

«Если у вас есть сомнения, авария это или нет — то это авария!»
(с) Мудрость предков
Большие сбои в онлайн-проектах происходят редко. А в больших проектах — ещё реже. Конечно, чем сложнее система, тем выше вероятность ошибки. Один час простоя крупных систем, особенно соцсетей, обходится недёшево, и потому в больших проектах прикладывается очень много усилий по предотвращению аварий и снижению негативного эффекта для пользователей. Но иногда то ли звёзды складываются в особенную комбинацию, то ли закон Мёрфи обретает реальную силу, и большие аварии всё же происходят. В истории Одноклассников крупнейший сбой произошёл 4 апреля 2013 года: в течение трёх дней проект был целиком или частично неработоспособен. О том, что же тогда произошло, по каким причинам и как мы с этим боролись, будет наш рассказ.
1. Что произошло?
Однажды вечером система мониторинга зафиксировала незначительную проблему с одним из серверов. Для её устранения нужно было поправить шаблон конфигурации. Дежурный администратор обратился за помощью к коллеге, разработавшему этот шаблон. Оказалось, что нужно было лишь добавить одну небольшую строку кода, по образу и подобию предыдущих. Администратор внёс необходимые исправления и отправил файл в production.
Вскоре посыпались сообщения о сбоях на разных серверах, их количество быстро росло. Дежурные сразу подняли лог и предположили, что всё дело в изменённом шаблоне конфигурации. Естественно, изменения сразу попытались откатить, вернув первоначальную версию шаблона на серверы. Однако к тому времени отказали уже все Linux-машины, составлявшие тогда б?льшую часть серверного парка Одноклассников. Так начались самые долгие три дня.
Последующий анализ по горячим следам помог установить причину лавинообразного сбоя, парализовавшего все подсистемы.
- На тот момент мы использовали старую версию openSUSE и, как следствие, старую версию bash «из коробки». Забэкпортить необходимые нам изменения выглядело проще, чем обновляться на новую ветку (сейчас bash обновлён до новой ветки, что потребовало фиксить синтаксис некоторых системных и наших скриптов). В процессе бэкпортирования была допущена ошибка, которая проявила себя только при очередном изменении шаблона конфигурации, распространённого по всем серверам.
- Разработчик, создававший и тестировавший шаблон, работал в текстовом редакторе, который не добавляет автоматически в конце файла символ переноса строки.
- Но дежурный администратор правил файл шаблона в другом редакторе, который поместил этот символ в конец файла.
- Оказалось, что в нашей системе централизованного управления (CFEngine) присутствовал баг, из-за которого в редактируемый файл всегда добавляется символ переноса строки. В результате получились два символа переноса подряд — пустая строка в конце файла.
- В модифицированном нами коде bash оказался другой баг, из-за которого интерпретатор при обнаружении пустой строки в конце конфигурационного файла входил в бесконечный цикл и переставал отвечать на внешние команды.
Как вы знаете, командный интерпретатор используется в самых разных операциях, в том числе при выполнении служебных скриптов. Запускаемые на серверах процессы bash сразу зацикливались и стремительно поглощали доступные вычислительные ресурсы машин. В результате серверы быстро выходили на максимальную нагрузку. Но это было ещё полбеды. Дело в том, что bash использовался и системой централизованного управления. Поэтому перегруженные серверы вдобавок перестали отвечать на какие-либо внешние команды. Мы не могли на них залогиниться, и в течение очень короткого промежутка времени около 5 000 серверов перестали функционировать.
Вопросы для самопроверки:
Что вы будете делать, если откажет ваша система централизованного управления? А если при этом на сервера нельзя будет залогиниться?
2. Три дня восстановления
К сожалению, нельзя было восстановить работоспособность системы просто перезапустив серверы. Связано это с особенностями архитектуры портала.
2.1. Взаимосвязи подсистем
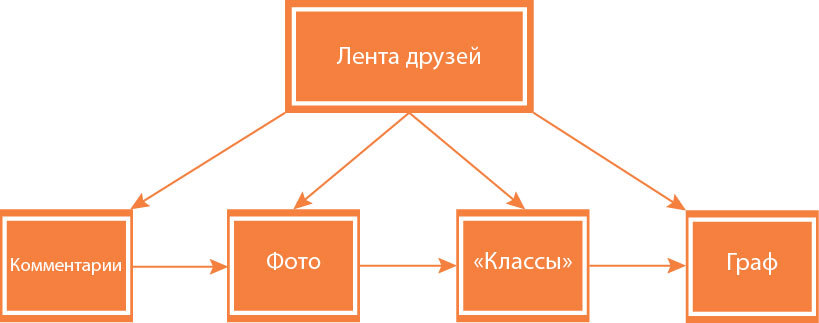
Одноклассники состоят из примерно 150 подсистем (различные базы данных, серверы бизнес-логики, кэши, графы, фронтэнды, системы конфигурации и т.д.). И работоспособность практически каждой подсистемы зависит от доступности других. Если хаотично перезапускать серверы, то можно нарушить работу не только одной конкретной подсистемы, но и множества других связанных с ней.
Пример связей между подсистемами:
Чем-то напоминает классику:
Дело в том, что при разработке и изменениях архитектуры проекта не закладывался сценарий, при котором единовременно может отказать весь кластер серверов. В коде некоторых подсистем не был предусмотрен механизм запуска и функционирования в условиях полной недоступности каких-то связанных компонентов. Предполагалось, что все системы будут работать хотя бы частично благодаря дублированию функционала и использованию резервных машин.
Вопросы для самопроверки:
Предусмотрен ли у вас механизм запуска сервисов в условиях неработоспособности всех или части взаимосвязанных подсистем?
2.2. Перезапуск серверов
Чтобы одновременно запустить основные подсистемы, на первых порах нужно было восстановить небольшое количество серверов: служебных и необходимых для запуска того или иного сервиса. Это позволяло постепенно восстанавливать работу зависимых от него сервисов, потом других, и т.д. По мере возможности поднимали из небытия дублирующие серверы для самых критичных сервисов.
Как вы помните, нужно было оживить около 5 000 машин. Перезагрузить их удалённо и загрузить по сети было нельзя, поскольку многие просто не были для этого сконфигурированы. Это было следствием выбранного когда-то подхода к созданию инфраструктуры. Ведь Одноклассники не развёртывали на пустом месте единовременно несколько тысяч серверов — парк постепенно разрастался в течение нескольких лет. Поэтому пришлось вручную перезагружать тысячи серверов и разрешать в BIOS управление по сети для автоматизации восстановления.
Изначально на некоторых серверах можно было «достучаться до bootstrap» — получить описание кластера и выяснить, где именно в нём хранятся те или иные данные. Пока серверы не были перезагружены, они очень медленно, но всё же отдавали конфигурацию, и можно было запустить какие–то сервисы. С ускорением процесса восстановления приходилось эти серверы перезагружать. Но для старта или нормальной работы каждой подсистеме нужно, чтобы были доступны другие связанные с ней подсистемы. Из-за перезагрузки терялся доступ к описанию некоторых кластеров и возможность запуска многих подсистем. Те, которые могли бы быть запущены, уже не запускались. А те, которые работали, переставали работать, и приходилось повторно их восстанавливать.
Ещё одна проблема была связана с жёсткими дисками. Если они долгое время работают без остановки под высокой нагрузкой, то при выключении часто выходят из строя. Именно с этим явлением мы и столкнулись. Поэтому нам пришлось регулярно заменять вышедшие из строя диски и восстанавливать консистентность баз данных. Были даже случаи, когда выходили из строя диски с рабочей копией и с её бэкапом. Причём серверы находились в разных дата-центрах. Так совпало.

Вопросы для самопроверки:
- Сконфигурированы ли ваши серверы для удалённого перезапуска?
- Насколько надежно организована ваша система бэкапов данных?
2.3. Восстановление данных
Приходилось восстанавливать бэкапы, внося в них накопившиеся логи транзакций, чтобы затем развернуть рабочие копии и запустить сервисы. Бэкап одной из баз данных нам не удалось восстановить целиком. Тогда мы параллельно запустили новый кластер хранения, в который переносили недостающие данные, собирая их из других подсистем, где они хранились для каких-то второстепенных нужд. Сначала мы выясняли, где и что искать, затем изменяли логику работы сервисов, писали скрипты для переноса данных, конфигурировали новый кластер, переносили данные… В конце концов, мы полностью восстановили всю потерянную информацию.
2.4. Запуск сервисов
После перезагрузки серверов мы рассылали по ним набор скриптов для запуска ОС и удаления из шаблона конфигурации той злополучной пустой строки. Параллельно с написанием и тестированием скриптов мы круглосуточно вручную восстанавливали серверы. К этой работе была привлечена не только команда Одноклассников, но и сотрудники из других проектов.
Если после перезагрузки сервера не сбоило оборудование и файловая система, то скрипты приводили сервис в рабочее состояние. Если из-за зависимостей от других подсистем сервис запустить не удавалось, то приходилось править код. Если и это не помогало, разбирались и искали решение. К счастью, значительное количество данных и сервисов было уже распределено между дата-центрами и нам требовалось оживить лишь необходимую для восстановления функционала часть.
Системы мониторинга и статистики повсеместно используются в интернет-проектах, и такой большой проект, как Одноклассники, не является исключением. Постоянно отслеживается огромное количество параметров, касающихся как корректности работы оборудования и приложений, так и поведения пользователей. Во время устранения аварии из-за слишком большого количества сбоев информация собиралась медленно или вообще не собиралась — попытки связи мониторов со многими серверами заканчивались таймаутами. В результате мониторы отмечали давно починенные серверы как сбойные, и наоборот — нерабочие серверы считал работающими, так как до них просто не дошла ещё очередь на опрос монитором. Зачастую системы мониторинга вообще выходили из строя. Мы не могли получить актуальные данные о состоянии серверов и узнать, корректно ли работают приложения. Поэтому приходилось делать проверки вручную, что отнимало дополнительное время

Вопросы для самопроверки:
Используете ли вы распределение данных и сервисов по разным дата-центрам? Насколько это повышает устойчивость к сбоям?
2.5. Завершение восстановления
Мы с самого начала составили план восстановления, наметив очерёдность работ. Все процедуры, выполнявшиеся в ходе восстановления, документировались. Работа людей координировалась, и когда кто-то завершал очередное задание, ему выдавалось следующее. Распределение заданий осуществлялось на основании текущей ситуации и оперативного плана. То есть процесс был управляемым, но лишь отчасти. Приходилось много импровизировать.
Восстановление первичной работоспособности, когда портал стал хотя бы загружаться и заработала часть функционала, заняло около суток.
Авария произошла в четверг вечером, а в воскресенье утром мы полностью восстановили работу портала.
3. Извлечение уроков
3.1. Инцидент-менеджмент
В Одноклассниках, как и во многих других проектах, применяется инцидент-менеджмент. То есть все нештатные ситуации фиксируются и делятся по категориям:
- баг в нашем коде,
- ошибки конфигурации,
- сбой аппаратуры,
- ошибочные действия сотрудников,
- сбои на стороне наших партнёров: платёжных агрегаторов, операторов связи, дата-центров и т.д.
Для устранения причин и последствий инцидента сразу назначается исполнитель.
Отдельно разбираются инциденты, имевшие серьёзные последствия для пользователей или потенциально на это способные. Это позволяет обнаруживать подозрительные тренды (например, рост числа сбоев какой-то категории), упреждать крупные аварии, а также сильно снижать негативный эффект от сбоев.
Серьёзные аварии бывали и ранее. Например, в 2012 году Одноклассники не работали в течение нескольких часов из-за недоступности одного из дата-центов в связи с пожаром в коллекторе связи. После этого мы поставили себе глобальную цель: наш портал должен быть полностью работоспособен при потере любого из дата-центров. Этой цели мы скоро достигнем.
Вопросы для самопроверки:
Будет ли ваш сервис доступен:
- при отказе нескольких серверов?
- одной или нескольких подсистем?
- одного из дата-центров?
- Как у вас построена работа с инцидентами?
Но к аварии подобного масштаба мы оказались не готовы. Никто не предполагал, что станут недоступны все серверы и что возникнут подобные осложняющие обстоятельства.
После аварии мы проанализировали последовательность и ход выполнения всех работ по восстановлению:
- сколько времени заняло,
- какие возникали сложности и почему,
- как они решались,
- почему были приняты те или иные решения.
3.2. Изменения в инфраструктуре, мониторинге и управлении
По результатам анализа был составлен план необходимых работ, в котором предусмотрены разнообразные аварии. На сегодняшний день мы сделали следующее:
- Завершили процесс замены ненадежных систем хранения данных (далее СХД) на основе Berkeley DB. С самого основания Одноклассников подобные системы использовались для хранения больших бинарных данных и key value для различных бизнес-сущностей небольшого размера. Этим СХД было свойственно много недостатков. Например, из-за особенностей архитектуры репликации Single Master периодически терялись изменения при отказе мастера, а иногда и при отказе его реплики. Также в ходе аварии выяснилось, что процедура восстановления из бэкапов очень медленная и ненадёжная. На данный момент завершён переход на системы на базе Cassandra и Voldemort.
- Внедрили автономную систему централизованного управления серверами через IPMI. Теперь для управления серверами достаточно, чтобы у них было питание и сетевой доступ к IPMI.
- Повысили надежность и точность систем мониторинга. После аварии мы по пунктам разобрали работу всех систем мониторинга и сделали следующее:
— полностью переписали скрипты для повышения стабильности работы,
— уменьшили таймауты проверок,
— ввели зависимости проверок приложений от доступности серверов по сети,
— обновили программное обеспечение,
— поменяли активные проверки на пассивные и внесли множество других изменений. - Внедрили защиту от изменения конфигурации на всех серверах. Теперь изменения могут автоматически применяться только в одном из дата-центров и только в рабочее время.
Вопросы для самопроверки:
- Как давно вы восстанавливали данные из бэкапа и сколько времени это заняло?
- Имеете ли вы возможность дистанционно управлять всеми серверами?
- Способна ли ваша система мониторинга корректно функционировать в случае полномасштабной аварии?
- Есть ли физическая возможность одним изменением конфигурации нарушить работу всех серверов за короткий период времени?
3.3. Изменения на портале
- Изменили процедуру внесения изменений в конфигурацию на production. Ввели принудительную проверку всех изменений ещё одним сотрудником. Тестирование любых изменений теперь проходит через б?льшее количество окружений:
— unstable (виртуалки, где можно «вытёсывать топором»),
— testing (с полным набором служебных систем, но не в production),
— stable (специально выделенная группа сотни production-серверов различных типов)
— и затем в production, отдельно по дата-центрам. - Определили обязательные типы тестов, которым подвергаются новые служебные системы или измененные служебные компоненты (нагрузочные, интеграционные, отказоустойчивости и т.д.), и дополнили их примерами.
- Переделали служебные системы и сеть с учётом дополнительных аварийных сценариев.
- Снизили зависимость от инфраструктуры, добавили дублирование, организовали аварийный доступ.
- Исправили мешающие запуску приложений зависимости и внедрили тестирование отказов сервисов. Теперь на постоянной основе проверяется работа функциональности при полном отказе подсистем. Также внедрили «рубильники», позволяющие принудительно отключать сервисы.
Вопросы для самопроверки:
- Как у вас построена процедура проверки и тестирования вносимых в production изменений?
- Насколько ваши служебные сервисы и рабочие инструменты подвержены сбоям в инфраструктуре?
3.4. План действий на случай аварии
Одной из основных проблем для нас было отсутствие плана действий при столь масштабной аварии. Мы разработали его на основании результатов анализа проведённых работ по восстановлению. Что входит в план:
- Чеклист для команды мониторинга со списком ответственных лиц, с которыми необходимо связываться, и их контактными данными.
- Распределение ролей и ответственности:
- какие сотрудники привлекаются к устранению аварии,
- какие зоны ответственности должны быть распределены и кем,
- кто является координатором,
- кто отвечает за подготовку оперативного плана,
- кто отвечает за периодическое общее информирование о статусе починки,
- кто, почему и как может перенять роли — это касается как самой починки, так последующего анализа и возможных действий после аварии.
- Чеклист по восстановлению сервисов: что чинить, в какой последовательности и как. Здесь определены списки приоритетных сервисов и порядок их восстановления; списки инструментов и систем, которые нужно контролировать; ссылки на инструкции и информация о том, что делать, если что-то пошло не так.
- Отдельная инструкция для человека, выполняющего роль координатора. Руководитель процесса устранения аварии должен оценить масштаб, распланировать, предоставлять необходимую информацию вышестоящему руководству, делегировать, контролировать, привлекать дополнительные ресурсы, фиксировать необходимую информацию и организовывать разбор инцидента.
- Отдельная инструкция на случай падения дата-центра. В ней определён список конкретных действий на случай падения одного из дата-центров.
- Регламент взаимодействия с партнёрами. Здесь способы коммуникации и распределение ролей с нашей стороны при взаимодействии с партнерами, а также уровни взаимодействия с ними:
- Информационный — в каком случае мы ограничиваемся только информированием.
- Мобилизация ресурсов — в каком случае мы массово мобилизуем ресурсы на стороне партнёра или на нашей стороне.
- Рабочая группа — в каком случае мы создаем рабочую группу с участием партнёров и кто в ней участвует.
«Аварийные» планы действий необходимо регулярно тестировать. Важность этой процедуры трудно переоценить. Если этого не делать, то уже через несколько месяцев ваш план устареет. И когда в один прекрасный день возникнет проблема, ваши действия либо не улучшат ситуацию, либо усугубят. Поэтому свои планы действий мы пересматриваем каждый квартал, а иногда и чаще, если требуется обучить новых сотрудников. Каждый раз оказывается, что нужно вносить какие-то коррективы из-за миграции серверов, запуска и закрытия микросервисов, изменений в операционной системе и системах мониторинга, и т.д.
Вопросы для самопроверки:
Существуют ли у вас планы на случаи аварий разной степени тяжести? Что вы будете делать, если все дата-центры, в которых находятся ваши серверы, будут полностью недоступны?
Пара слов в заключение
Предусмотреть все события и сбои в столь сложной системе, коей являются Одноклассники, невозможно. Однако архитектура проекта, системы защиты и всевозможные плановые процедуры позволяют нам сохранить большинство функционала и все данные в случае полного выхода из строя любого из наших дата-центров. И более того, в скором времени даже падение дата-центра не сможет повлиять на работу нашего портала.
Комментарии (34)

DustCn
08.10.2015 09:36+24>В модифицированном нами коде bash
Как вы старательно раскладываете грабли…
23derevo
08.10.2015 10:14там выше коллега ответил про баш:
habrahabr.ru/company/odnoklassniki/blog/268413/#comment_8604787

NeoCode
08.10.2015 09:57+15Вот поэтому я и не люблю языки программирования, в которых синтаксис активно зависит от непечатаемых символов ( python и т.п. ).
Я на подобное нарвался с какой-то древней утилитой (возможно make или что-то совсем экзотическое) еще учась в ВУЗе, на какой-то лабораторной работе. Что-то работало совершенно не так только от того, что где-то стояла табуляция вместо пробела.
Итого, единственный правильный способ обработки непечатаемых символов (пробелов, табуляций, переносов строк и возвратов каретки) в программах — пропускать их идущие подряд в любом порядке и в любом количестве и считать это одним «виртуальным разделителем».
spanasik
08.10.2015 10:37-12> python и т.п.
Просто не надо заставлять уборщицу вносить изменения в код. Для Python есть куча линтеров, PEP8 и прочее. При наличии адекватно настроенного редактора ошибиться с чем-то типа пробела или отступа невозможно. Специалисты это знают и умеют.
aml
08.10.2015 10:52+20Позволю не согласиться. Везде, где присутствует ручная работа, возможны ошибки. Это аксиома.
Чем больше граблей разложено в системе, тем больше шанс получить по голове. Вероятность не наступить ни на одни грабли падает в геометрической прогрессии с ростом числа граблей и числа прохожих (сотрудников). Если один человек наступает на одни грабли с вероятностью 0.01% в год, то хотя бы один из 100 человек наступят хотя бы раз на одни из 100 граблей — 1-(0.9999^100)^100 = 63% (упс!)
Проблемы необходимо устранять системно — раз и навсегда, чтобы не оставлять ошибкам ни единого шанса.spanasik
08.10.2015 10:59-3> Это аксиома.
Я не про ошибку вообще, а конкретно про «синтаксис активно зависит от непечатаемых символов». При использовании правильно настроенного редактора это не проблема, т.к. всё выявляется автоматически. Поэтому и нужны стандарты кодирования.
Понятно, что когда уборщица садится фиксить фантазии велосипедиста, то получается некрасиво.NeoCode
08.10.2015 11:35+9Надо чтобы было хорошо и при наличии правильно настроенного редактора, и при его отсутствии.
В жизни ведь всякое бывает, иногда и в «полевых условиях» приходится код править. Редакторы — их много, они разные (кому-то удобен один, кому-то другой), иногда проприетарные (т.е. любой так просто не скачаешь), иногда под разные ОС (и под нужную в данный момент может не оказаться), иногда они перестают поддерживаться и т.д. И код может переходить из рук в руки, из компании в компанию и т.д., а везде редакторы разные.
raacer
13.10.2015 14:48+1Надо чтобы было хорошо и при наличии хорошего программиста и при отсутствии. В жизни всякое бывает. Программисты — их много, они разные. Кому-то удобны пробелы, кому-то табуляция. Иногда они неожиданно увольняются, иногда умирают, и т.д.
А чтобы так было, нужен жесткий стандарт. Например, только 4 пробела. Как в Python.
raacer
13.10.2015 14:52Так вот для того, чтобы убрать ошибки ручной работы, и существуют PEP8 и всякие автоматически средства проверки.
raacer
13.10.2015 15:06Я тоже видел, как человек не разобравшись в синтаксисе питона целый день возмущался, почему программа выполняется не так как он хочет :) А в финале — гневный понос слов в сторону создателя языка. Вот так первое негативное впечатление порождает полное неприятие идеи. Это называется «неасилил».
Ваши «непечатные» символы печатаются прежде всего для людей. И игнорирование данного факта, смешение пробелов с табуляциями и расстановка отступов по принципу «мне так нравится» приводит к глупым багам и к большим трудностям в работе с чужим кодом.
С момента перехода на Python (более пяти лет назад) ни разу не сталкивался с багами, вызванными неправильными отступами (которых так боятся питононенавистники), и ни разу не встречал нечитабельной структуры (которая так часто встречается в коде питононенавистников), и вообще исчезла проблема «когда кто-то использовал табы, а другой — два пробела, а у меня четыре».
Ну а про «единственный правильный» — это вообще сверхсамоуверенность. Удачи Вам в написании своего языка программирования (подглядел в вашем профиле), самого правильного.

aleksandy
08.10.2015 11:02+14В статье как-то ничего не сказано о дальнейшей судьбе дежурного администратора, как он такой стресс перенёс?

shevchuk
08.10.2015 11:15+11Все с ним было хорошо. По итогам аварии никто не был уволен — починили и сели разбираться с найденными проблемами и рисками.

rauch
09.10.2015 04:29никого не уволили? серьезно?
ну премию хоть кому-нибудь дали? хоть один достойный человек купил себе машину по результатам восстановления бизнеса?

reji
09.10.2015 12:55Так вопрос не об увольнении, а о компенсации работодателем потери нервных клеток работником.
Оффтопик: даёшь классификацию профессии системного администратора как тяжелую/нервную с сокращённым сроком для выхода на пенсию; расширенным отпуском; обязательными командировками в санатории!


Silvar
08.10.2015 11:54+1В модифицированном нами коде bash оказался другой баг, из-за которого интерпретатор при обнаружении пустой строки в конце конфигурационного файла входил в бесконечный цикл и переставал отвечать на внешние команды.
А зачем вообще трогать системный bash? #!/usr/local/super_bash/bin/bash прекрасно справляется с задачей установки подходящего интерпритатора для скрипта.
Да и невозможность штатного обновления выглядит странно. Для меня это звучит примерно так: «скрипты были написаны абы как, без соблюдения требований и стандартов».
И, кстати, очень хотелось бы взглянуть на пример кода, который заставлял отказываться от обновленных версий в пользу ручной модификации кода интерпритатора (для самообразования, что бы так не делать)
koldyr
08.10.2015 12:47+1из статьи не понял, сможете ли вы сегодня произвести холодный запуск системы, появился ли кейс с периодическим перезапуском подсистем для избегания указанной проблемы с носителями и инициализацией?
privatelv
08.10.2015 13:35+2Зависимости, мешающие холодному запуску — устранены. Новые и существующие системы тестируются на наличие подобной проблемы. Есть возможность проблемные системы отключать, на тот случай если в production всетаки попадет проблемный код. И это тоже тестируется. Тестирование перезапуском по питанию специально не проводим, но это иногда случается :)



Nastradamus
08.10.2015 22:42+2В одной известной мне компании, скрипты пишутся уже около 15-ти лет на /bin/sh. Проблем с несовместимостью не было ни разу. Баш — зло для скртиптинга в продакшне.
brewerof
09.10.2015 00:22-8Разработчик, создававший и тестировавший шаблон
Но дежурный администратор правил файл шаблона в другом редакторе, который поместил этот символ в конец файла
То есть критично важный код пишут и тестируют одни и те же люди, а потом другие люди еще его правят? Блестяще организованный процесс обеспечения качества, есть чему поучиться.
Понятно почему у вас бажные скрипты выполняются в бажном кастомном интерпретаторе, а потом все валиться.
Потом, пункт два:
Одноклассники состоят из примерно 150 подсистем (различные базы данных, серверы бизнес-логики, кэши, графы, фронтэнды, системы конфигурации и т.д.). И работоспособность практически каждой подсистемы зависит от доступности других.
Вы считаете это хорошей архитектурой?
В извлечении уроков я не увидел ничего, касающегося пересмотра архитектурных подходов.
P.S. Избавьте от этих вопросов для самопроверки, в данной ситуации на двоешников похожи больше вы.hristoforov
09.10.2015 01:08+7Расскажите же, какая должна быть архитектура.
reji
09.10.2015 12:57Чем меньше точек отказа, тем лучше. Ваш, Кэп.
150 программных точек отказа — действительно очень много. Возможно, в статье имелось в виду другое.privatelv
09.10.2015 13:44+2Всё правильно: любому проекту хватит и трёх подсистем: nginx + PHP + MySQL.
Если серьёзно, под подсистемами имелись в виду модули со своей кодовой базой, своим кластером оборудования и своей конфигурацией.
150 подсистем — не значит 150 точек отказа. Наоборот: если ломается один модуль, он не ломает весь портал, а влияет лишь на небольшую часть функциональности.
Раньше это было не совсем так, о том в статье и речь, но после проделанной работы над ошибками подсистемы стали куда более независимыми в плане обслуживания.
hristoforov
09.10.2015 14:19+2Одноклассники состоят из примерно 150 подсистем (различные базы данных, серверы бизнес-логики, кэши, графы, фронтэнды, системы конфигурации и т.д.). И работоспособность практически каждой подсистемы зависит от доступности других.
Так 150 подсистем не означает 150 точек отказа всей системы. В идеальной системе все части должны быть не зависимы. В этом случае отказ одной из 150 частей не окажет влияния на остальные и пострадает небольшая часть функционала.
Можно иметь 1 большое хранилище данных и при его отказе из за бага потерять весь сайт, а можно иметь 50 и потерять 1/50.
При этом для обслуживания текущей нагрузки серверов будет примерно столько же, т.е. количество железных точек отказа будет одинаковое.
С другой стороны количество програмных точек отказа скорее связано с объёмом кода, сложностью задач, уровнем квалификации. И скорее всего багов в системе которая разделена на модули будет меньше, чем в одном большом.
В реальности конечно нельзя построить такую идеальную систему, где нет взаимосвязей, но к этому надо стремиться. Одноклассники как раз пытаются сделать так, что бы эффект от програмных и железных отказов был как можно более локализован.
spanasik
>модифицированный командный интерпретатор bash
зачем?
dmitrysamsonov
На тот момент мы использовали старую версию операционной системы openSUSE и, как следствие, старую версию bash «из коробки». Вместо того, чтобы обновить bash целиком, решили бэкпортировать необходимый функционал из новой версии. В процессе изменений была допущена ошибка.
На данный момент bash обновлён целиком.
Lamaster
Тот самый момент, когда проще портировать bash, чем bash-скрипты
dmitrysamsonov
Уточню, что забэкпортить необходимые изменения на тот момент выглядело проще, чем обновляться на новую ветку. В итоге мы всё равно обновились на новую ветку, что потребовало фиксить синтаксис некоторых системных и наших скриптов, но это уже другая история.