

Привет, Хабр!
Меня зовут Рустем, являюсь Senior DevOps Engineer в компании IBM, город Краков.
Недавно я рассказал, как можно задеплоить приложение в кластер Openshift в IBM Cloud, а сегодня я хотел бы рассказать, как за этим всем следить. Что же нам понадобится? Нам сегодня понадобится кластер в IBM Cloud и LogDNA для мониторинга и алертинга.
Давайте начнем с вводной, что же это за инструменты?
IBM Cloud
IBM Cloud — это набор услуг облачных вычислений для бизнеса, предлагаемых компанией информационных технологий IBM . Он объединяет платформу как услугу (PaaS) с инфраструктурой как услуга (IaaS). Платформа масштабируется и поддерживает как небольшие группы разработчиков и организации, так и крупные предприятия. Он глобально развернут в центрах обработки данных по всему миру. Основными конкурентами IBM на рынке облачных вычислений являются Amazon Web Services , Microsoft Azure и Google Cloud Platform.
LogDNA
LogDNA — это платформа наблюдения для управления вашими данными и выполнения действий с ними. Он принимает, обрабатывает и направляет данные журналов для обеспечения разработки и доставки приложений на уровне предприятия, обеспечения безопасности и соответствия требованиям.
LogDNA был воплощен в жизнь трехкратными соучредителями Крисом Нгуеном и Ли Лю и включен в зимнюю партию Y Combinator 2015 года. В 2018 году LogDNA заключила партнерское соглашение с технологическим гигантом IBM, чтобы стать единственным поставщиком журналов для IBM Cloud.
Распределенное ведение журналов с помощью LogDNA и OpenShift в IBM Cloud
Облачное приложение, основанное на микросервисах, содержит множество частей, которые пишут логи. Обычно хорошей практикой будет использовать службу сбора логов, которая может собирать все распределенные логи в одном месте. Существует множество решений для сбора и анализа логов, которые можно установить непосредственно в кластер Kubernetes или OpenShift, но тогда у вас появится дополнительное приложение, которое необходимо поддерживать, и еще одно, которому также требуется постоянное хранилище для хранения логов в течение определенного периода времени.
IBM Cloud предлагает «Службу ведения логов как услугу» в форме IBM Log Analysis с LogDNA. Он предлагает функции для фильтрации, поиска и сбора логов, алертинга и создания настраиваемых правил для мониторинга приложений и системных логов.
Время практики!
Шаг 1. Создадим службу LogDNA.
В браузере войдем в панель управления IBM Cloud.
В бургерном меню выберем «Observability».

Шаг 2. Создадим экземпляр «IBM Log Analysis с LogDNA».
Выберем «Logging» слева.
Нажмем «Create a logging instance».

Шаг 3. В следующем диалоговом окне:
Выберем регион, близкий к нашему кластеру OpenShift.
Оставим тарифный план «Lite», но можете обратить внимание на другие планы; это полнофункциональные планы. Но вам нужна платная учетная запись, чтобы использовать их. Мы будем использовать Lite для практики.
Прокрутим немного вниз.
Оставим имя службы и группу ресурсов «По умолчанию».
Нажимаем «Создать» в нижней части диалогового окна.

Шаг 4. Нажмем на “Edit log sources”

Шаг 5. Выберем вкладку «OpenShift». Скопируем и выполним следующие команды в IBM Cloud Shell:

Шаг 6. Давайте проверим, запущен ли агент логирования в нашем кластере.
Вводим команду в наш IBM CloudShell: oc get all -n ibm-observe

Шаг 7. Перейдем в наш LogDNA.
Вернемся в наш дэшборд IBM Cloud.
В бургерном меню выберем «Observability».
В меню ««Observability»» выберем «Logging».Ё
Нажмем «View LogDNA».

Шаг 8. Просмотрим наш дэшборд LogdNA.
Откроем выпадающее меню «All apps» и выберем поды, которые мы хотим промониторить.

Шаг 9. Создадим правило алертинга, пусть наш сервис будет отправлять нам алерт, когда наше приложение отдает 500-е ошибки.
Введем в поисковое меню внизу следующее: response:(>=500 <600)
Как мы видим, таких ошибок еще не было зарегистрировано.

Теперь нажимаем на “Unsaved view” в левом верхнем углу и сохраняем наш “View” и выбираем “Save as a new view”.

Даем название нашему “View” и категоризируем его как “Error” и сохраняем.

Шаг 10. Создадим наш алерт. Нажмем на “Attach an alert”.

Выбираем “View-specific alert” и выбираем куда будем отправлять наш алерт (slack, email, sysdig, pagerduty или webhook для стороннего приложения).
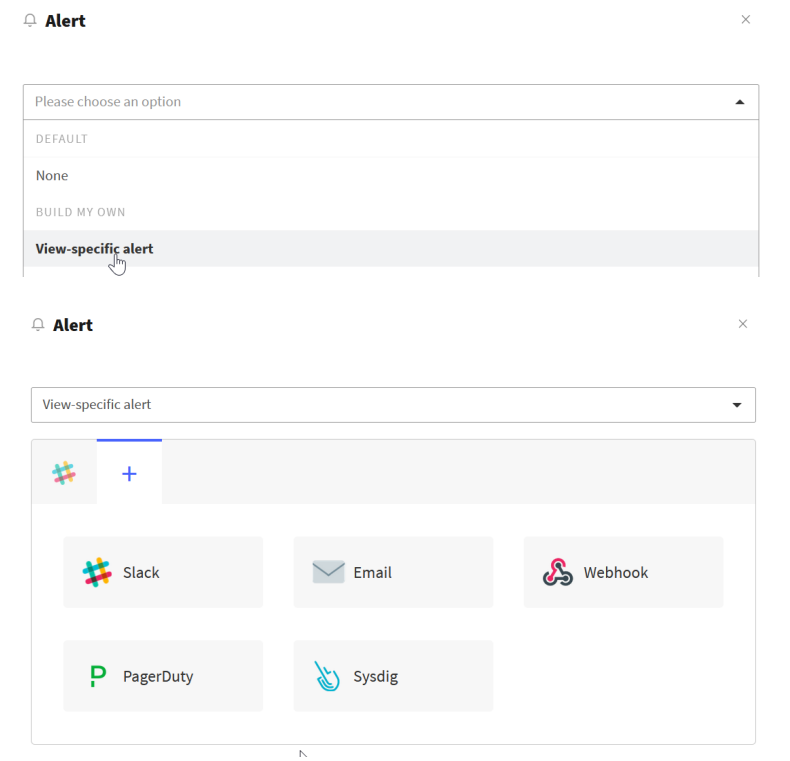
Будем слать наши алерты в Slack в канал “Operation team”.
Чтобы избежать аномалий, настроим алерт так, чтобы он реагировал на 5 ошибок подряд в течении одной минуты и вставим webhook нашего канала в слаке и сохраним.

Наш алерт сохранен и увидеть его можно в левом меню во вкладке “Errors”.

Готово! Мы подняли мониторинг в нашем кластере и настроили алертинг.
Уже сегодня в 20:00 в OTUS состоится открытое занятие, на котором попытаемся разобраться в контейнеризации и рассмотрим ее отличие от виртуализации. Также рассмотрим самый популярный инструмент по работе с контейнеризацией — docker. Регистрация — по ссылке.