
Сложно представить задачу более востребованную и частотную, чем задачу текстового поиска. Упростить ее помогают совершенно разные инструменты и методы, однако универсального решения нет. Как один из оптимальных вариантов в статье представлен парсер библиотеки Natasha для поиска почти любой структурированной информации в тексте.

«Контекстно-свободные грамматики» – громоздкое название. Хотя это безобидная и очень полезная штука. Феномен пришел в IT из лингвистики и натворил море чудес – с их помощью можно искать в тексте почти все нужные конструкции: адрес, денежную сумму, словосочетания с глаголом «раскидывать», кличку животного – что угодно. Чтобы раскрыть всю мощь КС-грамматик на примере, предлагаю представить, что перед нами поставили задачу извлечь названия организаций из текста.
texts = [
'Вознаграждение по Договору "00" июля 2019г. ООО ЛампыДок ИНН 0000011111. НДС…',
'Оплата задолженности ООО Чистки-СВ за содержание зданий за период с 09.03.2010г…',
'Оплата ИП Левин К.Д.: предоплата за июнь по сч. №0010011111 от 02.06.2017…',
'Оплата ИП Моргушина Линда Петровна: обслуживание б/к по сч. №00101111 от 01.11…'
]Вариантов, как выполнить задачу, несколько:
а) Разбить на токены (в данном случае слова и предложные конструкции), вытянуть цепочку по ключевым словам (ООО, ИП и др.);
б) Использовать NER-модули Python-библиотек. В статье рассматривается Natasha;
в) Использовать парсер для поиска заданных цепочек с помощью контекстно-свободных грамматик;
Сравним варианты б и в.
Парсеры на основе КС-грамматик производят поиск фактов по предложениям, используя правила, по которым строятся цепочки.
Цепочка – это последовательность, любая языковая конструкция. Например, «г. Москва, ул. Рязанская, д. 21», «Евгения Лисовская работает переводчиком». В примерах подчеркнуты компоненты формулы (дескрипторы), которые можно задать правилом и производить поиск подобных сочетаний в любом тексте: Name + Surn + «работает» + Noun.
Факт – это структурированная информация – результат анализа цепочек, – обычно представленная статьей:
RFact(text=’Евгения Лисовская работает переводчиком ’ ,
span={name: ‘Евгения’,
surname: ‘Лисовская’,
profession: ‘переводчик}’ Рассмотрим процесс извлечения фактов из текста на примере библиотеки Natasha.
Необходимые импорты:
from yargy import Parser, rule, or_, and_
from yargy.interpretation import fact
from yargy.predicates import gram, eq, is_capitalized, length_eq
from yargy.pipelines import morph_pipeline
from slovnet import NER
from navec import Navec
navec = Navec.load('C:/…/ Ntsh/navec_news_v1_1B_250K_300d_100q.tar')
ner = NER.load('C:/… /Ntsh/slovnet_ner_news_v1.tar')
ner.navec(navec)«navec» – эмбеддинги, их можно загрузить здесь.
«slovnet» – модели, скачивать на этой странице.
Первым делом определимся, из каких полей будет состоять факт. Для рассматриваемых текстов достаточно двух: форма организации и ее название. На Pythonфакт реализуется следующим образом:
Orgname = fact(
'Org',
['orgform', 'name'])Обозначим правило поиска организационных форм для взятых примеров. Так как их ограниченное количество, задаем набор в явном виде:
ORGFORM = morph_pipeline([
'ООО ',
'ИП '])morph_pipeline – это газеттир (Слово «газеттир» придумали в «Яндексе», это обозначение формата словарей - .gzt, с которыми работает Томита-парсер) – т.н. корневой словарь, в котором собирается информация обо всех словарях, грамматиках и прочих элементах.
Вторая часть искомой сущности – название. Оно формируется обобщенными правилами:
С предикатом or_ все просто. Он сообщает парсеру: «Далее перечисляются правила, связанные отношением “или”». Наименование компании может быть выражено фамилией, именем или существительным. Так и запишем. У Natasha есть целый набор предикатов, они лежат в справочнике.
Все части наименования собраны. Если оставить так, как есть, парсер просто соберет цепочки, соответствующие правилам. Чтобы на выходе получить факты, нужно включить в код интерпретацию:
ORGANIZATION = rule(
ORGFORM.interpretation(Orgname.orgform),
NAME.interpretation(Orgname.name).interpretation(Orgname))
#Передаем парсеру объект «организация» и запускаем поиск:
orgparser = Parser(ORGANIZATION)
def orgs_extract(text, parser):
for match in parser.findall(text):
found_values = match.tokens
return found_values
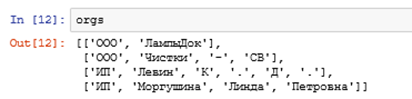
orgs = [orgs_extract(txt, orgparser) for txt in texts]Вывод для первого текста:


Дополнительная ценность – координаты сущности в тексте, которые могут пригодиться для расширенного анализа документа.
Если нужны только цепочки, изменим цикл в предыдущей функции:
Вывод:

Мы разобрали основы того, как можно извлекать и структурировать любые факты цепочки из текста с помощью библиотеки Natasha. Но если говорить об организациях – это довольно распространенная сущность, запрос на поиск которой неисчерпаем. Поэтому разработчики библиотеки включили их поиск в NER-модуль. И задача с поиском названия сводится к одной функции:
def organizations_mrkup(text):
organizations = []
markup = ner(text)
spans = markup.spans
for i in range(len(spans)):
if spans[i].type == 'ORG':
org_spans = spans[i]
start, stop = org_spans.start, org_spans.stop
organizations.append([text[start:stop], (start, stop)])
return organizationsВывод:

Из достоинств - название компании из второго текста вытянуто точно и полностью (в отличие от ручной настройки). Организации с упоминаниями форм «ООО», «ОАО» модуль видит лучше всего.
Сравним точность подходов по расстояниею Левенштейна:
NER |
Parser |
|
'ООО ЛампыДок' |
15 |
0 |
'ООО Чистки-СВ' |
0 |
3 |
‘ИП Левин К.Д.’ |
13 |
4 |
‘ИП Моргушина Линда Петровна’’ |
24 |
16 |
Итого |
52 |
23 |
Сравнение проходит на крайне небольшой выборке, при увеличении количества текстов показатели выровняются.
Поиск названий для ИП (с включением полных имен или инициалов) можно настроить в правилах для парсера.
Пример полной настройки:
PT = eq('.')
Name = fact(
'Name',
['surname', 'name', 'lastname', 'orgnm', ‘abbr’])
ORGFORM = morph_pipeline([
'ООО',
'ИП'])
SURN = gram('Surn').interpretation(
Name.surname)
NAME = gram('Name').interpretation(
Name.name)
ABBR = (is_capitalized()).interpretation(
Name.abbr)
PATR = (is_capitalized()).interpretation(Name.lastname)
INIT = and_(length_eq(1), is_capitalized())
FRST_INIT = INIT.interpretation(Name.name)
LST_INIT = INIT.interpretation(Name.lastname)
ORGNAME = and_(gram('NOUN'), is_capitalized()).interpretation(
Name.orgnm)
) ORGANIZATION = or_(
rule(ORGFORM, SURN, FRST_INIT, PT, LST_INIT, PT),
rule(ORGFORM, FRST_INIT, PT, LST_INIT, PT, SURN),
rule(ORGFORM, ORGNAME, TR, ABBR)
rule(ORGFORM, SURN, FRST_INIT, PT),
rule(ORGFORM, FRST_INIT, PT, SURN),
rule(ORGFORM, NAME, SURN, PATR),
rule(ORGFORM, SURN, NAME, PATR),
rule(ORGFORM, SURN, FRST_INIT),
rule(ORGFORM, FRST_INIT, SURN),
rule(ORGFORM, NAME, SURN),
rule(ORGFORM, SURN, NAME),
rule(ORGFORM, ORGNAME),
).interpretation(Name)
ORG = Parser(ORGANIZATION)Вывод:
Использование контекстно-свободных грамматик в NLP – огромное поле возможностей для работы с текстом. Для некоторых задач подобный подход – overkill, но для массового поиска фактов/цепочек в огромных данных парсер – отличный помощник, который обеспечит сравнимо высокую точность.
Комментарии (4)

iforvard
20.11.2021 23:14А если и форм больше (уфк, ано, мп, итд)и записаны они не только сокращённо?

NewTechAudit Автор
22.11.2021 12:56Парсер – механический поиск. Нужно указывать все формы, если они нужны Вам в результате поиска. В том числе, развернутые аббревиатуры.
michael108
У меня жена — библиограф, работает в библиотеке. Периодически их отдел составляет именные указатели. Задача — по списку фамилий с инициалами найти все вхождения этих фамилий в текст, составленный из описаний библиографических ссылок на статьи, материалы конференций, отзывы в разных источниках и т.д. Посмотрев, как жена днями и неделями мучается с этой работой, я написал программу для автоматизации этого процесса. Без конечной проверки человеком обойтись не удалось, но весь процесс теперь занимал несколько часов и сводился в основном к проверке, не пропущена ли какая-то ссылка или фамилия.
Изначально программа была написана на BlitzBasic, с которым я тогда активно работал (дело было ну очень давно), поэтому недавно я захотел переписать ее на C#. А заодно увеличить уровень автоматизации за счет автоматического составления исходного списка фамилий. Это классический поиск именованных сущностей. Для этого решил попробовать Natasha, которую так хвалят. И сильно разочаровался. Половину фамилий она вообще не находила, а среди того, что находила, было довольно много мусора. Пришлось оставить «человеческий» поиск фамилий в тексте.
У меня возникло подозрение, что Natasha оптимизирована для поиска именованных сущностей в более-менее связном и коротком тексте. Например, в аннотации статьи или в приговоре суда. Если же ей подсунуть большой текст, состоящий из массы не связанных между собой параграфов, насыщенный именованными сущностями, то она сильно лажает.
NewTechAudit Автор
@michael108 точно не берусь утверждать, что библиотека идеальна, она успешно охватывает определенный круг задач, как и любой другой модуль. Мы рассматриваем настраиваемый поиск с помощью парсера, где можно указать собственные правила, опираясь на закономерности указания имен.
«Мусор» встречается из-за обобщенных правил, которые указывают, что в тексте может встретиться, например, только фамилия. Для ее поиска в коде «NameExtractor» указывается правило – «слово с заглавной буквы». И парсер найдет всё, что попадает под это указание. Можно ограничить поиск еще одним правилом вроде «оканчивается на –ов/-ова/-ко». Это – пользовательская настройка, которую нужно писать самостоятельно.
Интерес разработчиков был скорее оставить ложноположительные вхождения, нежели отсечь ложноотрицательные вместе с истинно отрицательными. Сущности вроде имен и фамилий в принципе сложно найти механически, если у них нет статичного окружения. В таких случаях мы обращаемся к ML.
Не берусь делать однозначные выводы относительно качества работы их модели для NER на разных объемах и структуре текста. Она обучена на новостях и художественной литературе, что охватывает далеко не весь спектр жанров письменной речи.