
Автор этого материала — программист и ML-инженер — собрала Open Source библиотеки Python, которые помогут вам сделать данные лучше, чтобы избежать траты времени и упростить анализ данных. Подборкой делимся к старту курса по анализу данных.
Профилирование и оценка
Разведочный анализ данных
1. Pandas Profiling
Pandas Profiling генерирует отчёт о профилировании фреймов данных Pandas.
Основные функции:
Профилирование данных: недостающие и уникальные значения и т. д.
Распределения данных и гистограммы.
Квантильная и описательная статистика: среднее значение, стандартное отклонение, Q1 и т. д.
Выведение типа данных.
Взаимодействия и корреляции данных.
Создание отчёта в HTML.
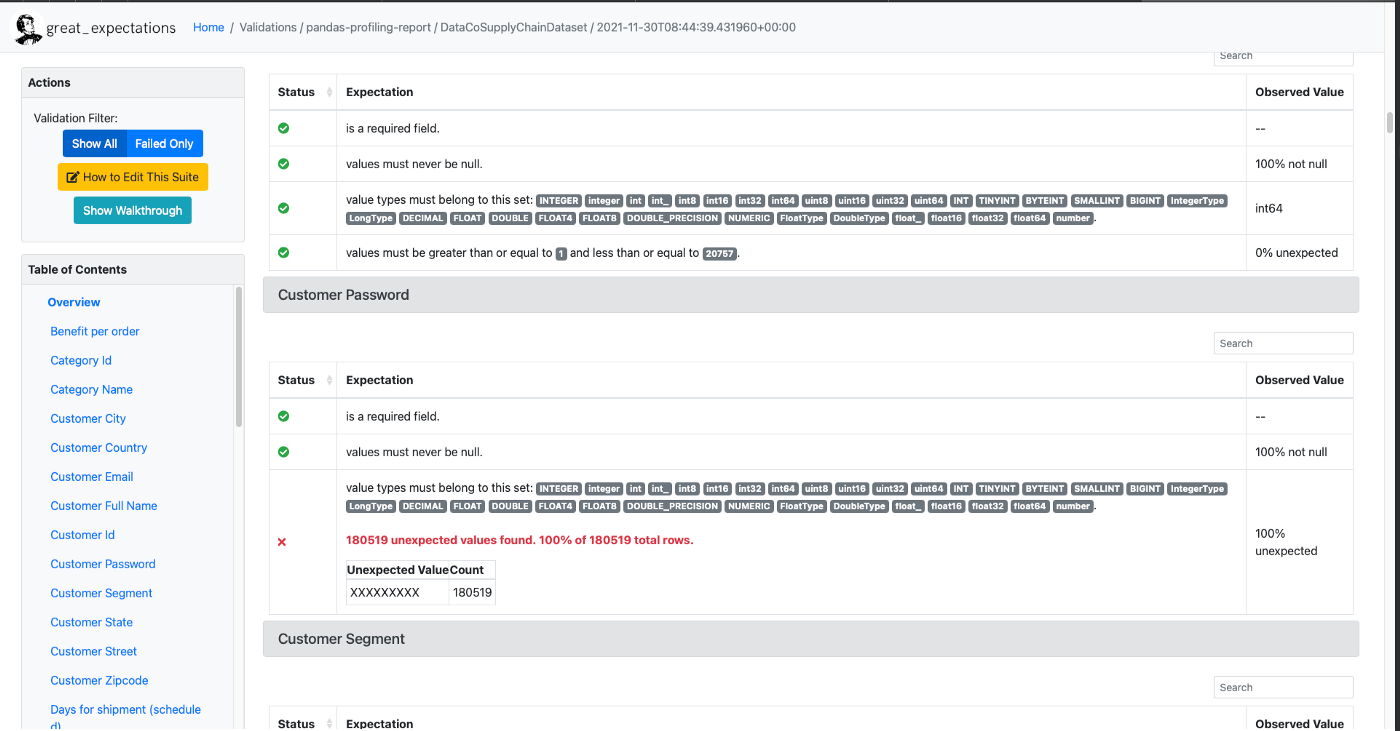
2. Great Expectations
Great Exception основана на ассертах данных из библиотеки Expectation. Это общедоступный, открытый стандарт качества данных, помогающий командам Data Science устранять недоработки конвейера данных, выполняя их тестирование, документирование и профилирование.
Основные функции:
Декларативные тесты данных на:
ожидаемое количество строк в таблице — от x до y;
ожидаемое число недостающих значений не превысит 20%;
ожидаемый формат даты в столбцах — MM-DD-YYYY;
дополнительные конструкции «из коробки»: уникальность, отклоняющиеся значения и другие характеристики данных;
пользовательские ожидания.
Другие функции:
Автоматическое профилирование данных.
Визуализация тестов в удобных для человека формах и документах.
Интеграция со многими инструментами и системами: Pandas, Jupyter Notebook, Spark, mysql, databricks и т. д.;

3. SodaSQL
SodaSQL — это инструмент командной строки, выполняющий SQL-запросы на основе входных данных. Вот что он делает:
Запускает тесты на разных наборах данных в разных источниках данных: Snowflake, PostgreSQL, Athena, и т. д., ищет недопустимые или недостающие данные.
Собирает метрики: минимальные, максимальные и средние значения, стандартное отклонение и многие другие метрики.
Основные функции:
Пользовательские тесты на SQL.
Определение тестов для каждой таблицы в формате yml.
Интеграция с инструментом оркестрации данных.
Подключение и сканирование наборов данных.
Определение формата столбцов: электронная почта, дата, номера телефонов и т. д.
Сохранение результатов сканирования в JSON.
Прогнозная аналитика
4. Ydata
Ydata оценивает качество данных конвейера данных на разных этапах его разработки. Она помогает составить целостное представление о данных, рассматривая их с разных точек зрения на предмет:
недостающих значений;
дублирования данных;
отклоняющихся значений и дрейфа данных;
отношений данных и корреляции данных.
Библиотека интегрируется с Great Expectations, в которой запускаются ассерты данных, позволяющие проверять, профилировать данные и автоматически генерировать отчёты:
5. DeepChecks
DeepChecks — это пакет Python, позволяющий легко проверять модели ML и связанные с различными задачами данные, например производительность модели; также DeepChecks обнаруживает:
значения null;
дублирование данных;
изменения частотности;
специальные символы и т. д.;
Библиотека сравнивает строки, обнаруживает их несоответствия. Она видит следующие характеристики данных:
смещения в распределении;
важность признаков.
Целостность данных и обнаружение смещения пригодятся при тестировании данных.
Работая с данными для обучения модели, тестовыми данными и текущими фреймами данных, можно воспользоваться набором тестов SingleDatasetIntegrity или специальными тестами из других наборов.
В DeepChecks можно писать свои тесты и их наборы, красиво отображая результаты в таблице или на графике Plotly:
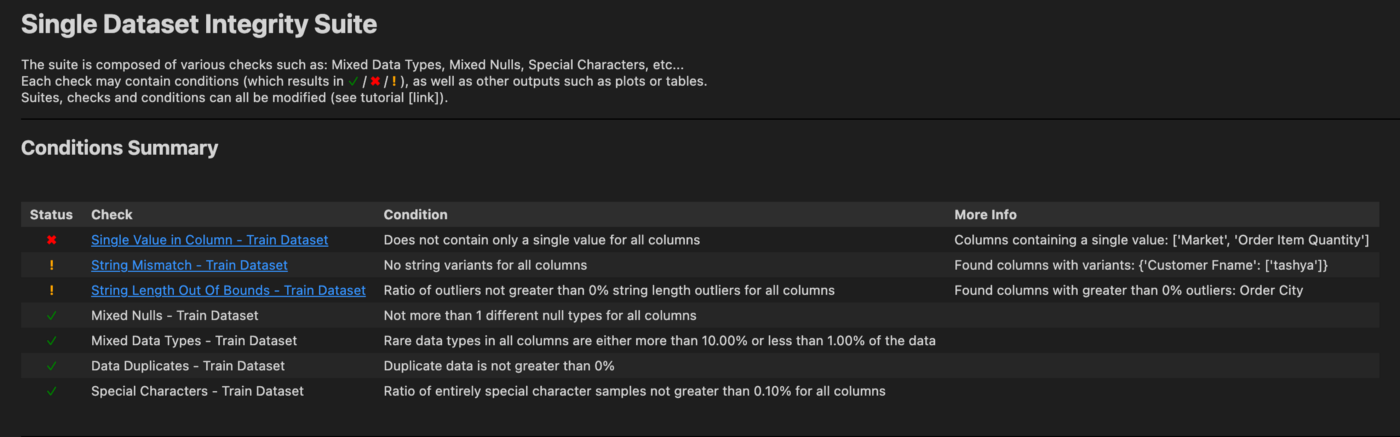

6. Evidently AI
Evidently AI — это инструмент для анализа и наблюдения за моделями ML.
Библиотека видит:
Распределение данных.
Дрейф данных.
Производительность модели.
Работоспособность модели.
Evidently AI интегрируется с Grafana и Prometheus, можно создать пользовательский дашборд.

7. Alibi Detect
Alibi Detect — специализированная библиотека ML для обнаружения отклоняющихся значений (выбросов), состязательности и дрейфа данных.
Основные функции:
Обнаружение дрейфа и отклоняющихся значений в табличных данных, тексте, изображениях и временных рядах.
Обнаружение с предварительно тренированным и нетренированным детектором.
Поддержка бэкендов TensorFlow и PyTorch для обнаружения дрейфа.
Очистка и форматирование данных
1. Scrabadub
Scrabadub — это инструмент выявляет и удаляет из любого текста личную информацию: имена, номера телефонов, адреса, номера кредитных карт и т. д. Можно реализовать собственные средства обнаружения данных:
text = "My cat can be contacted on example@example.com, or 1800 555-5555" scrubadub.clean(text)
>>'My cat can be contacted on {{EMAIL}}, or {{PHONE}}'2. Arrow
В Arrow реализован разумный, удобный подход к созданию, обработке, форматированию и преобразованию дат, времени и временных меток:
utc = arrow.utcnow()
time= utc.to('US/Pacific')
past = time.dehumanize("2 days ago")
print(past)
>> 2022-01-09T10:11:11.939887+00:00
print(past.humanize(locale="ar"))
>> 'منذ يومين'3. Beautifier
Beautifier — библиотека для очистки шаблонов URL и адресов электронной почты. Она позволяет:
Проверить корректность электронного адреса.
Анализировать электронные письма по домену и имени пользователя.
Анализировать URL по доменам и параметрам.
Очистить URL от символов Unicode, специальных символов и ненужных шаблонов перенаправления.
4. Ftfy
Ftfy расшифровывается как Fixes text for you («Исправляет текст для вас»). Вот её функции:
Исправление текста с неподходящими для языков разметки символами Unicode.
Удаление разрывов строк.
Преобразование HTML-сущностей в обычный текст.
Выявление текста с вероятностью искажения из-за неверной кодировки.
Объяснения того, что произошло с текстом.
ftfy.fix_text('The Mona Lisa doesn’t have eyebrows.')
>>"The Mona Lisa doesn't have eyebrows."5. Dora
Dora — это инструментарий разведочного анализа данных для Python.
Основные функции:
Очистка данных от "null", преобразование из категориальных данных в порядковые данные, преобразование данных в столбцах и удаление столбцов.
Выделение и извлечение признаков.
Отображение признаков на графике.
Разделение данных для валидации модели.
Преобразования данных с их версионированием.
Для работы многих функций, включая графики, данные должны быть числовыми.
6. DataCleaner
Data Cleaner автоматически очищает наборы данных и подготавливает их к анализу.
Основные функции:
Удаление строк с пропущенными значениями.
Замена отсутствующих значений.
Кодирование нечисловых переменных.
Работа с фреймами данных Pandas.
Работа в скриптах и в командной строке.
Предварительный просмотр таблиц
1. Tabulate
Вызов одной функции Tabulate выводит небольшие, красивые таблицы.
Основные функции:
Удобные для восприятия таблицы.
Форматирование таблиц в HTML и других форматах.

2. PrettyPandas
PrettyPandas — инструмент с простым API, генерирующий достойные табличные отчёты. Они хорошо воспринимаются благодаря:
добавлению итоговых строк и столбцов;
форматированию чисел валют и процентов.

На сегодня всё. Попробовать все эти инструменты в деле вы сможете на наших курсах. А мы поможем вам прокачать навыки или с самого начала освоить профессию в IT, востребованную в любое время:
Выбрать другую востребованную профессию.

Краткий каталог курсов и профессий
Data Science и Machine Learning
Python, веб-разработка
Мобильная разработка
Java и C#
От основ — в глубину
А также