

Я уже упоминал, каким неприятным сюрпризом оказалось исключение команды INTO из системы команд x86-64, когда я переводил компилятор на эти команды. Давайте разберемся, нужна ли сейчас команда, которая отвечала за контроль целочисленного переполнения еще со времен процессора 8086.
Кстати, а чего вообще прицепились к этому целочисленному переполнению? И зачем для него иметь еще какую-то отдельную проверку? Например, ну, нет же никакой отдельной команды INTD проверки деления на число с нулевым значением. Дело здесь в том, что согласно древней алтайской легенде когда-то два прекрасных юноши полюбили одну прекрасную девушку по имени Наноль. И вот они теперь не знают, что делать: ведь Наноль делить нельзя… Да, на ноль делить нельзя и поскольку дальнейшие вычисления теряют смысл, в этом случае процессор всегда генерирует исключение. Никаких дополнительных проверок и указаний ему не требуется. А вот для целочисленного переполнения есть ситуации, когда переполнение «не считается» - это адресная арифметика, например, когда требуется «заворот» в начало адресного пространства или что-нибудь подобное. Да даже простейший случай: если язык позволяет иметь в программе массивы с границей, начинающейся с единицы, то тогда, например, обнуление i-ого элемента массива z(1:n) выливается в команды вроде:
mov rbx,i
mov b ptr z+0FFFFFFFFh[rbx],0где при вычислении адреса учитывать переполнение не нужно. Казалось бы, ну и пусть себе, ведь это делает сам процессор или даже компилятор внутри одной команды. Но вычисление адреса в программе может быть и не одной командой. Как тогда быть? Ведь нужно или не нужно учитывать в таких командах переполнение, знает только компилятор, а не процессор. Вот как раз для таких случаев разработчики архитектуры x86 и ввели отдельную проверку переполнения. Компилятор ставит эту отдельную проверку, если идут обычные арифметические вычисления и не ставит, если идет вычисление адреса. Такая удобная для компиляторов команда INTO без параметров, представляет собой просто байт с кодом 0CEh. Эта команда ставится после собственно арифметических команд и проверяет флаг переполнения «O», который иногда почему-то путают с флагом переноса «С». Если флаг «О» установлен – вырабатывается сигнал прерывания. А почему команда так удобна для компиляторов? Так ведь тогда никаких забот с контролем переполнения: прилепил в конец очередной сгенерированной арифметической команды байт 0CEh и дело с концом!
И вот такую удобную команду контроля взяли и выкинули в процессорах AMD-64, а затем по наследству и в Intel. Хотя ошибка целочисленного переполнения – одна из самых коварных. Во-первых, программа может уйти очень далеко от места, где было переполнение, и только потом завершиться с ошибкой. Понять, что произошло, становится очень трудно. А во-вторых, может случиться самое неприятное, на мой взгляд, когда программа выдает правдоподобные (но неправильные) результаты. Есть даже программистская байка, что один раз авария пуска ракеты произошла из-за ошибки целочисленного переполнения, причем не в ПО системы управления, а всего лишь в датчике псевдослучайных чисел при моделировании условий полета. Из-за ошибки переполнения датчик выдавал такие случайные числа, что если очередную их тройку считать за три координаты, то все точки оказываются на графике в семи параллельных плоскостях. Якобы из-за этого моделирование стало не похоже на реальный полет и дело кончилось аварией.
И вот когда я переводил компилятор в архитектуру x86-64, встал вопрос: а как же наилучшим способом теперь контролировать переполнение? В том, что его обязательно надо контролировать в любом языке, я просто убежден, и никто меня в этом не разубедит.
И началась у меня прямо битва за эмуляцию INTO.
На первом этапе, я просто сохранял код арифметических команд с байтом 0CEh в конце. Но теперь независимо от флага переполнения этот байт вызывает в x86-64 исключение «запрещенная команда». Поэтому обработчик исключений стандартной библиотеки проверяет: не INTO ли это, и тогда уже сам проверяет флаг переполнения, или возвращаясь в программу за командой INTO или переходя на обработку переполнения. Т.е. для INTO получилась виртуальная машина x86. Ура! Все заработало точно так же, как и прежде! Увы, но не ура. Из-за потока исключений на байтах 0CEh скорость целых вычислений упала до уровня программ на каком-нибудь Питоне. Так не пойдет.
На следующем этапе я заменил байт INTO на вызов подпрограммы из стандартной библиотеки. Теперь подпрограмма проверяет флаг переполнения и выполняет или просто возврат или переход на обработку переполнения. Скорость целых вычислений из-за замены исключений на вызовы возросла до уровня программ на Яве. Если происходит переполнение, адрес команды, ее вызвавшей, можно определить по адресу возврата в стеке, который находится там в момент работы этой системной подпрограммы. Но все-таки начинала душить жаба - столько вызовов и все они, по сути, бесполезны: переполнение - это редкое событие, и каждый раз делать вызов только из-за адреса возврата в стеке, который тут же и выбрасывается, очень жалко.
Тогда на следующем этапе, как говорится, наступив на горло собственной песне, я заменил системный вызов одной командой условного перехода по переполнению (командой JO). С точки зрения производительности для целых вычислений все стало гораздо веселее. На уровне С++. И предсказатель переходов в процессоре сразу превратился в оракула: ведь практически никогда эти условные переходы не срабатывают. Но жаба продолжала душить. Ведь на каждый (почти всегда невыполняемый) условный переход тратится целых 6 байт! И вдобавок адрес конкретной команды, вызвавшей переполнение, теперь теряется – ведь переход не оставляет следов в стеке, как вызов подпрограммы. Правда, в отладочном режиме есть и другая информация о текущем месте в программе. У меня это, во-первых, текущее содержимое регистра R15D, куда постоянно пишется номер очередной строки исходного текста (два байта) и две первых буквы имени текущего модуля (просто, чтобы оставшееся место в регистре не пропадало впустую). А во-вторых, имеется системная переменная - адрес последней команды «где все еще было хорошо», который переписывается из стека как адрес возврата из последнего выполненного системного вызова. И хотя адрес самого переполнения не запоминается, как при выполнении INTO, но это еще терпимо, опять-таки учитывая редкость переполнения в программе. В таких редких случаях можно даже и отладчиком поискать подозрительные арифметические действия вблизи известного последнего адреса еще правильной работы.
Но пришла мысль, что раз все равно уже потерян адрес команды, где случилось переполнение, то тогда можно и не писать условный переход по переполнению сразу на обработчик, а передать его сначала, так сказать, «кунакам влюбленного джигита». Т.е. при работе компилятора создать связанный список всех сформированных условных переходов по переполнению и генерировать адрес очередного перехода на предыдущий условный переход. И только у самого первого в коде условного перехода оставить настоящий адрес обработчика переполнения. Смысл в том, что когда многие проверки окажутся в коде рядом, их можно реализовать не длинными командами c кодом 0F 80 XX XX XX XX, где XX XX XX XX адрес обработчика, а короткими с кодом 70 YY, где YY расстояние в байтах до предыдущего условного перехода.
Ниже на примере простого выражения из целых переменных
x1=(x2+x3)/(x2-x3)+(x3-x4)/(x3+x4);
показано, как именно получается выигрыш в длинах.
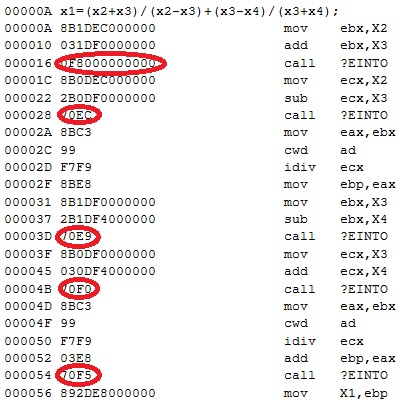
Например, если переполнение происходит в команде сложения по адресу 52, то срабатывает условный переход по адресу 54 и управление передается на переход по адресу 4B, затем по адресу 3D, затем по адресу 28 и, наконец, попадает на условный переход по адресу 16, откуда управление передается уже на обработчик переполнения. При компиляции адрес этого обработчика еще неизвестен, поскольку он расположен в стандартной библиотеке.
Длинная цепочка переходов по переполнению вместо одного перехода выполняется гораздо медленнее. Но поскольку опять-таки это очень редкое событие и к тому же обычно означающее аварийное завершение программы, то попадет ли управление на обработчик переполнения через 20 тактов или через 2000 тактов, не имеет особого значения. А выигрыш в байтах даже в таком маленьком примере существенен: 4х4=16 байт при размере всего фрагмента в 82 байта, т.е. 20%.
Наверное, можно было бы придумать еще варианты, например, вот такая комбинация из двух команд:
JNO M
INTO
M:
длиной 3 байта могла бы помочь узнать адрес команды, вызвавшей прерывание. Здесь INTO вызывается только при установленном флаге «O», далее опять срабатывает исключение «запрещенная команда», по которому обработчик может вычислить адрес виноватой команды. При этом условный переход JNO наоборот, почти всегда будет исполняться. Но я все-таки решил использовать вариант, при котором условные переходы по переполнению не выполняются, хотя, может быть, он и чаще будет длиннее по кодам.
Подведем итоги. Вроде бы битва за эмуляцию INTO закончилась неплохо, лишь с потерей адреса команды с переполнением. Зато удалось во многом отыграть назад скорость вычислений и длину кодов, который был в x86 при разрешенной команде INTO. На каждый контроль целочисленного переполнения теперь часто тратится всего два байта, а с точки зрения процессора – это два байта никогда не выполняющегося условного перехода, что улучшает эффективность предсказателя переходов, а, значит, и эффективность выполнения этого кода.
Хотя, на мой взгляд, лучше бы все-таки в x86-64 разрешили бы команду INTO, которая и короче и проще в применении. Я не понимаю причины ее исключения. Вряд ли разработчики AMD-64 не знали/не поняли смысл ее существования. Может быть, когда собирали статистику использования команд в реальных программах, она попадалась слишком редко. Ну, так ведь в исходном варианте языка Си контроль целочисленного переполнения вообще не предусматривался, неудивительно, что в его потомках об этом тоже особо не заботились. А может быть были трудности с каким-нибудь сбросом конвейеров процессора при обработке INTO или еще что-нибудь такое «аппаратное».
Но отсутствие удобной команды контроля переполнения провоцирует разработчиков программных средств на отказ от такого контроля. А отказ уже похож на экономию на противопожарных средствах: убыток от одного пожара тут же сделает бессмысленной всю такую экономию.
Даже если бы INTO в x86-64 выполнялась бы не очень быстро (а почему бы тогда не сделать ее специально очень быстрой?), проигрыш производительности от этого все равно чаще всего не компенсировал бы время поиска ошибки из-за переполнения, поскольку такой поиск может выливаться в часы, дни, а то и недели. А незамеченная ошибка переполнения из-за отсутствия его контроля, как гласит легенда, может даже привести к аварии ракеты.
P.S. В компиляторе я не выбросил, а просто закомментировал ветку, генерировавшую INTO по-старому, как байт 0CEh. А то вдруг в следующих поколениях процессоров ее опять разрешат.
Комментарии (4)

NickViz
27.05.2022 11:57"Но я все-таки решил использовать вариант, при котором условные переходы по переполнению не выполняются, хотя, может быть, он и чаще будет длиннее по кодам." - вы сравнивали оба варианта по быстродействию? (в нормальном без переполнения виде). навскидку - должно быть примерно одинаково, предсказание переходов по идее будет работать так же для 100% случившихся и не случившихся jump.

Dukarav Автор
27.05.2022 21:06Да, навскидку по быстродействию варианты близки. Но мне по душе больше тот, где счетчик команд не увеличивается дополнительно еще на байт из-за выполненного перехода. Чисто субъективно)
rutenis
Дело не в ошибке переполнения - это принципиальное свойство датчиков ПСЧ, использующих линейный конгруэнтный метод (по Кнуту). Обычно для них вычисления выполняются по модулю, равному размеру слова ЦП, соответственно, переполнения игнорируются. И может оказаться, например, что если выбирать ПСЧ тройками и использовать как координаты точек в единичном кубе, то все полученные точки лежат в нескольких плоскостях вместо того, чтобы более-менее равномерно заполнять куб.
Такая неприятная особенность была обнаружена в ПСЧ из библиотеки IBM для числового моделирования для Фортрана, откуда, вероятно, и пошла эта байка.
JPEGEC
А мне очень интересно откуда автор взял про 7 плоскостей.