовать как единственно верную, но реальная жизнь она сложнее чем несколько бенчмарков.
antag
04.10.2021 21:46+1В статье написали:
SonicBOOM was physically synthesized at 1 GHz on a commercial FinFET process, matching the frequency achieved by BOOMv2.
А значит нет никакой гарантии, что это супер-ядро SonicBOOM заработает на частоте более чем 1 GHz.
По IPC они только на 7% лучше, чем A72, а значит на 1 GHz они проиграют Байкалу, который на 1.5 Ghz. И проиграют Эльбрусу.
Мне кажется, это стоит подкрепить цифрами в SpecINT 2017 по A53 и A57
Очевидно, что у A57 IPC значитильно выше, чем у A53. Вон на той картинке есть A55. A53 еще слабее.
https://3dnews.ru/assets/external/illustrations/2020/12/10/1027480/sm.Esperanto-Maxion2.800.jpg
Civil
05.10.2021 00:31+2Очевидно, что у A57 IPC значитильно выше,
Приведите число, пожалуйста со ссылкой на источник.
Картинка кстати не в тему, там не тест, а цифра от балды (aka Estimate). К тому же вы говорили про SpecINT 2017, а привели картинку с SpecINT 2006.
А значит нет никакой гарантии, что это супер-ядро SonicBOOM заработает на частоте более чем 1 GHz.
Я правильно понимаю, что вы решили посреди дискуссии согласится с тем, что надо смотреть на производительность на максимально возможной частоте?
antag
05.10.2021 10:38+1Ядра A53 уже никто не тестирует.
Но A55 тестируют
https://www.anandtech.com/show/16983/the-apple-a15-soc-performance-review-faster-more-efficient/2
A55 на 1.8 GHz - 0.7 Spec CPU2017_INT
Байкал A57 на 1.5 GHz - 1.1 Spec CPU2017_INT
A53 слабее, чем A55.
Я правильно понимаю, что вы решили посреди дискуссии согласится с тем, что надо смотреть на производительность на максимально возможной частоте?
Рассматривать можно для любой частоты.
Но ядер RISV-V с высокой частотой и высокой производительностью вообще нет.
У SonicBOOM есть хороший IPC - на уровне ядер A72. Но частота там ниже, чем у A72. В статье написали только про 1 GHz у SonicBOOM на FinFET. А Finfet - это 16 нм, как минимум. А на такой низкой частоте SonicBOOM никакой конкуренции по производительности не составит даже Байкалу-М.
Civil
05.10.2021 11:28+3A55 на 1.8 GHz - 0.7 Spec CPU2017_INT
Ок, хотя вы заявляли про A53 и я все таки хотел бы увидеть цифры от Вас про него. (я в курсе что его не тестируют, но вы сами аппелировали к цифрам).
И таки давайте вернемся к тому что у Байкала-М1 - 4.94 coremark/mhz а у scr7 - 5.0. А то вы что-то прицепились к specint'у сейчас.
EDIT: Читая статью внимательнее я кстати заметил, что вы меня смогли ввести в заблуждение и начать сравнивать несравнимое:
One continuing issue with SPEC CPU 2017 is the Fortran subtests; due to a lacking compiler infrastructure both on iOS and Android, we’re skipping these components entirely for mobile devices. What this means also, is that the total aggregate scores presented here are not comparable to the full suite scores on other platforms, denoted by the (C/C++) subscript in the score descriptions.
Так что я продолжу настаивать на том, что это ваша задача предоставить корректные цифры для SpecINT 2017 для A55 (кстати учтите, это общая фишка Spec тестов на anandtech'е если речь идет про мобильные устройства, что для SpecINT 2006, что для 2017), поэтому из мобильных обзоров результаты сравнивать с платами и не мобильными - нельзя.
Рассматривать можно для любой частоты.
Повторюсь еще раз - вы в одном месте говорите про эффективность архитектуры как бенчмарки нормированные на ГГц, а как вам принесли цифры которые выглядят хорошо то сразу дали заднюю и начали говорить что надо смотреть еще и на частоту.
Определитесь уже. Пока это считать еще одним примером манипуляции с вашей стороны (буквально как только нашелся удобный пример который по вами определенным метрикам выглядел слишком хорошо, вы на ходу поменяли подход и еще отказываетесь это признать).
Но ядер RISV-V с высокой частотой и высокой производительностью вообще нет.
Я напомню, что SonicBOOM я привел в контексте сложности создания эффектинвых OoO ядер. Мне кажется, лучше примера чем OpenSource ядро которое делают в академии несколько аспирантов с научником (для SonicBOOM команда это 3 аспиранта и их научник, но строго говоря они использовали наработки прошлых команд аспирантов по прошлым версиям) и они за несколько лет (между in-order boomv2 и OoO sonicboom'ом - 3 года) сделали ядро эффективнее чем Cortex A57 (вы сами согласились про IPC). Кажется вполне подтверждает тезис про то что это немного легче, чем вы пытались это выставить.
В статье написали только про 1 GHz у SonicBOOM на FinFET
В статье строго говоря написано что они пытались сматчить частоты с BOOMv2 и это у них получилось. Строго говоря у них не сказано up to сколько они могут достичь.
А Finfet - это 16 нм, как минимум
Если вы чуть-чуть покопаетесь, то найдете что они использовали 22нм техпроцесс для синтеза (это есть на гитхабе в одном из репозиториев в обсуждении как достичь больших тактовых частот на SMIC 40nm, но ссылку давать вам не буду, так как от вас я достаточно много манипуляций информацией уже видел).
antag
05.10.2021 12:06И таки давайте вернемся к тому что у Байкала-М1 - 4.94 coremark/mhz а у scr7 - 5.0. А то вы что-то прицепились к specint'у сейчас.
У байкала:
66195.276064 на все ядра.
66195 / 8 / 1.5 = 5.516
Но этот тест Coremark не является показательным. Тот же байкал-Т на Mips тоже давал 5.5 там. Но процессор был слабее.
Тесты Spec точнее и лучше.
сделали ядро эффективнее чем Cortex A57 (вы сами согласились про IPC).
Нет. Они просто накидали исполнительных устройств и других блоков в ядро. Это относительно легко. Но в итоге не получили большую отдачу по IPC, и не получили гарантированную высокую частоту. А без этой частоты вся эта затея бессмысленна. Без высокой частоты делать такой процессор в железе бесполезно. Уже есть лучше по производительности. Raspberry PI A72 - значительно лучше.
Повторюсь еще раз - вы в одном месте говорите про эффективность архитектуры как бенчмарки нормированные на ГГц, а как вам принесли цифры которые выглядят хорошо то сразу дали заднюю и начали говорить что надо смотреть еще и на частоту.
Я написал свое доказательство.
У Эльбрусов и Байкалов одинаковые частоты на одинаковых техпроцессах, и примерно одинаковые напряжения.
И в условиях равных частот можно рассматривать IPC. Итоговая производительность ядра будет пропорциональна этому показателю.
Эльбрусы выигрывают на FP у Байкалов на одинаковых частотах.
Но никакой RISV-V в ближайшее время не выиграет по производительности у ядер Байкалов на одинаковых техпроцессах.
Российский RISV-V слабее, чем A57.
Лучший перспективный мировой - SiFive P550 - на уровне A75. Но российским разработчикам ядер RISV-V до этого уровня еще очень далеко.
Civil
05.10.2021 12:27+1Тесты Spec точнее и лучше.
Тоже подожду доказательства.
Нет
Повторюсь в последний раз - вы говорили про сложность создания OoO процессора. Вот пример. По эффективности - лучше чем A72. Цифры это явным образом доказывают.
Я написал свое доказательство.
Я не увидел от вас доказательства, только множественные манипуляции данными и попытки поменять подход как только Ваш начал разваливаться.
Эльбрусы выигрывают на FP у Байкалов на одинаковых частотах.
Вам несколько человек уже повторило:
Людям в среднем FP нафиг не сдался. Большинство задач FP блоки не нагружают.
Результаты в реальном мире и в синтетике будут разными (даже если синтетика - хорошая). Посмотрите на результаты в SPECах, и сравните их же с результатами в реальных приложениях. Кстати, тут Coremark показывает числа ближе к тому что увидят пользователи в процессе использования оборудования. И даже про сложности работы с FP вы можете наблюдать на примере Блендера (где разница между 8СВ и М1 практически отсутствует).
Но никакой RISV-V в ближайшее время не выиграет по производительности у ядер Байкалов на одинаковых техпроцессах.
Этому утверждению требуется доказательство.
Лучший перспективный мировой - SiFive P550 - на уровне A75.
Вернитесь к началу обсуждения и посмотрите список. Вы слишком категоричны, поэтому даже фраза "лучший мировой" является ложной (все зависит от того с какой стороны рассматривать).
antag
05.10.2021 12:38+1SCR7 на 20% быстрее, чем Cortex-A53.
A57 примерно на 70% быстрее, чем A53 на одинаковой частоте.
Тут сравнение Байкала и Raspberry Pi 3B+, который A53:
https://browser.geekbench.com/v5/cpu/compare/9641135?baseline=9551440
A57 будет на 40% быстрее, чем SCR7.
Civil
05.10.2021 13:24+1SCR7 на 20% быстрее, чем Cortex-A53.
В SpecINT 2017
A57 примерно на 70% быстрее, чем A53 на одинаковой частоте.
Тут нужно доказательство что в SpecINT 2017 A57 быстрее чем A53 на 70% на одинаковой частоте. Иначе связать результаты с SCR7 не удастся (разные бенчмарки могут и будут вести себя по-разному, а то следуя вашей же логике я могу привести по такой логике пример с парсингом XML где на равной частоте A53 отстает на 30% от A57)
Тут сравнение Байкала и Raspberry Pi 3B+, который A53:
https://browser.geekbench.com/v5/cpu/compare/9641135?baseline=9551440
A57 будет на 40% быстрее, чем SCR7.
Перенос результатов другого бенчмарка в принципе недопустим. Поэтому если приводите geekbench 5 - покажите его результаты для SCR7
antag
05.10.2021 14:00+1Перенос результатов другого бенчмарка в принципе недопустим. Поэтому если приводите geekbench 5 - покажите его результаты для SCR7
Перенос допустим. Найти реальные цифры Spec CPU2017 для A53 трудно. Никто не публиковал их. Но определить выигрыш A57 от A53 легко. Есть миллионы устройств на этих ядрах, и можно использовать то среднее преимущество на 70%, которое показывает geekbench 5.
И единственная надежная оценка производительности для SCR7 - это тот слайд про 20%.
В обоих случаях это не какой-то случайный результат на одной нагрузке, а среднее среди множества нагрузок - 9 штук для SCR7. И так же много нагрузок для geekbench.
Поэтому этим отдельным оценкам про 70% и 20% вполне можно доверять. И можно совмещать эти оценки в итоговый результат про 40% преимущества A57 над SCR7.
Когда не хватает конкретных конечных выводов, надо уметь пользоваться инструментами и данными, которые доступны.
Если сомневаетесь в моих выводах, попробуйте самостоятельно определить или найти информацию про то, как отличаются A57 и A53 по производительности.
A57 - это 3 декодера и OoO.
A53 - это 2 декодера без OoO.
Если бы между ними не было большой разницы по производительности, тогда такой OoO можно было бы признать бесполезным.
SCR7- это 2 декодера и OoO.
Civil
05.10.2021 15:35+1Перенос допустим.
Нет, недопустим. Это разные бенчмарки, совершенно не факт что их оценки будут совпадать.
Как я уже сказал - давайте я тогда возьму какой-то XML Benchmark с того же anandtech где разница между A53 и A57 всего 30% и буду на его базе говорить что разница между A53 и A57 - 30%, следуя вашей же логике.
И единственная надежная оценка производительности для SCR7 - это тот слайд про 20%.
Вы еще забыли слайд с 5.00 Coremark/mhz, например.
Когда не хватает конкретных конечных выводов, надо уметь пользоваться инструментами и данными, которые доступны.
Проблема в том, что вы постоянно забываете границы применимости инструментов и поэтому начинаете делать неверные выводы, но крайне категорично.
Если сомневаетесь в моих выводах, попробуйте самостоятельно определить или найти информацию про то, как отличаются A57 и A53 по производительности.
Сомневаюсь, потому что на практике разница в производительности очень сильно зависит от задачи, до такой степени что покопавшись достаточно вам удастся найти задачу где A53 обгонит равночастотный A57 (это будет узкий класс задач, впрочем).
Поэтому корректное сравнение производительности железа - это крайне сложный процесс и там недостаточно взять один какой-то бенчмарк и в нем все смотреть (причины и я и другие вам уже говорили многократно). Также как делать то, что вы сейчас творите - тоже недопустимо и приведет к неверным выводам.
SCR7- это 2 декодера и OoO.
Извините, я не понимаю что вы имеете в виду под "2 декодера". Используйте пожалуйста общепринятую терминологию.
Я могу попробовать догадаться что вы имеете в виду что он dual-issue, но я тут напомню что это само по себе не является показателем производительности, так как Cortex A73 тоже dual-issue, но при этом быстрее чем A72. Микроархитектуру нельзя упрощать до количества декодируемых команд за такт, к сожалению. Да и в целом только по теоретическим выкладкам анализировать производительность - в корне неверно.
antag
05.10.2021 16:13+1Cortex A73 тоже dual-issue, но при этом быстрее чем A72.
Не быстрее.
6.75 SPECInt/GHz - Cortex-A73 - в статье
6.13 SPECInt/GHz - Cortex-A57 - это реальные тесты
Попробуйте вписать A72 между ними.
A72 использовали в серверных Graviton и Kunpeng. А ядро A73 сделали специально для смартфонов. A73 не быстрее, но оно потребляет меньше.
Микроархитектуру нельзя упрощать до количества декодируемых команд за такт
Этим и отличается хорошая разработка от слабой.
A73 - это лучшее ядро, которое имеет только два декодера. Но никто больше не смог повторить на 2 декодерах такую высокую производительность.
SCR7 - тоже не смогли.
Так A75 - это очень хорошее ядро на 3 декодерах.
XT-910 - тоже 3 декодера. Но производительность ниже, чем у A75.
Так даже крупные разработчики на RISC-V проигрывают ядрам Cortex по производительности. А российские RISC-V проиграют еще больше. До уровня Cortex там очень далеко. А ядра Эльбрус уже на том уровне для INT, и даже выше для FP нагрузок.
Поэтому корректное сравнение производительности железа - это крайне сложный процесс и там недостаточно взять один какой-то бенчмарк и в нем все смотреть
Один бенчмарк - плохо.
Средний результат из 10 нагрузок - уже хорошо. Этого достаточно для точных оценок.
Coremark я не доверяю. Известно, что там даже простейшие мипсы без OoO накручивали до высокого уровня. Это слишком специфичный и мелкий бенчмарк, где научились хорошо прокачивать слабые ядра.
Civil
05.10.2021 17:06Не быстрее.
Я вам показал уже слайды ARM, где утверждается что быстрее в int и memory workloads. Поэтому обращайтесь к ним за разъяснениями что они имели в виду. В анонсах компании обычно не врут (им это черевато исками).
A73 - это лучшее ядро, которое имеет только два декодера. Но никто больше не смог повторить на 2 декодерах такую высокую производительность.
Я предполагаю что вы забыли включить ссылку на анализ всех когда либо выпущенных 2-issue (если я правильно понимаю что вы подразумеваете под двумя декодерами) процессорами. Надеюсь вы будете так любезны ее предоставить?
Но производительность ниже, чем у A75.
В данном месте я предлагаю вам доказать это на практике и привести какой-нибудь бенчмарк, где A75 показал бы результат выше чем 600 GFLOPS (напомню, столько заявлена производительность 4-х кластерного XT-910 в плавучке).
А ядра Эльбрус уже на том уровне для INT, и даже выше для FP нагрузок.
Вы тут ошибаетесь, это опровергнуто бенчмарками в реальных приложениях, где в ряде нагрузок Эльбрус отстает в разы от равночастотного А57. Ссылки были в треде.
Один бенчмарк - плохо.
Средний результат из 10 нагрузок - уже хорошо. Этого достаточно для точных оценок.
Без понимания что делает бенчмарк и как некоторые производители могут читерить - это чистой воды cargo cult.
Coremark я не доверяю. Известно, что там даже простейшие мипсы без OoO накручивали до высокого уровня. Это слишком специфичный и мелкий бенчмарк, где научились хорошо прокачивать слабые ядра.
Вы можете его исходный код почитать или документацию с обоснованием подхода. Так как Ваше недоверие абсолютно беспочвенно, он хорош для своих задач, надо просто понимать что он показывает (как и spec).
В целом, извините, я уже слегка подустал вам твердить одно и то же. Начинает казаться что вы просто не понимаете о чем ведете речь.
antag
05.10.2021 20:43Я вам показал уже слайды ARM, где утверждается что быстрее в int и memory workloads. Поэтому обращайтесь к ним за разъяснениями что они имели в виду. В анонсах компании обычно не врут (им это черевато исками).
Нам вообще не нужен промежуточный A73, чтобы сравнивать XT-910 c российскими процессорами.
Есть известные данные
6.11 SPECInt/GHz - XT-910 - в статье
6.13 SPECInt/GHz - Cortex-A57 - это реальные тесты Байкала.
7.8-8.0 SPECInt/GHz - Cortex-A75 - это наиболее вероятная оценка, и которая есть на некоторых слайдах.
Этих соотношений достаточно, чтобы утверждать, что XT-910 проигрывает ядру A75. Поэтому они и выбрали A73 для сравнения, а не A75.
Аналогично для SCR7 выбрали совсем слабое ядро A53 на своих слайдах, чтобы не позориться на фоне высокой производительности ядер A57 и A72.
Я предполагаю что вы забыли включить ссылку на анализ всех когда либо выпущенных 2-issue (если я правильно понимаю что вы подразумеваете под двумя декодерами) процессорами.
Посмотрите слайды XT-910.
Там перечисляют его характеристики:
• 3-decode,8-issue
Вот и подумайте для начала, чем issue отличается от decode. И не путайтесь в этих терминах.
В данном месте я предлагаю вам доказать это на практике и привести какой-нибудь бенчмарк, где A75 показал бы результат выше чем 600 GFLOPS (напомню, столько заявлена производительность 4-х кластерного XT-910 в плавучке).
У Эльбрус-16С есть 1500 GFLOPS на FP32. Это в 2.5 раза больше, чем у XT-910. А число ядер одинаковое - 16 штук.
Я уже написал свою основную позицию.
Ядро Эльбруса примерно на уровне A75 для INT, и сильнее ядра A75 на FLOAT.
Никаких RISC-V уровня A75 не существует физически. Только есть SiFive P550 в проекте. Но российским разработчикам до уровня ядра P550 очень далеко.
Если кто-то и придумает свои расширения RISC-V для FLOAT, то у Эльбруса тоже уже есть много этих GFLOPS.
Так фактически российские разработчики своих ядер выйдут на уровень производительности ядра Эльбруса только через несколько итераций и через несколько лет.
Civil
08.10.2021 02:58-1О, не заметил этого Вашего ответа. Прошу прощения. Впрочем, наверное это мой последний ответ вам в принципе, так как вы явно не слушаете и путаетесь в терминологии чуть чаще, чем всегда и я устал уже вам повторять одно и то же по черт знает какому разу.
Нам вообще не нужен промежуточный A73, чтобы сравнивать XT-910 c российскими процессорами.
Я вообще не сравниваю XT-910 с российскими процессорами, мне на это слегка плевать. Я указываю ВАМ на Ваши ошибки, не более.
Этих соотношений достаточно, чтобы утверждать, что XT-910 проигрывает ядру A75. Поэтому они и выбрали A73 для сравнения, а не A75.
Повторю вопрос - покажите какой А75 показывает на 16-и ядрах 600 гфлопс.
Если намеков не понимаете, то повторю явно: SPEC - это не все, нельзя по одному бенчмарку (тем более постоянно меняя specint на specfp и обратно) делать какие-либо выводы о производительности. Это хороший начальный отсчет (и то не всегда), но не более того.
Вот и подумайте для начала, чем issue отличается от decode. И не путайтесь в этих терминах.
Я не путаюсь, я не понимаю что вы имеете в виду когда говорите "2 декодера", так как в русском языке нет таких терминов в принципе. Пишите корректно, и не будет недопонимания. Не знаете как по-русски - пишите по-английски.
У Эльбрус-16С есть 1500 GFLOPS на FP32. Это в 2.5 раза больше, чем у XT-910. А число ядер одинаковое - 16 штук.
Эльбрус-16С не в стадии серийного производства даже, так что по факту нету (и не было в 2020, когда был рассказал про xt910)
А причем тут вообще Эльбрус, если мы про Cortex'ы?
Я уже написал свою основную позицию.
Да, и я уже который раз сказал почему она в корне не верна: потому что Эльбрус не показывает в реальных приложениях уровень А75 в INT, да и чтобы получить разумные результаты в float надо оптимизировать код чуть ли не руками. Поэтому даже если достичь уровня A57 - это будет уже лучше в большинстве реальных задач. А достичь A57 - не так сложно, примеров как это сделали быстро - хватает.
beeruser
06.10.2021 16:47habr.com/ru/post/581222/#comment_23556010
Тоже подожду доказательства.
Это какой-то троллинг?
Вы хотите сказать что наследник Dhrystone — поделка для тестирования микроконтроллеров, ибо больше им ничего протестировать нельзя, лучше эталонного индустриального набора бенчмарков, состоящего из серьёзных приложений? =DПосмотрите на результаты в SPECах, и сравните их же с результатами в реальных приложениях. Кстати, тут Coremark показывает числа ближе к тому что увидят пользователи в процессе использования оборудования.
Нет, это клоунада какая-то. SPEC состоит из них, этих самых, реальных приложений.
Coremark это настолько примитивная и бессмысленная синтетика, что к реальному софту она не имеет ни малейшего отношения.
The code is written in C and contains implementations of the following algorithms: list processing (find and sort), matrix manipulation (common matrix operations), state machine (determine if an input stream contains valid numbers), and CRC.
поэтому из мобильных обзоров результаты сравнивать с платами и не мобильными — нельзя.
Можно. Нужно смотреть результаты тестов, а не одну циферку. Одна циферка это довольно тупо.
Например оцените Феррари и Белаз по шкале 1...10Для микроархитектурной скорости (и прежде чем заявлять что-то про частоты) стоит посмотреть на 1-поточную производительность на максимально доступных частотах — то есть на Ryzen 5950X с его 5.05 ГГц.
Это и была оригинальная претензия к автору — микроархитектуру и частоту нельзя отделять.
Но есть один нюанс(с). Для серверного процессора реальная производительность одного ядра гораздо меньше, потому что загружены все ядра.
Реальная частота Xeon/Epyc — 2-3ГГцсделали ядро эффективнее чем Cortex A57
A57 это по сути расширение микроархитектуры A15 до 64-бит. Каких-то кардинальных изменений там нет.
…
Я напомню, что SonicBOOM я привел в контексте сложности создания эффектинвых OoO ядер. Мне кажется, лучше примера чем OpenSource ядро которое делают в академии несколько аспирантов с научником
Кажется вполне подтверждает тезис про то что это немного легче, чем вы пытались это выставить.
Кривая сложности тут растёт очень быстро.
Сделать высокопроизводительный OoO процессор на уровне лидеров это задача архисложная.
Буквально несколько человек в мире обладают необходимой компетенцией и доступом к ресурсам.
И это подтверждается отсутствием высокопроизводительных процессоров RISC-V, даже несмотря на доступ к достаточно серьёзным ресурсам.
habr.com/ru/post/581222/#comment_23556346Нет, недопустим. Это разные бенчмарки, совершенно не факт что их оценки будут совпадать.
GB5 имеет широкий набор тестов и его результаты линейно можно преобразовать в SPEC и обратно, без шума и пыли(с)
habr.com/ru/post/581222/#comment_23557444Так как Ваше недоверие абсолютно беспочвенно, он хорош для своих задач, надо просто понимать что он показывает (как и spec).
Ахах. И что же он показывает?
Как массив сортируется? Wow, вот это уровень!
Куда уж компилятору GCC до такой сложной задачи!В целом, извините, я уже слегка подустал вам твердить одно и то же. Начинает казаться что вы просто не понимаете о чем ведете речь.
Или вы :)
Civil
06.10.2021 18:52Это какой-то троллинг?
Не совсем, я человеку говорил про применимость бенчмарков много раз, а также человеку много раз указывали (вот не помню я делал или нет, но точно было), что МЦСТ под тот же SPEC делает оптимизации (а значит доверие результатам Эльбруса тут будет никакое). Я наивно понадеялся что человек таки пойдет и почитает про то что пишет и перестанет говорить странные вещи (особенно когда хватает свидетельств странному поведению).
Нет, это клоунада какая-то. SPEC состоит из них, этих самых, реальных приложений.
Авторы SPECа с вами не согласны. Бенчмарк базируется на реальных приложениях, но не обязательно состоит из них (какие-то используют приложение без изменений, в каких-то используются модифицированные версии из которых выкинуто лишнее). Почитайте их FAQ (Q7) и описания самих бенчмарков. И можно при желании найти еще кучу вещей, которые SPEC не покрывает от слова совсем, либо покрывает ограниченно. Это важно понимать и учитывать, вне зависимости от того индустриальный ли это стандарт или нет (тем более мягко говоря не все производители железа публикуют результаты spec'а, в том числе не просто так).
Coremark это настолько примитивная и бессмысленная синтетика, что к реальному софту она не имеет ни малейшего отношения.
Тут тоже сложно согласится, вы сами чуть ниже процитировали что оно тестирует. По вашему - в реальном софте не бывает валидаций, работ со списками и прочего что они тестируют?
И еще раз перечитайте всю ветку. Человек возводит (совершенно некорректно) SPEC в абсолют (как единственный показатель), притом ловко подменяет SPECint на fp когда ему это выгодно. Я изначально на coremark начал ссылаться как на пример, который явно опровергает его заявления.
А, ну и один немаловажный момент касательно конкретно Эльбрусов - ходят слухи что МЦСТ оптимизирует компилятор под нормальное выполнение SPEC'а. В таком контексте доверия к их результатам нет никакого (тем более они не публикуют в нормальном виде, как того требуют правила, эти результаты, поэтому строго говоря ссылаться на SPECи для них в принципе некорректно).
И я напомню, что Coremark по результатм куда больше на Эльбрусе напоминает результаты для более типичных для пользователя юз-кейсов (а я напомню - в современном мире это браузер и js, а в серверном мире - код на интерпретируемых языках или в виртуальных машинах).
Можно. Нужно смотреть результаты тестов, а не одну циферку. Одна циферка это довольно тупо.
Вы вырываете фразу из контекста, либо ответ предназначался не мне, но тогда лучше делайте отдельный пост. Если таки Вы уверены, что отвечали мне, то напомню, что вырывание фраз из контекста может быть отнесено к троллингу, а это запрещено правилами хабра.
Но есть один нюанс(с). Для серверного процессора реальная производительность одного ядра гораздо меньше, потому что загружены все ядра.
Есть не один, а много нюансов. Если подходить не как это делает человек, с которым этот тред был, то начинать надо с рассмотрения конкретно юз-кейса, потому что есть классы задач, где надо брать железо с малым количеством быстрых ядер, есть задачи где надо брать много медленных и целый спектр задач между. Просто взять самый дорогой процессор - не выйдет. Более того, я это и тут и в соседних топиках говорил - важно учитывать как на самом деле работает процессор (в плане буст частот). Современное железо в том числе от AMD - в этом плане сложное и некорректно просто брать базовую частоту и смотреть результаты на ней: AMD имеют тенденцию выдавать в boost'е частоты выше заявленных, например, а также intel'ы и как минимум десктопные amd при отсутствии внешних ограничений не будут опускаться до базовой частоты в принципе. Собственно поэтому реальная частота сильно зависит от условий и нагрузки на различные блоки, а не только ядра. И кстати не надо считать, что серверный процессор всегда загружен под заявзку по ряду причин:
Забить сервер задачами - очень сложно, если делать эффективно. И даже только утилизировать процессор - крайне непросто, если делать это эффективно.
Если делать неэффективно - выбор очень простой - либо недоутилизировать ресурсы (соответственно частоты будут выше), либо жертвовать latency (что не для любых задач в принципе допустимо)
С учетом того что я сказал выше, я думаю, достаточно очевидно что сказать на какой частоте будет работать процессор в среднем - практически невозможно.
А потом - почитайте еще раз аргументацию. Я по-прежнему настаиваю что если хочется оценить потенциал микроархитектуры на 1 ядро то надо брать однопоточный тест на наиболее быстром представителе (а это как минимум декларируемая цель автора). Если хочется получить что-то разумное - по хорошему надо смотреть на однопоток и многопоток как минимум характерных представителей микроархитектуры (более того - там есть место и для нормированных результатов на МГц или ГГц, но применимость у таких результатов очень ограничена) и предоставлять небольшой вагончик результатов.
И это подтверждается отсутствием высокопроизводительных процессоров RISC-V, даже несмотря на доступ к достаточно серьёзным ресурсам.
Высокопроизводительных RISC-V нет (и то спорно, смотрите всю ветку и примеры той же алибабы) в первую очередь потому что версия 1.0 спецификации на ISA была опубликована несколько лет назад.
Потом речь шла не о лидерах, а он процессоре по эффективности сопоставимым с A57, почитайте тред еще раз. Тому же A57 до лидеров как до луны, но вот с нуля до его уровня толпа аспирантов сделала ядро за пару лет (от прошлого in-order до первого out-of-order у boom'ов прошло несколько лет).
GB5 имеет широкий набор тестов и его результаты линейно можно преобразовать в SPEC и обратно, без шума и пыли(с)
С первой частью не спорю - имеет широкий набор тестов. А вот о преобразовании в SPEC и обратно - не согласен. Тесты в GB5 напрямую не конвертируются, как минимум потому что они не совпадают (gb5 не тестирует часть вещей из spec'а, и наоборот). Это раз.
Во вторых - gb как наборы тестов открыты для отправки всем, поэтому детали про условия тестирования неизвестны (также как и есть заведомо недостоверные результаты в базе, строго говоря я открыл топ и первые 7 результатов там - фэйк, а на самом деле таких куда больше), в то время как тесты от производителя предполагают наилучшие условия для их железа (впрочем 100% гарантии отсутствия читов или фэйков тоже нет, но тут производитель железа хотя бы свою репутацию на кон ставит).
Куда уж компилятору GCC до такой сложной задачи!
Отличный уровень аргументации. Посмотрите буквально чуть выше замечание про правила хабра и троллинг.
Ну и вопрос "причем тут GCC?" я пожалуй задавать не буду.
beeruser
07.10.2021 20:47-1Бенчмарк базируется на реальных приложениях, но не обязательно состоит из них
Софистика.какие-то используют приложение без изменений, в каких-то используются модифицированные версии из которых выкинуто лишнее.
И оставлено всё нужное. Это как-то делает из реальных приложений синтетические?Тут тоже сложно согласится
Сложно ли? По сути, вам говорят что карьерный экскаватор гораздо лучше подходит для рытья карьеров чем детская лопатка. Ваш ответ «подожду доказательства», «сложно согласиться».вы сами чуть ниже процитировали что оно тестирует. По вашему — в реальном софте не бывает валидаций, работ со списками и прочего что они тестируют?
Вы хотя бы понимаете, что сортировка массива в изоляции на тестовом массиве не показывает как будет вести себя этот код в реальной ситуации с реальными данными?
В реальной программе тысячи алгоритмов, которые нагружают все блоки процессора.
Более того, разные программы нагружают их совершенно по разному. По этому полноценный тест должен включать мегабайты кода и гигабайтные working sets. Только так можно оценить производительность подсистемы памяти, возможности OoO.
Также есть микроархитектурные тесты, направленные на изучение работы блоков процессора. Coremark не является ни тем, ни другим.
«EEMBC’s CoreMark® is a benchmark that measures the performance of microcontrollers (MCUs) and central processing units (CPUs) used in embedded systems.»ходят слухи что МЦСТ оптимизирует компилятор под нормальное выполнение SPEC'а
Как и Интел. Что логично, потому как в SPEC входят популярные приложения.(а я напомню — в современном мире это браузер и js, а в серверном мире — код на интерпретируемых языках или в виртуальных машинах).
Для этого есть Octane и Sunspider. Но они показывают связку CPU+VM в первую очередь.
Синтетический псевдо-бенчмарк с самописной VM опять же ничего путного не покажет.Человек возводит (совершенно некорректно) SPEC в абсолют (как единственный показатель)
Тесты для микроконтроллеров, с которыми вы тут носитесь, ничего не показывают.
Если вы зайдёте в процессорный раздел ixbt и будете бряцать coremark-ом, вас… не поймут.
forum.ixbt.com/?id=8Вы вырываете фразу из контекста, либо ответ предназначался не мне, но тогда лучше делайте отдельный пост.
Вам. Забыл добавить ссылку. Но несложно найти это место поиском.
Я не могу написать отдельный пост, потому как могу комментить только 1 раз в день.что если хочется оценить потенциал микроархитектуры на 1 ядро то надо брать однопоточный тест на наиболее быстром представителе
К этому нет претензий.(а это как минимум декларируемая цель автора).
Напомню, что этот тред начался с попытки оспорить заявления автора, который возвёл «микроархитектурную скорость» в абсолют(с)
habr.com/ru/post/581222/#comment_23548464Высокопроизводительных RISC-V нет (и то спорно, смотрите всю ветку и примеры той же алибабы)
Я читал об этом процессоре в тот же день как появился его анонс. Под высокопроизводительным я подразумеваю текущий уровень лидеров рынка.
Уровень старого смартфонного 2-wide чипа Cortex-A73 не является таковым.Потом речь шла не о лидерах, а он процессоре по эффективности сопоставимым с A57, почитайте тред еще раз.
Давайте почитаем.
"Самое производительное RISC-V ядро в мире — это новое ядро P550 от SiFive. И они только сейчас достали уровень Cortex-A75."А вот о преобразовании в SPEC и обратно — не согласен. Тесты в GB5 напрямую не конвертируются, как минимум потому что они не совпадают (gb5 не тестирует часть вещей из spec'а, и наоборот). Это раз.
Сколько нам открытий чудных…
medium.com/silicon-reimagined/performance-delivered-a-new-way-part-2-geekbench-versus-spec-4ddac45dcf03
Посмотрите на табличку
Table 3: Predicting SPEC CPU performance¹
The table also shows the predicted CPU2006 INT ST scores using the linear equation in Figure 1 and these are within 1% of measurements. Based on past studies, we generally find that the measurements and predictions are within 5% of each other.
<1% это достаточная точность предсказания?
Хотя там конечно всё в дисклеймерах, тем не менее, вполне занятно.
Вот как раз из-за широкого покрытия тестов, результаты хорошо коррелируют между собой.
От того, что SPEC имеет Bzip2 и GCC, а GB имеет LZMA и Clang особо ничего не меняется.также как и есть заведомо недостоверные результаты в базе, строго говоря я открыл топ и первые 7 результатов там
Для этого существует статистика.
Если есть тысяча корректных результатов и несколько фейковых, то эти фейки легко отбрасываются.
Отобранный результат можно посмотреть в чартах.Ну и вопрос «причем тут GCC?» я пожалуй задавать не буду.
Если такой вопрос у вас возник, то стоило бы.
GCC это один из тестов SPEC.
www.spec.org/cpu2017/Docs/benchmarks/502.gcc_r.html
Civil
08.10.2021 02:25Софистика.
Нет. Это важная часть информации о бенчмарке, позволяет понять что в реальном мире и реальных приложениях результаты могут отличаться.
И оставлено всё нужное. Это как-то делает из реальных приложений синтетические?
Зависит от вмешательств. В целом - да, делает.
Сложно ли? По сути, вам говорят что карьерный экскаватор гораздо лучше подходит для рытья карьеров чем детская лопатка. Ваш ответ «подожду доказательства», «сложно согласиться».
Аналогия не валидна.
Вы хотя бы понимаете, что сортировка массива в изоляции на тестовом массиве не показывает как будет вести себя этот код в реальной ситуации с реальными данными?
Конечно, но вы читали главную страничку сайта, и то не целиком (судя по цитатам дальше). Почитайте whitepaper, плюс код есть в открытом доступе.
В реальной программе тысячи алгоритмов, которые нагружают все блоки процессора.
Более того, разные программы нагружают их совершенно по разному. По этому полноценный тест должен включать мегабайты кода и гигабайтные working sets. Только так можно оценить производительность подсистемы памяти, возможности OoO.В реальной программе все зависит от программы. Такие выводы не верны в общем случаи (большинство софта практически не нагружает FP, весомый кусок софта не будет использовать современный SIMD и так далее). Также как не верен вывод про мегабайты кода и гигабайты working sets. Но с тем, что разные программы нагружают их соверешенно по разному - спорить не буду.
Также есть микроархитектурные тесты, направленные на изучение работы блоков процессора. Coremark не является ни тем, ни другим.
«EEMBC’s CoreMark® is a benchmark that measures the performance of microcontrollers (MCUs) and central processing units (CPUs) used in embedded systems.»Читайте целиком первую страницу, а лучше почитайте их paper.
Как и Интел. Что логично, потому как в SPEC входят популярные приложения.
Из этого я сделаю вывод, что список тестов SPECа вы не видели (или забыли), а утверждение про МЦСТ не читали, как и прошлые статьи. Почитайте, полезно будет.
Про утверждение про Intel - понимаете какое дело - утверждение про МЦСТ было что оптимизации идут не под реальные приложения, а именно под бенчмарки, что есть намек что это немного читы, не дающие особых преимуществ в реальных приложениях. Тут утверждение на совести автора статьи, но у меня как-то нет причин не верить ему. В то же время c Intel/AMD это не так важно, притом сразу по двум причинам - во первых архитектурно, а во вторых - потому что их компиляторы не так чтоб очень популярны (основная масса разработчиков использует сторонние компиляторы, типа gcc, clang, msvc) . Поэтому заявления про то что Intel специально оптимизирует компиляторы чтобы они показывали хорошие результаты в SPEC - мягко говоря необосновано. (читайте: нужно сослаться на что-то)
Для этого есть Octane и Sunspider. Но они показывают связку CPU+VM в первую очередь.
Для этого есть своя куча бенчмарков, да. Но в статье по ссылке некоторые из их прогоняли. И да, показывают связку CPU + VM, но это то что увидит большинство пользователей. Так что увы и ах, это важнее.
Тесты для микроконтроллеров, с которыми вы тут носитесь, ничего не показывают.
Я ношусь не с тестами для микроконтроллеров, а указываю на некорректные заявления человека и излишний карго-культ вокруг SPEC'а в первую очередь.
Если вы зайдёте в процессорный раздел ixbt и будете бряцать coremark-ом, вас… не поймут.
Вы так говорите, как будто на ixbt сидят такие люди с которыми об этом имеет смысл говорить. Простите за некоторый снобизм, но ixbt в текущем его состоянии даже как источник новостей не годится. Соответственно адекватных людей на форуме осталось крайне мало.
Вам. Забыл добавить ссылку. Но несложно найти это место поиском.
Тогда не вырывайте фразы из контекста, пожалуйста и не переходите на личности.
Я не могу написать отдельный пост, потому как могу комментить только 1 раз в день.
Я заметил сильно отрицательную карму, да.
Напомню, что этот тред начался с попытки оспорить заявления автора, который возвёл «микроархитектурную скорость» в абсолют(с)
Да, я помню.
Я читал об этом процессоре в тот же день как появился его анонс. Под высокопроизводительным я подразумеваю текущий уровень лидеров рынка.
Уровень старого смартфонного 2-wide чипа Cortex-A73 не является таковым.Тогда вас явно незатруднит показать у какого смартфонного A73 пусть в синтетике, но 600 GFLOPS (SP). Жду пример. Не помню правда писали ли они какой конкретно бенчмарк использовали, так что хоть какой-то)
"Самое производительное RISC-V ядро в мире — это новое ядро P550 от SiFive. И они только сейчас достали уровень Cortex-A75."
Вы тред перечитайте. Сейчас вы пытаетесь мои слова притянуть к другому аргументу. Там был отдельный момент, где человеку пытались доказать (автор статьи и я потом его поддержал), что OoO ядро уровня Cortex A57 сделать не сложно. Вот отсюда и пример.
Сколько нам открытий чудных…
Вы подменяете корреляцию для конкретной железки в исследовании на казуацию. Там автор статьи в конце обосновывает почему это корреляция и в каких случаях так нельзя делать.
В общем читайте свои же пруфы целиком, пожалуйста.
От того, что SPEC имеет Bzip2 и GCC, а GB имеет LZMA и Clang особо ничего не меняется.
Читайте состав бенчмарков (обоих) целиком. И учтите пару моментов про GB:
Он работает крайне недолго (минуты, а не часы)
Его нельзя оптимизировать в отличии от SPECа (отсюда кстати вполне очевидный вывод - сравнивать с тем, что заявляет вендор - нельзя, потому что вендор всегда применяет максимум оптимизаций, какие смог найти и прменить)
В GB есть тесты, которые умеют использовать аппаратные блоки (то же шифрование, например), в отличии от SPECа.
Результаты GB получены в неизвестных условиях.
Для этого существует статистика.
Если есть тысяча корректных результатов и несколько фейковых, то эти фейки легко отбрасываются.Когда у тебя буквально сотни и тысячи результатов с разбросом в десятки процентов (как это на популярных системах) - какой из них будет корректный? А что делать с тем, что ты в принципе не знаешь какой из результатов на сайте проведен в каких условиях? Кто-то прогонит бенчмарк в холодильнике, кто-то в пустыне и получит два разных числа. У кого-то параллельно будет крутиться какая-нибудь штука и жрать ресурсы и тоже получится кривой результат. Исследование результатов GB с целью выбора наиболее характерного - это отдельная тема и возможна на больших выборках, и то с некоторыми допущениями.
И не поймите меня неправильно - GB достаточно разумный бенчмарк, но у него есть свои области применимости и его результатам стоит верить либо когда авторы публикуют методологию, либо когда ты сам проводишь тестирования и знаешь хорошол среду. Во всех остальных случаях - слишком много мест где можно сделать не так и получить искаженные результаты.
GCC это один из тестов SPEC.
Да, только вот Ваша фраза "Куда уж компилятору GCC до такой сложной задачи!" не вяжется с утверждениями про spec.
Но я рад что вы наконец начали читать о бенчмарках, о которых говорите.
antag
05.10.2021 13:20+1Есть Alibaba XT910 - который они правда сравнивают с Cortex-A73, но он практически везде показывает результаты лучше, на десятки процентов.
Нет. Вот прямая цитата из статьи про XT-910:
We have run the SPECInt2006 benchmark. SPECInt2006 uses very large programs that frequently incur L2 cache misses. It factors in core performance, cache size, cache miss, DDR latency, etc., thereby providing a comprehensive evaluation on a CPU system. The performance of XT-910 is 6.11 SPECInt/GHz, which is 10% lower than the 6.75 SPECInt/GHz delivered by Cortex-A73
Тут хорошо видно и приросты A73 относительно A57, и саму производительность XT-910. Они всего лишь на уровне A57:
6.11 SPECInt/GHz - XT-910 - в статье
6.75 SPECInt/GHz - Cortex-A73 - в статье
6.13 SPECInt/GHz - Cortex-A57 - это реальные тесты Байкала.
Civil
05.10.2021 13:48Нет. Вот прямая цитата из статьи про XT-910:
Смотрите на слайды по приведенной мной ссылке, там EEMBC, nBench и производительность в плавучке.
antag
05.10.2021 14:15Там на слайде NBench A73 выиграл в среднем. Например, там есть нагрузка, где A73 выиграл у xt-910 в 1.6 раза.
EEMBC и Coremark - это мелкие нагрузки.
Нагрузки Spec 2006 показательнее, а там xt-910 проиграл. И так мы знаем, что xt-910 получился на уровне A57 в итоге - 6.11 SPECInt/GHz.
Выводы.
Крупная компания Alibaba спроектировала RISC-V ядро класса A57. Российские разработчики тоже смогут сделать такое ядро когда-нибудь в будущем. Но ядро Эльбруса уже производительнее этого уровня.
Armmaster Автор
04.10.2021 15:44И вот вам разница в 1.62 раза, а не в 3.
Вы постоянно занимаетесь манипуляцией цифр, в итоге получается каша. Мы же договорились - сравниваем однопоточный перф, каков там потенциал. Для этого я в прошлой статье приводил пример - AMD EPYC 72F3 в 8-ми ядерной конфигурации ( как у Эльбрус-8СВ).
Там для fp : 126 / 8 / 3.7 = 4,26 .
В итоге 4.26 / 1.38 = 3.09 раз
Иначе возвращаемся к разговорам о количестве ядер, термопакете и итоговой суммарной производительности и т.д.
Не будет. Серверный EPYC 7763 имеет те же 2450 MHz базовой частоты
3.7 для EPYC 72F3 как я написал выше
Компания ARM разрабатывает ядра более 20 лет. И они в итоге сделали Cortex-A57 для Байкала
Компания ARM 20 лет делает широченную линейку мобильных чипов. Cortex-A57 это опять-таки мобильный чип, который какая-то команда внутри Arm сделала за пару лет под нужны мобильного рынка, а не для Байкала
Примерно на 30% на одинаковой частоте.
Нет, ядра Syntacore слабее, чем A57.
Российским разработчикам RISC-V ядер очень далеко до этого уровня
В итоге российские разработчики в лучшем случае только через несколько лет и несколько итераций потенциально смогут выйти на уровень A75
Давайте подождём немного и всё увидим. Вы плохо воспринимаете те аргументы, которые я привожу, тогда уж проще дождаться готовых чипов и всё увидеть.
Но Эльбрус уже сейчас выше этого уровня по производительности FP на ядре
Выше Cortex-A75? Сомневаюсь. Опять-таки, мы это скоро всё увидим
antag
04.10.2021 16:25+1Для этого я в прошлой статье приводил пример - AMD EPYC 72F3 в 8-ми ядерной конфигурации ( как у Эльбрус-8СВ).
Там для fp : 126 / 8 / 3.7 = 4,26 .
Сдался вам этот 72F3, который никто не покупает. Epyc 72F3 - это самый неудачный выбор для сравнений, который сильно искажает любой анализ производительности.
В базе Spec есть всем хорошо известный 8-ядерный процессор i9-9900K:
43.5 / 8 cores / 3.600 Mhz = 1.51
Эльбрус-8СВ = 1.38
Разница получается только 10%.
Новый процессор Эльбрус-16С наберет примерно 44, а значит будет равен i9-9900K и по абсолютным цифрам в том Spec CPU2017 FP.
Выше Cortex-A75? Сомневаюсь. Опять-таки, мы это скоро всё увидим
Эльбрус в 2 раза выиграл на FP у A57.
Ядро A75 не выиграет в 2 раза у ядра A57 на FP, а выиграет 30%.
Ядер A75 будет в 3 раза больше, чем у Эльбруса. Но сами ядра A75 на FP значительно слабее.
Armmaster Автор
04.10.2021 16:54+1Ядро A75 не выиграет в 2 раза у ядра A57 на FP, а выиграет 30%.
Но сами ядра A75 на FP значительно слабее
Это всё утверждения сомнительной достоверности. Arm утверждает, что только переход с A57 на A72 даёт +26% на fp, правда не конкретизируя, это SpecFP CPU2017 или что-то другое. Если переход на A73 и A75 даёт по 20% каждый, например, то это уже 2.2 раза только по архитектурной скорости. Плюс частота. Так что ядра A75 могут оказать не то что значительно слабее, а вообще сильнее Эльбруса.
Сдался вам этот 72F3, который никто не покупает. Epyc 72F3 - это самый неудачный выбор для сравнений, который сильно искажает любой анализ производительности
Самый неудачный для Эльбруса )).
И действительно, какой этот Epyc 72F3 плохой, его даже никто не покупает. То ли дело Э8СВ, как горячие пирожки расхватывают!
checkpoint
05.10.2021 03:51В итоге российские разработчики в лучшем случае только через несколько лет и несколько итераций потенциально смогут выйти на уровень A75 по производительности.
Вполне не плохой результат. При этом разработчики не будут находится в полном вакууме, как это происходить сейчас с Эльбрусом.
Но Эльбрус уже сейчас выше этого уровня по производительности FP на ядре.
Только не понятно зачем нужно это высокопроизводительное FP на серварах СХД, СУБД или Web серверах, а так же на десктопах и ноутбуках с офисным пакетом.
Civil
04.10.2021 13:41-3Ядро Эльбрус-8СВ производительнее ядра Cortex-A57. А частоты у них совпадают на одинаковом техпроцессе.
Строго говоря не везде. Если посмотреть по тем тестам, то тот же 7zip - не очень отличается, время в блендере (не смотря на превосходство в 2 с лишним раза в specfp) - тоже, бенчмарки в JS вообще на Эльбрусе в разы хуже. А если посмотреть на соседние статьи то в интерпретируемых языках на Эльбрусе все совсем печально.
Так что я бы не делал таких строгих заявлений.
А частоты у них совпадают на одинаковом техпроцессе.
Строго говоря нет, потому что были другие процессоры на A57 на 28нм, которые работали на частотах в районе 2 ГГц (конкретно Opteron A1170), поэтому некорректно обобщать результаты Байкала на всю микроархитектуру.
antag
04.10.2021 15:58Строго говоря нет, потому что были другие процессоры на A57 на 28нм, которые работали на частотах в районе 2 ГГц (конкретно Opteron A1170)
A1170 работал с повышенным напряжением. И поэтому там было 2.0 GHz.
У Байкал-М и Эльбрус-8СВ примерно одинаковое низкое напряжение на ядрах. И поэтому можно сравнивать их частоты.
Это же касается A75 и Эльбрус-16С на 16 нм. На схожих напряжениях работы получается примерно одинаковые частоты у них.
поэтому некорректно обобщать результаты Байкала на всю микроархитектуру.
Корректно. Все российские разработчики примерно одинаково упираются в низкую частоту. И многие иностранные разработчики тоже. Так ядро A75 у Qualcomm работало до 3.0 GHz, но Mediatek клепает свои массовые процессоры Helio P65/G70/G80/G85 на ядрах A75 на 2.0 GHz, как и Байкал-S. Значит это некий оптимальный режим для нормального (низкого) потребления этого ядра на техпроцессах 12-16 нм.
Civil
04.10.2021 16:49A1170 работал с повышенным напряжением. И поэтому там было 2.0 GHz.
Какие именно напряжения у A1170, у Байкала-М1 и у Эльбруса-8СВ? Пожалуйста со ссылочками на источники.
Но даже так - это никоим образом не опровергает довод. Есть пример процессора, который в рамках схожего TDP (32 Вт у А1170) работал на частотах порядка 2 ГГц. Есть примеры мобильных процессоров на А57, работавших на 1.7-1.9 ГГц. Ваше заявление про "1.5 это предел" - на проходит проверку на практике.
Это же касается A75 и Эльбрус-16С на 16 нм. На схожих напряжениях работы получается примерно одинаковые частоты у них.
Точно такой же вопрос - какие напряжения у 16С (одно или несколько, не знаю как уж там по архитектуре). Давайте Вы приведете источники, а потом посмотрим.
Так ядро A75 у Qualcomm работало до 3.0 GHz, но Mediatek клепает свои массовые процессоры Helio P65/G70/G80/G85 на ядрах A75 на 2.0 GHz, как и Байкал-S. Значит это некий оптимальный режим для нормального (низкого) потребления этого ядра на техпроцессах 12-16 нм.
Строго говоря в разгноворе выше не имеет значения что и почему делает mediatek.
Но в целом намекну - посмотрите на TDP топового снапдрагона на A75 и на TDP топового медиатека на A75. В этом и будет ответ.
antag
04.10.2021 21:190,8 В-0.9 В для 2.0 GHz на 16 нм у Байкал / Эльбрус по официальным картинкам.
0.95 В для 1.5 GHz на 28 нм у Байкал / Эльбрус
У А1170 напряжение было выше для частоты 2.0 GHz. TDP там совпадает из-за отсутствия GPU, который есть у Байкал-М. Без GPU у байкала TDP будет меньше, чем у А1170.
Civil
05.10.2021 00:18У А1170 напряжение было выше для частоты 2.0 GHz
Я подожду ссылок с чиселками, чтобы убедиться. На картинки про Байкал и Эльбрус - тоже. Без ссылок и чисел, кажется, говорить не о чем (тем более вторую часть вы снова проигнорировали).
antag
05.10.2021 10:19Я подожду ссылок с чиселками, чтобы убедиться. На картинки про Байкал и Эльбрус - тоже.
Напряжение ядер Байкала есть в их pdf - 0.95 В.
Напряжение 1.0В для Эльбрус-8СВ тут
Но в других источниках есть и про 0.9 В у Эльбрус-8СВ. Вероятно разные экземпляры отличаются по качеству, и поэтому могут завышать до 1.0В, чтобы добиться стабильности.
Напряжение ядер A57 и частоты есть тут:
https://www.anandtech.com/show/9330/exynos-7420-deep-dive
Где-то были графики и для других техпроцессов. Для байкаловского напряжения 0.95В там и должно быть 1.5 GHz на 28 нм.
Civil
05.10.2021 10:37Но в других источниках есть и про 0.9 В у Эльбрус-8СВ. Вероятно разные экземпляры отличаются по качеству, и поэтому могут завышать до 1.0В, чтобы добиться стабильности.
Я подожду пока вы приведете ссылку где это будет объяснено. Пока буду довольствоваться ссылкой выше.
Ссылку на pdf байкала все еще жду.
Напряжение ядер A57 и частоты есть тут:
Там есть для Exynos 5433, но не для A1170 о котором речь. К тому же для самсунговского 28нм техпроцесса, который считается хуже чем TSMC 28nm (в целом считается что самсунговские техпроцессы заметно хуже по ряду показателей чем аналогичные нанометры на TSMC).
Где-то были графики и для других техпроцессов. Для байкаловского напряжения 0.95В там и должно быть 1.5 GHz на 28 нм.
Я предпочту все еще подождать пока вы ссылку найдете и принесете. А то простите, но я вам на слово не верю (слишком много попыток манипуляции данными с вашей стороны тут было).
antag
05.10.2021 10:54+1https://www.baikalelectronics.ru/upload/iblock/152/BE_M1000-Preliminary-Datasheet-ENG.pdf
Core supply VDD 0.95 ± 5%
Про Эльбрус-8СВ есть тут:
http://www.mcst.ru/files/60868d/06dece/61386c/f5f2c1/bocharov_n.a._zuev_a.g._slavin_o.a._proizvoditelnost_mikroprotsessora_elbrus-8sv_dlya_resheniya_zadach_tehnicheskogo_zreniya_v_usloviyah_ogranichenij_energopotrebleniya_.pdf
Номинальное напряжение микропроцессора составляет 0.9 В. В данной работе на тестируемом устройстве напряжение было повышено до 1.02 В, с целью более стабильной работы при изменении параметров.
К тому же для самсунговского 28нм техпроцесса, который считается хуже чем TSMC 28nm (в целом считается что самсунговские техпроцессы заметно хуже по ряду показателей чем аналогичные нанометры на TSMC).
Нет. там график для Samsung-14 нм - Exynos 7420.
Даже такой новый техпроцесс не позволил поднять выше 2.1 GHz даже с высоким напряжением 1.15 В. На других техпроцессах будут аналогичные графики.
https://www.anandtech.com/show/8718/the-samsung-galaxy-note-4-exynos-review/6
We're averaging 1175mV at 1800MHz across the various speed bins, and reaching up to 1262mV on the worst speed bins at 1.9GHz.
Civil
05.10.2021 11:33http://www.mcst.ru/files/60868d/06dece/61386c/f5f2c1/bocharov_n.a._zuev_a.g._slavin_o.a._proizvoditelnost_mikroprotsessora_elbrus-8sv_dlya_resheniya_zadach_tehnicheskogo_zreniya_v_usloviyah_ogranichenij_energopotrebleniya_.pdf
Для меня характеристики по прошлой ссылке выглядят более официально, чем отрывок из какой-то статьи непонятно когда писавшийся.
Нет. там график для Samsung-14 нм - Exynos 7420.
Я повторю еще раз - вы заявили что для A1170 оно больше. Приведите цифру с источником. Не надо, пожалуйста, пихать сюда Smasung'овские процессоры.
antag
05.10.2021 12:18Я повторю еще раз - вы заявили что для A1170 оно больше. Приведите цифру с источником. Не надо, пожалуйста, пихать сюда Smasung'овские процессоры.
Изначально речь была про то, что A57 якобы способен на более высокие частоты, чем 1500.
Вот те ссылки и показывают, что даже в смартфонах, где важен каждый Вт, потребовалось 1175mV для 1800MHz.
1175mV - это на 23% больше чем 0.95V у Байкала.
1800MHz - это на 20% больше чем 1500 Mhz.
Поэтому там все логично, и никаких противоречий нет. Частота в этом отрезке зависит почти линейно от напряжения.
Некоторые производители A57 захотели высокую частоту, и задрали напряжение. Байкал не захотел задирать напряжение, и поэтому остался на 1500 MHz.
Сам A1170 тут уже не играет большой роли для анализа частоты A57. A1170 выпускали мелкими партиями, и про него труднее найти информацию. Смартфоны на A57 выпускали миллионами. Они показательнее. Никто бы не стал завышать напряжение на ядре без веской причины. Но без повышения напряжения там нет высокой частоты.
Civil
05.10.2021 13:15Изначально речь была про то, что A57 якобы способен на более высокие частоты, чем 1500.
Ну так способен? Способен. Вот A1170 на 2 ГГц работает. Кажется тезис доказан.
Вот те ссылки и показывают, что даже в смартфонах, где важен каждый Вт, потребовалось 1175mV для 1800MHz.
Вы приводите ссылки на другие процессора с другим техпроцессом (а я специально выбирал наиболее высокие частоты для 28 nm TSMC).
Сам A1170 тут уже не играет большой роли для анализа частоты A57.
Вы сами сказали, цитирую:
A1170 работал с повышенным напряжением.
Я и поинтересовался с каким конкретно. Раз вы сделали такое заявление, значит у вас есть точная цифра. Иначе заявление сделано неправомерно (в таком ультимативном ключе). Я по-прежнему жду от Вас точную информацию на ваше утверждение о повышенном напряжении. Притом что то что я сказал примерно там же что-то в духе "да какая разница, вот есть примеры где работает на более высокой частоте, этого достаточно чтобы показать что может" - вы проигнорировали. Так что считаю что с этим тезисом вы согласны.
Armmaster Автор
03.10.2021 16:46Вот когда в Эльбрусе будет 80 ядер и 3Ггц, тогда и поговорим. А адекватные сравнения про 3-4 раза тут https://habr.com/ru/post/576420/
antag
03.10.2021 19:42+3Итак есть 2 утверждения:
1) среднегеометрическая int+fp "микроархитектурная скорость" у Эльбрус-8СВ выше, чем Ampere Altra.
2) ваше утверждение: микроархитектурная скорость на Эльбрусе, рассчитанный по данным запусков на Spec CPU2017 в 3-4 раза уступает современным RISC/CISC процессорам.
И вывод из этих двух "верных" утверждений: Ampere Altra по этой "микроархитектурной скорости" тоже уступает современным процессорам в 3-4 раза. Получился абсурд. Зачем-то сделали процессоры на Neoverse N1, отстающие в 4 раза в пересчете на ядро. Причем ядер там тоже обычно не так много: 64 у Graviton2, как и у AMD Epyc. Тогда нафиг сдался этот Neoverse, проигрывающий в 4 раза. Надо тоже закопать, как и Эльбрус.
Когда вы выбрали EPYC 72F3 в качестве примера продемонстрировать "микроархитектурную скорость", вы заложили мину, которая сильно искажала все выводы. EPYC 72F3 - это гипертрофированный 8-ядерник, которой фактически содержит 8 мощных одноядерных процессоров-кристаллов в одном корпусе. И еще там есть второй поток на каждом ядре Epyc, которого нет на ARM и на Эльбрусе.
Поэтому для анализа производительности Эльбруса надо брать более близкие альтернативы на ARM: Kunpeng или Ampere Altra. Это вполне современные OoO процессоры. Но значимого преимущества по вашей "микроархитектурной скорости" int+fp на Spec CPU2017 над Эльбрусом у Kunpeng и Altra нет.
Вместо Эльбруса можно разработать свое RISC ядро. Но это потенциальное "свое" будущее RISC-ядро все равно проиграет ядру Neoverse-N1, которое на данный момент является некоторым эталоном высокого качества разработки. И такое качественное ядро Neoverse-N1 очень трудно превзойти самостоятельно. Например, даже большая Huawei не смогла выдать такую производительность в своих ядрах Kunpeng, как у Neoverse N1.
Так если ядро Эльбруса в среднем в Spec CPU2017 на уровне ядер Kunpeng/Nеoverse, то какова вероятность, что своя альтернативная разработка ядра будет выше этого уровня, а значит выше уровня Neoverse и Kunpeng?
creker
03.10.2021 20:10+4Тогда нафиг сдался этот Neoverse, проигрывающий в 4 раза. Надо тоже закопать, как и Эльбрус.
Вот поэтому не надо страдать херней и делить все цифры на мегагерцы. Частоты процессора это часть его микроархитектуры (и вроде как устройство пайплайна и влияет на то, на каких максимальных частотах может работать процессор). Какие-то процессоры имеют высокий IPC, но относительно низкие частоты — амд. Какие-то имеют ниже IPC, но выше частоты — интел. По итогу, получаются эквивалентные решения. Помимо spec cpu у нас есть тесты на реальных приложениях, где altra вполне себе тягается с топовыми эпиками. Так что ответ, зачем его выпускали, прост — это топовый серверный процессор на сегодня. Эльбрус здесь никаким местом не конкурент, потому что всем похер будет на вашу манипуляцию с цифрами. Эпики и альтры имеют по 64+ ядра на 3+ГГц. Эльбрус такого не может даже близко. И даже если в него запихают столько ядер, частот таких все равно не будет. Дальше выбор, либо растить частоты, либо поднимать IPC. В статье речь как раз о том, как поднять IPC. И это еще вопрос, что придется для этого с частотами делать.antag
03.10.2021 20:36+1Вот поэтому не надо страдать херней и делить все цифры на мегагерцы.
В тех статьях для анализа предложили использвать количественный показатель - "микроархитектурная скорость". А я лишь проверил этот показатель на двух хороших современных процессорах: Kunpeng и Altra. И оказалась, что не так все плохо у ядер Эльбруса на фоне тех ядер Kunpeng и Neoverse.
И даже если в него запихают столько ядер, частот таких все равно не будет.
Насчет частот есть реальные примеры.
Лучший российский ARM Cortex - это Байкал-М на 1.5 GHz, как и Эльбрус-8СВ на одинаковом техпроцессе 28 нм. Так частоты там совпали. Аналогично для Байкал-S и Эльбрус-16С на одинаковом техпроцессе 16 нм частоты снова совпали - 2 GHz. Оказалось, что ядра Cortex в российских процессорах выдают те же частоты, что и Эльбрусы.
Допустим, что на RISC разработают свое "мощное" ядро. Будет ли оно выигрывать по частоте и производительности у ядра Cortex-A75 в Байкал-S?
Не будет. Любая самостоятельная российская разработка будет проигрывать ядру Cortex-A75 почти по любому показателю на одинаковом техпроцессе. А ядро Эльбруса за счет fp нагрузок не будет хуже, чем ядро Cortex-A75 в среднем на Spec CPU2017.
Для сравнения реальных альтернатив Эльбрусу не нужно рассматривать "мифическую" производительность Epyc. А нужно рассматривать производительность ядер Kunpeng, Cortex-A57, Cortex-A75, Neоverse. Такие ядра можно купить, как делает Байкал, или можно попытаться повторить самостоятельной разработкой ядра. Но самостоятельно прыгнуть выше уровня тех ядер Cortex и Neоverse совсем нереально.
Armmaster Автор
03.10.2021 21:27Байкал-S уже на подходе. Мне кажется, раз вы упорно стоите на своей точке зрения и не хотите принимать те выкладки, которые я здесь привожу, то просто стоит дождаться результатов Байкал-S. На том спор, как мне кажется, будет закончен.
Armmaster Автор
03.10.2021 21:24Вы, похоже, фундаментально не понимаете того, как устроен современный ОоО процессор.
Дело в том, что красота ОоО в том числе заключается, что он очень гибкий. Т.е. если хотите - делаете энергоэффективный проц по перфу не сильно мощный, либо фигачите топовую архитектуру выжимая максимум перфа и жертвуя пауэром. Всё зависит от вашей конечной цели.
Ampere Altra имеет определённую нишу для использования. Поэтому они хотели иметь побольше ядер с достаточным перфом. А дальше начались компромиссы и укладывания в теплопакет. Им не нужна особо плавучка, вот они её и подрезали. Зато вытянули частоту повыше, посчитав, что это важнее. По итогу у них 80 ядер на 7нм, тогда как у Эльбруса-32С на том же процессе 32 ядра, потому что больше не влезет в теплопакет.
Поэтому сравнивать надо по возможности одинаковое количество ядер и примерно одинаковый теплопакет. Потому что в ОоО это всё перетекает из одного в другое. Можно урезать количество ядер но накачать ОоО, увеличив его микроархитектурную скорость в 2-3 раза, например.
Поэтому как раз сравнение EPYC с Эльбрусом куда более верное, если мы хотим оценить предел микроархитектурной скорости. Оба эти процессора назначены вытягивать максимальный перф на ядро. И результат мы видим - Эльбрус проигрывает в 3-4 раза. Это же всё для упрощения понимания и проблемы по существу описаны.
Иначе мы можем переключиться на прямое сравнение перфа, где у Ampere Altra 306 int rate и 220 fp rate. А у Эльбрус-8СВ 10.68 int rate и 16.55 fp rate. А у гипотетического Эльбрус-32С на 7нм и пусть даже на 2.5Ггц (что ещё сомнительно) будет 71 int rate и 110 fp rate максимум. А реально меньше, т.к. с ростом частоты и ядер rate линейно не скалируется. Ну и о чём тут разговаривать.
{kind=link}
{kind=link}

ignat99
03.10.2021 14:06-2Есть хороший выход из этой ситуации. Не просто выложить весь проект (хардварный дизайн) всех чипов Эльбрус, но и сделать это максимально открыто. Предложив проект в виде стандартных решений под конкретные FPGA. Возможно, только тогда архитектура процессоров Эльбрус сможет конкурировать с ядрами RISC-V. Тоесть сделать открытыми и бесплатными все IP блоки разработанные для процессоров Эльбрус.
Но время, скорее всего, уже упущено.Armmaster Автор
03.10.2021 16:46-1Это всё не поможет, потому что gp cpu на базе Vliw никому не нужен

alex-open-plc
03.10.2021 14:46-6Моё, глубоко ошибочное мнение: процессоров эльбрус делать как можно больше! Ими можно вместо плитки отделывать санузлы.
checkpoint
03.10.2021 22:26Скажем так, если цена процессора Эльбрус опустится до цены кафельной плитки, то почем бы не использовать его по прямому назначению, даже при всех существующих проблемах ?
Но засада в том, что цена столь сложного изделия не может опуститься так низко (во всяком случае, предпосылок к этом нет никаких), что при прочих равных делает его применение бессмысленным, а потенциал улучшений либо исчерпан, либо упёрса в непреодолимую стену высокой стоимости и низкой вероятности на успех.

vadik_lyutiy
03.10.2021 15:02+2То что branch predictor и hw prefetch не помогут увеличить пиковые цифры на спеках для Эльбруса не совсем верно. Predictor поможет сократить задержку от выработки условия до перехода, а это прилично стоит. Сделать SW prefetch для чего-то более сложного, чем постоянное смещение врятли получится. Аппаратный же prefetch может намного более сложные случаи обрабатывать.
Armmaster Автор
03.10.2021 19:08И да, и нет.
Да, потому что действительно hw prefetcher имеет бОльший потенциал чем sw, а branch predictor (хороший) развязывает руки во многих местах.
Но мы с тобой прекрасно знаем, как вылизывались оптимизации для спеков на ecf_opt. Мне сложно представить, что там, где из-за префетча были реально ощутимые проблемы, там не докрутили sw prefetch до чего-то вменяемого. А в случае branch predictor'а на запусках с профилем и с учётом предиктного исполнения, опять-таки, вряд ли там можно что-то сильно улучшить.
Плюс в случае Эльбруса возникает много вопросов, как дружить тот же prefetcher со спекулятивными и предикатными лоадами, DAM'ом. Боюсь, там всё может оказаться так, что SW prefetch ещё и лучше на спеках окажется. Для branch predictor'а логику предикатного исполнения тоже надо будет как-то адаптировать. В общем, тут много нюансов возникает, о которых в академических статьях не прочитаешь.
В общем, как мне кажется, по итогу на Spec'ах prefetcher и branch predictor никак существенно цифры не поменяют.
vadik_lyutiy
03.10.2021 22:59А я вот вообще не помню, чтобы в языковом эльбрусовском компиляторе был софтовый prefetch(за исключением фиксированного смещения, которое там специально делается). И я почти уверен, что для любой архитектуры, софтварно сделать prefetch(более сложный как в железках) не получится, так как будет слишком много операций дополнительных. При этом на спеках точно есть какие-то сложные паттерны с которыми hw справляется.
По поводу prediction, тут менее очевидно. Но как минимум задержка от сравнения до перехода в 0 тактов процентов 5 на спеках целых даст.
Armmaster Автор
03.10.2021 23:08В общем, про префетч тут сложно однозначно что-то сказать. Посмотрим тогда.
Задержка от сравнения до перехода это всё же не относится к prediction, хотя тот ещё косячок. Кстати, интересно, может как раз введение prediction поможет этот косяк как-то поправить))
vadik_lyutiy
03.10.2021 23:14Найти чиселку сколько на x86 даёт prefetch не очень понятно как. В статьях врятли будет много инфы, там скорее отдельный алгоритм prefetch на отдельных задачах.
Prediction не prediction, это вопрос философский, но, на мой взгляд, абсолютно точно после этого выработку условия и переход можно ставить в один такт.
bircoph
03.10.2021 18:27+1Вы тихонько умалчиваете про одну архитектурную проблему OoO: это Spectre. В то время как Meltdown — это грубая ошибка, которую можно устранить правкой микроархитектуры или заткнуть микрокодом, то класс проблем Spectre принципиально неустраним до тех пор, пока существует OoO, по крайней мерез без кеша со строгим контролем прав доступа перед проверкой на хит (мне неизвестно об оборудовании, реализующем подобный контроль, но теоретически это возможно, хотя сопутствующие накладные расходы могут убить все преимущества ОоО, не говоря уже о сложности реализации соответствующего кода со стороны ядра ОС).
Так вот, если не делать mitigations=off, а включить все средства защиты от всех известных разновидностей Spectre на всех уровнях — микрокод процессора, ядро ОС, опции компиляции всех приложений (ну те же выключенные трамплины), то потери производительности на реальных приложениях достигнут несколько раз. Вот и получим, что Эльбрусы хуже не в 5-8 раз, а в 2-3 раза, что, как говорится, две большие разницы.
И на каждый заткнутый вариант Spectre найдётся v5, v10, v100500, который тоже придётся затыкать. Так что единственный практический путь получения безопасных вычислений — это отказ от OoO. В этом смысле меня глубоко печалит, что на Эльбрусах будет добавлен динамический предсказатель ветвления, что помножит на ноль их и без того не идеальное преимущество в плане безопасности.
Вот как раз на числодробилках и вычислительных узлах HPC и OoO можно оставить, и вообще mitigations=off сделать, т.к. конкретные узлы в заданный момент времени обычно и так эксклюзивны для конкретной задачи.
На практике считаю, что безопасные вычисления возможны только при отсутствиии OoO в частности и совместных кешей в общем случае. Хорошо бы делать CPU с такими защищёнными ядрами (а-ля ранние Intel Atom без branch predictor и HTT) для ядра, ssh и иных задач, где безопасность важнее всего и большей частью ядер, сделанных под числодробилки, кодеки и прочую мультимедию, где скорость важнее безопасности. Думаю, что будущее именно за таким подходом, но это потребует принципиальной микроархитектурной переработки всех существующих решений, по крайней мере сколь либо широко применяемых.
Тем более, что HPC вычисления, как правило, сопровождают достаточно квалифицированные специалисты, которые понимают специфику своих вычислений и по природе своей работы должны углубляться в особенности процессора и могут адаптировать программу под Эльбрус.
Спасибо, насмешили. Как человек, немало лет проработавший в HPC (и как пользователь, и как администратор и архитектор подобных систем) могу сказать, что почти всегда это не так. Среднестатистический научный софт, который гоняют на HPC, написан из рук вон плохо, по принципу, чтоб хоть как-то считало и работало. Да, есть примеры, когда софт тщательно продумывается и прорабатывается под возможности конкретного оборудования, но это редкие случаи. И более важную роль играет не оптимизация под CPU, а оптимизация под interconnect: минимизация latency на IB, минимизация блокировок MPI, асинхронная работа, решение проблем ранжирования, параллельного I/O и т.п.. Конечно, использование всех особенностей CPU, помимо банальной пересборки с -march=native, тоже важно, но на вторых ролях по сравнению с проблемами I/O и межузлового взаимодействия.
edo1h
03.10.2021 19:00Вы тихонько умалчиваете про одну архитектурную проблему OoO: это Spectre
в общем случае OoO не равно спекулятивному исполнению.
на мой непрофессиональный взгляд, если наша цель получить максимальную суммарную производительность, то можно обойтись без спекулятивного исполнения, SMT вполне сможет загрузить простаивающие ядра.
но вот максимальную однопоточную производительность, да, без спекулятивного исполнения не получить.bircoph
03.10.2021 22:04+1в общем случае OoO не равно спекулятивному исполнению.
В теории — возможно, почему бы и нет. На практике — равно. Если я не прав, приведите мне примеры OoO без run-time спекулятивности; желательно реально эксплуатируемые, т.е. за пределами инженерных образцов.
SMT вполне сможет загрузить простаивающие ядра.
Во-первых, SMT свойственны аналогичные Spectre проблемы с безопасностью: посмотрите на CVE по SMT, которые были есть и будут. Но SMT легко отключить, поэтому особой проблемой это не является.
Во-вторых, сможет или нет — зависит от задачи. Для полностью асинхронных задач, которые при этом не будут слишком толкаться по кешу данных, да поможет и хорошо. Но в HPC большинство MPI/OpenMP или гибридных задач синхронны — это значит, что N потоков будут работать со скоростью наиболее медленного из них, так что SMT лишь вредит в таких ситуациях и его либо отключают, либо делают CPU-affinity на физические ядра.
Armmaster Автор
03.10.2021 19:26Вы тихонько умалчиваете про одну архитектурную проблему OoO: это Spectre
Чувствую, придётся ещё отдельную статью про "безопасность" Эльбрусов писать.
Эльбрус идейно имеет точно такие же проблемы со спекулятивным исполнением, как и любой OoO. Просто в ОоО операции переставляет и спекулятивно исполняет железо, а в Эльбрусе - компилятор. Если этого не делать, производительность Эльбруса упадёт ещё сильнее. Мы это всё в коментах к прошлой статье обсудили.
В этом смысле меня глубоко печалит, что на Эльбрусах будет добавлен динамический предсказатель ветвления
Потому и собираются добавлять, что ничего это не изменит принципиально.
И вообще, опасность всех этих Spectre/Meltdown сильно преувеличена. Практически никто не будет покупать железо в 2 раза более медленное, но зато более устойчивым к Spectre/Meltdown.
Как человек, немало лет проработавший в HPC (и как пользователь, и как администратор и архитектор подобных систем) могу сказать, что почти всегда это не так. Среднестатистический научный софт, который гоняют на HPC, написан из рук вон плохо, по принципу, чтоб хоть как-то считало и работало
Как человек, проанализировавший тонны кода из под разнообразного пользовательского софта, могу сказать, что вам просто не с чем сравнить. Так вот, в HPC ситуацию намного лучше, чем в среднем по индустрии.

N-Cube
03.10.2021 20:39+3Так вот, в HPC ситуацию намного лучше, чем в среднем по индустрии.
А я вот поддержу комментатора выше. Скажем, если кластерный софт на матлабе, так там все на eval будет, обёрнутых один в другой много-много раз, видимо, это так разработчики полиморфизм и объектность понимают. Из моего опыта - переписанный на питон с матлаба большой вычислительный пакет выполнил за несколько минут на моем ноутбуке вычисления, на которые раньше тратилось два дня на сервере с 96 ядрами. Да, точность результата я контролировал до 10 в -17 степени, то есть результат полностью идентичен. На си - кластерный софт обыкновенно пишет и читает большие бинарные файлы побайтово, и так далее. Имхо, лучший код написан на фортране - возможно, просто потому, что когда писали на фортране, вычислительные ресурсы были жестко ограничены.
bircoph
03.10.2021 22:46+1На си - кластерный софт обыкновенно пишет и читает большие бинарные файлы побайтово, и так далее.
Да, это больная тема. Но софт на фортране тоже так любит: я работал с чудом, которое при чтении каждого события открывает файлик, читает событие, закрывает файлик. Только вот длина каждого события разная, индекса нет, для чтения N-го события нужно прочитать предшествующие N-1. А файл несколько гигабайт. И таких файлов тысяч десять. И почему-то оно проседало на i/o. Вот прямо удивительное дело.
Имхо, лучший код написан на фортране - возможно, просто потому, что когда писали на фортране, вычислительные ресурсы были жестко ограничены.
Уже нет. В те далёкие годы, когда софт массово писался на фортране, никаких SIMD не было, MPI / OpenMP тоже (да, я знаю, в современном фортране они поддерживаются, но несколько криво). И вот такой старый фортрановский софт начинает сильно проигрывать оттого, что SIMD не использует (а gfortran не столь умён, чтоб везде его задействовать), да и в целом с распараллеливанием плохо. За счёт этого софт на C/C++ работает в целом лучше. А всевозможные питоны имеют под капотом модули, написанные на C или C++.
N-Cube
04.10.2021 15:15SIMD и OpenMP и на си требуют переписывания кода, порой, начиная с разработки новой архитектуры приложения. На фортране многомерные массивы есть и код легче читать, но я не знаю, работает ли на них векторизация. OpenMP и в фортране и на си используется, и работает, в отличие от уймы реализаций MPI, которые зачастую работоспособны только при подкладывании им древних MPI библиотек. Уйма старого кода на си и фортране вообще не собирается GCC версий 9 и выше, а только 8.3, так что ситуация идентичная - чтобы получить распараллеливание, векторизацию и вообще скомпилировать новыми компиляторами, надо заново писать.
bircoph
03.10.2021 22:39+3Просто в ОоО операции переставляет и спекулятивно исполняет железо, а в Эльбрусе - компилятор.
Вот именно. И в Эльбрусе эту гадость легко программно отключить где нужно. Вы же говорите, что там работали раньше, значит, man lcc читали и сами прекрасно всё знаете.
А вот на x86_64 спекулятивность просто так не отключить. Обновления микрокода в купе с обновлением gcc дают некоторые fence интринсики, но это полумера, к тому же, сложная и неудобная для практического применения. Передать флаги компилятору, как в lcc, намного проще.
И вообще, опасность всех этих Spectre/Meltdown сильно преувеличена.
Meltdown вообще позволяет извлекать любые данные из любых процессов. Spectre сложнее использовать, но ваш покорный слуга /etc/shadow обычным пользователем так вытаскивал интереса ради. Так что это очень серьёзный класс проблем, который нельзя игнорировать.
Как человек, проанализировавший тонны кода из под разнообразного пользовательского софта, могу сказать, что вам просто не с чем сравнить. Так вот, в HPC ситуацию намного лучше, чем в среднем по индустрии.
Давайте определимся про какой софт речь: проприетарный или свободный. Я уже около 20 лет работаю со свободным софтом, качество, конечно, самое разное, но в целом лучше, чем в свободном или хотя бы условно открытом HPC софте.
С проприетарным софтом я мало работал, но почти всё, что я видел было совершенно ужасно, наверное, даже хуже научного свободного софта. Есть рассказы от сотрудников крупных транснациональных IT компаний, что у них качественный проприетарный софт, но ни подтвердить, ни опровергнуть это я не могу.
Armmaster Автор
03.10.2021 23:19+1И в Эльбрусе эту гадость легко программно отключить где нужно
Тогда проигрыш по перфу будет 10х по сравнению с ОоО.
В общем, если это действительно будет важно, сделают процы с затычкой под такого рода атаки. И вообще, это очень глубокая тема. Я знаю про атаки, когда правильно дёргая нужные участки памяти в своём процессе меняли состояние битов на соседних линиях в DRAM. Но всё это не отменяет того факта, что людям нужны быстрые процессоры, и они готовы на такого рода проблемы закрыть глаза во многих случаях.
Давайте определимся про какой софт речь: проприетарный или свободный
И тот, и другой.
Но если честно, мне кажется это очень субъективный спор. Мне пару моих товарищей, работающих в HPC написали по этому поводу что "да, это верно!". Вы же сейчас утверждаете обратное. Но непонятно, каким образом тут можно доказать любую точку зрения. В конце концов, если вы правы, тогда у Эльбруса в HPC большие проблемы.
vadik_lyutiy
03.10.2021 23:17Более того, в Эльбрусе это софтварно управляется, и вместо того чтобы пытаться с бубном заставить x86 делать то что хочется, на Эльбрусе можно явно "попросить".
creker
03.10.2021 19:44+2Вы тихонько умалчиваете про одну архитектурную проблему OoO: это Spectre
А зачем про нее говорить? Насколько это реальный вектор атаки? В каких случаях требуется включать прямо все митигации? Об этих атаках в основном заботятся облачные провайдеры и может какие-то энтерпрайзы. У обоих процессорных вендоров есть разные средства запуска кода в изолированной среде. У облачных провайдеров наверняка полно средств на уровне гипервизора. Насколько это сказывается на реальных задачах можно погуглить databricks.com/blog/2018/01/13/meltdown-and-spectre-performance-impact-on-big-data-workloads-in-the-cloud.html Вычислительно интенсивная задача и падение всего несколько процентов в разных облаках. Какое-то катастрофическое падение производительности я помню только во внутренних тестах гугла, когда они на коленке патчили llvm, чтобы перекомпилировать софт с митигациями. Или в синтетике с ранними версиями митигаций.bircoph
03.10.2021 23:04+2Насколько это реальный вектор атаки?
Скажем так, практически реализуемый, /etc/shadow непривилегированным пользователем вытягивается на системе без каких-либо защит от spectre. Это сложная и кропотливая работа, для скрипт-кидди не подойдёт, но это реализуемо на практике.
В каких случаях требуется включать прямо все митигации?
Во всех, где важна безопасность и, например, возможна одновременная работа хотя бы двух процессов, один из которых недоверямый. Т.е. на выделенном HPC узле это не нужно, но даже на домашнем десктопе с браузером и javascript или аналогичном телефоне уже необходима. О серверах я вообще не говорю.
Вычислительно интенсивная задача и падение всего несколько процентов в разных облаках.
Вот в том-то и дело, что числодробилка. А вы возьмите сильно ветвящиеся алгоритмы или многочисленные форки и картина будет совсем иной.

lunacyrcus
04.10.2021 02:04-1На счет Spectre/Meltdown то я тоже считаю что их фактическая опасность сильно преувеличена.
Банально потому что если у злоумышленника уже имеется возможность эксплуатировать что-то из них, то это значит что он уже имеет доступ к системе (либо физический, либо удаленное исполнение кода на целевой машине или в целевой сети), а значит, уже может пытаться эксплоитить там что-угодно, не вдаваясь в настолько изощренные попытки.
YuriPanchul
Я не согласен, что предсказатель переходов нужно вылизывать годами. Есть хорошо описанные в статьях продвинутые предсказатели, например TAGE. Приспособить его к любому процессору можно за год, с полной отладкой и оптимизацией.
Armmaster Автор
При формулировании данного тезиса у меня была следующая мотивация:
Мне приходилось общаться с людьми из Интела, свзяанными с вопросами перфа и бранч предиктора, и они мне говорили, что в предсказатель вложено очень много сил и его имплементация сильно далеко ушла в деталях от того, что опубликовано в академических статьях.
Также мне довелось самому сильно погрузиться в особенности реализации и проблемы перфа блока аппаратного предсказателя одного достаточно продвинутого GP CPU, который делали опытные люди. Несмотря на то, что идея, стоящая за реализацией префетчера, на мой взгляд даже проще, чем логика бранч предиктора, в деталях там оказалось очень много нюансов, что по итогу приводило к деградациям на 30% даже на некоторых спеках. И наверное моя фраза была больше направлена именно в сторону префетчера (хотя думаю, что с бранч предиктором ситуация схожая)
В случае Эльбруса бранч предиктор придётся дружить с логикой предикатного исполнения, в том числе в компиляторе. Это усложняет задачу с точки зрения архитектуры всей программно-аппаратной системы.
В случае МЦСТ итерация выпуска процессора это несколько лет. Например, в случае Эльбрус 32С речь идёт о 5 годах. Т.е. если в первой итерации будут проблемы, то исправление и доведение до ума - это уже следующая итерация, т.е. ещё плюс пару-тройку лет. В итоге от текущего момента это легко уползает куда-то к 2030-ому году.
Armmaster Автор
аппаратного префетчера имелось ввиду