

Разработка инфраструктуры машинного обучения — это новое конкурентное пространство. Операции машинного обучения (MLOps) обещают заменить надоевшие ручные сценарии автоматизированными и воспроизводимыми пайплайнами, открывая бесконечное количество ценностей для бизнеса в этом процессе. Следующая цитата из блога о продукции Pachyderm хорошо резюмирует эту предпосылку:
Представьте себе крупную организацию с сотнями моделей машинного обучения, которые нуждаются в тренинге и регулярной оценке. Любое небольшое изменение в датасетах для обучения может существенно повлиять на результат модели. Немного измените ограничивающие рамки или уменьшите размер файла, и вы можете получить совершенно разные результаты вывода. Масштабируйте этот сценарий на сотни моделей, и он быстро станет неуправляемым. Возможность системного восстановления после последствий таких экспериментов требует строгого контроля версий данных, их истории и методов управления жизненным циклом модели.
Крупные компании, предлагающие платформы "все в одном", множатся. Если пространство является настолько новым и запутанным, как можно ожидать от руководителей, что они смогут создать свою собственную платформу с нуля? Но по мере того, как потребности предприятий становятся все более специализированными, появляются и продукты, отвечающие этим потребностям. Волна узконаправленных продуктов с открытым исходным кодом стала реальной конкуренцией платформам.
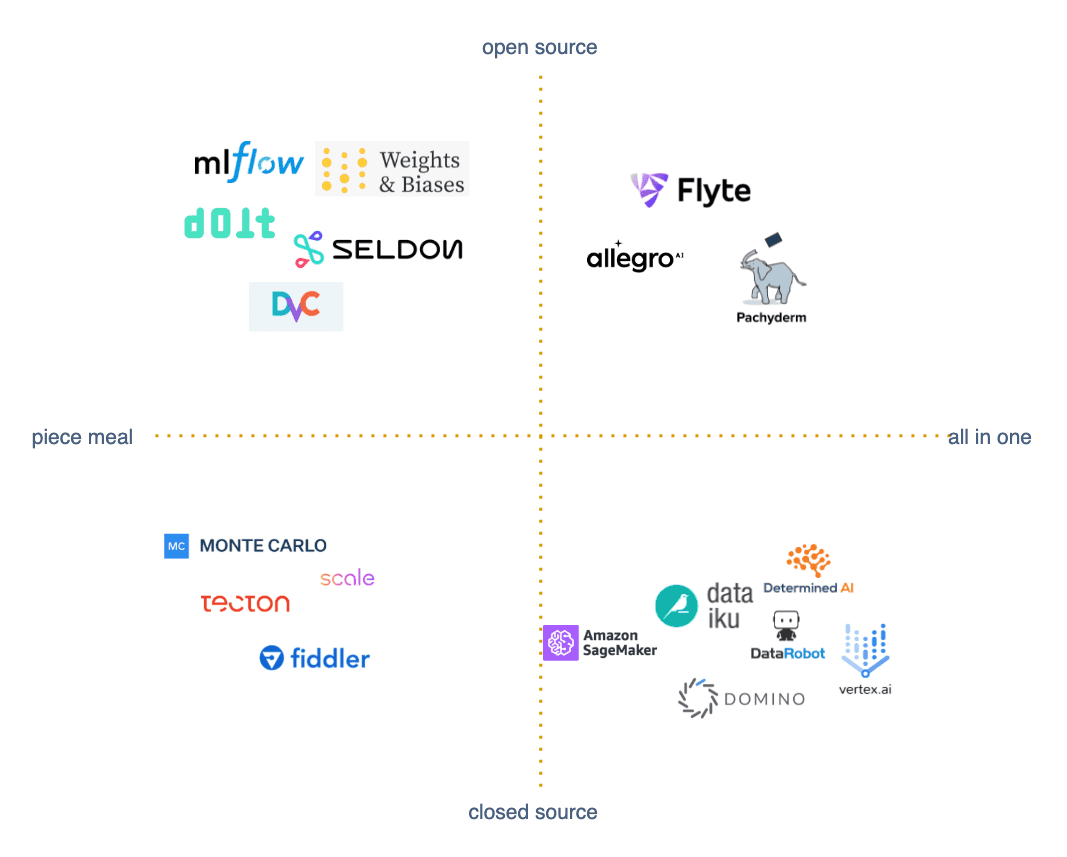
В левом верхнем квадранте находятся проекты с открытым исходным кодом, предоставляющие специализированные вспомогательные инструменты. Справа вверху находятся системы вычислений и автоматизации, предоставляющие ряд инструментов для работы с данными, пайплайнами и визуализацией на одной платформе. В нижнем правом секторе находятся корпоративные платформы с закрытым исходным кодом, которые охватывают науку о данных (даталогию), аналитику и обслуживание моделей. И наконец, слева внизу - несколько инструментов с закрытым исходным кодом, которые обеспечивают аутсорсинг определенных процессов для корпоративных клиентов. Более полный список инструментов приведен в этой инфографике.
В этом блоге будет рассказано о том, как мы использовали подход, альтернативный платформе "все в одном". Мы объединили несколько инструментов с открытым исходным кодом в целостную ML-платформу за три месяца, избежав подводных камней "создания собственной платформы". В обоих подходах есть свои преимущества и недостатки, но с каждым годом становится все проще и дешевле объединять лучшие в своем роде инструменты, а не соглашаться на корпоративную блокировку. Теперь вы можете выбрать опциональность, не жертвуя качеством. Если вы считаете это столь же интересным, как и мы, читайте дальше!
Масштабирование ML-команды
Когда партнер обратился к нам с просьбой о создании платформы, первым делом мы занялись документированием существующей инфраструктуры. В начале проекта у них была команда аналитиков и один-единственный специалист по анализу данных. Он обучал модели на штатной стойке GPU, сохранял результаты в локальном инстансе MLflow и использовал Jupyter notebooks в качестве хелперов для сценариев автоматизации. Аналитики в основном занимались очисткой и каталогизацией обучающей информации в Google Sheets.
Далее мы исследовали текущие и будущие цели партнера в области ML. Небольшое количество первоначальных моделей разрослось до 50, а в перспективе достигнет 100. Каждая из них включает несколько новых источников данных. Трекинг управления данными так же важен, как и регистрация артефактов модели. Команда растет, и одному специалисту по анализу данных нецелесообразно вручную отслеживать каждый источник информации и модель.
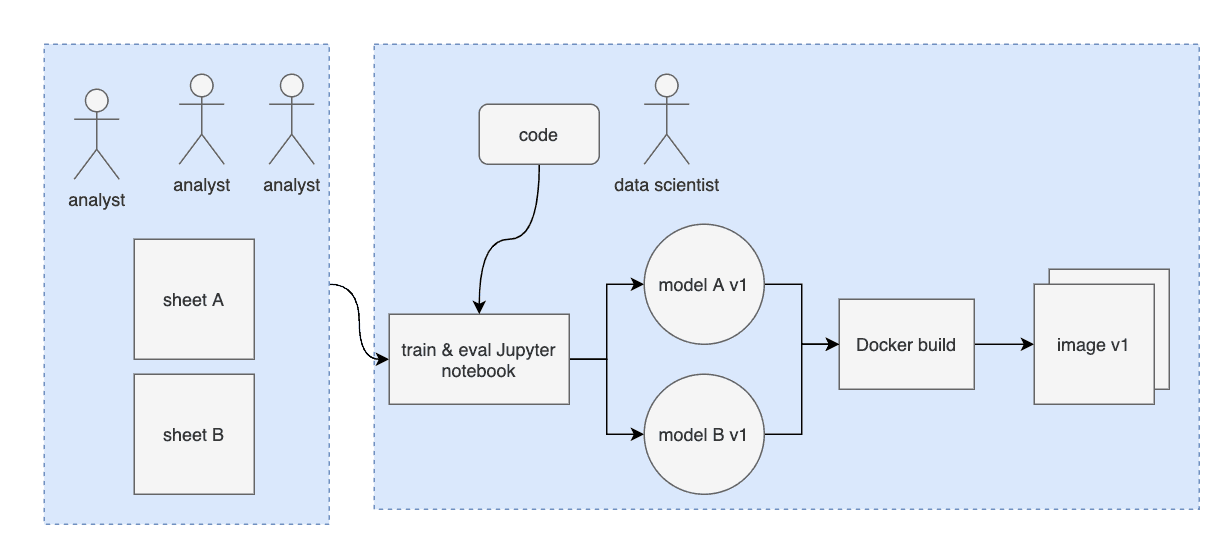
В итоге мы хотим автоматизировать версионирование данных, обучение моделей и построение образов после изменения данных аналитика. Чем шире размах нашего рабочего процесса, тем важнее регистрировать и отслеживать входы и выходы каждого задания. Система напоминает цитату из миссии Pachyderm, но наш партнер хотел получить кастомное решение.
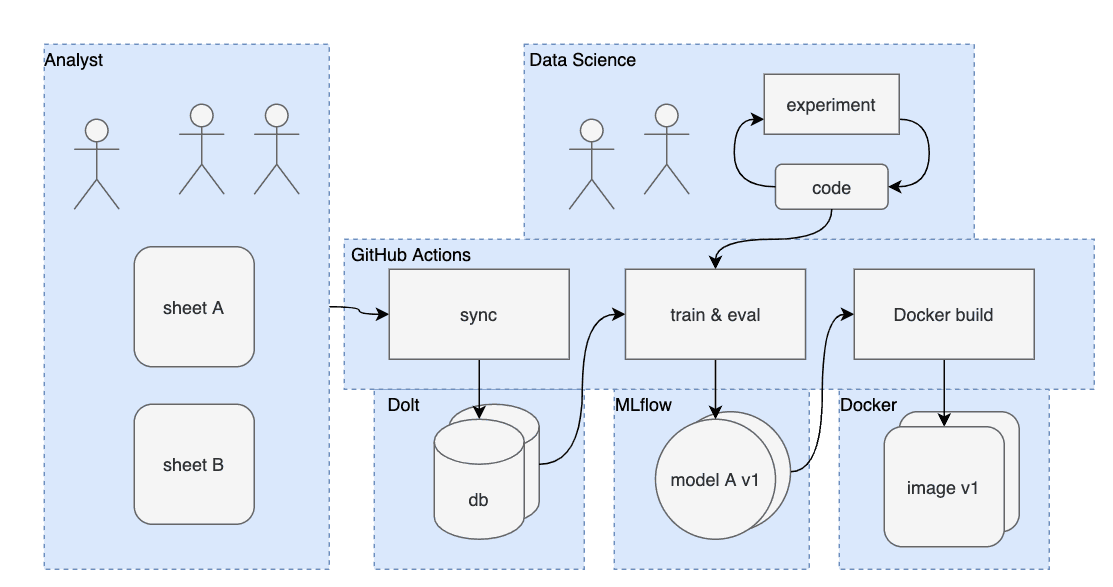
Собираем пазл по кусочкам
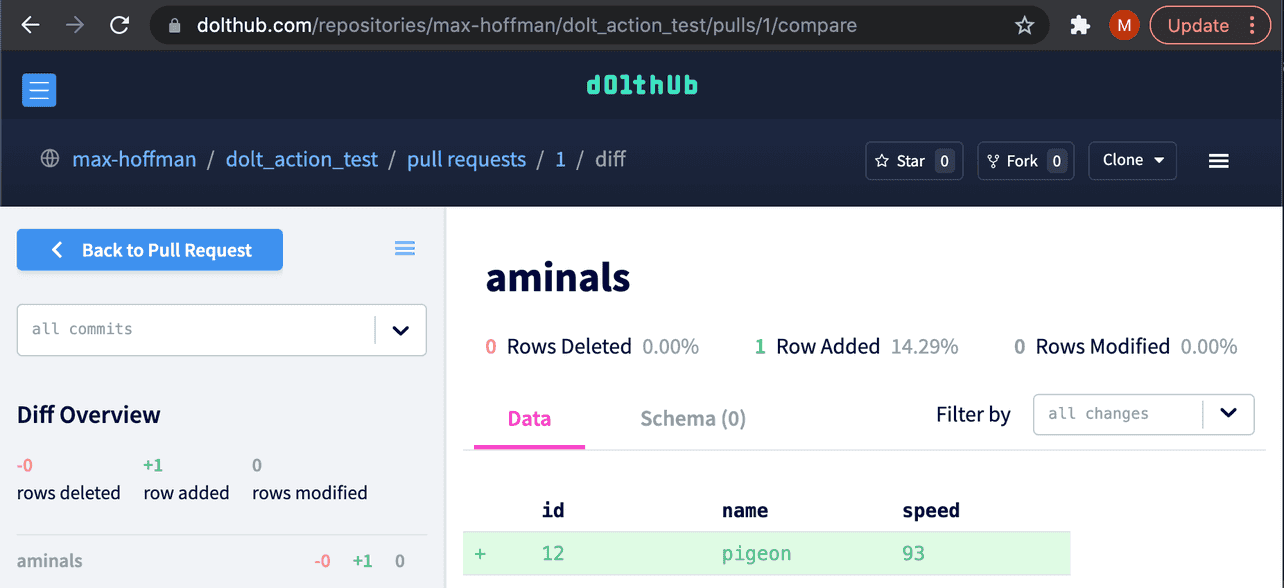
Мы присоединились к этому проекту, потому что Dolt — единственная база данных, которая предлагает полную Git-версию. Базы данных Dolt совместимы с MySQL, но их можно создавать и редактировать локально, реплицировать на удаленные серверы и постепенно улучшать с помощью пул-реквестов. Наш партнер хотел синхронизировать изменения в обучающих таблицах с базой данных, сверять их с помощью diffs в DoltHub UI и запускать новые сборки моделей при коммите (подробнее см. наш блог об интеграции Gsheets).
Dolt не является перспективной ML-платформой. Мы сосредоточены исключительно на создании лучшей базы данных SQL. Поэтому нам нужно было заполнить пробелы с помощью дополнительных инструментов.
"Служебный уровень" для выполнения заданий изначально являлся наиболее масштабным решением. Нам нужна система непрерывной интеграции (CI), и мы решили использовать GitHub Actions для планирования заданий. GitHub Actions - это закрытый исходный код, но он также является бесплатным продуктом, который предлагается в качестве базовой инженерной утилиты. GitHub вряд ли будет настойчиво монетизировать Actions, а если что-то изменится, мы всегда сможем перейти на решение с открытым исходным кодом. Объединение контроля исходного кода и CI также является очевидной победой. Мы можем писать произвольно сложные скрипты с контролем потока управления и должностными инструкциями в соответствии с нашими меняющимися потребностями.
Вот как выглядит запуск задания:
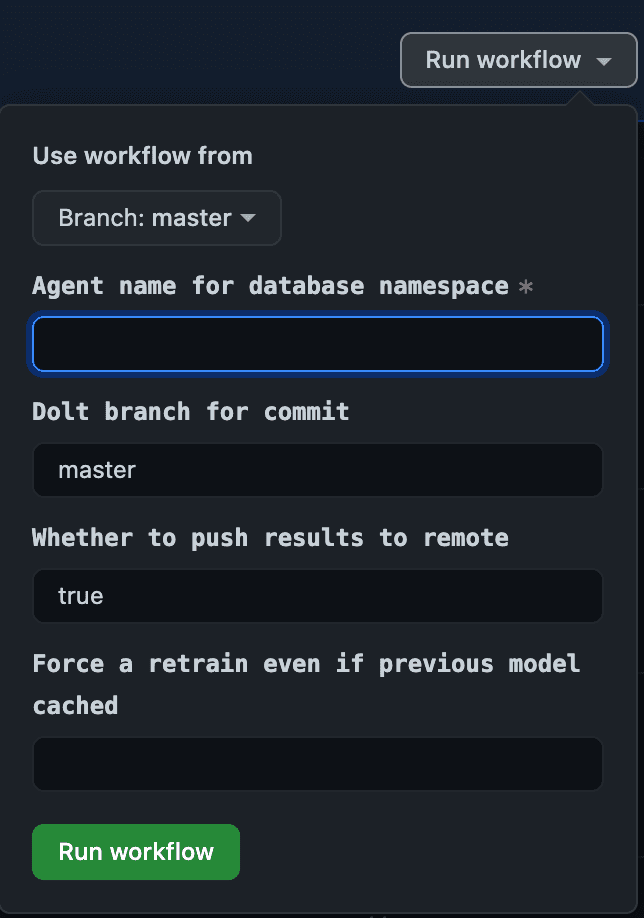
А вот как происходит агрегация журналов во время и после выполнения задания:
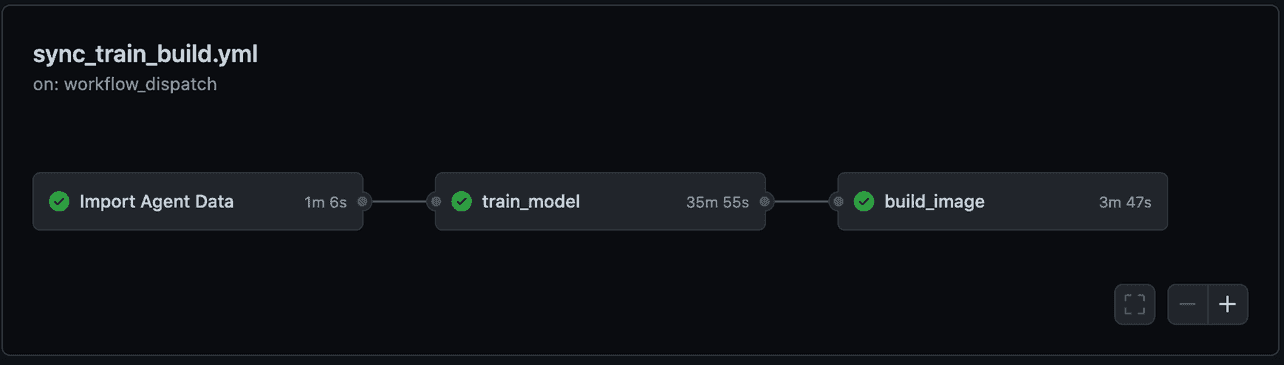
Далее мы решили продолжить использовать MLflow для хранения метаданных обучения. GitHub сохраняет версии кода, Dolt сохраняет версии данных, а MLflow тегирует модели соответствующими версиями коммитов.
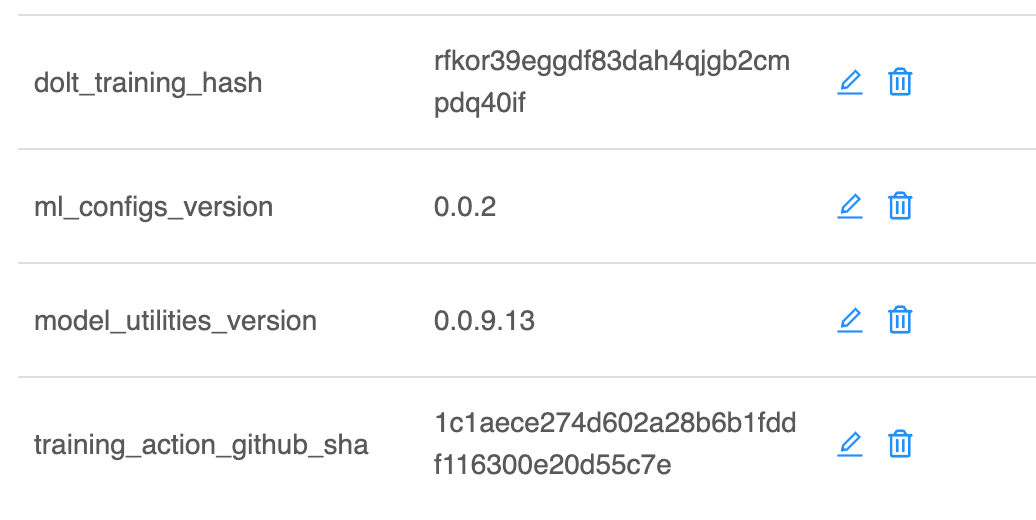
MLflow - хороший выбор, поскольку это узконаправленная библиотека протоколирования с открытым исходным кодом, которая охватывает все этапы процесса обучения. Экспериментальный трекер с лучшим пользовательским опытом может быть заменен на новый без изменения других компонентов системы.
Ведение учета выпусков для продакшна создает еще одну проблему для нашего партнера. Образы Docker для продакшна включают модели адаптеров по каждому из клиентов. Другими словами, как нам отследить 100 версий моделей адаптеров для каждого релиза? Вместо того чтобы создавать вторую базу данных, мы воспользовались бэкендом MLflow. Имена и версии моделей кодируются в виде json-строки, хешируются MD5 и вставляются в наш бэкенд:
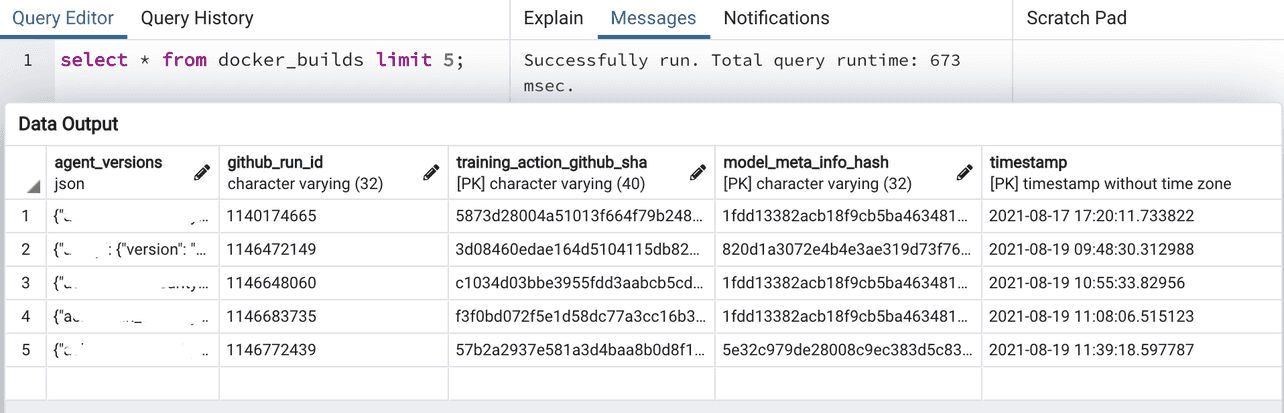
Образ Docker тегируется хэшем, сопровождающим версии модели. Если нам нужно откатиться к предыдущей коллекции моделей, то можно использовать ранее созданный образ. Для отката на одну версию модели мы воспользуемся MLflow API, чтобы тегнуть "последнюю рабочую модель" и создать новый образ.
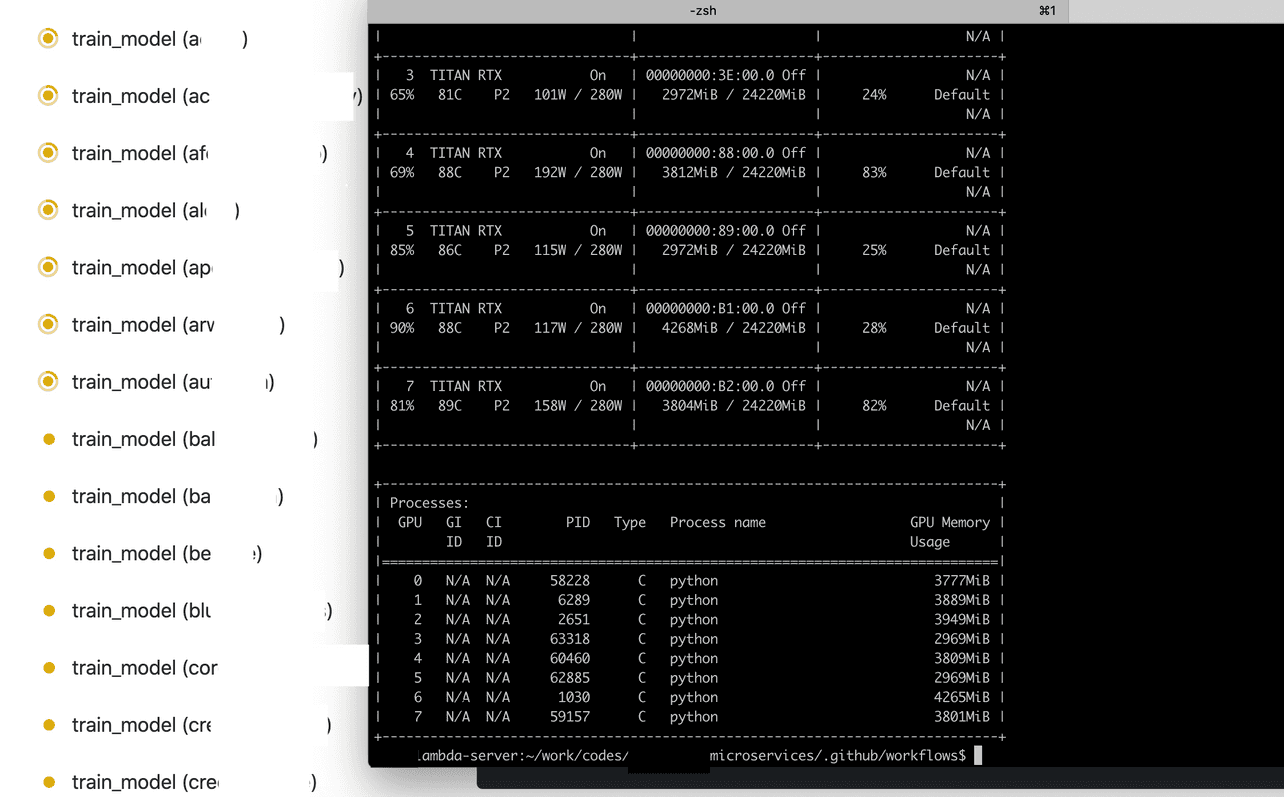
Вот система, работающая на полную мощность:
Ценообразование в SaaS
Стоимость зависит от рабочей нагрузки и выбора поставщика услуг. Наш партнер уже приобрел локальные GPU, что является неокупаемой затратой. Ближайший сопоставимый экземпляр AWS стоит гораздо дороже в год, но не требует обслуживания оборудования. Ближайший сопоставимый инстанс Pachyderm предусматривает доплату за каждый расчетный час при использовании услуг, входящих в состав платформы. Стоимость другой платформы, DataRobot, начинается примерно от $100 тыс. в год за 6 рабочих инстансов. Вот краткое изложение наших выводов:
способ вычисления |
фиксированный платёж |
переменный платёж |
платёж за 1 год |
платёж за 2 года |
самостоятельно |
30,000 |
3600 |
33,600 |
37,200 |
aws |
0 |
43,083 |
43,083 |
86,166 |
pachyderm |
0 |
67,738 |
67,738 |
134,756 |
datarobot |
0 |
98,000 |
98,000 |
196,000 |
Цифры AWS и Pachyderm могут быть репродуцированы на соответствующих им страницах с ценами. В каждом случае мы выбрали наиболее похожий вычислительный инстанс: AWS p2.8xlarge — 8 GPU/32 CPU/488 ГБ, а Pachyderm — 8 GPU/16 CPU/23 ГБ. Фиксированные затраты на самостоятельное размещение - это стойка для GPU, а переменные — это база данных, размещенная в облаке (RDS/Dolt).
Здесь важно не сравнивать между собой абсолютно разные вещи. Биллинг в облаке основан на фактическом использовании, а вы редко используете 100% зарезервированных часов вычислений. Аналогичным образом, офисное оборудование не масштабируется так же, как облачные кластеры Kubernetes. Тем не менее, счета за облачные услуги часто выходят из рамок сметы. Дробно используемые ресурсы выставляются как целые счета. При повторном запуске недельных учебных заданий используется больше CPU-часов, чем вы ожидаете. Оборудование наших клиентов было невозвратными затратами, и им придется платить мало ежемесячных счетов, до тех пор пока либо оно не выйдет из строя, или не произойдет 10-кратное масштабирование. Ситуация в ходе процесса может меняться.
Баланс оптимального качества работы
Используя инструменты с открытым исходным кодом, вы сами определяете свою дальнейшую судьбу. Для нетехнической команды это может быть обузой. Передача инфраструктурных рисков на аутсорсинг того, что не играет ключевой роли для вашего бизнеса, может показаться удобным. Однако организационные привычки срастаются с корпоративным программным обеспечением таким образом, что становится трудно менять системы в будущем.
Наш партнер может заменить Dolt устаревшей базой данных MySQL, или DVC, если набор наших данных для обучения неструктурирован; или на Delta Lake для команды с данными только для добавления. В определенный момент они масштабируются, но отсрочка усложнения Kubernetes позволит им как можно скорее сосредоточиться на бизнес-целях.
В будущем появятся новые ML-инструменты, для которых абстрактные модели неизбежно конвергируются. Альтернативы, улучшения и обновления для вашего бизнеса всегда под рукой, если вы это планируете.
Заключение
Рынок ML-платформ запутан, быстро меняется и полон сложными вопросами. Трудно количественно оценить бизнес-ценность одной единицы инфраструктуры ML. С другой стороны, теперь можно планировать эту неопределенность. Создание более дешевых, гибких систем, которые лучше приспосабливаются к изменениям, позволяет избежать “подводные камни” корпоративных SaaS-систем. Здесь мы описали пример одной модульной платформы с открытым исходным кодом.
Наш партнер использует GitHub Actions для планирования, выполнения и воспроизведения рабочих процессов на пользовательском оборудовании. Они поддерживают как задания на базе CPU, например, синхронизацию данных аналитиков в реляционной базе данных Dolt, так и задания на GPU, например, параллельное обучение 100 NLP-моделей. Метаданные отслеживаются в два этапа: один раз для каждой модели и второй раз для каждой коллекции моделей, упакованных в продакшн-релиз. Каждый из выбранных инструментов может быть изменен с течением времени. Система может вырасти до поддержки 1000 моделей адаптеров без изменения способа версионирования кода, моделей и данных.
Быстрая проверка гипотез — это одна из главных стратегий, способных сделать стартап успешным. Она позволяет чаще получать обратную связь от инвесторов, за счет возможности быстро разрабатывать простые прототипы сервисов, частично реализующих функционал проекта.
Приглашаем на открытое занятие, на котором мы рассмотрим полный цикл разработки прототипа ML-сервиса, начиная от обучения модели на собранном датасете, заканчивая развертыванием его в виде web-приложения.
ivankudryavtsev
Сумбурный, низкокачественный перевод.