

Программа sort во FreeBSD считывает строки из стандартного ввода или файла и возвращает те же строки в отсортированном порядке. В NetBSD есть аналогичная программа, есть такая же и в проекте GNU. Недавно мы получили багрепорт, в котором сообщалось, что сортировка FreeBSD намного медленнее, чем сортировка в NetBSD или GNU.
Я сгенерировал немного тестовых данных и попробовал это проверить. Я использовал числовую сортировку, поэтому вы видите флаг -n :
time sort -n test.txt -o /dev/null # FreeBSD
39.13 real 38.65 user 0.49 sys
time sort -n test.txt -o /dev/null # NetBSD
3.51 real 2.89 user 0.58 sys
time gsort -n --parallel=1 test.txt -o /dev/null # GNU
6.34 real 5.69 user 0.64 sysДействительно, значительно медленнее! Я был заинтригован и сначала взглянул на исходный код sort, но ничего необычного не заметил. Значит, мне нужно будет использовать инструменты профилирования, чтобы определить корень проблемы.
Так как я проверял sort на больших файлах, мне стало интересно, тратит ли программа много времени на выделение памяти, поэтому я решил сначала посмотреть на на количество выполняемых ей аллокаций. Это можно сделать, подсчитав количество вызовов malloc и подобных функций, таких как realloc. Я решил данную задачу с помощью инструмента dtrace.
# dtrace -n 'pid$target::*alloc:entry {@ = count()}' -c "sort -n -o /dev/null test.txt"Этот вызов dtrace выводит общее число всех вызовов malloc, realloc и т. д. Для тестового файла из 999999 строк я получил результат в 40019544 вызова. Четыре аллокации на каждую строку файла с входными данными! Для справки, sort NetBSD и GNU делали менее 100 аллокаций на тех же входных данных. Поскольку аллокации стоят дорого, мы определенно могли бы добиться значительного ускорения, если бы заранее выделяли некоторый пул памяти, а не отдельно для каждой строки. Но была ли проблема решена?
Не совсем. Я в очередной раз прибегнул к старому доброму инструменту отладки, простому оператору печати. Я добавил печать прямо перед вызовом procfile, функции, в которой происходит большинство аллокаций во время подготовки к сортировке, и сразу после. К сожалению, теперь мне стало ясно, что эти четыре миллиона malloc происходили в первые несколько секунд, тогда как всё время работы программы составляло около 40 секунд. Уменьшение количества malloc могло бы сократить время примерно на 5 секунд, но основная проблема заключалась не в этом. Было по-прежнему непонятно, какие функции в программе работают дольше всего, и использование dtrace для подсчета вызовов функций больше не могло мне помочь.
Следующим, что я попробовал, была утилита callgrind из пакета Valgrind. Этот инструмент профилирования подсчитывает количество выполненных инструкций, отсортированных в соответствии с тем, в какой функции они встречаются. Если мы предположим, что каждая инструкция занимает одинаковое количество времени, функция с наибольшим количеством выполненных инструкций окажется функцией, которая тратит больше всего времени на выполнение. Несмотря на то, что это грубое допущение, оно даёт неплохую оценку.
Callgrind можно запустить следующим образом:
$ valgrind --tool=callgrind sort -n -o /dev/null test.txtРезультатом будет файл с именем callgrind.out.PID. В состав callgrind также входит утилита callgrind_annotate для удобного отображения содержимого этого файла.
$ callgrind_annotate callgrind.out.PIDЯ получил следующий результат:
81,626,980,838 (25.33%) ???:__tls_get_addr [/libexec/ld-elf.so.1]
59,017,375,040 (18.31%) ???:___mb_cur_max [/lib/libc.so.7]
36,767,692,280 (11.41%) ???:read_number [/usr/home/c/Repo/freebsd-src/usr.bin/sort/sort]Это означает, что около 25% всех инструкций, выполняем в рамках работы программы, приходилось на вызовы функции __tls_get_addr, оставшиеся 18% приходились на ___mb_cur_max и, наконец, 11% приходились на read_number. Обратите внимание, что эти подсчеты являются исключающими; например, если read_number вызывает ___mb_cur_max, инструкции в ___mb_cur_max не будут добавлены к инструкциям в read_number.
Вот только что это за функции? Две наиболее часто используемые функции, __tld_get_addr и ___mb_cur_max, нигде в исходном коде не встречаются. Оказывается, эти две функции вызываются, когда используется значение MB_CUR_MAX. Хотя это значение выглядит как константа времени компиляции, оно таковым не является.
Я сдвинулся с мертвой точки, но хотелось копнуть глубже. Какие функции использовали MB_CUR_MAX так часто, и зачем? Callgrind не мог дать мне информацию о том, какие конкретно функции привели к вызовам __tls_get_addr и ___mb_cur_max.
Тут на сцену выходит трассировка стека. В каждый конкретный момент времени трассировка стека содержит историю того, как программа дошла до текущего момента. Если мы будем периодически сохранять стек, то сможем получить представление о том, сколько времени программа тратит на каждую функцию и где она вызывается. Инструмент dtrace опять-таки позволяет нам это сделать.
# dtrace -n 'profile-997 /pid == $target/{@[ustack()] = count()}' -c "sort -n -o /dev/null test.txt" -o out.stacksДанный вызов dtrace будет записывать трассировку стека на всём протяжении работы программы с частотой 997 Гц. Наконец, инструмент FlameGraph обеспечивает удобную, интерактивную и очень красивую визуализацию этих данных:
$ ./stackcollapse.pl out.stacks > out.stacks_folded
$ ./flamegraph.pl out.stacks_folded > stacks.svgВот результирующая SVG (в оригинале статье интерактивная):
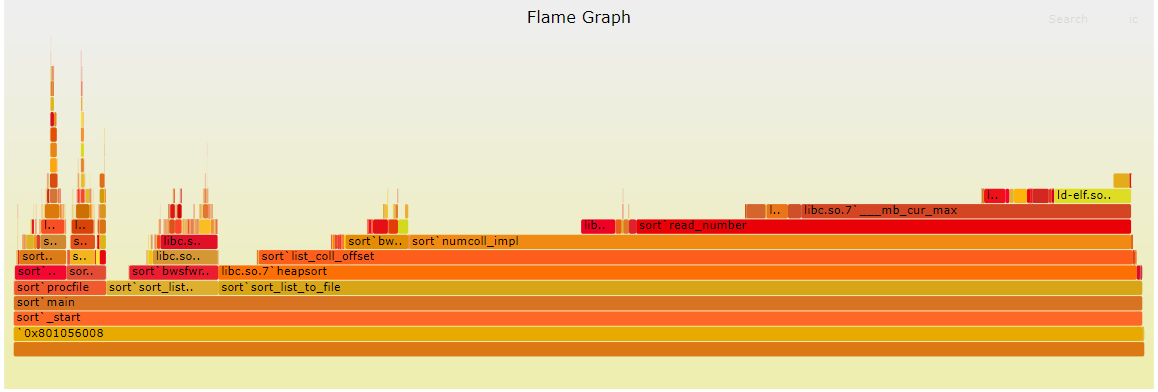
Ось X Ось X соответствует количеству инструкций, тогда как ось Y представляет стек. В отличие от Callgrind, эта визуализация не исключающая; все инструкции, которые выполняются во время вызова функции, учитываются для этой функции. Например, мы видим, что procfile занимает около 8% от общего количества инструкций в программе, sort_list_dump занимает около 10%, а sort_list_to_file занимает около 80%. Мы также можем видеть, что эти три функции выполняются из функции main.
Эта визуализация подтвердила мою предыдущую гипотезу о том, что четыре миллиона malloc, все в procfile, не так сильно замедляют работу программы. Я также заметил на графике очень длинную полоску со знакомым названием: ___mb_cur_max. Эта функция занимала около 30% инструкций программы, а также отвечала за вызовы __tls_get_addr. Ее вызывала функция read_number.
Теперь я видел очень простую, но эффективную оптимизацию этой программы. Я бы кэшировал значение MB_CUR_MAX в начале, чтобы при дальнейшем использовании не нужно было вызывать функции ___mb_cur_max и __tls_get_addr. Я внес это изменение и обнаружил значительное улучшение; оно почти вдвое сократило время выполнения!
К сожалению, FlameGraph также дал мне понять, что дальнейшие улучшения программы будут не такими простыми. Большая часть оставшегося времени тратится на использование функции сортировки, которая уходит корнями в libc. И большая часть времени, затрачиваемого на функцию сортировки, приходится на list_coll_offset, numcoll_impl и read_number, которые используются в функции сравнения. Дальнейшая оптимизация этой программы будет означать оптимизацию этих функций, что само по себе уже не так просто, как кэширование значения.
Тем не менее, мы получили приличный прирост производительности в результате этого исследования. А за счет использования флагов sort для изменения алгоритма сортировки на quicksort или mergesort вместо heapsort, мы получаем производительность, почти не уступающую sort в GNU или NetBSD.
Перевод статьи подготовлен в преддверии старта курса «Программист С». Если вам интересно проверить свой уровень знаний для поступления на курс, пройдите вступительный тест.
danfe
Стоит отметить, что описанные проблемы были исправлены одновременно с публикацией оригинала статьи, т.е. еще прошлым летом.