
Привет, Хабр!
Сегодня хотим обсудить «вечную» тему нынешнего века – эффективное и надёжное хранение данных. По исследованиям некоторых учёных, в год человечество генерирует данных больше, чем вся цивилизация с древнейших времён и до начала нашего столетия.
Куда нам столько и что делать с этой информацией? Кроме того, при таких объёмах встаёт вопрос не только хранения, но и извлечения данных. Поэтому мы решили вспомнить, какие способы для этого существуют и какой из них выбрать. Итак, начнём.

Эпоха электричества ознаменовала появление нового класса машин – компьютеров, которые позволили обрабатывать и хранить большое количество информации, ранее недоступное человеку.
Существенной вехой в истории развития вычислительных машин является появление категории «файлов».

Если рассмотреть понятие файла, оно заключается в том, что это некоторая область на устройстве хранения информации, имеющая своё название, из которой можно считывать данные и в которую их можно записывать.
Шестидесятые годы XX века являются рубежом, с которого начинается использование компьютеров не только в качестве исполнителей счётных задач, но и для обработки документов.
Для реализации вышеозначенной задачи требуется ввести новое понятие, так называемую «базу данных», суть которой сводится к некоторой совокупности организованно хранящейся информации.
Структура базы данных предполагает также взаимодействие между составляющими её различными элементами. Именно потребность в необходимости оперирования файлами привела к появлению надстройки над операционной системой – системы управления базами данных.
В этой статье мы рассмотрим системы управления базами данных, а также узнаем, что же представляют собой реляционные и нереляционные базы и в чём заключаются их особенности.
Ниже мы собрали список
основных пунктов, чтобы вам было проще ориентироваться по статье:
Программное обеспечение для работы с современными базами данных
В специализированной программе, которая использует для своего функционирования файл или файлы, за полноту и достоверность содержащихся данных обычно отвечал один человек. С появлением же потребности в использовании базы данных многими пользователями и многими специализированными программами появилась необходимость в отделении собственно хранения данных от самих прикладных программ, одновременно с необходимостью ведения их c требующимися полнотой, внесением нужных изменений и безопасностью.
Именно с этого момента начинает работу специализированный посредник, который берёт на себя функцию взаимодействия между конкретной прикладной программой и базой данных. Этот посредник получил название «система управления базами данных», или сокращенно ― СУБД.
СУБД представляет собой специальную программу, имеющую основной своей функцией создание, изменение и ведение базы данных некоторой совокупностью пользователей через прикладные программы.
Основные функции программного обеспечения баз данных
Создание изначальной структуры базы данных;
СУБД создаёт структуру базы данных в виде диалога, то есть последовательно получает от пользователя требующиеся ей данные. После чего производится начальное создание базы данных;
Возможность модифицирования данных пользователем. Дальнейшая работа с базой данных через СУБД позволяет пользователям вносить новые данные, стирать их, производить различные выборки. Такие возможности даёт специальный язык программирования, графический интерфейс пользователя;
Независимость прикладных программ от базы данных. Это позволяет изменять в некоторых пределах логическое представление базы данных, не меняя сам способ хранения; в то же время это позволяет производить некоторые изменения в базе данных, не вызывая необходимости поменять представление данных;
Логическое единство базы данных. СУБД не позволит ввести цифру вместо буквы, неправильную дату и т. д.;
Защита от повреждений в случае неправильного функционирования или повреждения ЭВМ – современные СУБД имеют средства резервного восстановления базы;
Разграничение доступа пользователей в зависимости от категории. Современные СУБД имеют средства контроля доступа, которые позволяют пользователям иметь доступ только к тем данным, к которым они имеют право;
Обеспечение одновременной работы нескольких пользователей. СУБД предоставляет средства одновременной работы, которые защищают целостность базы с помощью различных блокировок;
Управление хранением. Так как база данных располагается в памяти компьютера, при работе с ней происходит освобождение определённых блоков и заполнение других. СУБД производит рациональное управление местом хранения;
Поддержка деятельности администратора. Так как в процессе работы СУБД может потребоваться ввод новых данных технического типа: новое разграничение доступа, изменение структуры и т. д. СУБД предоставляет удобные средства, которые позволяют администратору производить все эти действия.
Преимущества и недостатки СУБД
Преимущества:
отслеживание отсутствия избыточности и согласованности данных;
использование данных многими пользователями;
сохранение структуры данных, то есть их целостности;
обеспечение безопасности;
стандартизация;
увеличение эффекта от использования системы управления данными с ростом масштаба (т. е. ярко выраженный эффект масштаба);
доступ к большим данным и их постоянная готовность к работе;
повышение производительности работы;
облегчение обслуживания системы, так как нет критической зависимости от какого-либо конкретного типа данных.
Но, несмотря на все ярко выраженные преимущества пользования системами управления базами данных, этот процесс также содержит определённый ряд сложностей, которые встают на пути.

Среди них можно перечислить:
общее большое усложнение всей системы;
дороговизна;
материальное обеспечение (аппаратное);
большие материальные затраты при сбое системы.
Реляционные базы данных
В последнее время большое распространение получила «реляционная модель», суть которой заключается в том, что основанная на математической теории множеств она рассматривает таблицы как отдельные множества, объединённые по определённому признаку, как показано на рисунке 1.
")
Для удобства представления и хранения система хранения данных в рамках реляционной модели обычно представляет собой совокупность таблиц, взаимосвязанных между собой определённым образом.
Таблица представляет собой плоскую двумерную сетку, которая содержит определённый тип или типы структурированных данных, например фильмы, группы крови, маршруты движения и т. д.
Если разбирать дальнейшее устройство любой таблицы, то она состоит из столбцов и строк.
Столбец таблицы представляет собой вертикальную область, выделенное свойство всех типологий, которые содержатся обычно в строках таблицы.
Строка таблицы представляет собой горизонтальную область, которая уникализирует типологию. Например, в строках таблицы могут содержаться фамилии, марки автомобилей, названия улиц и т. д.
Структурные элементы таблицы, из которых она состоит, взаимодействуют между собой, а также с другими структурными элементами других таблиц.
С ростом количества информации появилась необходимость в специальном языке, который бы оперировал данными и мог функционировать в абсолютно различающихся компьютерных системах таким образом, чтобы пользователи могли оперировать данными, составляя определённые запросы.
Отвечая на запросы времени, появился определённый язык, который получил название SQL – Structured Query Language (язык структурированных запросов), он был выпущен в 1986 году и к нынешнему времени фактически стал стандартом.
В качестве основных форм языка SQL можно назвать следующие:
интерактивная;
встроенная;
динамическая;
статическая.
Суть интерактивного SQL заключается в том, что пользователь базы данных может в интерактивном режиме использовать SQL-операторы.
Встроенный SQL позволяет интегрировать его операторы в код программы; в свою очередь, динамическая форма позволяет на лету генерировать операторы в процессе выполнения программ.
В отличие от перечисленных выше, статический представляет собой заранее определённые операторы в момент компиляции программы.
Если же говорить о достоинствах языка SQL, то среди них можно перечислить следующие:
переносимость между различными платформами;
стандартизированность;
поддержка компанией IBM;
поддержка компанией Microsoft;
основан на реляционных принципах;
высокоуровневая структура;
может исполнять запросы интерактивно;
может давать доступ к базам данных через программы;
предоставляет все средства языка для удобного доступа к базам данных;
поддержка различных архитектур;
поддержка бизнес-приложений;
наличие доступа к данным через сеть Интернет;
интегрированность с языком Java.
Системы управления базами данных могут работать как в качестве серверной части, то есть реализовывать архитектуру «клиент-сервер», так и в виде настольной версии, то есть СУБД, работающей локально.
Серверная система управления базами данных занимается хранением и поддержкой, а также отвечает на поступающие от клиентов запросы.
Под клиентами подразумеваются любые компьютеры или приложения, которые обращаются к базе данных, используя специальный язык обращений.
Причём если мы говорим об архитектуре «клиент-сервер», то клиент может даже находиться в одной стране, а сервер – в другой. Здесь под клиентом понимается обычный компьютер, а под сервером – специализированная машина, достаточно мощная, чтобы хранить базы и обрабатывать множество запросов.
В качестве главного отличия любой настольной СУБД от серверной можно назвать то, что она работает локально и не может обрабатывать запросы, поступающие от других клиентов.
Если перечислить основные виды известных SQL-серверов, то среди них можно назвать: Microsoft SQL Server, Oracle, MySQL, Postgresql.
В свою очередь, системой, поддерживающей SQL и являющейся настольной, можно назвать Microsoft Access.
Нереляционные базы данных
Кроме традиционных баз (SQL), существует ещё другой способ хранения данных, получивший широкое распространение со второй половины двухтысячных годов, – нереляционные базы данных. Они отличаются от реляционных тем, что в них для хранения используется не система из строк и столбцов, а применяется модель, которая оптимизирована для хранения определённого типа содержимого. Например, данные могут храниться в виде документов JSON, графов, а также ключей-значений.
Кроме того, можно сказать, что нереляционные базы данных не используют язык запросов SQL, и вместо него запросы осуществляются с помощью иных языков и конструкций. Ниже рассмотрим, какие типы NoSQL баз данных бывают.
Хранилища документов
Такой тип оперирует набором данных объекта, которые называются документом. Они хранятся в полях, которые могут быть представлены различными форматами, среди которых можно назвать такие, как XML, JSON и т. д. Набор данных и их полнота зависят от целей конкретного применения.
Причём здесь важным моментом является то, что в отличие от реляционной модели хранения, где данные одного объекта могут быть распределены по разным таблицам, здесь они хранятся в одном документе, и этот тип хранения не требует, чтобы все документы имели одинаковую структуру, благодаря чему и достигается достаточно большая гибкость.
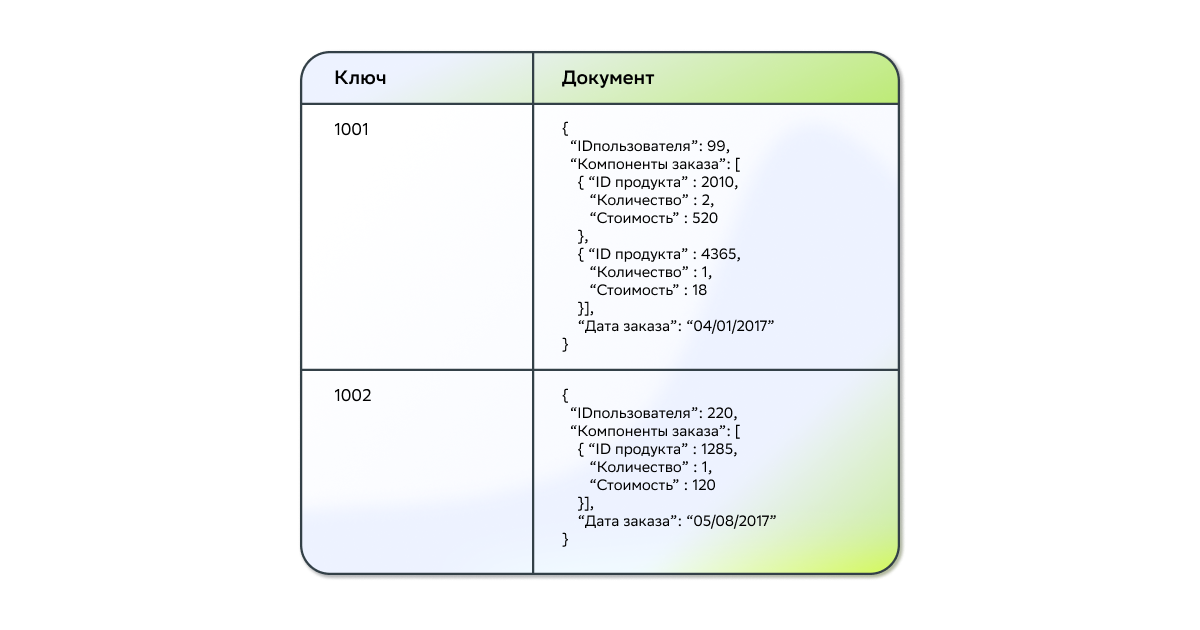
Для получения документов используется ключ документа, который представляет собой уникальную идентифицирующую сущность, благодаря которой можно получить доступ к конкретному документу.
Хранение данных в столбцах
Подобный тип хранения по своему виду очень сильно похож на реляционную базу данных – данные хранятся в столбцах, которые связаны и управляются как единое целое. В отличие от других типов хранения данных, при этой методике упорядочение данных происходит с помощью ключей, а не хэшей.
Хранение в виде «ключи-значения»
При таком способе хранения данные находятся в большой таблице, каждый набор данных обладает уникальным ключом. Подобный тип хранения можно использовать для применений, где используется поиск по ключам или диапазону ключей, но в то же время подобный тип хранения неудобен, если требуется осуществлять поиск и фильтрацию по значениям.
Хранилища содержимого графов
Данный тип хранилища представляет собой хранение данных, содержащихся в узлах, а также определяет связь между узлами. Подобные хранилища позволяют достаточно оперативно выполнять запросы, которые проходят через ряд узлов и рёбер, и производить анализ взаимосвязей между узлами.

Такие структуры позволяют производить поиск, например, «всех сотрудников, работающих в определённом отделе» либо «находящихся в подчинении определённого руководителя» и т. д.
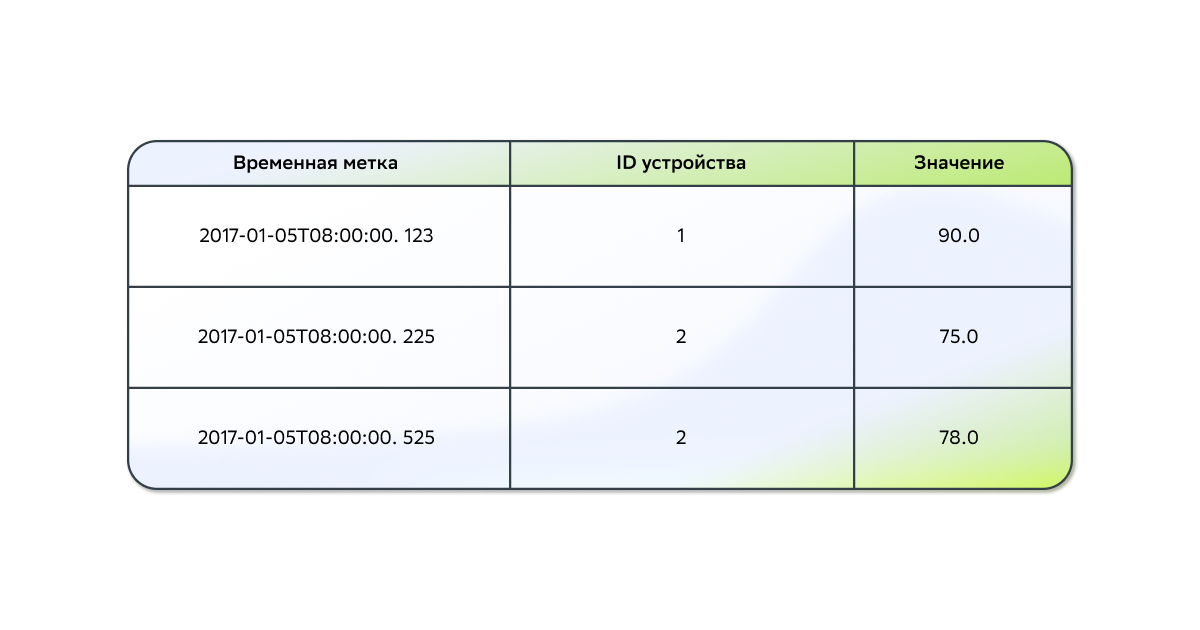
Хранилища данных временных рядов
Этот тип хранилища используется для наборов значений, которые обладают небольшим весом и привязаны к определённым моментам времени. Обычно это данные телеметрии, например датчика или датчиков интернета вещей.
Хранилище объектов
Подобного типа хранилища используются для сохранения и извлечения данных большого веса, в качестве которых могут выступать видеофайлы, изображения, файлы приложений и т. д. Само хранилище обладает, как правило, также достаточно большим объёмом, что позволяет ему хранить подобное содержимое.

Хранилище внешних индексов
Используется для индексированных данных других хранилищ, то есть подобный тип хранилища выступает в роли посредника, который ускоряет доступ к другим базам.
Как выбрать тип базы?
Как правило, реляционные базы выбирают для работы со сложными запросами и обработки рутинных задач. И здесь следует учесть вот что: SQL-базы масштабируются по вертикали, то есть с помощью увеличения нагрузки на отдельный конкретный сервер. В свою очередь, NoSQL-базы хорошо масштабируются по горизонтали за счёт увеличения количества серверов, что является весьма удобным при работе с большими объёмами данных, так называемыми Big Data.
Ещё одним интересным плюсом NoSQL является возможность хранения коллекций с различными атрибутами и полями, что позволяет за счёт отсутствия жёстких ограничений реализовывать поэтапную разработку. Также нереляционные базы хорошо справляются с задачами хранения недостаточно структурированных или же абсолютно неструктурированных данных.
Так как нереляционные базы, как правило, предназначены для доступа к ним с помощью конкретных шаблонов, они позволяют добиться более высоких показателей производительности, если сравнивать их с SQL-базами.
Среди некоторых из популярных нереляционных баз можно перечислить: MongoDB, Apache Cassandra, Couchbase.
Заключение
Компьютерная сфера вообще и технологии хранения данных в частности – это одна из тех сфер, которые претерпевают постоянные и очень быстрые изменения.
Сейчас, кроме реляционного способа хранения данных, появляются и развиваются и нереляционные способы, так называемые NoSQL. Потенциально данный способ при соответствующем подходе может дать большую производительность ввиду существенных отличий от реляционного подхода.
Нельзя дать однозначный ответ на вопрос, какой из типов баз является лучшим. Скорее следует руководствоваться комплексом нужных вам параметров: скорость доступа, тип данных, способ будущего масштабирования, наличие персонала, способного работать с этим типом баз и т. д.
В целом, для обеспечения эффективности могут быть выделены три основные составляющие:
хранение данных должно происходить распределённо, то есть внутри сети, которая состоит из нескольких ЭВМ, несмотря на то, что сами файлы могут быть достаточно большими;
необходимо создать такую схему хранения данных, которая обеспечит существенные преимущества по сравнению с традиционными реляционными базами данных, несмотря на то, что сами данные являются разреженными;
схема обработки данных должна строиться так, чтобы они обрабатывались непосредственно на той машине, где и находятся. Это позволит избежать передачи огромного массива по сети и в конечном счёте поднимет производительность.
Комментарии (4)

DonVietnam
23.06.2022 11:10Статья ради статьи и не более, уровень компании показываете моё почтение. СУБД - оказывается дорогостоящая вещь, буду знать.

hard_sign
23.06.2022 12:37Справедливости ради, это не уровень технической экспертизы, а уровень PR (или типа DR) отдела.

EvgenyVilkov
24.06.2022 14:00"И здесь следует учесть вот что: SQL-базы масштабируются по вертикали, то есть с помощью увеличения нагрузки на отдельный конкретный сервер "
Вы уверены? О MPP SQL c горизонтальным масштабированием не слышали? :)
mSnus
Так и предоставляю себе, как ПМ в Сбере выбирает базу данных, руководствуясь этой статьей, а потому городо объявляет команде разработчиков: "Мы будем использовать самую лучшую базу данных, которая называется SQL. Её даже IBM поддерживает! А кто не согласен, пусть идёт грузить люминь - самое лёгкое железо!"