
В прошлой статье я рассказал, как мы пришли к DDD и про его очень важную особенность — единый язык, на котором легче и дешевле разговаривать с бизнесом. Еще мы рассмотрели разработку, ведомую моделью. Когда вначале стоит не выполненная по требованию фича, а абстрактная модель, созданная по требованиям и имеющая отражения в различных представлениях. Все эти области оперируют терминами единого языка и реализованы максимально похожими, чтобы каждый, кто будет работать с проектом, смог разобраться в любой из них.
Сегодня поговорим о том, как приручить непосредственно исходные коды программ, как они архитектурно представляются. Расскажу про идеи, которые мы используем для построения прозрачной и понятной модели, чтобы ее было легко развивать вместе с заказчиком. Эти подходы касаются и архитектуры, и хранения исходного кода, и вообще в целом вопросов разработки. Также расскажу про практические сложности. Формат статьи не позволяет включить огромное количество кейсов, поэтому приведу только два примера.

DDD и микросервисы: взаимодополняющие подходы
Самое неприятное в микросервисной архитектуре — это когда вы понимаете, что вы разделили микросервисы неправильно и нужно делить их еще раз. Это очень дорого и очень болезненно. DDD позволяет сделать так, чтобы этого не происходило. Поэтому микросервисная архитектура и DDD взаимно дополняют друг друга.
Потому что, с одной стороны, есть верхнеуровневая идея, о которой сейчас в индустрии много говорят. О том, что, если вы начинаете использовать предметно-ориентированное проектирование и действительно думаете над разделением на ограниченные контексты с правильным формированием агрегатов и наведением границ между контекстами и агрегатами — то вам будет легко дробить систему на микросервисы.
С другой стороны, если вы хотите сделать микросервисы, то обязательно услышите про предметно-ориентированное проектирование. Потому что это один из лучших способов разделения системы на микросервисы. Это вертикальное разделение, дальнейшее дробление и разделение на фичи, которое, в том числе, и мы у себя используем. Можно сказать, что DDD открывает путь, чтобы разделение на микросервисы было качественным.
Я расскажу про DDD применительно к микросервисам. Потому что про монолиты сказано много, а для микросервисов материалов меньше. Именно из-за популярности микросервисной архитектуры DDD переживает такой подъем. По сути без терминов DDD сейчас невозможно объяснить, как поделить код на вертикальные сервисы. Мы сами используем микросервисную архитектуру, в том числе на вновь запускаемых проектах. Мы можем себе позволить, так как проработали инфраструктуру, у нас есть накопленные доменные знания, выделены контексты и агрегаты.
Разделение кода
Когда мы начинали работать над нашим приложением, у нас был один большой репозиторий. В нем хранились коды, связанные с приложением UI, бизнес-логикой и сервисным слоем, а также функционал, связанный с инфраструктурным уровнем. Возможно, нам несколько повезло, потому что наша инфраструктура, благодаря коллегам, которые были до нас, уже была достаточно независимо от бизнес-кода.
Тем не менее работа с одним большим монолитным репозиторием мешала нам делать переход от монолита к микросервисам. Очень велика была вероятность, что вновь созданный микросервис быстро станет связанным общей бизнес-логикой с монолитом и потеряет свою функцию отдельного независимого приложения.
Поэтому мы хотели провести некоторые границы и готовились выделять некоторые части решения в отдельные репозитории. И тут у нас появилось отдельное приложение от внешнего вендора, на которое мы решили смаппить нашу инфраструктуру. Но потом это пошло дальше и дальше. В итоге получилась такая ситуация:
Исходные коды новых микросервисов начали выносить в отдельные репозитории,
В старом репозитории оставались основные исходные коды приложения,
Инфраструктуру, чтобы не копировать, вынесли в пакеты и положили в наше хранилище в Artifactory внутри банка.
Таким образом, благодаря союзу DDD с микросервисами, фактически еще на самом старте мы разделили подход для работы с исходными кодами на подход инфраструктурный и подход бизнес-логики. И на наш взгляд это правильно — у них несколько разные цели и задачи. Опишу, какие подходы мы используем в разных частях решения.
BL (бизнес-логика)
Именно здесь для нас основное место применения тактических паттернов DDD, потому что мы хотим применять их не везде, а только там, где действительно нужна максимальная гибкость. Мы фокусируемся на атрибуте качества модифицируемость или гибкость, чтобы поддержать историю с беспрерывными новыми требованиями, которые мы вынуждены вносить в наш продукт.
Код бизнес логики — это доменная модель и аппликационный слой use cases. В написании бизнес-логики мы избегаем наследования, стараясь максимально заменять его композицией. Стараемся избегать любых подходов, которые вносят дополнительную жесткость (паттерны проектирования GoF, наследование, автогенерированный код).
Аппликационный слой мы разбиваем на небольшие функции. Это позволяет работать с функциями независимо: заказчик захотел фичу — включили её в поставку, не захотел — не включили. Любой компонент очень легко удалить без модификации исходного кода.
Вообще это выглядит, как будто подход с микросервисами переносится прямо на уровень внутрь сервиса: есть вертикальное разбиение по бизнес-логике на уровне микросервисов и есть вертикальное разбиение внутри микросервисов. Это характерно для очень многих индустрий и областей знания, когда подходы с высокого уровня переносятся на более низкий.
IL (инфраструктура)
Здесь у нас всё наоборот — разработка по DDD не затрагивает вопросы инфраструктуры, этот слой хочется делать более жестким, поскольку не так много причин для его изменения. Инфраструктурная логика позволяет программам запускаться и выполнять свои обязанности.
Поэтому инфраструктурной части фокус смещается с модифицируемости на производительность, переиспользуемость и защищенность. Инфраструктура как бы охраняет гибкую красивую доменную модель от внешнего мира.
И раз он должен быть максимально переиспользуемым, в нем мы применяем все лучшие практики проектирования, изобретенные индустрией. Это паттерны «Банды четырех» (GoF), SOLID, DRY, мелкое дробление классов, различные принципы вроде dom3.
Архитектура микросервиса
В том, как у нас выглядит микросервис, написанный по DDD, нет ничего удивительного. Мы используем луковую архитектуру, стараясь следовать домен-центричному принципу, когда в центре программы находится не слой доступа к данным, а доменная модель:
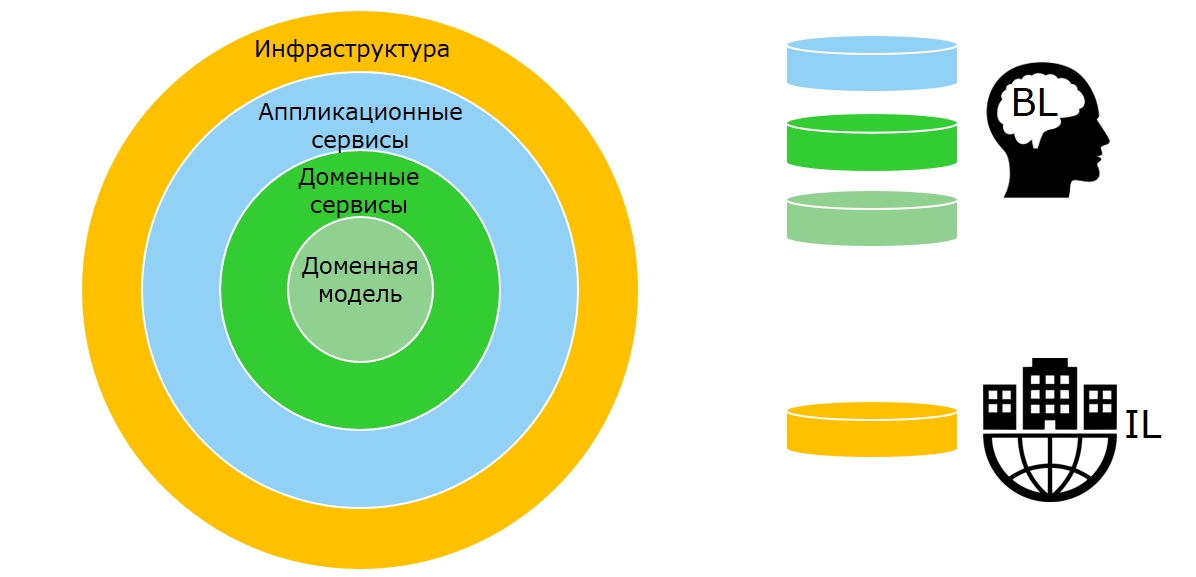
Луковая архитектура микросервиса. Внутренние слои относятся к бизнес-слою, внешний — к инфраструктуре.
То есть, как я уже говорил, ситуация внутри нашего микросервиса несколько схожа с той, что складывается на инфраструктурном уровне, когда вы делаете микросервис:

Аппликационная логика разбивается на отдельные небольшие хэндлеры, и чтобы перенаправлять команды и запросы к ним, мы используем медиатор. Все эти хэндлеры, которые описывают use cases, опираются на одну и ту же доменную модель, чтобы иметь возможность именно в доменной модели полностью поддерживать согласованное состояние и инварианты.
Инфраструктура имеет обслуживающую функцию. Она связывает доменную модель, как основную ценность, с различными инфраструктурными компонентами.
Общий код
Микросервисы у нас лежат в разных репозиториях, и нам очень хотелось сделать их похожими друг на друга. Вполне логично, что раз появились пакеты, связанные с инфраструктурой, и мы переиспользуем инфраструктуру от одного сервиса к другому — у нас возникла идея двигать общий код и дальше.

Этот общий код охватывает все слои нашего приложения. У нас есть сборки в инфраструктуре, которые помогают нам работать на уровне предметной области. Есть сборки, которые работают на уровне аппликационных хэндлеров либо других вариантов служб. И конечно — сборки, которые повторяют непосредственно инфраструктуру.
В итоге мы сначала запилили выделенный DDD-фреймворк, чтобы быстрее запускать новые микросервисы внутри организации, а потом вынесли его в open source. Фактически у нас получилось микросервисное шасси ViennaNET:

Основной язык, на котором мы разрабатываем — C#, работаем мы в инфраструктуре .net. К сожалению, у нас нет такого средства, как, например, в Java-мире, которое позволяло бы не думать о том, какую основу мы будем использовать для запуска наших микросервисов. Поэтому такие микросервисные шасси часто можно встретить на GitHub. Они не очень популярные, но мы решили пополнить список этих библиотек, выложив свою версию.
Доменный слой
В работе с доменным слоем у нас есть некоторый код, который поддерживает работу с доменными событиями — сущностями, спецификациями и валидацией. Мы сделали отдельный фреймворк валидации на основе одного из популярных фреймворков, которые есть в .net-мире.
Сущность
Пример кода сущности:
public class Card : IEntity<int>, IEventProvider
{
private IEventCollector _eventCollector;
...
public virtual void AddBlock([NotNull] BlockDetails blockDetails)
{
...
_eventCollector.CollectEvent(new CardBlocked(Id, blockDetails));
}
public virtual void SetCollector(IEventCollector sender)
{
_eventCollector = sender;
}
}В коде представлена сущность, в которой есть:
Интерфейсы, которые определяют ее как сущность;
Интерфейсы, которые определяют, что эта сущность может работать с событиями;
Дополнительные методы, которые позволяют инфраструктуре наполнить сущность средствами работы с инфраструктурными событиями.
Аппликационный слой
Здесь у нас сосредоточены в основном интерфейсы, которые позволяют работать с различными аспектами инфраструктурного уровня: шина сообщений, медиатор, интерфейс обмена сообщениями и вещи, которые касаются кэширования.
Типичный пример, как выглядит у нас какой-нибудь хэндлер в аппликационном слое:
Спойлер
public async Task<BlockResult> HandleAsync(BlockCardRequest dataRequest,
CancellationToken token)
{
using (var uow = _entityFactoryService.Create())
{
var card = await _entityFactoryService.Create<Card>()
.GetAsync(dataRequest.Id, token);
var result = await card.BlockCardAsync(request.Reason, token);
await uow.CommitAsync(token);
return result;
}
}Он содержит единицу работы, чтобы поддерживать транзакционность, и работает уже непосредственно с объектами доменного слоя. В данном примере, например, блокируется карта.
Инфраструктурный слой
Здесь у нас основная реализация, основное наполнение библиотек и различные функциональные возможности для работы с внешней инфраструктурой. В том числе, и реализация интерфейса, который используется на аппликационном уровне.
Если вам необходима поддержка DDD в вашем проекте, и этот проект состоит из большего числа сервисов, чем один, то, думаю, подобная идея будет возникать и у вас — повторить инфраструктуру, отделить ее и попытаться сделать так, чтобы эта инфраструктура подталкивала пользователя к программированию, к проектированию именно в рамках тактических шаблонов DDD.
Таким образом сервисы можно писать быстрее, они становятся единообразными. Причем, если этот фреймворк выложить хотя бы в качестве Inner Source, не говоря уже про Open Source, то сервисы будут единообразными на уровне разных команд. Инфраструктура становится единой, и можно прямо на основе этого строить внутреннее сообщество.
Например, у нас очень много вопросов внутреннего сообщества разработчиков связано с тем, как мы будем этот фреймворк дорабатывать, и как он будет выглядеть. Все, кто делают микросервисы и использует фреймворк, тяготеют к использованию DDD. И все они хотят иметь возможность не писать заново всю инфраструктуру.
Посмотрим теперь, какие сложности могут вас ожидать.
Сложность: Связь между контекстами
Первая сложность — какую связь между контекстами выбрать при использовании микросервисов. При этом, если посмотреть на архитектуру предприятия выше, то окажется, что взаимосвязь между контекстами имеет смысл. И точно также, как она имеет смысл между микросервисами внутри одного приложения, она имеет смысл, когда есть несколько команд, несколько приложений — уже на энтерпрайз-уровне. Можно сказать, что DDD тем и хорош — он очень хорошо реагирует на такие новые вызовы.
Реализовать общий функционал
Эта задача может быть как для двух сервисов (например, внутри вашего проекта), так и для двух команд внутри вашего предприятия. Стандартным подходом к интеграции, которое предлагает DDD — это подход с разделяемым ядром, когда вы хотите какую-то часть кода поддерживать вместе.
Наиболее типичный подход к этому — разработать общий микросервис. Именно в микросервисной архитектуре это будет наиболее логично выглядеть и позволит в дальнейшем согласованно вносить в него какие-то изменения и предоставлять функционал через API:

Более классический подход — сделать отдельную библиотеку и использовать ее в двух различных приложениях либо в двух различных микросервисах:

У нас был опыт такого использования, причем крайне неудачный, когда речь касалась бизнес-логики. Если вы добавляете сущность, агрегаты, даже объекты-значения с каким-то поведением, то считайте, что находитесь на хорошем, стабильном пути к распределенному монолиту. Поэтому я бы не рекомендовал так делать. Если вам нужно действительно какой-то общий функционал реализовать, то сделайте это в микросервисе.
Но если вам нужно что-то реализовать, что не имеет поведения — например, стандартные типы внутри приложения, микротипы, в которых есть небольшая валидация, но она явно не тянет на отдельный сервис — то вы вполне можете сделать общую библиотеку. В отличие от серьезной большой библиотеки с бизнес-логикой, это не принесет вам головной боли.
Вообще Shared Kernel в микросервисной среде в классическом виде — это, конечно, использование отдельного сервиса, который, например, две команды вместе поддерживают.
Получить доступ к функционалу другой команды
Это еще одна задача, которая встает перед разработчиком тоже очень часто. DDD предлагает использовать какой-то из подходов upstream/downstream:

Конечно, когда у вас заказчик-поставщик либо конформист, вы можете использовать любой из этих подходов (либо вам навяжут один из них). Но обычно такая интеграция между двумя командами внутри микросервисной среды чревата тем, что вам придется задуматься о версионировании внутреннего API, что может быть достаточно неприятной идеей.
Поэтому чаще при интеграции систем встречается более распространенный подход, использующий какие-то слои МЕЖДУ. Это уже соответствует шаблону Anticorruption layer, и распространенным вариантом такого слоя является корпоративная шина данных:

Думаю, коллеги, которые работают в больших компаниях, знают об этом. У многих есть такие корпоративные шины данных, а в них — канонические модели и преобразователи. Всё это позволяет развязать ваше приложение, но, естественно, посредники назначают за это некоторую цену.
Также распространенным паттерном является не использовать единую шину данных или единый проект, а сделать просто адаптер внутри каждой системы:

В микросервисной среде эти адаптеры часто представляются теми же микросервисами. У них API уже версионируется, и они защищают систему от взаимодействия с внешним миром. Такой подход мы тоже активно используем. Он доказывает свою эффективность, хотя, естественно, есть накладные расходы на написание дополнительного кода.
Получить доступ к данным другой команды
Это третья задача, которая возникает при интеграции микросервисов либо приложений при взаимодействии различных команд. Здесь вам уже не нужна бизнес-логика и функционал, а просто нужно сделать так, чтобы данные из какого-то источника попадали к вам и вы могли ими пользоваться.
Наиболее распространенный подход — те же Separate ways, когда две команды, два микросервиса начинают жить совершенно параллельно и вообще не пересекаются ни с точки зрения зависимостей от других сервисов, ни с точки зрения общих библиотек. Они просто получают подписку, например, на какой-то топик, складывают данные к себе и живут независимой жизнью:

Внутри микросервисного приложения такой подход встречается не очень часто, но на уровне энтерпрайз-архитектуры это, наоборот, очень распространенная практика, и она позволяет командам действительно вести независимую разработку.
Если посмотреть на взаимодействие контекстов, то DDD предлагает понятные паттерны для этого, и в микросервисной среде они тоже имеют несколько вариантов стандартного оформления, которые я здесь описал. Если в вашей компании есть другие варианты, было бы интересно их обсудить.
Сложность: Логика между слоями
Эта проблема о том, как разделить логику между слоями, и касается она организации сервиса внутри. Предметно-ориентированно проектирование здесь дает набор тактических паттернов, которые позволяют написать сервис красиво, гибко, модифицируемо — и при этом получить максимальную возможность его в дальнейшем развивать.
Распределение логики
Вопрос, который часто волнует людей, непосредственно связанных с разработкой — какую логику положить в аппликационный сервис, а какую — в доменный сервис либо в доменный слой вообще?
DDD говорит нам об этом довольно верхнеуровневые абстрактные вещи. Например, use case кладите в аппликационный сервис, а код, связанный с принятием решений, важных для вашей подобласти, вашего ограниченного контекста — в доменный. Что это значит, каждый решает по-своему. Расскажу, какие подходы сложились у нас.
Вначале мы, конечно, делали не так. Это некоторый свод правил, который появился на основе проб и ошибок. Меня очень порадовало, что он практически полностью совпал со рекомендациями Microsoft в 2018 году, как создавать микросервисы.
Наши разработчики, если нет принятия решений, кладут код в аппликационный сервис. Пример кода, где нет принятия решений:
Спойлер
public BlockResult BlockCard(int cardId, BlockDto blockDto)
{
if (cardId <= 0)
return new BlockResult("Card id must be greater than zero");
if (blockDto == null);
return new BlockResult("Block details must not be null");
var repository = _entityRepositoryFactory.Create<Card>();
var card = repository.Get(cardId);
if (card == null)
return new BlockResult("Card does not exist");
_accountsService.LockAccount(card);
card.BlockCard(blockDto.ToDetails());
...
}Мы просто делаем небольшую валидацию внешних приходящих метод-зависимостей, достаем сущность из репозитория и вызываем метод доменного сервиса и метод сущности. Мы никак не зависим от того, что эти методы, например, надо возвращать. Поэтому можноо сказать, что здесь не происходит никакого принятия бизнес-решения.
Если принятие решений есть, то разработчики кладут этот код в доменный слой, то есть делают отдельную доменную службу:
Спойлер
public class BlockingService : IBlockingService
{
...
public BlockResult BlockCard(Card card, BlockDetails blockDetails)
{
var result = _accountsService.LockAccount(card);
if(result.HasErrors())
{
return new BlockResult(result.GetErrorMessage());
}
card.BlockCard(blockDetails);
}
}В отличие от предыдущего примера здесь происходит блокировка счета, и ее результат влияет на то, будет ли дальше заблокирована карта. Это уже тянет на бизнес-логику, поэтому хотелось бы, чтобы она не уплывала в аппликационный сервис, потому что, как минимум, это может переиспользоваться от use case к use case.
Третий вариант — когда код настолько тесно связан с инфраструктурой, что просто не получается скрыть технический аспект — встречается также довольно часто. Тогда как внутри доменной модели мы хотим вообще не думать об инфраструктуре. И вообще желательно, чтобы пользователь, читая код доменной модели, не до конца понимал, что же происходит на инфраструктурном уровне.
Типичный пример, который можно привести в этом случае:
Спойлер
using(var session = _externalCardSessionFactory.CreateSession(card))
{
var context = _cardContextFactory.Create(card);
card.DoSomeStaff(context);
if (card.HasSomeConditions())
{
var batchResult = session.Commit(card);
if(batchResult.HasErrors())
{
card.DoErrorStaff(batchResult);
return;
}
card.DoFinalStaff(batchResult);
}
}Это ситуация, когда у вас есть объект типа сессии и он требует выполнения последовательных действий в зависимости от того, какие происходят изменения в бизнес-логике. То есть фактически вы ведете внешнюю систему синхронизировано с вашей системой по определенному бизнес-шаблону.
Так как эту сессию спрятать очень сложно, то такой код я бы поместил именно в аппликационный слой. Хотя здесь есть принятие решения в зависимости от состояния сущностей, этот код очень редко переиспользуется — поэтому, скорее всего, он будет только в одном месте вашей программы.
Еще лучше, если вам удается скрыть инфраструктуру за отделенным интерфейсом, реализовав принцип Dependency Inversion, о котором говорил Роберт Мартин:
Спойлер
public class BlockingService : IBlockingService
{
...
public BlockResult BlockCard(Card card, BlockDetails blockDetails)
{
var result = _accountsService.LockAccount(card);
if(result.HasErrors())
{
return new BlockResult(result);
}
card.BlockCard(blockDetails);
}
}Тогда вы спокойно можете реализовать взаимодействие именно с инфраструктурой, например в доменном сервисе, закрыв таким образом за интерфейсом блокировку счета. Или это может быть поход в отдельный сервис либо в очередь в зависимости от технической реализации.
Технические оптимизации
Также мы кладем в аппликационные сервисы технические оптимизации. DDD часто ругают за то, что она очень медленная. Но она не будет медленной, если вы будете, например, получать все данные до того, как они будут попадать в доменный код. Конечно, если вы делаете подряд сотню одних и тех же запросов в какую-то таблицу, это будет работать медленней. Но если перед выполнением операции сделать выборку всех записей и просто потом с ней работать, то скорость будет вполне приемлемой.
У нас не произошло глобальной просадки производительности при переходе к DDD. Даже наоборот, мы выиграли. Потому что у нас был реализован такой замечательный паттерн в решении, как периодический поэтапный поиск сокровищ: вызовы в базу шли один за другим вместо того, чтобы делать, например, джойн.
Любые транзакции
У нас за транзакционность на уровне одного сервиса отвечает единица работы. Поэтому единица работы размещается на аппликационном слое:
Спойлер
using (var collector = _eventCollectorFactory.BeginCollection())
{
using (var uow = _entityRepositoryFactory.Create())
{
var parser = _factory.Create(file);
var parseResult = parser.Parse();
uow.Commit();
eventCollector.Send();
}
}Валидация на основе доменных сущностей и внешних данных
Понятно, что команду вы будете валидировать, скорее всего, на аппликационном уровне. Но часто бывает, что нужно провалидировать не просто команду, а прямо изменение доменной сущности вместе с данными команды. И при этом вы можете затрагивать еще и данные внешних систем при этой валидации. У нас такие кейсы регулярно возникают.
В этом случае лучше использовать доменный слой, предварительно подготовив для него данные, чтобы он там не работал с инфраструктурой, а валидация происходила в одном месте. Такая валидация часто имеет очень большое значение для бизнеса, потому что она затрагивает и данные текущего состояния, текущего инварианта — поэтому ее лучше помещать в доменной модели.
Общая схема решения сложностей получилась вот такая:

Такие правила у нас сложились, такие проблемы есть. Думаю, у вас подходы другие, и было бы интересно это обсудить.
Резюме
DDD позволяет определить разделение системы на микросервисы, и в этом контексте про него стали говорить непрерывно. Это дало дополнительный толчок людям его изучать. В монолитных системах, на мой взгляд, предметно-ориентированное проектирование было не настолько популярным.
Тактические шаблоны подходят для применения в бизнес-логике и позволяют там достичь максимальной продуктивности. В инфраструктуре они избыточны, потому что там не нужна высокая гибкость, нет быстро меняющихся требований.
Инфраструктурные зависимости полезно отделить для повторного использования. Даже если вы работаете сейчас с монолитным проектом, вполне вероятно, что на этапе какого-то жизненного цикла вы захотите отделить некоторые его части в отдельные сервисы. И для повторного использования вам пригодится ваша же инфраструктура. Если вы расшарите ее на свое предприятие, то сможете получить неожиданные бонусы в виде построения, например, сообщества разработчиков определенной технологической платформы.
DDD предлагает подходы для взаимодействия как внутри приложения, так и с внешними системами. У нас есть стратегические вопросы, например, вопрос взаимодействия контекстов — и DDD дает ответы на них. Но эти подходы можно переносить и на уровень внутрь сервиса. Гибкость с точки зрения бизнес-логики интересна и на уровне, который находится не внутри сервиса, а снаружи.
DDD – развитая методология, существует большое количество средств для решения любых проблем, возникающих в процессе разработки. Есть много книг, описывающих как правильно пользоваться DDD, и большое количество объяснений на самые различные случаи, которые могут возникнуть при использовании методологии DDD.
Надеюсь, что если вы не используете DDD, но хотите его использовать, то моя статья позволит вам составить некоторый каркас того, о чем нужно думать на старте. Тогда процесс пройдет у вас намного менее болезненно, чем это было у нас — без переписывания кода и посыпания головы пеплом.
Видео моего выступления на TechLead Conf 2020:
13 и 14 июня пройдет объединенная конференция DevOpsConf 2022 и TechLead Conf 2022. Место проведения — кампус Сколково, самая инновационная и технологичная площадка в Москве.
Обсудим инженерные процессы в IT от XP до DevOps & Beyond, must have инструменты и практики изменений в командах для быстрых и качественных релизов. Программа практически сформирована. Билеты можно купить здесь.
Программный комитет DevOps 2022 ждет ваших заявок о выступлении на конференции — появились новые темы. От импортозамещения, переезда обратно из облаков — до новой инфраструктурной парадигм, рисков по железу и даже поддержки своих команд. Доклады по темам принимаются до 22 апреля.
hlogeon
Про DDD и тактики внедрения всегда интересно почитать. Но на мой взгляд основная часть именно стратегическая. Позволяет повернуть мозги разработки от проивзодства кода к производству ценности и удовлетворению бизнес-потребностей. Мне кажется, что DDD иногда может эффективнее работать без применения сложных паттернов и микросервисов. Кажется, часто забывают о том, что решение должно быть соразмерно задаче