
Введение
Привет, меня зовут Алексей Белявцев и я ETL-архитектор в X5 Group. Наши объёмы данных соизмеримы с крупнейшими международными компаниями и требуют специального ухода и содержания, что накладывает определённый отпечаток на специфику используемых решений. Я не планирую грузить вас описанием детальной архитектуры (всё равно её нельзя публиковать), скриптами загрузки (их тем более) и другими скучными подробностями технической реализации, которые в достатке присутствуют во всех data-driven компаниях, а хочу заглянуть в будущее и попытаться представить архитектуру, удовлетворяющую всем потенциально возможным требованиям, масштабируемую, отказоустойчивую и просто приятную во всех отношениях.
Речь пойдёт о практиках сборки данных (подготовка снастей и поиск водохранилища), а также о нахождении оптимальной точки раздачи данных (лунке в зимний сезон или просто удачного места в рогозе) в реалиях очень big data, сотен систем-источников (СИ) и петабайтах данных (примерно как порыбачить в океане). Цель изложения заключается в консолидации и структурировании информации по теме и размышлениях об идеализированной архитектуре в зависимости от потребностей подразделений компании в данных. Будут высказаны предположения по опережающему развитию архитектуры под новые требования бизнеса третьего десятилетия 21 века, при этом многие из затронутых тем на текущем этапе развития направления являются более чем holywar-ными, причём подходы, успешно использующиеся в одних компаниях, могут быть провальны в других и наоборот (зависит от многих факторов).
До начала чтения можно опционально ознакомиться с академическими видами архитектур, которые достаточно ёмко и понятно расписаны в статье (клац), не хватает разве что ϰ(каппа)-архитектуры, хотя её применение в VeryBigData как раз сомнительно ввиду огромных объёмов данных (какой смысл перекачивать все данные, в т.ч. не требующиеся в оперативном режиме через ODS?).
AS-IS (общепринятый)
Классическое построение DWH подразумевает некий набор инструментов извлечения (E значит extract), загрузки (L стало быть load) и даже преобразования (T есмь transform) данных, а также набор платформ для хранения и раздачи данных. Это может быть одна платформа, несколько платформ для различных целей, возможны даже варианты реализации подобия DWH в BI-инструментах (например Qlik на qvd-файлах - некоторое подобие DW, которое, несмотря на некоторого рода абсурдность в части невозможности обращения к такому DW ничем кроме Qlik, довольно широко применяется в компаниях с невысокой степенью ИТ-зрелости, и применяется даже вполне успешно. Что только подтверждает тезис: что одному хорошо, другому может мягко говоря не подойти).
Подавляющее большинство загрузок в DWH осуществляется ночью во время минимальной нагрузки на СИ, соответственно актуальность данных составляет t-1d. Причиной этого зачастую является:
Перегруженность СИ в дневное время и невозможность несения нагрузки ещё и на чтение в массово-параллельном режиме ETL-инструментами
Отсутствие изначальных требований по более оперативной экстракции данных
Неготовность к streaming/micro-batch загрузке: Самих ELT/ETL-инструментов / Систем-приёмников (на запись, на чтение или на то и другое и желательно без Join-ов)
Немного известной терминологии: Data Lake (DL, Озеро данных - здесь можно посмотреть всех "рыбов") - файловое хранилище всех типов сырых данных, (Enterprise) Data Warehouse (DW, Хранилище данных - эдакий Пруд для платной рыбалки, где точно знаешь что и когда выловишь) - хранилище структурированных подготовленных бизнес-данных. Доступное и подробное описание DL и DW в статье (клац).
Заодно небольшое наглядное пояснение последовательности букв "L" и "T" выше по тексту: ELT - берём "рыбов" из Озера "как есть", переносим в Пруд, где они уже размножаются, эволюционируют и пр.:

ETL - пока несём "рыбов" из Озера до Пруда, успеваем на ходу их клонировать, добавить необходимые генные модификации:

Вот примерный перечень этапов эволюции рыбалки работы с данными:
Чтение данных напрямую из СИ каждым потребителем (много рыбаков, каждый со своими снастями)
Централизованный DW (соответственно ETL, только без DL)
Добавление DL к DW (соответственно ELT)
Различные вариации с использованием комплексных подходов (и никакого браконьерства с сетями и динамитом!). Пожалуй про этот пункт и будем говорить далее
К слову, схематично таким образом у нас происходит централизованная обработка данных:

Из современных подходов можно пожалуй выделить: Logical DWH (он же слой виртуализации+семантики, ему минул 10-летний юбилей, но по-прежнему стоит упоминания) и LakeHouse (а вот этот совсем молодой), ниже чуть подробнее.
Logical DWH (клац): Концепт, позволяющий использовать гетерогенную архитектуру хранилища (на разных платформах) и нивелировать сложность работы с разными инструментами обращения к этим платформам. Представлен набором технологий: слой виртуализации данных, понимающий куда за какими данными нужно идти при получении запроса, и семантический слой, содержащий простые и понятные бизнес-термины для обращения к данным, ассоциированным с этими терминами. Идеологически LDWH сокращает до минимума количество перегрузок данных из платформы в платформу, а также значительно упрощает работу с данными для конечного пользователя. Использования на масштабах петабайтных данных и десятков тысяч пользователей под вопросом в части производительности,в частности объёму RAM под подобное решение.
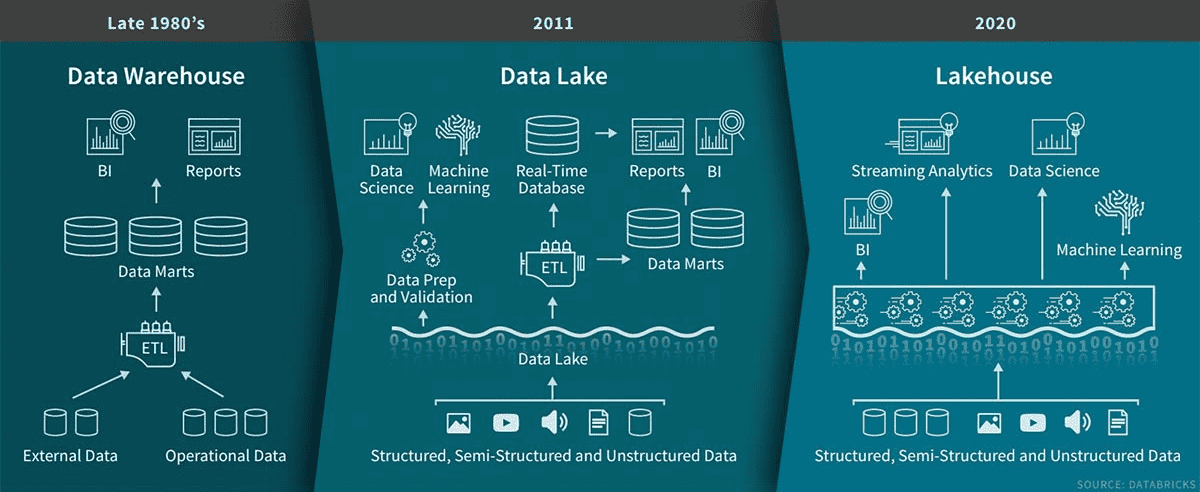
Databricks (считается главным лидером идеи) строит своё решение на технологии Delta Lake - некий уровень хранилища над Озером данных (на русском - клац, in English - clack) с поддержкой ACID-транзакций (клац), принудительным применением и эволюцией схемы (клац) и хитрой системой увязывания Streaming и Batch-режимов наполнения данными за счёт ряда инструментов (как ни удивительно все с приставкой "Delta"). В Delta Lake также присутствует деление Delta Storage Layer на Бронзу (OLTP, сырые данные из всех режимов загрузки. Качество данных, соответственно, так себе), Серебро (тут уже появляются модели данных, обработка, проверка качества данных) и Золото (презентационный OLAP-слой витрин для BI и пр.).
Предпосылки создания TO-BE архитектуры
В современных реалиях ускорения процессов со стороны бизнеса (лови больше, приноси чаще и вот это вот всё) чаще появляются запросы на максимально оперативное получение данных из СИ и преобразование этих данных для использования в системах различных классов (BI, технический мониторинг, прогнозы/анализ и т.д. и т.п.). В то же время растёт сама компания, увеличивается количество данных, что в конечном счёте приводит к определённым "челленджам", которые решаются изо дня в день. В качестве опережающего воздействия необходимо наметить точки потенциального развития в области централизованной (или нет?) работы с данными и сформировать видение на годы вперёд, с учётом масштабирования данных как по объёму, так и профилю и количеству запросов.
В случае отсутствия централизованных инструментов агрегации и предоставления данных в оперативном режиме для каждой задачи могут прорабатываться и внедряться разные решения, для которых специфично:
Разные платформы, возможно на специфичном железе, инструменты и языки (это когда удочки вроде бы одинаковые, а катушки друг к другу не подходят)
Решаются однотипные задачи и проблемы при каждом внедрении (каждый проходит путь от гарпуна до чего-то более цивилизованного, причём останавливаются на том моменте, когда процесс начинает мало-мальски удовлетворять)
Высокая стоимость внедрения и поддержки вследствие п.1 и 2
Значительное время цикла внедрения решения, отсутствие единого центра компетенций и пр. (некого спросить, как хотя бы катушкой пользоваться. Или даже есть кого, но все рассказывают по-разному и хвалят своё "болото")
Подобные решения по своей сути будут обходить стороной DL+DW, будет появляться альтернативная точка взгляда на "правду". Как не допустить подобной ситуации с самопроизвольным переходом на распределённый Data Mesh (клац), про который в описанном сценарии всеми известный персонаж сказал бы: "Это какой-то неправильный Data Mesh и он делает неправильные данные".
Что делать?
Извлечение данных (E)
Для получения данных в более оперативном режиме есть решение LogMining Change Data Capture (CDC), также на стороне СИ может быть организовано отбрасывание дельт в сторону ELT любыми внутренними средствами. Вкратце функциональность CDC представляет собой чтение транзакционных лог-файлов СИ, разбор и применение изменений в приёмник (как правило для начала в Kafka). Принято считать, что CDC максимально снижает нагрузку на СИ, хоть это утверждение и спорно в случае сравнения с Batch-выгрузками в периоды низкой нагрузки на СИ, ввиду необходимости включения Supplemental Logging на СИ для CDC, подробнее (клац). Из наиболее известных CDC-инструментов можно выделить следующие: Oracle Golden Gate, IBM InfoSphere Data Replication, Informatica PowerExchange CDC, Qlik Replicate (ex. Attunity), Debezium (open source). Первые три продукта очень схожи по функциональным возможностям, предельные объёмы обрабатываемых данных составляют ~1TB/hour, стоимость также сопоставима и "условно высока". В части последних двух продуктов достоверной информации о деталях и опыте внедрения на больших объёмах данных (>5TB/day) у меня нет (в Москве вообще не очень много водоёмов, а в тех что есть давно всё выловили).
Однако поговорить хотелось бы не про извлечение данных (безусловно важный, но решаемый в определённой степени вопрос), а о том, что же с ними делать и на каком этапе раздавать потребителям.
Преобразования, раздача данных (T/L)
Здесь сразу же напрашивается развилка ELT/ETL, и чем оперативнее нужно получать данные, тем левее перемещается буква L и вопрос формируется скорее следующим образом: "T - быть или не быть, и если быть, то где?". Конкретнее - в какой степени трансформация тех или иных данных должна быть централизована или напротив вынесена в отдельные решения. Из классической теории мы имеет 2 варианта:
Всё грузим в Data Lake, дальше строим модель данных и витрины в DW. Процесс (время доставки данных от СИ до результатирующей витрины) можно ускорить с помощью таких решений, как HBase (клац), Spark Structured Streaming (клац) и других подручных инструментов (например ловить на "дорожку" с лодки), однако всё равно вряд ли удастся удовлетворить требованиям по доставке данных, а в случае больших объёмов данных вся схема ещё и выльется в "копеечку". Кого устраивают остывшие данные - добро пожаловать в экосистему DL+DW на подлёдную рыбалку
Если п.1 не подходит и бурить лунки в -20° заказчик не расположен, уходим в историю изобретения собственного удилища: долго и дорого, но в конце концов потребности удовлетворит. А вот централизовать все требуемые трансформации вряд ли получится
Предположения по TO-BE архитектуре
Какие платформы использовать для получения и дальнейшей раздачи данных потребителям? В части оперативных данных круг несколько сужается ввиду осознания необходимости in-memory DB, которых также немало, сравнение есть здесь (клац) (GP формально не in-memory, но про это указано в статье, а к числовым параметрам производительности imho следует относиться со здоровой долей скептицизма ввиду вырожденности сценариев тестирования, хотя в лидерство HANA и Exasol пожалуй можно поверить, а ещё лучше перепроверить). В любом случае требуется Proof of Concept под используемые в конкретной компании модели, объёмы и запросы к данным и другую специфику (кому-то вообще интереснее на "ферме" фрукты-овощи собирать, а не рыбный промысел).
Ниже представлена схема, предполагаемо закрывающая потребности и недостатки AS-IS, а также предоставляющая возможность пересаживания потребителей на потоки данных с СИ при необходимости и переход с batch на streaming (опять же по мере необходимости):

Рассмотрим подробнее поток данных в ODS в режиме streaming и загрузку в Domain & Product Data Marts (это как раз те самые степи частных решений со своими бюджетами и реализациями из раздела проблем AS-IS), здесь есть 2 варианта:
Делаем предобработку на слое ODS (высокая централизованная нагрузка), выдаём предподготовленные данные (на схеме Fast data layer)
Выгружаем сырые данные, обработка происходит на стороне продуктовых систем (распределение нагрузки по различным платформам и инструментам)
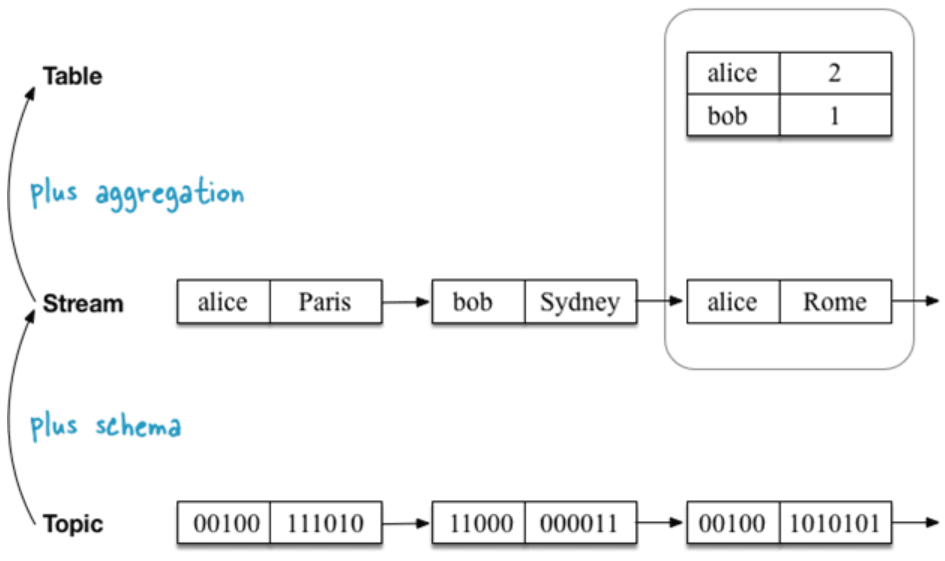
В части первичного преобразования данных можно например рассмотреть Kafka Streams (на русском - клац, in English - clack), схема из статьи (концептуальные уровни Kafka):
Схематично потоки данных, потенциально удовлетворяющие всем потребностям, будут выглядеть так (с учётом гетерогенности хранилища данных):

Плюсы работы по схеме выше:
Высокая отказоустойчивость
Максимальная разгрузка СИ за счёт единой точки входа
Гарантированная доставка данных
Возможность оптимизации времени загрузки и доставки данных от СИ до конечных систем
От внимательного (и не очень) читателя не должен был ускользнуть факт наличия аж 3 (трёх!) платформ централизованного хранения данных, т.е. эдакая распределённая система. Забегая вперёд, Да, вы можете использовать у себя две и даже одну платформы, более того, в определённых кейсах эти варианты будет оптимальнее предложенного. Но учитывая свою специфику, объемы данных и планы по развитию, мы остановились на магическом числе 3 (так как-то посолиднее (надёжнее) выглядит, да и функциональность у них разная). Итого по компонентам схемы:
Чтение данных из логов, настройка отправки изменений для оперативных данных, а также классические выгрузка в более спокойном batch-режиме напрямую из БД, через экстракторы, API и пр.
(опционально) Предварительная обработка логов, например упаковка в пакеты (не должна быть тяжеловесной)
Ключевой компонент - брокер сообщений, получающий и раздающий все потоки оперативных данных. Может (и должен быть) представлен в виде нескольких кластеров со своими настройками в зависимости от характера входных потоков данных, а также для недопущения взаимного негативного влияния критически важных потоков.
Различные инструменты работы с потоком данных (не исключаю, что есть ещё ряд удачных вариантов помимо Kafka Streams и Spark SS) - позволяют предобработать данные в режиме streaming и выдать не просто байты информации, а даже таблицы данных (например уровень 2-го порядка KTable - агрегированный поток данных).
Собственно ETL/ELT, обеспечивающий загрузку в batch-режиме в основное хранилище.
-
Главное хранилище больших данных (у нас называется DMP - Data Management Platform):
(Fast data layer) Собирает сырые данные, делает предобработку и раздаёт данные потребителям в высоконагруженном режиме
(EDW) Строит корпоративную модель данных, предоставляет витрины всем заинтересованным потребителям, входящий поток в большинстве своём идёт из Data Lake
(DL) Собирает сырые данные и раздаёт (как правило) их же, также является хранилищем охлаждённых данных из целевых систем (архив)
Продуктовые микросервисы, которые могут быть представлены широким спектром компонент, таких как job-серверы, СУБД (как реляционные, так и in-memory и даже графовые - в зависимости от потребности), очереди и т.д.
Целевые системы различных классов, как правило мониторинг (здесь очень актуален поток оперативных данных) и BI.
Выводы
Таким образом практика централизации раздачи оперативных данных выглядит более чем перспективным и эффективным с точки зрения совокупного сокращения времени и затрат на реализацию интеграций вариантом. Исходя из требований в части актуальности данных, их качества, нагрузке при обращении к данных, характеру запросов и многим другим параметрам из схемы выше можно подобрать оптимальный вариант интеграции, наиболее точно отвечающий запросу.
При этом EDW остаётся единой точкой правды (достоверных данных) благодаря устройствам контроля качества "рыбов" (в простонародье Data Quality или просто DQ), из которой 1 раз в сутки оперативные данные в конечных системах могут быть выверены или перезаписаны. При этом остаётся проблема возможного различия моделей данных (в частности одни и те же данные могут лежать в разных платформах в разных степенях нормализации в зависимости от особенностей работы самих платформ (но это целая отдельная история).
Послесловие
Отдельное спасибо авторам ссылочных статей за раскрытие аспектов многогранной темы больших и маленьких данных, надеюсь вы не против референтного использования ваших публикаций для придачи моему материалу большей завершённости.
Также буду благодарен за комментарии и опыт реализации подобных решений, допускаю что в концепте текущей статьи могут скрываться неразрешимые противоречия с реальным миром (а что если рыбы на самом деле не живут в Озере, а на деревьях?).
Перечень ссылочных статей (не является полным перечнем использованной литературы):
Arenadata: "Пять подходов к построению современной платформы данных" (https://arenadata.tech/about/blog/5-ways-to-dwh/)
Habr, Дмитрий Аношин @dimoobraznii: "Нужно ли нам озеро данных? А что делать с хранилищем данных?" (https://habr.com/ru/post/485180/)
Data Warehouse Information Center: "An Overview of Logical Data Warehousing" (https://datawarehouseinfo.com/logical-data-warehouse/)
Databricks: "What Is a Lakehouse?" (https://databricks.com/blog/2020/01/30/what-is-a-data-lakehouse.html)
Школа больших данных: "Как ускорить озеро данных или что такое Delta Lake на Apache Spark" (https://www.bigdataschool.ru/blog/what-is-delta-lake.html)
Towards data science: "The Fundamentals of Data Warehouse + Data Lake = Lake House" (https://towardsdatascience.com/the-fundamentals-of-data-warehouse-data-lake-lake-house-ff640851c832)
Habr, Ольга @Molechka: "Требования ACID на простом языке" (https://habr.com/ru/post/555920/)
Habr, Наталия Кошелева @reponche: "Погружение в Delta Lake: принудительное применение и эволюция схемы" (https://habr.com/ru/company/otus/blog/502324/)
Habr, Евгений Черный @Evgeny_Chernyy: "Переход от монолитного Data Lake к распределённой Data Mesh" (https://habr.com/ru/post/495670/)
Oraclegis: "Популярно о Supplemental Logging" (http://oraclegis.com/blog/2010/02/05/%d0%bf%d0%be%d0%bf%d1%83%d0%bb%d1%8f%d1%80%d0%bd%d0%be-%d0%be-supplemental-logging/)
Habr, Александр Петров @asash: "Big Data от А до Я. Часть 4: Hbase" (https://habr.com/ru/company/dca/blog/280700/)
Habr, @Nosp27: "Как мы готовили распределенный джойн на Spark Structured Streaming. Доклад с RamblerMeetup&Usermodel" (https://habr.com/ru/company/rambler_and_co/blog/569932/)
Habr, Дмитрий Павлов @kapustor: "Сравнение аналитических in-memory баз данных" (https://habr.com/ru/company/tinkoff/blog/310620/)
Школа больших данных: "Kafka Streams" (https://www.bigdataschool.ru/wiki/kafka-streams)
Kafka: "Core concepts" (https://kafka.apache.org/23/documentation/streams/core-concepts)
Архитектор ETL,
© Алексей Белявцев (@BaalExe)
Комментарии (6)

CyaN
16.12.2021 09:20А что в данном контексте подразумевается под СИ? Средства интеграции, сервисная инфраструктура, совокупность инструментов, etc?
vakhramov
Не понятно, какие задачи в итоге решаются, и для чего :)
bormanman
Никакие. Сайт «Пятёрочки» один из самых глючных, тормозных и неудобных среди всех ритейлеров. Не меняется годами. Баги там не переводятся и большинство прям детские, а с тех пор как они перешли на «x5 id» без слёз этим поделием пользоваться практически нет возможности.
Зато приятно узнать, что в их ИТ-отделе люди выучили много модных терминов.
BaalExe Автор
Задача - предоставить данные всем подразделениям компании "по потребностям", а именно с требуемой детализацией, актуальностью и в нужной степени нормализации. Классические подходы складывания всего и вся в DataLake уже не удовлетворяют потребностям бизнеса, поэтому рождаются разнообразные решения, о которых идёт речь в статье.
В части данных речь не идёт о регулярном взаимодействии система-система, централизованное хранилище предоставляет данные для анализа и использования в экосистемах доменов/продуктов в сценариях: различного рода прогнозы (товаров на полках, загруженности тех же касс и много другого), ML, BI-отчётность для многих задач от анализа вчерашнего дня/недели до оперативного воздействия при задержке выполнения какой-то задачи сотрудником (тут как раз нужна высокая актуальность данных) и любые другие сценарии использования данных.
vakhramov
А это работает? Вот у нас маленький город, есть большой Перекрёсток, перед НГ откроется Магнит напротив него. И уже нельзя будет по историческим предновогодним 2020 данным сказать, что в 2021 загруженность касс в Перекрёстке будет такая же.
Построили новый мост из НН на Бор в 2018, в пятницу стало не протолкнуться на парковке перед Перекрёстком (полно народа) - стало больше ездить людей на дачу (пораньше выезжать из города, спокойно затариться в пригороде Бор и ехать на дачу без пробок).
Внешние факторы (у нас это называется ручной ввод) учитываются :)?
Конъюнктура покупателей (дачники по пятницам) - учитывается в моделях?
BaalExe Автор
Ну, смотря что именно работает. Данные собираются и раздаются условно для всех 18 тысяч магазинов (на самом деле для проектов над ними в разных конфигурация по сетям, локации и пр.), в рамках этих проектов могут быть реализованы и вопрощены в жизнь разные модели. Ну думаю, что факт наличия данных в DWH как-то связан с оценкой единичной точкой сети, но уверен, что в рамках развития всей сети улучшение сервисов централизации корпоративных данных и улучшение качества, актуальности и пр. данных в будущем исключительно положительно скажется на пользовательского опыте. DWH - не готовая рыбка, а удочка, которую можно использовать в меру своих возможностей.