
В статье будет рассмотрен подход позволяющий существенно упростить создание и поддержку тестовой end-to-end (e2e) библиотеки. Также, будет показано как использование расписания в e2e тестировании помогает даже тогда, когда в реальной системе расписание отсутствует.
Центральной идеей данного подхода является возможность совмещения действий над системой и всех необходимых при этом проверках в вызове одной функции. А по ходу статьи мы будем героически решать возникающие на этом пути сложности.
Для упрощения объяснения концепции мы будем использовать сферический абстрактный интернет магазин с надуманными проблемами.
Объектный подход
Очень упрощённо автоматизированное тестирование можно представить в виде последовательности вызова функций. Некоторые из функций при этом совершают какое-то действие с системой, например создают, обновляют или удаляют какие-то объекты, а другие функции проверяют, что объекты действительно создались, изменились или были удалены.
Самым очевидным способом будет сделать эти функции простыми обёртками над api/sql запросами с явной передачей всех необходимых для этого параметров. И если для функций-действий это не доставляет особых проблем, то для функций-проверок приходится передавать практически одни и те же параметры (а иногда проверяемых параметров больше сотни) по всему сценарию. Такой подход провоцирует copy&paste, а также усложняет чтение сценария.
Рассмотрим это на примере:
// создадим клиента нашего магазина в системе через API
createClient(<много параметров>)
// проверка этого объекта
checkClient(<много параметров>)
// обновляем какие-то поля
updateClientEmail(client_id, new@email)
// сново перечисляем все проверочные параметры, меняется
// только e-mail
checkClient(<много параметров>)Чтобы избежать дублирования достаточно создать “виртуальное” представление объекта тестируемой системы в нашей тестовой библиотеке. А во время функций-действий не только выполнять API запрос, но и обновлять состояние нашего внутреннего объекта.
Сам объект при этом будет похож на класс в распространенных языках программирования с поддержкой ООП и выглядит примерно так:
object Client {
client_id,
name,
email,
// другие свойства объекта
}При таком подходе наш пример можно переписать так:
// создание клиента отличается только созданием нового объекта
client1 = createClient(<много параметров>)
// а вот вызов проверки существенно упростился, т.к. все необходимые
// параметры неявно передаются через объект
client1.check()
// обновляем какие-то поля: в тестируемой системе через API и у нашего
// "виртуального" client1
client1.updateEmail(new_email)
// объект изменился, а вызов функции-проверки ничем не отличается
client1.check()Сценарий при этом стал более читаемым, тестируемые объекты обрели явные имена (client1 в примере), а усилия на его создание и поддержку существенно сократились.
В дальнейшем мы во всех примерах будем исходить именно из объектного подхода в автоматизации.
Особенности тестирования систем с расписанием
Уже из описания следует, что в таких системах часть событий происходит по внутреннему расписанию, при этом в ряде случаев эти события затрагивают сразу большие группы тестовых сценариев.
Пример: в целях экономии на доставке владельцы нашего магазина решили все заказы клиента за день отправлять одной посылкой. Для этого в 18:00 неизвестного часового пояса через cron запускается скрипт, который агрегирует заказы клиентов за день. Нам нужно убедиться, что агрегация осуществляется корректно, особенно с учётом того, что есть приоритетные заказы, которые должны быть отправлены сразу после оформления.
При реальном тестировании наступления 18:00 никто естественно не ждёт, а просто вызывает нужный скрипт и/или используют виртуальный перевод времени тестируемой системы.
Внутреннее расписание нашей библиотеки будет состоять из специальных блоков, которые мы назовём globalSteps. Эти блоки выполняются в заранее определённом порядке, а переход на следующий globalStep будет выполнен только после выполнения задач всех сценариев предыдущего блока.
Рассмотрим на примере:
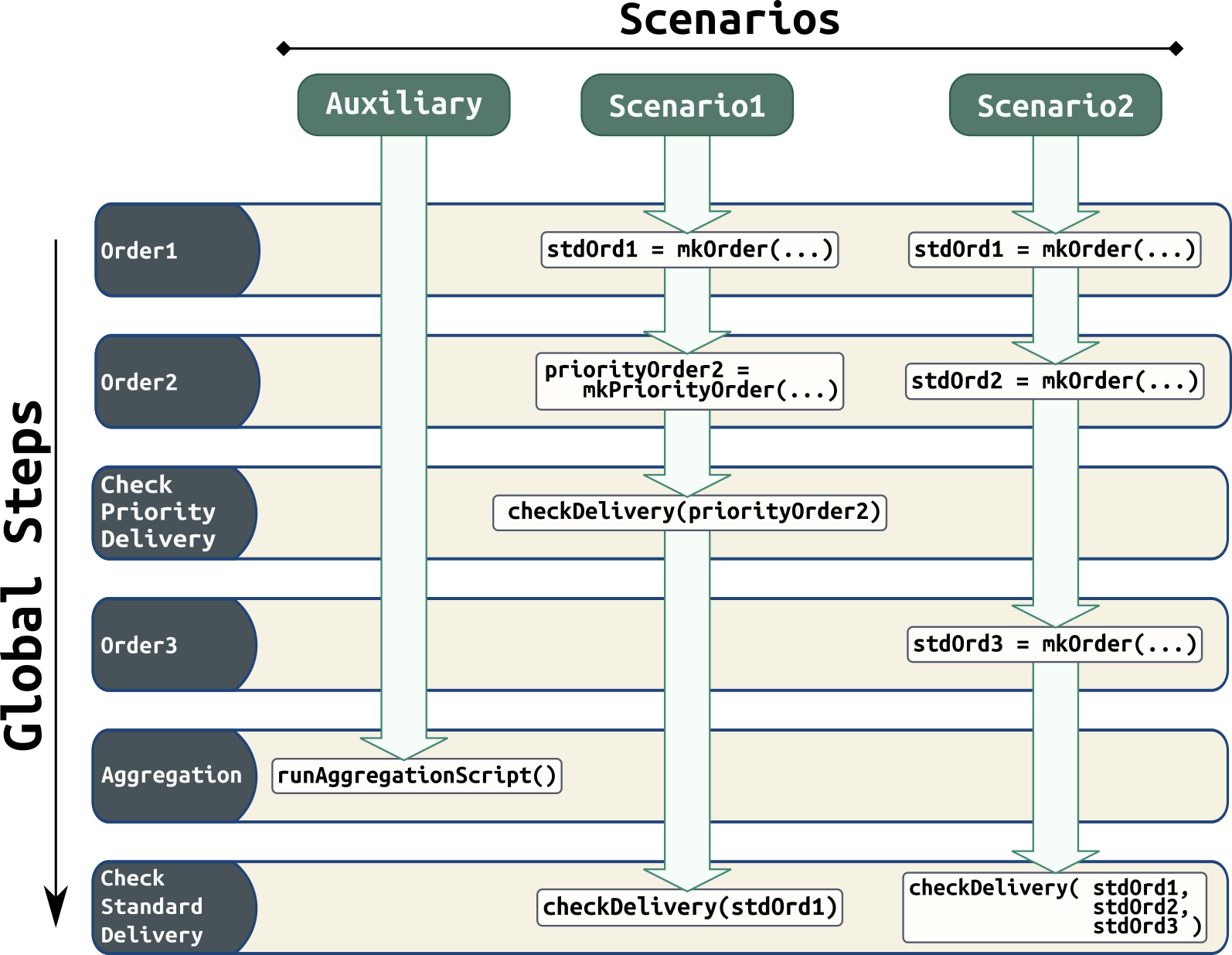
Сначала будут выполнены задачи из globalStep(order1) для сценариев scenario1 и scenario2 (в auxiliary сценарии у нас нет никаких задач для этого шага), после чего мы перейдём к globalStep(order2) и т.д.
Вспомогательный (auxiliary) сценарий нужен для того, чтобы выполнять задачи внутреннего расписания тестируемой системы, а задач функционального тестирования в нём быть не должно. На псевдоязыке scenario1 можно описать так:
scenario("Scenario1") {
globalStep("order1") {
stdOrd1 = mkOrder(...)
}
globalStep("order2") {
priorityOrder2 = mkPriorityOrder(...)
}
globalStep("checkPriorityDelivery") {
// проверяем что priorityOrder был отправлен сразу
checkDelivery(priorityOrder2)
}
globalStep("checkStdDelivery") {
// проверяем что stdOrd1 был отправлен только после
// запуска runAggregationScript() и других заказов
// туда не попало
checkDelivery(stdOrd1)
}
}А auxiliary так:
scenario("Auxilary") {
globalStep("aggregation") {
runAggregationScript()
}
}Другим, менее очевидным способом использования расписания в тестовой библиотеке, является тестирование растянутых по времени событий. Поясню это на примере: после создания заказа клиенту должно быть отправлено письмо, но эмпирическим путём выяснено, что письмо приходит не мгновенно, а с задержкой до 10 секунд. Тогда создание заказа вместе с проверкой будут выглядеть так:
ord1 = mkOrder(...)
wait(10s)
ord1.checkEmail()
Если у нас будет 100 подобных сценариев и они будут выполняться последовательно, то только время ожидание составит 100*10s = 1000s ~ 16.66min, что достаточно неприятно. Но, если мы применим подход с globalSteps, то этого можно избежать:
auxilary |
scenario1 |
scenarioN |
|
makeOrder |
ord1=mkOrder(...) |
ord1=mkOrder(...) |
|
wait |
sleep(10s) |
||
checkEmail |
ord1.checkEmail() |
ord1.checkEmail() |
На этом экспресс курс по системам с расписанием завершён и мы переходим непосредственно к нашей концепции.
Event
Реальные сценарии легко бьются на небольшие автономные блоки, которые включают в себя одиночное действие (action) над системой и все необходимые при этом проверки. Постараемся это описать в виде некоего события (event).
Если посмотреть на последний пример, то наш event обобщённо можно описать так:
действие (action)
<пауза>
реакция системы (feedback)
Чтобы не вызывать паузу непосредственно в нашем event, введём специальный блок для выполнения отложенных действий и назовём его feedback. Теперь наше событие в псевдокоде можно описать так:
event makeOrder(<params>) -> Order {
newOrder = mkOrderHttp(<params>)
feedback {
newOrder.checkEmail()
}
return newOrder
}Из этого примера видно следующее:
у нас создаётся новый объект newOrder, который очень удобно передавать как параметр другим функциям
вызов функции checkEmail() вызывается отложено в feedback блоке
объект newOrder возвращается из event для его дальнейшего использования в сценариях
если бы не feedback блок, то event ничем не отличается от обычной функции
При этом внимательный и хорошо подкованный читатель возможно заметил, что feedback очень похож на вызов лямбда функции. Без лишних, деталей в нашем реальном проекте, реализованном на Kotlin, эта функция выглядела бы примерно так:
fun makeOrder(stageContext: Stage, <order_params>): Order {
val newOrder = mkOrderApi(<order_params>)
stageContext.feedback {
newOrder.checkEmail()
}
return newOrder
}Другими словами, вся описываемая здесь машинерия легко выразима в mainstream языках программирования поддерживающих лямбда-выражения.
К сожалению, технические детали реализации концепции сильно перегрузят статью, поэтому в конце будет просто приведена ссылка на минимально работающий пример на Kotlin.
Как мы выяснили ранее, еvent сам по себе это просто функция, но из-за наличия feedback части она может вызываться только в специальном контексте. Создадим этот контекст расширив концепцию globalSteps добавив в него новые блоки выполнения и назовём это stage.
Stage будет состоять минимум из трёх уже знакомых частей:
action
<pause>
feedback
Главное отличие stage от event в том, что stage является частью расписания и именно в нём выполняются events (один или несколько) и общая для всех сценариев пауза. Другими словами, можно сказать, что stage состоит из двух globalSteps (action и feedback) разделённых паузой.
На псевдоязыке создание расписания можно описать так:
schedule {
addStage(name = "createClient", pause = 10s)
addStage(name = "createOrder", pause = 20s)
addStage(name = "deliveryOrder", pause = 0s)
// и т.д.
}Напомню, что как и в случае с globalSteps, сценарий будет выполняться в порядке добавления stages в расписание. Порядок вызова stages в самих сценариях при этом игнорируется.
Далее концепция stage будет расширена.
StateCheck
Все проверки тестовой системы принципиально можно поделить на два вида
проверка внутреннего состояния системы (через sql, RestAPI и т.д.)
ожидание активного ответа в виде некоего сообщения (e-mail, sms, mq-message и т.д.)
Вышеописанные feedback проверки отлично работают с сообщениями, но проверки внутреннего состоянии имеют ряд особенностей:
Часто api реальной системы возвращает информацию только по группе объектов, например все заказы одного клиента. В таких случаях проверки одиночных объектов не работают.
Если мы пропустим проверку какого-то сообщения системы, то это легко вычислить, например сравнив количество выполненных проверок и реальное количество сообщений. В противовес этому, пропущенную sql/api-проверку обнаружить гораздо сложнее.
Правильно составленный sql/api-запрос к системе позволяет заметить неучтённые изменения соседних объектов.
Рассмотрим пример для последнего пункта: делаем два заказа, но один оплачиваем и его статус сразу меняется на подтверждённый, а другой, нет и спустя какое-то время, он отменяется без нашего участия. Если мы будем выполнять все проверки через feedback вариант, то получим следующее:
stage ("createOrder") {
// создаётся объект order1 (вирутальный и через api) со статусом
// created, тут же добавляется feedback для отложенной
// sql проверки order1
order1 = client1.createOrder()
// аналогично создаётся объект order2 с feedback проверкой
order2 = client1.createOrder()
}
stage ("payment") {
// выполняем api-запрос с подтверждением оплаты и меняем
// внутренний статус order1 на confirmed,
// создаём feedback для проверки order1
order1.makePayment()
// order2 не меняется и никаких дополнительных проверок по
// нему не запланировано
}
stage ("done") {
// меняем статус order1 на completed и планируем feedback проверку
order1.delivered()
// К этому моменту, в связи с истечением срока оплаты, order2 в
// реальной системе меняет статус на rejected, но статус нашего
// виртуального order2 всё ещё created.
// Никаких проверок не запланировано и несоответствие реального
// и виртуального статусов остаётся незамеченным. Другими словами
// мы допустили ошибку в нашем сценарии и она никак себя
// не проявила.
}Эту проблему можно решить через агрегированную проверку, при которой в одном sql/api-запросе будут возвращаться сразу все заказы нашего клиента. Сценарий от этого не станет правильным (мы где-то пропустили order2.reject()), но ошибка станет видна в отчёте тестирования.
Т.е. мы хотим, чтобы при изменении хотя бы одного из объектов сценария выполнялись все агрегированные проверки объектов данного типа.
Реализовать это достаточно просто:
нужно иметь списки всех объектов сценария разбитые по типам (например clients, orders и т.д.)
устанавливать флаг наличия обновления на группе объектов одного типа в соответствующих events
написать код, который, при наличии флага, выполнит все агрегированные проверки и сбросит этот флаг
Посмотрим что будет происходить в stage("createOrder") с учётом вышесказанного.
stage ("createOrder") {
// order1 автоматически будет добавлен в список orders при
// создании. Внутри нашего event установится флаг orders.isUpdated
order1 = client1.createOrder()
// order2 также добавляется к orders и устанавливается флаг
// orders.isUpdated, но так как он был установлен ранее это
// ничего не меняет и проверка будет выполнена ровно один раз.
order2 = client1.createOrder()
}Внутри нашего stage добавим блок stateCheck, а порядок выполнения теперь будет выглядеть так:
action
<pause>
stateCheck
feedback
Внутри блока stateCheck будет происходить примерно следующее:
if (clients.isUpdated) {
// выполняем нужные проверки для каждого клиента
clients.forEach { client ->
client.checkClient()
}
// сбрасываем флаг isUpdated для клиентов
clients.isUpdated = false
}
if (orders.isUpdated) {
// проверка заказов агрегированная по клиентам нашего сценарии
for (clnt in clients) {
// собираем список “виртуальных” заказов относящихся к текущему клиенту
orderList = orders.filter{order ->
clnt.client_id == order.client_id
}
// вызов функции проверки всех заказов для одного клиента
doOrdersSqlCheck(client_id, orderList)
}
// никто не мешает выполнять в этом блоке сразу одиночные
// проверки всех заказов
for (ord in orders) {
ord.doOneOrderApiCheck()
}
// сбрасываем флаг isUpdated для заказов
orders.isUpdated = false
}Надеюсь, что приведённый код добавил немного ясности к описанию этого блока. Остаётся только добавить пару моментов их практического применения:
Внутри stateCheck можно добавить сразу несколько проверок, что особенно удобно когда нужно всесторонне протестировать разные api endpoints.
Один event может устанавливать флаг isUpdated сразу для нескольких типов объектов (например и для orders, и для clients).
Иногда, во время выполнения action части, система не возвращает внутренний идентификатор объекта (например номер заказа), но он становится известен во время stateCheck. В этом случае удобно делать связывание внутренних идентификаторов реальной системы с нашими виртуальными объектами на этом шаге. После чего в feedback проверках можно использовать этот идентификатор как ключ.
Если вам кажется, что проверка сразу всех однотипных объектов является излишней, при изменении хотя бы одного из них, то учтите, что внутри одного сценария часто находятся потенциально взаимозависимые объекты. Также stateCheck проверки являются “срезами” состояний системы, что сильно помогает при расследовании проблем.
InnerStep и GlobalContext
Рассмотрим достаточно сложную для нашей автоматизации ситуацию: пусть магазин не имеет собственной службы доставки, а курьерская служба с которой мы работаем имеет очень низкий уровень развития IT. Из-за этого информация о получении заказа приходит не в реальном времени, а в конце их операционного дня, причём данные отправляются в виде большого текстового файла в котором есть информация сразу по всем доставленным заказам за день.
Нам нужно проверить, что файл корректно обрабатывается. Для этого мы должны сформировать его на основании данных заказов из наших тестовых сценариев. В какой-то один сценарий это вынести нельзя по разным причинам:
в большинстве сценариев заказ должен завершиться доставкой, т.е. почти в каждом из сценариев должно быть что-то вроде order1.delivered()
может быть огромное число тестовых случаев связанных именно с доставкой и описание их всех в одном сценарии будет адом, а этого мы хотим избежать
в некоторых сценариях, факт доставки будет лишь предварительным условием, например, в случаях возврата товара
Получается, что данные для факта доставки должны быть доступны сразу из всех сценариев, а чтобы не нарушать изолированность внутренних объектов сценария (таких как client, order и т.д.) нам придётся ввести некий общедоступный globalContext.
По мере необходимости в этот общий контекст будут добавляться свои объекты, например globalContext::deliveryConfirmation, а в сценариях это будет выглядеть примерно так:
// ScenarioXYZ
stage("ConfirmDelivery-add") {
// добавляем данные о доставке в globalContext
globalContext::deliveryConfirmation.add(order1)
}
// Auxillary
stage("ConfirmDelivery-sendFile") {
// формируем файл на основе данных других сценариев
globalContext::deliveryConfirmation.generate_file()
}Проблема с формированием общего для всех доставок файла решена, но при этом в расписании пока нет места для выполнения проверок, ведь stage("ConfirmDelivery-sendFile") выполняется уже после окончания stage("ConfirmDelivery-add") и его stateCheck/feedback блоков.
Давайте попробуем это исправить добавив проверки в отдельный stage. Рассмотрим это на примере из двух сценариев: Scenario1 (работа с заказом) и Auxiliary (тут будет отправка файла). Чтобы было понятно запишем их выполняемые действия в хронологическом порядке:
/* Scenario1 */
stage("ConfirmDelivery-add") {
// данные в globalContext добавлены, но проверки пока выполнять
// нельзя
globalContext::deliveryConfirmation.add(order1)
}
/* Auxiliary */
stage("ConfirmDelivery-sendFile") {
// файл отправлен, проверки уже выполнять можно, но тут мы ничего не знаем
// о внутренних объектах других сценариев таких как Scenario1::order1
globalContext::deliveryConfirmation.generate_file()
}
/* Scenario1 */
stage("ConfirmDelivery-check") {
// action часть в checkDelivery() не нужна, нам просто нужно
// инициировать выполнение всех stateCheck и feedback проверок
// для order1
order1.checkDelivery()
}Это “прекрасно” работает, но выглядит несколько коряво…
Чтобы выполнить это всё за один stage, просто добавим новый туда блок для “ConfirmDelivery-sendFile” из auxiliary, назовём его innerStep. Т.е. stage теперь будет выглядеть так:
action
innerStep
<pause>
stateCheck
feedback
Так же объединим обновление globalContext и проверки из checkDelivery в новый event:
event Order.confirmDelivery() {
// добавляем данные в globalContext
globalContext::deliveryConfirmation.add(this)
// инициируем stateCheck проверки
orders.setUpdated()
feedback {
// описываем все необходимые feedback проверки
}
}После чего сценарии приобретают нормальный вид:
/* Scenario1 */
stage(“ConfirmOrder”) {
order1.confirmDelivery()
}
/* Auxiliary */
// суффикс @InnerStep в имени stage указывает на то, что функция
// будет выполнена в соответствующем блоке
stage(“ConfirmOrder@InnerStep”) {
globalContext::deliveryConfirmation.generateFile()
}На этом наполнение блоками нашего stage будем считать законченным. А вот про globalContext хочется добавить пару замечаний:
в реальном тестировании в нём обычно содержится очень много информации: там может быть список номеров пластиковых карт для тестовых платежей, внутренняя копия товаров с ценами и т.д.
также, там обязательно должен быть общий счётчик, на основании которого генерируются уникальные для всех сценариев идентификаторы (смотрите реализацию функции generate в коде на github)
Другими словами globalContext в реальном тестировании играет очень важную роль.
Сценарии
Опишем свойства идеального, с моей точки зрения, сценария:
Не содержит вызова проверок, они выполняются автоматически.
Наши внутренние объекты должны иметь удобные для тестировщика имена, например client1, order2 и т.д. Это упрощает написание и восприятие длинных сценариев.
Для простых случаев ожидаемый результат действий должен вычисляться автоматически. Например, стоимость заказа можно рассчитать сложив стоимость его позиций, и не требовать явного указания в сценарии
Если переданные в event данные не позволяют сразу определить поведение системы, то это должно указываться явно. Например, можем специально попробовать создать двух пользователей с одним e-mail, что не допускается нашим магазином. В этом случае требуется явное указание об ошибке.
Сценарий не должен содержать ветвлений, иначе это просто минимум два сценария. По сути он должен быть декларативным.
Выполнять проверки автоматически с помощью events/stages мы научились ранее, а объектный подход дал нам понятные имена. То, что нужно указывать явно, а что лучше считать в events автоматически, приходит с опытом. Ну и отсутствие ветвлений непосредственно в сценариях – это просто культура их написания.
Всё перечисленное в сумме даёт очень компактные и легко читаемые сценарии. Давайте посмотрим это на простом примере:
scenario ("SomeScenario") {
// метаданные позволяют фильтровать сценарии при запуске прогона и
// добавляют полезную информацию в отчёты
metadata {
owner: "Vasya"
labels: Client, Order, Negative
}
stage ("CreateClient") {
client1 = createClient(email = "vasya@mail.test", <...>)
// Негативный случай не приводит к созданию виртуального
// объекта в системе, а специальное имя в виде '_' делает
// негативные случаи более видимыми.
// Поведение при сложной бизнес-логике не считаем,
// а явно передаём в event.
_ = createClient(
isValid = false,
error_message = "Клиент с email 'vasya@mail.test', уже существует",
email = client1.email, // vasya@mail.test
<...>
)
}
stage ("CreateOrder") {
// а вот расчёт стоимости заказов можно спокойно перенести внутрь event
order1 = client1.createOrder(["носки": 10/*штук*/, "перчатки": 1/*пара*/])
order2 = client1.createOrder(["интересная книга": 1/*штука*/])
}
// отправка заказов у нас раз в день, поэтому createDelivery может
// выполняться только в выделенном для этого stage, иначе stateCheck
// проверки покажут ошибку
stage ("SendOrder") {
// createDelivery не только создаст новый объект но и свяжет с ним
// наши order1 и order2
delivery1 = createDelivery(orders = [order1, order2])
}
stage ("ConfirmDelivery") {
// носки и перчатки клиенту понравились
order1.confirmDelivery()
// а вот книга оказалась не очень-то интересной
order2.rejectDelivery()
// Помимо обновления статуса заказов и статуса доставки у нас ещё деньги
// от order2 вернуться на внутренний счёт клиента. Поэтому логично в
// rejectDelivery и confirmDelivery устанавливать флаги обновления для
// всех объектов сценария:
// clients.setUpdated(), orders.setUpdated(), deilveries.setUpdated().
}
}Пример реализации
Реализация данной идеи в реальном проекте сделана на язык Kotlin. Он позволяет создавать свой собственный DSL язык, что, я считаю, критичным при описании сценариев. Также, Kotlin позволяет задавать значения по-умолчанию для входных параметров функций, что сильно облегчает поддержку тестовой библиотеки в условиях постоянно развиваемой тестируемой системы
Минимальная реализация представлена на github. Для простоты восприятия там нет связи с каким-либо фрэймворком автоматизации или системами построения отчётов, а также удалены многие полезные мелочи, такие как: работа с конфигами, фильтрация запуска сценариев на основании их медатаданных и т.д. Но при этом всё, что связано с реализацией расписания, там сохранено в максимально близком к реальному проекту виде. Из-за вышеописанных ограничений всё “тестирование” представляет из себя создание и обновление “виртуальных” объектов и вывод их состояния на экран.
Итоги
Объединение двух достаточно простых идей: объектного подхода и использование events/stages в расписании, позволило превратить ад автоматизации e2e тестирования в достаточно интересный и высокоэффективный процесс. При этом, получилось достигнуть всех целей, которые были заложены при разработке данной концепции:
проверки больше не теряются
ошибки сценариев хорошо видны в отчётах
сценарии понятны даже людям, не вовлечённых в процесс тестирования
написать простой сценарий можно буквально за 15 минут
автоматизация помогает в ручном тестирование при создании предварительных условий
поддержка тестовой библиотеки достаточно простая, т.к. при изменение функционала тестируемой системы обычно нужно поправить только логику нескольких events, а не все сценарии
размылась граница между ручными тестировщиками и автоматизаторами тестирования, т.к. для написание автоматических сценариев не требуется хороших навыков программирования
но минимум один хороший программист в команде должен быть, чтобы создать каркас библиотеки и помогать другим тестировщикам (иногда без опыта программирования) со сложными проблемами.
А также из-за огромного числа вещей происходящих в автоматическом режиме, складывается впечатление, что здесь не обошлось без щепотки магии.
Klems
При чтении статьи, местами возникает ощущение, что вы сами создали себе проблемы, которые потом героически решали (и теперь есть о чем поделиться на Хабре).
Нет, схема то интересная. Но если она у вас решила одну проблему, но добавила две - то возможно такая схема не совсем подходит?
Если вы можете выполнять последовательно первые шаги всех сценариев, а потом делать ожидание и выполнять проверки (на момент проверок созданы куча заказов и прочих данных для всех сценариев разом, т.е. друг другу они не мешают), то почему же вы не могли просто распараллелить все сценарии?
С самого начала посыл стоял в том, что вас не устраивали задержки по 10сек в каждом тесте. При этом пассивное ожидание я уже давно нигде не встречал. Есть же такие библиотеки как awaitility, позволяющие делать "активное" ожидание (проверка производится с заданной периодичностью в течение некоторого времени, после которого наступает timeout). И вместо того, чтобы всегда ждать 10 сек, вы будете проходить проверку как только, так сразу.
Автоматические проверки - хорошо. Но неявные проверки, которые для теста обязательны - не очень хорошо. Есть риск, что такую проверку из общего места уберут (допустим она будет неприменима для большого количества новых тестов), а туда, где она была нужна - не добавят. Потому что забудут, и потому что будет неочевидно, кому она была нужна. То есть на данный момент, добавляя новый тест, вам нужно держать в голове, где какие проверки делаются неявно.
kubashin_a Автор
Сделайте скидку на то, что в этой статье примеры очень игрушечные. В реальной жизни тестировались отнюдь не интернет-магазины, а достаточно сложные финтех системы с очень "богатым" расписанием. В них огромное количество вещей происходит не потому-что вы дёрнули какой-то API, а потому-что пришло для этого время. Смотрите пример с агрегацией доставок в 18:00 из начала статьи.
Именно из-за расписания запускать сценарии просто параллельно при этом невозможно, их нужно синхронизировать между собой по массовым операциям.
Просто для понимания масштаба проблемы: одна из тестовых библиотек покрывала две недели плюс последний день месяца работы реальной системы. При этом полный регрешен составлял более 6000 сценариев и около 3600 Global Steps.
Проблемы которые мы решали и решили описаны в конце статьи: проверки больше не теряются, ошибки сценариев видны в отчётах и т.д. История про 10сек – это просто пример... Но мы часто сталкиваемся с тем, что единственный способ корректно выполнить проверку, это ввести фиксированную паузу. Если есть возможность сделать "умное" ожидание, то мы всегда предпочитаем его.
Автоматические проверки несколько раз помогли нам найти проблему после ручного тестирования. Просто потому, что тестировщик не подумал сделать проверку в промежуточном этапе. Ну и по мере роста тестовой библиотеки, ручная расстановка проверок – это определённая боль: кто-то её просто пропустит, какая-то проверка добавиться когда у вас уже есть несколько сотен сценариев и добавлять её руками будет проблематично.
P.S. Эта схема и правда подходит только для весьма специфичных случаев, но если подходит… то работает более чем отлично )